
Rumah >Peranti teknologi >AI >Amalan algoritma pembelajaran mendalam NIO
Amalan algoritma pembelajaran mendalam NIO

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-15 11:07:061669semak imbas

1. Latar belakang perniagaan NIO Power
1 Sistem perkhidmatan tenaga NIO
Matlamat pasukan perniagaan NIO Power adalah untuk membina sistem perkhidmatan tenaga pintar yang inovatif secara global, penyelesaian kuasa berasaskan Internet mudah alih, dengan rangkaian kemudahan pengecasan dan pertukaran yang meluas, dan untuk membina "boleh dipercayai " rangkaian bekalan kuasa berdasarkan teknologi awan NIO. Sistem perkhidmatan tenaga "boleh dicas semula, boleh diganti dan boleh dinaik taraf" menyediakan pemilik kereta dengan perkhidmatan kuasa senario penuh.

2. Cabaran pengendalian dan penyelenggaraan peralatan
Perkhidmatan operasi dan penyelenggaraan peralatan kuasa NIO terutamanya termasuk stesen pertukaran kuasa NIO, cerucuk pengecasan super NIO, cerucuk pengecasan rumah 7KW 2.0, cerucuk pengecas cepat rumah 20KW dan peralatan lain pada masa ini perkhidmatan ini menghadapi banyak cabaran, terutamanya termasuk:
① Pastikan peralatan tidak mempunyai bahaya keselamatan.
② Aduan pengguna: Pengalaman kuasa yang lemah.
③ Kadar kejayaan pengecasan dan pertukaran dikurangkan kerana kegagalan peralatan.
④ Masa hentikan akibat kegagalan peralatan.
⑤ Kos operasi dan penyelenggaraan adalah tinggi.
2. Penyelesaian operasi dan penyelenggaraan peralatan NIO Power
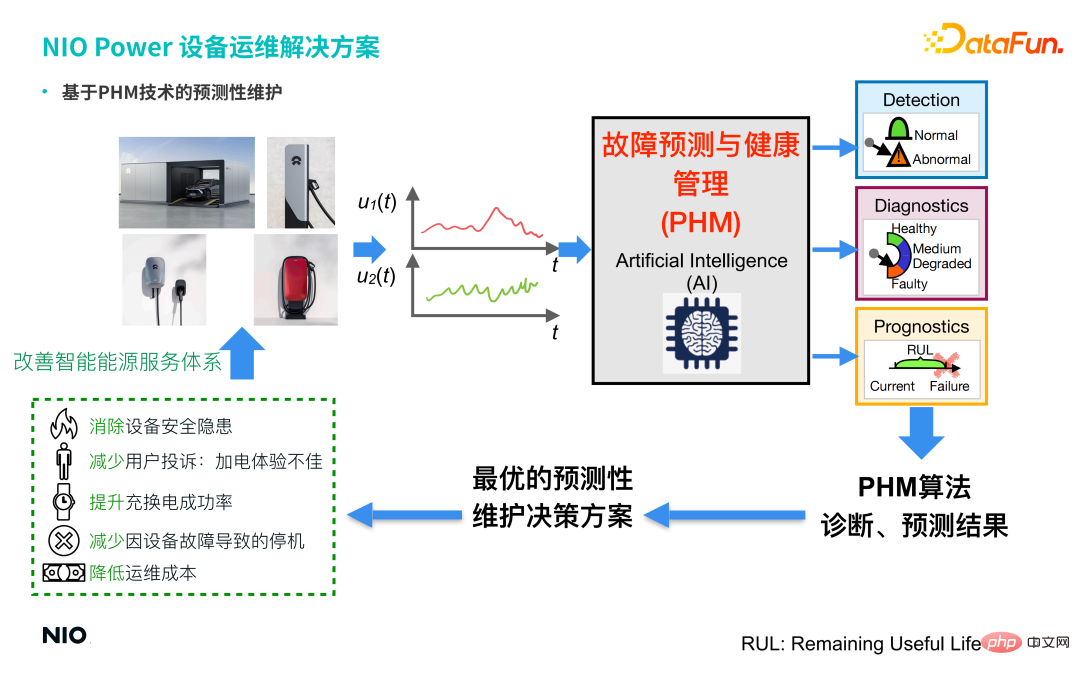
Empat jenis peralatan pengecasan dan nyahcas utama syarikat (stesen swap bateri, cerucuk pengecasan super, cerucuk pengecasan rumah 7KW, cerucuk pengecasan cepat rumah 20KW) semuanya mengandungi sejumlah besar penderia, jadi data yang dikumpul oleh penderia dalam masa nyata disatukan dan disambungkan kepada storan dan pengurusan Bersepadu Awan Tenaga NIO dijalankan, dan teknologi penyelenggaraan ramalan berdasarkan PHM (Ramalan Kesalahan dan Pengurusan Kesihatan) diperkenalkan Melalui satu siri algoritma AI, seperti GAN (Generative Adversarial Network ) dan Conceptor (Conceptor Network), status pengesanan abnormal peralatan diperoleh dan diagnosis kerosakan, dan menyediakan penyelesaian membuat keputusan penyelenggaraan ramalan yang optimum untuk peralatan berdasarkan keputusan ramalan diagnosis, dan mengeluarkan perintah operasi dan penyelenggaraan yang berkaitan. untuk mencapai:
① Hapuskan bahaya keselamatan peralatan.
② Kurangkan aduan pengguna tentang pengalaman kuasa yang lemah.
③ Tingkatkan kadar kejayaan pengecasan dan pertukaran.
④ Kurangkan masa henti yang disebabkan oleh kegagalan peralatan.
⑤ Kurangkan kos operasi dan penyelenggaraan.
Oleh itu, pengenalan teknologi dan algoritma PHM telah membantu syarikat menambah baik sistem perkhidmatan tenaga pintarnya dan membentuk gelung tertutup, dengan itu menambah baik dan mengoptimumkan keupayaan perkhidmatan NIO Power.
3. Cabaran yang dihadapi oleh teknologi PHM
Teknologi PHM semasa semuanya berdasarkan teknologi kecerdasan buatan dipacu data dan "didorong data " bergantung pada Sebilangan besar sampel dan label digunakan untuk membina model, dan model sering dibina di bawah senario yang ideal, tetapi senario sebenar selalunya tidak sesuai.
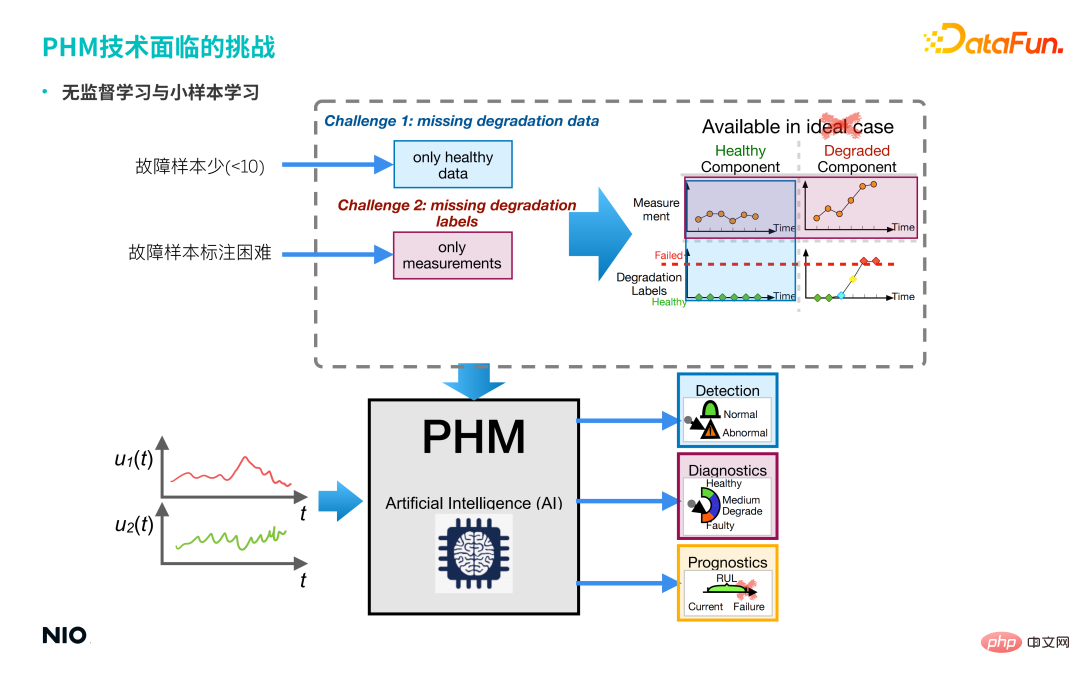
Seperti yang dapat dilihat daripada gambar di atas, adegan sebenar selalunya mempunyai ciri-ciri berikut:
① Beberapa sampel kerosakan.
② Sukar untuk melabelkan sampel kesalahan.
Ini membawa kepada dua jenis masalah yang dihadapi dalam senario ini: satu masalah pembelajaran tanpa pengawasan, dan satu lagi masalah pembelajaran sampel kecil.
4. Teknologi canggih PHM
Sebagai tindak balas kepada dua jenis masalah yang dihadapi dalam senario sebenar, kami telah mencadangkan berikut Beberapa teknologi PHM termaju digunakan dalam senario NIO Power.
1. Pengesanan anomali tanpa pengawasan berdasarkan Generative Adversarial Network (GAN)
(1) Struktur GAN
Rangkaian permusuhan generatif, yang dicadangkan pada 2014, ialah sejenis teknologi pembelajaran tanpa pengawasan berdasarkan pembelajaran mendalam, terutamanya terdiri daripada dua sub-rangkaian: penjana dan diskriminator.
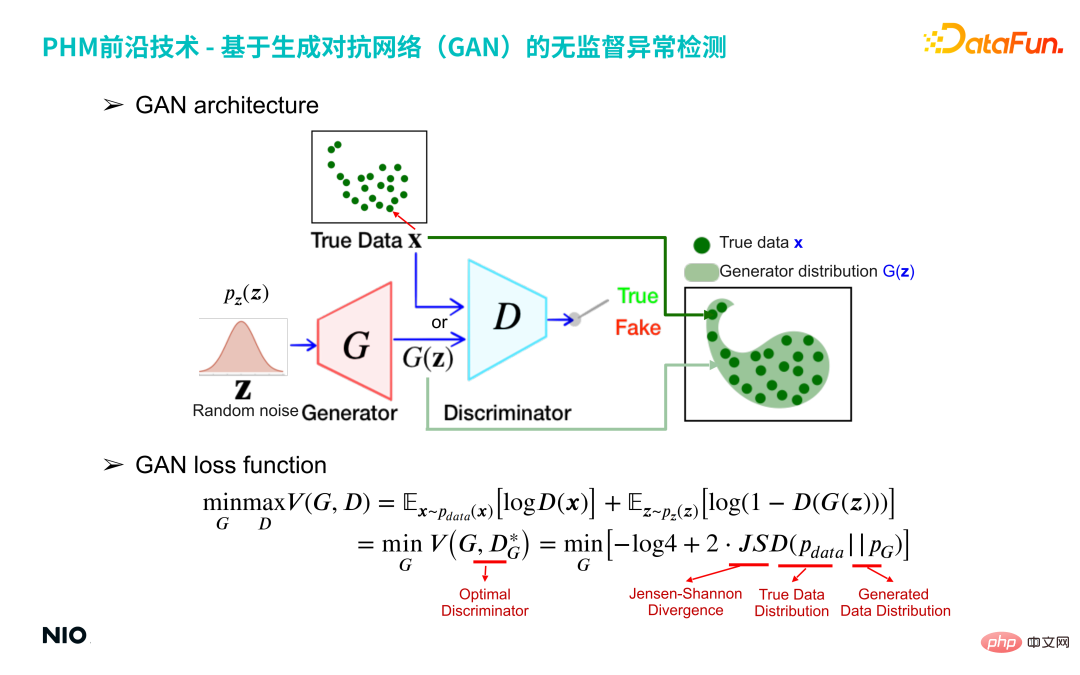
Rangkaian G merah dalam gambar di atas ialah rangkaian penjana, dan D biru rangkaian Iaitu rangkaian diskriminator.
Rangkaian penjana Memasukkan taburan nombor rawak (seperti taburan Gaussian) dan mengeluarkan taburan khusus yang ditentukan oleh pengguna; Dari perspektif sampel, 100 data yang diambil daripada taburan nombor rawak adalah input kepada rangkaian G. Rangkaian G akan memetakan 100 sampel ini ke dalam ruang yang sama dengan data sebenar untuk membentuk taburan G(z), dan. Rangkaian diskriminator digunakan untuk mendapatkan perbezaan antara dua taburan G(z) dan data sebenar X, dan kemudian rangkaian G dioptimumkan sehingga taburan G(z) hampir dengan taburan data sebenar X. Rangkaian G akan mengeluarkan 100 data ini dan membentuk pengedaran khusus G(z).
Inti rangkaian diskriminator adalah untuk membina anggaran taburan G(z) dan data sebenar x taburan Jensen-Shanon divergence, yang mengukur perbezaan antara taburan yang dijana dan taburan sebenar. Anggaran perbezaan Jensen-Shanon dilaksanakan melalui rangkaian pengelasan binari standard berdasarkan entropi silang binomial, dan output rangkaian diskriminator ialah nilai berterusan dari 0 hingga 1. Jika output adalah 1, ia dianggap bahawa sampel input X berasal dari taburan sebenar jika output adalah 0, sampel input X dianggap palsu dan palsu.
Dalam bentuk latihan rangkaian GAN, sampel yang dihasilkan oleh penjana cuba mendekati pengedaran sampel sebenar, manakala diskriminator cuba membezakan sampel yang dijana sebagai palsu , yang memberikan penjana dengan kecerunan nilai perbezaan Jensen-Shanon yang lebih tepat, membolehkan penjana bergerak ke arah yang lebih baik. Pada akhirnya, kedua-duanya membentuk hubungan konfrontasi Penjana "terdesak" menjana data palsu, dan diskriminator "terdesak" membezakan antara data input yang benar dan palsu. Rangkaian GAN akhirnya akan mencapai keadaan keseimbangan: pengedaran data yang dijana G(z) hanya meliputi pengedaran semua sampel sebenar X.
(2) Fungsi kehilangan GAN
Memahami rangkaian GAN dari perspektif matematik boleh difahami daripada kehilangan fungsi. Fungsi kehilangan boleh menggunakan fungsi nilai V(G, D) untuk mengoptimumkan parameter rangkaian G dan rangkaian D secara serentak melalui pengoptimuman minmax biasa untuk rangkaian G tertentu, matlamat pengoptimuman adalah untuk meminimumkan fungsi nilai, seperti yang ditunjukkan dalam formula berikut:
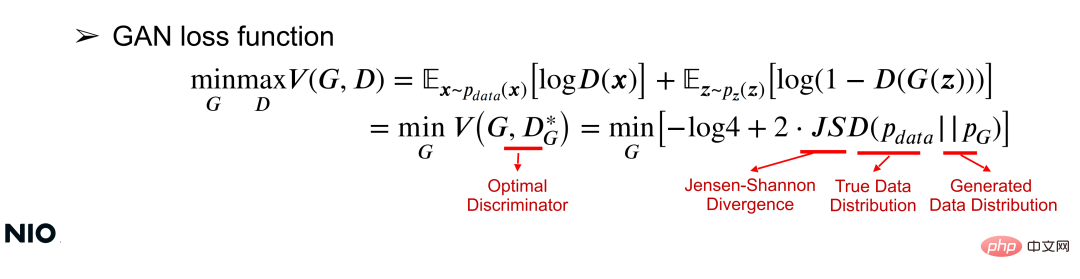
Dalam formula, JSD ialah istilah pengoptimuman teras bagi fungsi kehilangan, iaitu perbezaan antara dua taburan. Seperti yang dapat dilihat daripada formula, intipati pengoptimuman ini adalah untuk meminimumkan perbezaan pengedaran antara X dan G(z); semakin kecil perbezaan pengedaran, semakin berjaya rangkaian G dilatih.
(3) Auto-Pengekod dibantu GAN untuk Pengesanan Anomali (AE-GAN)
Berdasarkan rangkaian GAN , Memperkenalkan Auto-Pengekod untuk merealisasikan pengesanan anomali data pengendalian peralatan.
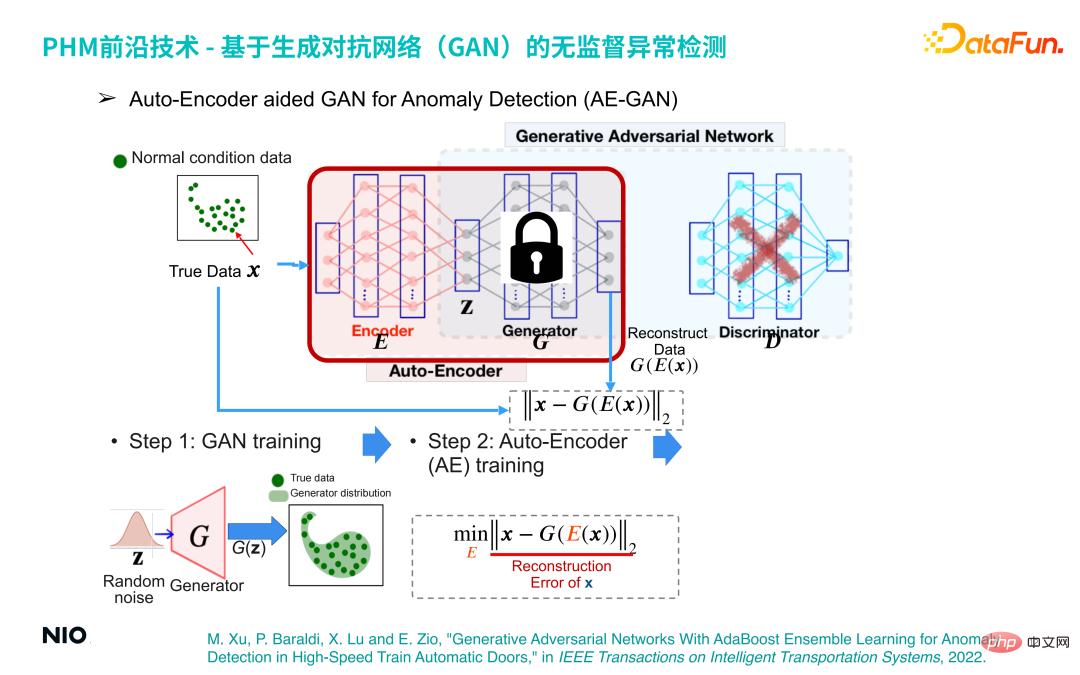
Kaedah pelaksanaan khusus ialah:
Langkah 1 , bina model GAN dan latih untuk mendapatkan rangkaian G, yang hanya membina semula pengedaran data pengendalian peralatan.
Langkah kedua ialah membuang bahagian rangkaian D dalam rangkaian GAN, menetapkan parameter rangkaian G dan memperkenalkan rangkaian Pengekod sebelum rangkaian G; cara, rangkaian Pengekod dan G Gabungan rangkaian membentuk satu set rangkaian Auto-Pengekod standard, dan fungsi kehilangan rangkaian ini ialah ralat pembinaan semula.
Dengan cara ini, kami boleh melengkapkan pengesanan anomali dengan mengoptimumkan rangkaian Auto-Pengekod Prinsip di sebaliknya ialah: tanpa mengira sampel input, melalui Auto -Rangkaian pengekod Sampel output akan berada dalam selang sampel biasa. Oleh itu, jika sampel input adalah sampel biasa, sampel yang dijana dan sampel asal berada dalam selang yang sama, jadi ralat pembinaan semula akan menjadi sangat kecil atau hampir kepada 0 dan jika sampel input adalah sampel tidak normal, yang dihasilkan sampel masih dalam selang sampel biasa Ini akan membawa kepada ralat pembinaan semula yang besar oleh itu, ralat pembinaan semula boleh digunakan untuk menentukan sama ada sampel adalah normal.
Langkah ketiga ialah mendapatkan satu siri markah ralat pembinaan semula melalui sekumpulan kecil sampel biasa, dan menggunakan nilai maksimumnya sebagai ambang ralat pembinaan semula untuk anomali pengesanan .
Prinsip ini telah dibincangkan sepenuhnya dalam kertas kerja, yang diterbitkan dalam IEEE dalam Transactions on Intelligent Transportation Systems pada 2022 , kertas itu maklumat adalah seperti berikut:
M. Xu, P. Baraldi, X. Lu dan E. Zio, "Rangkaian Adversarial Generatif Dengan Pembelajaran Ensemble AdaBoost untuk Pengesanan Anomali dalam Kelajuan Tinggi Latih Pintu Automatik," IEEE dalam Transaksi pada Sistem Pengangkutan Pintar, 2022.
2. Diagnosis kerosakan sampel kecil berdasarkan RNN (Konseptor) tanpa pengawasan
Jenis kedua teknologi yang kami gunakan ialah teknologi diagnosis kesalahan sampel kecil RNN (bernama Conceptor Network: Conceptor) tanpa pengawasan.
(1) RNN Tanpa pengawasan
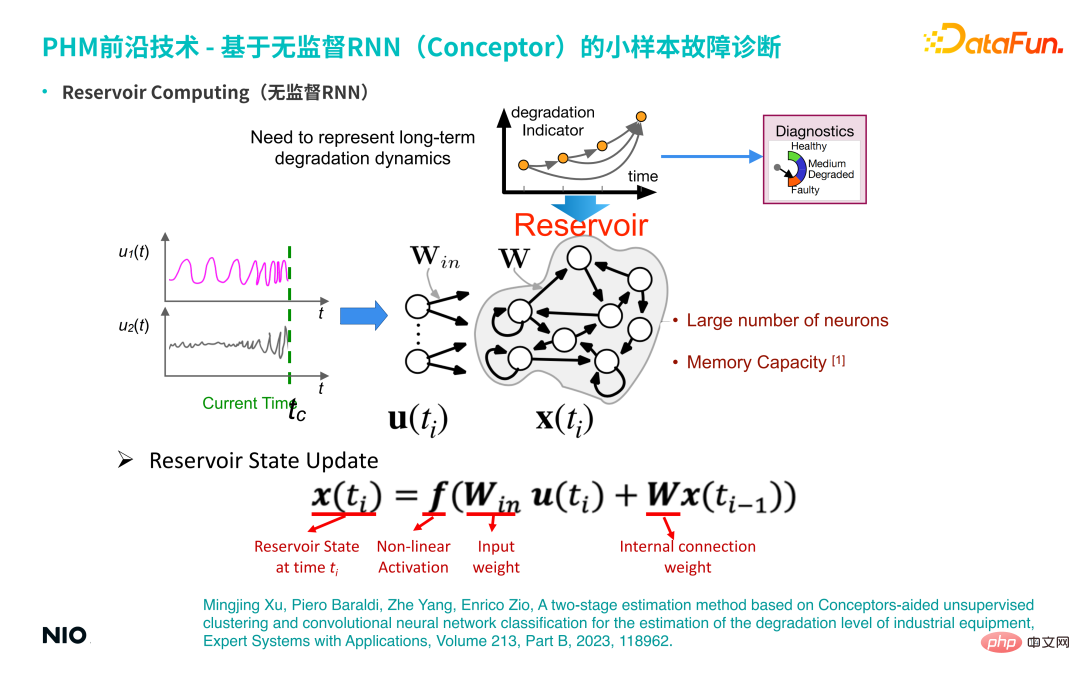
Pertama Perkenalkan dahulu latar belakang RNN tanpa pengawasan teknologi ini. Berbanding dengan RNN biasa, perkara paling istimewa tentang RNN tanpa pengawasan ialah berat sambungan neuron dalam lapisan input rangkaian dan berat sambungan lapisan tersembunyi dimulakan secara rawak dan ditetapkan semasa keseluruhan proses latihan dan inferens. Ini bermakna kita tidak perlu melatih parameter berat lapisan input dan lapisan tersembunyi oleh itu, berbanding dengan rangkaian RNN biasa, kita boleh menetapkan neuron lapisan tersembunyi menjadi sangat besar, supaya tempoh ingatan dan kapasiti memori; rangkaian akan Jika ia sangat besar, tempoh ingatan untuk siri masa input akan menjadi lebih lama. Neuron lapisan tersembunyi RNN khas tanpa pengawasan ini sering dipanggil Reservoir.
① Kemas Kini Negeri Takungan
Kaedah kemas kini keadaan adalah sama dengan kaedah kemas kini RNN standard.
② Perwakilan kebergantungan temporal jangka panjang oleh Conceptor
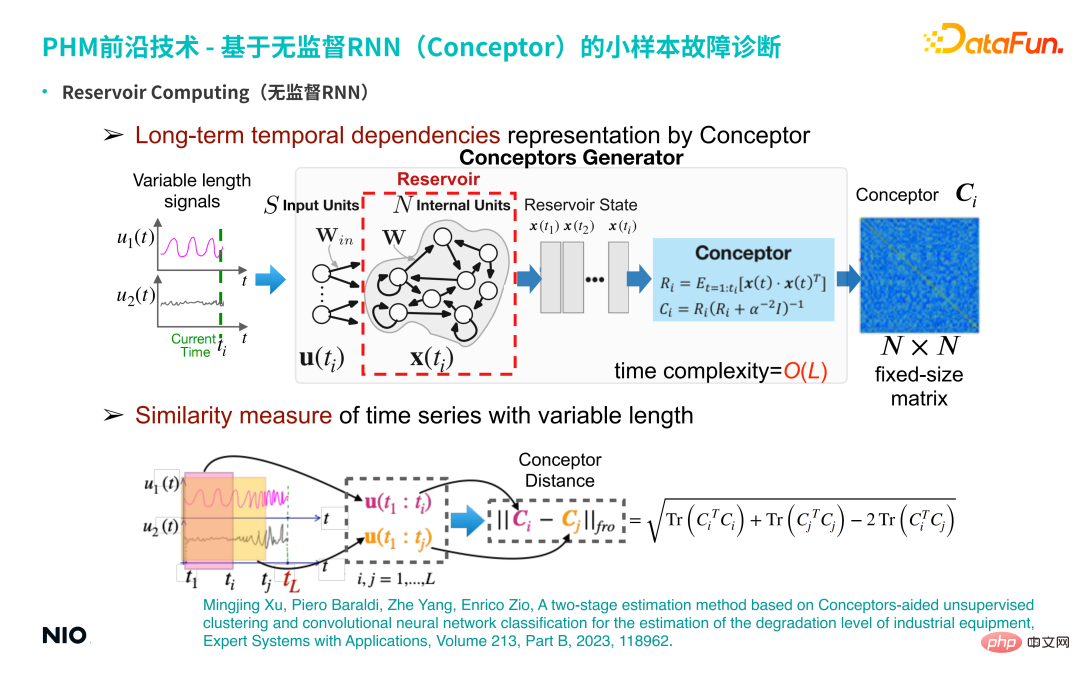
Bangunkan kaedah pembelajaran perwakilan tanpa pengawasan berdasarkan RNN tanpa pengawasan ini Secara khusus, masukkan siri masa berbilang dimensi dengan panjang pembolehubah, dan dapatkan neuron tersembunyi RNN bagi setiap langkah penggunaan Reservoir kaedah Conceptor (ditunjukkan dalam kotak biru muda dalam rajah di atas) untuk mendapatkan matriks konsep dimensi N×N. Difahamkan dari segi algebra linear, maksud matriks ini ialah: apabila memproses siri masa, untuk setiap langkah masa, isyarat siri masa diunjurkan ke dalam ruang N-dimensi (N sepadan dengan skala neuron tersembunyi).
Jika ada ti langkah masa, kemudian ti titik dalam ruang dimensi N membentuk awan titik tersebut ellipsoid boleh diuraikan ke arah N yang saling ortogon, dan vektor eigen dan nilai eigen dalam setiap arah diperoleh.
Peranan Conceptor adalah untuk menangkap nilai eigen dan vektor eigen dan menormalkan nilai eigen untuk N eigenvectors ini, ia boleh difahami sebagai sifat N yang ditangkap dalam siri masa (seperti berkala, aliran, turun naik dan ciri siri masa kompleks yang lain) ialah pengekstrakan ciri tersirat dan semua maklumat ciri yang diekstrak disimpan dalam matriks N-dimensi Tengah ini (iaitu, matriks Konsep, kotak biru gelap; di sebelah kanan rajah di atas).
③ Ukuran kesamaan siri masa dengan panjang berubah
Berdasarkan ciri asas matriks, kedua-duanya siri masa Matriks Conceptor dikurangkan dan norma Frobenius diekstrak, iaitu, jarak Konsep bagi dua siri masa diperolehi skalar ini boleh digunakan untuk mencirikan perbezaan antara dua siri masa.
(2) Diagnosis kesalahan sampel kecil berdasarkan Conceptor
Berdasarkan ciri Conceptor di atas, ia boleh digunakan untuk diagnosis kesalahan sampel kecil Analisis penyelesaian masalah sampel.
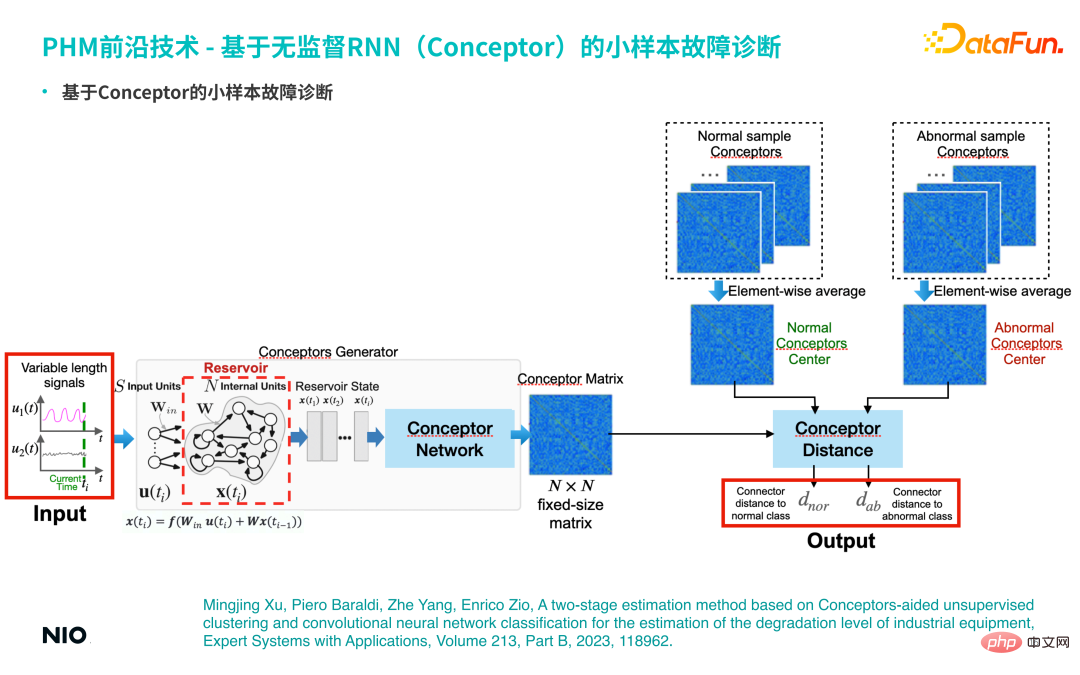
Jika terdapat sebilangan kecil sampel kerosakan sebenar (contohnya, kurang daripada 10 sampel kerosakan), yang sepadan siri masa Semua dimasukkan ke dalam rangkaian Conceptor dan diagregatkan untuk membentuk matriks konsep yang sepadan, yang berfungsi sebagai perwakilan abstrak bagi mod kerosakan kategori ini, sampel biasa juga akan diagregatkan ke dalam matriks konsep biasa. Semasa ujian, gunakan kaedah yang sama untuk mengekstrak matriks konsep yang sepadan daripada siri masa input, dan menjalankan analisis perbandingan dengan matriks konsep sampel normal dan sampel tidak normal untuk mengira perbezaan konsep yang sepadan. Jika persamaan antara sampel input dan matriks konsep mod kegagalan tertentu adalah tinggi, sampel boleh dianggap tergolong dalam mod kegagalan tersebut.
Kaedah ini juga dibincangkan sepenuhnya dalam kertas berikut:
Mingjing Xu , Piero Baraldi, Zhe Yang, Enrico Zio, Kaedah anggaran dua peringkat berdasarkan pengelompokan tanpa pengawasan berbantukan Konsep dan klasifikasi rangkaian saraf konvolusi untuk anggaran tahap kemerosotan peralatan industri, Sistem Pakar dengan Aplikasi, Jilid 213, Bahagian B, 2023 , 118962.
5 Kes aplikasi operasi pintar dan penyelenggaraan teknologi PHM
1 stesen swap bateri
(1) Latar Belakang
Rantai petak bateri di stesen swap bateri bekerjasama dengan petak bateri angkat untuk mengangkat bateri yang masuk ke gudang pengecasan untuk mengecas. Jika rantai rosak, ia mungkin longgar atau putus, yang boleh menyebabkan bateri tersekat semasa pengangkutan ke tong pengecasan dan menjadikannya mustahil untuk memasuki tong. Di samping itu, jika rantai putus, bateri akan jatuh, menyebabkan kerosakan bateri atau kemalangan kebakaran.
Oleh itu, adalah perlu untuk membina model untuk mengesan kelonggaran rantai terlebih dahulu, mencegah berlakunya kemalangan keselamatan yang berkaitan dengan lebih awal, dan meminimumkan risiko.
(2) Tetapan masalah

Pembolehubah utama secara langsung berkaitan dengan melonggarkan rantai Ia ialah isyarat berkaitan getaran Walau bagaimanapun, kos pengumpulan dan penyimpanan data getaran adalah tinggi, jadi kebanyakan peralatan tidak mengumpul isyarat berkaitan getaran.
Dalam kes kehilangan data getaran, kelonggaran rantai boleh dikesan melalui tork, kedudukan, kelajuan dan isyarat lain motor pemacu rantai.
(3) Analisis mekanisme industri
Membandingkan data rantai longgar dan data rantai biasa dalam rajah di bawah , anda boleh Adalah jelas bahawa kelonggaran rantai petak bateri akan menyebabkan turun naik berkala yang jelas dalam isyarat tork, dan amplitud turun naik akan menunjukkan arah aliran pengecilan.
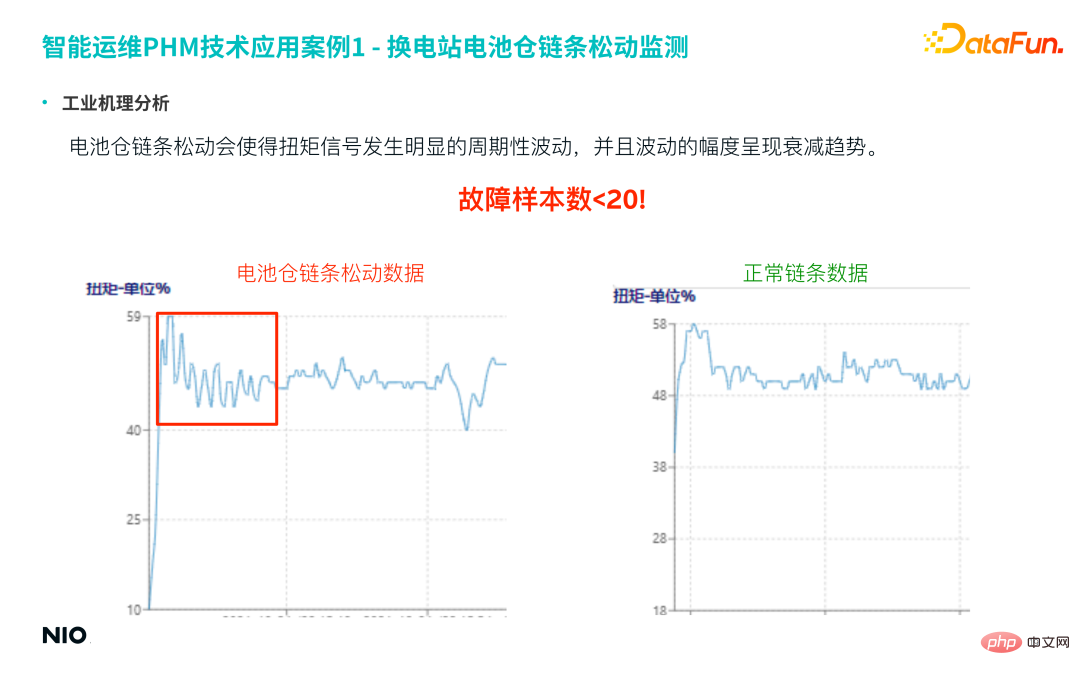
Bilangan sebenar sampel untuk kerosakan ini adalah sangat kecil, kurang daripada 20 sampel, bagaimanapun, jenis kesalahan ini adalah sangat penting, jadi ketepatan dan kadar ingat semula model ramalan adalah sangat tinggi.
(4) Reka bentuk model pengesanan kelonggaran rantai
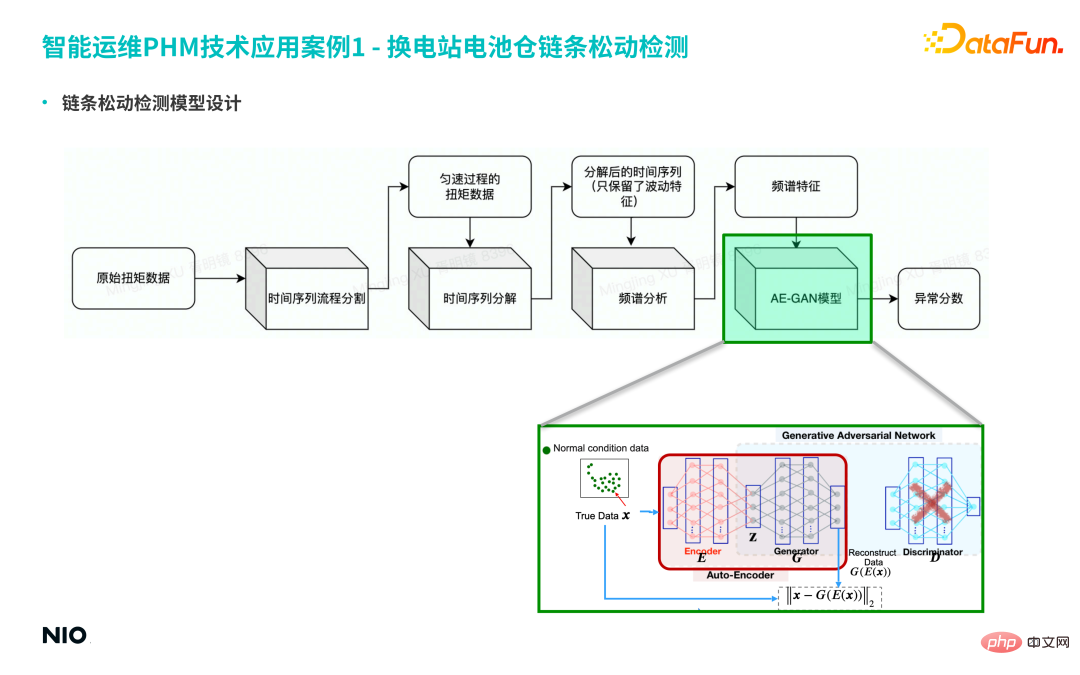
① Mula-mula, bahagikan data asal kepada siri masa, dan ekstrak data tork proses seragam daripada siri jangka panjang.
② Kemudian urai siri masa, hanya mengekalkan ciri turun naik siri masa.
③ Lakukan analisis spektrum selanjutnya pada jujukan, dan akhirnya dapatkan ciri spektrum.
Walau bagaimanapun, terdapat lebih daripada satu jalur frekuensi pada masa kegagalan, dan amplitud dalam jalur frekuensi yang berbeza mematuhi taburan tertentu gunakan kaedah tradisional untuk mengenal pasti Kadar yang lebih rendah akan menyebabkan lebih banyak penggera palsu dan penggera terlepas. Oleh itu, model AE-GAN dipilih untuk menangkap pengedaran kerosakan khusus dengan lebih tepat di bawah mod kerosakan, dan akhirnya memperoleh skor anomali peralatan.
(5) Data pengesanan kelonggaran rantai dan proses interaksi algoritma
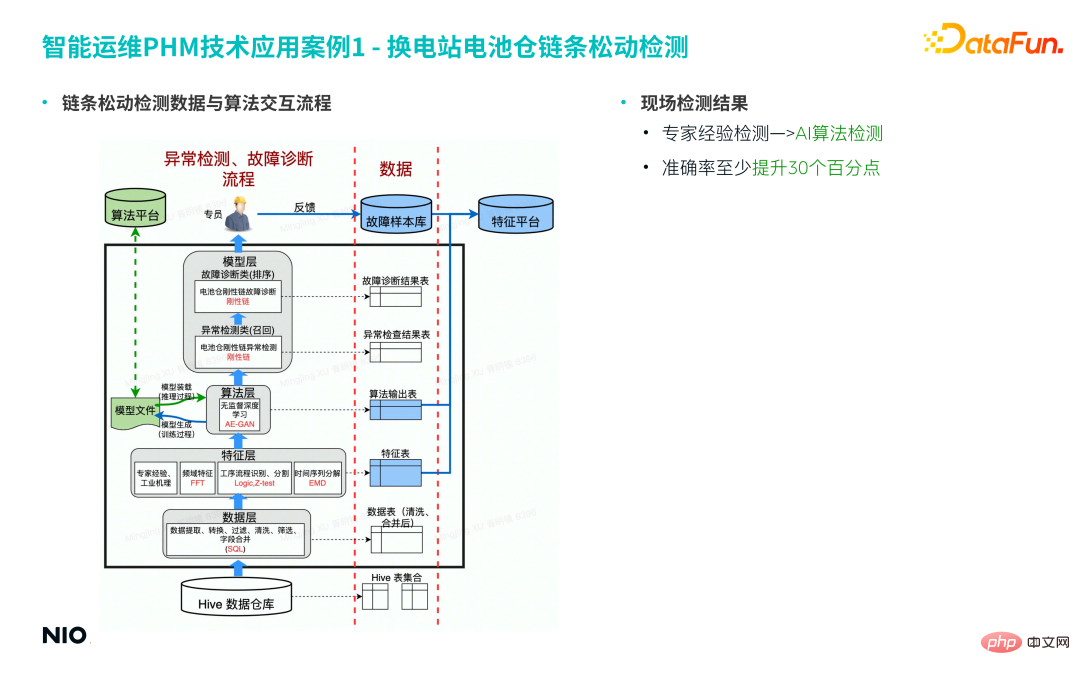
Interaksi antara data pengesanan longgar dan algoritma terutamanya termasuk lapisan berikut: gudang data, lapisan data, lapisan ciri, lapisan algoritma dan lapisan model.
Antaranya, lapisan ciri terutamanya modul algoritma yang terlibat dalam kejuruteraan ciri yang disebutkan di atas, dalam kes ini, lapisan algoritma menggunakan algoritma AE-GAN berdasarkan hasil skor anomali lapisan algoritma; dan jadual ciri dalam lapisan ciri Data direkodkan, dan penghakiman dan pembuatan keputusan selanjutnya dijalankan dalam lapisan model pesanan kerja output akhir dihantar kepada pakar untuk diproses.
Berdasarkan proses di atas, pengesanan pengalaman pakar tradisional dinaik taraf kepada pengesanan algoritma AI, dan kadar ketepatan meningkat lebih daripada 30%.
2. Diagnosis kesalahan kemerosotan hujung caj berlebihan
(1) Analisis mekanisme industri
Mula-mula, wujudkan model fizikal berdasarkan arus pengecasan, voltan, suhu dan isyarat fizikal lain bagi pistol pengecas untuk mendapatkan kuantiti fizikal pekali kenaikan suhu kepala pistol, dan gunakan ini sebagai isyarat ciri untuk diagnosis kerosakan selanjutnya. Walau bagaimanapun, kejuruteraan ciri berasaskan fizik jenis ini biasanya menggunakan tetingkap gelongsor masa untuk penjanaan ciri, dan akhirnya memperoleh siri masa baharu kerana hasil jujukan ciri tersebut selalunya bising.
Angka berikut ialah contoh Projek ini biasanya memilih satu minggu atau satu bulan data sebagai tetingkap masa untuk mendapatkan siri masa ciri yang serupa dengan angka tersebut di bawah. Ia boleh dilihat dari rajah bahawa bunyi jujukan ini adalah sangat besar, dan sukar untuk membezakan secara langsung antara sampel terdegradasi dan sampel biasa.
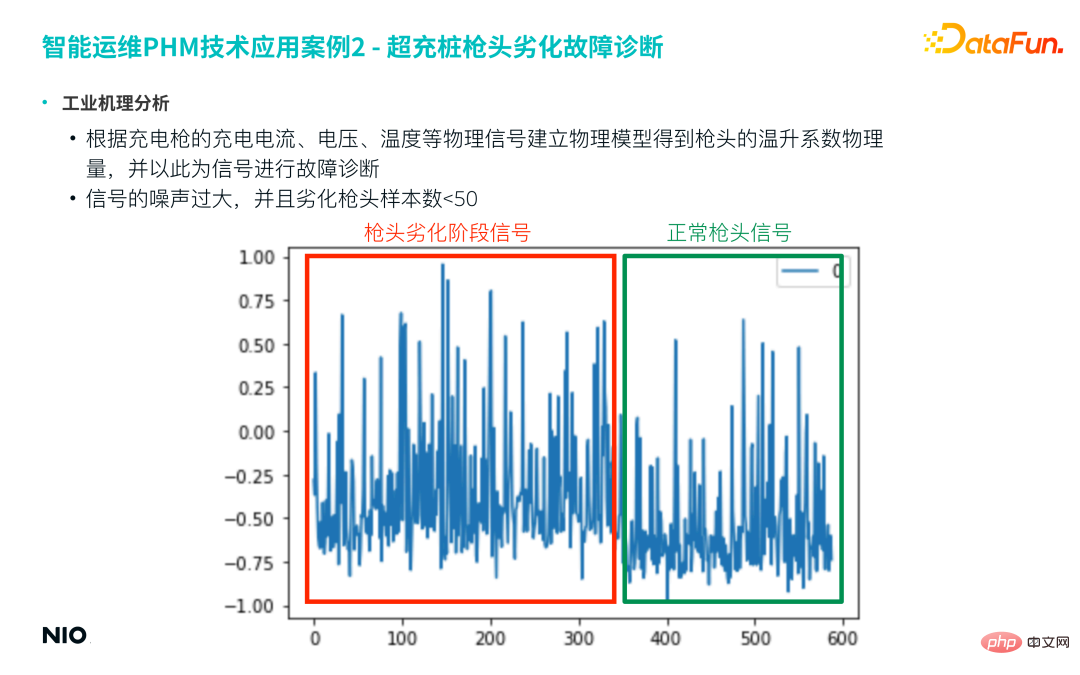
Selain itu, dalam sampel kegagalan sebenar, bilangan petua terdegradasi selalunya kurang daripada 50.
Berdasarkan dua sebab di atas, model Conceptor diperkenalkan untuk menyingkirkan pengalaman manual dan secara automatik menangkap ciri siri masa sampel terdegradasi melalui model.
(2) Proses diagnosis kerosakan
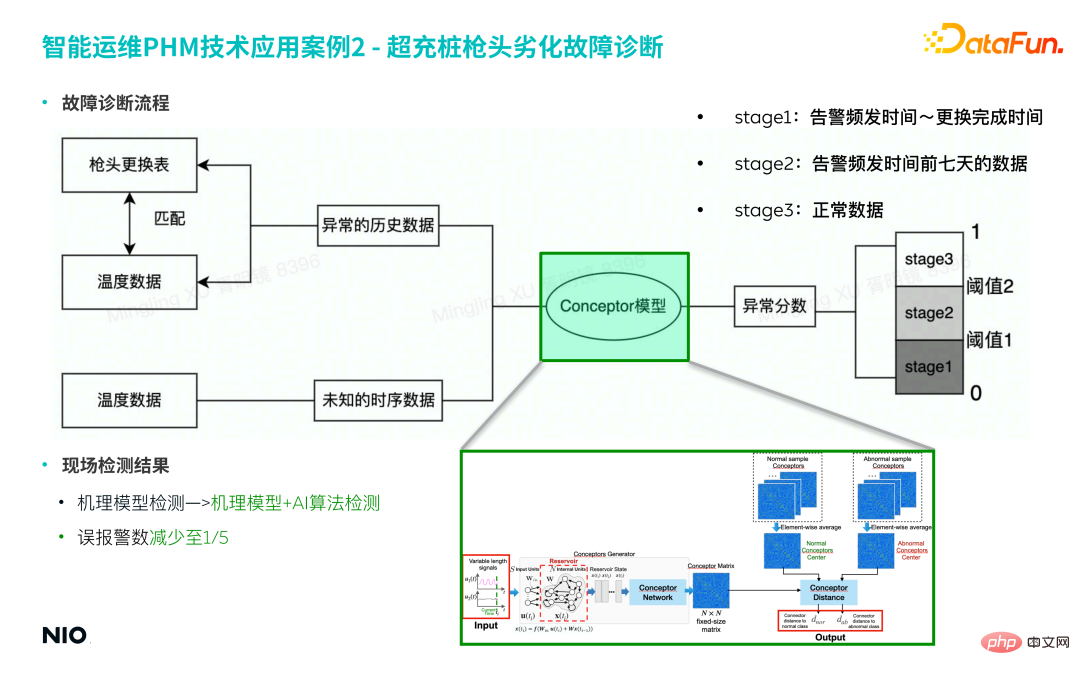
① Koleksi Data sampel kerosakan
- Syarikat telah menghasilkan beribu-ribu cerucuk pengecasan yang berlebihan, yang mana hanya berpuluh-puluh cerucuk pengecasan yang berlebihan telah digantikan petuanya.
- Padankan data sampel kerosakan bagi tempoh yang sepadan berdasarkan rekod penggantian hujung pistol sebagai set latihan untuk model.
- Data kerosakan mengandungi siri masa 6 dimensi dengan panjang jujukan yang berbeza-beza.
② Pembinaan Model
- Mekanisme fizikal di sebalik kerosakan ini agak kompleks, jadi Pemodelan berdasarkan pengetahuan terdahulu, pengalaman pakar dan mekanisme fizikal agak sukar untuk dilaksanakan, dan model itu sukar untuk digeneralisasikan.
- Kaedah model Conceptor yang disebut dalam artikel ini adalah berdasarkan kaedah dipacu data semata-mata dan tidak memperkenalkan sebarang ciri pengekstrakan maklumat fizikal terdahulu, yang boleh mengurangkan dengan ketara kerumitan model untuk meningkatkan kecekapan pemodelan.
- Menggunakan kaedah model Conceptor, data siri masa pelbagai dimensi bagi tempoh tidak normal dimasukkan ke dalam model untuk mendapatkan matriks perwakilan konsep yang sepadan.
a. Jika 50 sampel kerosakan dimasukkan, 50 matriks perwakilan konsep akan diperolehi; b. Agregat min bagi 50 matriks ini dan darabkannya dengan pusat graviti matriks pencirian bagi mod sesar untuk mendapatkan matriks pencirian di bawah mod sesar;
c. Dalam fasa ujian model, matriks konsep dikira untuk data ujian input, dan dibandingkan dengan matriks perwakilan mod kegagalan untuk mendapatkan skor anomali.
③ Amaran model
1) Berdasarkan keputusan model, 3 tahap berbeza dibahagikan terlebih dahulu Peraturan penggera digunakan untuk menilai mengikut tahap kemerosotan yang berbeza, dan akhirnya mencapai amaran awal hierarki.
- Berdasarkan proses di atas, menaik taraf kaedah pengesanan model mekanisme tradisional kepada model mekanisme yang digabungkan dengan kaedah pengesanan algoritma AI boleh mengurangkan penggera palsu model kadar kepada 1/5 daripada yang asal.
6 Sesi Soal JawabS1: Dalam model AE-GAN, bagaimana untuk membezakan sampel normal daripada sampel tidak normal. ?
A1: Untuk model AE-GAN terlatih, masukkan sampel ke Auto-Pengekod untuk mendapatkan ralat pembinaan semula sampel, iaitu skor anomali jika skor adalah kurang daripada yang ditentukan Jika ambang melebihi, sampel dianggap normal, jika tidak ia dianggap sebagai sampel tidak normal. Premis penggunaan kaedah ini ialah semua data latihan adalah data sampel biasa.
S2: Semasa melatih rangkaian GAN, adakah anda menggunakan campuran data kesalahan sampel kecil dan data biasa? Bagaimana untuk mengimbangi kedua-dua data?
A2: Apabila melatih rangkaian GAN, sama ada data biasa atau data tidak normal dalam mod tertentu tidak akan digunakan untuk latihan, jadi akan ada tiada Isu seperti ketidakseimbangan sampel. Jika terdapat jurang yang besar antara dua jenis sampel data dalam data sebenar, rangkaian GAN 1 secara amnya akan dilatih untuk sampel biasa, dan kemudian rangkaian GAN 2 akan dilatih untuk corak tetap sampel abnormal tertentu, dan sampel ujian akan diuji berdasarkan kesilapan pembinaan semula kedua-dua rangkaian.
S3: Adakah model runtuh berlaku semasa latihan GAN?
A3: Mod runtuh ialah masalah teras yang dihadapi dalam latihan model GAN. Pertama, fahami keruntuhan mod, dan kedua, fokus pada tugas teras latihan GAN.
Mod runtuh bermakna data yang dijana oleh penjana memfokus pada kawasan tertentu apabila ini berlaku sebabnya ialah takrifan fungsi kehilangan dalam rangkaian GAN diabaikan. Semasa proses latihan rangkaian GAN, kehilangan rangkaian G dan kehilangan rangkaian D biasanya dikira secara berasingan, dan fungsi kehilangan bersama kedua-dua rangkaian (iaitu, kehilangan JSD dalam formula) sering diabaikan. Jika mod latihan runtuh berlaku, kehilangan JSD selalunya tidak menumpu oleh itu, menggambarkan kehilangan JSD semasa proses latihan boleh mengelakkan keruntuhan mod. Ini juga merupakan sebab mengapa banyak versi model GAN yang dipertingkatkan baru-baru ini telah dapat menonjol dan menghasilkan hasil yang lebih baik di samping itu, memperkenalkan helah khusus ke dalam rangkaian GAN standard juga boleh mencapai kesan yang sama.
S4: Apakah kelebihan membetulkan lapisan tersembunyi RNN secara rawak?
A4: Untuk senario di mana terdapat jurang yang besar antara sampel positif dan negatif, jika anda menggunakan LSTM, RNN, GRNN dan model lain yang biasa digunakan, anda akan sering menghadapi masalah bahawa fungsi kehilangan tidak menumpu; oleh itu, jenis ini Cara untuk menangani masalah selalunya bermula dari pembelajaran tanpa pengawasan, secara rawak membetulkan berat lapisan tersembunyi rangkaian utama, dan menggunakan kaedah khusus untuk mengatur komponen ciri matriks konsep yang dijana walaupun parameter berat adalah rawak, perwakilan yang diperolehi Komponen boleh mencerminkan ciri tersembunyi siri masa dan cukup untuk membezakan adegan sampel kecil di atas adalah kelebihan lapisan tersembunyi RNN secara rawak tetap.
S5: Memperkenalkan bentuk rangkaian model Conceptor.
A5: Model ditunjukkan di bawah.
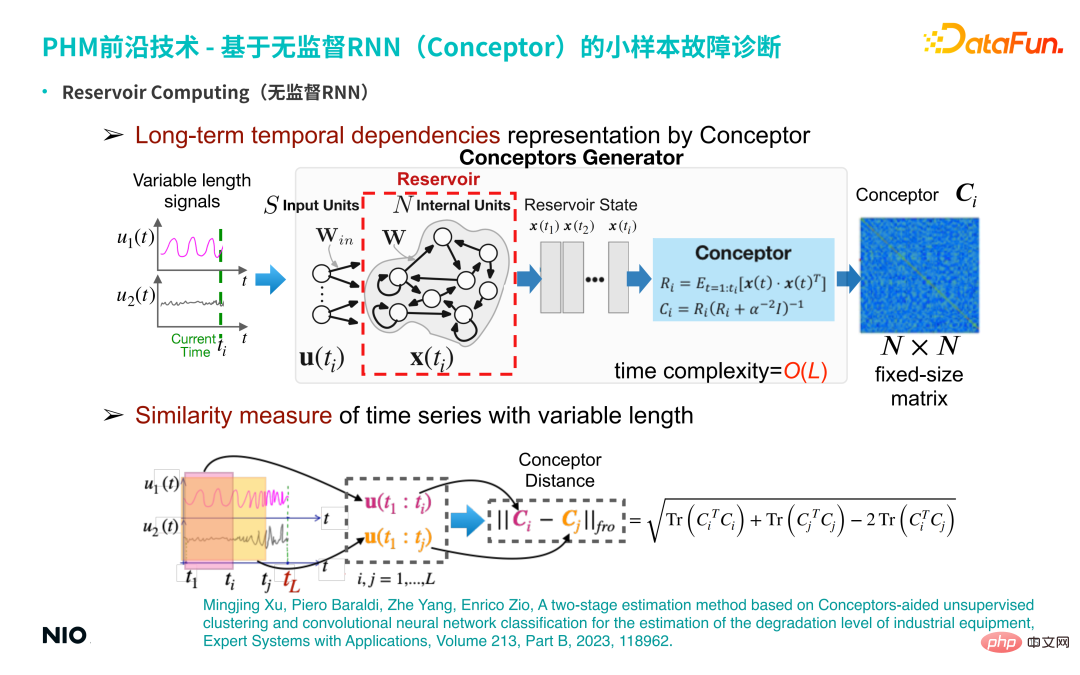
Antaranya, bahagian Rizab pada asasnya sama seperti rangkaian RNN biasa, iaitu satu-satunya perbezaan ialah Wdalam dan W ditetapkan secara rawak (perhatikan bahawa ia hanya dijana secara rawak sekali) ; seterusnya, untuk setiap langkah masa Keadaan tersembunyi neuron jangka panjang dikira dan dikemas kini, dan matriks konsep yang sepadan diperolehi. Di atas adalah versi lengkap Conceptor.
S6: Apakah proses latihan rangkaian Pengekod dalam AE-GAN? Apakah input dan output?
A6: Rajah berikut ialah proses latihan rangkaian Pengekod.
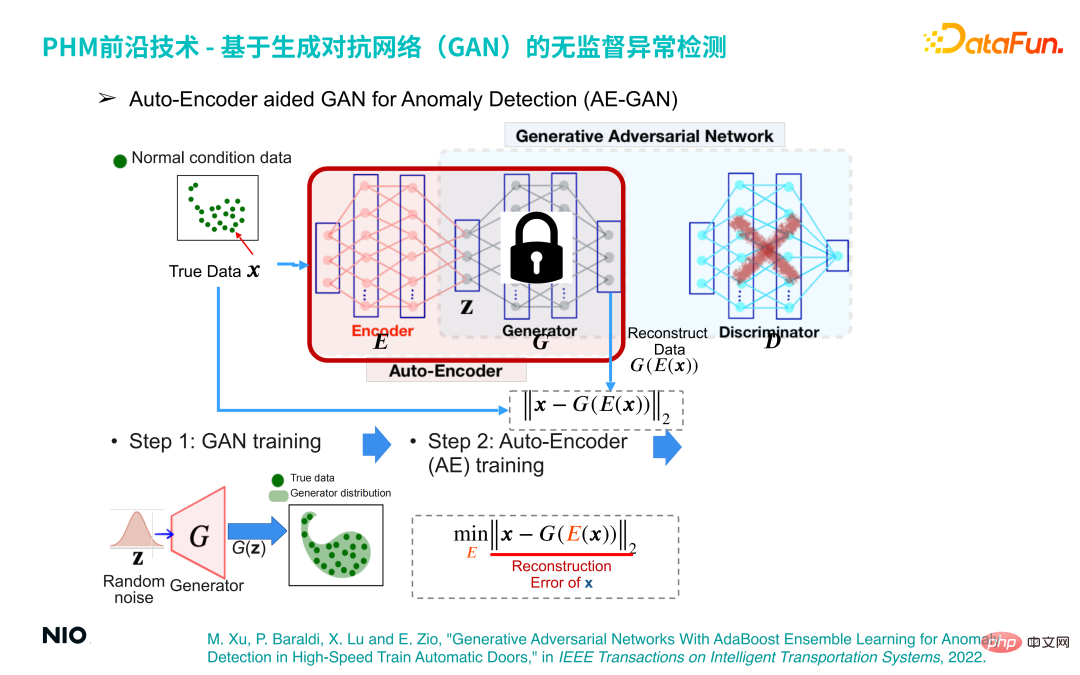
Pertama, GAN standard akan dilatih, dan atas dasar ini, parameter lapisan tersembunyi dalam G rangkaian akan diperbaiki; kemudian dalam G Masukkan rangkaian Pengekod sebelum rangkaian dan sambungkan kedua-dua rangkaian untuk membentuk rangkaian Pengekod Auto. Input rangkaian Auto-Pengekod ialah sampel data asal, dan output ialah sampel data yang dibina semula rangkaian AE-GAN mengenal pasti data tidak normal dengan membina sampel yang dibina semula.
S7: Adakah terdapat kertas kerja dan kod sumber terbuka yang berkaitan untuk kedua-dua kaedah yang diterangkan dalam artikel?
J7: Sila lihat bab artikel yang berkaitan untuk mendapatkan butiran Kod tersebut belum lagi menjadi sumber terbuka.
S8: Bolehkah AE-GAN digunakan untuk pengesanan anomali dalam medan imej?
A8: Ia boleh digunakan. Walau bagaimanapun, berbanding dengan isyarat biasa, medan imej mempunyai dimensi yang lebih tinggi, pengedaran data yang lebih kompleks dan jumlah data yang lebih besar yang diperlukan untuk latihan. Oleh itu, jika ia digunakan untuk pengelasan imej dan terdapat sedikit sampel data, kesan model akan terjejas jika ia digunakan untuk pengesanan anomali, kesannya masih baik.
S9: Apakah penunjuk penilaian untuk pengesanan anomali? Positif palsu dan negatif palsu, dan kedua-duanya dinilai bersama.
A9: Penunjuk penilaian yang paling intuitif ialah kadar positif palsu dan kadar negatif palsu Lebih banyak penunjuk saintifik termasuk kadar ingatan semula, kadar ketepatan, skor-F, dsb.
S10: Bagaimana untuk memadankan ciri sampel kerosakan?
J10: Jika tiada cara yang lebih langsung dan lebih pantas untuk mendapatkan ciri-ciri kerosakan, kaedah dipacu data tulen biasanya digunakan untuk melombong ciri sampel kesalahan, biasanya dengan membina rangkaian pembelajaran mendalam. Ciri utama sampel kesalahan dipelajari dan diwakili sebagai matriks konsep.
S11: Bagaimanakah algoritma PHM melaksanakan pemilihan model?
J11: Untuk sebilangan kecil sampel, kaedah RNN tanpa pengawasan biasanya digunakan untuk mencirikan ciri-ciri data menggunakan matriks konsep medan jika terdapat sejumlah besar normal sampel untuk masalah pengesanan anomali, ia boleh digunakan rangkaian AE-GAN dilaksanakan.
S12: Bagaimana untuk mengenal pasti anomali melalui dua jenis output matriks konsep oleh RNN?
A12: Output matriks konsep oleh RNN boleh difahami sebagai set semua ciri dalam siri masa input kerana ciri-ciri data dalam keadaan yang sama adalah serupa, ini Matriks konsep semua sampel dalam keadaan dipuratakan dan diagregatkan, iaitu, matriks pusat konsep dalam keadaan jenis ini diabstrakkan untuk siri masa input keadaan yang tidak diketahui, dengan mengira matriks konsepnya dan membandingkannya dengan matriks pusat konsep, pusat konsep dengan persamaan tertinggi ialah Matriks ialah kategori yang sepadan dengan data input.
S13: Bagaimana untuk menetapkan ambang anomali dalam rangkaian AE-GAN?
A13: Selepas melengkapkan latihan rangkaian, gunakan sekumpulan kecil data sampel biasa untuk mengira ralat pembinaan semula dan ambil nilai maksimum sebagai ambang.
S14: Adakah ambang anomali dalam rangkaian AE-GAN akan dikemas kini?
A14: Secara umumnya, ia tidak akan dikemas kini, tetapi jika pengedaran data asal berubah (seperti keadaan operasi berubah), ambang mungkin perlu dilatih semula dan ambang malah boleh diubah kaedah berkaitan pembelajaran pemindahan diperkenalkan ke dalam rangkaian GAN untuk memperhalusi ambang.
S15: Bagaimanakah siri masa GAN melatih?
A15: GAN secara amnya tidak melatih siri masa asal, tetapi melatih ciri yang diekstrak berdasarkan siri masa asal.
S16: Berbanding dengan GAN tradisional, apakah peranan memperkenalkan GAN dalam AE-GAN? Apakah penambahbaikan yang boleh diperolehi?
A16: GAN tradisional juga sering digunakan untuk pengesanan anomali. AE-GAN mempunyai analisis yang lebih mendalam tentang prinsip GAN, jadi ia juga boleh mengelakkan masalah seperti mod runtuh ke tahap yang paling besar dan pengenalan Auto-Pengekod dapat memastikan bahawa prinsip pengesanan anomali dilaksanakan dengan tepat, dengan itu mengurangkan kadar penggera palsu.
S17: Adakah terdapat peningkatan keseluruhan dalam data siri masa bagi cerucuk pengecasan semasa cuti? Bagaimana untuk mengelakkan salah penilaian?
A17: Model diagnosis kerosakan dibahagikan kepada banyak peringkat Hasil lapisan model hanyalah asas untuk lapisan membuat keputusan dan bukan hasil akhir biasanya digabungkan dengan logik perniagaan lain untuk membantu pertimbangan.
S18: Selepas model dilancarkan, bagaimana untuk menilai kesan aplikasi pengesanan anomali tanpa pengawasan?
J18: Secara umumnya berdasarkan hasil pengesanan anomali, pakar teknikal akan ditetapkan untuk mengesahkan dalam adegan sebenar di tapak.
S19: Adakah terdapat sebarang percubaan untuk mengesan keabnormalan pada bateri di stesen swap bateri menggunakan dua kaedah yang dinyatakan dalam artikel?
J19: Percubaan berkaitan sedang dijalankan.
S20: Bagaimana untuk menyatukan panjang data siri masa? Adakah padding dengan 0 menyebabkan kecerunan tidak jatuh?
A20: Model Conceptor yang disebut dalam artikel boleh mengendalikan siri masa dalam sebarang panjang, jadi tidak perlu mengisi 0s, dan ia juga mengelakkan parameter "latihan " proses, jadi ini boleh dielakkan jenis masalah.
S21: Adakah GAN akan mengalami keterlaluan?
J21: Jika ia hanya digunakan dalam bidang pengesanan anomali, sebenarnya, lebih banyak "overfitting" model akan berprestasi, lebih baik ia akan menjadi. Di samping itu, disebabkan oleh rawak yang besar dalam rangkaian G model GAN semasa proses latihan, overfitting biasanya tidak berlaku.
S22: Apabila melatih model GAN, apakah susunan magnitud data latihan yang digunakan? Apakah tetapan umum untuk mencapai hasil yang lebih baik?
A22: Masalah jenis ini secara amnya bergantung pada saiz rangkaian saraf, dimensi neuron tersembunyi, dsb. Secara umumnya, untuk rangkaian saraf 2 lapisan dengan 100 neuron setiap lapisan, jumlah data latihan perlu 1-2 urutan magnitud lebih besar daripada dimensi lapisan tersembunyi untuk mencapai hasil yang lebih baik juga perlu menggunakan Beberapa helah untuk mengelakkan keruntuhan corak daripada berlaku.
S23: Parameter tersembunyi unit minimum dalam model Conceptor adalah ditetapkan berdasarkan pengalaman pakar? Bagaimanakah bias dibandingkan dengan RNN biasa? Apakah volum label untuk analisis kegagalan? Bagaimana untuk mengukur nilai perniagaan?
A23: Banyak model Conceptor pada masa ini dalam talian menggunakan set parameter empirikal yang sama tanpa pelarasan parameter lanjut mengikut pengalaman praktikal, tetapan parameter yang berkaitan antara 10 hingga 100, yang perbezaan dalam kesan ke atas keputusan adalah sangat kecil, satu-satunya perbezaan adalah dalam kos pengiraan. Jika saiz sampel data kerosakan adalah kecil dan anda mahu keputusan menjadi lebih tepat, anda boleh menetapkan parameter kepada 128, 256 atau lebih tinggi Sejajar dengan itu, kos pengiraan akan lebih tinggi. Bilangan label untuk analisis kesalahan biasanya antara 1 dan 10. Kuantifikasi nilai perniagaan biasanya diukur dengan penggera palsu dan penggera terlepas, kerana penggera palsu dan penggera terlepas boleh ditukar terus kepada impak nilai perniagaan kuantitatif.
S24: Bagaimana untuk menentukan masa mula kerosakan dan ketepatan serta kadar panggil balik?
A24: Kaedah Conceptor boleh digunakan untuk membentuk berbilang matriks konsep menggunakan tetingkap pertumbuhan masa dilakukan pada matriks konsep untuk menentukan masa berlakunya kerosakan. Lihat kertas berkaitan dalam bab Conceptor untuk butiran.
S25: Adakah sebilangan besar data normal mempunyai nilai yang sama? Adakah model akan mempelajari sampel yang sama berulang kali?
A25: Dalam senario sebenar, disebabkan keadaan pengendalian peralatan yang berbeza, data biasa selalunya berbeza secara meluas.
S26: Apakah ciri-ciri kerosakan yang sesuai untuk GAN, dan apakah ciri-ciri kerosakan yang sesuai untuk RNN?
J26: Sukar untuk membahagikan senario penggunaan khusus kedua-dua model ini secara amnya, GAN lebih baik dalam menyelesaikan masalah dengan pengedaran data khas yang sukar digunakan rangkaian klasifikasi. RNN tanpa pengawasan lebih sesuai untuk menangani masalah sampel kecil.
S27: Bolehkah model yang dinyatakan dalam artikel ini digunakan dalam senario khas seperti "pengesanan pelanggaran kakitangan"?
J27: Untuk senario khusus domain, jika pengetahuan khusus domain boleh diperkenalkan untuk mengekstrak ciri tertib tinggi, secara amnya boleh dilakukan jika hanya imej digunakan untuk pengesanan , jika saiz sampel imej Jika ia besar dan boleh mewakili tingkah laku biasa, masalah itu boleh diubah menjadi pengesanan adegan subbahagian domain CV, yang boleh dikesan menggunakan model yang disebutkan dalam artikel ini.
S28: Adakah Conceptor Distance merupakan pertimbangan persamaan? Adakah ia dipelajari dengan parameter?
A28: Ia tanpa parameter.
S29: Adakah saya perlu melatih model untuk setiap kesalahan?
J29: Ia bergantung pada senario tertentu, termasuk keperluan model, saiz sampel kerosakan, kerumitan pengedaran, dsb. Jika persamaan bentuk gelombang pemasaan dua kesalahan adalah sangat tinggi, secara amnya tidak perlu melatih model yang berasingan Anda hanya perlu membina model berbilang klasifikasi untuk menentukan sempadan pengelasan mod kesalahan sangat berbeza, anda boleh menggunakan model GAN untuk mengemas kini data pengenalan yang tepat.
S30: Berapakah masa latihan model dan kos latihan?
A30: Model Conceptor mempunyai kos latihan yang sangat kecil dan boleh digunakan untuk mengekstrak ciri masa latihan model GAN secara relatifnya lebih lama, tetapi untuk data jadual berstruktur biasa, latihan Ia tidak akan mengambil masa terlalu lama.
S31: Apabila melatih model, apakah rupa set latihan sampel biasa? Semasa menghiris tetingkap gelongsor siri masa, adakah terdapat bilangan minimum kali disyorkan untuk setiap subset siri masa?
A31: Kedua-dua model tidak mempunyai keperluan pada bilangan sampel positif dan negatif memandangkan masa latihan model, beribu-ribu sampel yang mewakili secara amnya dipilih untuk latihan. Secara amnya tiada pengesyoran nombor minimum untuk bilangan kali dalam subset masa.
S32: Apakah anggaran dimensi matriks ciri yang diperolehi oleh rangkaian RNN?
A32: Dimensi matriks ciri berkaitan secara langsung dengan bilangan neuron tersembunyi Jika terdapat N neuron tersembunyi, dimensi matriks ciri ialah N×N. Memandangkan kerumitan model dan kecekapan pengiraan, N biasanya tidak ditetapkan terlalu besar, dan nilai tetapan yang biasa digunakan ialah 32.
S33: Mengapa tidak menggunakan diskriminator dalam GAN sebagai pengelas? Diskriminator hanya mempelajari data biasa, dan data tidak normal akan diklasifikasikan sebagai data palsu. Apakah kelemahan pendekatan ini?
A33: Mengikut prinsip GAN, rangkaian D digunakan untuk membezakan sampel biasa daripada sampel palsu dan jika sampel palsu dilatih ke keadaan "badan lengkap", mereka akan menjadi sangat hampir dengan sampel biasa, menjadikannya sukar untuk membezakan antara sampel biasa dan sampel tidak normal dan rangkaian AE-GAN menganggap bahawa sampel normal dan sampel tidak normal mempunyai tahap perbezaan tertentu, yang merupakan asas teori untuk menggunakan AE- GAN.
S34: Bagaimana untuk memastikan keupayaan generalisasi model pembelajaran sampel kecil?
A34: Keupayaan generalisasi model perlu berdasarkan andaian a priori: semua kerosakan jenis yang sama mempunyai pengedaran data yang serupa. Jika pengedaran data kerosakan yang serupa agak berbeza, secara amnya adalah perlu untuk membahagikan lagi kategori kesalahan untuk memastikan keupayaan generalisasi model.
S35: Bagaimana untuk melaksanakan prapemprosesan data pada data input?
A35: Untuk kedua-dua model yang dinyatakan dalam artikel, data hanya perlu dinormalisasi.
S36: Bagaimanakah GAN dibandingkan dengan arahan tradisional tanpa pengawasan seperti hutan pengasingan dan AE?
J36: Melalui kesempurnaan teori, GAN boleh menggambarkan dengan lebih lengkap taburan data sampel normal, dengan itu membina sempadan keputusan yang lebih lengkap. Walau bagaimanapun, kaedah seperti AE biasa, hutan terpencil dan SVM Satu Kelas tidak mempunyai kesempurnaan teori dan tidak boleh membina sempadan keputusan yang lebih lengkap.
S37: Jika pembeza tidak dapat membezakan antara sampel biasa dan sampel palsu pada peringkat kemudian, maka bahagian GAN akan menjadi tidak penting Adakah AE-GAN akan merosot menjadi AE pada masa ini?
J37: Jika pihak diskriminasi memang tidak dapat mengenal pasti sampel biasa dan sampel palsu, dapat dilihat dari sisi bahawa latihan penjana sangat berjaya dalam peringkat pengesanan anomali, hanya Penjana digunakan tanpa diskriminator. Penjana dalam rangkaian GAN adalah sangat penting, jadi AE-GAN tidak akan merosot kepada AE Ia boleh difahami sebagai versi AE yang dinaik taraf, yang merupakan AE biasa.
S38: Pernahkah anda mencuba menggunakan Transformer dan bukannya RNN?
J38: Dalam senario dengan sampel kecil dan keperluan kebolehtafsiran tinggi, tiada percubaan sedemikian telah dibuat dan percubaan berkaitan boleh dibuat kemudian.
S39: Apakah perbezaan antara AE-GAN dan VAE?
A39: VAE juga merupakan kaedah yang biasa digunakan untuk pengesanan anomali VAE menggunakan taburan Gaussian terdahulu dalam lapisan tersembunyi dan mengubah bentuk taburan Gaussian terdahulu agar sesuai dengan sebenar data. Menjadikan kedua-dua taburan setara; walau bagaimanapun, fungsi kehilangan yang digunakan oleh VAE ialah divergence KL dan bukannya divergence JSD, dan divergence KL adalah tidak simetri, jadi ia mungkin tidak berfungsi dengan baik dalam sampel kompleks.
S40: Adakah bunyi data yang teruk atau hilang dalam ciri isyarat semasa percubaan? Apakah kaedah pembersihan ciri yang lebih baik?
A40: Sarung pistol pengecas dalam artikel adalah kes bunyi yang serius. Sesetengah kaedah penguraian berdasarkan siri masa boleh menguraikan item berkala, item trend, item hingar, dll. dalam siri masa ciri yang hilang boleh diproses menggunakan kaedah data yang tidak lengkap.
S41: Bolehkah strategi peningkatan seperti APA ditambah kepada latihan?
A41: Mengambil GAN sebagai contoh, peningkatan sampel dilakukan terutamanya dengan menambahkan bunyi, dan strategi peningkatan APA tidak digunakan.
S42: Dalam langkah kedua 4.1.(3), jika julat normal menjangkau selang yang besar, jika terdapat 3 sampel 1, 2, dan 3, antara yang mana sampel 1 dan 2 adalah sampel biasa, dan sampel 3 adalah sampel tidak normal 1 dan sampel 2 berada pada kedua-dua belah julat normal, dan sampel 3 tidak jauh di sebelah sampel 1 tetapi telah melebihi julat normal, maka akan terdapat sesuatu antara sampel 1 dan 2 Apakah keadaan apabila ralat pembinaan semula antara sampel 1 dan 3 adalah lebih besar daripada sampel 1 dan 3?
J42: Rujukan yang disediakan dalam artikel ini mengandungi banyak contoh ekstrem Contohnya, contoh yang anda sebutkan ialah contoh bola dua gaussian biasa. AE-GAN boleh menyelesaikan masalah jenis ini.
Atas ialah kandungan terperinci Amalan algoritma pembelajaran mendalam NIO. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI