
Rumah >Peranti teknologi >AI >SurroundOcc: Surround 3D grid penghunian SOTA baharu!
SurroundOcc: Surround 3D grid penghunian SOTA baharu!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-09-18 20:25:011820semak imbas
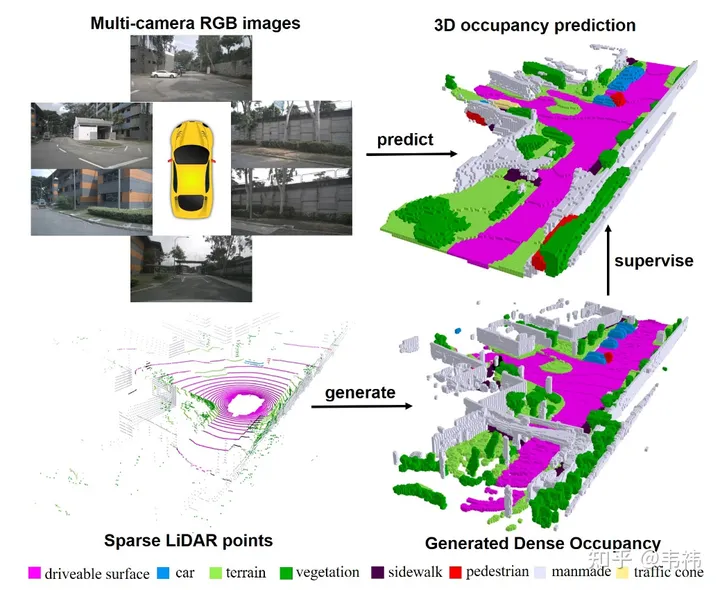
Dalam kerja ini, kami membina set data raster penghunian padat daripada awan titik berbilang bingkai dan mereka bentuk rangkaian raster penghunian tiga dimensi berdasarkan struktur Unet 2D-3D berasaskan pengubah. Kami berbesar hati kerana artikel kami telah disertakan dalam ICCV 2023. Kod projek kini adalah sumber terbuka dan semua orang dialu-alukan untuk mencubanya.

arXiv: https://arxiv.org/pdf/2303.09551.pdf
Kod: https://github.com/weiyithu/SurroundOcc
Pautan halaman utama: https://weiby.itio. SurroundOcc/
Saya telah mencari kerja seperti orang gila sejak kebelakangan ini, dan saya tidak sempat menulis baru-baru ini. Sebagai pengakhiran kerja saya, saya fikir lebih baik untuk menulis Ringkasan Zhihu. Malah, pengenalan artikel itu sudah ditulis dengan baik oleh pelbagai akaun awam, dan terima kasih kepada publisiti mereka, anda boleh terus merujuk kepada Heart of Autonomous Driving: nuScenes SOTA! SurroundOcc: Rangkaian ramalan penghunian 3D visual tulen untuk pemanduan autonomi (Tsinghua & Tianda). Secara umum, sumbangan dibahagikan kepada dua bahagian Satu bahagian ialah cara menggunakan awan titik lidar berbilang bingkai untuk membina set data penghunian yang padat, dan bahagian lain ialah cara mereka bentuk rangkaian untuk ramalan penghunian. Malah, kandungan kedua-dua bahagian adalah agak mudah dan mudah difahami Jika anda tidak faham apa-apa, anda boleh bertanya kepada saya. Jadi dalam artikel ini, saya ingin bercakap tentang sesuatu selain daripada tesis Satu ialah bagaimana untuk menambah baik penyelesaian semasa untuk menjadikannya lebih mudah untuk digunakan, dan yang lain ialah arah pembangunan masa depan.
Deployment
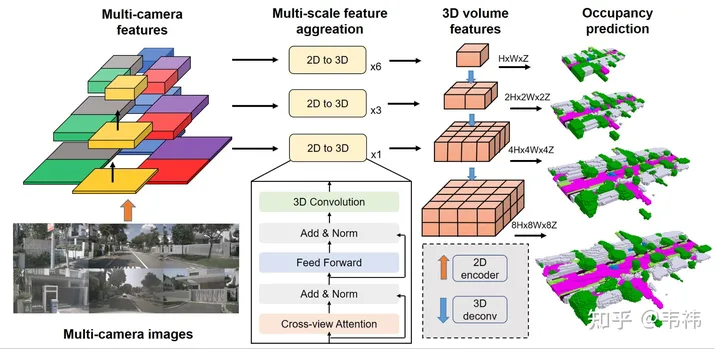
Sether Rangkaian mudah digunakan terutamanya bergantung kepada sama ada terdapat mana -mana pengendali yang sukar dilaksanakan di bahagian papan. lapisan dan lilitan 3D.
Fungsi utama transformer adalah untuk menukar ciri 2D kepada ruang 3D Malah, bahagian ini juga boleh dilaksanakan menggunakan LSS, Homography atau pun mlp, jadi bahagian rangkaian ini boleh diubah suai mengikut penyelesaian yang dilaksanakan. Tetapi setakat yang saya tahu, penyelesaian pengubah tidak sensitif kepada penentukuran dan mempunyai prestasi yang lebih baik di kalangan beberapa penyelesaian Adalah disyorkan bahawa mereka yang mempunyai keupayaan untuk melaksanakan penggunaan pengubah harus menggunakan penyelesaian asal.
Untuk lilitan 3D, anda boleh menggantikannya dengan lilitan 2D Di sini anda perlu membentuk semula ciri 3D asal (C, H, W, Z) ke dalam ciri 2D (C* Z, H, W), dan kemudian. Anda boleh menggunakan lilitan 2D untuk pengekstrakan ciri Dalam langkah ramalan penghunian terakhir, bentuk semula ke (C, H, W, Z) dan lakukan penyeliaan. Sebaliknya, sambungan langkau menggunakan lebih banyak memori video kerana resolusinya yang lebih besar Semasa penggunaan, ia boleh dialih keluar dan hanya lapisan resolusi minimum yang akan ditinggalkan. Percubaan kami mendapati bahawa kedua-dua operasi dalam lilitan 3D ini akan mempunyai beberapa titik kejatuhan pada nuscenes, tetapi skala set data industri adalah jauh lebih besar daripada nuscenes, dan kadangkala beberapa kesimpulan akan berubah, dan titik drop harus kurang atau bahkan tiada.
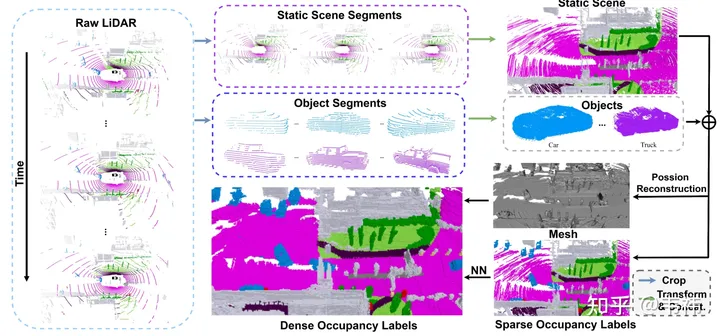
Dari segi pembinaan set data, langkah yang paling memakan masa ialah pembinaan semula Poisson. Kami menggunakan set data nuscenes, yang menggunakan lidar 32 baris untuk pengumpulan. Walaupun menggunakan teknologi jahitan berbilang bingkai, kami mendapati masih terdapat banyak lubang pada awan titik yang dijahit. Oleh itu, kami menggunakan pembinaan semula Poisson untuk mengisi lubang ini. Walau bagaimanapun, banyak awan titik lidar yang kini digunakan dalam industri adalah agak padat, seperti M1, RS128, dsb. Oleh itu, dalam kes ini, langkah pembinaan semula Poisson boleh diabaikan untuk mempercepatkan pembinaan set data
Sebaliknya, SurroundOcc menggunakan bingkai pengesanan sasaran tiga dimensi yang dianotasi dalam nuscenes untuk memisahkan pemandangan statik dan objek dinamik . Walau bagaimanapun, dalam aplikasi sebenar, autolabel, yang merupakan model pengesanan & penjejakan sasaran tiga dimensi yang besar, boleh digunakan untuk mendapatkan bingkai pengesanan setiap objek dalam keseluruhan jujukan. Berbanding dengan label beranotasi secara manual, hasil yang dihasilkan dengan menggunakan model besar pasti akan mempunyai beberapa ralat Manifestasi yang paling langsung ialah fenomena ghosting selepas penyambungan berbilang bingkai objek. Tetapi sebenarnya, pekerjaan tidak mempunyai keperluan yang tinggi untuk bentuk objek Selagi kedudukan bingkai pengesanan adalah agak tepat, ia boleh memenuhi keperluan.
HALA TUJU MASA DEPAN
Kaedah semasa masih bergantung pada lidar untuk memberikan isyarat pengawasan penghunian, tetapi pada banyak kenderaan, terutamanya yang mempunyai pemanduan berbantu aras rendah Tanpa lidar , kereta ini boleh menghantar semula sejumlah besar data RGB melalui mod bayangan, jadi hala tuju masa depan ialah sama ada mereka hanya boleh menggunakan RGB untuk pembelajaran diselia sendiri. Penyelesaian semula jadi adalah menggunakan NeRF untuk penyeliaan Secara khusus, bahagian tulang belakang hadapan kekal tidak berubah untuk mendapatkan ramalan penghunian, dan kemudian pemaparan voxel digunakan untuk mendapatkan RGB dari setiap perspektif kamera, dan nilai sebenar RGB dalam set latihan digunakan. sebagai kerugian Buat isyarat penyeliaan. Tetapi sayangnya kaedah mudah ini tidak berfungsi dengan baik apabila kami mencubanya Kemungkinan sebabnya ialah julat pemandangan luar terlalu besar, dan nerf mungkin tidak dapat menahannya, tetapi ia juga mungkin. bahawa kami belum melaraskannya dengan betul. Anda boleh mencubanya lagi.
Arah lain ialah masa & aliran pekerjaan. Malah, aliran pekerjaan jauh lebih berguna untuk tugas hiliran daripada pekerjaan rangka tunggal. Semasa ICCV, kami tidak mempunyai masa untuk menyusun set data aliran pekerjaan, dan apabila kami menerbitkan kertas kerja, kami perlu membandingkan banyak garis dasar aliran, jadi kami tidak mengusahakannya pada masa itu. Untuk rangkaian pemasaan, anda boleh merujuk kepada penyelesaian BEVFormer dan BEVDet4D, yang agak mudah dan berkesan. Bahagian yang sukar ialah set data aliran Objek umum boleh dikira menggunakan rangka pengesanan sasaran tiga dimensi jujukan, tetapi objek berbentuk khas seperti beg plastik haiwan kecil mungkin perlu diberi penjelasan menggunakan kaedah aliran tempat kejadian.

Kandungan yang perlu ditulis semula ialah: Pautan asal: https://mp.weixin.qq.com/s/_crun60B_lOz6_maR0Wyug#🎜 #
Atas ialah kandungan terperinci SurroundOcc: Surround 3D grid penghunian SOTA baharu!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- rpa是什么技术
- Apakah itu teknologi bahagian hadapan web?
- Sejauh manakah anda tahu tentang teknologi navigasi inersia pemanduan autonomi?
- Artikel ini akan memberi anda pemahaman yang mudah difahami tentang pemanduan autonomi
- Satu artikel untuk memahami persepsi lidar dan gabungan visual mengenai pemanduan autonomi