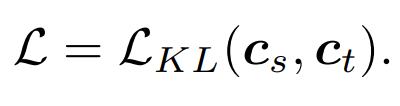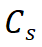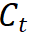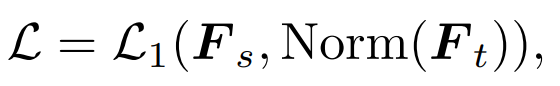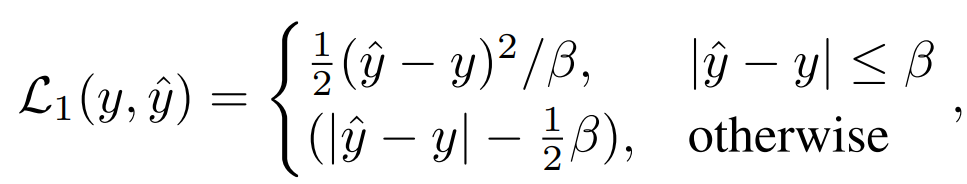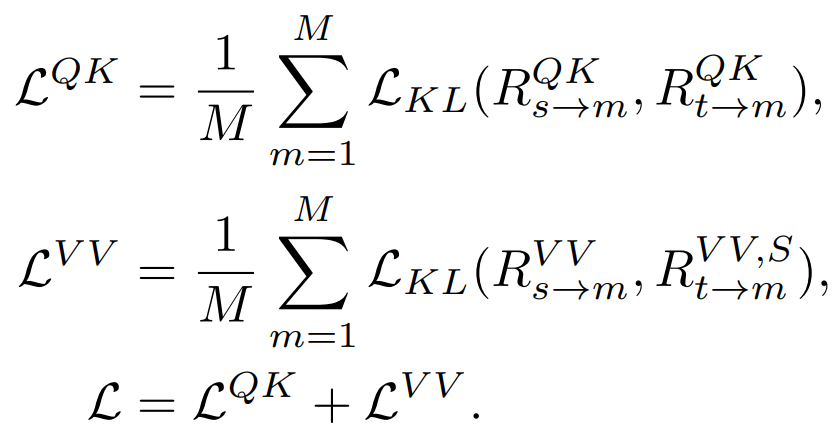Dinyatakan semula: Motivasi penyelidikan
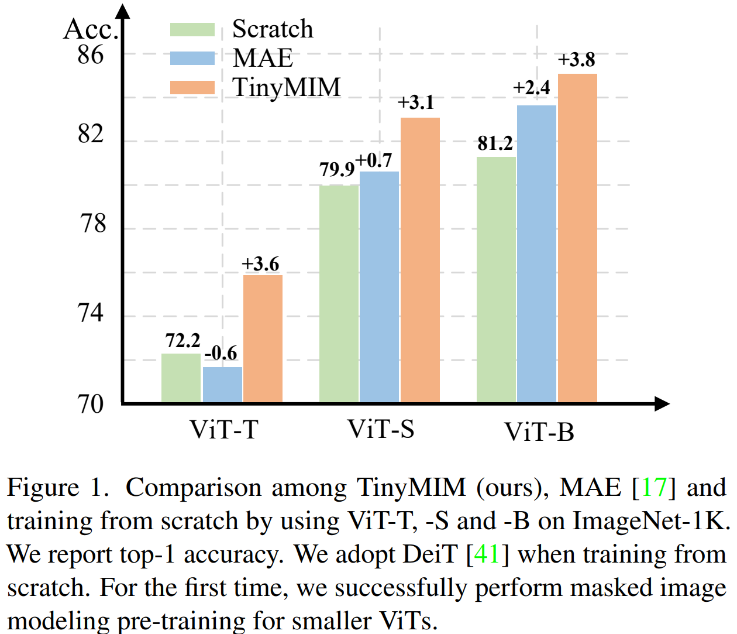
Pemodelan topeng diri yang provis, sangat berkesan dan berkesan. Walau bagaimanapun, seperti yang ditunjukkan dalam Rajah 1, MIM berfungsi lebih baik untuk model yang lebih besar. Apabila model sangat kecil (seperti parameter ViT-T 5M, model sedemikian sangat penting untuk dunia nyata), MIM mungkin mengurangkan kesan model ke tahap tertentu. Sebagai contoh, kesan klasifikasi ViT-L yang dilatih dengan MAE pada ImageNet adalah 3.3% lebih tinggi daripada model yang dilatih dengan penyeliaan biasa, tetapi kesan klasifikasi ViT-T yang dilatih dengan MAE pada ImageNet adalah 0.6% lebih rendah daripada kesan klasifikasi ViT-T yang dilatih dengan MAE pada ImageNet. model terlatih dengan penyeliaan biasa. Dalam kerja ini kami mencadangkan TinyMIM, yang menggunakan kaedah penyulingan untuk memindahkan pengetahuan daripada model besar kepada ViT sambil mengekalkan struktur tidak berubah dan tidak mengubah suai struktur untuk memperkenalkan model kecil induktif yang lain. 
- Alamat kertas: https://arxiv.org/pdf/2301.01296.pdf alamat
- ensu /TinyMIM
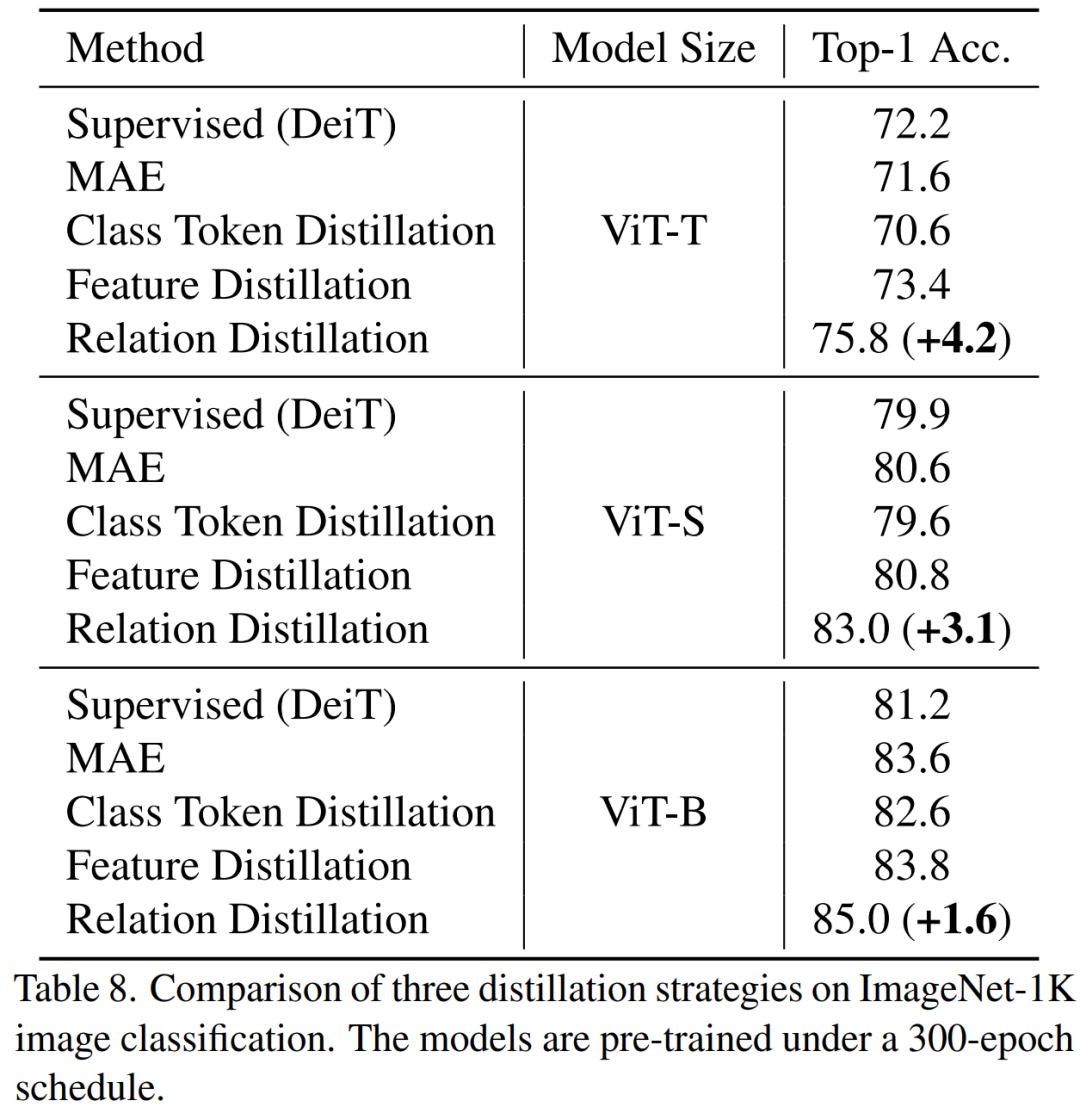
Kami secara sistematik mengkaji kesan objektif penyulingan, peningkatan data, penyelarasan, fungsi kehilangan tambahan, dll. pada penyulingan. Dalam kes hanya menggunakan ImageNet-1K secara ketat sebagai data latihan (termasuk model Guru juga hanya menggunakan latihan ImageNet-1K) dan ViT-B sebagai model, kaedah kami mencapai prestasi terbaik pada masa ini. Seperti yang ditunjukkan dalam rajah: Bandingkan kaedah kami (TinyMIM) dengan kaedah berasaskan pembinaan semula topeng MAE, dan kaedah pembelajaran diselia DeiT yang dilatih dari awal. MAE mempunyai peningkatan prestasi yang ketara apabila modelnya agak besar, tetapi apabila modelnya agak kecil, penambahbaikan adalah terhad dan mungkin menjejaskan kesan akhir model. Kaedah kami, TinyMIM, mencapai peningkatan yang ketara merentas saiz model yang berbeza.
Sumbangan kami adalah seperti berikut:
1 Sasaran penyulingan: 1) Penyulingan hubungan antara token adalah lebih berkesan daripada penyulingan token kelas atau peta ciri sahaja; lapisan sebagai sasaran penyulingan. 2. Peningkatan data dan penyelarasan model (Penyaturan data dan rangkaian): 1) Kesan penggunaan imej bertopeng adalah lebih teruk;
3. Kerugian tambahan: MIM tidak bermakna sebagai fungsi kehilangan tambahan.
4 Strategi penyulingan makro: Kami mendapati penyulingan bersiri (ViT-B -> ViT-S -> ViT-T) berfungsi dengan baik. Kaedah
Kami menyiasat matlamat penyulingan, imej input dan modul matlamat penyulingan secara sistematik. 2.1 Faktor yang mempengaruhi kesan penyulingan ciri-ciri blok perantaraan
a. Dang Apabila i=L, ia merujuk kepada ciri-ciri lapisan keluaran Transformer. Apabila i b. Ciri-ciri Perhatian (Perhatian) dan ciri lapisan suapan ke hadapan (FFN)
setiap lapisan Pemindahan dan Pembentukan
Lapisan yang berbeza akan mempunyai kesan yang berbeza. c.QKV ciri
Akan ada ciri Q, K, V yang digunakan dalam Perhatian ini langsung Suling ciri-ciri ini. 2) Hubungan
Q, K, V juga digunakan untuk mengira ciri-ciri perhatian ini, dan juga boleh digunakan untuk mengira ciri-ciri peta perhatian ini. penyulingan. 3) Input: Bertopeng atau tidak Penyulingan pengetahuan tradisional adalah dengan memasukkan terus gambar yang lengkap. Kaedah kami adalah untuk meneroka model pemodelan topeng penyulingan, jadi kami juga meneroka sama ada imej bertopeng sesuai sebagai input untuk penyulingan pengetahuan. 2.2 Perbandingan kaedah penyulingan pengetahuan 1) Penyulingan Token Kelas:
yang paling mudah, kelas seperti token
di mana merujuk kepada token kelas model pelajar, dan
merujuk kepada token kelas model guru.
2) Penyulingan ciri: Kami terus merujuk kepada penyulingan ciri [1] untuk perbandingan
Penyulingan hubungan : Kami juga mencadangkan The strategi penyulingan lalai dalam artikel ini
3. Eksperimen
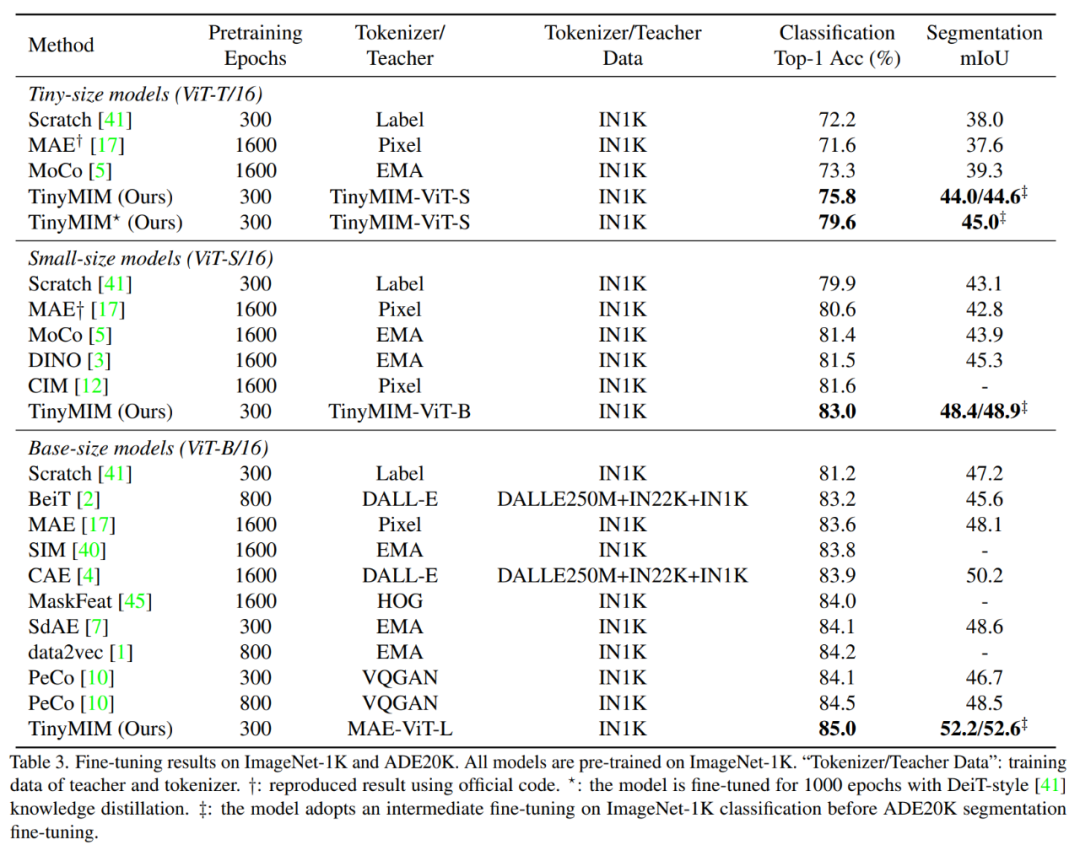
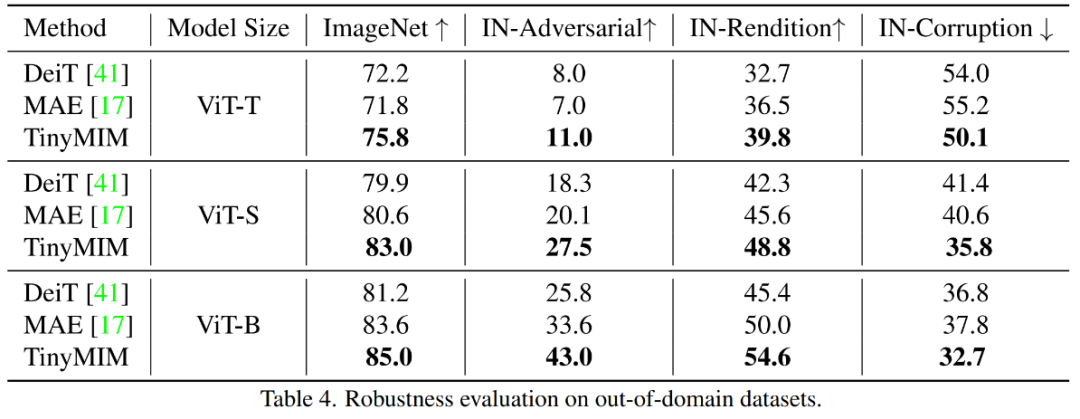
🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜🎜 hasil percubaan utama 🎜🎜 🎜Kaedah kami telah dilatih di ImageNet- 1K , dan model guru juga telah dilatih terlebih dahulu pada ImageNet-1K. Kami kemudian memperhalusi model pra-latihan kami pada tugas hiliran (pengkelasan, pembahagian semantik). Prestasi model adalah seperti yang ditunjukkan dalam rajah: 🎜🎜🎜🎜🎜🎜🎜Kaedah kami dengan ketara mengatasi kaedah berasaskan MAE sebelum ini, terutamanya untuk model kecil. Khususnya, untuk model ultra-kecil ViT-T, kaedah kami mencapai ketepatan klasifikasi 75.8%, peningkatan sebanyak 4.2 berbanding model garis dasar MAE. Untuk model kecil ViT-S, kami mencapai ketepatan klasifikasi 83.0%, peningkatan sebanyak 1.4 berbanding kaedah terbaik sebelumnya. Untuk model bersaiz asas, kaedah kami mengatasi model garis dasar MAE dan model terbaik sebelumnya masing-masing oleh CAE 4.1 dan 2.0. Pada masa yang sama, kami juga menguji kekukuhan model, seperti yang ditunjukkan dalam rajah:
dengan TinyM-Net dengan MA-Net Image -A dan ImageNet- R masing-masing meningkat sebanyak +6.4 dan +4.6.
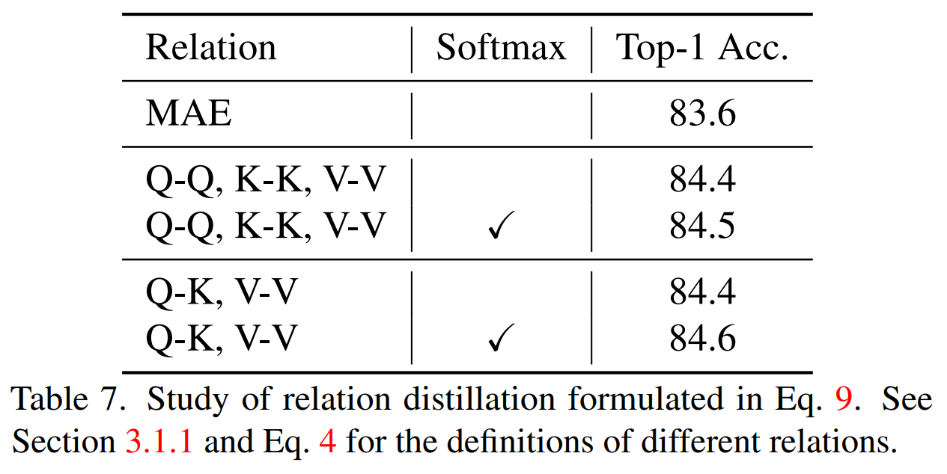
1) Menyuling perhubungan yang berbeza menyuling hubungan QK,V V dan Softmax dilaksanakan apabila mengira hubungan Terbaik keputusan.
2) Strategi penyulingan yang berbeza
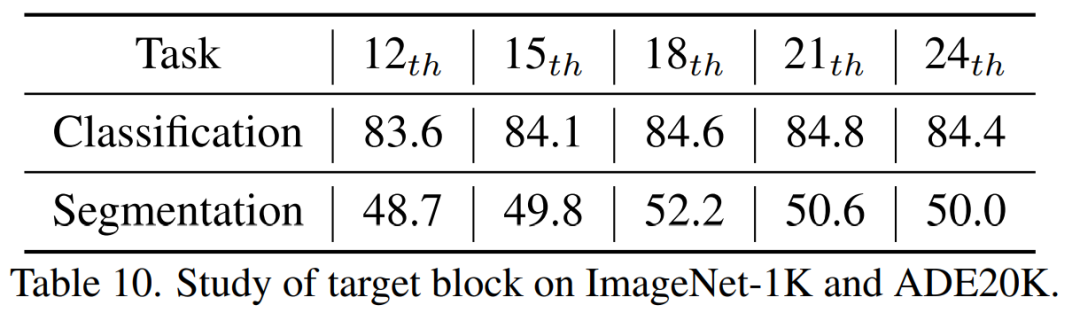
TinyMIM kaedah penyulingan bercirikan, pemetaan dan perhubungan asas yang lebih baik Kesannya ialah sama pada model semua saiz. 3) Lapisan tengah penyulingan Kami mendapati bahawa lapisan kelapan belas penyulingan mencapai hasil terbaik.
IV Kesimpulan 🎜🎜🎜🎜🎜🎜Dalam kertas kerja ini, kami mencadangkan TinyMIM, yang merupakan model pertama yang berjaya membolehkan model kecil mendapat manfaat daripada Pemodelan Semula Topeng (MIM). Daripada menggunakan pembinaan semula topeng sebagai tugas, kami melatih model kecil dengan melatih model kecil untuk mensimulasikan hubungan model besar dalam cara penyulingan pengetahuan. Kejayaan TinyMIM boleh dikaitkan dengan kajian menyeluruh tentang pelbagai faktor yang boleh mempengaruhi pra-latihan TinyMIM, termasuk sasaran penyulingan, input penyulingan dan lapisan perantaraan. Melalui eksperimen yang meluas, kami menyimpulkan bahawa penyulingan hubungan adalah lebih baik daripada penyulingan ciri dan penyulingan label kelas, dsb. Dengan kesederhanaan dan prestasi yang berkuasa, kami berharap kaedah kami akan menyediakan asas yang kukuh untuk penyelidikan masa depan. 🎜🎜🎜🎜🎜🎜[1] Wei, Y., Hu, H., Xie, Z., Zhang, Z., Cao, Y., Bao, J., ... & Guo, B. (2022) . Saingan pembelajaran kontras pemodelan imej bertopeng dalam penalaan halus melalui penyulingan ciri arXiv pracetak arXiv:2205.14141.🎜🎜.Atas ialah kandungan terperinci Microsoft Research Asia melancarkan TinyMIM: meningkatkan prestasi ViT kecil melalui penyulingan pengetahuan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



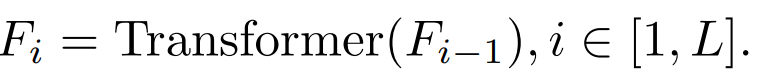
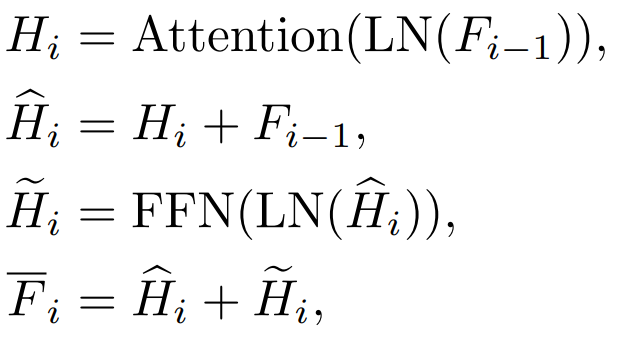
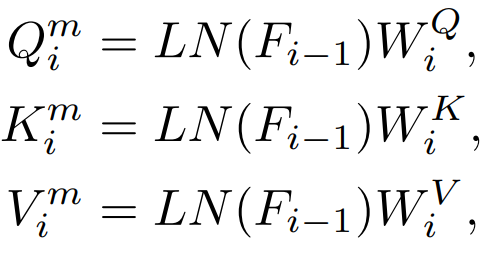 c.QKV ciri
c.QKV ciri 2) Hubungan
2) Hubungan