Selepas mengumpul data, ia perlu ditafsir dan dianalisis untuk mendapatkan pemahaman yang lebih mendalam tentang maksud yang terkandung dalam data. Dan makna ini boleh mengenai corak, aliran, atau hubungan antara pembolehubah.
Tafsiran data ialah proses menyemak data melalui kaedah yang ditakrifkan dengan jelas Tafsiran data membantu memberi makna kepada data dan membuat kesimpulan yang relevan.
Analisis data ialah proses menyusun, mengelas dan meringkaskan data untuk menjawab soalan kajian. Kita harus menyelesaikan analisis data dengan cepat dan cekap dan membuat kesimpulan yang menonjol.
Jenis lukisan data visual yang berbeza adalah aspek penting untuk mencapai matlamat di atas. Apabila data terus berkembang, keperluan ini terus berkembang, jadi gambar rajah visualisasi data adalah sangat penting. Walau bagaimanapun, terdapat banyak jenis gambar rajah visualisasi data, dan dalam kerja sebenar, selalunya sukar untuk memilih jenis yang paling sesuai untuk perniagaan atau data semasa.
Pembuat keputusan berbantukan visual
Penyelidikan menunjukkan bahawa mata manusia ialah GPU selari lebar jalur tinggi dengan sejumlah besar isyarat visual, dengan lebar jalur 2.339G/s, yang bersamaan dengan Kad rangkaian 20 Gigabit, dengan keupayaan Pengecaman mod yang sangat berkuasa, dan kelajuan pemprosesan simbol visual adalah banyak urutan magnitud lebih pantas daripada nombor atau teks Dalam era data besar, visualisasi data ialah alat yang berkuasa untuk orang ramai untuk mendapatkan pandangan tentang konotasi data dan memahami nilai yang terkandung dalam data.
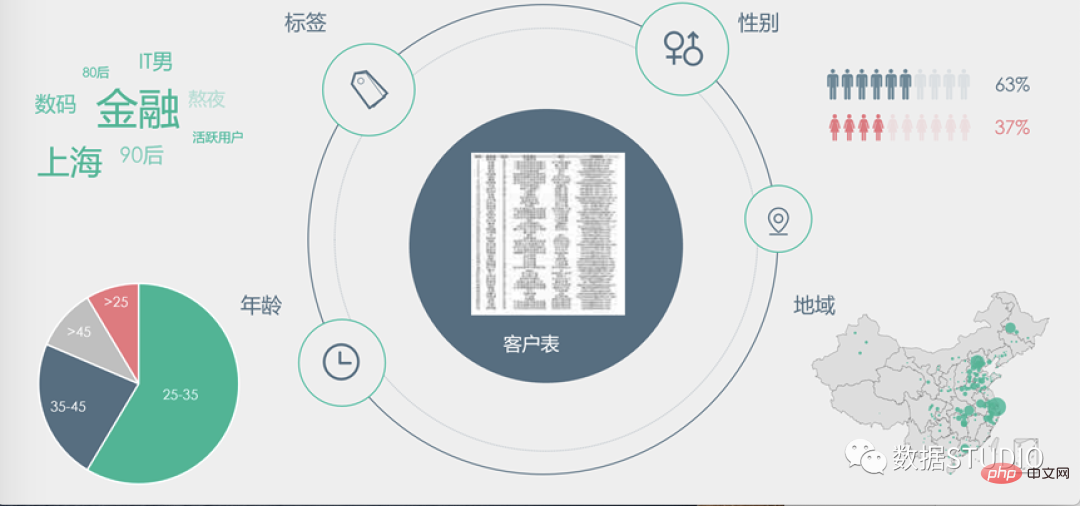
Oleh itu, visualisasi sering digunakan untuk membantu membuat keputusan Seperti yang ditunjukkan dalam gambar di atas, terdapat jadual pelanggan yang padat di tengah-tengah Apakah maklumat berharga yang boleh diperolehi untuk membimbing membuat keputusan? Hanya melihat pada baris dan lajur data mungkin mengambil masa yang lama untuk membuat beberapa kesimpulan, tetapi selepas visualisasi, kita boleh dengan mudah memahami kesimpulan dengan cepat melalui pelbagai bentuk visualisasi untuk membantu membuat keputusan.
Ini ialah: Analisis visual, iaitu untuk memperhalusi maklumat kepada pengetahuan dan memainkan peranan "melihat perkara yang perlu diketahui", membolehkan pembuat keputusan dengan cepat melombong maklumat berkesan daripada kompleks, jumlah besar dan pelbagai dimensi data.
Artikel ini meringkaskan dan memperkenalkan pelbagai rajah visualisasi dan senario penggunaannya yang sesuai, dan juga menunjukkan kod untuk melukis rajah ini menggunakan pakej lukisan yang biasa digunakan (plotly, seaborn dan matplotlib).
Carta Bar
Carta bar ialah graf yang memaparkan data kategori menggunakan bar segi empat tepat. Ketinggian atau panjang bar ini adalah berkadar dengan nilai yang diwakilinya. Bar boleh menegak atau mendatar. Carta bar menegak kadangkala dipanggil carta lajur.
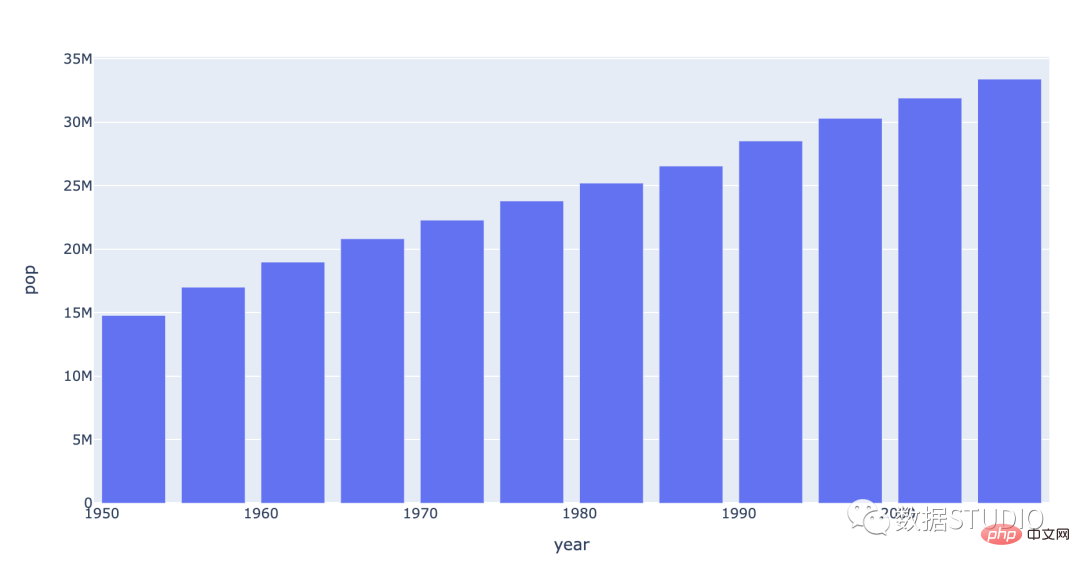
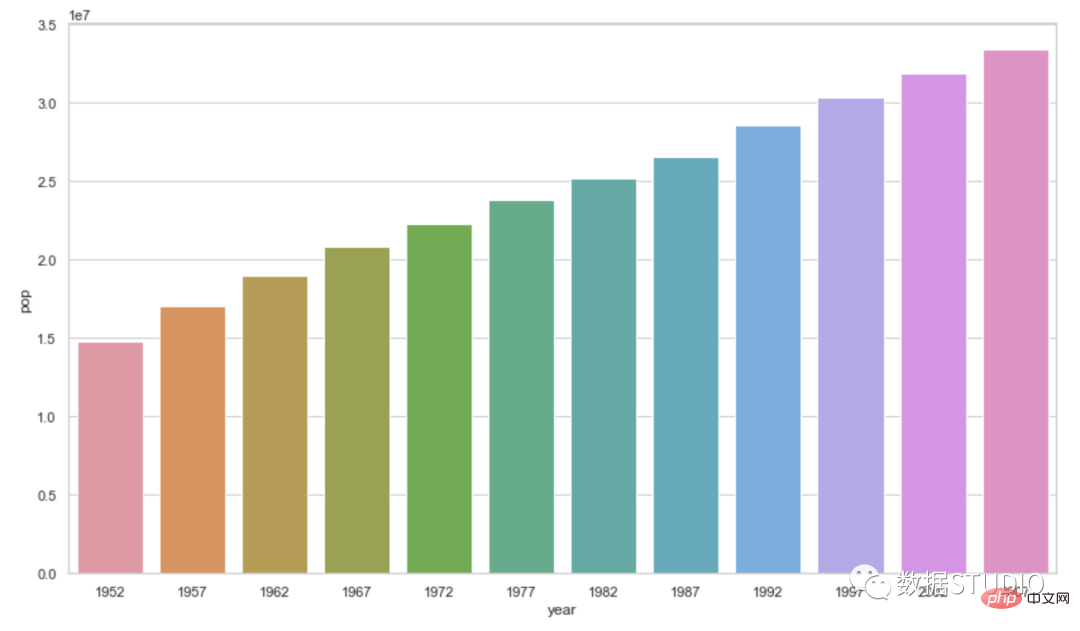
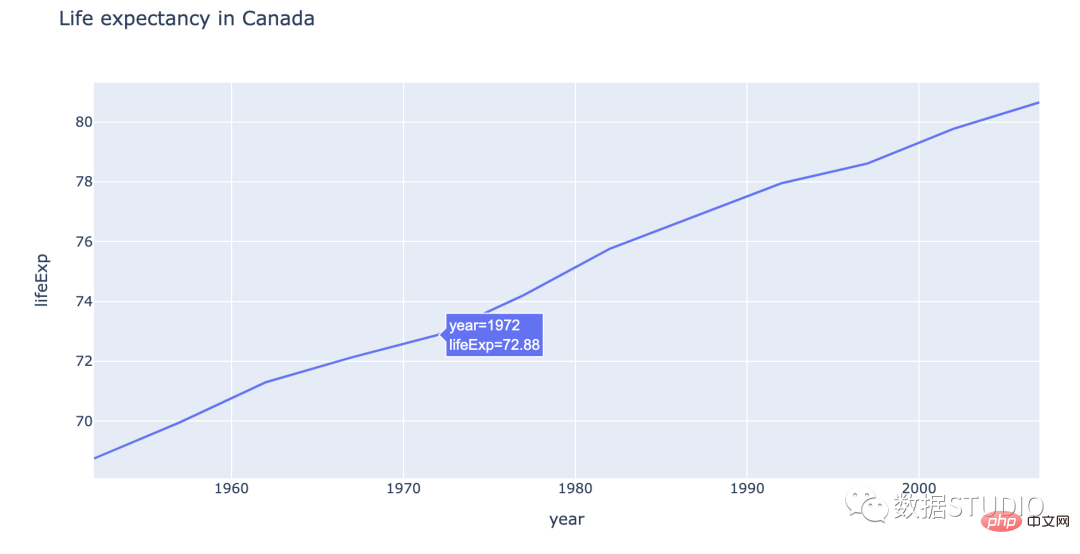
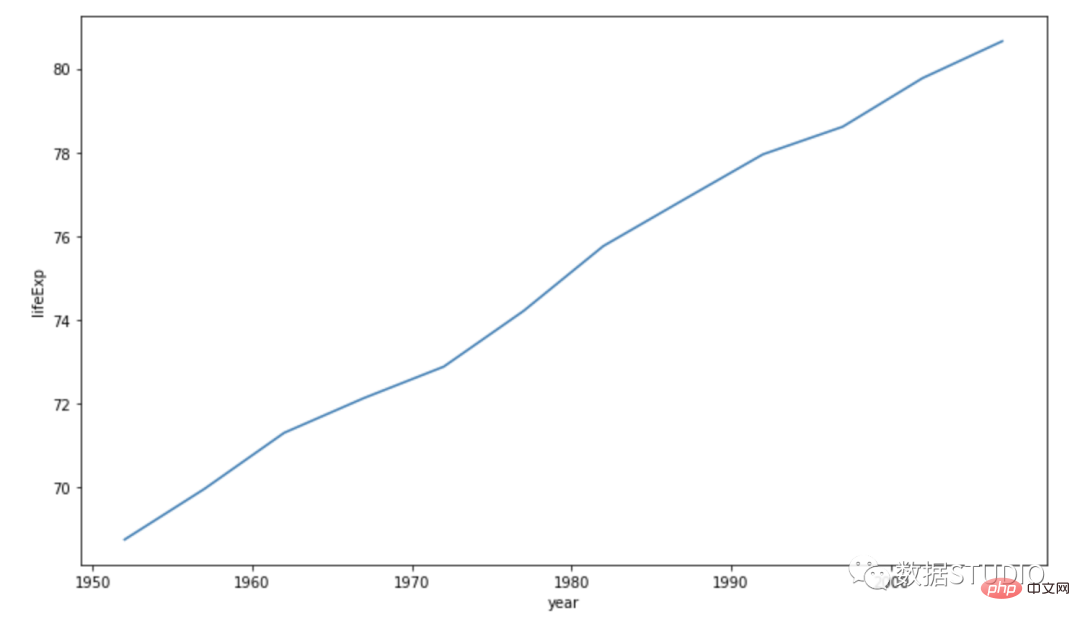
Di bawah ialah carta palang yang menunjukkan populasi Kanada mengikut tahun.
Carta bar sesuai untuk perbandingan data kategori Apabila diletakkan secara mendatar, ia juga dipanggil carta bar. Nota: Bilangan item data carta bar hendaklah tidak melebihi 12 bilangan item data carta bar tidak boleh melebihi 30.
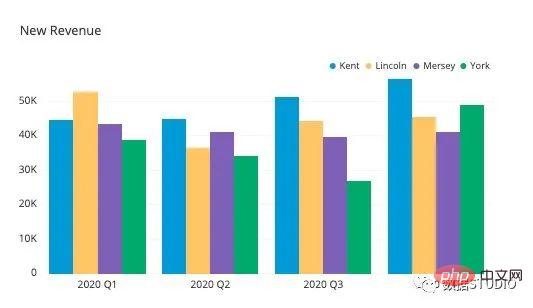
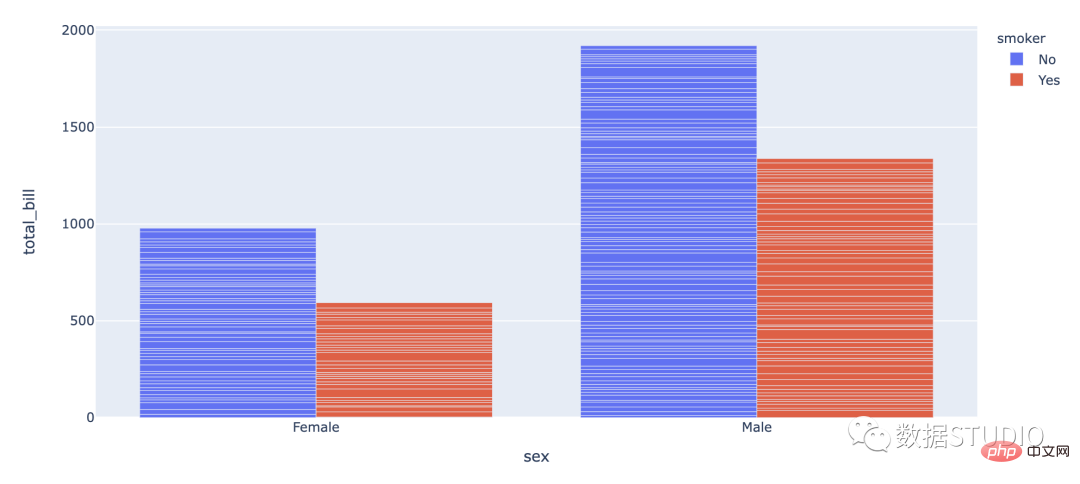
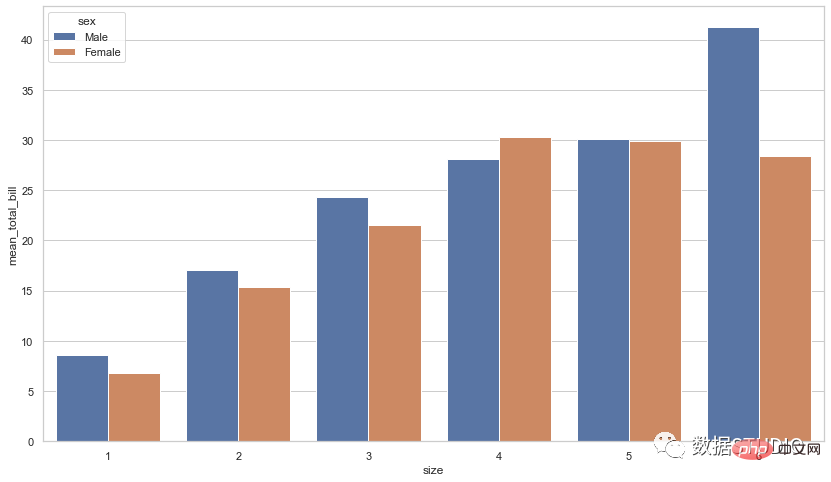
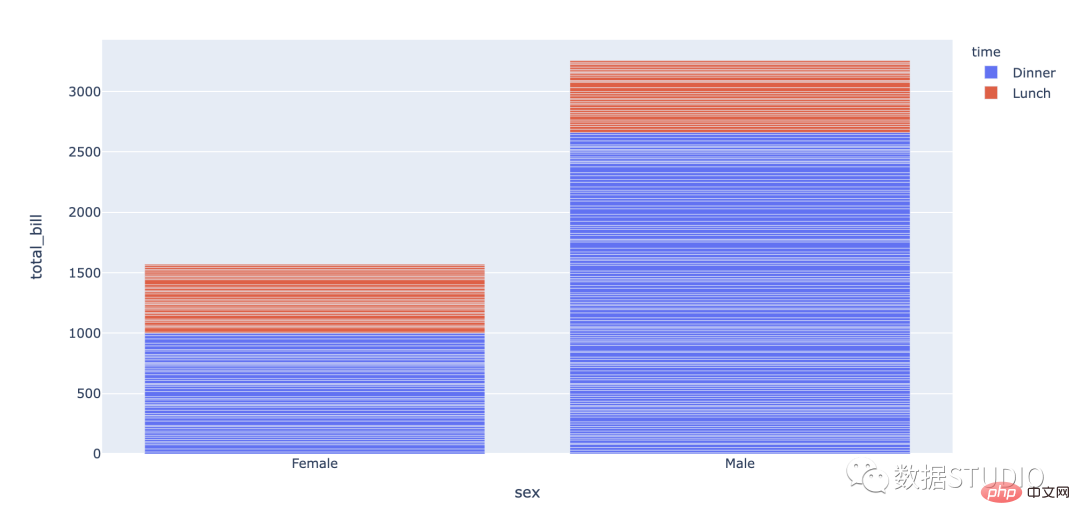
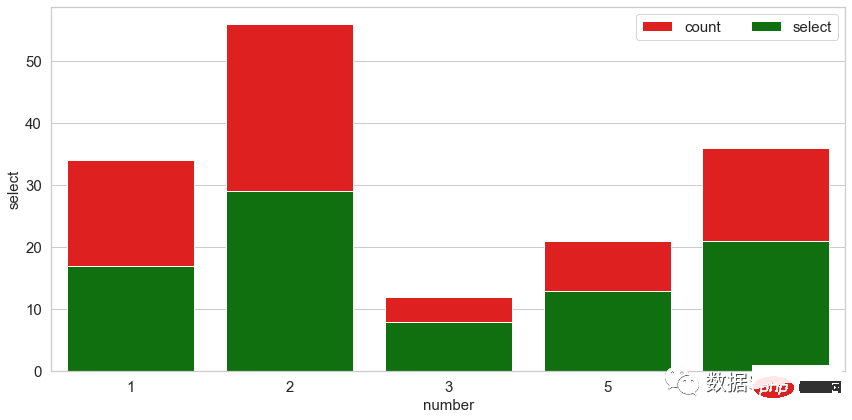
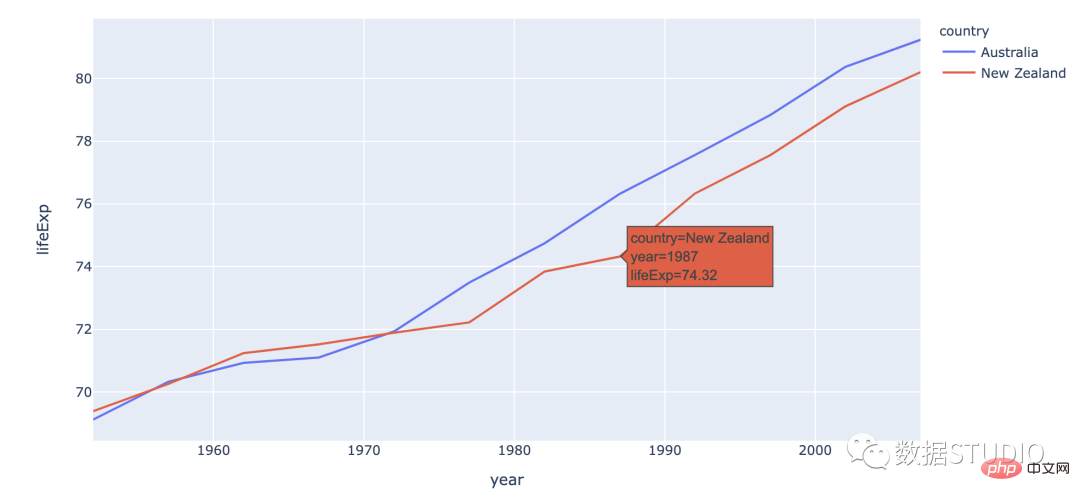
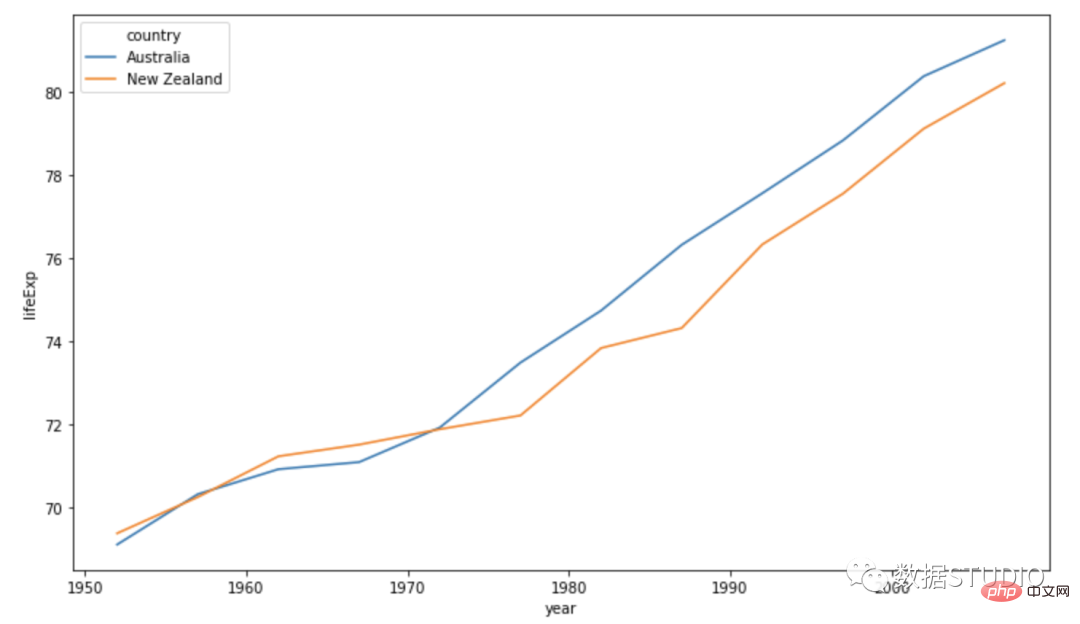
Carta bar berkumpulan digunakan apabila set data mempunyai subkumpulan yang perlu divisualisasikan secara grafik. Subkumpulan dibezakan oleh warna yang berbeza. Berikut ialah penerangan carta sedemikian:
import plotly.express as px
df = px.data.iris() # iris is a pandas DataFrame
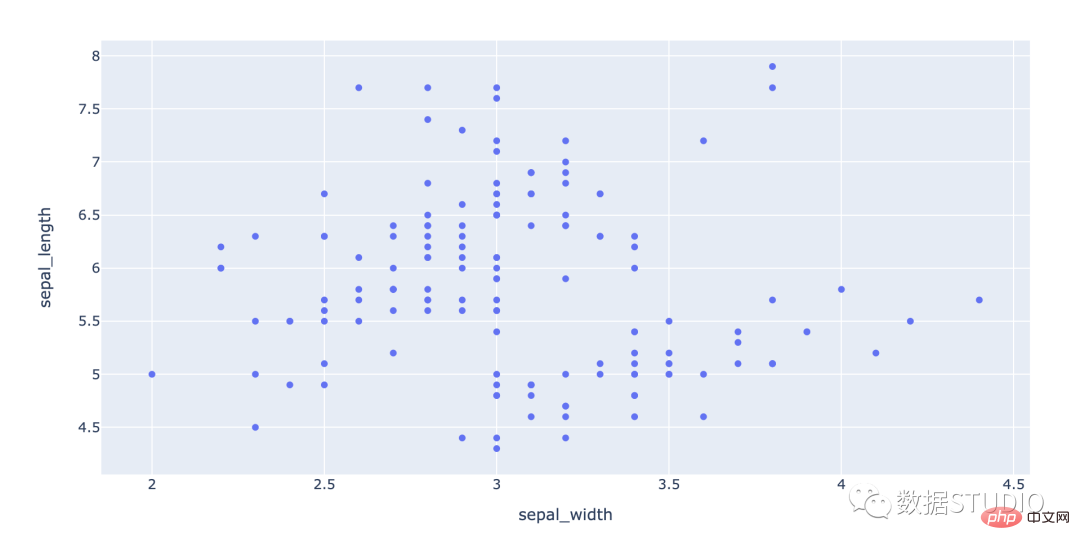
fig = px.scatter(df, x="sepal_width", y="sepal_length")
fig.show()
Seaborn code
import seaborn as sns
tips = sns.load_dataset("tips")
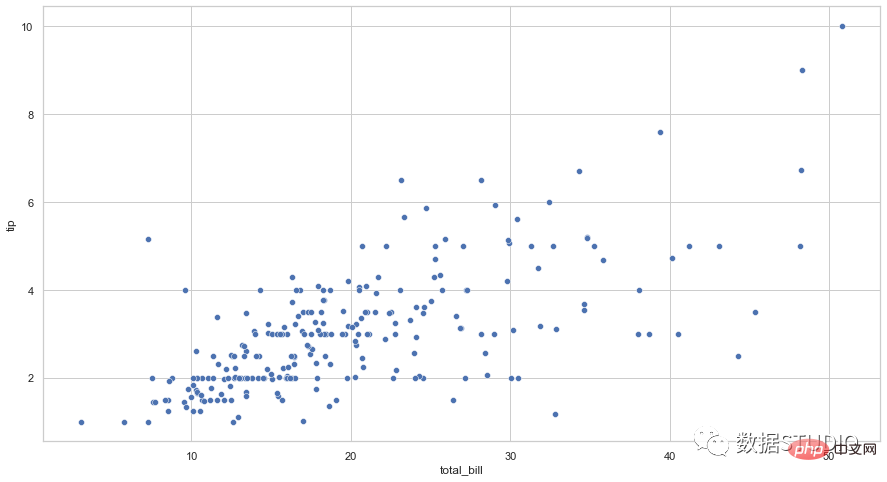
sns.scatterplot(data=tips, x="total_bill", y="tip")
根据数据点的相关性,散点图分为不同的类型。下面列出了这些关联类型
Korelasi Positif
Dalam jenis graf ini, peningkatan dalam pembolehubah bebas menunjukkan peningkatan dalam pembolehubah yang bergantung padanya. Scatterplots boleh mempunyai korelasi positif yang tinggi atau korelasi positif yang rendah.
Korelasi Negatif
Dalam plot jenis ini, peningkatan dalam pembolehubah bebas menunjukkan penurunan dalam pembolehubah yang bergantung padanya. Plot taburan boleh mempunyai korelasi negatif yang tinggi atau rendah.
Tiada Korelasi
Jika tiada korelasi yang jelas antara dua set data yang ditunjukkan pada plot berselerak, ia dianggap tidak berkorelasi.
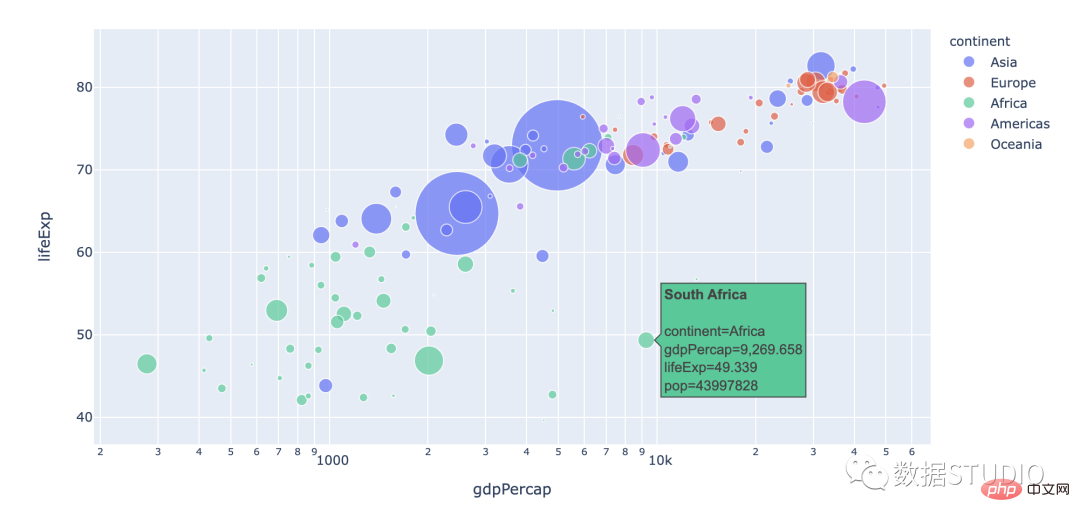
Carta Buih
Carta Buih menunjukkan tiga atribut data. Mereka diwakili oleh kedudukan x, kedudukan y dan saiz gelembung. Carta gelembung ialah carta berbilang variasi yang merupakan variasi carta serakan dan juga boleh dianggap sebagai gabungan carta serakan dan carta kawasan peratusan.
Berkenaan: Sesuai untuk perbandingan data klasifikasi dan analisis korelasi.
Nota: Saiz data dan kapasiti carta gelembung adalah terhad. Tetapi ia boleh diberi pampasan dengan menambahkan beberapa gelagat interaktif: menyembunyikan beberapa maklumat dan memaparkannya apabila tetikus diklik atau dilegar, atau menambah pilihan untuk menyusun semula atau menapis kategori kumpulan. Selain itu, saiz gelembung dipetakan ke kawasan dan bukannya jejari atau diameter. Kerana jika ia berdasarkan jejari atau diameter, saiz bulatan bukan sahaja akan berubah secara eksponen, tetapi juga menyebabkan ralat visual.
import matplotlib.pyplot as plt
import seaborn as sns
from gapminder import gapminder # import data set
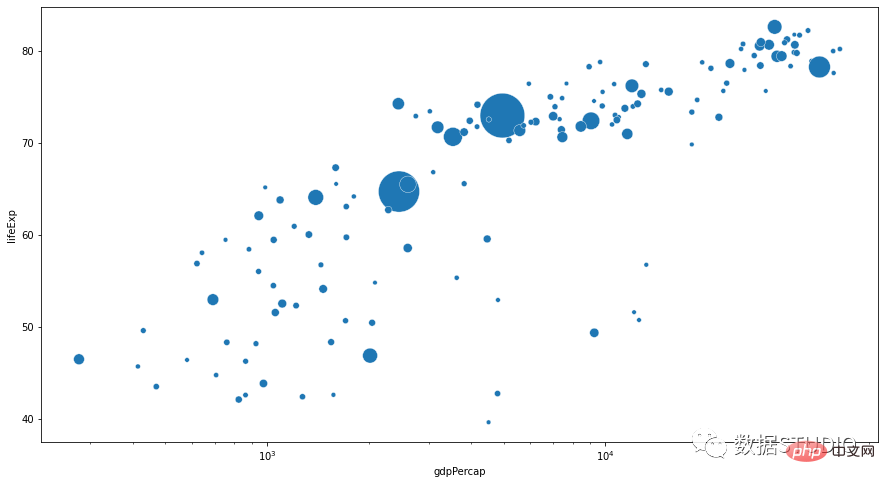
data = gapminder.loc[gapminder.year == 2007]
b = sns.scatterplot(data=data, x="gdpPercap",
y="lifeExp", size="pop",
legend=False, sizes=(20, 2000))
b.set(xscale="log")
plt.show()
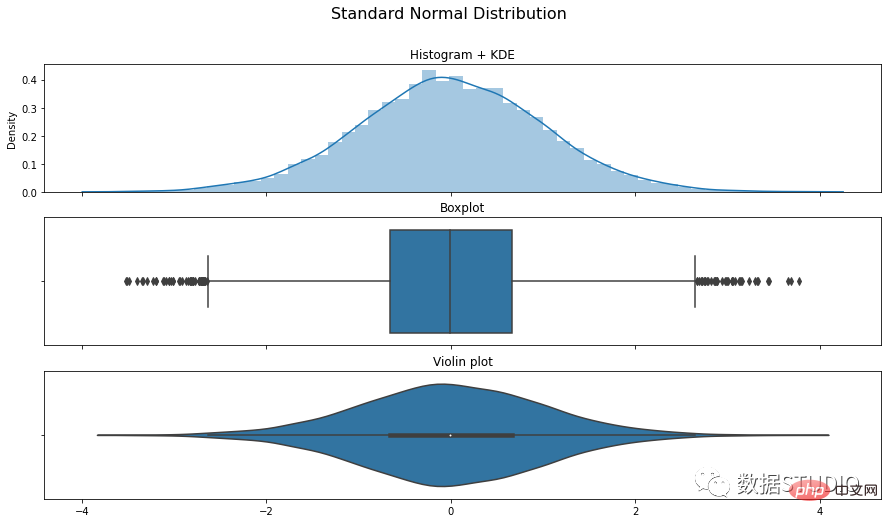
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
N = 10**4
x = np.random.normal(size=N)
fig, ax = plt.subplots(3, 1,figsize=(15,8), sharex=True)
sns.distplot(x, ax=ax[0])
ax[0].set_title('Histogram + KDE')
sns.boxplot(x, ax=ax[1])
ax[1].set_title('Boxplot')
sns.violinplot(x, ax=ax[2])
ax[2].set_title('Violin plot')
fig.suptitle('Standard Normal Distribution', fontsize=16)
plt.show()
总结
这是用于生成这些图的 plotly 和 seaborn 中方法和属性的备忘单。
Jenis plot
plot
seaborn
Graf bar ringkas
express bar
barplot
barplot
atribut warna dan barmode='kumpulan'
atribut rona GRAPH BAR Graph
Color Attribute
label dan Atribut Warna dengan Pelbagai Plot Grafik GRAPH
Express Line
LinePlot
multiple Line Graph
Color and Simbol Atributes
hue atribut
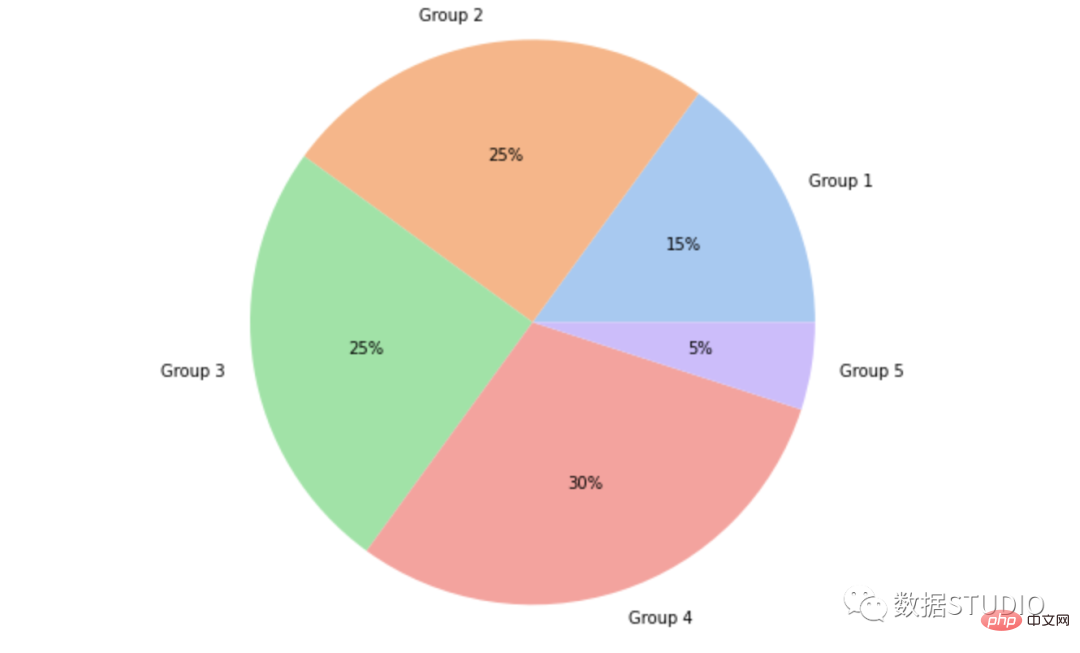
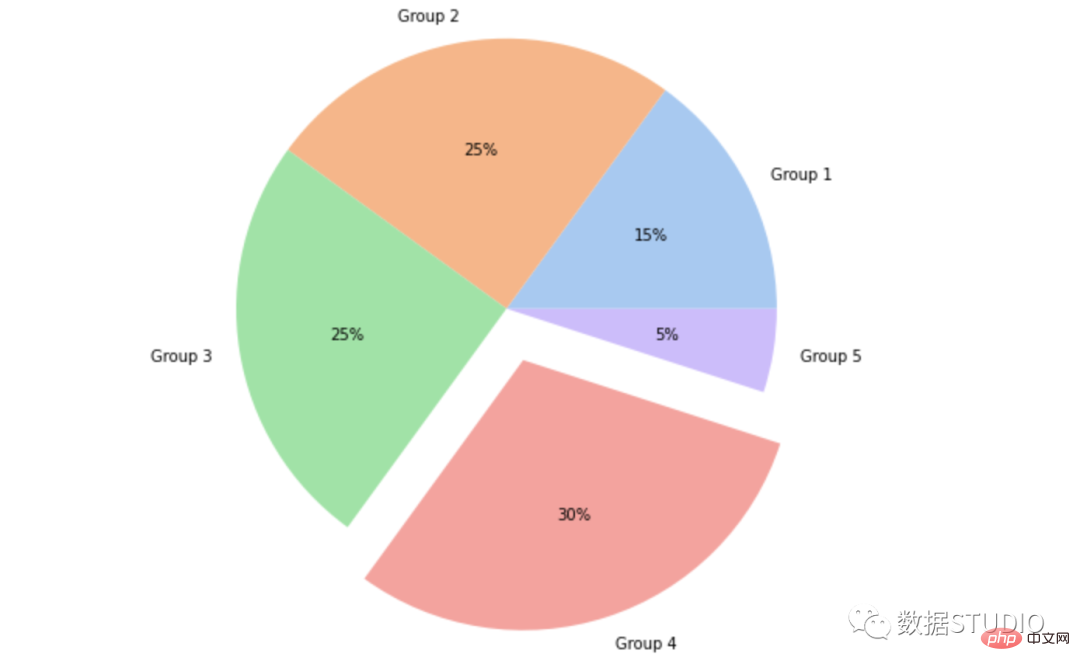
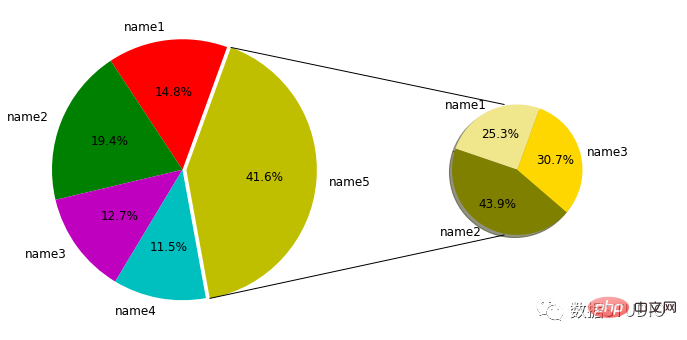
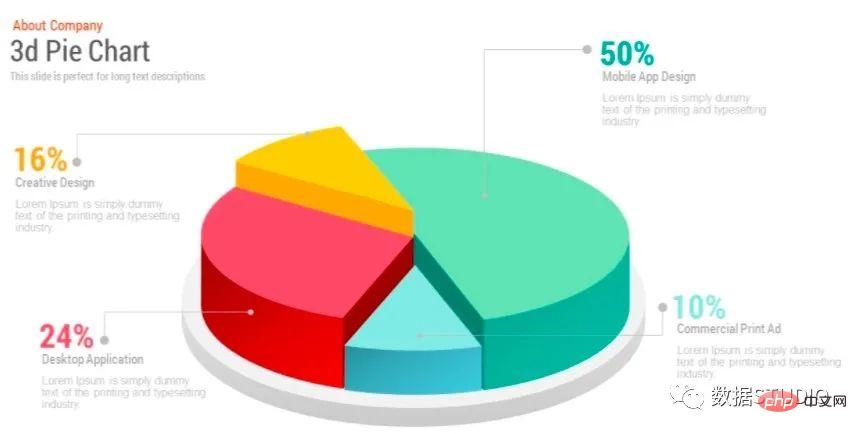
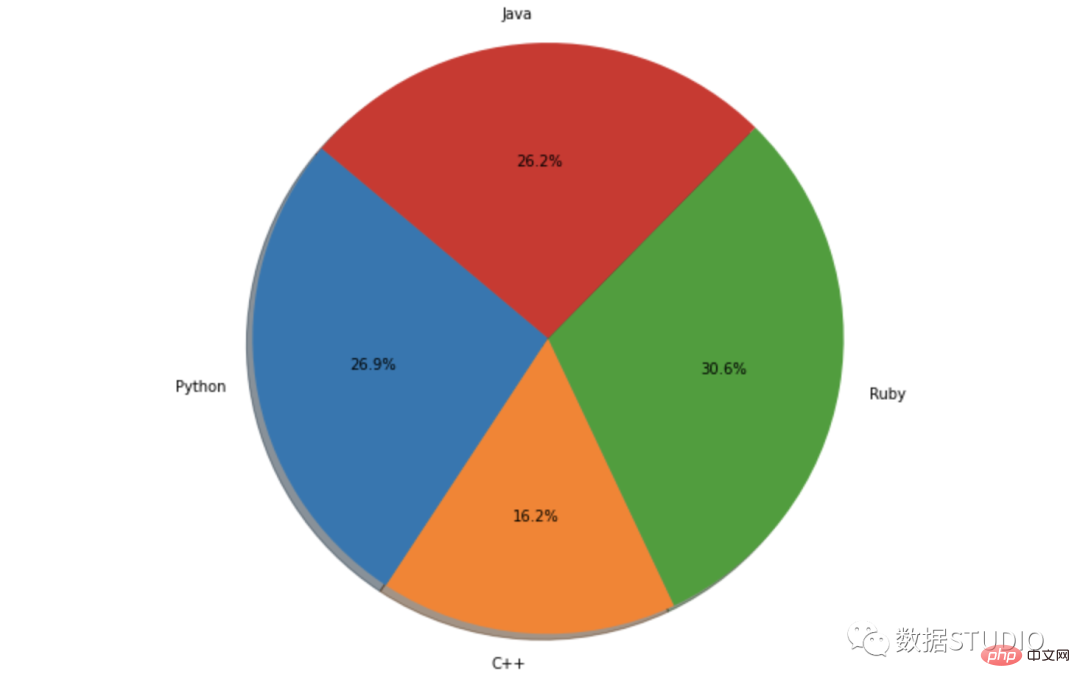
Carta pai mudah
pai ekspres
matplotlib.pyplot.pie
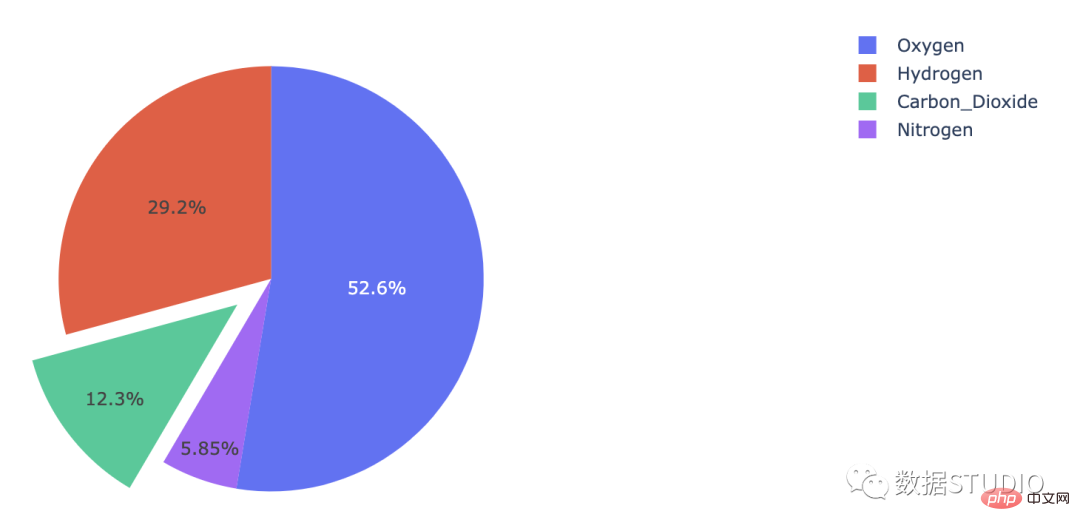
Carta pai meletup
graph_objects Pai dengan atribut tarik
meletup atribut
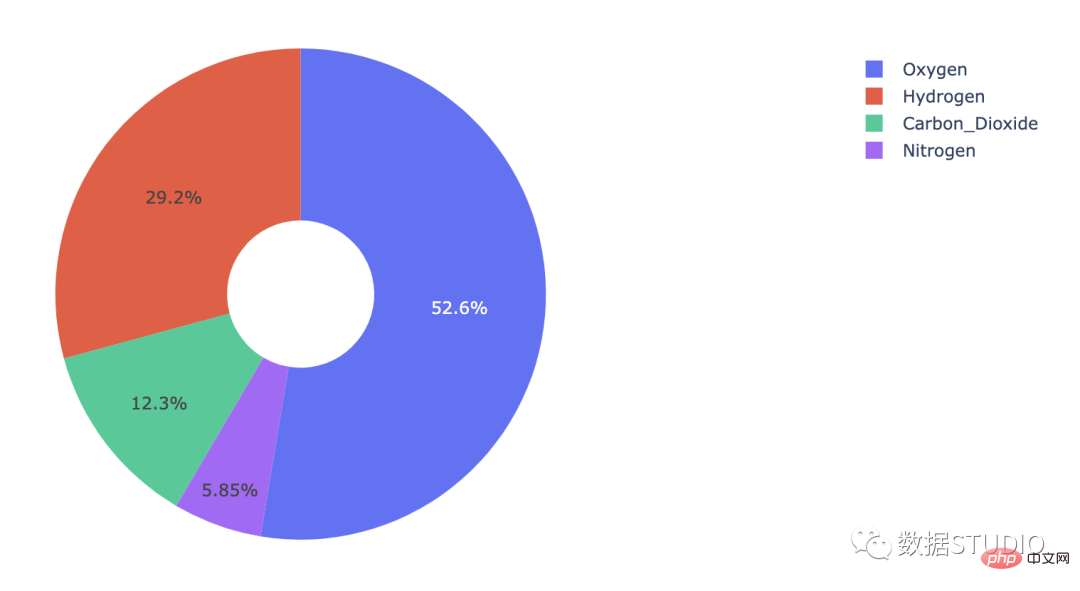
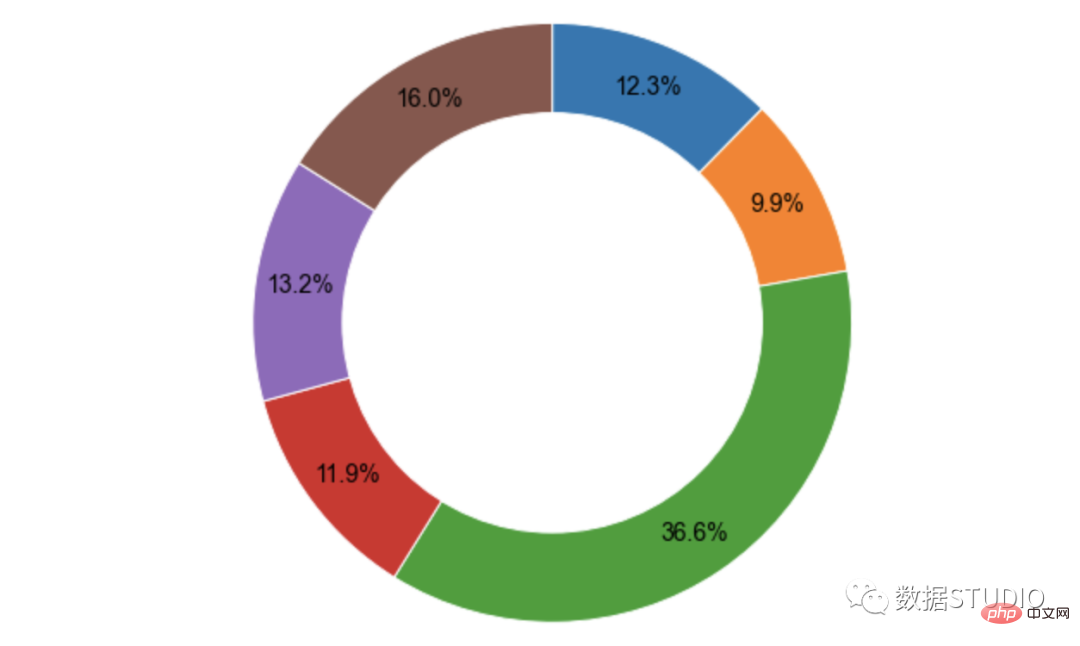
Carta donat
graph_objects Pai dengan atribut hole
Add.py matplot
Click
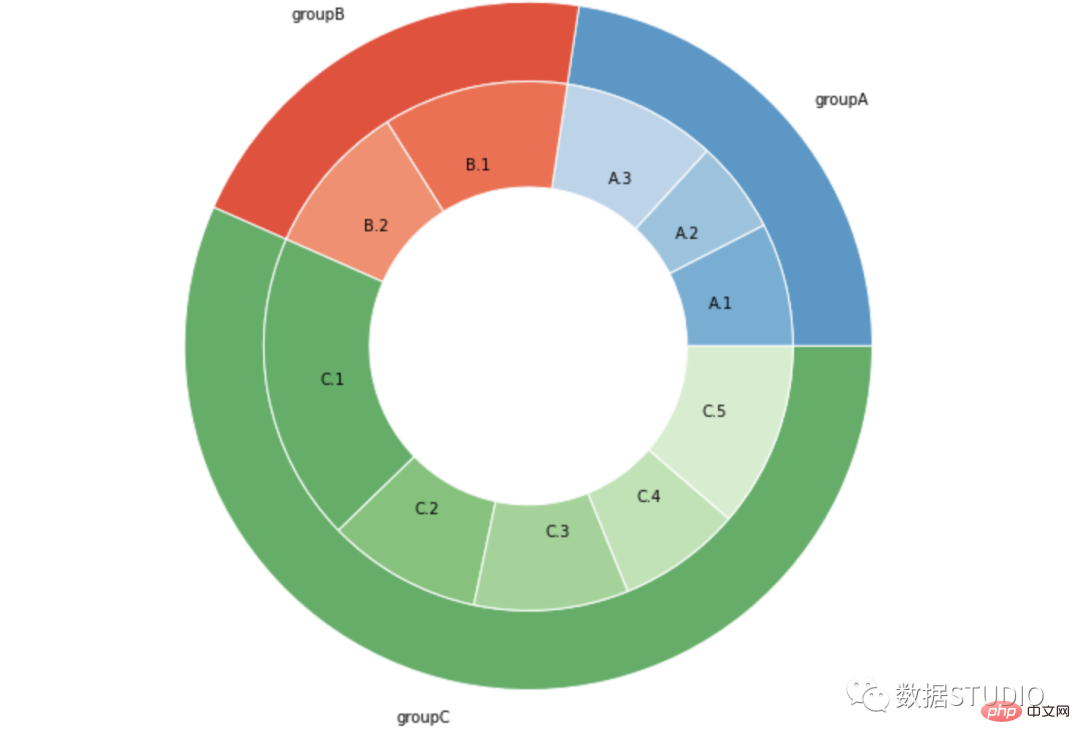
carta pai
Gunakan pakej carta pygoogle
atribut bayang
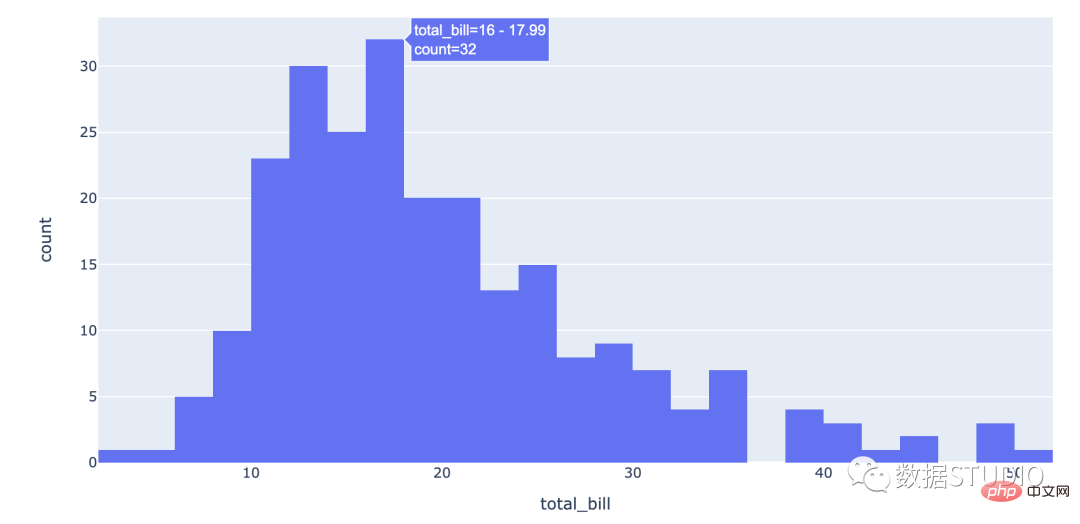
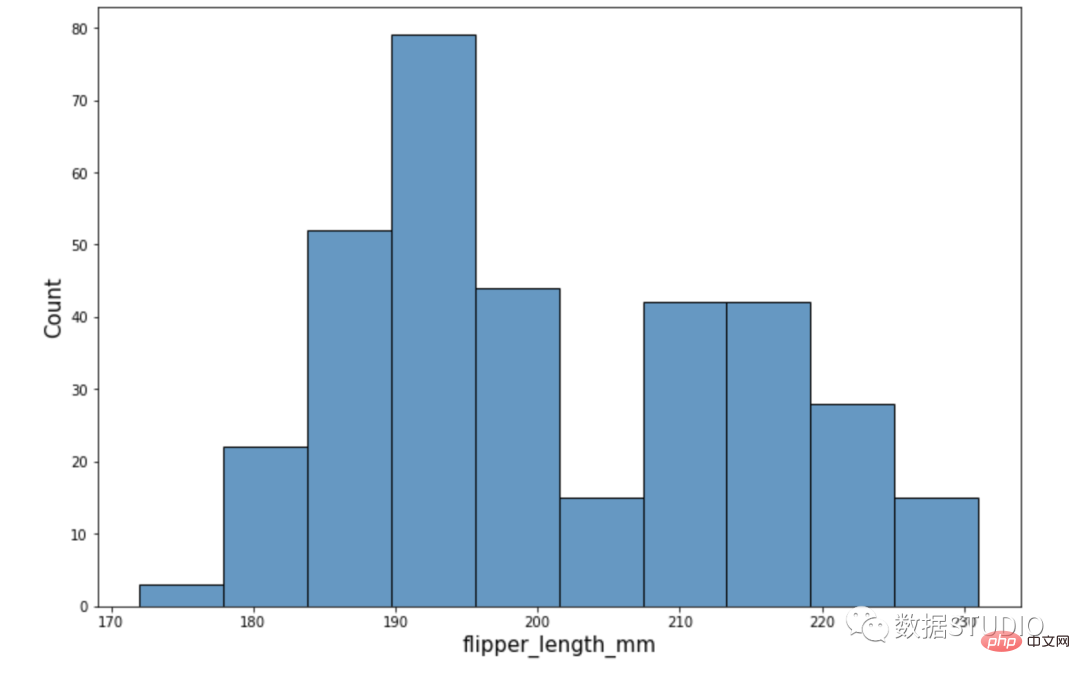
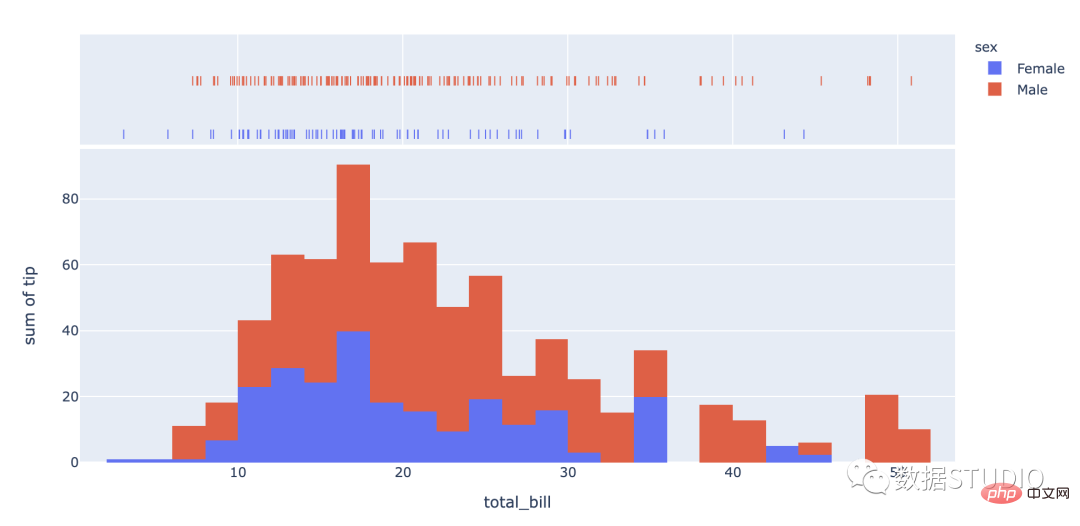
Histogram biasa
express histogram
histplot
Bimodal histogram
color attribute
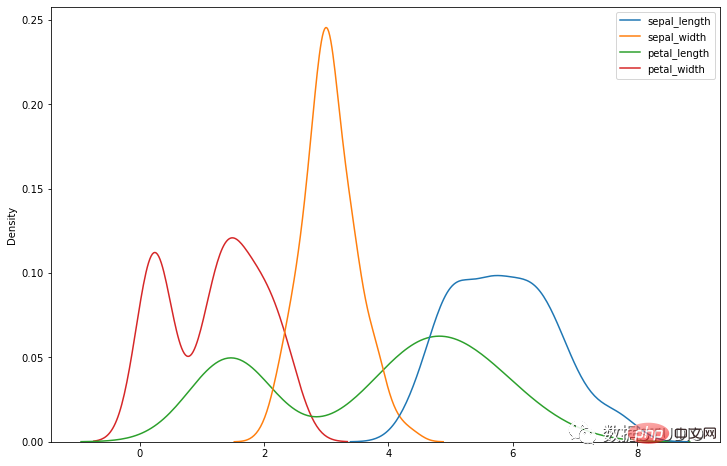
kdeplot
kdeplot
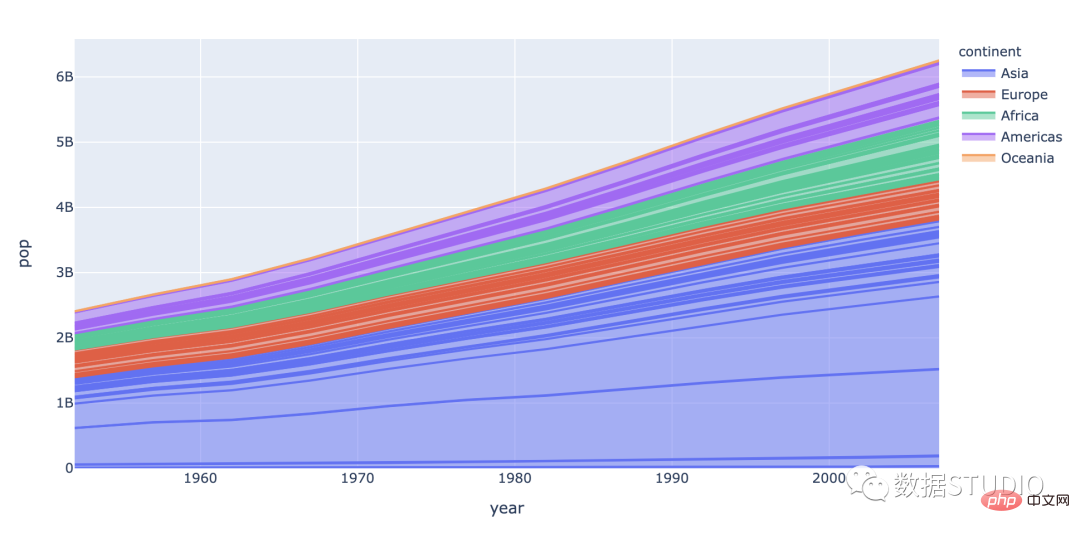
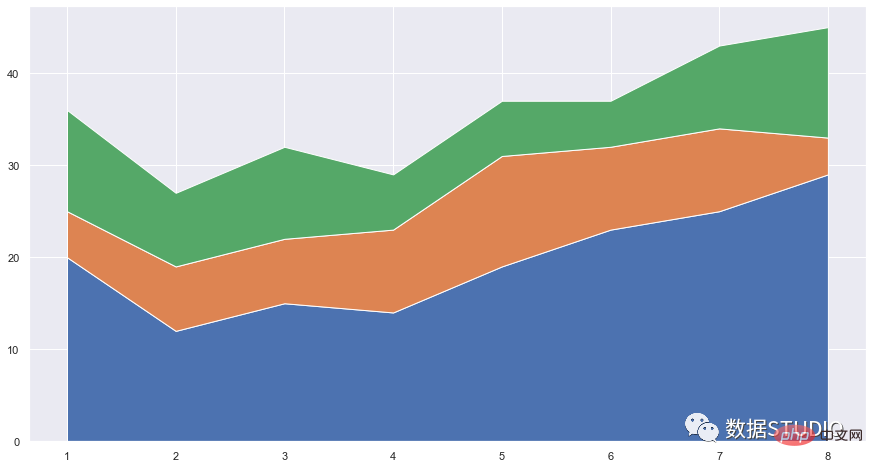
carta rea
kawasan ekspres
matplotlib.pyplot.stackplot
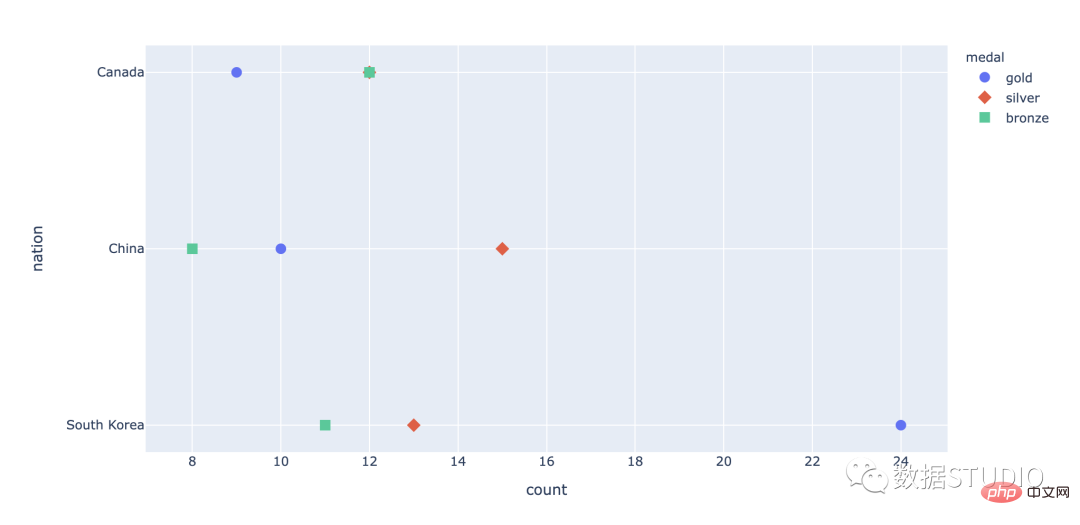
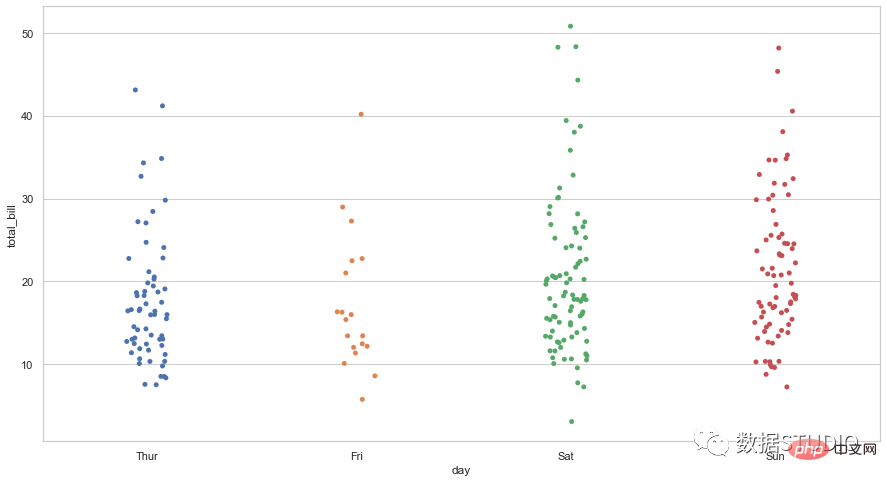
Graf titik
nyatakan serakan
stripplot
Petak serakan
nyatakan serakan
serakan
Carta buih
serakan nyata dengan atribut warna dan saiz
plot serakan dengan atribut saiz
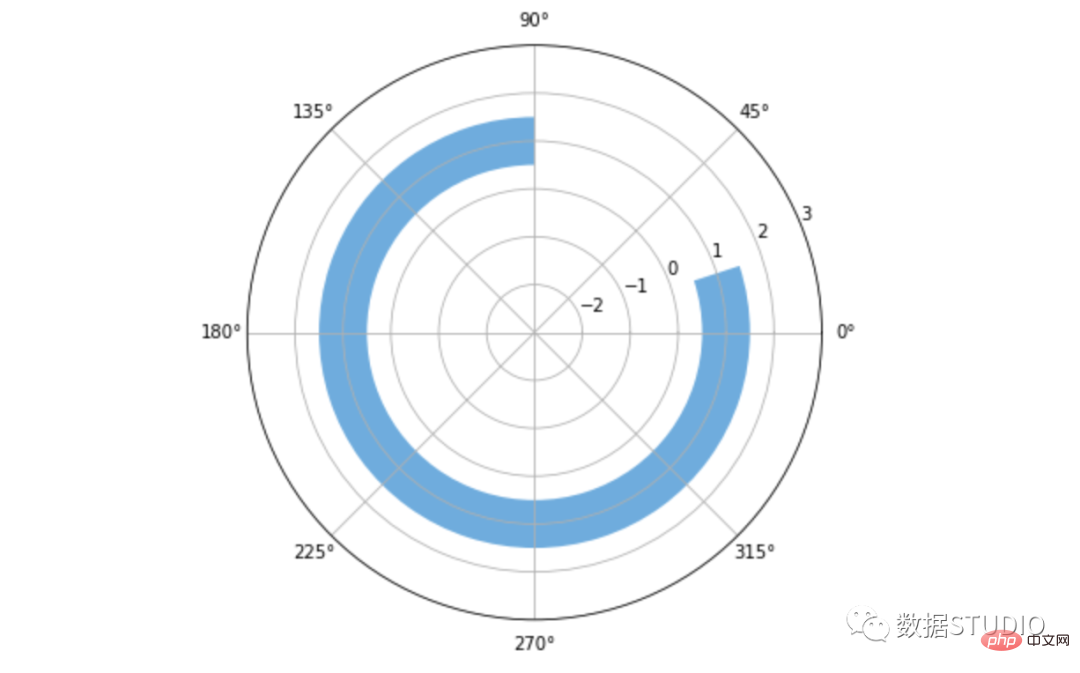
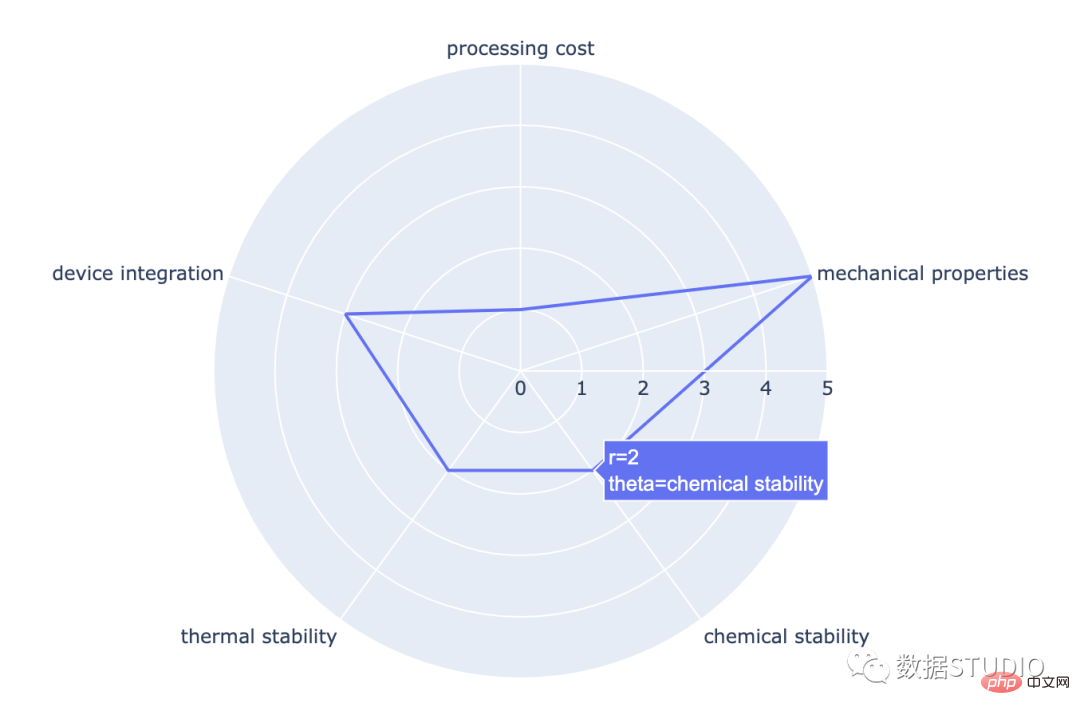
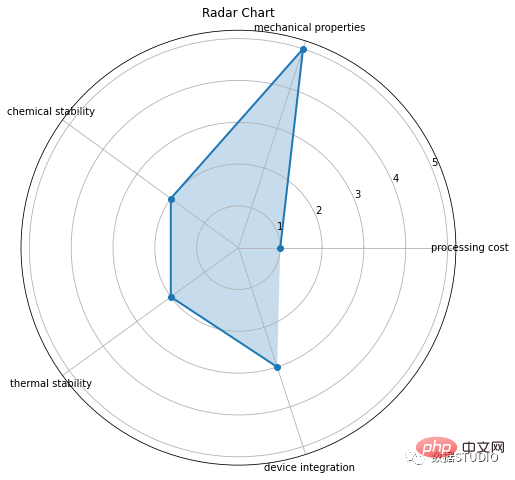
Carta radar
express line_polar
matplotlib.pyplot
Pilotlib.pyplot figure graph_objects Rajah yang mempunyai Scatter dengan atribut penanda
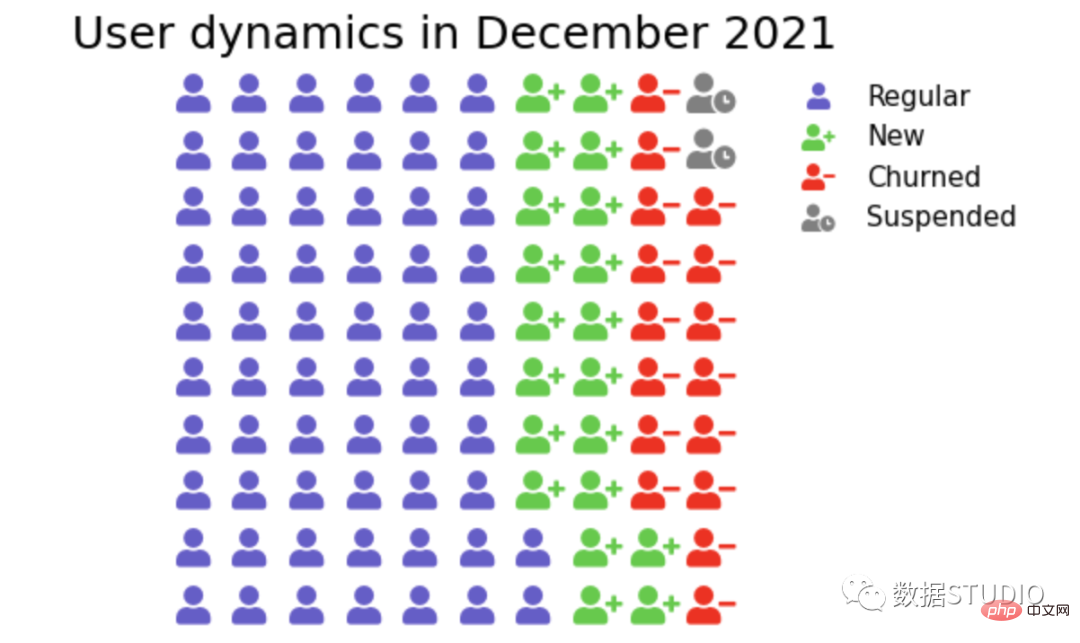
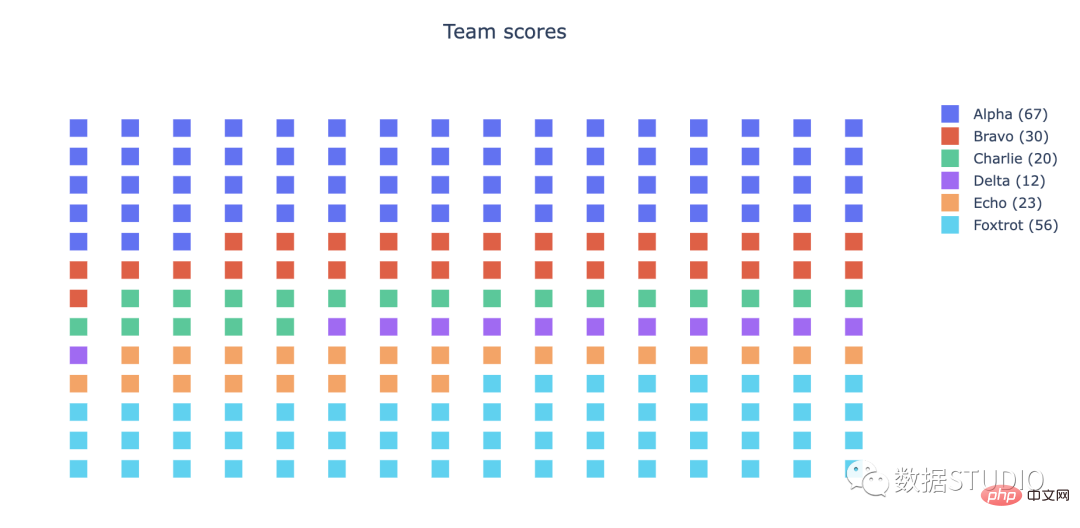
matplotlib.pyplot figure dengan pakej pywaffle
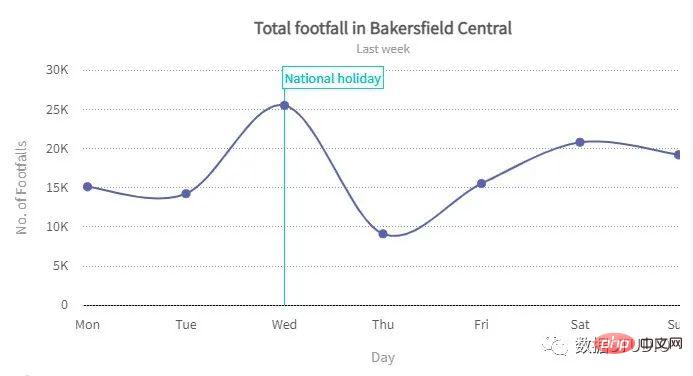
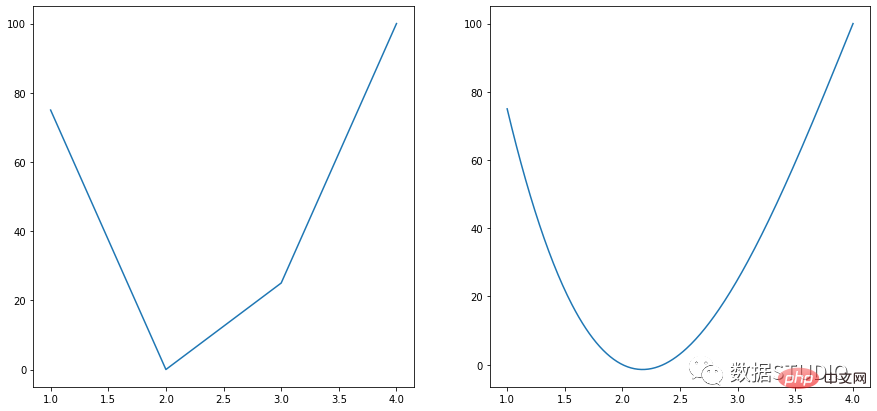
Spline carta
express line dengan line_shape='spline'
Scipy.interpolate.make_interp_spline
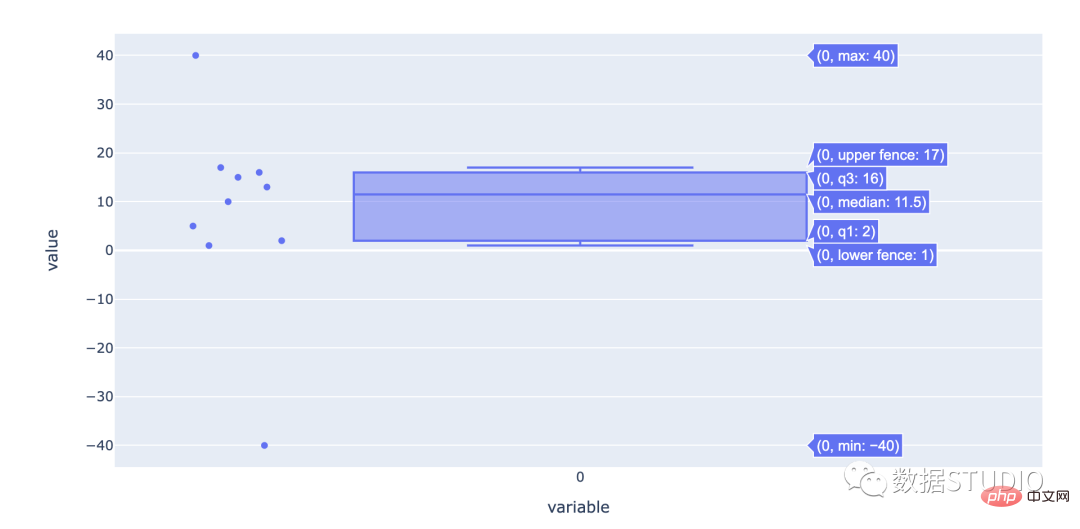
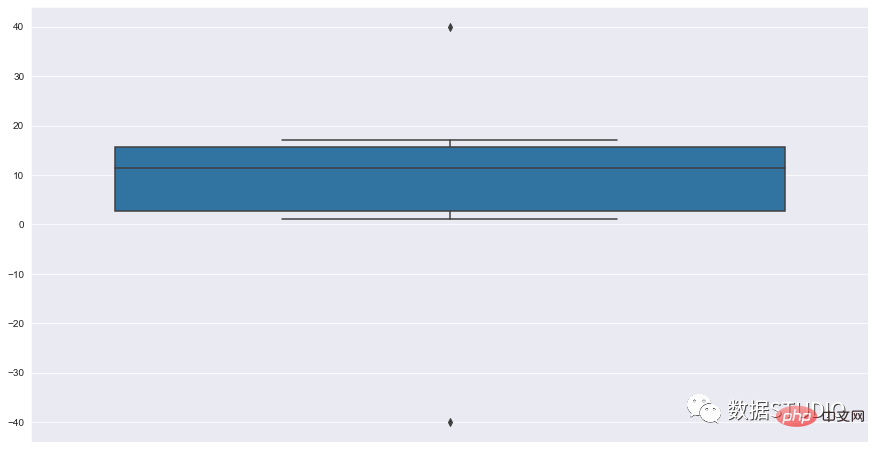
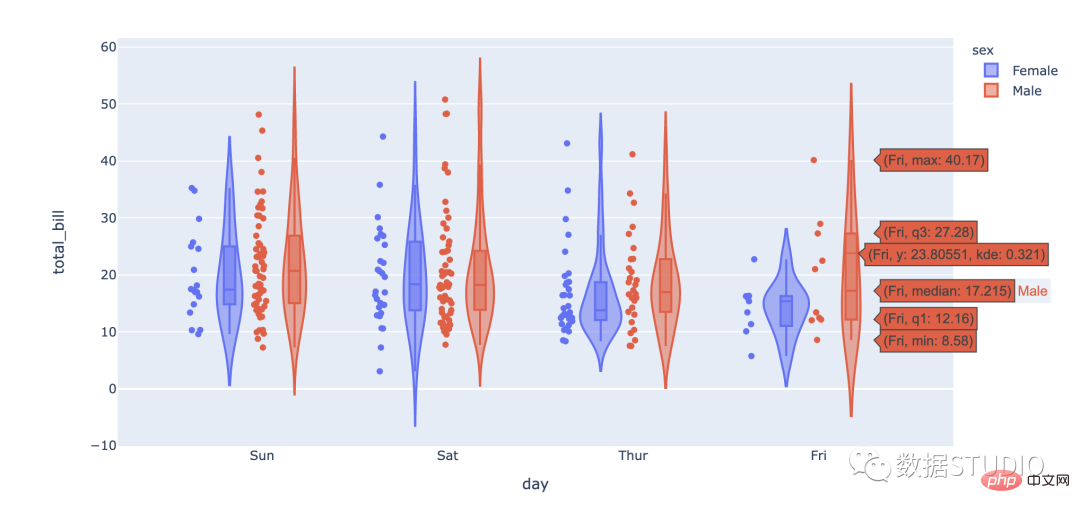
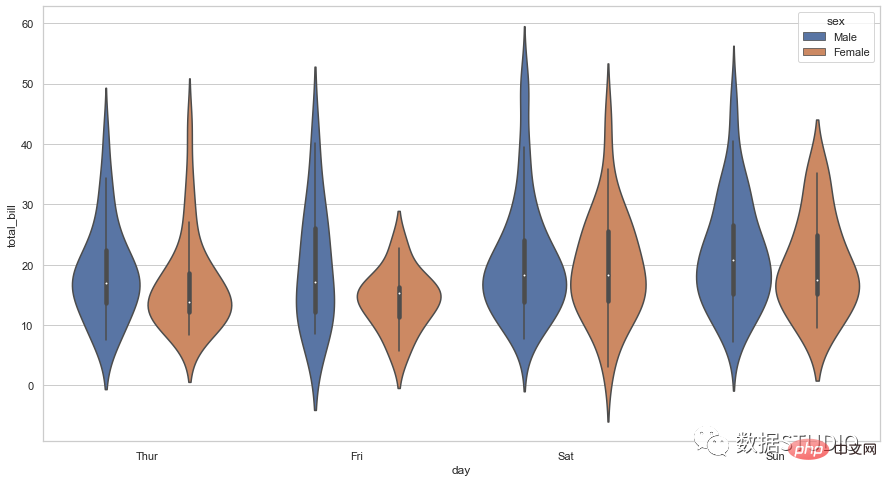
kotak plot
Kotak Biola
biola ekspres
plot biola
Atas ialah kandungan terperinci Petua |. 14 jenis visualisasi data yang paling biasa digunakan dalam Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!