
Rumah >Peranti teknologi >AI >Betapa menakjubkan model penukaran pertuturan mudah yang menyokong pertukaran bahasa silang, suara manusia dan salakan anjing dan hanya menggunakan jiran terdekat?
Betapa menakjubkan model penukaran pertuturan mudah yang menyokong pertukaran bahasa silang, suara manusia dan salakan anjing dan hanya menggunakan jiran terdekat?

- 王林ke hadapan
- 2023-07-04 17:57:091177semak imbas
Dunia suara yang disertai AI sangat ajaib. Ia bukan sahaja boleh menukar suara seseorang kepada mana-mana orang lain, tetapi juga bertukar suara dengan haiwan.
Kami tahu bahawa matlamat penukaran suara adalah untuk menukar suara sumber kepada suara sasaran sambil mengekalkan kandungan tidak berubah. Kaedah penukaran pertuturan mana-mana ke mana-mana baru-baru ini meningkatkan keaslian dan persamaan pembesar suara, tetapi dengan mengorbankan kerumitan yang sangat meningkat. Ini bermakna latihan dan inferens menjadi lebih mahal, menjadikan penambahbaikan sukar untuk dinilai dan diwujudkan.
Persoalannya, adakah penukaran pertuturan berkualiti tinggi memerlukan kerumitan? Dalam makalah baru-baru ini dari Universiti Stellenbosch di Afrika Selatan, beberapa penyelidik meneroka isu ini.

- Alamat kertas: https://arxiv.org/pdf/2305.18975.pdf
- Alamat GitHub: https://bshall.github.io/
Mereka memperkenalkan K-Nearest Neighbor Speech Conversion (kNN-VC), kaedah penukaran sebarang-ke-mana-mana pertuturan yang mudah dan berkuasa . Daripada melatih model transformasi eksplisit, regresi jiran terdekat K hanya digunakan.
Secara khusus, penyelidik mula-mula menggunakan model perwakilan pertuturan yang diselia sendiri untuk mengekstrak urutan ciri ujaran sumber dan sebutan rujukan, dan kemudian menukar setiap bingkai perwakilan sumber kepada pembesar suara sasaran dengan menggantikannya dengan jiran terdekat dalam rujukan , dan akhirnya gunakan vocoder saraf untuk mensintesis ciri yang ditukar untuk mendapatkan pertuturan yang ditukar.Berdasarkan keputusannya, di sebalik kesederhanaannya, KNN-VC mencapai kebolehfahaman yang setanding malah dipertingkatkan dan persamaan pembesar suara dalam kedua-dua penilaian subjektif dan objektif berbanding beberapa sistem penukaran pertuturan garis dasar.
Mari kita hayati kesan penukaran suara KNN-VC. Melihat dahulu pada penukaran suara manusia, KNN-VC digunakan pada pembesar suara sumber dan sasaran yang tidak kelihatan dalam set data LibriSpeech. Suara Disintesis
KNN-VC juga menyokong penukaran suara merentas bahasa , Contohnya, Sepanyol ke Jerman, Jerman ke Jepun, Cina ke Sepanyol.
Source Chinese 00: 08
target Bahasa Sepanyol 00: 05 Ucapan Keistimewaan 300: 08 even lebih luar biasa, KNN-VC masih dapat menukar suara manusia dan bunyi salakan anjing.
Sumber anjing menyalak00:09
Sumber suara manusia
00:05
Suara sintetik 0:09
Suara sintetik 5
00:05
Mari kita lihat bagaimana KNN-VC berjalan dan membandingkan dengan kaedah jixian yang lain. Gambaran Keseluruhan Kaedah dan Keputusan Eksperimen
Rajah seni bina kNN-VC ditunjukkan di bawah, mengikut struktur pengekod-penukar-vokoder. Mula-mula pengekod mengekstrak perwakilan yang diselia sendiri bagi sumber dan ucapan rujukan, kemudian penukar memetakan setiap bingkai sumber kepada jiran terdekat mereka dalam rujukan, dan akhirnya vokoder menjana bentuk gelombang audio berdasarkan ciri yang ditukar.
Pengekod menggunakan WavLM, penukar menggunakan regresi jiran terdekat K, dan vocoder menggunakan HiFiGAN. Satu-satunya komponen yang memerlukan latihan ialah vocoder. Untuk pengekod WavLM, penyelidik hanya menggunakan model WavLM-Large yang telah dilatih dan tidak melakukan sebarang latihan mengenainya dalam artikel. Bagi model transformasi kNN, kNN adalah bukan parametrik dan tidak memerlukan sebarang latihan. Untuk vokoder HiFiGAN, repo pengarang HiFiGAN asal telah digunakan untuk mengekod ciri WavLM, menjadi satu-satunya bahagian yang memerlukan latihan.
Gambar
Dalam percubaan, penyelidik terlebih dahulu membandingkan KNN-VC dengan kaedah asas lain, menggunakan data sasaran terbesar yang tersedia (kira-kira 8 minit audio bagi setiap pembesar suara) untuk menguji sistem penukaran pertuturan .
Untuk KNN-VC, penyelidik menggunakan semua data sasaran sebagai set padanan. Untuk kaedah garis dasar, mereka purata pembenaman pembesar suara untuk setiap ujaran sasaran.
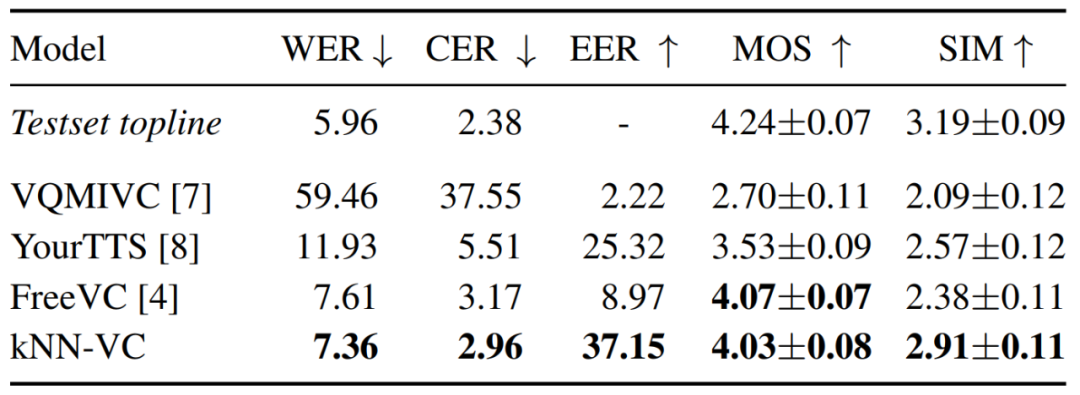
Jadual 1 di bawah melaporkan keputusan untuk kebolehfahaman, keaslian dan persamaan pembesar suara untuk setiap model. Seperti yang dapat dilihat, kNN-VC mencapai keaslian dan kejelasan yang serupa dengan FreeVC garis dasar terbaik, tetapi dengan persamaan pembesar suara yang dipertingkatkan dengan ketara. Ini juga mengesahkan penegasan artikel ini: penukaran pertuturan berkualiti tinggi tidak memerlukan kerumitan yang meningkat.
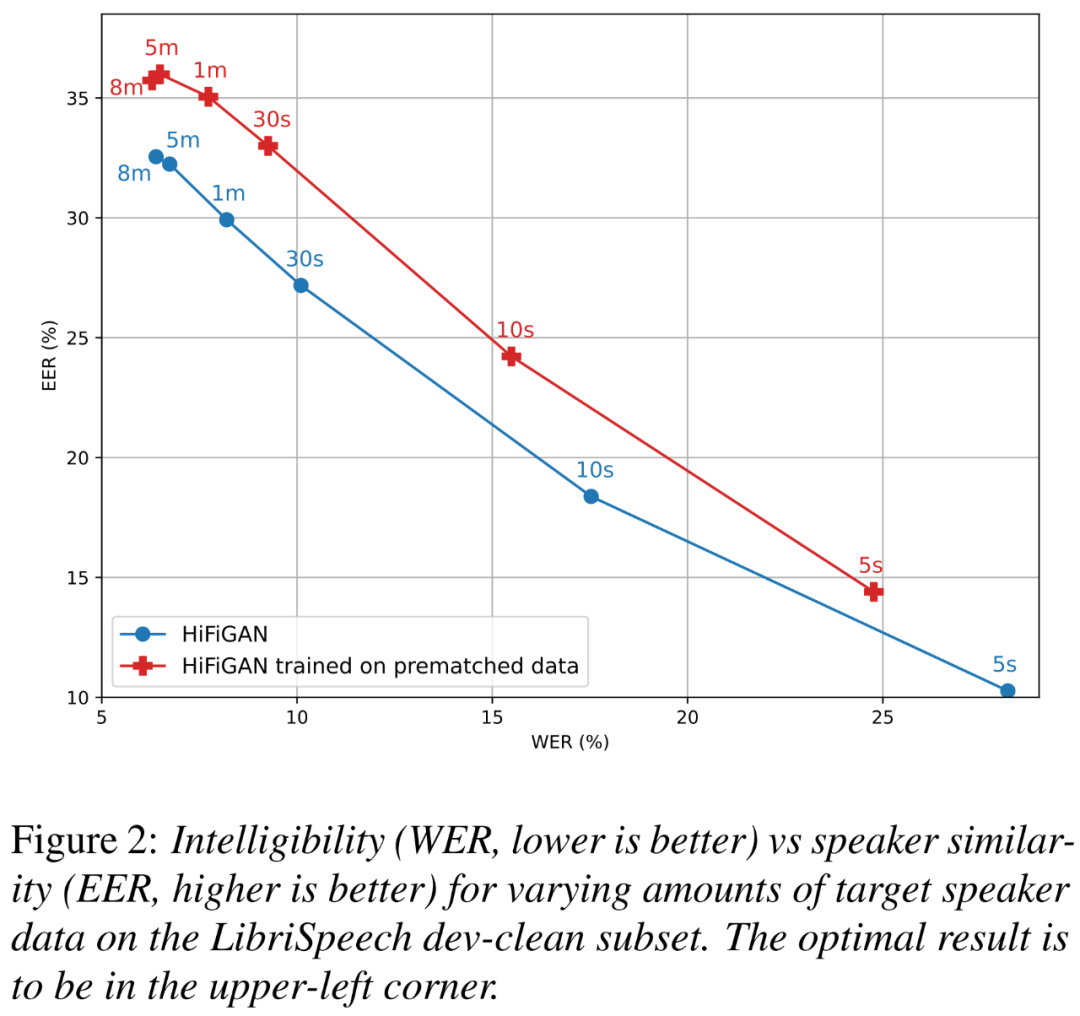
Di samping itu, penyelidik ingin memahami sejauh mana peningkatan disebabkan oleh HiFi-GAN yang dilatih pada data pra-padanan, dan sejauh mana saiz data pembesar suara sasaran mempengaruhi kebolehfahaman dan persamaan pembesar suara.
Rajah 2 di bawah menunjukkan hubungan antara WER (lebih kecil lebih baik) dan EER (lebih tinggi adalah lebih baik) untuk dua varian HiFi-GAN pada saiz pembesar suara sasaran yang berbeza.
 Gambar
Gambar
Komen hangat netizen
Untuk kaedah penukaran pertuturan baharu ini kNN-VC yang "hanya menggunakan jiran terdekat", sesetengah orang berpendapat bahawa model pertuturan yang telah dilatih digunakan dalam model pertuturan yang telah dilatih. , jadi "sahaja" digunakan Tidak cukup tepat. Tetapi tidak dapat dinafikan bahawa kNN-VC masih lebih ringkas berbanding model lain.
Hasilnya juga membuktikan bahawa kNN-VC adalah sama berkesan, jika bukan yang terbaik, berbanding kaedah penukaran pertuturan mana-mana kepada mana-mana yang sangat kompleks. .
 Gambar
Gambar
Atas ialah kandungan terperinci Betapa menakjubkan model penukaran pertuturan mudah yang menyokong pertukaran bahasa silang, suara manusia dan salakan anjing dan hanya menggunakan jiran terdekat?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI