
Rumah >Peranti teknologi >AI >Peperiksaan AI dan peperiksaan awam hampir tiba! Pasukan Microsoft China mengeluarkan penanda aras baharu AGIEval, yang direka khas untuk peperiksaan manusia
Peperiksaan AI dan peperiksaan awam hampir tiba! Pasukan Microsoft China mengeluarkan penanda aras baharu AGIEval, yang direka khas untuk peperiksaan manusia

- PHPzke hadapan
- 2023-05-16 16:22:12998semak imbas
Apabila model bahasa menjadi semakin berkebolehan, penanda aras penilaian sedia ada ini benar-benar agak kebudak-budakan, dan prestasi beberapa tugasan jauh di belakang manusia.
Ciri penting kecerdasan am buatan (AGI) ialah keupayaan generalisasi model untuk mengendalikan tugas peringkat manusia, manakala penanda aras tradisional yang bergantung pada set data buatan tidak mewakili keupayaan manusia dengan tepat.
Baru-baru ini, penyelidik Microsoft mengeluarkan penanda aras baharu AGIEval, yang digunakan khusus untuk menilai model asas dalam Prestasi "human-centric" pada ujian piawai seperti Peperiksaan Masuk Kolej, Peperiksaan Perkhidmatan Awam, Peperiksaan Kemasukan Sekolah Undang-undang, Pertandingan Matematik dan Peperiksaan Bar.

Pautan kertas: https://arxiv.org/pdf/2304.06364.pdf
Pautan data: https://github.com/microsoft/AGIEval
Para penyelidik menilai menggunakan penanda aras AGIEval Tiga model asas tercanggih, termasuk GPT-4, ChatGPT dan Text-Davinci-003, keputusan eksperimen mendapati bahawa prestasi GPT-4 dalam pertandingan SAT, LSAT dan matematik melebihi tahap purata manusia, dan ketepatan Ujian matematik SAT tercapai Kadar ketepatan ujian Bahasa Inggeris Peperiksaan Masuk Kolej Cina mencapai 92.5%, menunjukkan prestasi luar biasa model asas semasa.
Tetapi GPT-4 kurang mahir dalam tugasan yang memerlukan penaakulan yang kompleks atau pengetahuan khusus domain Analisis menyeluruh tentang keupayaan model (pemahaman, pengetahuan, penaakulan dan pengiraan) mendedahkan perkara ini. Kekuatan dan batasan model.
AGIEval Dataset
Dalam beberapa tahun kebelakangan ini, model asas berskala besar seperti GPT-4 telah menunjukkan keupayaan yang sangat berkuasa dalam pelbagai bidang dan boleh membantu manusia dalam memproses kejadian harian , malah Ia juga boleh memberikan nasihat membuat keputusan dalam bidang profesional seperti undang-undang, perubatan dan kewangan.
Dalam erti kata lain, sistem kecerdasan buatan secara beransur-ansur menghampiri dan mencapai kecerdasan am buatan (AGI).
Tetapi apabila AI secara beransur-ansur disepadukan ke dalam kehidupan seharian, cara menilai keupayaan generalisasi berpusatkan manusia bagi model, mengenal pasti kelemahan yang berpotensi dan memastikan bahawa ia boleh mengendalikan tugasan yang kompleks dan berpusatkan manusia dengan berkesan , dan Menilai kemahiran menaakul untuk memastikan kebolehpercayaan dan kebolehpercayaan dalam konteks yang berbeza adalah kritikal.
Para penyelidik membina set data AGIEval terutamanya mengikut dua prinsip reka bentuk:
1 Tugasan Kognitif
Matlamat utama reka bentuk "berpusatkan manusia" adalah untuk memusatkan tugasan yang berkait rapat dengan kognisi manusia dan penyelesaian masalah, dan secara lebih Menilai keupayaan generalisasi model asas secara bermakna dan menyeluruh.
Untuk mencapai matlamat ini, para penyelidik memilih pelbagai kemasukan rasmi, awam, standard tinggi dan peperiksaan kelayakan yang memenuhi keperluan pengambil ujian manusia umum, termasuk peperiksaan kemasukan kolej, undang-undang peperiksaan kemasukan sekolah, peperiksaan matematik, peperiksaan bar dan peperiksaan perkhidmatan awam negeri yang diambil setiap tahun oleh berjuta-juta orang yang ingin memasuki pendidikan tinggi atau laluan kerjaya baharu.
Dengan mematuhi piawaian yang diiktiraf secara rasmi ini untuk menilai keupayaan peringkat manusia, AGIEval memastikan bahawa penilaian prestasi model berkaitan secara langsung dengan kebolehan manusia membuat keputusan dan kognitif.
2 Perkaitan dengan senario dunia sebenar
Dengan memilih daripada standard yang tinggi tugas peperiksaan kemasukan dan kelayakan memastikan keputusan penilaian mencerminkan kerumitan dan kepraktisan cabaran yang sering dihadapi oleh individu dalam bidang dan konteks yang berbeza.
Pendekatan ini bukan sahaja mengukur prestasi model dari segi kebolehan kognitif manusia, tetapi juga memberikan pemahaman yang lebih baik tentang kebolehgunaan dan keberkesanan dalam kehidupan sebenar, iaitu membantu dalam pembangunan Membangunkan kecerdasan buatan sistem yang lebih dipercayai, lebih praktikal dan lebih sesuai untuk menyelesaikan pelbagai masalah dunia sebenar.
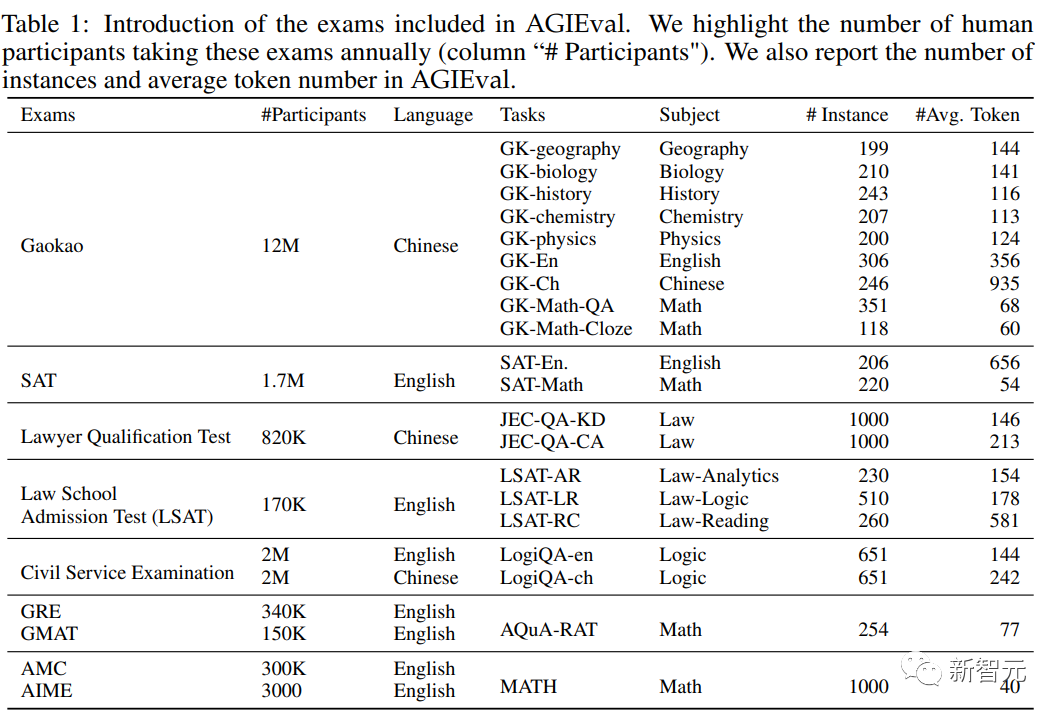
Berdasarkan prinsip reka bentuk di atas, penyelidik memilih pelbagai peperiksaan standard dan berkualiti tinggi yang menekankan penaakulan peringkat manusia dan perkaitan dunia sebenar , Secara khusus termasuk:
1 Peperiksaan Masuk Kolej Am
Peperiksaan Masuk Kolej termasuk. pelbagai Mata pelajaran yang memerlukan pemikiran kritis, penyelesaian masalah dan kemahiran analitikal dan sesuai untuk menilai prestasi model bahasa yang besar berhubung dengan kognisi manusia.
Terutama termasuk Peperiksaan Rekod Siswazah (GRE), Ujian Penilaian Akademik (SAT) dan Peperiksaan Masuk Kolej China (Gaokao), yang boleh menilai kebolehan am dan pengetahuan khusus subjek pelajar memohon kemasukan ke institusi pengajian tinggi .
Set data mengumpul peperiksaan yang sepadan dengan 8 mata pelajaran Peperiksaan Masuk Kolej Cina: sejarah, matematik, Bahasa Inggeris, Bahasa Cina, geografi, biologi, kimia dan fizik terpilih daripada GRE ; mata pelajaran Bahasa Inggeris dan matematik telah dipilih daripada SAT untuk membina set data penanda aras.
2. Ujian Kemasukan Sekolah Undang-undang
Ujian Kemasukan Sekolah Undang-undang, seperti LSAT , Direka untuk mengukur kebolehan penaakulan dan analisis pelajar undang-undang masa hadapan, peperiksaan merangkumi bahagian seperti penaakulan logik, pemahaman bacaan, dan penaakulan analisis Ia memerlukan pengambil ujian untuk menganalisis maklumat yang kompleks dan membuat kesimpulan yang tepat model bahasa dalam penaakulan undang-undang dan kemahiran analisis.
3. Peperiksaan Peguam
boleh menilai kecekapan undang-undang seseorang individu yang mengikuti pengajian kerjaya undang-undang Pengetahuan, kemahiran analisis dan pemahaman etika Peperiksaan merangkumi pelbagai topik undang-undang, termasuk undang-undang perlembagaan, undang-undang kontrak, undang-undang jenayah dan undang-undang harta, dan memerlukan calon untuk menunjukkan keupayaan mereka untuk menggunakan prinsip dan alasan perundangan dengan berkesan ujian boleh menunjukkan pengetahuan undang-undang profesional dan pertimbangan etika Menilai prestasi model bahasa dalam konteks
4. Ujian Kemasukan Pengurusan Siswazah (GMAT)
GMAT adalah piawaian The. peperiksaan boleh menilai kebolehan analitikal, kuantitatif, lisan dan komprehensif pelajar lepasan sekolah perniagaan masa depan Ia terdiri daripada penilaian penulisan analitikal, penaakulan komprehensif, penaakulan kuantitatif dan penaakulan lisan Ia menilai pemikiran kritis pengambil ujian, menganalisis data dan komunikasi yang berkesan. kebolehan.
5 Pertandingan Matematik Sekolah Menengah
Pertandingan ini merangkumi pelbagai bidang matematik. topik, Termasuk teori nombor, algebra, geometri dan kombinatorik, dan sering mengemukakan masalah bukan rutin yang memerlukan penyelesaian kreatif.
Secara khusus termasuk Pertandingan Matematik Amerika (AMC) dan Peperiksaan Matematik Jemputan Amerika (AIME), yang boleh menguji keupayaan matematik, kreativiti dan keupayaan menyelesaikan masalah pelajar, dan boleh menilai selanjutnya pemprosesan model bahasa Keupayaan untuk menyelesaikan masalah matematik yang kompleks dan kreatif, dan keupayaan model untuk menjana penyelesaian baru.
6. Peperiksaan Perkhidmatan Awam Dalam Negeri
boleh menilai kelayakan individu yang mencari kemasukan ke dalam perkhidmatan awam Kompetensi dan kemahiran, peperiksaan merangkumi penilaian pengetahuan am, kebolehan penaakulan, kemahiran bahasa, dan kepakaran dalam mata pelajaran tertentu yang berkaitan dengan peranan dan tanggungjawab pelbagai jawatan perkhidmatan awam di China model dalam konteks pentadbiran awam, dan Potensi mereka untuk pembangunan dasar, proses membuat keputusan dan penyampaian perkhidmatan awam.
Hasil penilaian
Model yang dipilih termasuk:
ChatGPT, perbualan yang dibangunkan oleh OpenAI Model AI baharu yang boleh melibatkan diri dalam interaksi pengguna dan perbualan dinamik, dilatih menggunakan set data arahan besar-besaran dan ditala selanjutnya melalui pembelajaran pengukuhan dengan maklum balas manusia (RLHF), membolehkannya menyampaikan kandungan kontekstual dan koheren selaras dengan jangkaan manusia.
GPT-4, sebagai model GPT generasi keempat, mengandungi rangkaian asas pengetahuan yang lebih luas dan mempamerkan prestasi peringkat manusia dalam banyak senario aplikasi. GPT-4 telah diubahsuai berulang kali menggunakan ujian lawan dan ChatGPT, menghasilkan peningkatan ketara dalam fakta, kebolehbootan dan pematuhan peraturan.
Teks-Davinci-003 ialah versi pertengahan antara GPT-3 dan GPT-4, yang lebih baik daripada GPT selepas halus- penalaan melalui arahan -3 berprestasi lebih baik.
Selain itu, skor purata dan markah tertinggi pengambil ujian manusia juga dilaporkan dalam eksperimen sebagai had tahap manusia untuk setiap tugas, tetapi ia tidak mewakili sepenuhnya perkara yang mungkin dilakukan oleh manusia. mempunyai pelbagai kemahiran dan pengetahuan.
Penilaian sifar/Penilaian beberapa pukulan
Dalam penetapan sampel sifar, model menilai secara langsung Penilaian masalah; dalam beberapa tugasan, sebilangan kecil contoh (seperti 5) daripada tugasan yang sama dimasukkan sebelum penilaian pada sampel ujian.
Untuk menguji lagi keupayaan penaakulan model, gesaan rantaian pemikiran (CoT) turut diperkenalkan dalam eksperimen, iaitu, mula-mula masukkan gesaan "Mari kita fikirkan langkah mengikut langkah" untuk menjana penjelasan bagi soalan yang diberikan. Kemudian masukkan gesaan "Penjelasan ialah" untuk menjana jawapan akhir berdasarkan penjelasan.
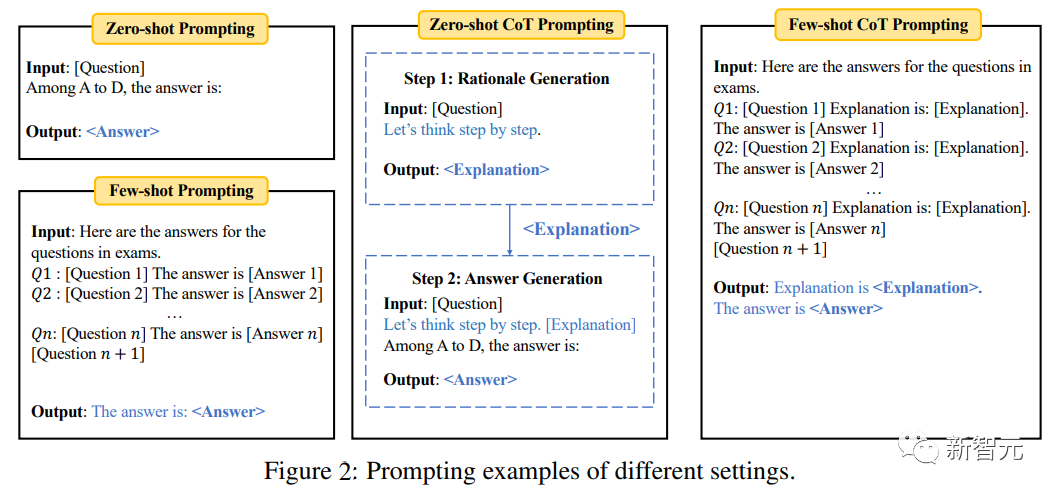
"soalan aneka pilihan" dalam penanda aras menggunakan ketepatan pengelasan standard; soalan kosong" gunakan padanan tepat (EM ) dan penunjuk F1.
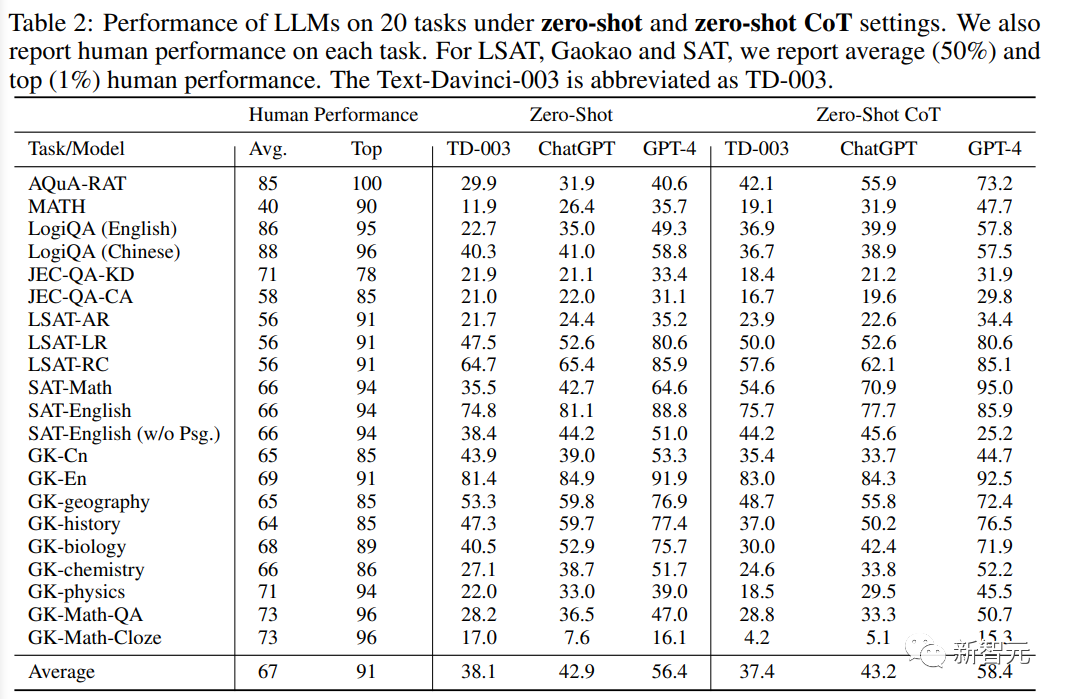
Ia boleh didapati daripada keputusan eksperimen:
1. GPT-4 dengan ketara mengatasi rakan sejawatannya dalam semua tetapan tugas , mencapai ketepatan 93.8% pada Gaokao-Bahasa Inggeris dan ketepatan 95% pada SAT-MATH, menunjukkan GPT-4 mempunyai keupayaan umum yang sangat baik dalam mengendalikan tugas berpusatkan manusia.
2. ChatGPT dengan ketara mengatasi Text-Davinci-003 dalam tugasan yang memerlukan pengetahuan luaran, seperti yang melibatkan geografi, biologi, kimia, fizik dan matematik , menunjukkan bahawa ChatGPT mempunyai pangkalan pengetahuan yang lebih kukuh dan lebih mampu mengendalikan tugasan yang memerlukan pemahaman mendalam tentang domain tertentu.
Sebaliknya, ChatGPT sedikit mengatasi Text-Davinci- merentas semua tetapan penilaian dalam tugasan yang memerlukan pemahaman tulen dan tidak terlalu bergantung pada pengetahuan luar, seperti tugasan Bahasa Inggeris dan LSAT. 003, atau keputusan yang setara. Pemerhatian ini bermakna kedua-dua model mampu mengendalikan tugas yang berpaksikan pemahaman bahasa dan penaakulan logik tanpa memerlukan pengetahuan domain khusus.
3 Walaupun prestasi keseluruhan model ini baik, semua model bahasa berprestasi lemah dalam tugasan inferens yang kompleks, seperti MATH dan LSAT-AR , GK-. fizik, dan GK-Math, menonjolkan batasan model ini dalam mengendalikan tugas yang memerlukan penaakulan lanjutan dan kemahiran menyelesaikan masalah.
Kesukaran yang diperhatikan dalam mengendalikan masalah inferens kompleks menyediakan peluang untuk penyelidikan dan pembangunan masa depan yang bertujuan untuk meningkatkan keupayaan inferens umum model.
4 Berbanding dengan pembelajaran sifar pukulan, pembelajaran beberapa pukulan biasanya hanya boleh membawa peningkatan prestasi yang terhad, menunjukkan bahawa model bahasa pukulan sifar semasa Pembelajaran pukulan keupayaan menghampiri keupayaan pembelajaran beberapa pukulan, yang juga menandakan peningkatan besar daripada model asal GPT-3, apabila prestasi beberapa pukulan adalah lebih baik daripada pukulan sifar.
Penjelasan yang munasabah untuk perkembangan ini ialah peningkatan pelarasan manusia dan pelarasan kepada arahan dalam model bahasa semasa ini membolehkan model memahami tugasan dan konteks lebih awal , dengan itu membolehkan mereka beraksi dengan baik walaupun dalam situasi sifar pukulan, membuktikan keberkesanan arahan.
Atas ialah kandungan terperinci Peperiksaan AI dan peperiksaan awam hampir tiba! Pasukan Microsoft China mengeluarkan penanda aras baharu AGIEval, yang direka khas untuk peperiksaan manusia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI