
Rumah >Peranti teknologi >AI >Cambridge, Tencent AI Lab dan lain-lain mencadangkan model bahasa besar PandaGPT: satu model menyatukan enam modaliti
Cambridge, Tencent AI Lab dan lain-lain mencadangkan model bahasa besar PandaGPT: satu model menyatukan enam modaliti

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-05 12:19:51910semak imbas
Penyelidik dari Cambridge, NAIST dan Tencent AI Lab baru-baru ini mengeluarkan hasil penyelidikan yang dipanggil PandaGPT, yang merupakan kaedah untuk menjajarkan dan mengikat model bahasa besar dengan modaliti berbeza untuk mencapai Teknik rentas modaliti untuk kebolehan mengikut arahan. PandaGPT boleh menyelesaikan tugas yang rumit seperti menjana penerangan imej terperinci, menulis cerita daripada video dan menjawab soalan tentang audio. Ia boleh menerima input berbilang modal secara serentak dan menggabungkan semantiknya secara semula jadi.

- Laman utama projek: https://panda-gpt.github.io/
- Kod: https://github.com/yxuansu/PandaGPT
- Kertas: http ://arxiv.org/abs/2305.16355
- Paparan Demo dalam talian: https://huggingface.co/spaces/GMFTBY/PandaGPT
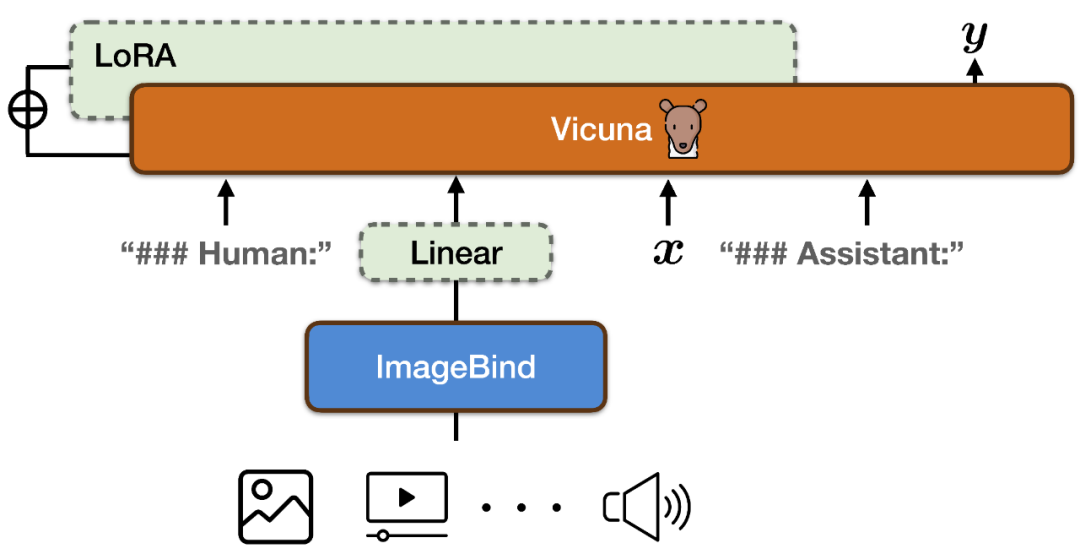
Untuk merealisasikan imej & video, teks, audio, haba peta , peta kedalaman, bacaan IMU, keupayaan mengikut arahan dalam enam mod, PandaGPT menggabungkan pengekod berbilang mod ImageBind dengan model bahasa besar Vicuna (seperti yang ditunjukkan dalam rajah di atas).
Untuk menyelaraskan ruang ciri pengekod berbilang mod ImageBind dan model bahasa besar Vicuna, PandaGPT menggunakan sejumlah 160k arahan bahasa berasaskan imej yang dikeluarkan dengan menggabungkan LLaVa dan Mini-GPT4 Ikut data sebagai data latihan. Setiap contoh latihan terdiri daripada imej dan set pusingan dialog yang sepadan.
Untuk mengelakkan memusnahkan sifat penjajaran pelbagai mod ImageBind itu sendiri dan mengurangkan kos latihan, PandaGPT hanya mengemas kini modul berikut:
- Matriks unjuran linear baharu ditambahkan pada hasil pengekodan ImageBind, dan perwakilan yang dijana oleh ImageBind ditukar dan dimasukkan ke dalam urutan input Vicuna; maklumat kepada berat LoRA modul perhatian Vicuna. Jumlah bilangan parameter kedua-dua menyumbang kira-kira 0.4% daripada parameter Vicuna. Fungsi latihan ialah objektif pemodelan bahasa tradisional. Perlu diingat bahawa semasa proses latihan, hanya berat bahagian output model yang sepadan dikemas kini, dan bahagian input pengguna tidak dikira. Keseluruhan proses latihan mengambil masa lebih kurang 7 jam untuk diselesaikan pada GPU 8×A100 (40G).
- Perlu ditekankan bahawa versi semasa PandaGPT hanya menggunakan data teks imej sejajar untuk latihan, tetapi mewarisi enam keupayaan pemahaman mod pengekod ImageBind ( imej/video , teks, audio, kedalaman, peta haba dan IMU) dan sifat penjajaran antara mereka, membolehkan keupayaan rentas modal antara semua modaliti.
Dalam eksperimen, pengarang menunjukkan keupayaan PandaGPT untuk memahami modaliti yang berbeza, termasuk soalan dan jawapan berasaskan imej/video, penulisan kreatif berasaskan imej/video, berasaskan maklumat visual dan pendengaran Penaakulan dan banyak lagi, berikut ialah beberapa contoh:
Imej:


Berbanding dengan model bahasa berbilang modal yang lain, ciri paling menonjol PandaGPT ialah keupayaannya untuk memahami dan menggabungkan maklumat secara semula jadi daripada modaliti yang berbeza.
Video + Audio:
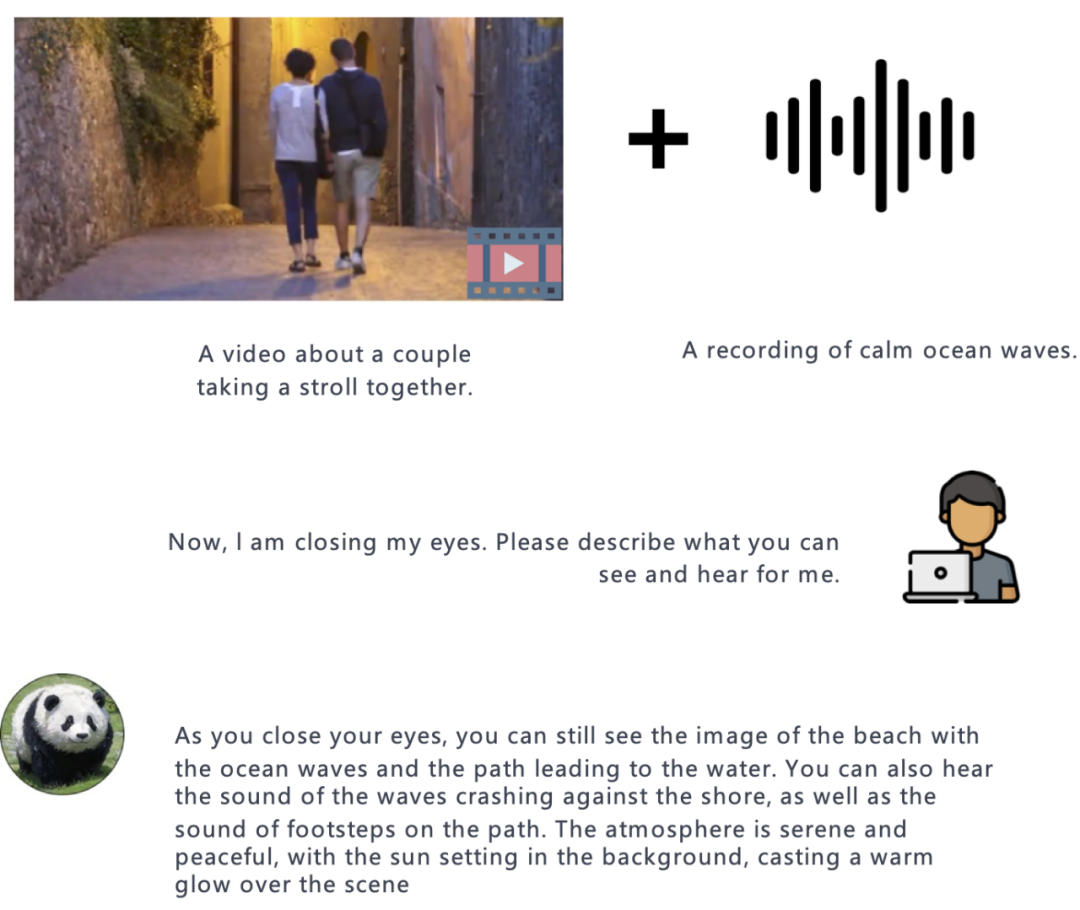
Imej + Audio:

Ringkasan
Pengarang juga merumuskan banyak masalah semasa PandaGPT dan hala tuju pembangunan masa depannya. Walaupun PandaGPT mempunyai keupayaan luar biasa untuk mengendalikan pelbagai modaliti dan gabungannya, masih terdapat banyak cara untuk meningkatkan prestasi PandaGPT dengan lebih baik.
- PandaGPT boleh meningkatkan lagi pemahaman modaliti selain daripada imej dengan menggunakan data penjajaran modal lain, seperti menggunakan data ASR dan TTS untuk modaliti teks audio. pemahaman seni dan kebolehan mengikut arahan.
- Mod selain teks hanya diwakili oleh vektor benam, menyebabkan model bahasa tidak dapat memahami maklumat terperinci model di luar teks. Lebih banyak penyelidikan tentang pengekstrakan ciri berbutir halus, seperti mekanisme perhatian rentas modal, boleh membantu meningkatkan prestasi.
- PandaGPT pada masa ini hanya membenarkan maklumat modal selain teks untuk digunakan sebagai input. Pada masa hadapan, model ini berpotensi untuk menyatukan keseluruhan AIGC ke dalam model yang sama, iaitu, satu model secara serentak boleh menyelesaikan tugasan seperti penjanaan imej & video, sintesis pertuturan dan penjanaan teks.
- Tanda aras baharu diperlukan untuk menilai keupayaan untuk menggabungkan input berbilang modal.
- PandaGPT juga mungkin menunjukkan beberapa kelemahan biasa model bahasa sedia ada, termasuk halusinasi, ketoksikan dan stereotaip.
Akhir sekali, penulis menekankan bahawa PandaGPT hanyalah prototaip penyelidikan dan belum bersedia untuk aplikasi terus dalam persekitaran pengeluaran.
Atas ialah kandungan terperinci Cambridge, Tencent AI Lab dan lain-lain mencadangkan model bahasa besar PandaGPT: satu model menyatukan enam modaliti. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI