
Rumah >Peranti teknologi >AI >Menemui 100+ kelemahan secara automatik dalam empat pangkalan data utama dalam satu hari, penyelidikan Universiti Zhejiang memenangi kertas terbaik dalam SIGMOD 2023
Menemui 100+ kelemahan secara automatik dalam empat pangkalan data utama dalam satu hari, penyelidikan Universiti Zhejiang memenangi kertas terbaik dalam SIGMOD 2023

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-24 15:58:061000semak imbas
Persidangan Antarabangsa ACM SIGMOD/PODS 2023 mengenai Pengurusan Data (SIGMOD 2023) akan diadakan di Seattle, Amerika Syarikat dari 18-23 Jun waktu tempatan. Baru-baru ini, persidangan itu mengumumkan senarai kertas terbaik, dengan "Predicate Pushdown for Data Science Pipelines" daripada Microsoft Research dan "Detecting Logic Bugs of Join Optimizations in DBMS" daripada Universiti Zhejiang menang. Ini adalah kali pertama pasukan penyelidik tanah besar China memenangi anugerah kertas terbaik pada persidangan itu sejak penubuhannya pada 1975. Antaranya, penyelidikan dari Universiti Zhejiang mencadangkan kaedah baru yang secara automatik boleh menemui kelemahan logik dalam sistem pengurusan pangkalan data seperti MySQL, MariaDB, TiDB dan PolarDB.

Sejak beberapa dekad yang lalu, sistem pengurusan pangkalan data moden (DBMS) telah terus berkembang untuk menyokong pelbagai seni bina baharu, seperti platform awan dan HTAP , yang memerlukan pengoptimuman penilaian pertanyaan yang semakin canggih. Pengoptimum pertanyaan dianggap sebagai salah satu komponen yang paling kompleks dan penting dalam DBMS Fungsinya adalah untuk menghuraikan pertanyaan SQL input dan kemudian menjana pelan pelaksanaan yang cekap dengan bantuan model kos terbina dalam. Ralat dalam pelaksanaan pengoptimum pertanyaan mungkin membawa kepada kelemahan (pepijat), termasuk kelemahan ranap dan lubang logik. Kerentanan ranap sistem mudah dikesan kerana ranap sistem menyebabkan sistem berhenti serta-merta. Walau bagaimanapun, kelemahan logik mudah diabaikan kerana ia boleh menyebabkan DBMS mengembalikan set hasil yang salah yang sukar untuk dikesan. Kertas kerja ini memberi tumpuan kepada mengesan kelemahan senyap ini.

Terdapat pendekatan baru dalam mengesan kelemahan logik dalam DBMS, iaitu Pivoted Query Synthesis (PQS). Idea teras kaedah ini adalah untuk memilih baris pangsi (baris pangsi) secara rawak daripada jadual dan kemudian menjana pertanyaan dengan baris ini sebagai hasilnya. Jika sebarang pertanyaan yang disintesis tidak dapat mengembalikan baris data itu, maka kerentanan logik telah dikesan. PQS digunakan terutamanya untuk menyokong pertanyaan pilihan dalam satu jadual, dan 90% daripada kelemahan yang dilaporkan hanya melibatkan pertanyaan jadual tunggal. Masih terdapat jurang penyelidikan yang besar untuk pertanyaan berbilang jadual yang menggunakan algoritma gabungan dan struktur gabungan yang berbeza (yang lebih terdedah kepada ralat berbanding pertanyaan jadual tunggal).
Rajah berikut menunjukkan kelemahan logik dua pertanyaan gabungan dalam MySQL. Kedua-dua kelemahan boleh dikesan menggunakan alat baharu yang dicadangkan dalam artikel ini.
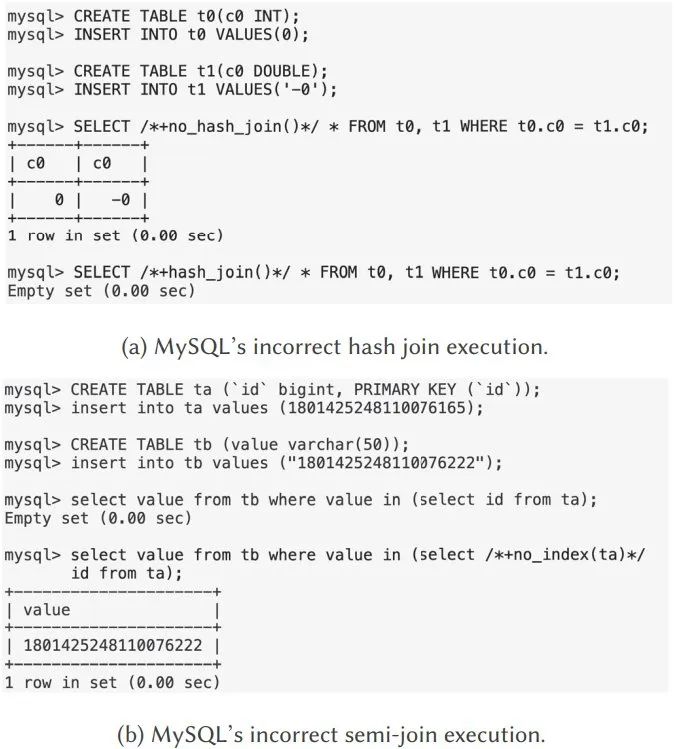
Rajah 1: Contoh kelemahan logik dalam pengoptimuman gabungan dalam DBMS
Rajah 1 (a) menunjukkan kelemahan logik dalam gabungan cincang dalam MySQL 8.0.18. Dalam contoh ini, pertanyaan pertama mengembalikan set hasil yang betul kerana ia dilaksanakan menggunakan gabungan gelung bersarang blok. Walau bagaimanapun, pertanyaan kedua menggunakan cantuman cincang dalaman menjadi salah dan mengembalikan set hasil kosong yang salah. Ini kerana algoritma cantuman hash asas salah mengandaikan bahawa 0 tidak sama dengan -0.
Kerentanan logik dalam Rajah 1 (b) berasal daripada pemprosesan separa gabungan dalam MySQL 8.0.28. Dalam pertanyaan pertama, gabungan dalam gelung bersarang menukar jenis data varchar kepada bigint, menghasilkan set hasil yang betul. Apabila melaksanakan pertanyaan kedua menggunakan cincang separa gabungan, varchar jenis data akan ditukar kepada dua kali ganda, mengakibatkan kehilangan ketepatan data dan ralat dalam perbandingan yang setara.
Kesukaran menggunakan kaedah sintesis pertanyaan untuk mengesan kelemahan logik dalam pertanyaan gabungan berbilang jadual adalah jauh lebih besar daripada pertanyaan satu jadual Ini melibatkan dua cabaran:
- Pengesahan hasil: Untuk mengesahkan ketepatan keputusan pertanyaan, kaedah sebelumnya menggunakan strategi ujian pembezaan. Ideanya adalah untuk menggunakan pelan pelaksanaan fizikal yang berbeza (cara sistem pangkalan data sebenarnya melaksanakan pernyataan pertanyaan) untuk memproses pertanyaan. Jika rancangan ini mengembalikan set hasil yang tidak konsisten, kecacatan logik mungkin telah dikesan. Walau bagaimanapun, kaedah ujian pembezaan mempunyai dua kelemahan. Pertama, kelemahan logik tertentu boleh menjejaskan berbilang pelan pelaksanaan fizikal dan menyebabkan kesemuanya menghasilkan keputusan ralat yang sama. Kedua, apabila set hasil yang tidak konsisten diperhatikan, ia menjadi mahal untuk menyemak secara manual rancangan pelaksanaan yang menjana hasil yang betul. Penyelesaian yang mungkin untuk masalah ini adalah untuk membina keputusan ground-truth untuk pertanyaan ujian sewenang-wenangnya, tetapi alat sedia ada tidak menyokong operasi ini
- ruang carian : Untuk skema pangkalan data yang diberikan, nombornya; pertanyaan gabungan yang boleh dijana skala secara eksponen dengan bilangan jadual dan lajur. Memandangkan adalah mustahil untuk menghitung semua pertanyaan yang mungkin untuk pengesahan, mekanisme penerokaan ruang pertanyaan yang berkesan diperlukan untuk membolehkan kami mengesan kelemahan logik secekap mungkin.
Sebagai tindak balas kepada masalah di atas, penyelidik dari Universiti Zhejiang mencadangkan kaedah yang dipanggil Transformed Query Synthesis (TQS). TQS ialah alat baharu, sejagat dan kos efektif untuk tugas mengesan kelemahan logik dalam pengoptimuman gabungan dalam DBMS.
Sebagai tindak balas kepada cabaran pertama yang dinyatakan di atas, penyelesaian yang dicadangkan oleh penyelidik ialah DSG, yang bermaksud Skema Berpandukan Data dan Penjanaan pertanyaan ) . Memandangkan set data yang diwakili sebagai jadual lebar, DSG boleh membahagikan set data kepada berbilang jadual berdasarkan paradigma yang dikesan. Untuk mempercepatkan penemuan kelemahan, DSG juga menyuntik beberapa data bunyi buatan ke dalam pangkalan data yang dijana. Mula-mula, tukar skema pangkalan data kepada graf, di mana nod ialah jadual/lajur dan tepi ialah hubungan antara nod. DSG menggunakan jalan rawak pada graf corak untuk memilih jadual untuk pertanyaan, dan kemudian menggunakan jadual ini untuk menjana cantuman. Untuk pertanyaan gabungan tertentu yang melibatkan berbilang jadual, kami boleh mencari hasil kebenaran dengan mudah daripada jadual lebar. Dengan cara ini, DSG boleh menjana koleksi (pertanyaan, hasil) dengan berkesan untuk pengesahan pangkalan data.
Untuk menangani cabaran kedua di atas, kaedah yang direka oleh penyelidik ialah KQE, iaitu Penerokaan ruang Pertanyaan berpandukan Pengetahuan (Penerokaan ruang Pertanyaan berpandukan Pengetahuan) . Pendekatan bermula dengan memanjangkan graf corak ke dalam graf pelan-berulang, yang mewakili keseluruhan ruang penjanaan pertanyaan. Setiap pertanyaan gabungan kemudiannya diwakili sebagai subgraf. Untuk menjaringkan graf pertanyaan yang dijana, KQE menggunakan indeks graf berasaskan benam yang mencari ruang yang telah diterokai untuk graf pertanyaan yang serupa dari segi struktur. Penjana pertanyaan berjalan rawak dibimbing berdasarkan skor liputan untuk meneroka sebanyak mungkin ruang pertanyaan yang tidak diketahui.
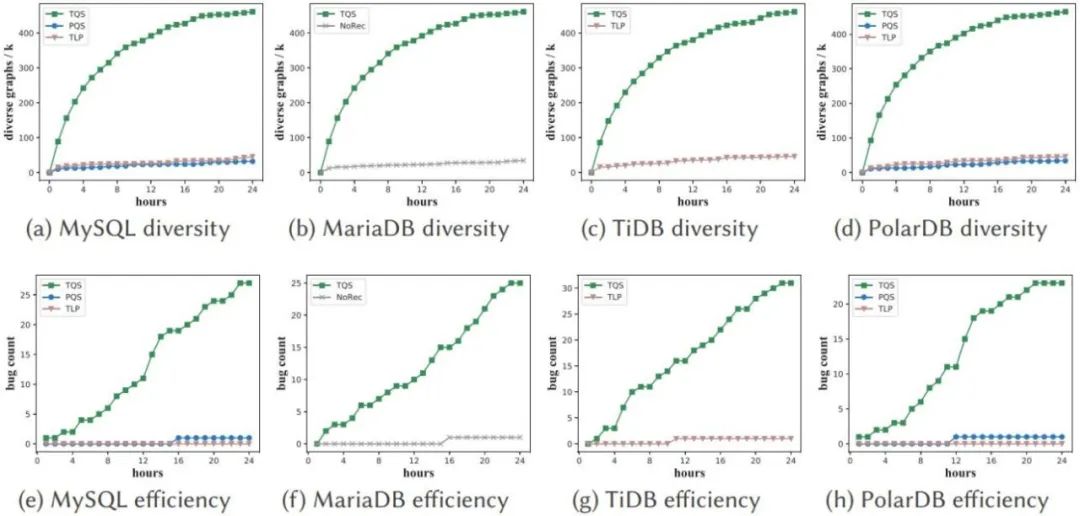
Untuk menunjukkan fleksibiliti dan keberkesanan kaedah, penyelidik menilai TQS pada empat DBMS yang biasa digunakan: MySQL, MariaDB, TiDB dan PolarDB . Selepas berjalan selama 24 jam, TQS berjaya menemui 115 kelemahan, termasuk 31 dalam MySQL, 30 dalam MariaDB, 31 dalam TiDB dan 23 dalam PolarDB. Dengan menganalisis punca, jenis kelemahan ini boleh diringkaskan, antaranya terdapat 7 jenis kelemahan dalam MySQL, 5 jenis dalam MariaDB, 5 jenis dalam TiDB, dan 3 jenis dalam PolarDB. Para penyelidik telah menyerahkan kelemahan yang ditemui kepada komuniti yang sesuai dan menerima maklum balas yang positif.
Berikut akan menerangkan masalah yang perlu diselesaikan dan penyelesaian yang dicadangkan oleh Universiti Zhejiang dalam bentuk matematik.
Definisi Masalah
Terdapat dua jenis kelemahan pangkalan data: ranap dan kerentanan logik. Kerentanan ranap timbul daripada pelaksanaan sistem pengendalian dan DBMS. Ia boleh menyebabkan DBMS ditamatkan secara paksa atas sebab-sebab seperti sumber yang tidak mencukupi seperti memori atau akses kepada alamat memori yang tidak sah. Oleh itu, kelemahan ranap mudah ditemui. Kerentanan logik adalah lebih sukar untuk dicari, kerana pangkalan data masih akan berjalan seperti biasa dan memproses pertanyaan dan mengembalikan hasil yang kelihatan betul (dan kebanyakan masa mereka melakukannya, tetapi dalam beberapa kes, mereka mungkin Membaca set hasil yang salah). Kerentanan senyap ini adalah seperti bom yang tidak kelihatan dan lebih berbahaya kerana ia sukar untuk dikesan dan boleh menjejaskan ketepatan aplikasi.
Makalah ini memperkenalkan pengoptimum pertanyaan untuk mengesan kelemahan logik untuk masalah pertanyaan gabungan berbilang jadual. Penyelidik memanggil kelemahan ini menyertai pepijat pengoptimuman. Menggunakan tatatanda yang diberikan dalam Jadual 1, masalah pengesanan kerentanan pengoptimuman gabungan boleh ditakrifkan secara rasmi sebagai:
Definisi: Untuk setiap pertanyaan qi dalam beban kerja pertanyaan Q, biarkan pertanyaan dioptimumkan Pemproses melakukan penyatuan qi melalui pelbagai pelan sebenar dan mengesahkan set keputusannya 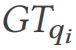 menggunakan nilai kebenaran asas
menggunakan nilai kebenaran asas 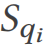 . Jika
. Jika 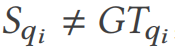 , kelemahan pengoptimuman sambungan telah ditemui.
, kelemahan pengoptimuman sambungan telah ditemui.
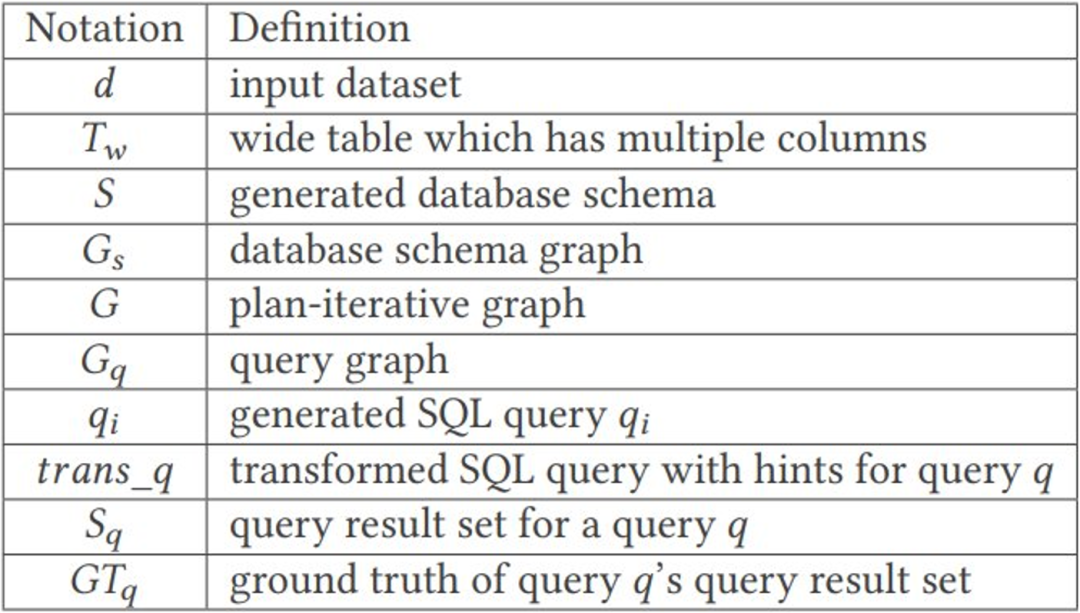
Jadual 1: Jadual Penerangan Simbol
Gambaran Keseluruhan Program
Rajah 2 memberikan gambaran keseluruhan seni bina TQS. Memandangkan set data garis dasar dan DBMS sasaran, TQS mencari kemungkinan kelemahan logik dalam DBMS dengan menjana pertanyaan berdasarkan set data. TQS mempunyai dua komponen utama: skema berpandukan data dan penjanaan pertanyaan (DSG) dan penerokaan ruang pertanyaan berpandukan pengetahuan (KQE)
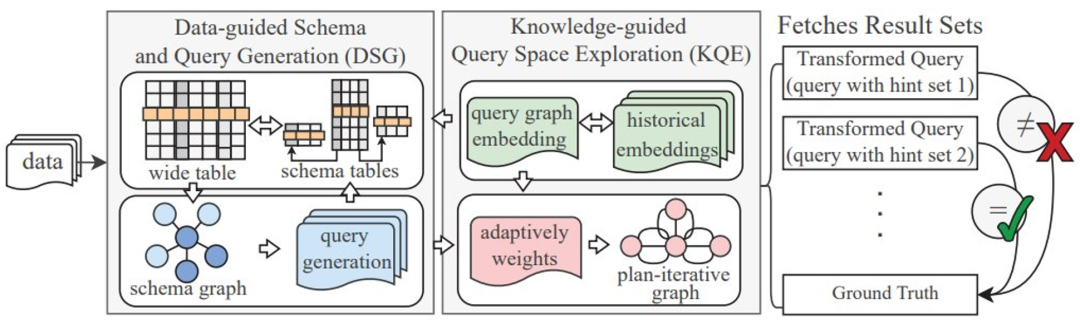
Rajah 2: Gambaran Keseluruhan TQS
DSG merawat set data input sebagai jadual lebar dan kecuali tuple asal, DSG juga sengaja mensintesis beberapa tupel dengan nilai rawan ralat (seperti nilai nol atau rentetan yang sangat panjang). Untuk pertanyaan penyertaan, DSG mencipta skema baharu untuk jadual lebar dengan membahagikan jadual lebar kepada berbilang jadual, memastikan bahawa jadual mematuhi paradigma berasaskan kebergantungan berfungsi. DSG memodelkan skema pangkalan data sebagai graf dan kemudian menjana pertanyaan logik/konseptual melalui jalan rawak pada graf skema. DSG akan merealisasikan pertanyaan logik kepada pelan pelaksanaan fizikal dan mengubah pertanyaan dengan pembayang yang berbeza, membolehkan DBMS melaksanakan pelbagai rancangan pelaksanaan fizikal yang berbeza untuk mencari kelemahan. Untuk pertanyaan gabungan, hasil kebenaran asas diperoleh dengan memetakan graf gabungan kembali ke jadual lebar.
Selepas melengkapkan persediaan corak dan pemisahan data, KQE mengembangkan rajah corak menjadi rajah lelaran perancangan. Setiap pertanyaan diwakili sebagai subgraf. KQE membina indeks graf berasaskan benam untuk pembenaman graf pertanyaan dalam sejarah (iaitu, dalam ruang pertanyaan yang telah diterokai). Secara intuitif, peranan KQE adalah untuk memastikan bahawa graf pertanyaan yang baru dijana berada sejauh mungkin daripada jiran terdekatnya dalam sejarah, iaitu ini adalah untuk meneroka graf pertanyaan baharu dan bukannya mengulangi graf pertanyaan sedia ada. KQE melakukan ini dengan menskor graf pertanyaan yang dijana berdasarkan persamaan struktur (untuk menanyakan graf dalam sejarah) sambil menggunakan kaedah berjalan rawak suai untuk menjana pertanyaan. .
Algoritma 1 meringkaskan idea teras TQS, dengan baris 2, 10, dan 12 ialah DSG, dan baris 4, 8, dan 9 ialah KQE.

Memandangkan set data 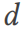 dan jadual lebar
dan jadual lebar 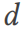 sampel daripada
sampel daripada 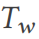 , DSG menukar satu Jadual jadual lebar tunggal
, DSG menukar satu Jadual jadual lebar tunggal 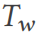 dibahagikan kepada berbilang jadual dan jadual ini membentuk skema pangkalan data
dibahagikan kepada berbilang jadual dan jadual ini membentuk skema pangkalan data 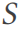 yang mematuhi 3NF (baris 2). Corak
yang mematuhi 3NF (baris 2). Corak 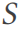 boleh dilihat sebagai graf
boleh dilihat sebagai graf 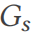 , dengan jadual dan lajur ialah bucu dan tepi mewakili hubungan antara bucu. DSG menggunakan laluan rawak pada
, dengan jadual dan lajur ialah bucu dan tepi mewakili hubungan antara bucu. DSG menggunakan laluan rawak pada 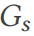 untuk menjana ungkapan gabungan pertanyaan (baris 10). Malah, pertanyaan sertai boleh diunjurkan sebagai subgraf
untuk menjana ungkapan gabungan pertanyaan (baris 10). Malah, pertanyaan sertai boleh diunjurkan sebagai subgraf 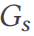 . DSG boleh mendapatkan semula hasil kebenaran asas untuk pertanyaan ini dengan mudah dengan memetakan subgraf kembali ke jadual lebar
. DSG boleh mendapatkan semula hasil kebenaran asas untuk pertanyaan ini dengan mudah dengan memetakan subgraf kembali ke jadual lebar 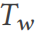 (baris 12).
(baris 12).
KQE memanjangkan rajah corak ke dalam rajah lelaran perancangan (baris 4). Untuk mengelakkan ujian laluan yang serupa, KQE akan membina indeks graf berasaskan benam
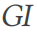
untuk mengindeks pembenaman graf pertanyaan sedia ada (baris 9) . KQE mengemas kini berat tepi π graf lelaran perancangan G berdasarkan persamaan struktur antara graf pertanyaan semasa dan graf pertanyaan sedia ada (baris 8). KQE menjaringkan laluan yang mungkin seterusnya, yang membimbing penjana berjalan rawak, dengan itu memilih untuk meneroka ruang pertanyaan yang tidak diketahui.
Untuk pertanyaan 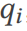 , TQS mengubah pertanyaan melalui set pembayang
, TQS mengubah pertanyaan melalui set pembayang 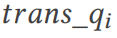 untuk melaksanakan berbilang pelan pertanyaan sebenar yang berbeza (Bahagian 11 OK). Akhir sekali, set hasil pertanyaan
untuk melaksanakan berbilang pelan pertanyaan sebenar yang berbeza (Bahagian 11 OK). Akhir sekali, set hasil pertanyaan
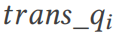 dibandingkan dengan nilai kebenaran asas
dibandingkan dengan nilai kebenaran asas 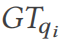 (baris 14). Jika ia tidak konsisten, maka kerentanan pengoptimuman gabungan telah dikesan (baris 15).
(baris 14). Jika ia tidak konsisten, maka kerentanan pengoptimuman gabungan telah dikesan (baris 15).
Untuk penerangan terperinci tentang DSG dan KQE sila baca kertas asal.
Hasil eksperimen
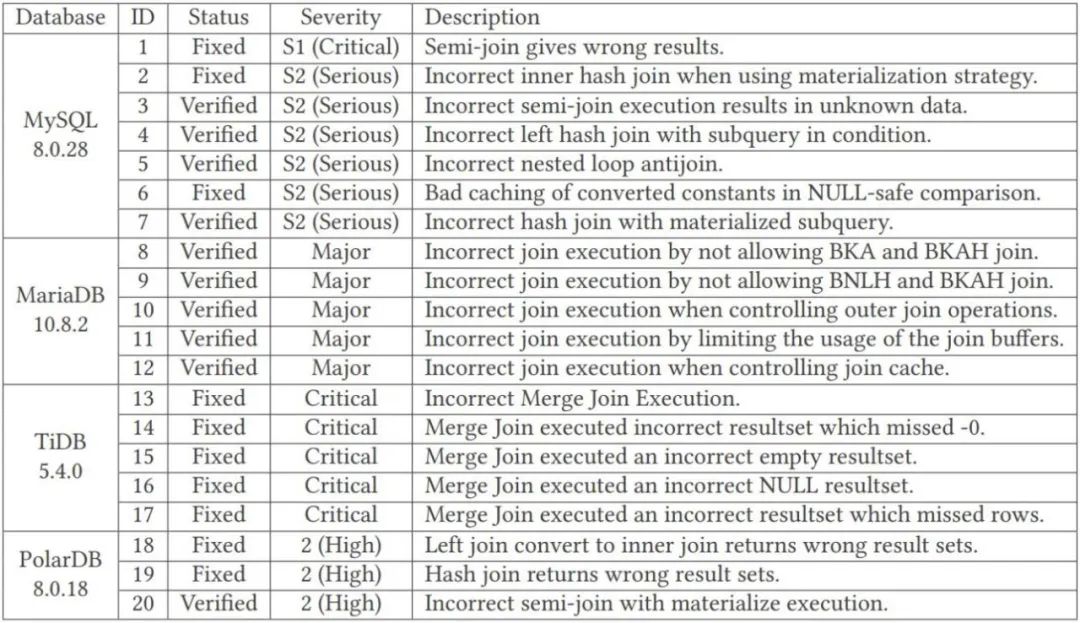
TQS berjaya menemui beberapa kelemahan logik dalam sistem pengurusan pangkalan data seperti MySQL, MariaDB, TiDB dan PolarDB Ia dibahagikan kepada 20 jenis, termasuk 7 kelemahan dalam MySQL dan 7 dalam MariaDB . Terdapat 5 jenis TiDB, 5 jenis PolarDB dan 3 jenis PolarDB, seperti yang ditunjukkan dalam jadual di bawah.
Berbanding dengan kaedah lain, prestasi keseluruhan TQS yang dicadangkan oleh Universiti Zhejiang juga agak mengagumkan, dan ia telah mencapai peningkatan ketara dalam banyak petunjuk. Keputusan yang cemerlang telah diperolehi, dan keberkesanan setiap komponen juga telah diuji melalui eksperimen pembolehubah terkawal.
Tetapi penyelidik juga mengatakan bahawa TQS pada masa ini memfokuskan pada pertanyaan equijoin. Walau bagaimanapun, idea DSG dan KQE juga boleh diperluaskan kepada kes bukan equijoin. Satu-satunya kesukaran ialah cara untuk menjana dan mengurus keputusan kebenaran pertanyaan - dalam kes bukan equijoin, saiz hasil ini meningkat secara eksponen. Aspek ini masih memerlukan kajian lanjut pada masa hadapan.
Atas ialah kandungan terperinci Menemui 100+ kelemahan secara automatik dalam empat pangkalan data utama dalam satu hari, penyelidikan Universiti Zhejiang memenangi kertas terbaik dalam SIGMOD 2023. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI