
Rumah >pangkalan data >tutorial mysql >Bagaimana untuk mengindeks medan rentetan dalam MySQL
Bagaimana untuk mengindeks medan rentetan dalam MySQL

- 王林ke hadapan
- 2023-05-28 14:38:522629semak imbas
Anggapkan bahawa anda sedang menyelenggara sistem yang menyokong log masuk e-mel Jadual pengguna ditakrifkan seperti ini:
create table SUser( ID bigint unsigned primary key, email varchar(64), ... )engine=innodb;
Memandangkan anda perlu menggunakan e-mel untuk log masuk, mesti ada pernyataan yang serupa dengan ini dalam kod perniagaan:
select f1, f2 from SUser where email='xxx';
Jika tiada indeks pada medan e-mel, maka penyata ini hanya boleh melakukan imbasan jadual penuh.
1) Bolehkah saya membina indeks pada medan alamat e-mel?
MySQL menyokong indeks awalan, anda boleh mentakrifkan sebahagian daripada rentetan sebagai indeks
2) Jika anda cipta indeks Apakah yang berlaku jika pernyataan tidak menyatakan panjang awalan?
Indeks akan mengandungi keseluruhan rentetan
3) Bolehkah anda berikan contoh untuk menggambarkan?
alter table SUser add index index1(email); 或 alter table SUser add index index2(email(6));
indeks1 mengandungi keseluruhan rentetan setiap rekod
indeks2 mengandungi keseluruhan rentetan setiap rekod 6 bait
4) Apakah perbezaan dalam struktur data dan storan antara dua takrifan berbeza ini?
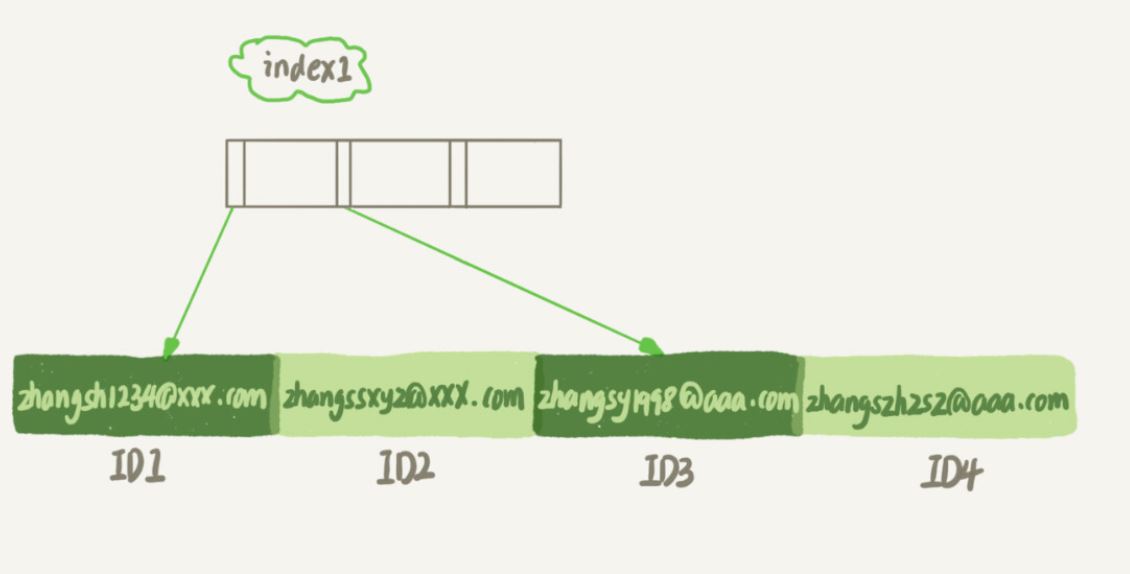
Adalah jelas bahawa struktur indeks e-mel(6) akan menduduki lebih sedikit ruang
5) Apakah kelemahan struktur indeks e-mel(6) ini?
boleh meningkatkan bilangan imbasan rekod tambahan
6) Pernyataan berikut, dalam dua definisi indeks ini Bagaimana adakah perkara berikut dilaksanakan?
select id,name,email from SUser where email='zhangssxyz@xxx.com';
indeks1 (iaitu, struktur indeks keseluruhan rentetan e-mel), urutan pelaksanaan
Cari nilai indeks yang memuaskan daripada pokok indeks index1 ialah ’zhangssxyz@xxx Untuk rekod .com’ ini, dapatkan nilai ID2
Kembali ke jadual dan cari baris yang nilai kunci utamanya ialah ID2, nilai itu nilai e-mel adalah betul, dan tambahkan baris rekod ini Set keputusan
meneruskan ke rekod seterusnya dalam pepohon indeks, dan mendapati bahawa keadaan e-mel='zhangssxyz@xxx; .com&rsquo tidak lagi dipenuhi dan gelung berakhir.
Dalam proses ini, anda hanya perlu mendapatkan data sekali sahaja daripada indeks kunci utama, jadi sistem berpendapat bahawa hanya satu baris telah diimbas.
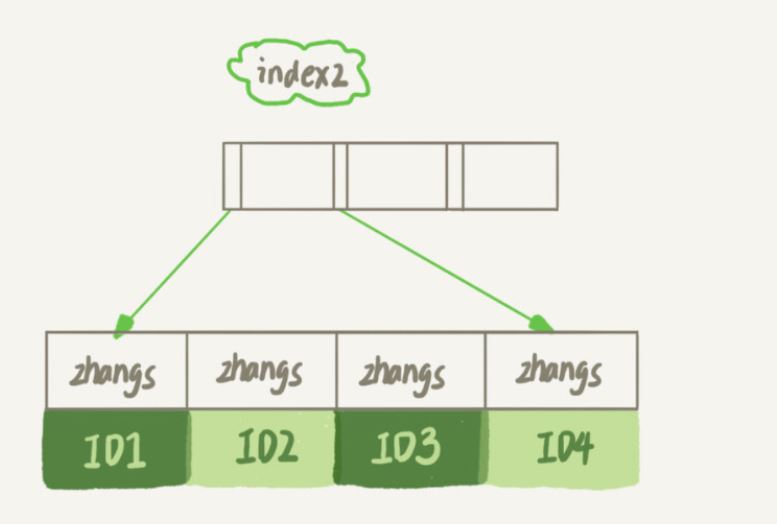
indeks2 (iaitu e-mel(6) struktur indeks), urutan pelaksanaan
Cari rekod yang memenuhi nilai indeks ’zhangs&rsquo daripada pokok indeks2, dan cari yang pertama ialah ID1;
Pergi ke kunci utama dan cari baris yang nilai kunci utamanya ialah ID1. Ia dinilai bahawa nilai e-mel bukan ’zhangssxyz@. xxx.com’, dan baris rekod ini dibuang;
Dapatkan rekod seterusnya di lokasi yang baru ditemui pada index2 dan ketahui bahawa ia masih "zhangs". , kemudian dapatkan keseluruhan baris pada indeks ID dan hakim, kali ini nilainya, tambahkan baris rekod ini pada set hasil; yang diperoleh pada idxe2 bukan ’zhangs’ dan gelung berakhir.
Dalam proses ini, indeks kunci utama perlu diambil sebanyak 4 kali, iaitu 4 baris diimbas.
Menggunakan indeks awalan boleh menyebabkan pernyataan pertanyaan membaca data lebih banyak kali.
- 8) Adakah indeks awalan benar-benar tidak berguna?
Jika indeks2 yang kami takrifkan bukan e-mel(6) tetapi e-mel(7), maka hanya ada satu rekod yang memenuhi awalan ’zhangss’, dan ID2 boleh ditemui terus , mengimbas hanya satu baris dan ia berakhir.
- 9) Jadi apakah langkah berjaga-jaga untuk menggunakan indeks awalan?
Pemilihan panjang adalah munasabah
- 10) Apabila saya ingin mencipta indeks awalan untuk rentetan, saya tahu apa yang perlu saya lakukan Apakah panjang indeks awalan yang harus digunakan?
Kira berapa banyak nilai berbeza yang terdapat pada indeks untuk menentukan berapa lama awalan sepatutnya.
- 11) Bagaimana untuk mengira berapa banyak nilai berbeza yang terdapat pada indeks?
select count(distinct email) as L from SUser;
12) Apakah yang perlu kita lakukan seterusnya selepas mendapat berapa banyak nilai berbeza yang sepadan dengan indeks?
Pilih awalan yang berbeza panjang seterusnya untuk melihat nilai ini
select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7, from SUser;
Kemudian, di antara L4~L7, cari A pertama nilai tidak kurang daripada L * 95% bermakna lebih daripada 95% data boleh didapati melalui indeks ini.
- 13) Apakah kesan indeks awalan terhadap indeks penutup?
Pernyataan SQL berikut: select id,email from SUser where email='zhangssxyz@xxx.com';
Berbanding dengan pernyataan SQL
select id,name,email from SUser where email='zhangssxyz@xxx.com';
dalam contoh sebelumnya, pernyataan pertama hanya memerlukan pengembalian id dan e-mel padang.
Jika anda menggunakan index1 (iaitu, struktur indeks keseluruhan rentetan e-mel), anda boleh mendapatkan ID dengan menyemak e-mel Kemudian tidak perlu memulangkan jadual. Ini adalah indeks penutup.
用 index2(即 email(6) 索引结构)的话,就不得不回到 ID 索引再去判断 email 字段的值。
14)那我把index2 的定义修改为 email(18) 的前缀索引不就行了?
这个18是你自己定义的,系统不知道18这个长度是否已经大于我的email长度,所以它还是会回表去查一下验证。
总而言之:使用前缀索引就用不上覆盖索引对查询性能的优化了
针对类似于邮箱这样的字段,使用前缀索引可能会产生不错的效果。但是,遇到身份证这种前缀的区分度不够好的情况时,我们要怎么办呢?
索引选取的要更长一些。
但是所以越长的话,占的磁盘空间更大,相同的一页能放下的索引值就变少了,反而会影响查询效率。
16)如果我们能够确定业务需求里面只有按照身份证进行等值查询的需求,还有没有别的处理方法呢?
-
既然正过来相同的多,那我就把它倒过来存。查询时候这样查
select field_list from t where id_card = reverse('input_id_card_string');
使用 的时候用count(distinct) 方法去做个验证
-
使用 hash 字段。在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
alter table t add id_card_crc int unsigned, add index(id_card_crc);
新记录插入时必须使用 crc32() 函数生成校验码,并填入新字段中。由于校验码可能存在冲突,也就是说两个不同的身份证号通过 crc32() 函数得到的结果可能是相同的,所以你的查询语句 where 部分要判断 id_card 的值是否精确相同。
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
这样,索引的长度变成了 4 个字节(int类型),比原来小了很多
17)使用倒序存储和使用 hash 字段这两种方法有什么异同点?
相同点:都不支持范围查询
倒序存储的字段上创建的索引是按照倒序字符串的方式排序的,已经没有办法利用索引方式查出身份证号码在[ID_X, ID_Y]的所有市民了。同样地,hash 字段的方式也只能支持等值查询。
区别
从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,而 hash 字段方法需要增加一个字段。当然,倒序存储方式使用 4 个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个 hash 字段也差不多抵消了。
在 CPU 消耗方面,倒序方式每次写和读的时候,都需要额外调用一次 reverse 函数,而 hash 字段的方式需要额外调用一次 crc32() 函数。以仅考虑这两个函数的计算复杂度为前提,reverse 函数对 CPU 资源的额外消耗将较少。
就查询性能而言,采用哈希字段方式的查询更具可靠性。虽然crc32算法不可避免地存在冲突的风险,但这种风险极其微小,因此我们可以认为查询时平均扫描行数接近于1。使用倒序存储方式仍然需要使用前缀索引来进行扫描,因此会增加扫描的行数。
案例:如果你在维护一个学校的学生信息数据库,学生登录名的统一格式是”学号 @gmail.com", 而学号的规则是:十五位的数字,其中前三位是所在城市编号、第四到第六位是学校编号、第七位到第十位是入学年份、最后五位是顺序编号。
学生必须输入正确的登录名和密码,方可继续使用系统。如果只考虑登录验证这个行为,你会如何为登录名设计索引?
如果一个学校每年预计2万新生,50年才100万记录,如果直接使用全字段索引,可以节省多少存储空间?。除非遇到超大规模数据,否则不需要使用后两种方法,从而避免了开发转换和限制风险
在实际操作中,只需对所有字段进行索引,一个学校的数据库数据量和查询负担不会变得很大。 如果单从优化数据表的角度: \1. 后缀@gmail可以单独一个字段来存,或者用业务代码来保证, \2. 城市编号和学校编号估计也不会变,也可以用业务代码来配置 \3. 然后直接存年份和顺序编号就行了,这个字段可以全字段索引
Atas ialah kandungan terperinci Bagaimana untuk mengindeks medan rentetan dalam MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!