
Rumah >Peranti teknologi >AI >DeepMind menulis semula algoritma pengisihan dengan AI menjejalkan model besar 33B ke dalam GPU pengguna tunggal
DeepMind menulis semula algoritma pengisihan dengan AI menjejalkan model besar 33B ke dalam GPU pengguna tunggal

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-12 18:49:571485semak imbas
目录:
- Algoritma pengisihan yang lebih pantas ditemui menggunakan pembelajaran tetulang mendalam
- Video-LLaMA: Model Bahasa Audio-Visual Ditala Arahan untuk Pemahaman Video
- Penjanaan Adegan Semula Jadi 3D berasaskan Patch daripada Satu Contoh
- Proses Titik Resapan Spatio-temporal
- SpQR: Perwakilan Berkuantiti Jarang untuk Pemampatan Berat LLM Tanpa Rugi
- UniControl: Model Difusi Bersatu untuk Penjanaan Visual Boleh Kawal Di Alam Liar
- FrugalGPT: Cara Menggunakan Model Bahasa Besar Sambil Mengurangkan Kos dan Meningkatkan Prestasi
论文 1:Algoritma pengisihan yang lebih pantas ditemui menggunakan pembelajaran tetulang mendalam
- 作者:Daniel J. Mankowitz 等🎜>
- 论文地址:https://www.nature.com/articles/s41586-023-06004-9
摘要:「通过交换和复制移动,AlphaDev 跳过了一个步骤,以一伯以一种动,AlphaDev是捷径的方式连接项目。」这种前所未见、违反直觉的思想不禁让人回忆起 2016 年那个春天。
七在年七七,年起年那个春天。击败人类世界冠军,如今 AI 又在编程上给Ketua Pegawai Eksekutif Google DeepMind我们已将其开源到主要 C++ 库中供开发人员使用。这只是 AI 提升代码效率进步的开始。」
可一有华序算法,速度快 70%:DeepMind AlphaDev 革新计算基础,每天调用万亿次的库更新了
作者:Hang Zhang 等
- 论文地址:https://arxiv.org/abs/2306.02858
- 摘要:近期近期,夀庭语瞩目的能力。我们能否给大模型装上 “眼睛” 和 “耳朵”,让它能够理解视频,陪它视频,陪它视频,陪它着中中文🎜>
下面两个例子展示了 Video-LLaMA 的视听综合感知能力的视听综合感知能力,介力,介华声视频展开。
推荐:给语言大模型加上综合视听能力,达摩院
论文 3:Penjanaan Pemandangan Semula Jadi 3D berasaskan patch daripada Satu Contoh
- Pengarang: Weiyu Li et al
- Alamat kertas: https://arxiv.org/abs/2304.12670
Abstrak: Pasukan Chen Baoquan Universiti Peking, bersama penyelidik dari Universiti Shandong dan Tencent AI Lab, mencadangkan senario sampel tunggal yang pertama tanpa Kaedah yang boleh menjana pelbagai pemandangan 3D berkualiti tinggi melalui latihan.

Disyorkan: CVPR 2023 | Penjanaan pemandangan 3D: Hasilkan hasil yang pelbagai daripada satu contoh tanpa sebarang latihan rangkaian saraf.
Kertas 4: Proses Titik Resapan Spatio-temporal
- Pengarang: Yuan Yuan et al.
- Alamat kertas: https://arxiv.org/abs/2305.12403
Abstrak: Pusat Penyelidikan Sains Bandar dan Pengkomputeran Jabatan Kejuruteraan Elektronik Universiti Tsinghua baru-baru ini mencadangkan proses titik resapan spatiotemporal, yang menembusi batasan kaedah sedia ada seperti bentuk probabilistik terhad dan persampelan tinggi kos untuk memodelkan proses titik spatiotemporal, dan mencapai yang fleksibel, Model proses titik spatio-temporal yang cekap dan mudah dikira boleh digunakan secara meluas dalam pemodelan dan ramalan peristiwa spatio-temporal seperti bencana alam bandar, kecemasan, dan penduduk. aktiviti, dan menggalakkan pembangunan pintar perancangan dan pengurusan bandar. Jadual berikut menunjukkan kelebihan DSTPP berbanding penyelesaian proses titik sedia ada.
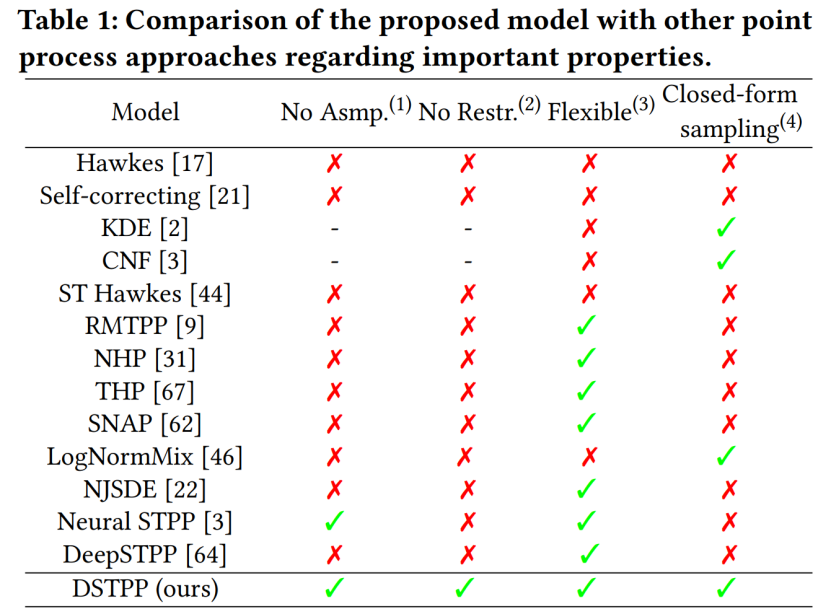
Disyorkan: Bolehkah model penyebaran meramalkan gempa bumi dan jenayah? Penyelidikan terkini oleh pasukan Tsinghua mencadangkan proses titik resapan ruang-masa.
Kertas 5: SpQR: Perwakilan Berkuantiti Jarang untuk Pemampatan Berat LLM Nyaris Tak Rugi
- Pengarang: Tim Dettmers et al
- Alamat kertas: https://arxiv.org/pdf/2306.03078.pdf
Abstrak: Untuk menyelesaikan masalah ketepatan, penyelidik dari University of Washington, ETH Zurich dan institusi lain mencadangkan format pemampatan baharu dan teknologi pengkuantitian SpQR ( Jarang - perwakilan terkuantisasi), mencapai pemampatan hampir-lossless LLM merentas skala model buat kali pertama sambil mencapai tahap mampatan yang serupa dengan kaedah sebelumnya.
SpQR berfungsi dengan mengenal pasti dan mengasingkan pemberat anomali yang menyebabkan ralat pengkuantitian yang sangat besar, menyimpannya dengan ketepatan yang lebih tinggi sambil memampatkan semua pemberat lain Ke kedudukan 3-4, kurang daripada 1% ketepatan relatif kebingungan kerugian dicapai dalam LLaMA dan Falcon LLM. Jalankan LLM parameter 33B pada GPU pengguna 24GB tunggal tanpa sebarang penurunan prestasi sambil 15% lebih pantas. Rajah 3 di bawah menunjukkan seni bina keseluruhan SpQR.
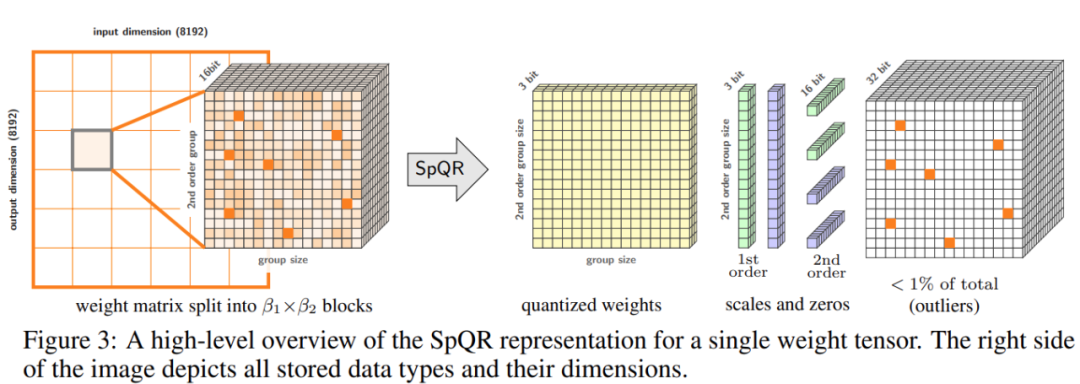
Disyorkan: Letakkan 33 bilion parameter model besar ke dalam GPU pengguna tunggal, 15% pecutan tanpa kehilangan prestasi.
Kertas 6: UniControl: Model Difusi Bersatu untuk Penjanaan Visual Boleh Kawal Di Alam Liar
- Pengarang: Can Qin et al
- Alamat kertas: https://arxiv.org/abs/2305.11147
Abstrak: Dalam artikel ini, penyelidik dari Salesforce AI, Northeastern University dan Stanford University mencadangkan Penyesuai gaya MOE dan Sedar Tugas HyperNet Untuk merealisasikan keupayaan penjanaan keadaan pelbagai mod dalam UniControl. UniControl dilatih dalam sembilan tugas C2I yang berbeza, menunjukkan keupayaan penjanaan visual yang kuat dan keupayaan generalisasi sifar pukulan. Model UniControl terdiri daripada pelbagai tugasan pra-latihan dan tugasan sifar.

Disyorkan: Model bersatu untuk penjanaan imej boleh dikawal berbilang mod ada di sini, dan parameter model serta kod inferens adalah semua sumber terbuka.
Kertas 7: FrugalGPT: Cara Menggunakan Model Bahasa Besar Sambil Mengurangkan Kos dan Meningkatkan Prestasi
- Pengarang: Lingjiao Chen et al
- Alamat kertas: https://arxiv.org/pdf/2305.05176.pdf
Ringkasan: Keseimbangan antara kos dan ketepatan adalah faktor utama dalam membuat keputusan, terutamanya apabila menerima pakai teknologi baharu. Cara menggunakan LLM secara berkesan dan cekap ialah cabaran utama bagi pengamal: jika tugasan itu agak mudah, maka mengagregatkan berbilang respons daripada GPT-J (iaitu 30 kali lebih kecil daripada GPT-3) boleh mencapai prestasi yang serupa dengan GPT-3 , dengan itu mencapai pertukaran kos dan alam sekitar. Walau bagaimanapun, pada tugas yang lebih sukar, prestasi GPT-J mungkin merosot dengan ketara. Oleh itu, pendekatan baharu diperlukan untuk menggunakan LLM secara kos efektif.
Satu kajian baru-baru ini cuba mencadangkan penyelesaian kepada masalah kos ini secara eksperimen menunjukkan bahawa FrugalGPT boleh bersaing dengan prestasi LLM individu terbaik (seperti GPT-4), iaitu. kos dikurangkan sehingga 98%, atau ketepatan LLM individu terbaik dipertingkatkan sebanyak 4% pada kos yang sama. Kajian ini membincangkan tiga strategi pengurangan kos, iaitu penyesuaian segera, penghampiran LLM, dan lata LLM.
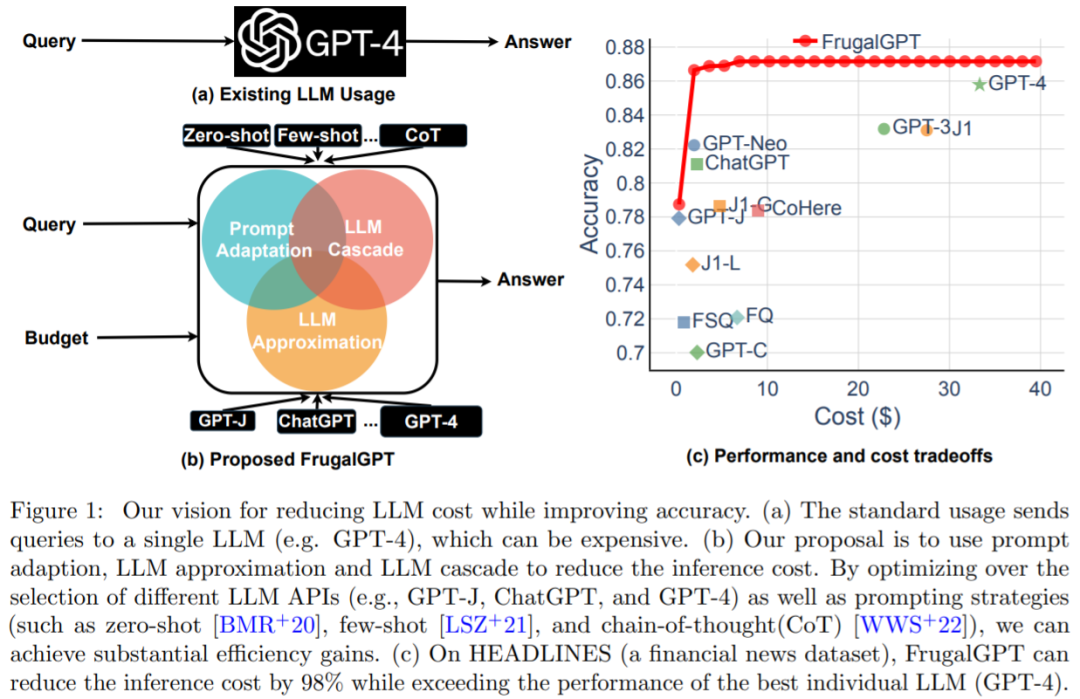
Disyorkan: Penggantian API GPT-4? Prestasi adalah setanding dan kos dikurangkan sebanyak 98%. Stanford mencadangkan FrugalGPT, tetapi penyelidikan itu kontroversi.
Atas ialah kandungan terperinci DeepMind menulis semula algoritma pengisihan dengan AI menjejalkan model besar 33B ke dalam GPU pengguna tunggal. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI