
Rumah >Peranti teknologi >AI >Mengawal lengan robot bercantum dua menggunakan algoritma pembelajaran pengukuhan DDPG Actor-Critic
Mengawal lengan robot bercantum dua menggunakan algoritma pembelajaran pengukuhan DDPG Actor-Critic

- 王林ke hadapan
- 2023-05-12 21:55:17957semak imbas
Dalam artikel ini, kami akan memperkenalkan latihan ejen pintar untuk mengawal lengan robot dwi-sendi dalam persekitaran Reacher, program simulasi berasaskan Unity yang dibangunkan menggunakan kit alat Unity ML-Agents. Matlamat kami adalah untuk mencapai kedudukan sasaran dengan ketepatan yang tinggi, jadi di sini kami boleh menggunakan algoritma Kecerunan Dasar Deterministik Dalam (DDPG) terkini yang direka bentuk untuk keadaan berterusan dan ruang tindakan.

Aplikasi Dunia Sebenar
Senjata robot memainkan peranan penting dalam pembuatan, kemudahan pengeluaran, penerokaan angkasa lepas serta operasi mencari dan menyelamat. Adalah sangat penting untuk mengawal lengan robot dengan ketepatan dan fleksibiliti yang tinggi. Dengan menggunakan teknik pembelajaran pengukuhan, sistem robotik ini boleh didayakan untuk belajar dan melaraskan tingkah laku mereka dalam masa nyata, dengan itu meningkatkan prestasi dan fleksibiliti. Kemajuan dalam pembelajaran pengukuhan bukan sahaja menyumbang kepada pemahaman kita tentang kecerdasan buatan, tetapi mempunyai potensi untuk merevolusikan industri dan mempunyai kesan yang bermakna kepada masyarakat.
Reacher ialah simulator lengan robot yang sering digunakan untuk pembangunan dan ujian algoritma kawalan. Ia menyediakan persekitaran maya yang mensimulasikan ciri fizikal dan undang-undang gerakan lengan robotik, membolehkan pembangun menjalankan penyelidikan dan eksperimen pada algoritma kawalan tanpa memerlukan perkakasan sebenar.
Persekitaran Reacher terutamanya terdiri daripada bahagian berikut:
- Lengan robotik: Reacher mensimulasikan lengan robot bercantum dua, termasuk tapak tetap dan dua sendi boleh alih. Pemaju boleh mengubah sikap dan kedudukan lengan robot dengan mengawal dua sendinya.
- Titik sasaran: Dalam julat pergerakan lengan robotik, Reacher menyediakan titik sasaran dan kedudukan titik sasaran dijana secara rawak. Tugas pembangun adalah untuk mengawal lengan robot supaya hujung lengan robot boleh menghubungi titik sasaran.
- Enjin fizik: Reacher menggunakan enjin fizik untuk mensimulasikan ciri fizikal dan corak pergerakan lengan robot. Pembangun boleh mensimulasikan persekitaran fizikal yang berbeza dengan melaraskan parameter enjin fizik.
- Antara muka visual: Reacher menyediakan antara muka visual yang boleh memaparkan kedudukan lengan robot dan mata sasaran, serta trajektori postur dan pergerakan lengan robot. Pembangun boleh nyahpepijat dan mengoptimumkan algoritma kawalan melalui antara muka visual.
Simulator Reacher ialah alat yang sangat praktikal yang boleh membantu pembangun menguji dan mengoptimumkan algoritma kawalan dengan pantas tanpa memerlukan perkakasan sebenar.
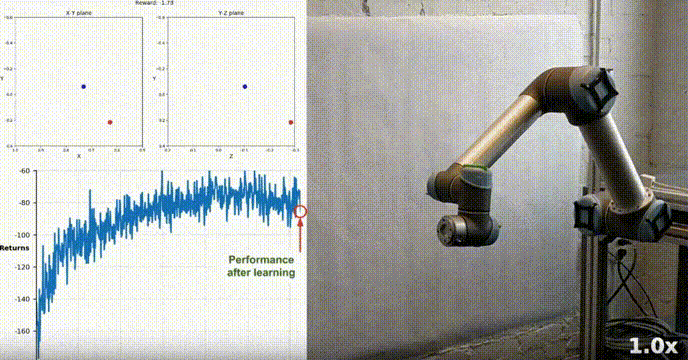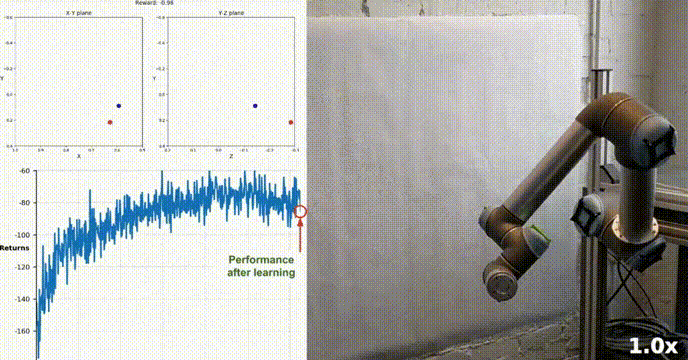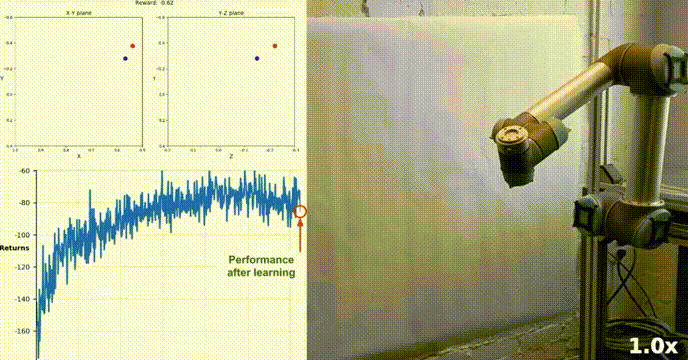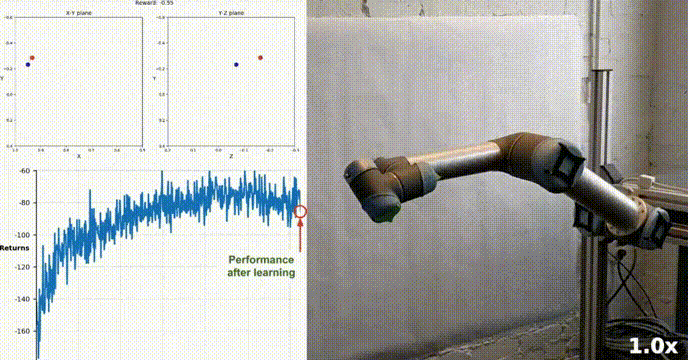
Persekitaran Simulasi
Reacher dibina menggunakan kit alat Unity ML-Agents, ejen kami boleh mengawal lengan robot dwi-sendi. Matlamatnya adalah untuk membimbing lengan ke arah kedudukan sasaran dan mengekalkan kedudukannya dalam kawasan sasaran selama mungkin. Persekitaran menampilkan 20 ejen yang disegerakkan, masing-masing berjalan secara bebas, yang membantu mengumpul pengalaman dengan cekap semasa latihan.

Keadaan dan Ruang Tindakan
Memahami keadaan dan ruang tindakan adalah penting untuk mereka bentuk algoritma pembelajaran pengukuhan yang berkesan. Dalam persekitaran Reacher, ruang keadaan terdiri daripada 33 pembolehubah selanjar yang memberikan maklumat tentang lengan robot, seperti kedudukannya, putaran, halaju dan halaju sudut. Ruang tindakan juga berterusan, dengan empat pembolehubah sepadan dengan tork yang dikenakan pada dua sendi lengan robot. Setiap pembolehubah tindakan ialah nombor nyata antara -1 dan 1.
Jenis Tugasan dan Kriteria Kejayaan
Tugas Reacher dianggap sebagai episodik, dengan setiap serpihan mengandungi bilangan langkah masa yang tetap. Matlamat ejen adalah untuk memaksimumkan jumlah ganjarannya semasa langkah ini. Efektor hujung lengan menerima bonus +0.1 untuk setiap langkah yang diperlukan untuk mengekalkan kedudukan sasaran. Kejayaan dianggap apabila ejen mencapai skor purata 30 mata atau lebih daripada 100 operasi berturut-turut.
Memahami persekitaran, di bawah kami akan meneroka algoritma DDPG, pelaksanaannya dan cara ia menyelesaikan masalah kawalan berterusan dalam persekitaran ini dengan berkesan.
Pemilihan Algoritma untuk Kawalan Berterusan: DDPG
Mengenai tugas kawalan berterusan seperti Masalah Reacher, pilihan algoritma adalah penting untuk mencapai prestasi optimum. Dalam projek ini, kami memilih algoritma DDPG kerana ia merupakan kaedah pengkritik aktor yang direka khusus untuk mengendalikan keadaan berterusan dan ruang tindakan.
Algoritma DDPG menggabungkan kelebihan kaedah berasaskan dasar dan berasaskan nilai dengan menggabungkan dua rangkaian saraf: rangkaian Aktor menentukan tingkah laku terbaik berdasarkan keadaan semasa, dan rangkaian rangkaian Kritik) menganggarkan tingkah laku keadaan fungsi nilai (fungsi-Q). Kedua-dua jenis rangkaian mempunyai rangkaian sasaran yang menstabilkan proses pembelajaran dengan menyediakan sasaran tetap semasa proses kemas kini.
Dengan menggunakan rangkaian Kritik untuk menganggar fungsi q dan rangkaian Aktor untuk menentukan tingkah laku optimum, algoritma DDPG menggabungkan kelebihan kaedah kecerunan dasar dan DQN dengan berkesan. Pendekatan hibrid ini membolehkan ejen belajar dengan cekap dalam persekitaran kawalan berterusan.
<code>import random from collections import deque import torch import torch.nn as nn import numpy as np from actor_critic import Actor, Critic class ReplayBuffer: def __init__(self, buffer_size, batch_size): self.memory = deque(maxlen=buffer_size) self.batch_size = batch_size def add(self, state, action, reward, next_state, done): self.memory.append((state, action, reward, next_state, done)) def sample(self): batch = random.sample(self.memory, self.batch_size) states, actions, rewards, next_states, dones = zip(*batch) return states, actions, rewards, next_states, dones def __len__(self): return len(self.memory) class DDPG: def __init__(self, state_dim, action_dim, hidden_dim, buffer_size, batch_size, actor_lr, critic_lr, tau, gamma): self.actor = Actor(state_dim, hidden_dim, action_dim, actor_lr) self.actor_target = Actor(state_dim, hidden_dim, action_dim, actor_lr) self.critic = Critic(state_dim, action_dim, hidden_dim, critic_lr) self.critic_target = Critic(state_dim, action_dim, hidden_dim, critic_lr) self.memory = ReplayBuffer(buffer_size, batch_size) self.batch_size = batch_size self.tau = tau self.gamma = gamma self._update_target_networks(tau=1)# initialize target networks def act(self, state, noise=0.0): state = torch.tensor(state, dtype=torch.float32).unsqueeze(0) action = self.actor(state).detach().numpy()[0] return np.clip(action + noise, -1, 1) def store_transition(self, state, action, reward, next_state, done): self.memory.add(state, action, reward, next_state, done) def learn(self): if len(self.memory) </code>
Kod di atas juga menggunakan Replay Buffer, yang boleh meningkatkan kecekapan dan kestabilan pembelajaran. Replay Buffer pada asasnya ialah struktur data memori yang menyimpan sejumlah tetap pengalaman atau peralihan lalu, yang terdiri daripada status, tindakan, ganjaran, status seterusnya dan maklumat penyiapan. Kelebihan utama penggunaannya adalah untuk membolehkan ejen memecahkan korelasi antara pengalaman berturut-turut, dengan itu mengurangkan kesan korelasi temporal yang berbahaya.
Dengan melukis kumpulan mini rawak pengalaman daripada penimbal, ejen boleh belajar daripada set transformasi yang pelbagai, yang membantu menstabilkan dan menyamaratakan proses pembelajaran. Replay Buffers juga membenarkan ejen menggunakan semula pengalaman lalu beberapa kali, dengan itu meningkatkan kecekapan data dan menggalakkan pembelajaran yang lebih berkesan daripada interaksi terhad dengan persekitaran.
Algoritma DDPG ialah pilihan yang baik kerana keupayaannya untuk mengendalikan ruang tindakan berterusan dengan cekap, yang merupakan aspek utama dalam persekitaran ini. Reka bentuk algoritma membolehkan penggunaan cekap pengalaman selari yang dikumpulkan oleh pelbagai ejen, menghasilkan pembelajaran yang lebih pantas dan penumpuan yang lebih baik. Sama seperti Reacher yang diperkenalkan di atas, ia boleh menjalankan 20 ejen pada masa yang sama, jadi kami boleh menggunakan 20 ejen ini untuk berkongsi pengalaman, belajar secara kolektif dan meningkatkan kelajuan pembelajaran.
Algoritma selesai Seterusnya kami akan memperkenalkan proses pemilihan dan latihan hiperparameter.
Algoritma DDPG berfungsi dalam persekitaran Reacher
Untuk lebih memahami keberkesanan algoritma dalam persekitaran, kita perlu melihat dengan lebih dekat komponen dan langkah utama yang terlibat dalam proses pembelajaran .
Seni Bina Rangkaian
Algoritma DDPG menggunakan dua rangkaian neural, Actor dan Critic. Kedua-dua rangkaian mengandungi dua lapisan tersembunyi, setiap satu mengandungi 400 nod. Lapisan tersembunyi menggunakan fungsi pengaktifan ReLU (Rectified Linear Unit), manakala lapisan output rangkaian Actor menggunakan fungsi pengaktifan tanh untuk menjana tindakan antara -1 hingga 1. Lapisan keluaran rangkaian pengkritik tidak mempunyai fungsi pengaktifan kerana ia menganggarkan fungsi q secara langsung.
Berikut ialah kod rangkaian:
<code>import numpy as np import torch import torch.nn as nn import torch.optim as optim class Actor(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim, learning_rate=1e-4): super(Actor, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, output_dim) self.tanh = nn.Tanh() self.optimizer = optim.Adam(self.parameters(), lr=learning_rate) def forward(self, state): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(x)) x = self.tanh(self.fc3(x)) return x class Critic(nn.Module): def __init__(self, state_dim, action_dim, hidden_dim, learning_rate=1e-4): super(Critic, self).__init__() self.fc1 = nn.Linear(state_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim + action_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, 1) self.optimizer = optim.Adam(self.parameters(), lr=learning_rate) def forward(self, state, action): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(torch.cat([x, action], dim=1))) x = self.fc3(x) return x</code>
Pemilihan hiperparameter
Hiperparameter yang dipilih adalah penting untuk pembelajaran yang cekap. Dalam projek ini, saiz Replay Buffer kami ialah 200,000 dan saiz kelompok ialah 256. Kadar pembelajaran Aktor ialah 5e-4, kadar pembelajaran Kritik ialah 1e-3, parameter kemas kini lembut (tau) ialah 5e-3, dan gamma ialah 0.995. Akhirnya, bunyi tindakan telah ditambah, dengan skala hingar awal 0.5 dan kadar pengecilan hingar 0.998.
Proses latihan
Proses latihan melibatkan interaksi berterusan antara kedua-dua rangkaian, dan dengan 20 ejen selari berkongsi rangkaian yang sama, model belajar secara kolektif daripada pengalaman yang dikumpul oleh semua ejen. Persediaan ini mempercepatkan proses pembelajaran dan meningkatkan kecekapan.
<code>from collections import deque import numpy as np import torch from ddpg import DDPG def train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.1, noise_decay=0.99): scores_window = deque(maxlen=100) scores = [] for episode in range(1, episodes + 1): env_info = env.reset(train_mode=True)[brain_name] states = env_info.vector_observations agent_scores = np.zeros(num_agents) for step in range(max_steps): actions = agent.act(states, noise_scale) env_info = env.step(actions)[brain_name] next_states = env_info.vector_observations rewards = env_info.rewards dones = env_info.local_done for i in range(num_agents): agent.store_transition(states[i], actions[i], rewards[i], next_states[i], dones[i]) agent.learn() states = next_states agent_scores += rewards noise_scale *= noise_decay if np.any(dones): break avg_score = np.mean(agent_scores) scores_window.append(avg_score) scores.append(avg_score) if episode % 10 == 0: print(f"Episode: {episode}, Score: {avg_score:.2f}, Avg Score: {np.mean(scores_window):.2f}") # Saving trained Networks torch.save(agent.actor.state_dict(), "actor_final.pth") torch.save(agent.critic.state_dict(), "critic_final.pth") return scores if __name__ == "__main__": env = UnityEnvironment(file_name='Reacher_20.app') brain_name = env.brain_names[0] brain = env.brains[brain_name] state_dim = 33 action_dim = brain.vector_action_space_size num_agents = 20 # Hyperparameter suggestions hidden_dim = 400 batch_size = 256 actor_lr = 5e-4 critic_lr = 1e-3 tau = 5e-3 gamma = 0.995 noise_scale = 0.5 noise_decay = 0.998 agent = DDPG(state_dim, action_dim, hidden_dim=hidden_dim, buffer_size=200000, batch_size=batch_size,actor_lr=actor_lr, critic_lr=critic_lr, tau=tau, gamma=gamma) episodes = 200 max_steps = 1000 scores = train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.2, noise_decay=0.995)</code>
Langkah utama dalam proses latihan adalah seperti berikut:
Mulakan rangkaian: Ejen memulakan rangkaian Pelakon dan Pengkritik yang dikongsi serta rangkaian sasaran masing-masing dengan pemberat rawak. Rangkaian sasaran menyediakan sasaran pembelajaran yang stabil semasa kemas kini.
- Berinteraksi dengan persekitaran: Setiap ejen menggunakan rangkaian Aktor yang dikongsi untuk berinteraksi dengan persekitaran dengan memilih tindakan berdasarkan keadaan semasanya. Untuk menggalakkan penerokaan, istilah hingar juga ditambah pada tindakan pada peringkat awal latihan. Selepas mengambil tindakan, setiap ejen memerhatikan ganjaran yang terhasil dan keadaan seterusnya.
- Pengalaman menyimpan: Setiap ejen menyimpan pengalaman yang diperhatikan (keadaan, tindakan, ganjaran, next_state) dalam penimbal ulang tayang dikongsi. Penampan ini mengandungi jumlah pengalaman terkini yang tetap supaya setiap ejen boleh belajar daripada pelbagai peralihan yang dikumpul oleh semua ejen.
- Belajar daripada pengalaman: Lukiskan sekumpulan pengalaman secara berkala daripada penimbal ulang tayang yang dikongsi. Gunakan pengalaman pensampelan untuk mengemas kini rangkaian pengkritik yang dikongsi dengan meminimumkan ralat min kuasa dua antara nilai Q yang diramalkan dan nilai Q sasaran.
- Kemas kini Rangkaian Pelakon: Rangkaian aktor kongsi dikemas kini menggunakan kecerunan dasar, yang dikira dengan mengambil kecerunan output rangkaian pengkritik dikongsi berkenaan dengan tindakan yang dipilih. Rangkaian pelakon yang dikongsi belajar memilih tindakan yang memaksimumkan nilai Q yang dijangkakan.
- Kemas kini rangkaian sasaran: Rangkaian sasaran Aktor dan Pengkritik yang dikongsi dikemas kini secara lembut menggunakan campuran berat rangkaian semasa dan sasaran. Ini memastikan proses pembelajaran yang stabil.
Paparan hasil
Ejen kami berjaya belajar mengawal lengan robot dua sendi dalam persekitaran Racher menggunakan algoritma DDPG. Sepanjang proses latihan, kami memantau prestasi ejen berdasarkan skor purata kesemua 20 ejen. Apabila ejen meneroka persekitaran dan mengumpul pengalaman, keupayaannya untuk meramalkan tingkah laku optimum untuk memaksimumkan ganjaran bertambah baik dengan ketara.
Adalah dapat dilihat bahawa ejen menunjukkan kecekapan yang ketara dalam tugas, dengan skor purata melebihi ambang yang diperlukan untuk menyelesaikan persekitaran (30+), walaupun prestasi ejen adalah Terdapat variasi sepanjang proses latihan, tetapi trend keseluruhan adalah menaik, menunjukkan bahawa proses pembelajaran berjaya.
Graf di bawah menunjukkan skor purata 20 ejen:
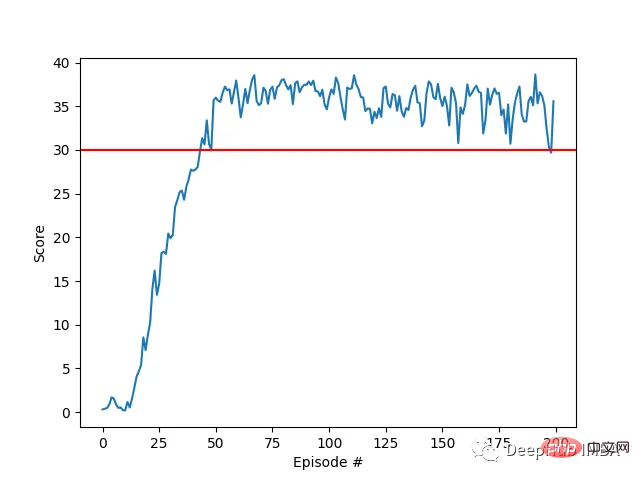
Anda dapat melihat bahawa algoritma DDPG yang kami laksanakan telah menyelesaikan masalah persekitaran Racher dengan berkesan. Ejen dapat menyesuaikan tingkah laku mereka dan mencapai prestasi yang diharapkan dalam tugas.
Langkah seterusnya
Hiperparameter dalam projek ini telah dipilih berdasarkan gabungan pengesyoran daripada literatur dan ujian empirikal. Pengoptimuman lanjut melalui penalaan hiperparameter sistem boleh membawa kepada prestasi yang lebih baik.
Latihan selari berbilang ejen: Dalam projek ini, kami menggunakan 20 ejen untuk mengumpul pengalaman pada masa yang sama. Kesan penggunaan lebih banyak agen pada keseluruhan proses pembelajaran mungkin menghasilkan penumpuan yang lebih cepat atau prestasi yang lebih baik.
Penormalan kelompok: Untuk meningkatkan lagi proses pembelajaran, melaksanakan penormalan kelompok dalam seni bina rangkaian saraf patut diterokai. Dengan menormalkan ciri input setiap lapisan semasa latihan, penormalan kelompok boleh membantu mengurangkan anjakan kovariat dalaman, mempercepatkan pembelajaran dan berpotensi meningkatkan generalisasi. Menambah penormalan kelompok pada rangkaian Pelakon dan Pengkritik boleh membawa kepada latihan yang lebih stabil dan cekap, tetapi ini memerlukan ujian lanjut.
Atas ialah kandungan terperinci Mengawal lengan robot bercantum dua menggunakan algoritma pembelajaran pengukuhan DDPG Actor-Critic. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI