
Rumah >Peranti teknologi >AI >Membunuh dua kali OpenAI dalam skala dan prestasi, Meta Voice mencapai pencapaian peringkat LLaMA! Model MMS sumber terbuka mengenali 1100+ bahasa
Membunuh dua kali OpenAI dalam skala dan prestasi, Meta Voice mencapai pencapaian peringkat LLaMA! Model MMS sumber terbuka mengenali 1100+ bahasa

- PHPzke hadapan
- 2023-05-24 16:25:061351semak imbas
Dari segi suara, Meta telah mencapai satu lagi pencapaian peringkat LLaMA.
Hari ini, Meta melancarkan projek suara berbilang bahasa berskala besar yang dipanggil MMS yang akan merevolusikan teknologi suara.
MMS menyokong lebih daripada 1,000 bahasa, dilatih dengan Bible dan mempunyai kadar ralat yang hanya separuh daripada set data Whisper.
Dengan hanya satu model, Meta membina Menara Babel.
Selain itu, Meta telah memilih untuk menjadikan semua model dan kod sumber terbuka, dengan harapan dapat menyumbang untuk melindungi kepelbagaian bahasa dunia.

Model sebelumnya boleh merangkumi kira-kira 100 bahasa, tetapi kali ini, MMS terus meningkatkan jumlah ini sebanyak 10-40 kali ganda!
Secara khusus, Meta telah membuka model pengecaman/sintesis pertuturan berbilang bahasa dalam lebih daripada 1,100 bahasa dan model pengecaman pertuturan dalam lebih daripada 4,000 bahasa.
Berbanding OpenAI Whisper, model ASR berbilang bahasa menyokong 11 kali lebih banyak bahasa, tetapi purata kadar ralat pada 54 bahasa adalah kurang daripada separuh daripada FLEURS.
Selain itu, penskalaan ASR kepada begitu banyak bahasa hanya menghasilkan prestasi yang sangat kecil.
Alamat kertas: https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
Lindungi bahasa yang hilang, MMS meningkatkan pengecaman pertuturan 40 kali ganda
Melengkapkan mesin dengan keupayaan untuk mengecam dan menjana pertuturan, membolehkan lebih ramai orang memperoleh maklumat.
Walau bagaimanapun, menjana model pembelajaran mesin berkualiti tinggi untuk tugasan ini memerlukan sejumlah besar data berlabel, seperti beribu-ribu jam audio dan transkripsi - yang untuk kebanyakan bahasa Data jenis ini hanya tidak wujud.
Model pengecaman pertuturan sedia ada hanya meliputi kira-kira 100 bahasa, yang hanya sebahagian kecil daripada lebih 7,000 bahasa yang diketahui di planet ini. Lebih membimbangkan, separuh daripada bahasa-bahasa ini berada dalam bahaya hilang dalam hayat kita.
Dalam projek Massively Multilingual Speech (MMS), penyelidik mengatasi beberapa cabaran dengan menggabungkan wav2vec 2.0 (kerja perintis Meta dalam pembelajaran penyeliaan kendiri) dengan cabaran set data baharu.
Set data ini menyediakan data berlabel dalam lebih daripada 1100 bahasa dan data tidak berlabel dalam hampir 4000 bahasa.

Melalui latihan silang bahasa, wav2vec 2.0 mempelajari unit fonetik yang digunakan dalam pelbagai bahasa
Sesetengah bahasa ini, seperti Tatuyo, hanya mempunyai beberapa ratus pembesar suara, dan bagi kebanyakan bahasa dalam set data, teknologi pertuturan tidak wujud sebelum ini.
Hasilnya menunjukkan bahawa prestasi model MMS adalah lebih baik daripada model sedia ada, dan bilangan bahasa yang diliputi adalah 10 kali ganda berbanding model sedia ada.
Meta sentiasa memfokuskan pada kerja berbilang bahasa: dari segi teks, projek NLLB Meta mengembangkan terjemahan berbilang bahasa kepada 200 bahasa, manakala projek MMS mengembangkan teknologi pertuturan kepada lebih banyak bahasa.
Alkitab menyelesaikan masalah set data pertuturan
Mengumpul data audio dalam beribu-ribu bahasa bukanlah perkara yang mudah, dan ini juga merupakan masalah pertama yang dihadapi oleh penyelidik di Meta cabaran.
Anda tahu, set data pertuturan sedia ada terbesar hanya merangkumi 100 bahasa selebihnya. Untuk mengatasi masalah ini, penyelidik telah beralih kepada teks agama seperti Bible.
Teks jenis ini telah diterjemahkan ke dalam pelbagai bahasa yang berbeza, digunakan dalam penyelidikan meluas dan telah diterbitkan dalam pelbagai rakaman awam.
Untuk tujuan ini, penyelidik Meta telah mencipta set data bacaan Perjanjian Baru secara khusus dalam lebih daripada 1,100 bahasa, menyediakan purata 32 jam data bagi setiap bahasa.
Ditambah dengan rakaman tidak berteg bagi pelbagai bacaan agama lain, para penyelidik meningkatkan bilangan bahasa yang tersedia kepada lebih 4,000.
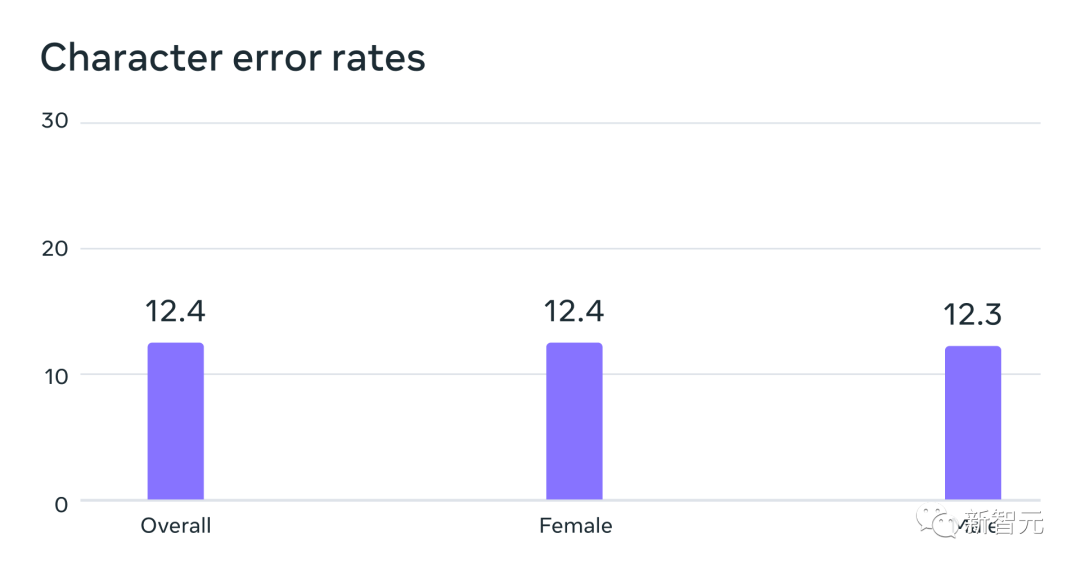
Model pengecaman pertuturan automatik yang dilatih pada data MMS dengan prestasi yang serupa untuk pembesar suara lelaki dan wanita pada Kadar Ralat penanda aras FLEURS
Data biasanya dituturkan oleh lelaki, tetapi model ini menunjukkan prestasi yang sama baik pada suara lelaki dan perempuan.
Dan, walaupun kandungan rakaman itu bersifat keagamaan, ini tidak terlalu berat sebelah model ke arah menghasilkan lebih banyak bahasa keagamaan.
Penyelidik percaya ini kerana mereka menggunakan kaedah pengelasan temporal connectionist, yang kurang terhad berbanding model bahasa besar atau model urutan-ke-jujukan yang digunakan untuk pengecaman pertuturan yang lebih besar.
Lebih besar model, lebih baik ia boleh melawan?
Penyelidik terlebih dahulu memproses data untuk meningkatkan kualitinya dan membolehkannya digunakan oleh algoritma pembelajaran mesin.
Untuk melakukan ini, penyelidik melatih model penjajaran pada data sedia ada dalam lebih daripada 100 bahasa dan menggunakan model ini dengan algoritma penjajaran paksa yang cekap, yang Boleh mengendalikan rakaman kira-kira 20 minit atau lebih.
Penyelidik mengulangi proses ini beberapa kali dan melakukan langkah penapisan silang pengesahan terakhir berdasarkan ketepatan model untuk mengalih keluar data berpotensi tidak sejajar.
Untuk membolehkan penyelidik lain mencipta set data pertuturan baharu, penyelidik menambahkan algoritma penjajaran pada PyTorch dan mengeluarkan model penjajaran.
Pada masa ini, terdapat 32 jam data untuk setiap bahasa, tetapi ini tidak mencukupi untuk melatih model pengecaman pertuturan diselia tradisional.
Itulah sebabnya penyelidik melatih model pada wav2vec 2.0, yang boleh mengurangkan jumlah data beranotasi yang diperlukan untuk melatih model.
Secara khususnya, para penyelidik melatih model penyeliaan sendiri pada kira-kira 500,000 jam data pertuturan dalam lebih 1,400 bahasa—hampir lima kali lebih banyak berbanding sebelum ini.
Kemudian penyelidik boleh memperhalusi model untuk tugasan pertuturan tertentu, seperti pengecaman pertuturan berbilang bahasa atau pengecaman bahasa.
Untuk lebih memahami prestasi model yang dilatih pada data pertuturan berbilang bahasa berskala besar, penyelidik menilainya pada set data penanda aras sedia ada.
Para penyelidik menggunakan model wav2vec 2.0 parameter 1B untuk melatih model pengecaman pertuturan berbilang bahasa untuk lebih daripada 1100 bahasa.
Prestasi menurun apabila bilangan bahasa meningkat, tetapi penurunan adalah sederhana - daripada 61 bahasa kepada 1107 bahasa, kadar ralat aksara hanya meningkat kira-kira 0.4 %, tetapi liputan bahasa meningkat lebih daripada 18 kali ganda.
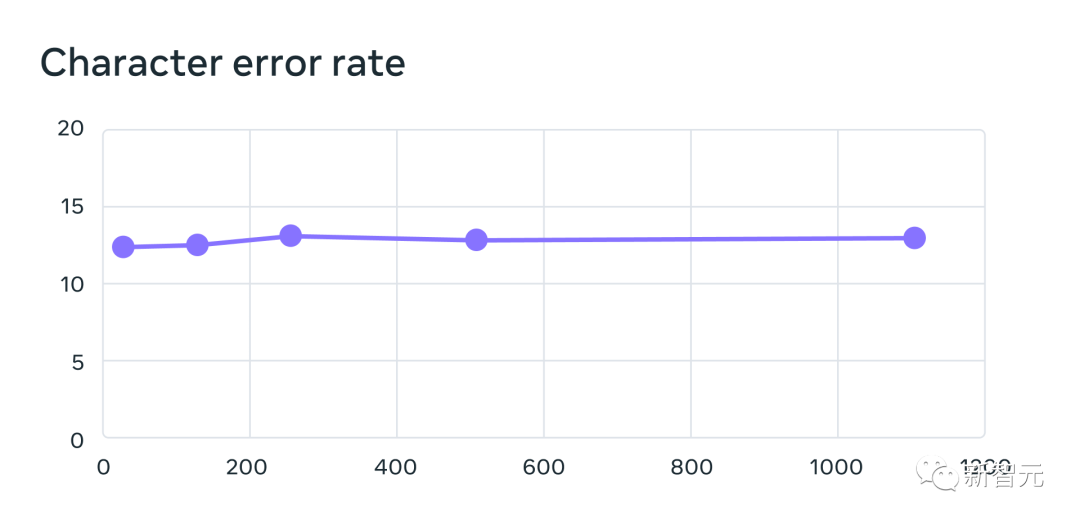
61 daripada sistem pengecaman berbilang bahasa yang dilatih menggunakan data MMS apabila meningkatkan bilangan bahasa yang disokong oleh setiap sistem daripada 61 kepada 1,107 Kadar ralat untuk bahasa FLEURS. Kadar ralat yang lebih tinggi menunjukkan prestasi yang lebih rendah
Dalam perbandingan epal-ke-epal dengan OpenAI's Whisper, para penyelidik mendapati bahawa hampir separuh daripada model dilatih mengenai ralat perkataan data Pertuturan Berbilang Bahasa Besar-besaran kadar, tetapi Pertuturan Berbilang Bahasa Secara Besar-besaran merangkumi 11 kali lebih banyak bahasa daripada Whisper.
Daripada data yang kita dapat lihat bahawa berbanding dengan model pertuturan terbaik pada masa ini, model Meta menunjukkan prestasi yang sangat baik.
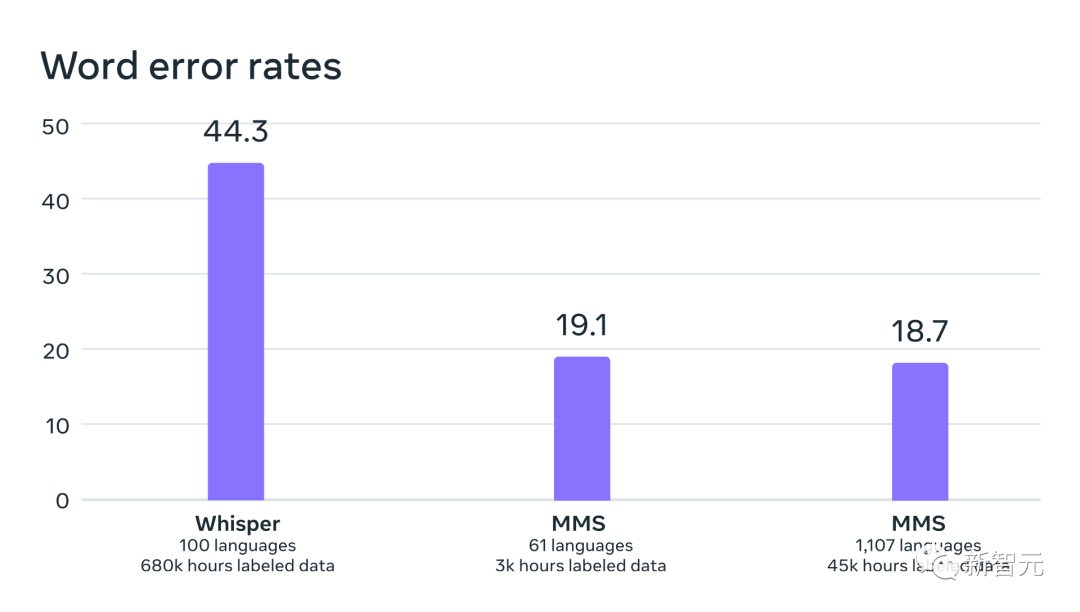
Perbandingan kadar ralat perkataan antara OpenAI Whisper dan Massively Multilingual Speech pada 54 bahasa FLEURS
Seterusnya , para penyelidik melatih model pengenalan bahasa (LID) untuk lebih 4,000 bahasa menggunakan set data mereka sendiri dan sedia ada seperti FLEURS dan CommonVoice dan menilainya pada tugas FLEURS LID.
Fakta telah membuktikan bahawa walaupun ia menyokong hampir 40 kali ganda bilangan bahasa, prestasinya masih sangat baik.
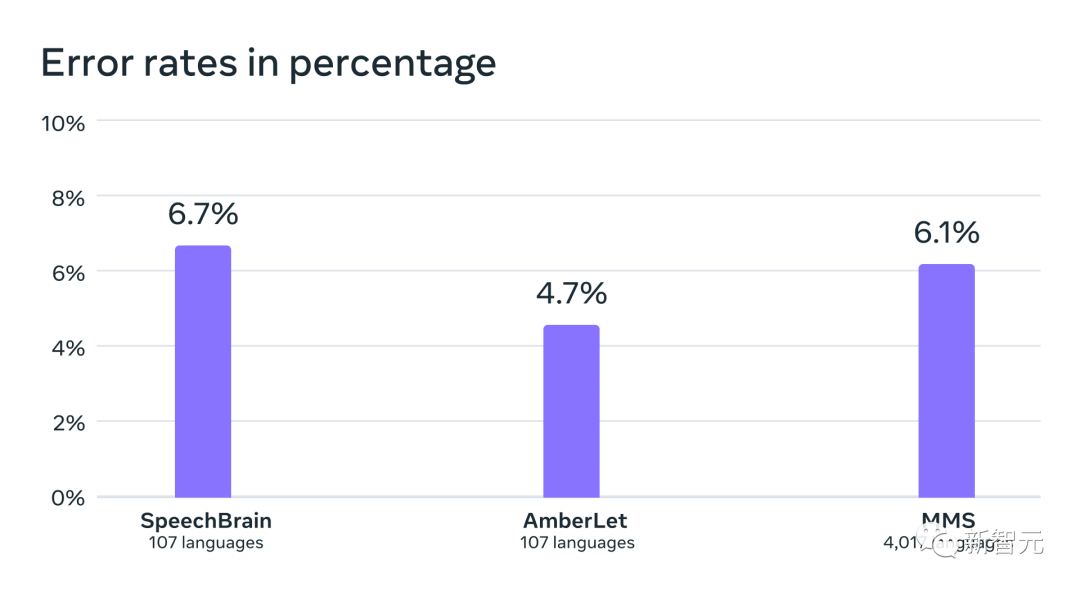
Ketepatan pengecaman bahasa pada tanda aras VoxLingua-107 bagi kerja sedia ada, menyokong lebih daripada 100 bahasa dan MMS Ia menyokong lebih daripada 4,000 bahasa.
Penyelidik juga telah membina sistem teks ke pertuturan untuk lebih daripada 1,100 bahasa.
Satu had data pertuturan berbilang bahasa berskala besar ialah untuk kebanyakan bahasa ia mengandungi bilangan penutur berbeza yang agak kecil, selalunya hanya satu penutur.
Walau bagaimanapun, ciri ini merupakan kelebihan untuk membina sistem teks ke pertuturan, jadi penyelidik telah melatih sistem serupa untuk lebih daripada 1,100 bahasa.
Hasilnya menunjukkan bahawa kualiti pertuturan yang dihasilkan oleh sistem ini tidaklah buruk.
Masa depan adalah milik satu model
Penyelidik Meta berpuas hati dengan hasilnya, tetapi seperti semua teknologi AI yang baru muncul, model semasa Meta tidak sempurna .
Contohnya, model pertuturan ke teks mungkin salah menciri perkataan atau frasa yang dipilih, yang berpotensi mengakibatkan hasil keluaran yang menyinggung perasaan atau tidak tepat.
Pada masa yang sama, Meta percaya bahawa kerjasama gergasi AI adalah penting untuk pembangunan teknologi AI yang bertanggungjawab.
Banyak bahasa di dunia terancam lenyap, dan pengehadan teknologi pengecaman pertuturan dan penjanaan pertuturan semasa hanya akan mempercepatkan aliran ini.
Penyelidik membayangkan dunia di mana teknologi mempunyai kesan sebaliknya, menggalakkan orang ramai mengekalkan bahasa mereka kerana mereka boleh mengakses maklumat dan menggunakan teknologi dengan menuturkan bahasa pilihan mereka.
Projek ucapan berbilang bahasa berskala besar merupakan langkah penting ke arah ini.
Pada masa hadapan, penyelidik berharap dapat meningkatkan lagi liputan bahasa, menyokong lebih banyak bahasa dan juga mencari cara untuk mengendalikan dialek. Anda tahu, dialek bukan mudah untuk teknologi pertuturan sedia ada.
Matlamat utama Meta adalah untuk memudahkan orang ramai mengakses maklumat dan menggunakan peranti dalam bahasa pilihan mereka.
Akhir sekali, penyelidik Meta juga membayangkan senario masa depan di mana satu model boleh menyelesaikan beberapa tugas pertuturan dalam semua bahasa.
Walaupun Meta pada masa ini melatih model berasingan untuk pengecaman pertuturan, sintesis pertuturan dan pengecaman bahasa, para penyelidik percaya bahawa pada masa hadapan, hanya satu model akan dapat menyelesaikan semua tugasan ini, malah lebih banyak lagi. daripada.
Atas ialah kandungan terperinci Membunuh dua kali OpenAI dalam skala dan prestasi, Meta Voice mencapai pencapaian peringkat LLaMA! Model MMS sumber terbuka mengenali 1100+ bahasa. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI