
Rumah >pembangunan bahagian belakang >Tutorial Python >Cara menggunakan ClickHouse dalam Python
Cara menggunakan ClickHouse dalam Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-17 08:19:283618semak imbas
ClickHouse ialah pangkalan data kolumnar sumber terbuka (DBMS) yang telah menarik perhatian ramai sejak beberapa tahun kebelakangan ini, ia digunakan terutamanya dalam bidang analisis dalam talian data (OLAP) dan telah sumber terbuka pada 2016. Pada masa ini, komuniti domestik sedang berkembang pesat, dan pengeluar utama telah membuat susulan dan menggunakannya secara besar-besaran.
Toutiao menggunakan ClickHouse secara dalaman untuk analisis tingkah laku pengguna Terdapat beribu-ribu nod ClickHouse secara dalaman, dengan maksimum 1,200 nod dalam satu kelompok Jumlah volum data adalah berpuluh-puluh PB, dengan peningkatan harian sebanyak 300TB data mentah kira-kira.
Tencent menggunakan ClickHouse secara dalaman untuk analisis data permainan dan telah mewujudkan sistem pemantauan dan operasi yang lengkap untuknya.
Memulakan percubaan pada Julai 2018, Ctrip telah memindahkan 80% perniagaan dalamannya ke pangkalan data ClickHouse. Data meningkat lebih daripada satu bilion setiap hari, dan hampir satu juta permintaan pertanyaan dibuat.
Kuaishou juga menggunakan ClickHouse secara dalaman Jumlah kapasiti storan adalah kira-kira 10PB, dengan 200TB ditambah setiap hari, dan 90% pertanyaan adalah kurang daripada 3S.
Di luar negara, Yandex mempunyai ratusan nod yang digunakan untuk menganalisis gelagat klik pengguna, dan syarikat terkemuka seperti CloudFlare dan Spotify turut menggunakannya.
ClickHouse pada asalnya dibangunkan untuk membangunkan YandexMetrica, platform analitik web kedua terbesar di dunia. Ia telah digunakan secara berterusan sebagai komponen teras sistem selama bertahun-tahun.
1. Perihal amalan penggunaan ClickHouse
Pertama, mari kita semak beberapa konsep asas:
OLTP: Ia adalah pangkalan data perhubungan tradisional, terutamanya Mengendalikan penambahan, pemadaman, pengubahsuaian dan pertanyaan, menekankan ketekalan transaksi, seperti sistem perbankan dan sistem e-dagang.OLAP: Ia ialah pangkalan data jenis gudang yang terutamanya membaca data, menjalankan analisis data yang kompleks, memfokuskan pada sokongan keputusan teknikal dan memberikan hasil yang intuitif dan mudah.
1.1. ClickHouse digunakan pada senario gudang data
ClickHouse ialah pangkalan data kolumnar, yang lebih sesuai untuk senario OLAP ialah:
Sebahagian besar adalah permintaan baca
Data dikemas kini dalam kelompok yang agak besar (> 1000 baris) dan bukannya kemas kini satu baris; tidak memperbaharui sama sekali.
Data yang ditambahkan pada pangkalan data tidak boleh diubah suai.
Untuk bacaan, ekstrak beberapa baris daripada pangkalan data, tetapi hanya subset kecil lajur.
Jadual lebar, iaitu setiap jadual mengandungi sejumlah besar lajur
Agak sedikit pertanyaan (biasanya ratusan pertanyaan sesaat setiap pelayan ) kali atau kurang)
Untuk pertanyaan mudah, benarkan kelewatan kira-kira 50 milisaat
Data dalam lajur agak kecil: nombor dan aksara pendek Rentetan (cth., 60 bait setiap URL)
Keupayaan tinggi diperlukan apabila memproses satu pertanyaan (sehingga berbilion baris sesaat setiap pelayan)
Transaksi tidak diperlukan
Keperluan konsistensi data yang rendah
Setiap pertanyaan mempunyai jadual yang besar. Kecuali dia, yang lain semua kecil.
Hasil pertanyaan jauh lebih kecil daripada data sumber. Dalam erti kata lain, data ditapis atau diagregatkan supaya hasilnya muat dalam RAM pelayan tunggal
1.2 Alat Pelanggan DBeaver
Alat klien Clickhouse ialah dbeaver , Laman web rasmi ialah https://dbeaver.io/.
dbeaver ialah alat pangkalan data umum sumber terbuka (GPL) percuma untuk pembangun dan pentadbir pangkalan data. [Baidu Encyclopedia]
Matlamat teras projek ini adalah untuk meningkatkan kemudahan penggunaan, jadi kami mereka bentuk dan membangunkan alat pengurusan pangkalan data secara khusus. Percuma, merentas platform, berdasarkan rangka kerja sumber terbuka dan membenarkan penulisan pelbagai sambungan (pemalam).
Ia menyokong mana-mana pangkalan data dengan pemacu JDBC.
Ia boleh mengendalikan sebarang sumber data luaran.
Buat dan konfigurasi sambungan baharu melalui "Pangkalan Data" dalam menu antara muka operasi, seperti yang ditunjukkan dalam rajah di bawah, pilih dan muat turun pemacu ClickHouse (tiada pemandu secara lalai).

Konfigurasi DBeaver adalah berdasarkan Jdbc Secara amnya, URL dan port lalai adalah seperti berikut:
jdbc:clickhouse://192.168.17.61:8123
Seperti yang ditunjukkan dalam rajah di bawah.
Apabila menggunakan DBeaver untuk menyambung ke Clickhouse untuk membuat pertanyaan, kadangkala sambungan atau pertanyaan tamat pada masa ini, anda boleh menambah dan menetapkan parameter socket_timeout dalam parameter sambungan untuk menyelesaikan masalah.
jdbc:clickhouse://{host}:{port}[/{database}]?socket_timeout=600000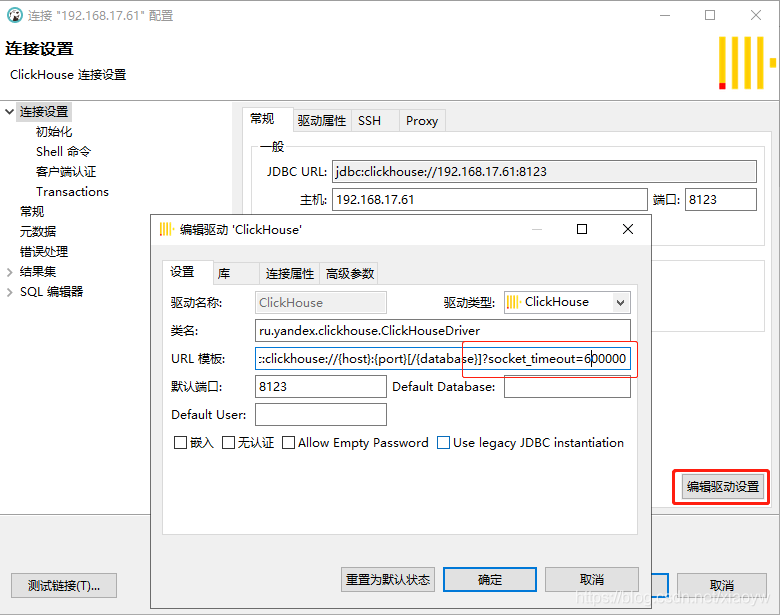
1.3 Amalan aplikasi data besar
Penerangan ringkas tentang persekitaran:
Sumber perkakasan adalah terhad, dengan hanya 16G memori, dan data transaksi berjumlah ratusan juta.
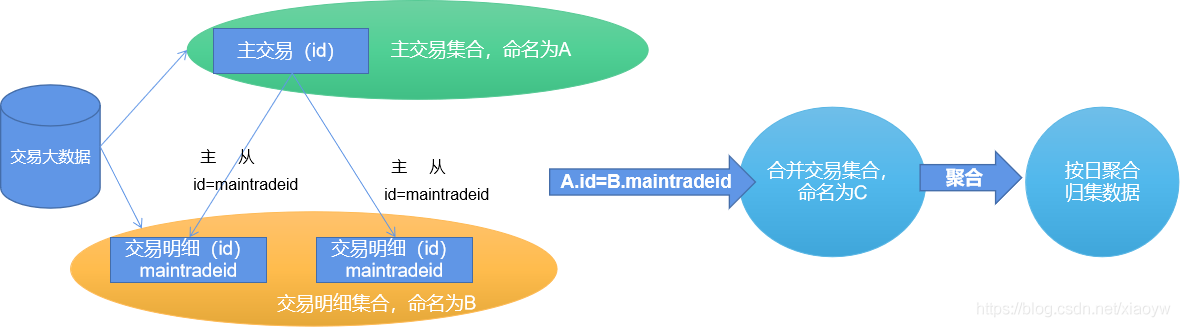
Aplikasi ini ialah data besar transaksi tertentu, yang terutamanya termasuk jadual induk transaksi, maklumat pelanggan yang berkaitan, maklumat material, harga sejarah, maklumat diskaun dan mata, dll. Jadual transaksi utama ialah struktur Jadual pokok persatuan diri.
Untuk menganalisis tingkah laku dagangan pelanggan, di bawah syarat sumber terhad, butiran transaksi diekstrak dan disusun mengikut hari dan titik dagangan ke dalam rekod transaksi, seperti yang ditunjukkan dalam rajah di bawah.
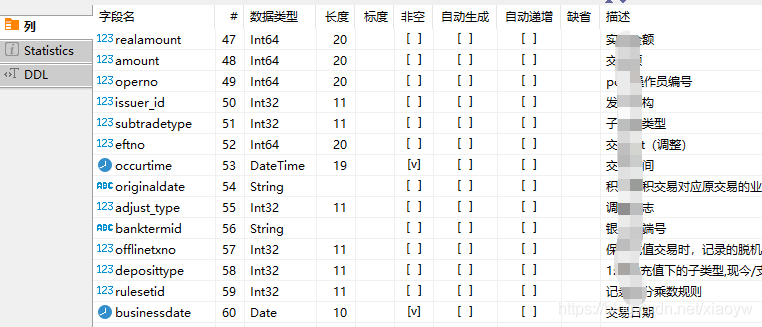
其中,在ClickHouse上,交易数据结构由60个列(字段)组成,截取部分如下所示:
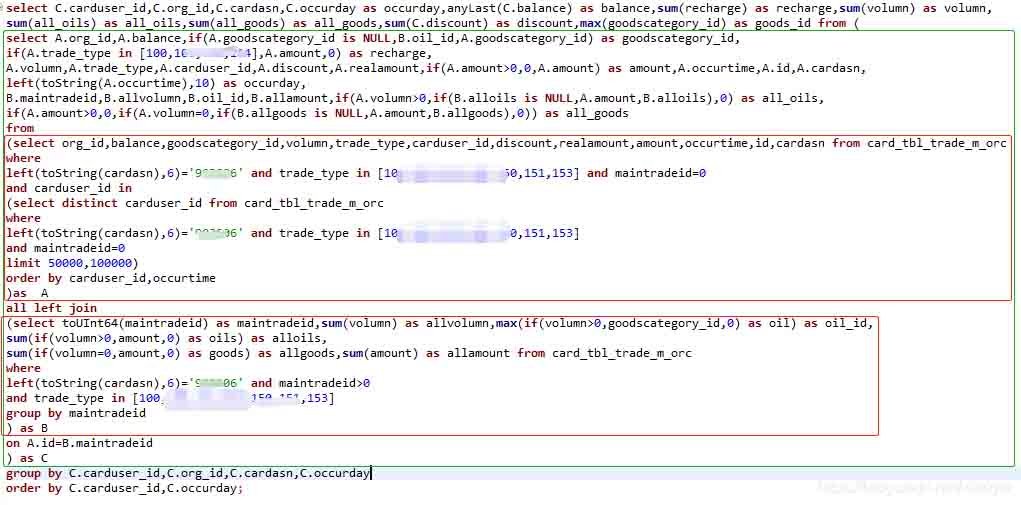
针对频繁出现“would use 10.20 GiB , maximum: 9.31 GiB”等内存不足的情况,基于ClickHouse的SQL,编写了提取聚合数据集SQL语句,如下所示。
大约60s返回结果,如下所示:

2. Python使用ClickHouse实践
2.1. ClickHouse第三方Python驱动clickhouse_driver
ClickHouse没有提供官方Python接口驱动,常用第三方驱动接口为clickhouse_driver,可以使用pip方式安装,如下所示:
pip install clickhouse_driver
Collecting clickhouse_driver
Downloading https://files.pythonhosted.org/packages/88/59/c570218bfca84bd0ece896c0f9ac0bf1e11543f3c01d8409f5e4f801f992/clickhouse_driver-0.2.1-cp36-cp36m-win_amd64.whl (173kB)
100% |████████████████████████████████| 174kB 27kB/s
Collecting tzlocal<3.0 (from clickhouse_driver)
Downloading https://files.pythonhosted.org/packages/5d/94/d47b0fd5988e6b7059de05720a646a2930920fff247a826f61674d436ba4/tzlocal-2.1-py2.py3-none-any.whl
Requirement already satisfied: pytz in d:\python\python36\lib\site-packages (from clickhouse_driver) (2020.4)
Installing collected packages: tzlocal, clickhouse-driver
Successfully installed clickhouse-driver-0.2.1 tzlocal-2.1使用的client api不能用了,报错如下:
File "clickhouse_driver\varint.pyx", line 62, in clickhouse_driver.varint.read_varint
File "clickhouse_driver\bufferedreader.pyx", line 55, in clickhouse_driver.bufferedreader.BufferedReader.read_one
File "clickhouse_driver\bufferedreader.pyx", line 240, in clickhouse_driver.bufferedreader.BufferedSocketReader.read_into_buffer
EOFError: Unexpected EOF while reading bytes
Python驱动使用ClickHouse端口9000。
ClickHouse服务器和客户端之间的通信有两种协议:http(端口8123)和本机(端口9000)。DBeaver驱动配置使用jdbc驱动方式,端口为8123。
ClickHouse接口返回数据类型为元组,也可以返回Pandas的DataFrame,本文代码使用的为返回DataFrame。
collection = self.client.query_dataframe(self.query_sql)
2.2. 实践程序代码
由于我本机最初资源为8G内存(现扩到16G),以及实际可操作性,分批次取数据保存到多个文件中,每个文件大约为1G。
# -*- coding: utf-8 -*-
'''
Created on 2021年3月1日
@author: xiaoyw
'''
import pandas as pd
import json
import numpy as np
import datetime
from clickhouse_driver import Client
#from clickhouse_driver import connect
# 基于Clickhouse数据库基础数据对象类
class DB_Obj(object):
'''
192.168.17.61:9000
ebd_all_b04.card_tbl_trade_m_orc
'''
def __init__(self, db_name):
self.db_name = db_name
host='192.168.17.61' #服务器地址
port ='9000' #'8123' #端口
user='***' #用户名
password='***' #密码
database=db_name #数据库
send_receive_timeout = 25 #超时时间
self.client = Client(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
#self.conn = connect(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
def setPriceTable(self,df):
self.pricetable = df
def get_trade(self,df_trade,filename):
print('Trade join price!')
df_trade = pd.merge(left=df_trade,right=self.pricetable[['occurday','DIM_DATE','END_DATE','V_0','V_92','V_95','ZDE_0','ZDE_92',
'ZDE_95']],how="left",on=['occurday'])
df_trade.to_csv(filename,mode='a',encoding='utf-8',index=False)
def get_datas(self,query_sql):
n = 0 # 累计处理卡客户数据
k = 0 # 取每次DataFrame数据量
batch = 100000 #100000 # 分批次处理
i = 0 # 文件标题顺序累加
flag=True # 数据处理解释标志
filename = 'card_trade_all_{}.csv'
while flag:
self.query_sql = query_sql.format(n, n+batch)
print('query started')
collection = self.client.query_dataframe(self.query_sql)
print('return query result')
df_trade = collection #pd.DataFrame(collection)
i=i+1
k = len(df_trade)
if k > 0:
self.get_trade(df_trade, filename.format(i))
n = n + batch
if k == 0:
flag=False
print('Completed ' + str(k) + 'trade details!')
print('Usercard count ' + str(n) )
return n
# 价格变动数据集
class Price_Table(object):
def __init__(self, cityname, startdate):
self.cityname = cityname
self.startdate = startdate
self.filename = 'price20210531.csv'
def get_price(self):
df_price = pd.read_csv(self.filename)
......
self.price_table=self.price_table.append(data_dict, ignore_index=True)
print('generate price table!')
class CardTradeDB(object):
def __init__(self,db_obj):
self.db_obj = db_obj
def insertDatasByCSV(self,filename):
# 存在数据混合类型
df = pd.read_csv(filename,low_memory=False)
# 获取交易记录
def getTradeDatasByID(self,ID_list=None):
# 字符串过长,需要使用'''
query_sql = '''select C.carduser_id,C.org_id,C.cardasn,C.occurday as
......
limit {},{})
group by C.carduser_id,C.org_id,C.cardasn,C.occurday
order by C.carduser_id,C.occurday'''
n = self.db_obj.get_datas(query_sql)
return n
if __name__ == '__main__':
PTable = Price_Table('湖北','2015-12-01')
PTable.get_price()
db_obj = DB_Obj('ebd_all_b04')
db_obj.setPriceTable(PTable.price_table)
CTD = CardTradeDB(db_obj)
df = CTD.getTradeDatasByID()返回本地文件为:
3. 小结一下
ClickHouse运用于OLAP场景时,拥有出色的查询速度,但需要具备大内存支持。Python第三方clickhouse-driver 驱动基本满足数据处理需求,如果能返回Pandas DataFrame最好。
ClickHouse和Pandas聚合都是非常快的,ClickHouse聚合函数也较为丰富(例如文中anyLast(x)返回最后遇到的值),如果能通过SQL聚合的,还是在ClickHouse中完成比较理想,把更小的结果集反馈给Python进行机器学习。
操作ClickHouse删除指定数据
def info_del2(i):
client = click_client(host='地址', port=端口, user='用户名', password='密码',
database='数据库')
sql_detail='alter table SS_GOODS_ORDER_ALL delete where order_id='+str(i)+';'
try:
client.execute(sql_detail)
except Exception as e:
print(e,'删除商品数据失败')在进行数据删除的时候,python操作clickhou和mysql的方式不太一样,这里不能使用以往常用的%s然后添加数据的方式,必须完整的编辑一条语句,如同上面方法所写的一样,传进去的参数统一使用str类型
Atas ialah kandungan terperinci Cara menggunakan ClickHouse dalam Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!