
Rumah >Peranti teknologi >AI >Tiada lagi kebimbangan tentang 'persidangan video' yang memalukan! Google CHI akan mengeluarkan Artifak Visual Captions baharu: biarkan gambar menjadi pembantu sari kata anda
Tiada lagi kebimbangan tentang 'persidangan video' yang memalukan! Google CHI akan mengeluarkan Artifak Visual Captions baharu: biarkan gambar menjadi pembantu sari kata anda

- WBOYke hadapan
- 2023-06-12 19:10:241005semak imbas
Dalam beberapa tahun kebelakangan ini, bahagian "persidangan video" dalam kerja telah meningkat secara beransur-ansur, dan pengeluar juga telah membangunkan pelbagai teknologi seperti sari kata masa nyata untuk memudahkan komunikasi antara orang dengan bahasa yang berbeza dalam mesyuarat .
Tetapi terdapat satu lagi perkara yang menyakitkan jika ada istilah yang tidak dikenali oleh pihak lain disebut dalam perbualan, dan sukar untuk menggambarkannya dengan kata-kata, seperti makanan ". Sukiyaki", atau " "Pergi ke taman untuk bercuti minggu lepas", sukar untuk menggambarkan pemandangan yang indah kepada pihak lain dengan kata-kata, malah menunjukkan bahawa "Tokyo terletak di wilayah Kanto di Jepun" dan memerlukan peta untuk menunjukkannya, dan lain-lain. Jika anda hanya menggunakan kata-kata, ia mungkin membuat pihak lain semakin marah.

Baru-baru ini, Google telah menunjukkan pada persidangan teratas mengenai interaksi manusia-komputer ACM CHI (Persidangan Faktor Manusia dalam Sistem Pengkomputeran ) Kapsyen Visual, sistem yang memperkenalkan penyelesaian visual baharu dalam persidangan jauh, boleh menjana atau mendapatkan semula imej dalam konteks perbualan untuk meningkatkan pemahaman pihak lain tentang konsep yang kompleks atau tidak dikenali.

Pautan kertas: https://research.google/pubs/pub52074/
Pautan kod: https://github.com/google/archat
Sistem Kapsyen Visual adalah berdasarkan diperhalusi Model bahasa besar yang boleh mengesyorkan secara proaktif elemen visual yang berkaitan dalam perbualan kosa kata terbuka dan telah disepadukan ke dalam projek sumber terbuka ARChat.

Dalam tinjauan pengguna, penyelidik menjemput 26 peserta di makmal untuk berinteraksi dengan mereka di luar makmal 10 peserta dinilai sistem, dan lebih daripada 80% pengguna pada dasarnya bersetuju bahawa Kapsyen Video boleh memberikan cadangan visual yang berguna dan bermakna dalam pelbagai senario dan boleh meningkatkan pengalaman komunikasi.
Idea Reka Bentuk
Sebelum pembangunan, penyelidik terlebih dahulu menjemput 10 peserta dalaman, termasuk jurutera perisian, penyelidik, pereka UX, artis visual, pelajar dan pengamal dari teknikal dan bukan -latar belakang teknikal untuk membincangkan keperluan dan jangkaan khusus untuk perkhidmatan peningkatan visual masa nyata.
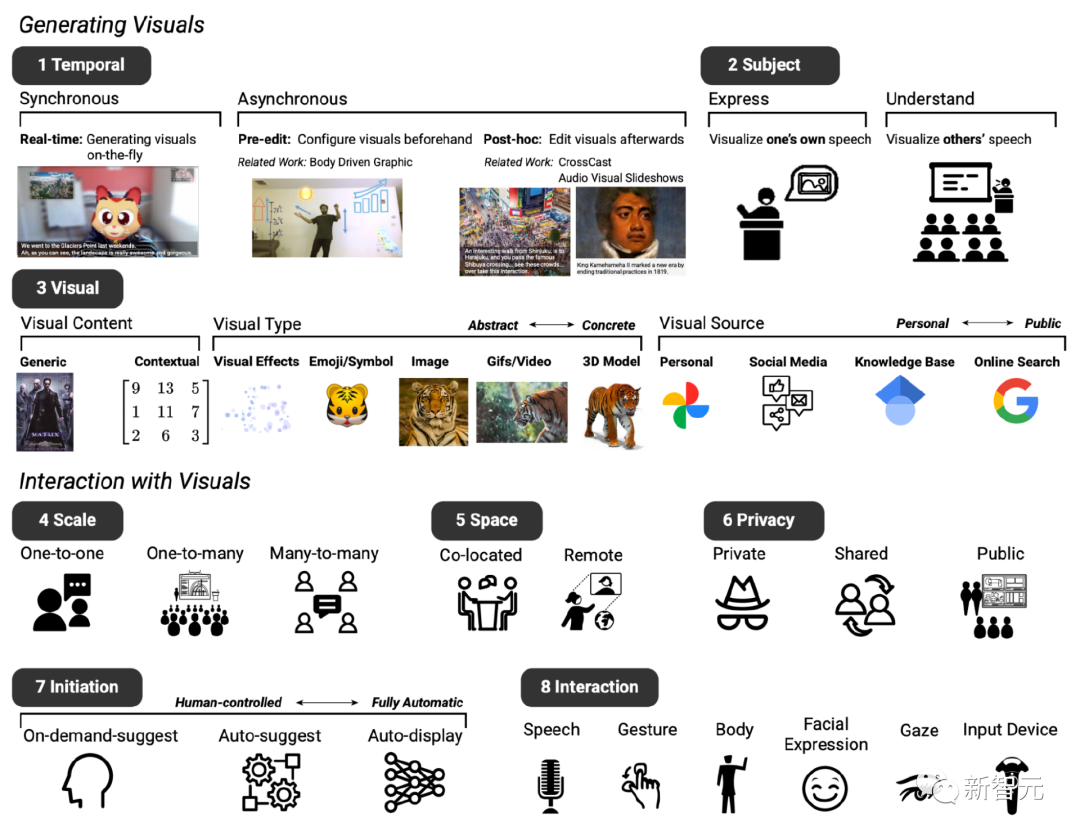
Selepas dua mesyuarat, berdasarkan sistem teks-ke-imej sedia ada, reka bentuk asas sistem prototaip yang dijangkakan telah diwujudkan, terutamanya termasuk lapan dimensi (ditandakan sebagai D1 hingga D8).
D1: Masa, sistem peningkatan visual boleh dipaparkan secara serentak atau tidak segerak dengan dialog
D2: Tema, yang boleh digunakan untuk menyatakan dan memahami kandungan pertuturan
D3: Visual, boleh menggunakan pelbagai kandungan visual, jenis visual dan sumber visual
D4: Skala , bergantung pada saiz mesyuarat, Penambahbaikan visual mungkin berbeza-beza
D5: Ruang, sama ada persidangan video terletak bersama atau dalam tetapan jauh
D6: Privasi, Faktor ini juga mempengaruhi sama ada visual perlu dipaparkan secara tertutup, dikongsi sesama peserta atau umum kepada semua orang
D7: Keadaan awal, peserta juga mengenal pasti orang yang mereka ingin berinteraksi apabila terlibat dalam perbualan Cara yang berbeza untuk berinteraksi dengan sistem, contohnya, tahap "inisiatif" yang berbeza, iaitu pengguna boleh menentukan secara autonomi apabila sistem campur tangan dalam sembang D8: Interaksi, peserta membayangkan kaedah interaksi yang berbeza , sebagai contoh, menggunakan suara atau gerak isyarat untuk input
Gunakan kesan visual dinamik untuk meningkatkan ruang reka bentuk komunikasi bahasa
Berdasarkan maklum balas awal, penyelidik mereka bentuk sistem Kapsyen Video untuk menumpukan pada penjanaan kesan visual yang disegerakkan bagi kandungan visual, jenis dan sumber yang berkaitan secara semantik.
Walaupun kebanyakan idea dalam mesyuarat penerokaan menumpukan pada perbualan jarak jauh satu-sama-satu, Kapsyen Video juga boleh digunakan satu-ke-banyak (cth., menyampaikan kepada penonton) dan penggunaan senario banyak-ke-banyak (perbincangan persidangan berbilang orang).
Selain itu, visual yang paling melengkapi perbualan sangat bergantung pada konteks perbincangan, jadi set latihan yang direka khas diperlukan.
Para penyelidik mengumpul 1595 empat kali ganda, termasuk bahasa, kandungan visual, jenis, sumber, merangkumi pelbagai senario kontekstual, termasuk perbualan harian, kuliah, panduan perjalanan, dsb.
Contohnya, pengguna berkata "Saya ingin melihatnya!" (saya ingin melihatnya!) sepadan dengan kandungan visual dan "emotikon" "muka tersenyum" (emoji) jenis visual dan sumber visual "carian awam" (carian awam).
"Adakah dia memberitahu anda tentang perjalanan kami ke Mexico sepadan dengan kandungan visual "Foto dari perjalanan ke Mexico", jenis visual "Foto" dan "Album Peribadi?" "sumber visual.
Set data VC 1.5K ialah sumber terbuka pada masa ini.
Pautan data: https://github.com/google/archat/tree/main/dataset
Model Ramalan Niat Visual
Untuk meramalkan visual yang melengkapkan perbualan, penyelidik melatih niat visual berdasarkan model bahasa yang besar menggunakan set data VC1.5K Model ramalan niat.
Semasa fasa latihan, setiap niat visual dihuraikan ke dalam format "

Berdasarkan format ini, sistem boleh mengendalikan perbualan kosa kata terbuka dan ramalan kontekstual kandungan visual, sumber visual dan visual menaip.

Pendekatan ini juga lebih baik dalam amalan daripada pendekatan berasaskan kata kunci kerana pendekatan yang kedua tidak dapat mengendalikan perbendaharaan kata terbuka Contohnya , pengguna boleh berkata "Mak Cik Amy anda akan melawat Sabtu ini Jika kata kunci tidak dipadankan, adalah mustahil untuk mengesyorkan jenis visual atau sumber visual yang berkaitan.
Para penyelidik menggunakan 1276 (80%) sampel daripada dataset VC1.5K untuk memperhalusi model bahasa besar, dan baki 319 (20%) sampel sebagai data ujian, dan menggunakan token dengan tepat Indeks kadar digunakan untuk mengukur prestasi model yang diperhalusi, iaitu peratusan token yang betul dalam sampel yang diramalkan dengan betul oleh model.
Model akhir boleh mencapai 97% ketepatan token latihan dan 87% ketepatan token pengesahan.
Tinjauan Praktikal
Untuk menilai kepraktisan model sari kata visual terlatih, pasukan penyelidik menjemput 89 peserta untuk melaksanakan 846 tugasan dan meminta untuk menilai kesannya. , 1 bermaksud sangat tidak setuju, 7 bermaksud sangat setuju.
Hasil eksperimen menunjukkan bahawa kebanyakan peserta lebih suka melihat kesan visual dalam perbualan (S1), dan 83% memberikan penilaian 5-agak setuju atau lebih tinggi.
Tambahan pula, peserta mendapati visual yang dipaparkan berguna dan bermaklumat (S2), dengan 82% memberikan rating lebih tinggi daripada 5 kualiti tinggi (Q3), 82% memberikan penilaian yang lebih tinggi daripada 5 mata; dan berkaitan dengan suara asal (Q4, 84%).
Peserta juga mendapati bahawa jenis visual yang diramalkan (Q5, 87%) dan sumber visual (Q6, 86%) adalah tepat dalam konteks perbualan yang sepadan.
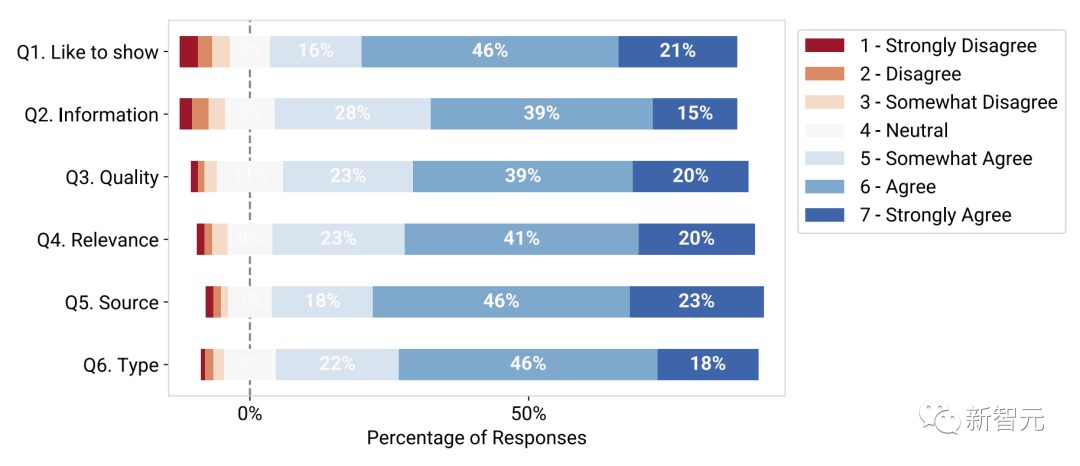
Peserta kajian menilai keputusan penilaian teknikal model ramalan visual
Berdasarkan model ramalan niat visual yang diperhalusi ini, penyelidik membangunkan Kapsyen Visual pada platform ARChat, yang boleh menambah widget interaktif baharu secara terus pada strim kamera platform persidangan video seperti Google Meet .
Dalam aliran kerja sistem, Kapsyen Video boleh menangkap suara pengguna secara automatik, mendapatkan semula ayat terakhir, memasukkan data ke dalam model ramalan niat visual setiap 100 milisaat dan mendapatkan semula kesan visual yang berkaitan, dan kemudian berikan visual yang disyorkan.
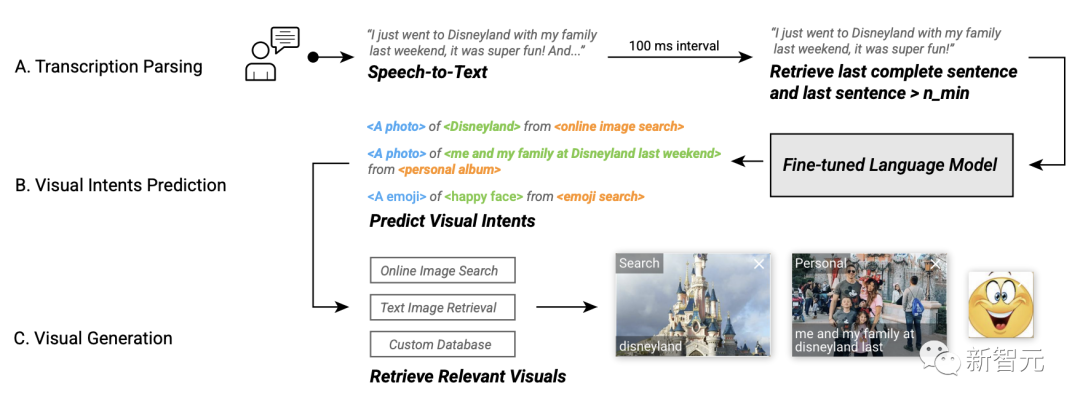
Aliran kerja sistem Kapsyen Visual
Kapsyen Visual menawarkan tiga tahap inisiatif pilihan apabila mengesyorkan visual:
Paparan automatik (inisiatif tinggi): Sistem secara autonomi mencari dan memaparkan visual secara terbuka kepada semua peserta mesyuarat Kesan tanpa interaksi pengguna.
Pengesyoran automatik (inisiatif sederhana): Visual yang disyorkan dipaparkan dalam paparan skrol peribadi, dan kemudian pengguna mengklik pada visual untuk memaparkannya secara terbuka dalam mod ini, Visual sistem disyorkan secara proaktif, tetapi pengguna memutuskan masa dan perkara yang hendak dipaparkan.
Cadangan atas permintaan (inisiatif rendah): Sistem hanya akan mengesyorkan kesan visual selepas pengguna menekan bar ruang.
Penyelidik menilai sistem Kapsyen Visual dalam kajian makmal terkawal (n = 26) dan kajian penggunaan fasa ujian (n = 10), dan peserta mendapati bahawa visual masa nyata membantu Memudahkan perbualan langsung dengan menerangkan konsep yang tidak dikenali, menyelesaikan kekaburan bahasa dan menjadikan perbualan lebih menarik.
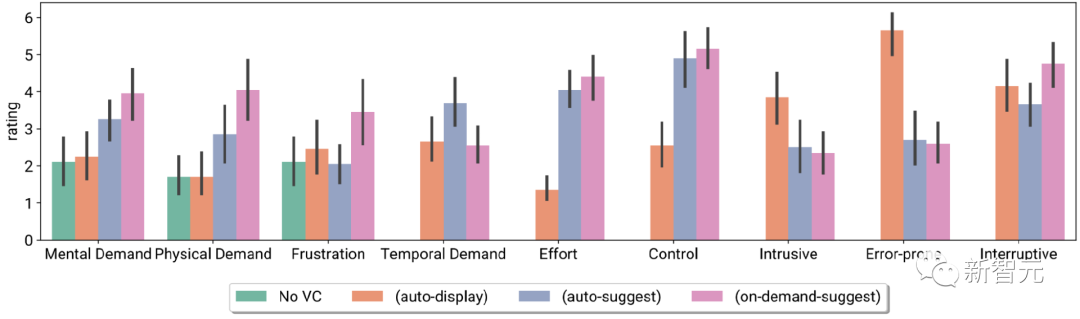
Indeks beban tugas peserta dan penilaian skala Likert, termasuk tiada VC dan tiga inisiatif berbeza VC Seksual
Peserta juga melaporkan pilihan sistem yang berbeza untuk berinteraksi di lapangan, iaitu menggunakan pelbagai peringkat inisiatif VC dalam senario mesyuarat yang berbeza
Atas ialah kandungan terperinci Tiada lagi kebimbangan tentang 'persidangan video' yang memalukan! Google CHI akan mengeluarkan Artifak Visual Captions baharu: biarkan gambar menjadi pembantu sari kata anda. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI