
Rumah >pangkalan data >Redis >Bagaimana Redis mempercepatkan Spark
Bagaimana Redis mempercepatkan Spark

- PHPzke hadapan
- 2023-06-03 11:45:361465semak imbas
Apache Spark semakin menjadi model untuk alat pemprosesan data besar generasi akan datang. Dengan meminjam daripada algoritma sumber terbuka dan mengagihkan tugas pemprosesan merentas kluster nod pengiraan, rangka kerja penjanaan Spark dan Hadoop dengan mudah mengatasi kedua-dua jenis analisis data yang boleh mereka lakukan pada satu platform dan dalam kelajuan mereka boleh melaksanakan tugasan ini rangka kerja tradisional. Spark menggunakan memori untuk memproses data, menjadikannya jauh lebih pantas (sehingga 100 kali lebih pantas) daripada Hadoop berasaskan cakera.
Tetapi dengan sedikit bantuan, Spark boleh berlari dengan lebih pantas. Jika anda menggabungkan Spark dengan Redis (teknologi penyimpanan struktur data dalam memori yang popular), anda sekali lagi boleh meningkatkan prestasi tugasan analisis pemprosesan dengan ketara. Ini disebabkan oleh struktur data yang dioptimumkan oleh Redis dan keupayaannya untuk meminimumkan kerumitan dan overhed semasa menjalankan operasi. Menggunakan penyambung untuk menyambung ke struktur data dan API Redis boleh mempercepatkan lagi Spark.
Berapa banyak kelajuan jika Redis digunakan bersama-sama dengan Spark, ternyata pemprosesan data (untuk menganalisis data siri masa yang diterangkan di bawah) adalah lebih pantas daripada Spark hanya menggunakan memori proses atau mematikan -heap cache untuk menyimpan data 45x – Bukan 45% lebih pantas, tetapi penuh 45x lebih pantas
Kepentingan kelajuan transaksi analitik berkembang kerana banyak syarikat perlu mendayakan analitik sepantas transaksi perniagaan. Memandangkan semakin banyak keputusan menjadi automatik, analitis yang diperlukan untuk memacu keputusan tersebut harus berlaku dalam masa nyata. Apache Spark ialah rangka kerja pemprosesan data tujuan am yang sangat baik walaupun ia tidak sepenuhnya masa nyata, ia merupakan satu langkah besar ke arah menjadikan data berguna dengan cara yang lebih tepat pada masanya.
Spark menggunakan Resilient Distributed Datasets (RDDs), yang boleh disimpan dalam memori yang tidak menentu atau dalam sistem storan berterusan seperti HDFS. Semua RDD yang diedarkan merentasi nod gugusan Spark kekal tidak berubah, tetapi RDD lain boleh dibuat melalui operasi transformasi.
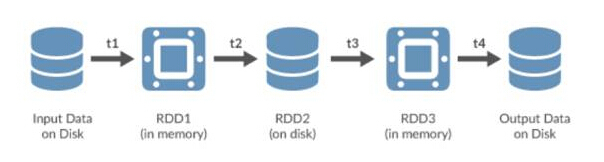
Spark RDD
RDD ialah objek abstrak yang penting dalam Spark. Mereka mewakili cara bertoleransi kesalahan untuk membentangkan data dengan cekap kepada proses berulang. Menggunakan pemprosesan dalam memori bermakna masa pemprosesan akan dikurangkan mengikut urutan magnitud berbanding menggunakan HDFS dan MapReduce.
Redis direka khas untuk prestasi tinggi. Kependaman submilisaat ialah hasil daripada struktur data yang dioptimumkan yang meningkatkan kecekapan dengan membenarkan operasi dilakukan berhampiran dengan tempat data disimpan. Struktur data ini bukan sahaja menggunakan memori dengan cekap dan mengurangkan kerumitan aplikasi, tetapi juga mengurangkan overhed rangkaian, penggunaan lebar jalur dan masa pemprosesan. Redis menyokong berbilang struktur data, termasuk rentetan, set, set diisih, cincang, bitmap, hiperloglog dan indeks geospatial. Struktur data Redis adalah seperti batu bata Lego, menyediakan pembangun saluran mudah untuk melaksanakan fungsi yang kompleks.
Untuk menunjukkan secara visual cara struktur data ini dapat memudahkan masa pemprosesan dan kerumitan aplikasi, kami juga boleh mengambil struktur data set tersusun (Set Diisih) sebagai contoh. Set tertib pada asasnya ialah set ahli yang dipesan mengikut skor.

Koleksi diisih Redis
Anda boleh menyimpan banyak jenis data di sini dan ia diisih secara automatik mengikut markah. Jenis data biasa yang disimpan dalam koleksi tersusun termasuk data siri masa seperti item (mengikut harga), nama produk (mengikut kuantiti), harga saham dan bacaan penderia seperti cap masa.
Pesona koleksi yang dipesan terletak pada operasi terbina dalam Redis, yang membolehkan pertanyaan julat, persilangan berbilang koleksi yang dipesan, mendapatkan semula mengikut tahap dan skor ahli, dan lebih banyak urus niaga dilaksanakan dengan mudah dan dengan kelajuan maksimum juga boleh dilaksanakan pada skala. Bukan sahaja operasi terbina dalam menyimpan kod yang perlu ditulis, tetapi melaksanakan operasi dalam memori mengurangkan kependaman rangkaian dan menjimatkan lebar jalur, membolehkan daya pemprosesan tinggi dengan kependaman sub-milisaat. Jika set diisih digunakan untuk menganalisis data siri masa, peningkatan prestasi selalunya boleh dicapai dengan tertib magnitud berbanding sistem storan kunci/nilai dalam ingatan lain atau pangkalan data berasaskan cakera.
Penyambung Spark-Redis dibangunkan oleh pasukan Redis untuk meningkatkan keupayaan analisis Spark. Pakej ini membolehkan Spark menggunakan Redis sebagai salah satu sumber datanya. Melalui penyambung ini, Spark boleh mengakses secara langsung struktur data Redis, dengan itu meningkatkan prestasi pelbagai jenis analisis dengan ketara.

Spark Redis Connector
Untuk menunjukkan faedah yang dibawa kepada Spark, pasukan Redis memutuskan untuk menggunakan beberapa senario berbeza Laksanakan potongan masa (julat) pertanyaan untuk membandingkan analisis siri masa secara mendatar dalam Spark. Senario ini termasuk: Spark menyimpan semua data dalam memori dalam timbunan, Spark menggunakan Tachyon sebagai cache luar timbunan, Spark menggunakan HDFS dan gabungan Spark dan Redis.
Pasukan Redis menggunakan pakej siri masa Cloudera's Spark untuk membina pakej siri masa Spark-Redis yang menggunakan koleksi pesanan Redis untuk mempercepatkan analisis siri masa. Selain menyediakan semua struktur data yang membolehkan Spark mengakses Redis, pakej ini juga melaksanakan dua tugas tambahan
Secara automatik memastikan bahawa nod Redis konsisten dengan gugusan Spark, memastikan setiap nod Spark menggunakan data Redis tempatan, sekali gus mengoptimumkan kependaman.
Sepadukan dengan kerangka data Spark dan API sumber data untuk menukar pertanyaan SQL Spark secara automatik kepada mekanisme mendapatkan semula data yang paling berkesan dalam Redis.
Ringkasnya, ini bermakna pengguna tidak perlu risau tentang konsistensi operasi antara Spark dan Redis dan boleh terus menggunakan Spark SQL untuk analisis, sambil meningkatkan prestasi pertanyaan dengan hebat.
Data siri masa yang digunakan dalam perbandingan mendatar ini termasuk: data kewangan yang dijana secara rawak dan 1024 saham setiap hari selama 32 tahun. Setiap saham diwakili oleh set pesanannya sendiri, skor ialah tarikh, dan ahli data termasuk harga pembukaan, harga terakhir, harga terakhir, harga tutup, volum dagangan dan harga tutup larasan. Imej berikut menggambarkan perwakilan data dalam set diisih Redis yang digunakan untuk analisis Spark:
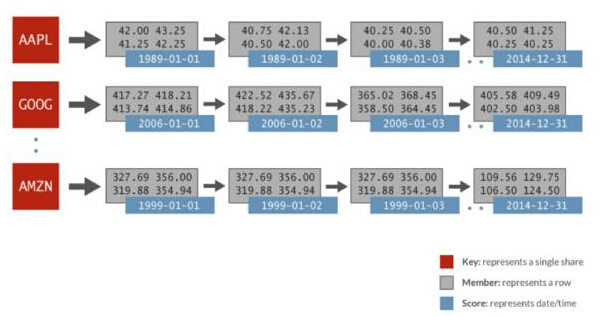
siri masa Spark Redis Dalam contoh, untuk set tertib AAPL, terdapat ialah markah yang diwakili untuk setiap hari (1989-01-01), dan berbilang nilai untuk sepanjang hari diwakili sebagai baris yang berkaitan. Hanya gunakan perintah ZRANGEBYSCORE yang mudah dalam Redis untuk melakukan ini: dapatkan semua nilai untuk kepingan masa tertentu, dan oleh itu dapatkan semua harga saham dalam julat tarikh yang ditentukan. Redis boleh melaksanakan jenis pertanyaan ini lebih pantas daripada sistem storan kunci/nilai lain, sehingga 100 kali lebih pantas.
Perbandingan sebelah menyebelah ini mengesahkan peningkatan prestasi. Telah didapati bahawa Spark menggunakan Redis boleh melakukan pertanyaan hirisan masa 135 kali lebih pantas daripada Spark menggunakan HDFS, dan 45 kali lebih pantas daripada Spark menggunakan memori atas (proses) atau Spark menggunakan Tachyon sebagai cache luar timbunan. Angka di bawah menunjukkan purata masa pelaksanaan berbanding untuk senario yang berbeza: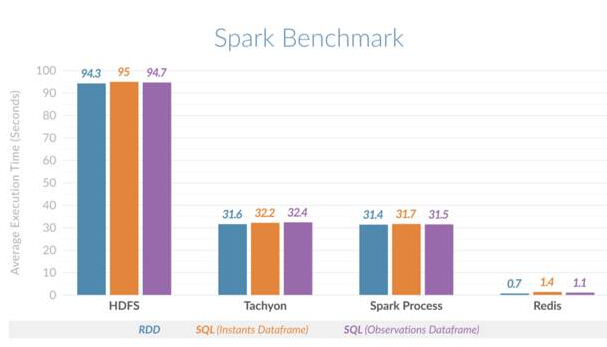 Perbandingan Mendatar Spark Redis
Perbandingan Mendatar Spark Redis
Panduan ini akan dibuat langkah demi langkah langkah Bimbing anda untuk memasang kumpulan Spark standard dan pakej Spark-Redis. Melalui contoh pengiraan perkataan yang mudah, ia menunjukkan cara mengintegrasikan penggunaan Spark dan Redis. Selepas anda mencuba pakej Spark dan Spark-Redis, anda boleh meneroka lebih banyak senario yang menggunakan struktur data Redis yang lain.
Walaupun set yang dipesan sangat sesuai untuk data siri masa, struktur data Redis yang lain seperti set, senarai dan indeks geospatial boleh memperkayakan lagi analitik Spark. Bayangkan ini: proses Spark cuba memikirkan kawasan mana yang sesuai untuk melancarkan produk baharu, dengan mengambil kira faktor seperti pilihan orang ramai dan jarak dari pusat bandar untuk mengoptimumkan kesan pelancaran. Bayangkan bagaimana struktur data seperti indeks geospatial dan koleksi dengan keupayaan analitik terbina dalam boleh mempercepatkan proses ini dengan ketara. Kombinasi Spark-Redis mempunyai prospek aplikasi yang hebat. Spark menyediakan pelbagai keupayaan analisis, termasuk SQL, pembelajaran mesin, pengkomputeran graf dan Spark Streaming. Menggunakan keupayaan pemprosesan dalam memori Spark hanya membawa anda ke skala tertentu. Walau bagaimanapun, dengan Redis, anda boleh melangkah lebih jauh: bukan sahaja anda boleh meningkatkan prestasi dengan menggunakan struktur data Redis, tetapi anda juga boleh mengembangkan Spark dengan lebih mudah, iaitu, dengan menggunakan sepenuhnya mekanisme penyimpanan data memori teragih yang disediakan oleh Redis untuk memproses ratusan Ribu rekod, malah berbilion rekod. Contoh siri masa hanyalah permulaan. Menggunakan struktur data Redis untuk pembelajaran mesin dan analisis graf juga dijangka membawa manfaat masa pelaksanaan yang ketara kepada beban kerja ini.Atas ialah kandungan terperinci Bagaimana Redis mempercepatkan Spark. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!