
Rumah >Peranti teknologi >AI >Topik Khas ChatGPT: Keupayaan dan Masa Depan Model Bahasa Besar
Topik Khas ChatGPT: Keupayaan dan Masa Depan Model Bahasa Besar

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-02 21:34:052445semak imbas
1. Pengkomersialan model generatif
Kini, trek AI generatif sedang hangat. Menurut statistik PitchBook, landasan AI generatif akan menerima sejumlah kira-kira AS$1.4 bilion dalam pembiayaan pada 2022, hampir mencecah jumlah keseluruhan lima tahun yang lalu. Syarikat bintang seperti OpenAI dan Stability AI, dan syarikat permulaan lain seperti Jasper, Regie.AI, Replika, dll. semuanya telah menerima bantuan modal.
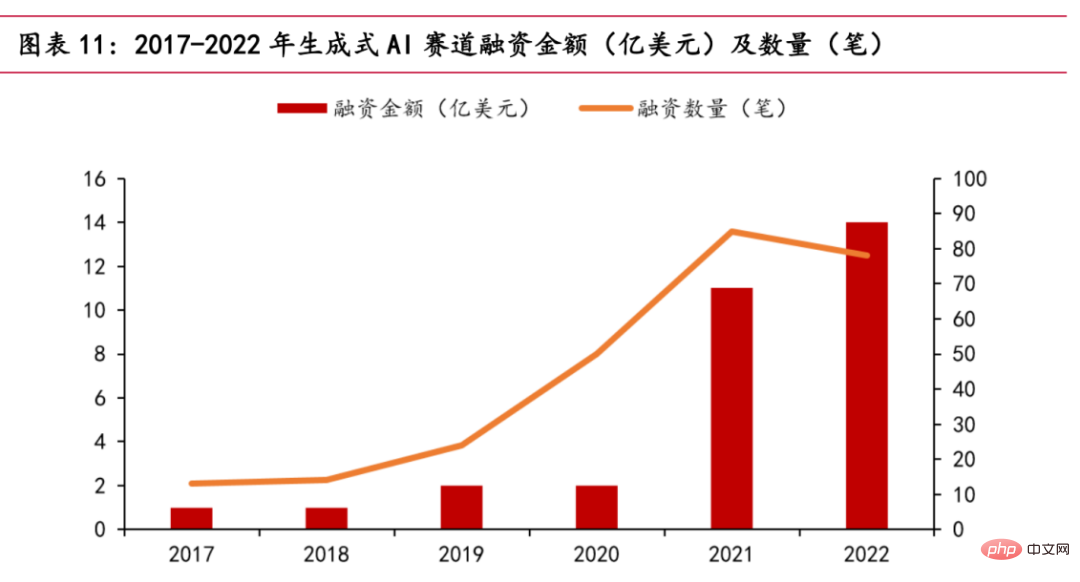
Carta hubungan antara jumlah pembiayaan dan masa
Pada Oktober 2022, Stability AI menerima kira-kira AS$100 juta dalam pembiayaan, dan model sumber terbuka yang dikeluarkan Stable Penyebaran boleh berdasarkan Input penerangan teks oleh pengguna menjana gambar, meletupkan bidang lukisan AI. Pada 30 November 2022, selepas ChatGPT mengumumkan beta awamnya, lima hari selepas ia masuk dalam talian, bilangan pengguna global melebihi satu juta. Dalam masa kurang daripada 40 hari sejak pelancarannya, pengguna aktif harian telah melebihi 10 juta. Pada awal pagi 15 Mac 2023, OpenAI mengeluarkan model siri GPT-GPT-4 terkuat pada masa ini, yang menyediakan model berbilang modal berskala besar yang boleh menerima input imej dan teks serta menghasilkan output teks, yang mempunyai kesan gangguan dalam industri. Pada 17 Mac 2023, Microsoft mengadakan persidangan Microsoft 365 Copilot, secara rasmi memasang model GPT-4 OpenAI ke dalam suite Office, dan melancarkan Copilot fungsi AI baharu. Ia bukan sahaja boleh membuat PPT dan menulis salinan, tetapi juga melakukan analisis dan menjana video. Selain itu, pelbagai pengeluar domestik utama turut mengumumkan pelancaran produk serupa dengan ChatGPT. Pada 8 Februari, pakar Alibaba mengumumkan bahawa Akademi Damo sedang membangunkan robot perbualan seperti ChatGPT dan telah membukanya kepada pekerja dalam syarikat untuk ujian. Adalah mungkin untuk menggabungkan teknologi model besar AI secara mendalam dengan alat produktiviti DingTalk. Pada 8 Februari, He Xiaodong, Naib Presiden JD.com, berkata terus terang: JD.com mempunyai senario yang kaya dan data berkualiti tinggi dalam bidang ChatGPT. Pada 9 Februari, sumber berkaitan di Tencent berkata: Tencent kini mempunyai rancangan untuk produk yang serupa dengan kandungan ChatGPT dan AI, dan penyelidikan khas juga sedang berjalan dengan teratur. NetEase berkata bahawa perniagaan pendidikannya akan menyepadukan kandungan yang dijana AI, termasuk tetapi tidak terhad kepada guru penutur AI, pemarkahan dan penilaian esei, dsb. Pada 16 Mac, Baidu secara rasmi mengeluarkan model bahasa besar dan produk AI generatif "Wen Xin Yi Yan" Dua hari selepas dikeluarkan, 12 syarikat telah melengkapkan kumpulan pertama kerjasama kontrak dan memohon panggilan API Baidu Intelligent Cloud Wen Xin Yi Yan. perkhidmatan. Bilangan syarikat yang diuji mencecah 90,000.
Pada masa ini, model besar telah secara beransur-ansur menembusi kehidupan kita. Pada masa hadapan, semua lapisan masyarakat berkemungkinan akan mengalami perubahan yang menggegarkan bumi. Mengambil ChatGPT sebagai contoh, ia merangkumi aspek berikut:
- Media ChatGPT+: Ia boleh merealisasikan penulisan berita pintar dan meningkatkan keberkesanan berita
- ChatGPT+ Filem dan Televisyen: Sesuaikan filem dan kandungan televisyen mengikut minat awam Mendapat penarafan yang lebih tinggi, box office dan dari mulut ke mulut mengurangkan kos penciptaan kandungan untuk pasukan penerbitan filem dan televisyen dan meningkatkan kecekapan kreatif.
- Pemasaran ChatGPT+: Bertindak sebagai perkhidmatan pelanggan maya untuk membantu pemasaran produk. Sebagai contoh, pengenalan produk 24 jam dan perkhidmatan dalam talian mengurangkan kos pemasaran dengan cepat dapat memahami keperluan pelanggan dan mengikuti aliran teknologi menyediakan perkhidmatan perundingan yang stabil dan boleh dipercayai dengan kawalan dan keselamatan yang kukuh;
- ChatGPT+Hiburan: Objek sembang masa nyata, mempertingkatkan persahabatan dan keseronokan.
- Pendidikan ChatGPT+: Menyediakan alat pendidikan baharu untuk menyemak dan mengisi jurang dengan cepat melalui soalan layan diri.
- ChatGPT+ Finance: Realisasikan maklumat kewangan, pengeluaran automatik produk kewangan dan cipta penasihat kewangan maya.
- SembangGPT+Perubatan: Fahami keadaan pesakit dengan cepat dan berikan maklum balas tepat pada masanya, memberikan sokongan emosi segera.
Perlu diingatkan bahawa walaupun perbincangan utama di sini ialah pelaksanaan model bahasa yang besar, sebenarnya, model besar berbilang modal (audio, video, gambar) lain juga mempunyai senario aplikasi yang luas.
2. Pengenalan kepada model generatif
1. Model bahasa besar arus perdana: LaMDA
dikeluarkan oleh Google. Model LaMDA adalah berdasarkan rangka kerja pengubah, mempunyai 137 bilion parameter model dan mempunyai keupayaan untuk memodelkan kebergantungan jarak jauh dalam teks. Model dilatih melalui perbualan. Ia terutamanya merangkumi dua proses: pra-latihan dan penalaan halus: Dalam peringkat pra-latihan, mereka menggunakan sehingga 1.56T set data perbualan awam dan teks halaman web, menggunakan model bahasa (LM) sebagai fungsi objektif latihan, iaitu matlamatnya adalah untuk meramal watak seterusnya (token). Dalam fasa penalaan halus, mereka mereka bentuk berbilang tugas, seperti atribut pemarkahan respons (sensitiviti, keselamatan, dll.), untuk memberikan model bahasa pilihan manusianya. Rajah di bawah menunjukkan satu jenis tugasan penalaan halus.

Fasa pra-latihan model LaMDA

Salah satu tugas fasa penalaan halus model LaMDA
Model LaMDA Memfokuskan pada tugas penjanaan dialog tetapi sering membuat kesilapan fakta. Google mengeluarkan Bard (perkhidmatan AI perbualan percubaan) tahun ini, yang dikuasakan oleh model LaMDA. Walau bagaimanapun, semasa sidang akhbar Bard, Bard membuat kesilapan fakta, yang menyebabkan harga saham Google menjunam pada hari Rabu, jatuh lebih daripada 8% semasa sesi itu serendah kira-kira AS$98 pada hari penyegaran, dan nilai pasarannya hilang sebanyak AS$110 bilion, yang mengecewakan.
2. Model bahasa besar arus perdana: InstructGPT
Model InstructGPT adalah berdasarkan seni bina GPT dan terutamanya terdiri daripada penalaan halus diselia (Supervise Fune-Tuning, SFT) dan pembelajaran pengukuhan maklum balas manusia (Reinforce Learning Penalaan Fune Manusia, RLHF). ChatGPT, produk perbualan yang dikuasakan oleh InstructGPT, menumpukan pada penjanaan teks bahasa, dan juga boleh menjana kod dan melaksanakan operasi matematik yang mudah. Butiran teknikal khusus telah dibincangkan secara terperinci dalam dua isu sebelumnya. Pembaca boleh membacanya di sini dan tidak akan mengulanginya di sini.
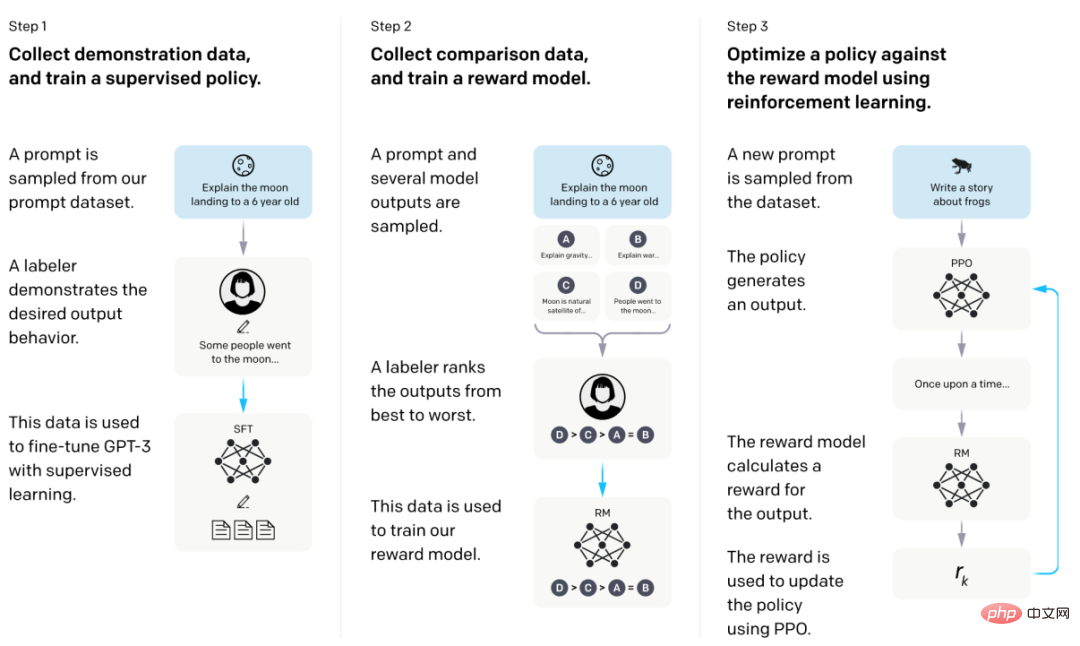
Carta aliran latihan model InstructGPT
3. Model bahasa besar arus perdana: Cluade
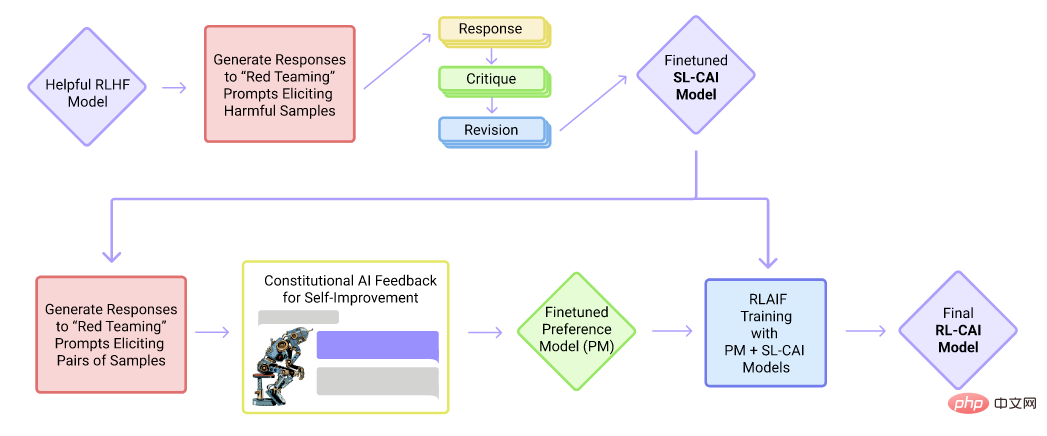
Cluade. carta aliran latihan model
Cluade ialah produk perbualan Syarikat Anthropic. Cluade, seperti ChatGPT, adalah berdasarkan rangka kerja GPT dan merupakan model bahasa sehala. Walau bagaimanapun, tidak seperti ChatGPT, ia dilatih terutamanya oleh penalaan halus dan pembelajaran pengukuhan yang diselia dengan maklum balas AI. Dalam peringkat penalaan halus yang diselia, ia mula-mula merumuskan satu siri peraturan (Perlembagaan), seperti tiada maklumat berbahaya, tiada berat sebelah kaum, dsb., dan kemudian memperoleh data yang diselia berdasarkan peraturan ini. Kemudian, biarkan AI menilai kualiti respons dan melatih set data secara automatik untuk pembelajaran pengukuhan.
Berbanding dengan ChatGPT, Claude boleh menolak permintaan yang tidak sesuai dengan lebih jelas, dan perkaitan antara ayat lebih semula jadi. Claude sanggup bersuara apabila berhadapan dengan masalah yang di luar kemampuannya. Pada masa ini, Cluade masih dalam peringkat ujian dalaman. Bagaimanapun, menurut keputusan ujian dalaman ahli pasukan Scale Sepllbook, berbanding ChatGPT, Claude lebih kuat dalam 8 daripada 12 tugasan yang diuji.
3. Keupayaan model bahasa besar
Kami mempunyai statistik tentang model bahasa besar di dalam dan luar negara, serta keupayaan model, status sumber terbuka, dsb.
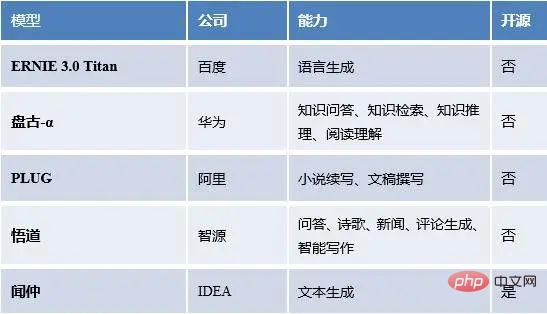
Model bahasa besar popular domestik
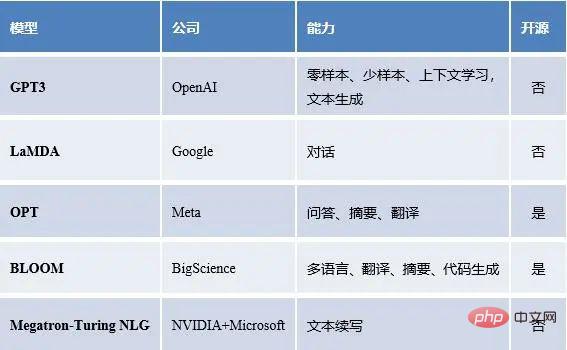
Model bahasa besar popular asing
boleh dilihat Ia ternyata model bahasa yang besar mempunyai pelbagai keupayaan, termasuk tetapi tidak terhad kepada pembelajaran beberapa pukulan, pemindahan sifar pukulan dan sebagainya. Jadi persoalan yang sangat wajar timbul, bagaimana kebolehan ini muncul? Dari mana datangnya kuasa model bahasa yang besar? Seterusnya, kami cuba menjawab keraguan di atas.
Rajah di bawah menunjukkan beberapa model bahasa besar yang matang dan proses evolusi. Kesimpulannya, kebanyakan model akan melalui tiga peringkat: pra-latihan, penalaan halus arahan dan penjajaran. Model perwakilan termasuk Deepmind's Sparrow dan OpenAI's ChatGPT.
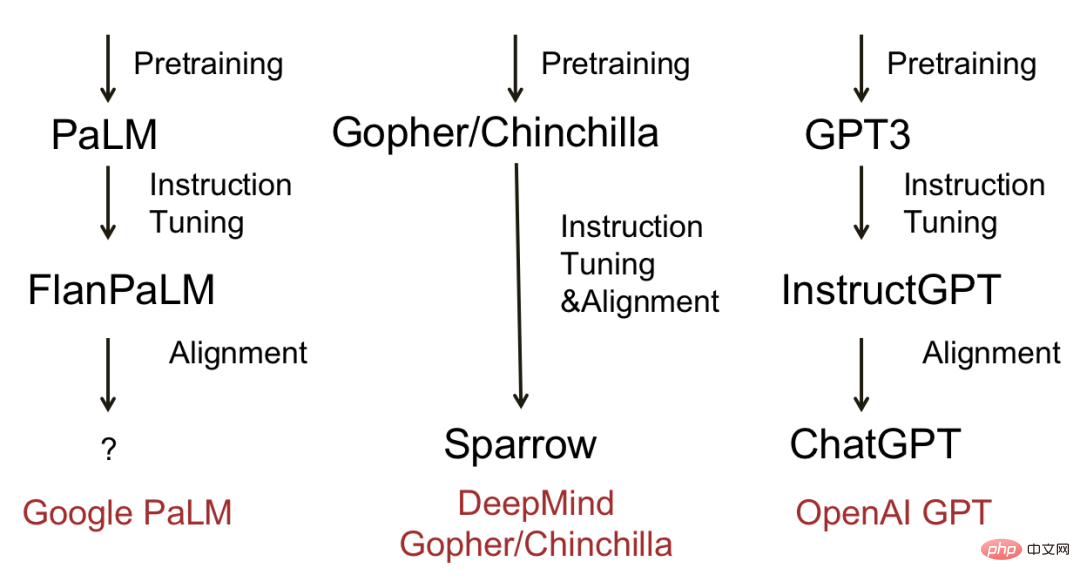
Rajah evolusi model bahasa besar yang popular
Jadi, di sebalik setiap langkah, apakah jenis keupayaan yang boleh dicapai oleh model itu? Dr. Fu Yao dari Universiti Edinburgh meringkaskan perkara yang dipercayainya sebagai hubungan yang sepadan antara langkah dan kebolehan, memberikan kami sedikit inspirasi.
1. Fasa pra-latihan Matlamat fasa ini adalah untuk mendapatkan model asas yang berkuasa. Sejajar dengan itu, keupayaan yang ditunjukkan oleh model pada peringkat ini termasuk: penjanaan bahasa, keupayaan pembelajaran konteks, pengetahuan dunia, keupayaan penaakulan, dll. Model perwakilan pada peringkat ini termasuk GPT-3, PaLM, dsb.
2. Tahap penalaan halus. Matlamat fasa ini adalah untuk membuka beberapa kebolehan yang muncul. Keupayaan timbul di sini secara khusus merujuk kepada keupayaan yang tidak dimiliki oleh model kecil tetapi hanya model besar sahaja. Model yang telah menjalani penalaan halus arahan mempunyai keupayaan yang tidak dimiliki oleh model asas. Sebagai contoh, dengan membina arahan baru, model boleh menyelesaikan tugasan baru contoh lain ialah keupayaan rantaian pemikiran, iaitu, dengan menunjukkan model proses penaakulan, model juga boleh meniru penaakulan yang betul, dll. Model perwakilan termasuk InstructGPT, Flan, dsb.
Fasa penjajaran. Matlamat peringkat ini adalah untuk menjadikan model itu mempunyai nilai kemanusiaan, seperti untuk menjana balasan bermaklumat dan bukan untuk menghasilkan kenyataan diskriminasi, dsb. Ia boleh dianggap bahawa peringkat penjajaran memberikan model "personaliti". Model perwakilan jenis ini ialah ChatGPT.
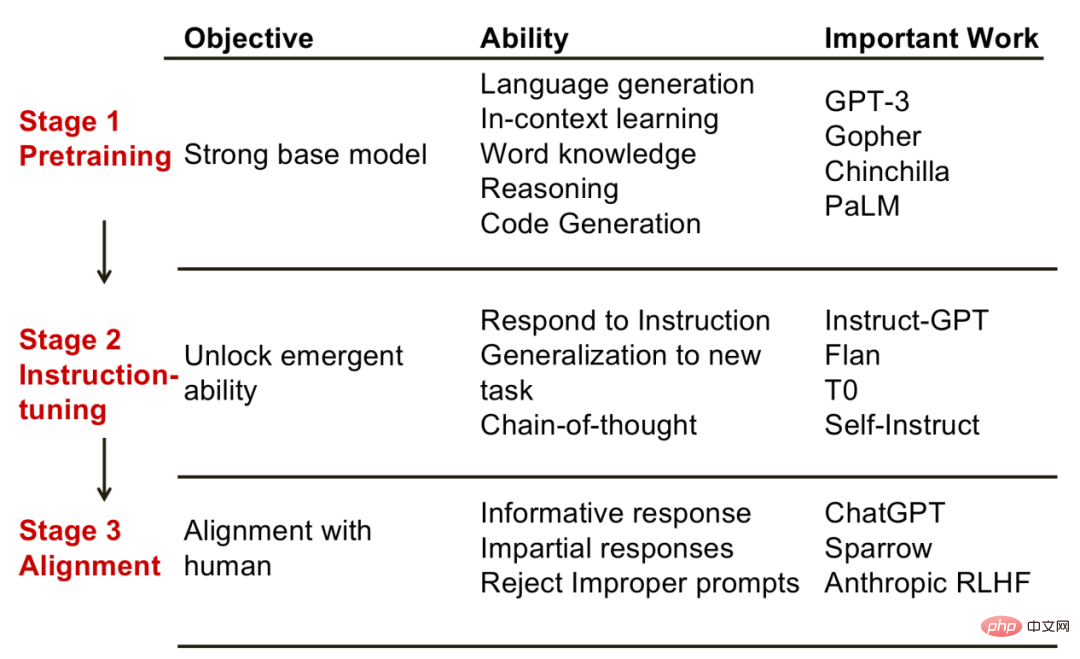
Tiga peringkat model bahasa besar. Gambar itu datang daripada "Fu Yao: Mengenai Sumber Keupayaan Model Bahasa Besar"
Secara umumnya, ketiga-tiga peringkat di atas saling melengkapi dan amat diperlukan. Hanya apabila model asas yang cukup berkuasa diperoleh dalam peringkat pra-latihan bolehlah untuk merangsang (atau meningkatkan) keupayaan lain model bahasa melalui penalaan halus arahan. Peringkat penjajaran memberikan model "watak" tertentu untuk lebih mematuhi beberapa keperluan masyarakat manusia.
4. Pengenalpastian model generatif
Walaupun teknologi model bahasa besar membawa kemudahan, ia juga mengandungi risiko dan cabaran. Pada peringkat teknikal, ketulenan kandungan yang dijana oleh GPT tidak boleh dijamin, seperti pertuturan berbahaya, dsb. Pada peringkat penggunaan, pengguna mungkin menyalahgunakan teks yang dijana AI dalam bidang seperti pendidikan dan penyelidikan saintifik. Pada masa ini, banyak syarikat dan institusi telah mula mengenakan sekatan ke atas penggunaan ChatGPT. Microsoft dan Amazon telah melarang pekerja syarikat daripada berkongsi data sensitif kepada ChatGPT kerana bimbang membocorkan maklumat sulit Universiti Hong Kong telah mengharamkan penggunaan ChatGPT atau alat kecerdasan buatan lain dalam semua kelas, tugasan dan penilaian di Universiti Hong Kong. Kami terutamanya memperkenalkan kerja berkaitan dalam industri.
GPTZero: GPTZero ialah alat penjanaan teks dan pengenalan yang terawal. Ia adalah laman web dalam talian (https://gptzero.me/) yang diterbitkan oleh Edward Tian (pelajar sarjana muda CS dari Princeton, Amerika Syarikat). Prinsipnya bergantung pada kebingungan teks (PPL) sebagai penunjuk untuk menentukan siapa yang menulis kandungan yang diberikan. Antaranya, kebingungan digunakan untuk menilai kualiti model bahasa, yang pada asasnya untuk mengira kebarangkalian ayat muncul.
Antara muka tapak web GPTZero
(Di sini kami menggunakan ChatGPT untuk menjana laporan berita dan membenarkan GPTZero menentukan sama ada ia dijana teks.)
Pengesan Output GPT2: Alat ini diterbitkan oleh OpenAI. Ia memanfaatkan set data "Kandungan Dijana GPT2" dan Reddit, diperhalusi pada RoBerta, untuk mempelajari pengelas pengesanan. Iaitu, "lawan sihir dengan sihir." Laman web rasmi juga mengingatkan bahawa keputusan ramalan lebih boleh dipercayai hanya apabila teks melebihi 50 aksara (token).

Antara muka tapak web Pengesan Output GPT2
Pengelas Teks AI: Alat ini dikeluarkan oleh OpenAI. Prinsipnya adalah untuk mengumpul teks tulisan manusia dan teks penulisan AI pada topik yang sama. Bahagikan setiap teks kepada pasangan gesaan dan balas, dan biarkan kebarangkalian GPT menghasilkan jawapan selepas penalaan halus (contohnya, membenarkan GPT menghasilkan Ya/Tidak) sebagai ambang keputusan. Pengelasan alat ini sangat terperinci, dan hasilnya termasuk 5 kategori: sangat tidak mungkin dijana oleh AI (ambang 0.98).
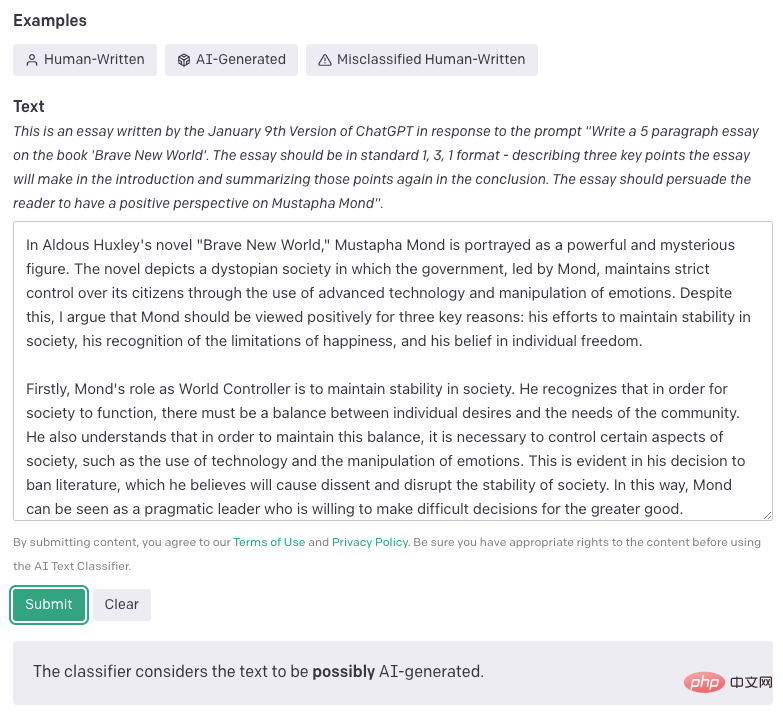
Antara muka laman web Pengelas Teks AI
5 Ringkasan & Tinjauan
Model bahasa besar mempunyai keupayaan muncul yang tidak dimiliki oleh model kecil. seperti pembelajaran sampel sifar yang sangat baik, pemindahan domain dan keupayaan rantai pemikiran. Keupayaan model besar sebenarnya datang daripada pra-latihan, penalaan halus arahan dan penjajaran Ketiga-tiga proses ini berkait rapat dan telah membolehkan model bahasa besar yang sangat berkuasa hari ini.
Model bahasa besar (siri GPT) pada masa ini tidak mempunyai keupayaan kemas kini keyakinan, penaakulan formal, carian Internet, dsb. Sesetengah pakar percaya bahawa jika pengetahuan boleh diturunkan di luar model, bilangan parameter akan dikurangkan dengan banyak, dan model bahasa besar akan dikurangkan dengan banyaknya. Model benar-benar boleh melangkah lebih jauh.
Hanya di bawah pengawasan dan tadbir urus yang munasabah, teknologi kecerdasan buatan boleh memberi perkhidmatan yang lebih baik kepada orang ramai. Masih jauh lagi untuk membangunkan model berskala besar di China!
Rujukan
[1] https://stablediffusionweb.com
[2] https://openai.com/product/gpt-4
[3] LaMDA: Model Bahasa untuk Aplikasi Dialog, Arxiv 2022.10
[4] AI Perlembagaan: Ketidakmudaratan daripada Maklum Balas AI, Arxiv 2022.12
[5] https://scale.com / blog/chatgpt-vs-claude#Calculation
[6] Guolian Securities: "ChatGPT telah tiba, dan pengkomersilan semakin pantas"
[7] Guotai Junan Securities: "Rangka Kerja Penyelidikan ChatGPT 2023》
[8] Fu Yao: Pra-latihan, penalaan halus arahan, penjajaran, pengkhususan: Mengenai sumber keupayaan model bahasa yang besar https://www.bilibili.com/video/BV1Qs4y1h7pn/?spm_id_from= 333.880 .my_history.page.click&vd_source=da8bf0b993cab65c4de0f26405823475
[9] Analisis artikel sepanjang 10,000 perkataan! Hasilkan semula dan gunakan GPT-3/ChatGPT, perkara yang anda patut tahu https://mp.weixin.qq.com/s/ILpbRRNP10Ef1z3lb2CqmA
Atas ialah kandungan terperinci Topik Khas ChatGPT: Keupayaan dan Masa Depan Model Bahasa Besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI