
Rumah >Peranti teknologi >AI >Pasukan Universiti Fudan mengeluarkan pembantu peribadi perubatan dan kesihatan China, manakala sumber terbuka 470,000 set data berkualiti tinggi
Pasukan Universiti Fudan mengeluarkan pembantu peribadi perubatan dan kesihatan China, manakala sumber terbuka 470,000 set data berkualiti tinggi

- PHPzke hadapan
- 2023-09-05 12:01:05999semak imbas
Dengan peningkatan teleperubatan, pesakit semakin cenderung untuk memilih perundingan dan perundingan dalam talian untuk mendapatkan sokongan perubatan yang mudah dan cekap. Baru-baru ini, model bahasa besar (LLM) telah menunjukkan keupayaan interaksi bahasa semula jadi yang kuat, membawa harapan untuk kesihatan dan pembantu perubatan untuk memasuki kehidupan orang ramai
Alamat halaman utama: https://med.fudan-disc.com Alamat Github: https://github.com/FudanDISC/DISC-MedLLM Laporan Teknikal- //arxiv.org/abs/2308.14346

1.
Apabila pesakit rasa tidak sihat, mereka boleh Bertanya model untuk menerangkan simptom anda, dan model akan memberikan sebab yang mungkin, pelan rawatan yang disyorkan, dsb. sebagai rujukan Apabila maklumat kurang, ia akan meminta penerangan terperinci tentang gejala. 
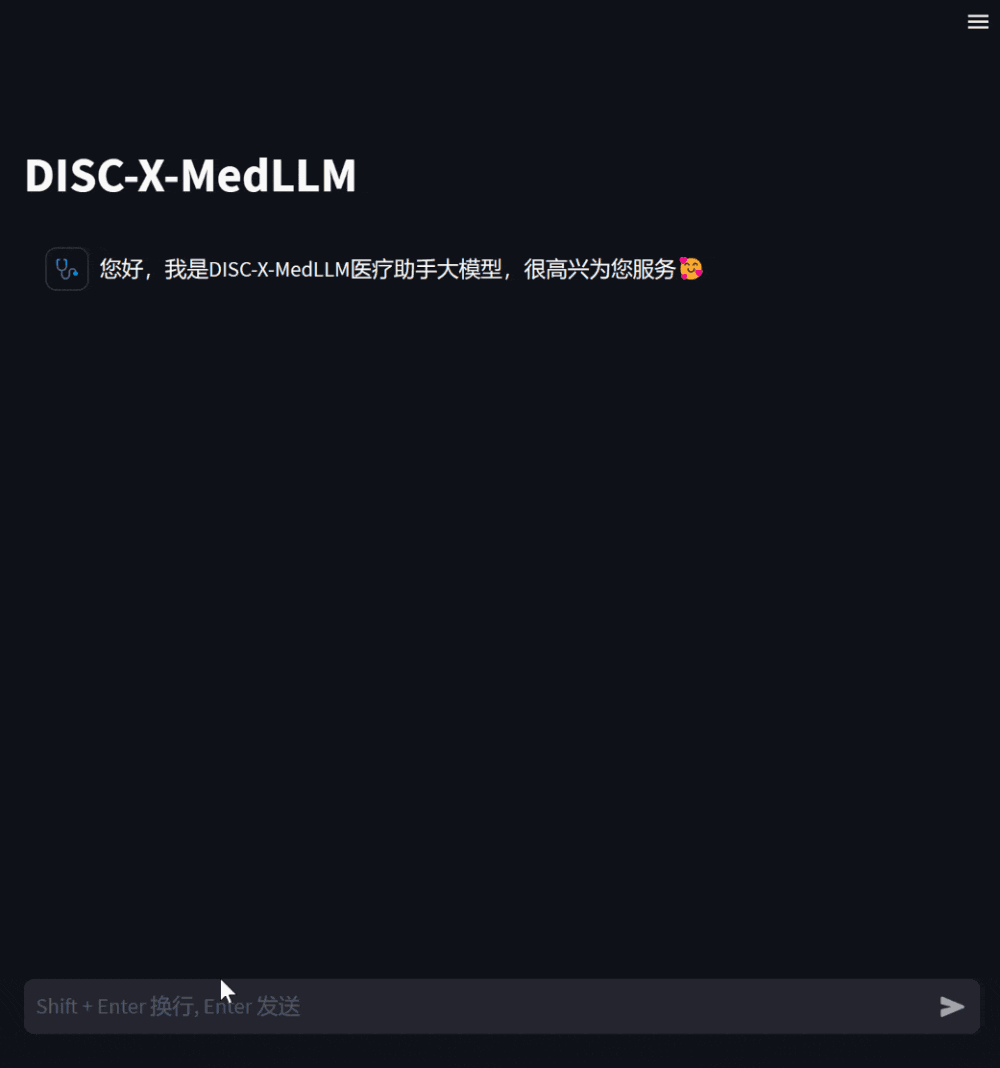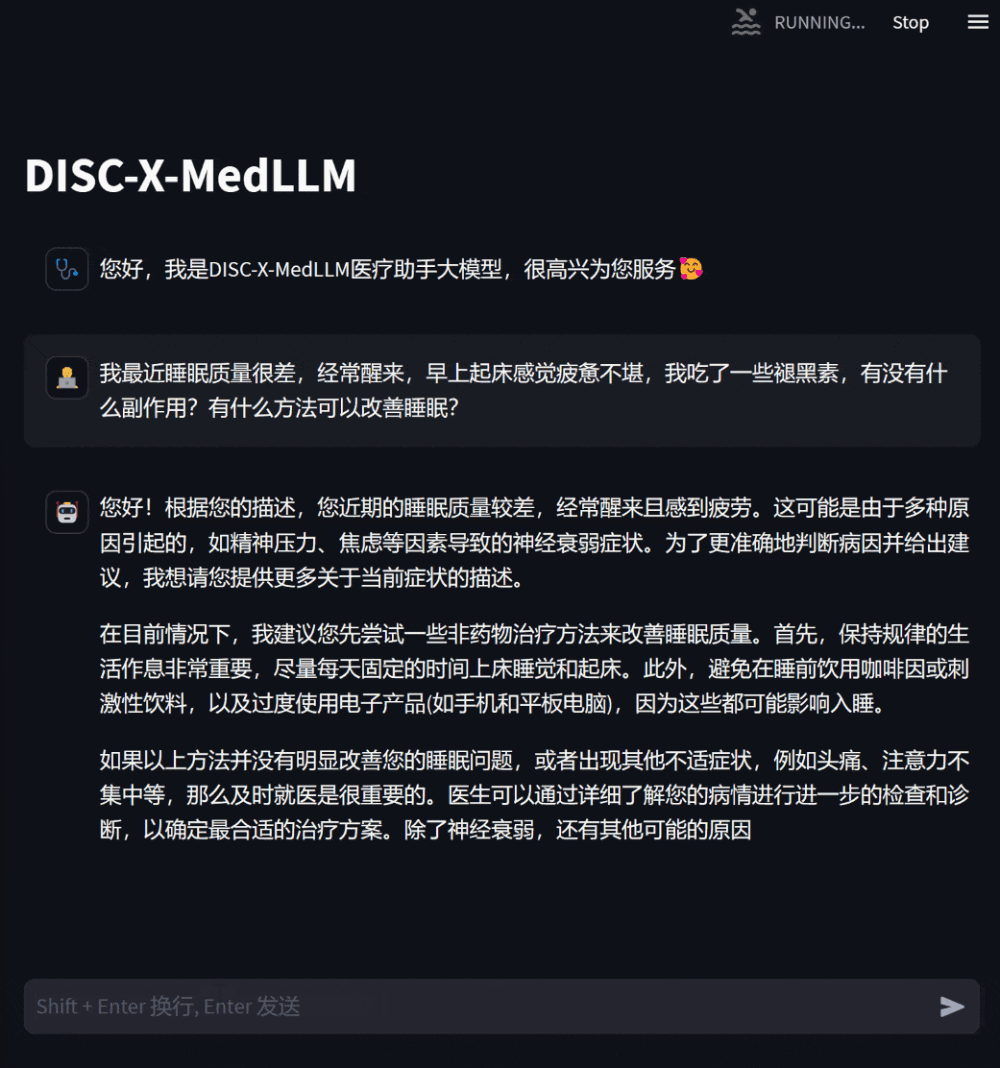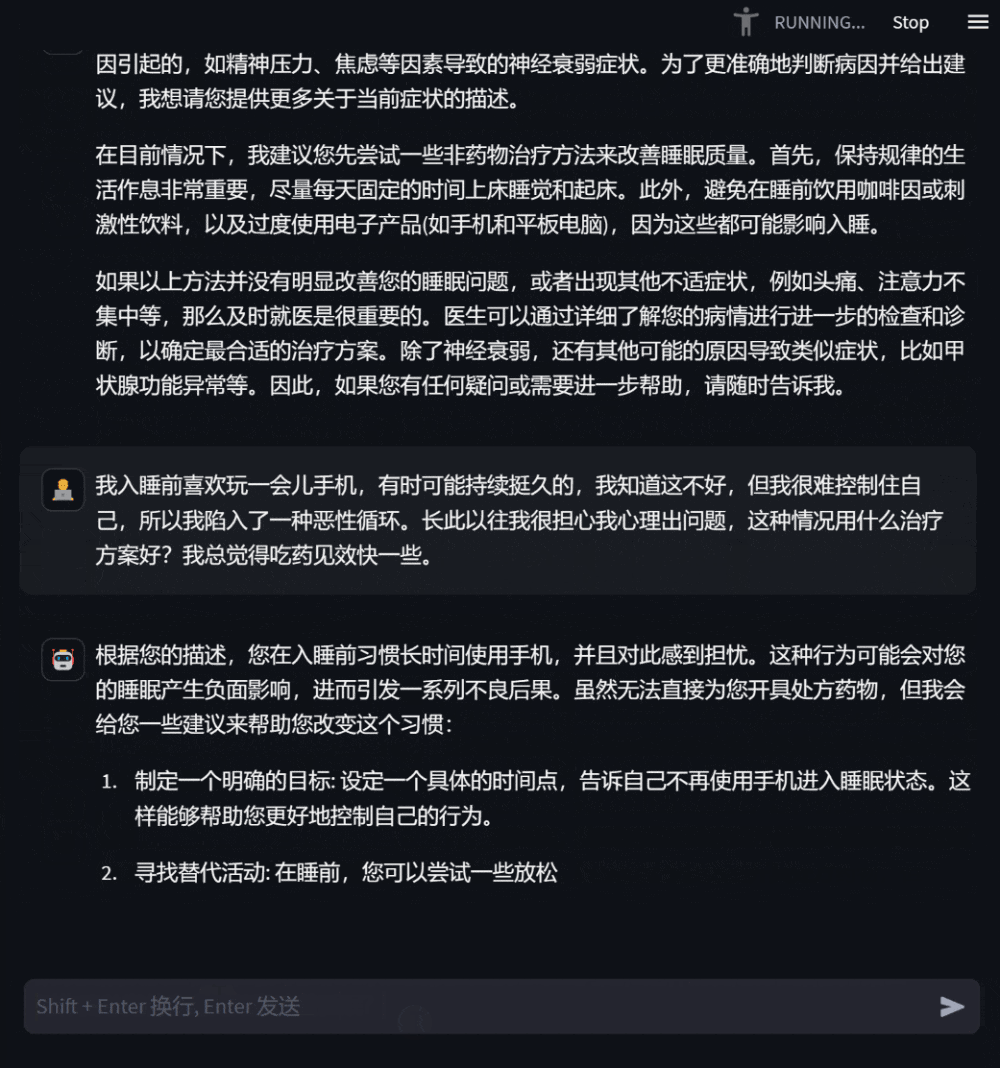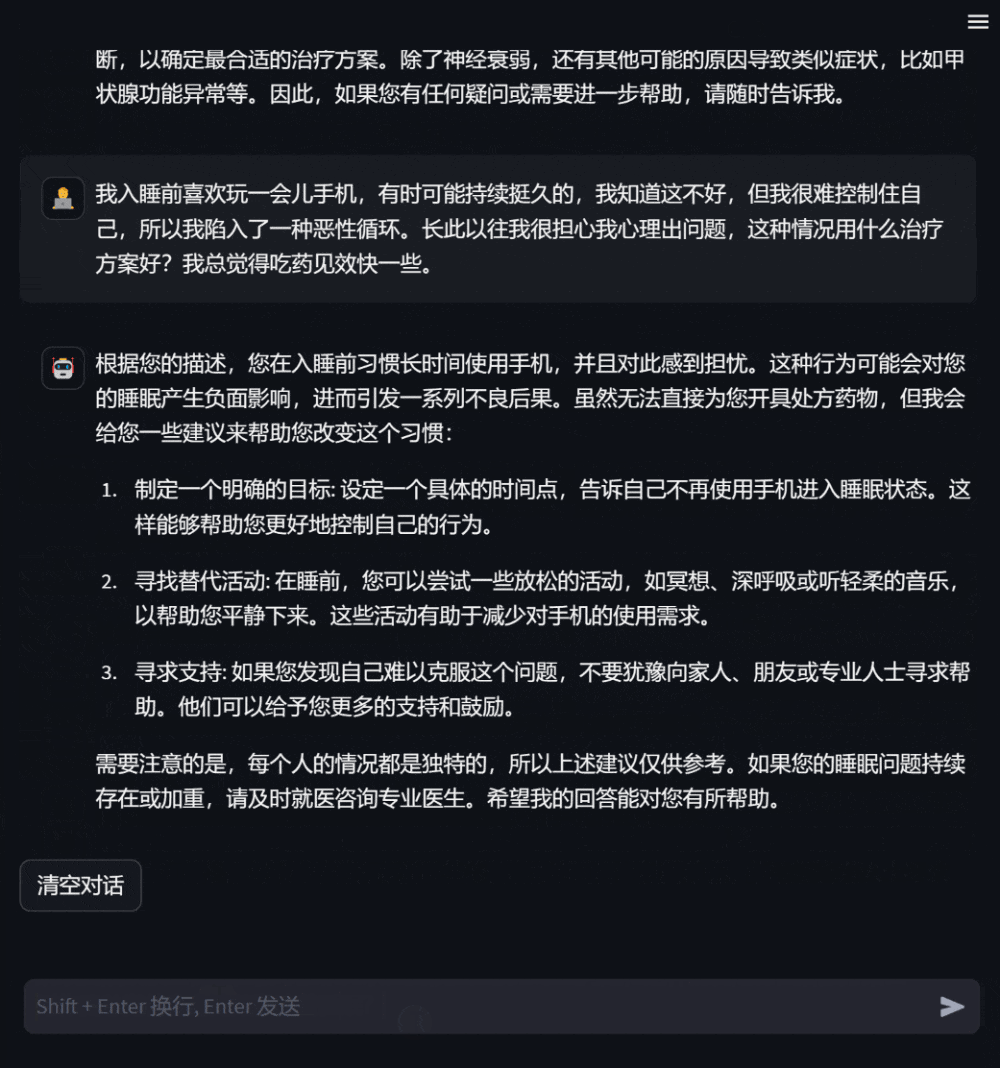
- Rajah 5: Pembinaan DISC-Med-SFT
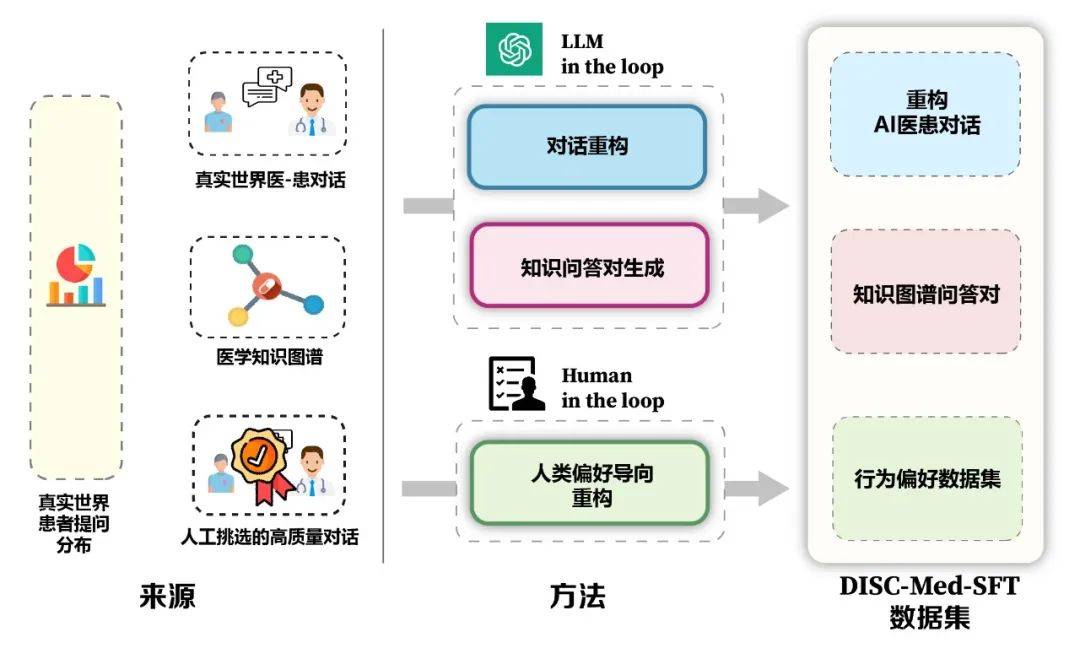 dalam proses latihan model, kami menambah DISC-Med-SFT dengan set data domain umum dan sampel data daripada korpora sedia ada, membentuk DISC-Med-SFT-ext.
dalam proses latihan model, kami menambah DISC-Med-SFT dengan set data domain umum dan sampel data daripada korpora sedia ada, membentuk DISC-Med-SFT-ext.
Berpegang pada maklumat penting dalam jawapan doktor asal dan berikan penjelasan yang sesuai agar lebih komprehensif dan logik.
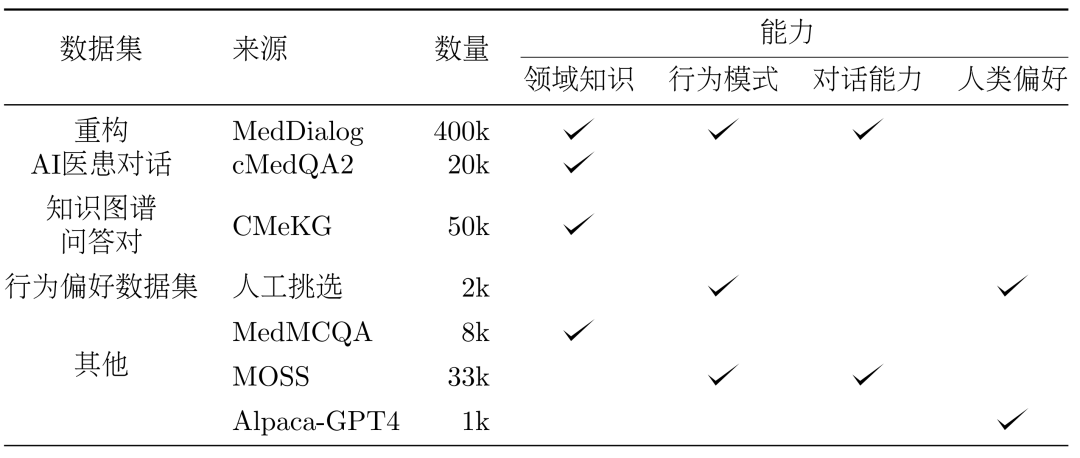
Rajah 6: Contoh penulisan semula dialog dijana sampel latihan QA. Berdasarkan CMeKG, kami membuat sampel dalam graf pengetahuan mengikut maklumat jabatan nod penyakit, dan menggunakan model GPT-3.5 Prompts yang direka bentuk sesuai untuk menjana sejumlah lebih daripada 50,000 sampel dialog adegan perubatan yang pelbagai.
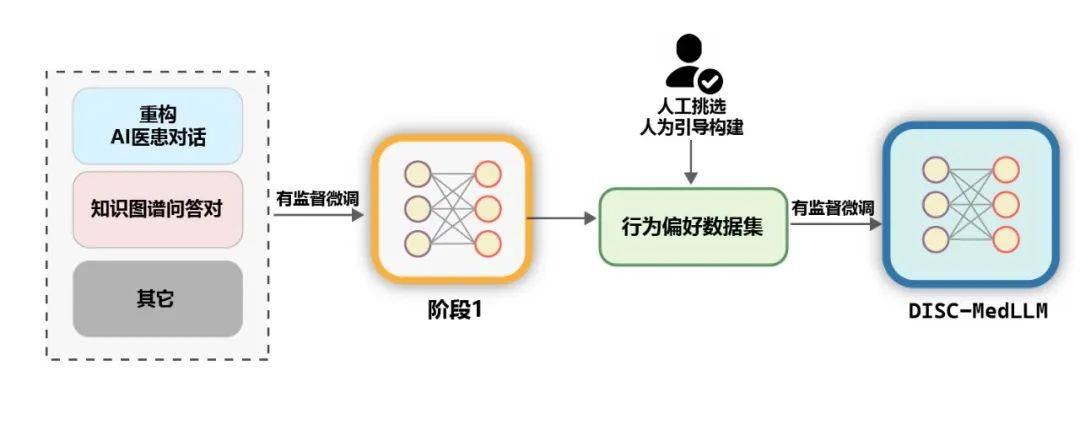
Set Data Keutamaan Tingkah LakuDi peringkat akhir latihan, untuk meningkatkan lagi prestasi model, kami menggunakan set data yang lebih selaras dengan keutamaan tingkah laku manusia untuk penyeliaan menengah penalaan halus. Kira-kira 2000 sampel berkualiti tinggi dan pelbagai telah dipilih secara manual daripada dua set data MedDialog dan cMedQA2 Selepas menulis semula beberapa contoh dan menyemaknya secara manual kepada GPT-4, kami menggunakan kaedah sampel kecil untuk memberikannya kepada GPT-3.5, menjana tinggi. -set data keutamaan tingkah laku berkualiti. Lain-lainData am. Untuk memperkayakan kepelbagaian set latihan dan mengurangkan risiko kemerosotan model dalam keupayaan asas semasa peringkat latihan SFT, kami memilih secara rawak beberapa sampel daripada dua set data penalaan halus yang diselia, moss-sft-003 dan data gpt4 alpaca. zh. MedMCQA. Untuk meningkatkan keupayaan Soal Jawab model, kami memilih MedMCQA, set data soalan aneka pilihan dalam bidang perubatan Inggeris dan menggunakan GPT-3.5 untuk mengoptimumkan soalan dan jawapan yang betul dalam soalan aneka pilihan, menjana kira-kira 8,000 orang Cina profesional. sampel Soal Jawab perubatan. 4. Eksperimen latihan. Seperti yang ditunjukkan dalam rajah di bawah, proses latihan DISC-MedLLM dibahagikan kepada dua peringkat SFT.
Penilaian. Prestasi LLM perubatan dinilai dalam dua senario, iaitu QA pusingan tunggal dan dialog berbilang pusingan.Penilaian QA pusingan tunggal: Untuk menilai ketepatan model dari segi pengetahuan perubatan, kami mengambil sampel 1500 sampel daripada Peperiksaan Kelayakan Perubatan Kebangsaan China (NMLEC) dan Peperiksaan Kemasukan Lepasan Siswazah Kebangsaan (NEEP). ) Perubatan Barat 306 soalan utama + aneka pilihan untuk menilai prestasi model dalam satu pusingan QA.
Penilaian dialog pelbagai pusingan: Untuk menilai secara sistematik keupayaan dialog model, kami menggunakan tiga set data awam - Penanda Aras Perubatan Cina (CMB-Clin), Set Data Dialog Perubatan Cina (CMD) dan Data Hasrat Perubatan Cina Pilih sampel secara rawak daripada set (CMID) dan biarkan GPT-3.5 memainkan peranan pesakit dan berdialog dengan model Empat penunjuk penilaian dicadangkan - inisiatif, ketepatan, kegunaan dan kualiti bahasa, yang dijaringkan oleh GPT-4. Semak keputusan Bandingkan model. Model kami dibandingkan dengan tiga LLM am dan dua LLM perbualan perubatan Cina. Termasuk GPT-3.5, GPT-4, Baichuan-13B-Chat OpenAI, BianQue-2 dan HuatuoGPT-13B;
Keputusan QA pusingan tunggal. Keputusan keseluruhan penilaian aneka pilihan ditunjukkan dalam Jadual 2. GPT-3.5 menunjukkan petunjuk yang jelas. DISC-MedLLM mencapai tempat kedua dalam tetapan sampel kecil dan menduduki tempat ketiga di belakang Baichuan-13B-Chat dalam tetapan sampel sifar. Terutama, kami mengatasi prestasi HuatuoGPT (13B) yang dilatih dengan tetapan pembelajaran pengukuhan.Jadual 2: Keputusan penilaian aneka pilihan
Hasil beberapa pusingan dialog. Dalam penilaian CMB-Clin, DISC-MedLLM mencapai skor keseluruhan tertinggi, diikuti rapat oleh HuatuoGPT. Model kami mendapat markah tertinggi dalam kriteria positif, menonjolkan keberkesanan pendekatan latihan kami yang berat sebelah corak tingkah laku perubatan. Keputusan ditunjukkan dalam Jadual 3.Jadual 3: Keputusan CMB-clin Dalam sampel CMD, seperti yang ditunjukkan dalam Rajah 8, GPT-4 memperoleh markah tertinggi, diikuti oleh GPT-3.5. Model dalam bidang perubatan, DISC-MedLLM dan HuatuoGPT, mempunyai skor prestasi keseluruhan yang sama, dan prestasi mereka dalam jabatan yang berbeza adalah cemerlang. 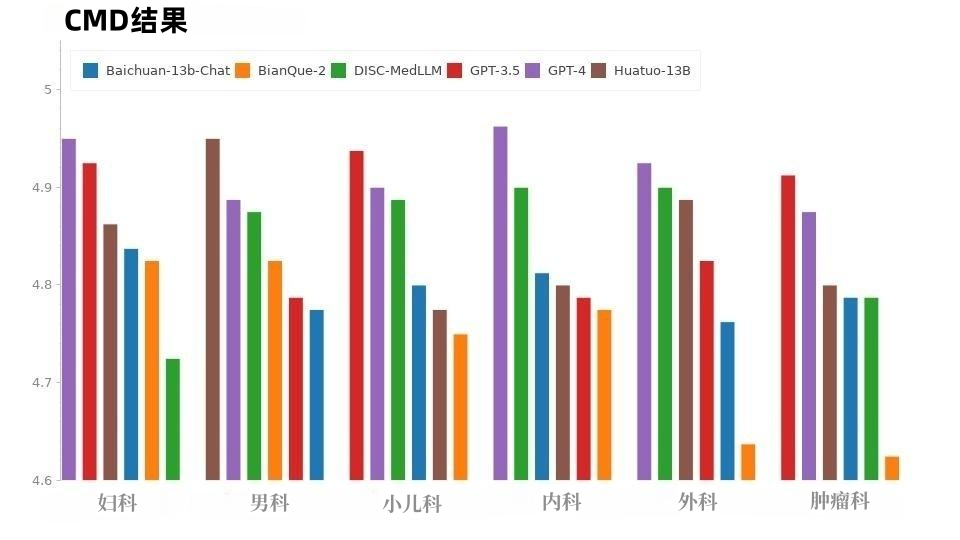
Rajah 8: Keputusan CMD Situasi CMID adalah serupa dengan CMD, seperti yang ditunjukkan dalam Rajah 9, GPT-3.5 dan GPT Kecuali untuk siri GPT, DISC-MedLLM menunjukkan prestasi terbaik. Ia mengatasi HuatuoGPT dalam tiga niat: keadaan, rejimen rawatan dan ubat. 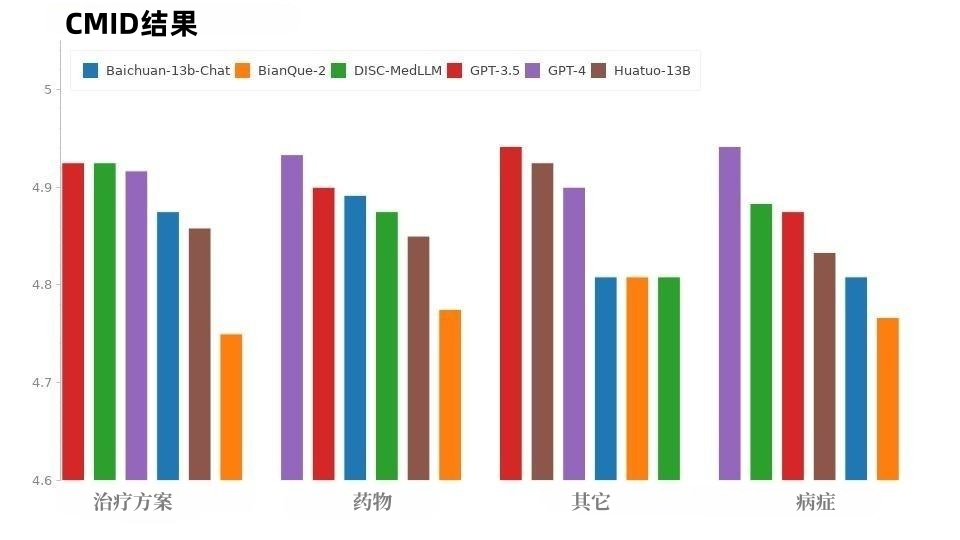
Rajah 9: Keputusan CMID Prestasi setiap model yang tidak konsisten antara CMB-Clin dan CMD/CMID mungkin disebabkan oleh tiga set data yang berbeza ini. CMD dan CMID mengandungi sampel soalan yang lebih eksplisit, dan pesakit mungkin sudah mempunyai diagnosis dan menyatakan keperluan yang jelas apabila menerangkan simptom, dan soalan dan keperluan pesakit mungkin tidak ada kaitan dengan status kesihatan peribadi mereka. Model tujuan umum GPT-3.5 dan GPT-4, yang cemerlang dalam banyak aspek, adalah lebih baik dalam mengendalikan situasi ini. 5 Ringkasan Data data DISC-Med-SFT mengambil kesempatan daripada kelebihan dan keupayaan dialog dunia sebenar dan aspek LLM umum, dan menjalankan tiga peningkatan domain, dalam tiga peningkatan domain. dialog perubatan Kemahiran dan keutamaan manusia; set data berkualiti tinggi melatih model besar perubatan DISC-MedLLM, yang mencapai peningkatan ketara dalam interaksi perubatan, menunjukkan kebolehgunaan yang tinggi, dan menunjukkan potensi aplikasi yang hebat. Penyelidikan dalam bidang ini akan membawa lebih banyak prospek dan kemungkinan untuk mengurangkan kos perubatan dalam talian, mempromosikan sumber perubatan, dan mencapai keseimbangan. DISC-MedLLM akan membawa perkhidmatan perubatan yang mudah dan diperibadikan kepada lebih ramai orang dan menyumbang kepada punca kesihatan umum.
Atas ialah kandungan terperinci Pasukan Universiti Fudan mengeluarkan pembantu peribadi perubatan dan kesihatan China, manakala sumber terbuka 470,000 set data berkualiti tinggi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!