
Rumah >pembangunan bahagian belakang >Tutorial Python >Perhatikan perbezaan antara perpustakaan urllib dan perpustakaan permintaan dalam Python
Perhatikan perbezaan antara perpustakaan urllib dan perpustakaan permintaan dalam Python
- Go语言进阶学习ke hadapan
- 2023-07-25 15:16:501982semak imbas
1. Pengenalan
Apabila menggunakan perangkak Python, anda perlu mensimulasikan permintaan rangkaian. Pustaka utama yang digunakan ialah perpustakaan permintaan dan perpustakaan urllib terbina dalam gunakan permintaan, yang merupakan lanjutan daripada urllib yang dikapsulkan semula.
Apakah perbezaan antara mereka?
Berikut adalah penjelasan terperinci melalui kes untuk memahami perbezaan utama dalam penggunaannya.
2. urllib library
Pengenalan: Objek respons perpustakaan urllib mula-mula mencipta http dan meminta objek, dan kemudian memuatkannya ke dalam reques.urlopen untuk melengkapkan permintaan http.
Apa yang dikembalikan ialah http, objek tindak balas, yang sebenarnya adalah atribut html. Gunakan .read().decode() untuk menyahkod dan menukarnya kepada jenis rentetan str Selepas penyahkodan, aksara Cina boleh dipaparkan.
Contoh:
from urllib import request
#请求头
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
}
wd = {"wd": "中国"}
url = "http://www.baidu.com/s?"
req = request.Request(url, headers=headers)
response = request.urlopen(req)
print(type(response))
print(response)
res = response.read().decode()
print(type(res))
print(res)Hasil larian:
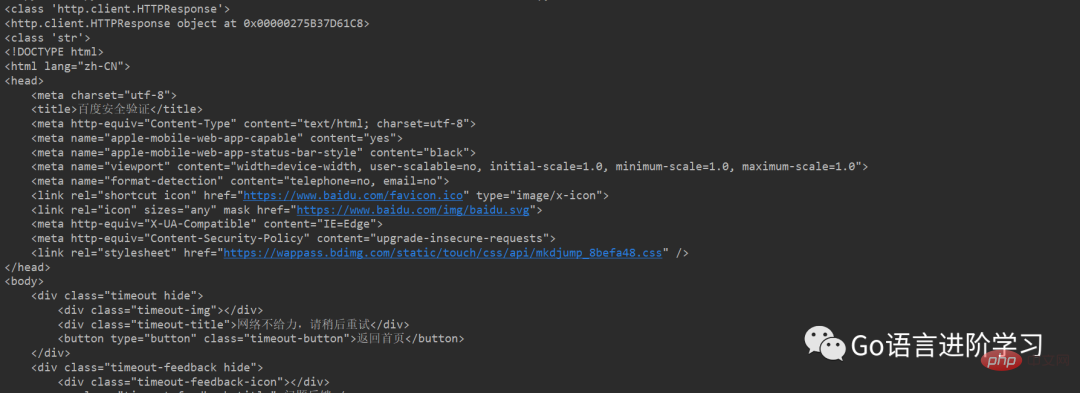
Biasanya merangkak halaman web, apabila membina permintaan http, anda perlu Tambah beberapa maklumat tambahan, seperti Ejen Pengguna, kuki, dsb., atau tambah pelayan proksi. Selalunya ini adalah mekanisme anti-merangkak yang diperlukan.
三、requests库
简介:requests库调用是requests.get方法传入url和参数,返回的对象是Response对象,打印出来是显示响应状态码。
通过.text 方法可以返回是unicode 型的数据,一般是在网页的header中定义的编码形式,而content返回的是bytes,二级制型的数据,还有 .json方法也可以返回json字符串。
如果想要提取文本就用text,但是如果你想要提取图片、文件等二进制文件,就要用content,当然decode之后,中文字符也会正常显示。
requests的优势:Python爬虫时,更建议用requests库。因为requests比urllib更为便捷,requests可以直接构造get,post请求并发起,而urllib.request只能先构造get,post请求,再发起。
例:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36"
}
wd = {"wd": "中国"}
url = "http://www.baidu.com/s?"
response = requests.get(url, params=wd, headers=headers)
data = response.text
data2 = response.content
print(response)
print(type(response))
print(data)
print(type(data))
print(data2)
print(type(data2))
print(data2.decode())
print(type(data2.decode()))运行结果 (可以直接获取整网页的信息,打印控制台):
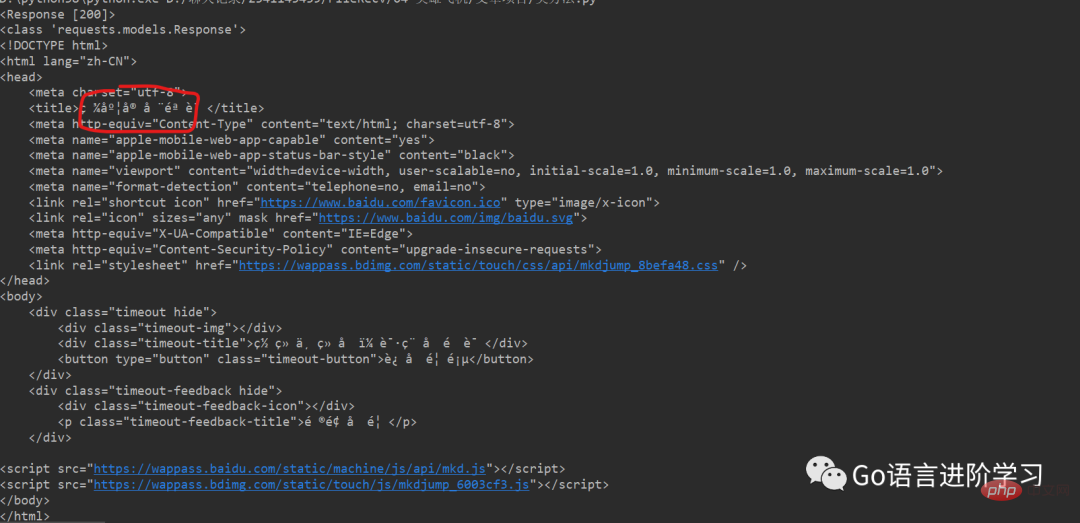
四、总结
1. 本文基于Python基础,主要介绍了urllib库和requests库的区别。
2. 在使用urllib内的request模块时,返回体获取有效信息和请求体的拼接需要decode和encode后再进行装载。进行http请求时需先构造get或者post请求再进行调用,header等头文件也需先进行构造。
3. requests是对urllib的进一步封装,因此在使用上显得更加的便捷,建议在实际应用当中尽量使用requests。
4. 希望能给一些对爬虫感兴趣,有一个具体的概念。方法只是一种工具,试着去爬一爬会更容易上手,网络也会有很多的坑,做爬虫更需要大量的经验来应付复杂的网络情况。
5. 希望大家一起探讨学习, 一起进步。
Atas ialah kandungan terperinci Perhatikan perbezaan antara perpustakaan urllib dan perpustakaan permintaan dalam Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!