
Rumah >Peranti teknologi >AI >Tukarkan siri masa kepada masalah klasifikasi
Tukarkan siri masa kepada masalah klasifikasi

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-18 22:12:201329semak imbas
Artikel ini akan menggunakan perdagangan saham sebagai contoh. Kami menggunakan model AI untuk meramalkan sama ada saham akan naik atau turun pada hari berikutnya. Dalam konteks ini, tiga algoritma pengelasan, XGBoost, Hutan Rawak dan Pengelas Logistik, dibandingkan. Satu lagi fokus artikel ialah penyediaan data. Bagaimanakah kita perlu mengubah data supaya model boleh memprosesnya.

Artikel ini akan mengikut langkah-langkah model proses CRISP-DM dan menggunakan pendekatan berstruktur untuk menyelesaikan kes perniagaan. CRISP-DM ialah kaedah yang digunakan secara meluas dalam analisis terpendam dan sering digunakan dalam membina projek sains data.
Perkara lain ialah kita akan menggunakan pakej Python openbb. Pakej ini termasuk beberapa sumber data daripada sektor kewangan dan sangat mudah digunakan.
Langkah pertama ialah memasang perpustakaan yang diperlukan:
<code>pip install pandas numpy “openbb[all]” swifter scikit-learn</code>
Pemahaman perniagaan
Pertama-tama kita harus memahami masalah yang ingin kita selesaikan dalam contoh kita, masalahnya boleh ditakrifkan seperti berikut:
<code>预测股票代码 AAPL 的股价第二天会上涨还是下跌。</code>
Kemudian timbul persoalan tentang jenis model pembelajaran mesin yang perlu anda pertimbangkan. Kami ingin meramalkan sama ada saham akan naik atau turun pada hari berikutnya. Jadi apa yang kita hadapi di sini ialah masalah klasifikasi binari di mana kita ingin meramal sama ada saham akan naik (dengan nilai 1) atau turun (dengan nilai 0) pada hari berikutnya. Dalam masalah pengelasan, kami meramalkan kelas. Dalam kes kami, ia adalah klasifikasi binari kelas 0 dan 1.
Pemahaman dan Penyediaan Data
Fasa pemahaman data memfokuskan pada mengenal pasti, mengumpul dan menganalisis set data. Sebagai langkah pertama, kami memuat turun data saham Apple. Begini cara untuk melakukannya menggunakan openbb:
<code>data = openbb.stocks.load(symbol = 'AAPL',start_date = '2023-01-01',end_date = '2023-04-01',monthly = False) data</code>
Kod ini memuat turun data antara 2023-01-01 dan 2023-04-01. Data yang dimuat turun mengandungi maklumat berikut:
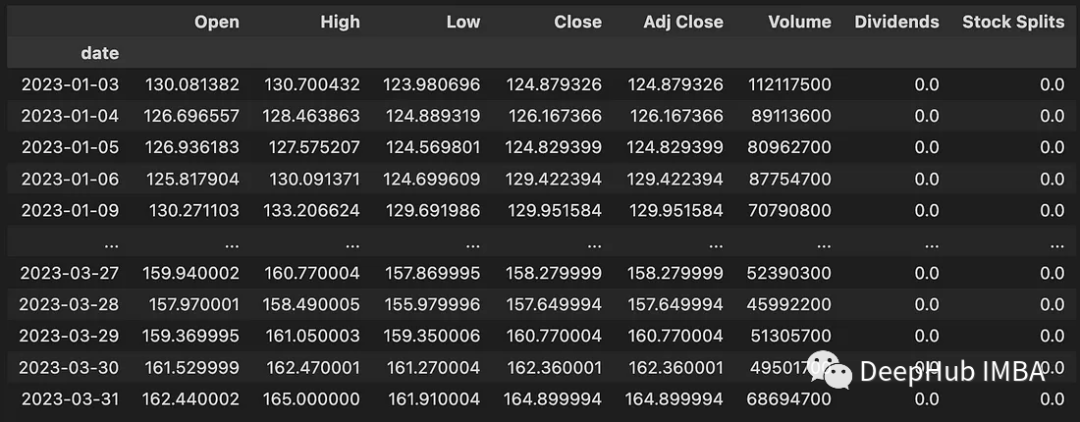
- Terbuka: Harga pembukaan harian USD
- Tinggi: Harga tertinggi hari ini (USD)
- Terendah: Harga terendah hari ini (USD)
- Penutup: Harga penutup harian dalam USD
- Penutup Adj: Harga penutupan larasan berkaitan dengan dividen atau pecahan saham
- Volume : Bilangan saham yang didagangkan
- Dividen: Dividen dibayar
- Pembahagian Saham: Pelaksanaan pecahan saham
Kami telah memuat turun data, tetapi data belum lagi sesuai untuk pemodelan model Klasifikasi. Jadi data masih perlu disediakan untuk pemodelan. Oleh itu, adalah perlu untuk membangunkan fungsi untuk memuat turun data dan kemudian menukar data untuk pemodelan. Kod berikut menunjukkan fungsi ini:
<code>def get_training_data(symbol, start_date, end_date, monthly_bool=True, lookback=10): data = openbb.stocks.load( symbol = symbol, start_date = start_date, end_date = end_date, monthly = monthly_bool) data = get_label(data) data_up_down = data['up_down'].to_numpy() training_data = get_sequence_data(data_up_down, lookback) return training_data</code>
Fungsi pertama yang disertakan di sini ialah get_label():
<code>def encoding(n): if n > 0: return 1 else: return 0 def get_label(data): data['Delta'] = data['Close'] - data['Open'] data['up_down'] = data['Delta'].swifter.apply(lambda d: encoding(d)) return data</code>
Tugas utamanya ialah mengira perbezaan antara harga penutup dan nilai harga pembukaan. Kami menandakan semua hari apabila harga saham meningkat sebagai 1 dan semua hari apabila harga saham jatuh sebagai 0. Lajur atas_bawah tambahan mengandungi sama ada harga saham meningkat atau menurun pada tarikh tertentu. Fungsi swifter.apply() digunakan di sini dan bukannya panda apply() kerana swifter menyediakan sokongan berbilang teras.
Fungsi kedua ialah get_sequence_data(). Tinjauan balik parameter menentukan bilangan hari yang lalu dimasukkan dalam ramalan. Kod get_sequence_data() adalah seperti berikut:
<code>def get_sequence_data(data_up_down, lookback): shape = (data_up_down.shape[0] - lookback + 1, lookback) strides = data_up_down.strides + (data_up_down.strides[-1],) return np.lib.stride_tricks.as_strided(data_up_down, shape=shape, strides=strides)</code>
Fungsi ini menerima dua parameter: data_up_down dan lookback. Ia mengembalikan tatasusunan NumPy baharu yang mewakili paparan tetingkap gelongsor tatasusunan data_up_down dengan saiz tetingkap yang ditentukan, ditentukan oleh hujah lihat balik. Untuk menggambarkan bagaimana fungsi ini berfungsi, mari kita lihat contoh kecil.
<code>get_sequence_data(np.array([1, 2, 3, 4, 5, 6]), 3)</code>
Hasilnya adalah seperti berikut:
<code>array([[1, 2, 3],[2, 3, 4],[3, 4, 5],[4, 5, 6]])</code>
Di bawah, kami memuat turun data untuk stok Apple dan mengubahnya untuk pemodelan. Kami menggunakan tetingkap lihat balik 10 hari.
<code>data = get_training_data(symbol = 'AAPL', start_date = '2023-01-01', end_date = '2023-04-01', monthly_bool = False, lookback=10) pd.DataFrame(data).to_csv("data/data_aapl.csv")</code>
Data sudah sedia, mari mulakan model dan menilai model.
Pemodelan
Baca dalam data dan jana data ujian dan latihan.
<code>data = pandas.read_csv("./data/data_aapl.csv") X=data.iloc[:,:-1] Y=data.iloc[:,-1] X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=4284, stratify=Y)</code>
Regression Logistik:
Pengkelas ini ialah model berasaskan linear dan sering digunakan sebagai model garis dasar. Kami menggunakan pelaksanaan scikit-learn:
<code>model_lr = LogisticRegression(random_state = 42) model_lr.fit(X_train,y_train) y_pred = model_lr.predict(X_test)</code>
XGBoost:
XGBoost ialah pelaksanaan pepohon keputusan dirangsang kecerunan yang direka untuk kelajuan dan prestasi. Ia tergolong dalam algoritma penggalak pokok, yang menghubungkan banyak pengelas pokok yang lemah dalam urutan.
<code>model_xgb = XGBClassifier(random_state = 42) model_xgb.fit(X_train, y_train) y_pred = model_xgb.predict(X_test)</code>
Hutan Rawak:
Hutan rawak membina berbilang pokok keputusan. Kaedah Bagging dipanggil sejenis pembelajaran ensemble kerana ia menggunakan pelbagai pelajar yang saling berkaitan untuk pembelajaran. Akronim "bagging" bermaksud pengagregatan bootstrap. Pelaksanaan scikit-learn juga digunakan di sini:
<code>model_rf = RandomForestClassifier(random_state = 42) model_rf.fit(X_train, y_train) y_pred = model_rf.predict(X_test)</code>
Penilaian
Selepas memodelkan dan melatih model, kita perlu menilai prestasinya pada data ujian. Recall, Precision dan F1-Score digunakan untuk mengukur metrik. Jadual di bawah menunjukkan keputusan.
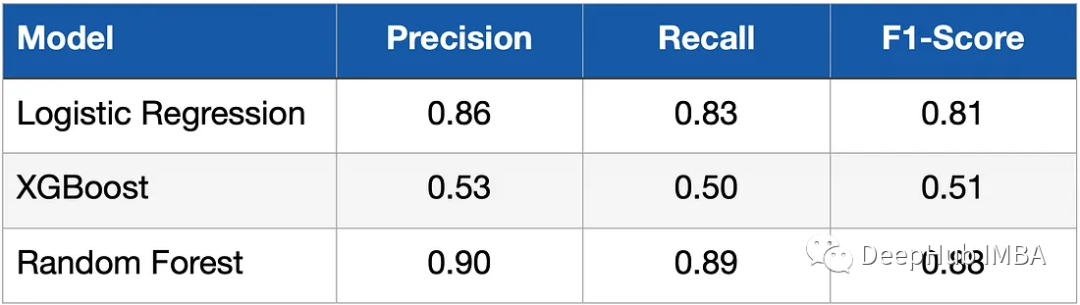
Anda dapat melihat bahawa pengelas logistik (regresi logistik) dan hutan rawak telah mencapai hasil yang jauh lebih baik daripada model XGBoost ini? Ini kerana datanya agak mudah, dengan hanya beberapa dimensi ciri, dan panjang data juga sangat kecil, dan semua model kami belum ditala.
Ringkasan
Tujuan utama artikel kami adalah untuk memperkenalkan cara menukar siri masa harga saham kepada masalah klasifikasi, dan untuk menunjukkan cara menggunakan fungsi tetingkap untuk menukar siri masa kepada urutan semasa pemprosesan data Model tidak perlu ditala dengan banyak, jadi lebih mudah model berfungsi dengan lebih baik untuk penilaian prestasi.
Atas ialah kandungan terperinci Tukarkan siri masa kepada masalah klasifikasi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI