
Rumah >Peranti teknologi >AI >Rahsia 'shell' ChatGPT domestik kini telah ditemui
Rahsia 'shell' ChatGPT domestik kini telah ditemui

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-30 18:09:071570semak imbas

“Iflytek adalah penutup untuk ChatGPT!” “Baidu Wenxin adalah penutup untuk Stable Diffusion!” “Model besar SenseTime sebenarnya adalah plagiarisme!”…
Bukan sekali dua dunia luar mempersoalkan model besar keluaran dalam negara.
Penjelasan untuk fenomena ini oleh orang dalam industri ialah terdapat kekurangan sebenar set data Cina berkualiti tinggi Apabila melatih model, hanya boleh menggunakan set data beranotasi bahasa asing yang dibeli. untuk "bertindak sebagai bantuan asing" . Jika set data yang digunakan untuk latihan ranap, hasil yang serupa akan dijana, yang membawa kepada insiden sendiri.
Antara kaedah lain, menggunakan model besar sedia ada untuk membantu dalam menjana data latihan terdedah kepada pembersihan data yang tidak mencukupi.
Industri telah membentuk konsensus secara beransur-ansur:
Jalan ke AGI akan terus mengemukakan keperluan yang sangat tinggi untuk kuantiti data dan kualiti data.
Situasi semasa memerlukan dalam 2 bulan lalu, banyak pasukan domestik mempunyai set data Cina sumber terbuka berturut-turut Selain set data umum, mereka juga disasarkan pada pengaturcaraan, perubatan, dsb. Chuiyu juga mempunyai set data Cina sumber terbuka khusus yang dikeluarkan.
Set data berkualiti tinggi tersedia tetapi sedikit
Penemuan baharu dalam model besar sangat bergantung pada set data berkualiti tinggi dan kaya.
Menurut "Undang-undang Penskalaan untuk Model Bahasa Neural" OpenAI, undang-undang penskalaan diikuti oleh model besar (undang-undang penskalaan) Dapat dilihat bahawa peningkatan jumlah data latihan secara bebas boleh menjadikan model pra-latihan Kesannya menjadi lebih baik.
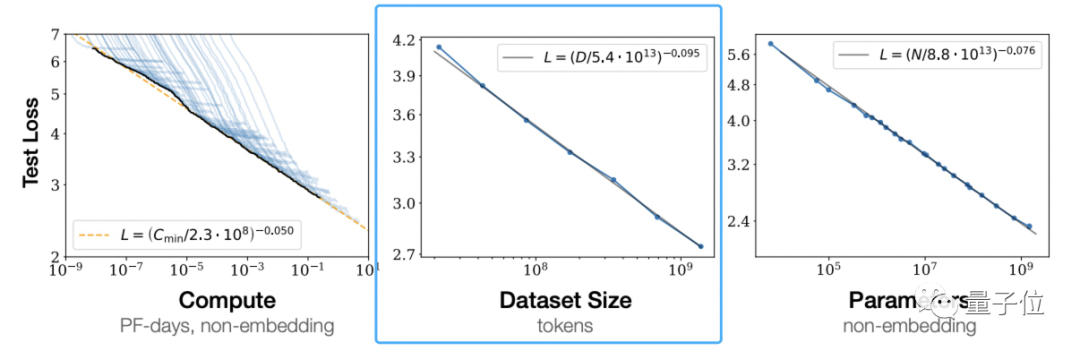
Ini bukan pendapat OpenAI.
DeepMind juga menegaskan dalam kertas model Chinchilla bahawa kebanyakan model besar sebelum ini tidak dilatih dengan secukupnya, dan juga mencadangkan formula latihan optimum, yang telah menjadi piawaian yang diiktiraf dalam industri.
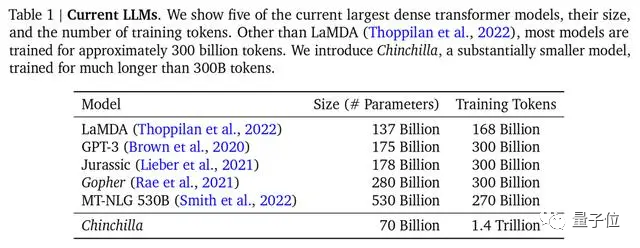
△Arus perdana Untuk model besar, Chinchilla mempunyai parameter paling sedikit tetapi latihan paling mencukupi
Walau bagaimanapun, set data arus perdana yang digunakan untuk latihan terutamanya dalam bahasa Inggeris, seperti Common Crawl, BooksCorpus, WiKipedia, ROOT , dsb., yang merupakan data Common Crawl Cina yang paling popular hanya menyumbang 4.8%.
Apakah keadaan set data Cina?
Tiada set data awam - ini disahkan oleh Qubits daripada Zhou Ming, pengasas dan Ketua Pegawai Eksekutif Lanzhou Technology dan salah seorang warga China yang paling berjaya dalam bidang NLP hari ini - seperti set data entiti yang dinamakan MSRA-NER, Weibo -NER, dsb., serta CMRC2018, CMRC2019, ExpMRC2022, dsb. yang boleh didapati di GitHub, tetapi jumlah keseluruhannya ialah penurunan dalam baldi berbanding set data bahasa Inggeris.
Selain itu, sesetengah daripada mereka sudah lama, dan mereka mungkin tidak mengetahui konsep penyelidikan NLP terkini (penyelidikan berkaitan konsep baharu hanya muncul dalam bahasa Inggeris di arXiv).
Walaupun set data Cina berkualiti tinggi wujud, bilangannya kecil dan menyusahkan untuk digunakan. Ini adalah situasi yang teruk yang perlu dihadapi oleh semua pasukan yang menjalankan penyelidikan model berskala besar. Pada forum Jabatan Elektronik Universiti Tsinghua sebelum ini, Profesor Tang Jie dari Jabatan Sains Komputer di Universiti Tsinghua berkongsi bahawa semasa menyediakan data untuk pra-latihan model 100 bilion ChatGLM-130B, beliau berhadapan dengan situasi yang selepas membersihkan data Cina, jumlah yang boleh digunakan adalah kurang daripada 2TB.
Adalah mendesak untuk menyelesaikan kekurangan set data berkualiti tinggi di dunia China.
Salah satu penyelesaian yang berkesan ialah menggunakan data Bahasa Inggeris secara langsung untuk melatih model besar.
Dalam senarai Arena Chatbot arena tanpa nama berskala besar yang dinilai oleh pemain manusia, GPT-3.5 menduduki tempat kedua dalam kedudukan bukan bahasa Inggeris (yang pertama ialah GPT-4) . Anda harus tahu bahawa 96% daripada data latihan GPT-3.5 adalah dalam bahasa Inggeris Tidak termasuk bahasa lain, jumlah data Cina yang digunakan untuk latihan adalah sangat kecil sehingga ia boleh dikira dengan "n perseribu".
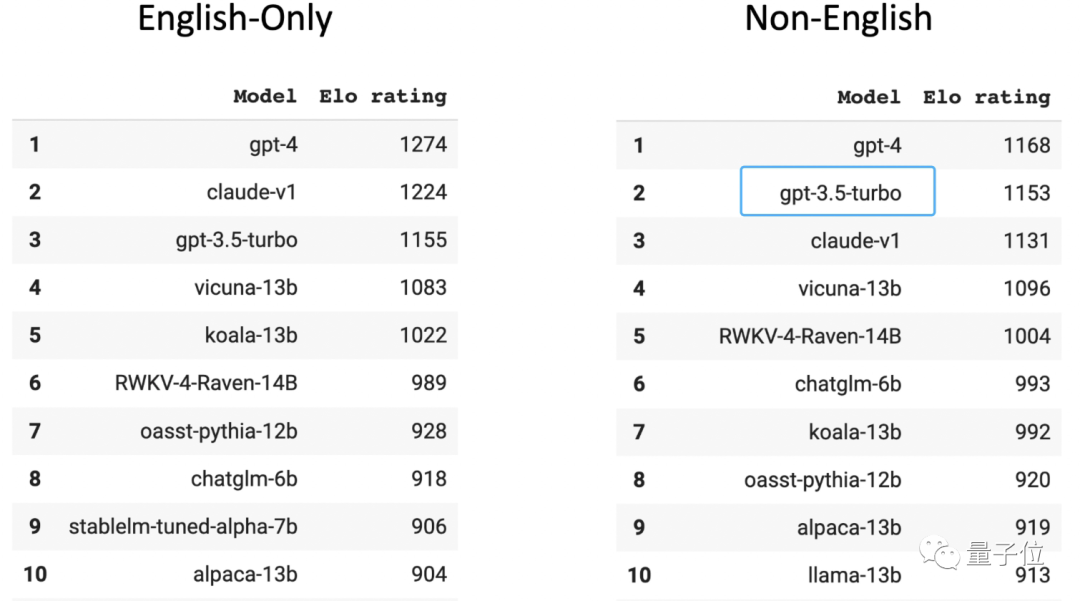
Seorang calon PhD dalam pasukan besar berkaitan model di salah satu daripada tiga universiti tempatan terbaik mendedahkan bahawa jika kaedah ini diguna pakai dan ia tidak terlalu menyusahkan, anda boleh sambungkan perisian terjemahan kepada model untuk menterjemah semua bahasa Semua ditukar kepada bahasa Inggeris, dan kemudian output model ditukar kepada bahasa Cina, dan kemudian dikembalikan kepada pengguna.
Walau bagaimanapun, model besar yang diberi makan dengan cara ini sentiasa berfikir bahasa Inggeris Apabila menghadapi kandungan dengan ciri bahasa Cina seperti penulisan semula simpulan bahasa, pemahaman bahasa sehari-hari dan penulisan semula artikel, ia selalunya tidak dikendalikan dengan baik, mengakibatkan kesilapan terjemahan. atau potensi penyelewengan budaya.
Penyelesaian lain ialah mengumpul, membersihkan dan melabel korpus Cina, membuat set data Cina berkualiti tinggi baharu dan membekalkannya kepada model besar.
Set data sumber terbuka sedang mengumpulkan kayu api
Setelah melihat keadaan semasa, banyak pasukan model domestik yang besar memutuskan untuk mengambil jalan kedua dan mula menggunakan pangkalan data peribadi untuk mencipta set data.
Baidu mempunyai data ekologi kandungan, Tencent mempunyai data akaun awam, Zhihu mempunyai data Soal Jawab, dan Alibaba mempunyai data e-dagang dan logistik.
Dengan data peribadi terkumpul yang berbeza, adalah mungkin untuk mewujudkan halangan kelebihan teras dalam senario dan medan tertentu Pengumpulan, pengisihan, penapisan, pembersihan dan pelabelan yang ketat bagi data ini boleh memastikan keberkesanan dan ketepatan model terlatih. .
Dan pasukan model besar yang kelebihan data peribadinya tidak begitu jelas mula merangkak data merentasi seluruh rangkaian (dapat dijangka bahawa jumlah data perangkak akan menjadi sangat besar).
Untuk membina model besar Pangu, Huawei merangkak 80TB teks daripada Internet dan akhirnya membersihkannya ke dalam set data Cina 1TB yang digunakan untuk latihan Inspur Source 1.0 mencapai 5000GB (berbanding dengan Set data latihan model GPT3 sebanyak 570GB); model besar Tianhe Tianyuan yang dikeluarkan baru-baru ini juga merupakan hasil pengumpulan data web global Pusat Pengkomputeran Tianjin, dan kemasukan pelbagai data latihan sumber terbuka dan set data lapangan profesional.
Pada masa yang sama, dalam dua bulan yang lalu, terdapat tergesa-gesa untuk mengumpulkan lebih banyak kayu api untuk set data Cina -
Banyak pasukan telah berturut-turut mengeluarkan set data Cina sumber terbuka untuk membuat untuk set data sumber terbuka China semasa kekurangan atau ketidakseimbangan.
Sesetengah daripadanya disusun seperti berikut:
- CodeGPT: Set data perbualan berkaitan kod yang dijana oleh GPT dan GPT, institusi di belakangnya ialah Fudan Universiti.
- CBook-150k: Koleksi buku korpus Cina, termasuk kaedah muat turun dan pengekstrakan 150,000 buku Cina, meliputi banyak bidang seperti kemanusiaan, pendidikan, teknologi, ketenteraan, politik, dll.; organisasi di belakangnya ialah Universiti Fudan.
- RefGPT: Untuk mengelakkan kos anotasi manual yang mahal, kami mencadangkan kaedah untuk menjana dialog berasaskan fakta secara automatik dan mendedahkan sebahagian daripada data kami, termasuk 50,000 item Berbilang pusingan dialog dalam bahasa Cina di belakangnya adalah pengamal NLP dari Universiti Shanghai Jiao Tong, Universiti Politeknik Hong Kong dan institusi lain.
- COIG: Nama penuh ialah "Set Data Arahan Terbuka Bersama China Ia adalah korpus penalaan arahan yang lebih besar dan lebih pelbagai, dan kualitinya dipastikan dengan pengesahan manual; institusi termasuk Institut Kecerdasan Buatan Beijing, Universiti Sheffield, Universiti Michigan, Kolej Dartmouth, Universiti Zhejiang, Universiti Beihang dan Universiti Carnegie Mellon.
- Sumber Undang-undang Cina yang Hebat: Sumber data undang-undang China, dikumpul dan dianjurkan oleh Universiti Shanghai Jiao Tong.
- Huatuo: Set data arahan perubatan Cina yang dibina melalui graf pengetahuan perubatan dan API GPT3.5 Atas dasar ini, LLaMA telah diperhalusi untuk dipertingkatkan prestasi arahan kesan soal jawab LLaMA dalam bidang perubatan sumber projek adalah Institut Teknologi Harbin.
- Baize: Gunakan sebilangan kecil "soalan benih" untuk membenarkan ChatGPT bersembang dengan dirinya sendiri dan secara automatik mengumpulkannya menjadi data perbualan berbilang pusingan berkualiti tinggi set; University of California, San Diego (UCSD)Pasukan yang bekerja dengan Universiti Sun Yat-sen dan MSRA telah menjadikan set data yang dikumpul menggunakan kaedah ini sumber terbuka.
Apabila lebih banyak set data Cina sumber terbuka dan dibawa ke perhatian, sikap industri adalah satu sikap yang dialu-alukan dan kegembiraan. Sebagai contoh, sikap yang dinyatakan oleh Zhang Peng, pengasas dan Ketua Pegawai Eksekutif Zhipu AI:
Data Cina berkualiti tinggi hanya disembunyikan di bilik kerja Sekarang setelah semua orang menyedari masalah ini, secara semula jadi menjadi jawapan yang sepadan, seperti data sumber terbuka.
Ringkasnya, ia berkembang ke arah yang baik, bukan?
Perlu diingat bahawa selain data pra-latihan, data maklum balas manusia juga amat diperlukan pada peringkat ini.
Contoh sedia ada ada di hadapan kita:
Berbanding dengan GPT-3, kelebihan penting tindanan ChatGPT ialah menggunakan RLHF (Pembelajaran Peneguhan Maklum Balas Manusia) untuk menjana Penyempurnaan data berlabel berkualiti tinggi membolehkan pembangunan model besar yang sejajar dengan niat manusia.
Cara paling langsung untuk memberikan maklum balas manusia ialah memberitahu pembantu AI "jawapan anda salah", atau suka atau tidak suka terus di sebelah balasan yang dijana oleh pembantu AI.

Apabila anda menggunakannya dahulu, anda boleh mengumpul gelombang maklum balas pengguna dan membiarkan bola salji bermula Ini adalah salah satu sebab mengapa semua orang tergesa-gesa mengeluarkan model besar.
Kini, produk seperti ChatGPT domestik, daripada Baidu Wenxinyiyan, Fudan MOSS hingga Zhipu ChatGLM, semuanya menyediakan pilihan maklum balas.
Tetapi pada pandangan kebanyakan pengguna, atribut yang paling penting bagi produk model besar ini ialah "mainan".
Apabila menghadapi jawapan yang salah atau tidak memuaskan, anda akan memilih untuk menutup antara muka dialog secara terus, yang tidak kondusif untuk pengumpulan maklum balas manusia oleh model besar di belakangnya.
Atas ialah kandungan terperinci Rahsia 'shell' ChatGPT domestik kini telah ditemui. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI