
Rumah >Peranti teknologi >AI >Apabila pembelajaran mesin dilaksanakan dalam pemanduan autonomi, terasnya bukanlah model, tetapi saluran paip
Apabila pembelajaran mesin dilaksanakan dalam pemanduan autonomi, terasnya bukanlah model, tetapi saluran paip

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-05 11:46:061531semak imbas
Artikel ini diterbitkan semula daripada Lei Feng.com Jika anda perlu mencetak semula, sila pergi ke tapak web rasmi Lei Feng.com untuk memohon kebenaran.
Apabila saya memulakan kerja pertama saya di luar kolej, saya fikir saya tahu banyak tentang pembelajaran mesin. Saya mempunyai dua latihan di Pinterest dan Khan Academy membina sistem pembelajaran mesin. Semasa tahun terakhir saya di Berkeley, saya menjalankan penyelidikan tentang pembelajaran mendalam untuk penglihatan komputer dan bekerja di Caffe, salah satu perpustakaan pembelajaran mendalam yang popular yang pertama. Selepas tamat pengajian, saya menyertai syarikat permulaan kecil yang dipanggil "Cruise", yang pakar dalam menghasilkan kereta pandu sendiri. Sekarang saya berada di Akuarium, membantu syarikat menggunakan model pembelajaran mendalam untuk menyelesaikan masalah sosial yang penting.
Saya telah membina pembelajaran mendalam yang cukup hebat dan timbunan penglihatan komputer selama ini. Lebih ramai orang menggunakan pembelajaran mendalam dalam aplikasi pengeluaran sekarang berbanding semasa saya membuat penyelidikan di Berkeley. Banyak masalah yang mereka hadapi sekarang adalah sama yang saya hadapi di Cruise pada 2016. Saya mempunyai banyak pelajaran yang dipelajari tentang pembelajaran mendalam dalam pengeluaran yang ingin saya kongsikan dengan anda, dan saya harap anda tidak perlu mempelajarinya dengan cara yang sukar.

Kapsyen: Pasukan pengarang membangunkan model pembelajaran mesin pertama yang digunakan pada kereta
1 ML Kisah tentang penempatan model pada kereta pandu sendiri
Mula-mula, izinkan saya bercakap tentang model ML pertama Cruise yang digunakan pada kereta. Semasa kami membangunkan model itu, aliran kerja terasa sama seperti yang biasa saya lakukan semasa hari penyelidikan saya. Kami melatih model sumber terbuka pada data sumber terbuka, menyepadukannya ke dalam tindanan perisian produk syarikat, dan menggunakan model tersebut ke kereta. Selepas beberapa minggu bekerja, kami menggabungkan PR terakhir dan menjalankan model pada kereta.
"Misi selesai!" Saya tidak tahu, kerja sebenar baru bermula.
Model sedang berjalan dalam pengeluaran dan pasukan QA kami mula menyedari masalah dengan prestasinya. Tetapi kami mempunyai model lain untuk dibina dan tugas lain untuk dilakukan, jadi kami tidak menangani isu tersebut dengan segera. Apabila kami meneliti isu 3 bulan kemudian, kami mendapati bahawa skrip latihan dan pengesahan semuanya telah rosak kerana pangkalan kod telah berubah sejak penggunaan pertama kami.
Selepas seminggu pembaikan, kami melihat beberapa bulan pepijat yang lalu dan menyedari bahawa banyak isu yang diperhatikan dalam proses pengeluaran model tidak dapat diselesaikan dengan mudah dengan mengubah suai kod model dan kami perlu mengumpul dan tag isu daripada data Baharu kami pada kenderaan syarikat dan bukannya bergantung pada data sumber terbuka. Ini bermakna kita perlu mewujudkan proses pelabelan, termasuk semua alatan, operasi dan infrastruktur yang diperlukan untuk proses tersebut.
Selepas 3 bulan lagi, kami menjalankan model baharu yang dilatih berdasarkan data yang kami pilih secara rawak daripada kereta. Kemudian, tandakannya dengan alat kami sendiri. Tetapi apabila kita mula menyelesaikan masalah mudah, kita perlu menjadi lebih arif tentang perubahan yang mungkin membawa akibat.
Kira-kira 90% masalah diselesaikan dengan penyusunan data yang teliti bagi senario yang sukar atau jarang berlaku, bukannya melalui perubahan seni bina model mendalam atau penalaan hiperparameter. Sebagai contoh, kami mendapati model berprestasi buruk pada hari hujan (jarang berlaku di San Francisco), jadi kami melabelkan lebih banyak data daripada hari hujan, melatih semula model pada data baharu dan prestasi model bertambah baik. Begitu juga, kami mendapati model berprestasi buruk pada frustum hijau (kurang biasa berbanding frustum oren), jadi kami mengumpul data tentang frustum hijau dan melalui proses yang sama, dan prestasi model bertambah baik.
Kita perlu mewujudkan proses yang boleh mengenal pasti dan menyelesaikan jenis isu ini dengan cepat.
Ia mengambil masa beberapa minggu untuk memasang versi 1.0 model ini, dan 6 bulan lagi untuk melancarkan versi model baharu dan dipertingkatkan. Semasa kami bekerja lebih dan lebih pada beberapa perkara (infrastruktur pelabelan yang lebih baik, pemprosesan data awan, infrastruktur latihan, pemantauan penggunaan), kami sedang melatih semula dan mengatur semula model kira-kira setiap bulan hingga setiap minggu.
Sambil kami membina lebih banyak saluran paip model dari awal dan berusaha untuk menambah baiknya, kami mula melihat beberapa tema biasa. Menggunakan apa yang kami pelajari pada saluran paip baharu, menjadi lebih mudah untuk menjalankan model yang lebih baik dengan lebih pantas dan dengan sedikit usaha.
2 Kekalkan pembelajaran berulang
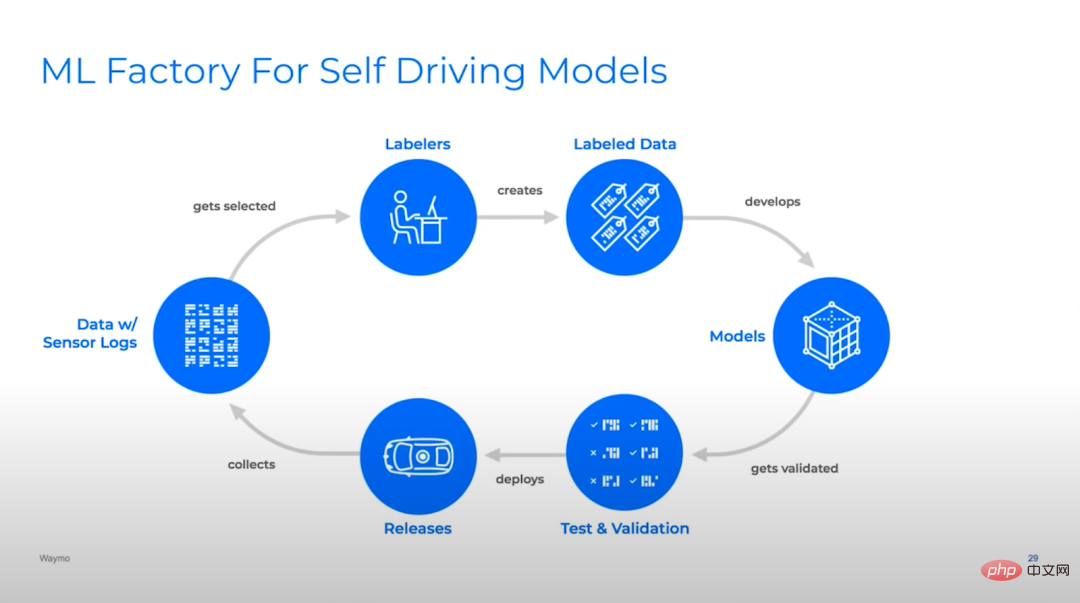
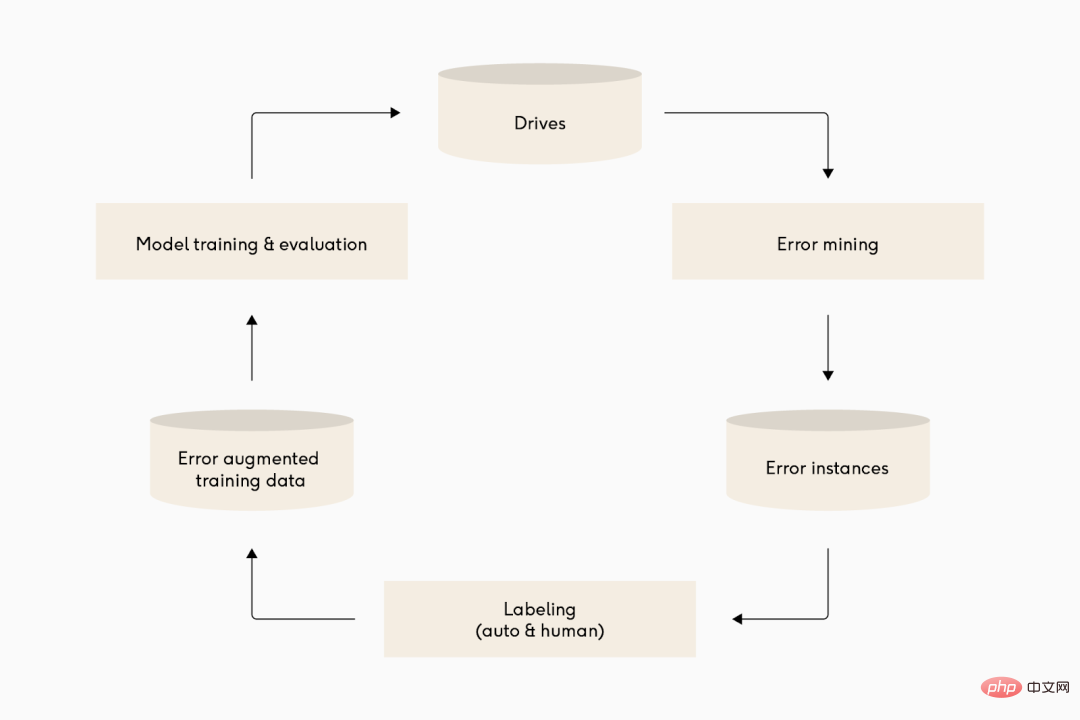
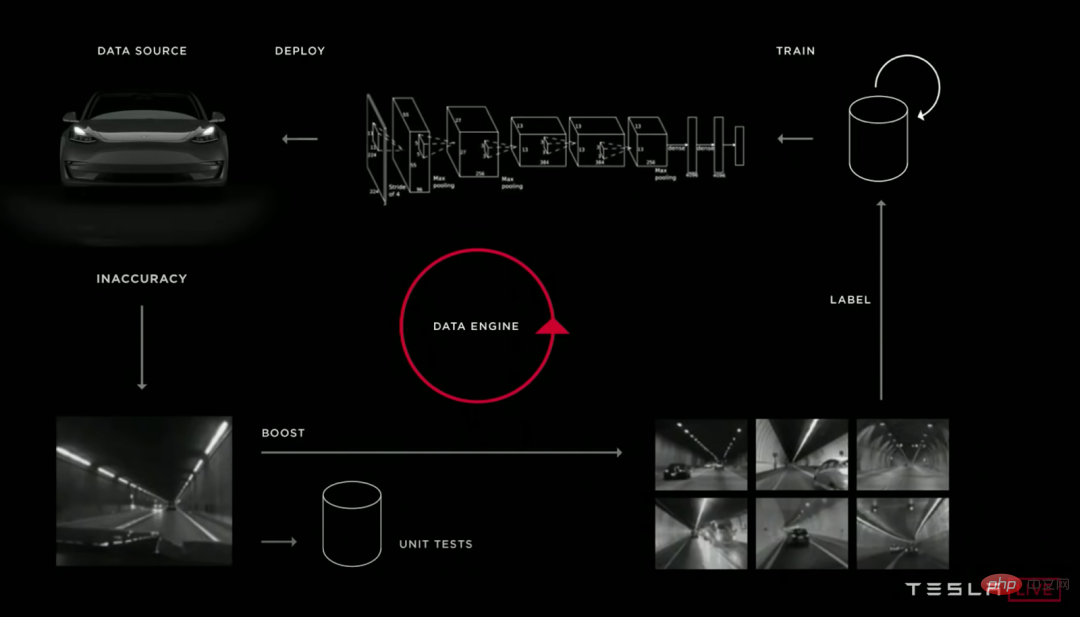
Ilustrasi: Banyak pasukan pembelajaran mendalam memandu sendiri yang berbeza mempunyai kitaran lelaran yang agak serupa bagi saluran paip model mereka. Dari atas ke bawah: Waymo, Cruise dan Tesla.
Saya pernah berfikir bahawa pembelajaran mesin adalah terutamanya mengenai model. Pada hakikatnya, pembelajaran mesin dalam pengeluaran perindustrian kebanyakannya adalah saluran paip. Salah satu peramal kejayaan terbaik ialah keupayaan untuk melelang dengan cekap pada saluran paip model. Ini bukan sahaja bermakna lelaran dengan cepat, ia bermakna lelaran dengan bijak, dan bahagian kedua adalah kritikal, jika tidak saluran paip anda akan menghasilkan model yang buruk dengan cepat.
Kebanyakan perisian tradisional menekankan lelaran pantas dan proses penghantaran tangkas, kerana keperluan produk tidak diketahui dan mesti ditemui melalui penyesuaian, jadi daripada membuat perancangan terperinci dengan andaian yang tidak stabil pada peringkat awal, adalah lebih baik untuk menyampaikan dengan cepat. MVP dan lelaran.
Sama seperti keperluan perisian tradisional adalah kompleks, domain input data yang mesti ditangani oleh sistem pembelajaran mesin adalah sangat luas. Tidak seperti pembangunan perisian biasa, kualiti model pembelajaran mesin bergantung pada pelaksanaannya dalam kod dan data yang bergantung kepada kod tersebut. Pergantungan pada data ini bermakna model pembelajaran mesin boleh "meneroka" domain input melalui pembinaan/pengurusan set data, membolehkannya memahami keperluan tugasan dan menyesuaikan diri dengannya dari semasa ke semasa tanpa perlu mengubah suai kod.
Untuk memanfaatkan ciri ini, pembelajaran mesin memerlukan konsep pembelajaran berterusan yang menekankan lelaran ke atas data dan kod. Pasukan pembelajaran mesin mesti:
- Kenal pasti masalah dalam data atau prestasi model
- Diagnosis sebab masalah berlaku
- Tukar data atau kod model untuk menyelesaikan masalah ini
- Sahkan bahawa model menjadi lebih baik selepas melatih semula
- Gunakan model baharu dan ulangi
Pasukan harus cuba melalui kitaran ini sekurang-kurangnya setiap bulan. Kalau pandai, mungkin buat setiap minggu.
Syarikat besar boleh melengkapkan kitaran penggunaan model dalam masa kurang daripada sehari, tetapi membina infrastruktur dengan cepat dan automatik adalah sukar untuk kebanyakan pasukan. Jika model dikemas kini kurang kerap daripada ini, ia boleh membawa kepada rasuah kod (talian paip model terganggu disebabkan oleh perubahan dalam pangkalan kod) atau peralihan domain data (model dalam pengeluaran tidak boleh digeneralisasikan kepada perubahan dalam data dari semasa ke semasa).
Syarikat besar boleh melengkapkan kitaran penggunaan model dalam sehari, tetapi amat sukar bagi kebanyakan pasukan untuk membina infrastruktur dengan cepat dan automatik. Mengemas kini model kurang kerap daripada ini boleh membawa kepada rasuah kod (talian paip model terganggu disebabkan oleh perubahan dalam pangkalan kod) atau peralihan domain data (model dalam pengeluaran tidak boleh digeneralisasikan kepada perubahan dalam data dari semasa ke semasa).
Walau bagaimanapun, jika dilakukan dengan betul, pasukan boleh mendapat rentak yang baik di mana mereka menggunakan model yang dipertingkatkan ke dalam pengeluaran.
3 Mewujudkan gelung maklum balas
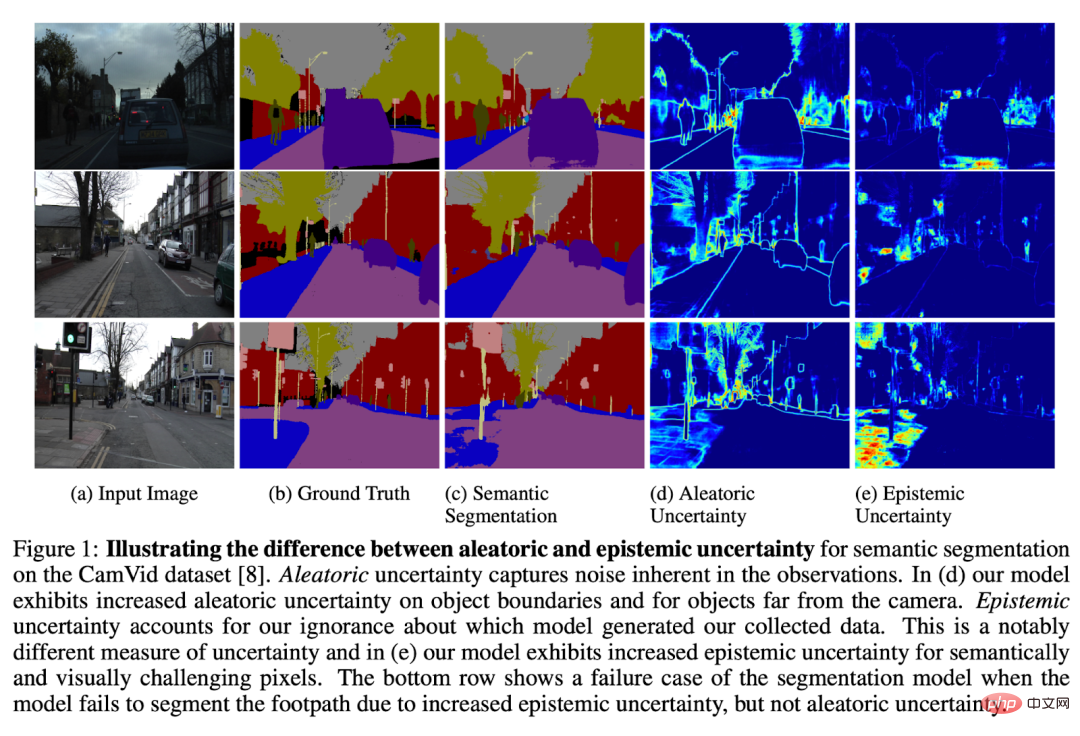
Ketidakpastian dalam menentukur model ialah bidang penyelidikan yang menarik di mana model boleh membenderakan di tempat yang difikirkannya mungkin gagal.
Bahagian penting dalam lelaran secara berkesan pada model adalah untuk menumpukan pada menyelesaikan masalah yang paling berkesan. Untuk menambah baik model, anda perlu tahu apa yang salah dengannya dan boleh mengkategorikan masalah mengikut keutamaan produk/perniagaan. Terdapat banyak cara untuk membina gelung maklum balas, tetapi ia bermula dengan mencari dan mengelaskan ralat.
Manfaatkan gelung maklum balas khusus domain.
Jika ada, ini boleh menjadi cara yang sangat berkuasa dan berkesan untuk mendapatkan maklum balas tentang model anda. Contohnya, tugas ramalan boleh mendapatkan data berlabel "secara percuma" dengan melatih data sejarah kejadian sebenar, membolehkan mereka terus diberi sejumlah besar data baharu dan menyesuaikan diri dengan situasi baharu secara automatik.
Sediakan aliran kerja yang membolehkan orang ramai menyemak output model anda dan membenderakan ralat apabila ia berlaku.
Pendekatan ini amat berguna apabila seseorang boleh menangkap ralat dengan mudah melalui banyak inferens model. Cara paling biasa ini berlaku ialah apabila pelanggan menyedari ralat dalam output model dan mengadu kepada pasukan pembelajaran mesin. Ini tidak boleh dipandang remeh kerana saluran ini membolehkan anda memasukkan maklum balas pelanggan terus ke dalam kitaran pembangunan! Satu pasukan boleh meminta manusia menyemak semula output model yang mungkin terlepas oleh pelanggan: Bayangkan seorang pengendali menonton robot menyusun pakej pada tali pinggang penghantar dan mengklik butang apabila mereka melihat ralat berlaku.
Sediakan aliran kerja yang membolehkan orang ramai menyemak output model anda dan membenderakan ralat apabila ia berlaku. Ini amat sesuai apabila ralat dalam sejumlah besar inferens model mudah ditangkap oleh semakan manusia. Cara yang paling biasa ialah apabila pelanggan menyedari ralat dalam output model dan mengadu kepada pasukan ML. Perkara ini tidak boleh dipandang remeh, kerana saluran ini membolehkan anda memasukkan maklum balas pelanggan terus ke dalam kitaran pembangunan Satu pasukan boleh meminta manusia meneliti keluaran model yang mungkin terlepas oleh pelanggan: fikirkan pengendali yang menonton pakej menyusun robot pada tali pinggang penghantar. Klik butang setiap kali mereka melihat ralat berlaku.
Pertimbangkan untuk menyediakan semakan automatik apabila model dijalankan terlalu kerap untuk disemak oleh manusia.
Ini amat berguna apabila mudah untuk menulis "semakan kewarasan" terhadap output model. Sebagai contoh, benderakan setiap kali pengesan objek lidar dan pengesan objek imej 2D tidak konsisten, atau pengesan bingkai ke bingkai tidak konsisten dengan sistem penjejakan temporal. Apabila ia berfungsi, ia memberikan banyak maklum balas berguna, memberitahu kami di mana keadaan kegagalan berlaku. Apabila ia tidak berfungsi, ia hanya mendedahkan pepijat dalam sistem semakan anda, atau terlepas setiap masa sistem itu menjadi salah, yang merupakan risiko yang sangat rendah dan ganjaran yang tinggi.
Penyelesaian yang paling umum (tetapi sukar) ialah menganalisis ketidakpastian model pada data yang dijalankan.
Contoh mudah ialah melihat contoh model yang menghasilkan output berkeyakinan rendah dalam pengeluaran. Ini boleh menunjukkan di mana model itu memang tidak pasti, tetapi tidak 100% tepat. Kadangkala, model boleh menjadi salah dengan yakin. Kadangkala model tidak dapat ditentukan kerana kekurangan maklumat yang tersedia untuk inferens yang baik (cth., data input bising yang sukar difahami oleh manusia). Terdapat model yang menangani isu ini, tetapi ini adalah bidang penyelidikan yang aktif.
Akhir sekali, maklum balas model tentang set latihan boleh digunakan.
Contohnya, menyemak ketidakkonsistenan antara model dan set data latihan/pengesahannya (iaitu contoh kehilangan tinggi) menunjukkan kegagalan keyakinan tinggi atau pelabelan yang salah. Analisis pembenaman rangkaian saraf boleh menyediakan cara untuk memahami corak mod kegagalan dalam set data latihan/pengesahan, dan boleh mendedahkan perbezaan dalam pengagihan data mentah dalam set data latihan dan pengeluaran.

Kapsyen: Masa kebanyakan orang mudah dikeluarkan daripada kitaran latihan semula biasa. Walaupun ini melibatkan kos masa mesin yang kurang cekap, ia menghilangkan banyak kesakitan manual.
Kandungan utama mempercepatkan lelaran adalah untuk mengurangkan jumlah kerja yang diperlukan untuk melengkapkan kitaran lelaran. Walau bagaimanapun, sentiasa ada cara untuk memudahkan urusan, jadi anda perlu mengutamakan perkara yang ingin anda perbaiki. Saya suka memikirkan usaha dalam dua cara: masa jam dan masa manusia.
Masa jam merujuk kepada masa yang diperlukan untuk menjalankan tugas pengkomputeran tertentu, seperti ETL data, model latihan, menjalankan inferens, mengira metrik, dsb. Masa manusia merujuk kepada masa manusia mesti campur tangan secara aktif untuk menjalankan saluran paip, seperti menyemak hasil secara manual, menjalankan arahan atau mencetuskan skrip di tengah-tengah saluran paip.
Sebagai contoh, berbilang skrip mesti dijalankan secara manual mengikut urutan dengan mengalihkan fail secara manual antara langkah, yang sangat biasa, tetapi membazir. Beberapa matematik tuala kertas belakang: Jika jurutera pembelajaran mesin berharga $90 sejam dan membazirkan 2 jam seminggu menjalankan skrip dengan tangan, itu menambah sehingga $9,360 setiap orang setahun!
Menggabungkan berbilang skrip dan gangguan manusia menjadi satu skrip automatik sepenuhnya menjadikan menjalankan gelung saluran paip model lebih pantas dan lebih mudah, menjimatkan banyak wang dan menjadikan jurutera pembelajaran mesin anda kurang pelik.
Sebaliknya, masa jam selalunya perlu "munasabah" (cth., boleh dilakukan semalaman). Satu-satunya pengecualian adalah jika jurutera pembelajaran mesin menjalankan eksperimen yang meluas, atau jika terdapat kekangan kos/skala yang melampau. Ini kerana masa jam biasanya berkadar dengan saiz data dan kerumitan model. Apabila beralih daripada pemprosesan tempatan kepada pemprosesan awan teragih, masa jam dikurangkan dengan ketara. Selepas itu, penskalaan mendatar dalam awan cenderung untuk menyelesaikan kebanyakan masalah untuk kebanyakan pasukan sehingga masalah bertambah besar.
Malangnya, tidak mungkin untuk mengautomasikan sepenuhnya beberapa tugasan. Hampir semua aplikasi pembelajaran mesin pengeluaran adalah tugas pembelajaran yang diselia, dan kebanyakannya bergantung pada beberapa jumlah interaksi manusia-komputer untuk memberitahu model perkara yang harus dilakukannya. Di sesetengah kawasan, interaksi manusia-komputer adalah percuma (mis., kes penggunaan pengesyoran media sosial atau aplikasi lain dengan jumlah maklum balas pengguna langsung yang besar). Dalam kes lain, masa manusia lebih terhad atau mahal, seperti apabila ahli radiologi terlatih "melabel" imbasan CT untuk data latihan.
Bagaimanapun, adalah penting untuk meminimumkan masa buruh dan kos lain yang diperlukan untuk menambah baik model. Walaupun pasukan awal mungkin bergantung kepada jurutera pembelajaran mesin untuk mengurus set data, selalunya lebih menjimatkan (atau dalam kes pakar radiologi, diperlukan) untuk mempunyai pengguna operasi atau pakar domain tanpa pengetahuan pembelajaran mesin melakukan pengurusan data yang berat. Pada ketika ini, menjadi penting untuk mewujudkan proses operasi untuk pelabelan, pemeriksaan, penambahbaikan dan versi set data menggunakan alat perisian yang baik.
5 Galakkan jurutera ML untuk bersenam

Lagenda: Semasa jurutera ML mengangkat berat, mereka juga meningkatkan berat pembelajaran model mereka
Membina alatan yang mencukupi untuk menyokong domain baharu atau kumpulan pengguna baharu boleh mengambil banyak masa dan usaha, tetapi jika dilakukan dengan baik, hasilnya akan berbaloi. Salah seorang jurutera saya di Cruise sangat bijak (ada yang akan berkata malas).
Jurutera ini mewujudkan gelung berulang di mana gabungan maklum balas operasi dan pertanyaan metadata akan mengekstrak dan melabelkan data yang prestasi modelnya lemah. Pasukan operasi luar pesisir kemudian akan melabelkan data dan menambahkannya pada versi baharu set data latihan. Selepas itu, jurutera menyediakan infrastruktur yang membolehkan mereka menjalankan skrip pada komputer mereka dan melancarkan satu siri tugas awan untuk melatih semula secara automatik dan mengesahkan model mudah pada data yang baru ditambah.
Setiap minggu, mereka menjalankan skrip latihan semula. Kemudian, sementara model itu melatih dan mengesahkan dirinya, mereka pergi ke gim. Selepas beberapa jam kecergasan dan makan malam, mereka akan kembali untuk menyemak keputusan. Secara kebetulan, data baharu dan dipertingkatkan akan membawa kepada penambahbaikan pada model, dan selepas semakan dua kali pantas untuk memastikan semuanya masuk akal, mereka kemudian menghantar model baharu ke pengeluaran dan kebolehmanduan kereta akan bertambah baik. Mereka kemudian menghabiskan masa seminggu untuk menambah baik infrastruktur, bereksperimen dengan seni bina model baharu dan membina saluran paip model baharu. Jurutera ini bukan sahaja mendapat kenaikan pangkat pada penghujung suku tahun, dia juga dalam keadaan yang sangat baik.
6 Kesimpulan
Untuk meringkaskan: Semasa fasa penyelidikan dan pembangunan prototaip, tumpuan diberikan kepada membina dan menerbitkan model. Walau bagaimanapun, apabila sistem bergerak ke dalam pengeluaran, tugas teras adalah untuk membina sistem yang boleh mengeluarkan model yang dipertingkatkan secara kerap dengan usaha yang minimum. Lebih baik anda mendapat ini, lebih banyak model yang anda boleh bina!
Untuk melakukan ini, kita perlu memberi tumpuan kepada perkara berikut:
- Jalankan saluran paip model pada irama biasa dan fokus untuk menjadikan model penghantaran lebih baik daripada sebelumnya. Dapatkan model baharu dan dipertingkatkan ke dalam pengeluaran setiap minggu atau kurang!
- Tetapkan gelung maklum balas yang baik daripada output model kepada proses pembangunan. Ketahui contoh model yang kurang baik dan tambahkan lebih banyak contoh pada set data latihan anda.
- Automasikan tugasan tugas berat terutamanya dalam perancangan anda dan wujudkan struktur pasukan yang membolehkan ahli pasukan anda menumpukan pada bidang kepakaran mereka. Andrej Karpathy Tesla memanggil keadaan akhir yang ideal "Cuti Operasi." Saya cadangkan, sediakan aliran kerja di mana jurutera pembelajaran mesin anda pergi ke gim dan biarkan saluran paip pembelajaran mesin anda melakukan kerja berat!
Akhir sekali, perlu ditekankan bahawa dalam pengalaman saya, kebanyakan masalah tentang prestasi model boleh diselesaikan dengan data, tetapi beberapa masalah hanya boleh diselesaikan dengan mengubah suai kod model.
Perubahan ini selalunya sangat khusus untuk seni bina model yang ada, contohnya, selepas bekerja pada pengesan objek imej selama beberapa tahun, saya menghabiskan terlalu banyak masa untuk bimbang tentang tugasan kotak sebelumnya yang terbaik untuk nisbah orientasi tertentu dan meningkatkan peleraian peta ciri untuk objek kecil.
Walau bagaimanapun, sebagai Transformers menunjukkan janji untuk menjadi jenis seni bina model universal untuk banyak tugas pembelajaran mendalam yang berbeza, saya mengesyaki bahawa lebih banyak teknik ini akan menjadi kurang relevan dan tumpuan pembangunan pembelajaran mesin akan beralih lebih baik Memperbaik data ditetapkan.
Atas ialah kandungan terperinci Apabila pembelajaran mesin dilaksanakan dalam pemanduan autonomi, terasnya bukanlah model, tetapi saluran paip. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI