
Rumah >pembangunan bahagian belakang >Tutorial Python >Bagaimanakah Python memproses fail Excel?
Bagaimanakah Python memproses fail Excel?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-08 17:58:151980semak imbas
『Penerangan Masalah』
Excel yang akan diproses kali ini mempunyai dua helaian, dan nilai helaian lain perlu dikira berdasarkan data satu helaian. Masalahnya ialah helaian yang akan dikira mengandungi bukan sahaja nilai berangka, tetapi juga formula. Mari kita lihat:
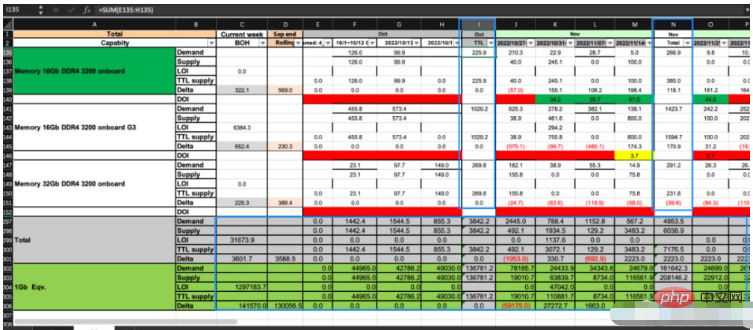
Seperti yang ditunjukkan dalam gambar di atas, excel ini mempunyai dua helaian: CP dan DS Kita mesti mengikut peraturan perniagaan tertentu dan berdasarkan data dalam CP Kira data sel DS yang sepadan. Kotak biru dalam gambar mengandungi formula, manakala kawasan lain mengandungi nilai berangka.
Mari kita lihat, jika kita mengikut logik pemprosesan yang dinyatakan sebelum ini, baca excel ke dalam rangka data dalam kelompok pada satu masa, dan kemudian tulis semula dalam kelompok sekali gus. Bahagian kod ini adalah seperti berikut:
import pandas as pd
import xlwings as xw
#要处理的文件路径
fpath = "data/DS_format.xlsm"
#把CP和DS两个sheet的数据分别读入pandas的dataframe
cp_df = pd.read_excel(fpath,sheet_name="CP",header=[0])
ds_df = pd.read_excel(fpath,sheet_name="DS",header=[0,1])
#计算过程省略......
#保存结果到excel
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()Masalah dengan kod di atas ialah apabila kaedah pd.read_excel() membaca data dari excel ke bingkai data, untuk sel dengan formula, formula dibaca terus dan dikira Hasilnya (jika tiada hasil, Nan dikembalikan), dan apabila kita menulis ke kecemerlangan, kita terus menulis semula kerangka data dalam kelompok sekali gus, supaya sel dengan formula sebelum ditulis semula dengan nilai yang dikira atau Nan, dan formula dibuang.
Baiklah, masalah telah timbul, bagaimana kita harus menyelesaikannya? Dua idea terlintas di fikiran:
Apabila menulis semula rangka data ke cemerlang, jangan tulis semula dalam kelompok sekaligus, tetapi tulis semula hanya data yang dikira melalui lelaran baris dan lajur . Sel-sel dengan formula tidak bergerak; >
Saya memang mencuba dua idea di atas masing-masing. 「Pilihan 1」
Kod berikut cuba melintasi bingkai data dan menulis nilai yang sepadan mengikut sel Sel dengan formula tidak bergerak
#根据ds_df来写excel,只写该写的单元格
for row_idx,row in ds_df.iterrows():
total_capabity_val = row[('Total','Capabity')].strip()
total_capabity1_val = row[('Total','Capabity.1')].strip()
#Total和1Gb Eqv.所在的行不写
if total_capabity_val!= 'Total' and total_capabity_val != '1Gb Eqv.':
#给Delta和LOI赋值
if total_capabity1_val == 'LOI' or total_capabity1_val == 'Delta':
ds_worksheet.range((row_idx + 3 ,3)).value = row[('Current week','BOH')]
print(f"ds_sheet的第{row_idx + 3}行第3列被设置为{row[('Current week','BOH')]}")
#给Demand和Supply赋值
if total_capabity1_val == 'Demand' or total_capabity1_val == 'Supply':
cp_datetime_columns = cp_df.columns[53:]
for col_idx in range(4,len(ds_df.columns)):
ds_datetime = ds_df.columns.get_level_values(1)[col_idx]
ds_month = ds_df.columns.get_level_values(0)[col_idx]
if type(ds_datetime) == str and ds_datetime != 'TTL' and ds_datetime != 'Total' and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',f'{ds_datetime}')]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',f'{ds_datetime}')]}")
elif type(ds_datetime) == datetime.datetime and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',ds_datetime)]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',ds_datetime)]}")Kod di atas berfungsi menyelesaikan masalah Masalah diselesaikan, iaitu, formula sel dengan formula dikekalkan. Walau bagaimanapun, menurut nasihat mengenai excel pemprosesan Python yang disebutkan pada permulaan artikel kami, kod ini mempunyai masalah prestasi yang serius, kerana ia sering mengendalikan sel excel melalui API, menghasilkan penulisan yang sangat perlahan 40 minit, yang tidak boleh diterima, jadi rancangan itu terpaksa ditinggalkan.
"Pilihan 2"
Penyelesaian ini berharap dapat mengekalkan nilai formula apabila membaca sel dengan nilai formula dalam excel. Ini hanya boleh didapati daripada API setiap perpustakaan excel Python untuk melihat sama ada terdapat kaedah yang sepadan. Saya melihat dengan teliti kaedah read_excel() Pandas dan tiada sokongan parameter yang sepadan. Saya menemui API untuk menyokong Openpyxl, seperti berikut:
import openpyxl ds_format_workbook = openpyxl.load_workbook(fpath,data_only=False) ds_wooksheet = ds_format_workbook['DS'] ds_df = pd.DataFrame(ds_wooksheet.values)
Kuncinya ialah parameter data_only di sini Jika Benar, data akan dikembalikan Jika Salah, nilai formula boleh dikekalkan
Saya fikir saya mendapati saya sangat gembira untuk mencari penyelesaian yang sepadan, tetapi apabila saya melihat struktur data dalam kerangka data dibaca melalui openpyxl, saya terkejut. Oleh kerana pengepala jadual excel saya ialah pengepala dua peringkat yang agak kompleks, dan terdapat situasi di mana sel digabungkan dan berpecah dalam pengepala Selepas pengepala sedemikian dibaca ke dalam bingkai data oleh openpyxl, ia tidak mengikut berbilang peringkat pengepala panda. Indeks diproses, tetapi ia hanya diproses menjadi indeks berangka 0123...
Tetapi pengiraan kerangka data saya akan bergantung pada indeks berbilang peringkat, jadi kaedah pemprosesan openpyxl ini menjadikan saya pengiraan seterusnya tidak dapat diproses.
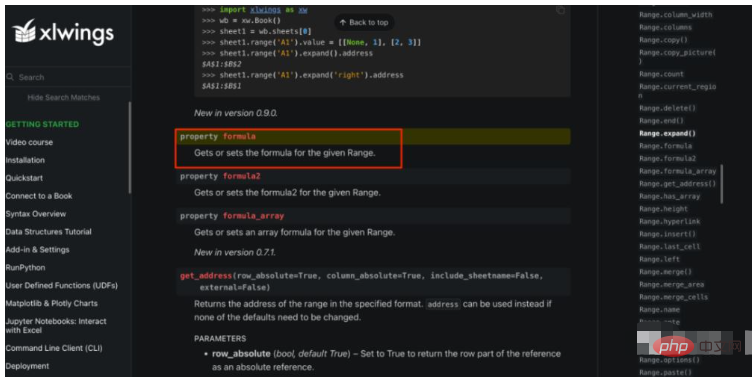
Openpyxl tidak berfungsi, bagaimana pula dengan xlwings? Selepas mencari melalui dokumentasi API xlwings, saya benar-benar menjumpainya, seperti yang ditunjukkan di bawah:
Kelas Julat menyediakan Formula yang dipanggil Harta, yang boleh mendapatkan dan menetapkan formula. Apabila saya melihat ini, saya rasa seperti telah menemui harta karun, dan saya dengan cepat mula mempraktikkan kod tersebut. Mungkin kerana inersia, atau mungkin saya takut dengan kecekapan mengendalikan Excel mengikut baris, lajur dan sel pada masa lalu, penyelesaian pertama yang saya fikirkan ialah melakukannya dalam kelompok sekaligus, iaitu membaca semua formula dalam Excel sekali gus, dan kemudian tulis semuanya sekali gus Kembali, jadi kod awal saya adalah seperti ini:#使用xlwings来读取formula app = xw.App(visible=False,add_book=False) ds_format_workbook = app.books.open(fpath) ds_worksheet = ds_format_workbook.sheets["DS"] #先把所有公式一次性读取并保存下来 formulas = ds_worksheet.used_range.formula #中间计算过程省略... #一次性把所有公式写回去 ds_worksheet.used_range.formula = formulas
 Tetapi saya salah fikir ds_worksheet.used_range.formula membuatkan saya salah faham bahawa formula itu hanya akan kembali sel dengan formula dalam excel, tetapi sebenarnya ia Semua sel dikembalikan, hanya formula dikekalkan untuk sel dengan formula. Jadi, apabila saya menulis semula formula itu, ia akan menimpa nilai lain yang saya kira melalui kerangka data dan ditulis untuk cemerlang.
Tetapi saya salah fikir ds_worksheet.used_range.formula membuatkan saya salah faham bahawa formula itu hanya akan kembali sel dengan formula dalam excel, tetapi sebenarnya ia Semua sel dikembalikan, hanya formula dikekalkan untuk sel dengan formula. Jadi, apabila saya menulis semula formula itu, ia akan menimpa nilai lain yang saya kira melalui kerangka data dan ditulis untuk cemerlang.
Dalam kes ini, saya hanya boleh memproses sel dengan formula secara berasingan dan bukannya sekaligus, jadi kod tersebut perlu ditulis seperti ini:
#使用xlwings来读取formula
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
#保留excel中的formula
#找到DS中Total所在的行,Total之后的行都是formula
row = ds_df.loc[ds_df[('Total','Capabity')]=='Total ']
total_row_index = row.index.values[0]
#获取对应excel的行号(dataframe把两层表头当做索引,从数据行开始计数,而且从0开始计数。excel从表头就开始计数,而且从1开始计数)
excel_total_row_idx = int(total_row_index+2)
#获取excel最后一行的索引
excel_last_row_idx = ds_worksheet.used_range.rows.count
#保留按日期计算的各列的formula
I_col_formula = ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula
N_col_formula = ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula
T_col_formula = ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula
U_col_formula = ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula
Z_col_formula = ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula
AE_col_formula = ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula
AK_col_formula = ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula
AL_col_formula = ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula
#保留Total行开始一直到末尾所有行的formula
total_to_last_formula = ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula
#中间计算过程省略...
#保存结果到excel
#直接把ds_df完整赋值给excel,会导致excel原有的公式被值覆盖
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
#用之前保留的formulas,重置公式
ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula = I_col_formula
ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula = N_col_formula
ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula = T_col_formula
ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula = U_col_formula
ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula = Z_col_formula
ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula = AE_col_formula
ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula = AK_col_formula
ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula = AL_col_formula
ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula = total_to_last_formula
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()Selepas ujian, kod di atas menyelesaikan masalah masalah dengan sempurna Ia memenuhi keperluan saya dan prestasinya sangat baik.
Atas ialah kandungan terperinci Bagaimanakah Python memproses fail Excel?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!