
Rumah >Peranti teknologi >AI >Baca semua model generatif SOTA dalam satu artikel: ulasan lengkap 21 model dalam sembilan kategori!
Baca semua model generatif SOTA dalam satu artikel: ulasan lengkap 21 model dalam sembilan kategori!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-02 15:43:072109semak imbas
Dalam dua tahun yang lalu, terdapat lonjakan dalam pengeluaran model generatif berskala besar dalam industri AI, terutamanya selepas sumber terbuka Stable Diffusion dan antara muka terbuka ChatGPT, yang telah merangsang lagi keghairahan industri untuk model generatif.
Namun, terdapat banyak jenis model generatif dan kelajuan keluarannya sangat pantas Jika anda tidak berhati-hati, anda mungkin terlepas sota
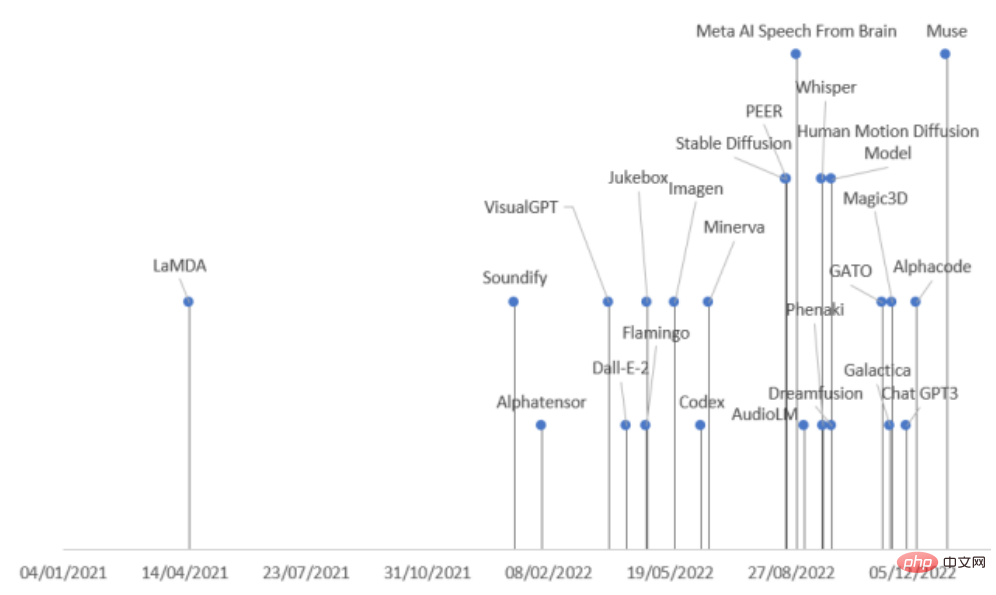
Baru-baru ini, dari Comilla, Sepanyol Penyelidik dari Universiti Bishop St. John menyemak secara menyeluruh kemajuan terkini dalam AI dalam pelbagai bidang, membahagikan model generatif kepada sembilan kategori mengikut mod dan bidang tugas, dan meringkaskan 21 model generatif yang dikeluarkan pada tahun 2022 untuk memahami penjanaan sekaligus sejarah pembangunan model!

Pautan kertas: https://arxiv.org/abs/2301.04655
Klasifikasi AI Generatif
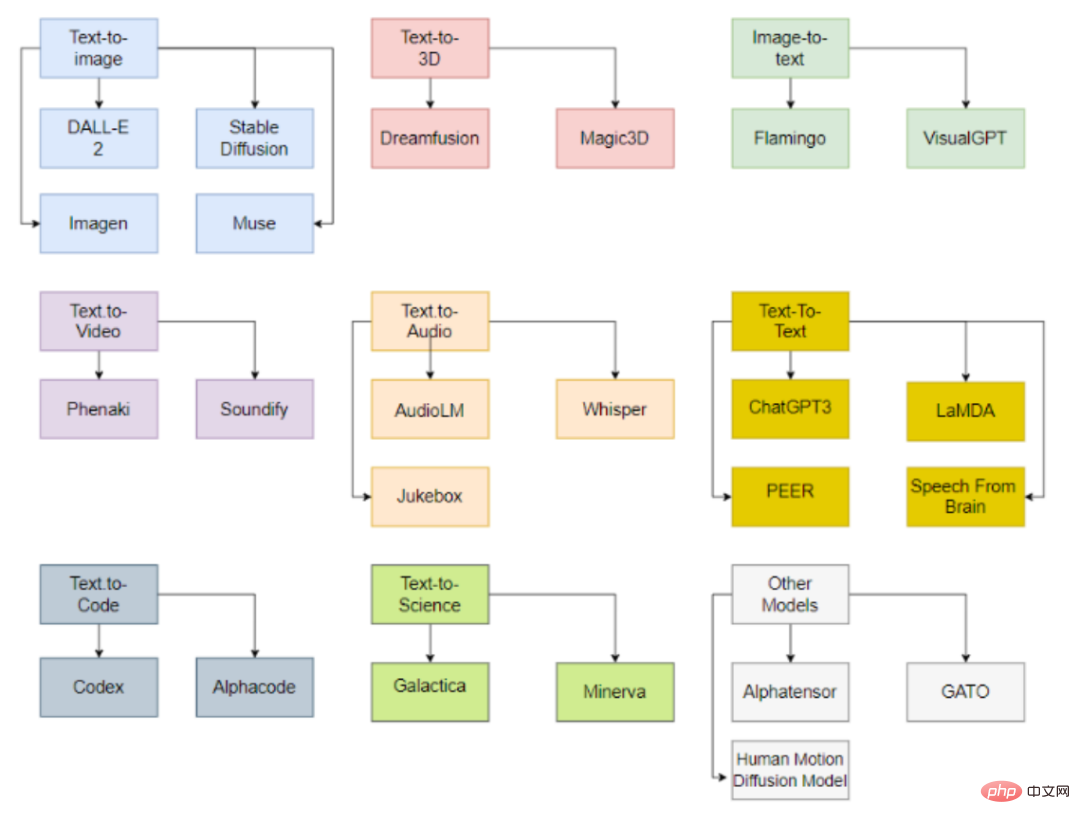
Model boleh mengikut input dan Jenis data output dikelaskan, pada masa ini terutamanya termasuk 9 kategori.
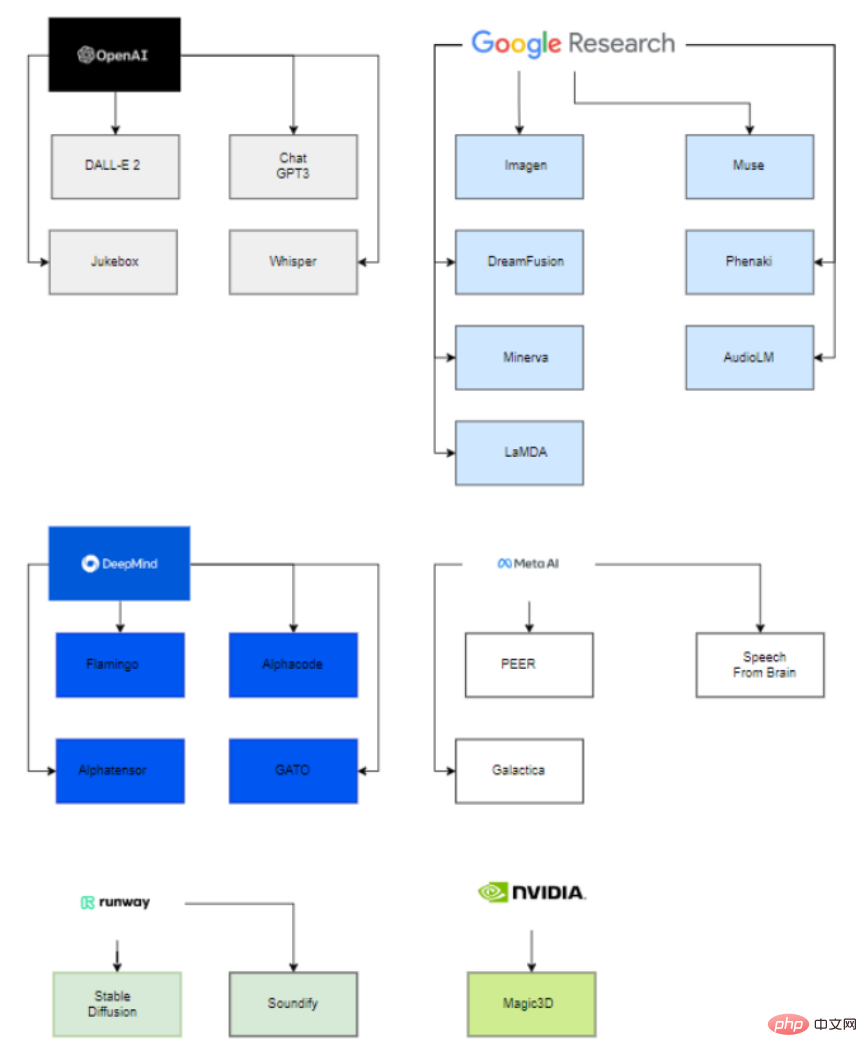
Apa yang menarik ialah di sebalik model besar yang diterbitkan ini, hanya enam organisasi (OpenAI, Google, DeepMind, Meta, Runway, Nvidia) terlibat dalam menggunakan model terbaharu ini. Model lanjutan.
Sebab utamanya ialah untuk dapat menganggar parameter model ini, seseorang mesti mempunyai kuasa pengkomputeran yang sangat besar, serta orang yang berkemahiran tinggi dan berpengalaman dalam sains data dan pasukan kejuruteraan data.
Oleh itu, hanya syarikat ini, dengan bantuan syarikat pemula yang diperoleh dan kerjasama dengan ahli akademik, boleh berjaya menggunakan model AI generatif.
Dari segi syarikat besar yang terlibat dalam syarikat permulaan, Microsoft boleh dilihat melabur $1 bilion dalam OpenAI dan membantu mereka membangunkan model yang serupa, Google memperoleh Deepmind pada tahun 2014.
Di pihak universiti, VisualGPT dibangunkan oleh Universiti Sains dan Teknologi King Abdullah (KAUST), Universiti Carnegie Mellon dan Universiti Teknologi Nanyang, dan model Resapan Gerakan Manusia dibangunkan oleh Universiti Tel Aviv di Israel.
Begitu juga, projek lain dibangunkan oleh syarikat dan universiti, seperti Stable Diffusion, dibangunkan oleh Runway, Stability AI, dan University of Munich, dibangunkan oleh Runway dan kerjasama DreamFusion A; antara Google dan Universiti California, Berkeley.
Model teks-ke-imej
DALL-E 2
DALL-E 2, dibangunkan oleh OpenAI, mampu menjana imej dan seni yang asli, realistik, Realistik, dan OpenAI telah menyediakan API untuk mengakses model.
Apa yang istimewa tentang DALL-E 2 ialah keupayaannya untuk menggabungkan konsep, atribut dan gaya yang berbeza Keupayaannya diperoleh daripada rangkaian neural model CLIP terlatih imej-bahasa, supaya ia boleh menggunakan bahasa semula jadi. untuk menunjukkan coretan Teks yang paling berkaitan.
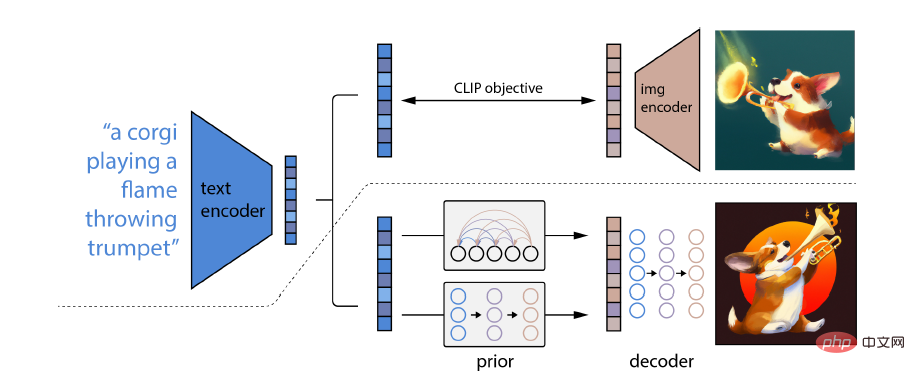
Secara khusus, pembenaman CLIP mempunyai beberapa sifat yang diingini: keupayaan untuk melakukan transformasi yang stabil pada pengedaran imej yang mempunyai keupayaan tangkapan sifar yang kuat dan dilaksanakan selepas keadaan penalaan halus; hasil terkini.
Untuk mendapatkan model penjanaan imej yang lengkap, modul penyahkod pembenaman imej CLIP digabungkan dengan model terdahulu untuk menjana pembenaman imej CLIP yang berkaitan daripada kapsyen teks yang diberikan

Model lain termasuk Imagen, Stable Diffusion, Muse
Text-to-3D model
Bagi sesetengah industri, hanya imej 2D boleh dijana dan automasi tidak dapat dilengkapkan , contohnya, dalam bidang permainan, model 3D perlu dihasilkan.
Dreamfusion
DreamFusion telah dibangunkan oleh Google Research dan menggunakan model resapan teks-ke-imej 2D terlatih untuk sintesis teks-ke-3D.
Dreamfusion menggantikan teknik CLIP dengan kehilangan yang diperoleh daripada penyulingan model resapan dua dimensi, iaitu model resapan boleh digunakan sebagai kerugian dalam masalah pengoptimuman berterusan am untuk menjana sampel.

Berbanding dengan kaedah lain, yang kebanyakannya sampel piksel, pensampelan dalam ruang parameter adalah jauh lebih sukar daripada pensampelan dalam ruang piksel DreamFusion menggunakan penjana boleh dibezakan, memfokuskan pada mencipta model 3D yang menjadikan imej dari sudut rawak.

Model lain seperti Magic3D dibangunkan oleh NVIDIA.
Model Imej-ke-Teks
Ia juga berguna untuk mendapatkan teks yang menerangkan imej, yang bersamaan dengan versi songsang penjanaan imej.
Flamingo
Model ini dibangunkan oleh Deepmind dan boleh dilakukan pada tugas bahasa visual terbuka dengan hanya beberapa gesaan daripada contoh input/output pembelajaran.
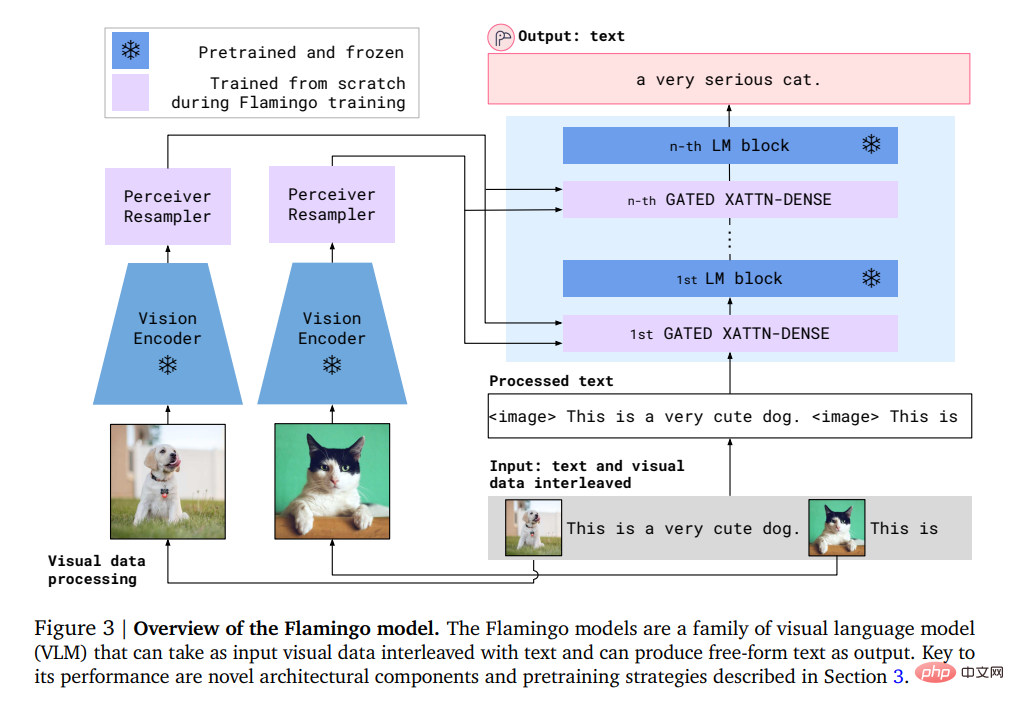
Secara khususnya, input Flamingo termasuk model penjanaan teks autoregresif di bawah keadaan visual, yang boleh menerima jujukan token teks yang dijalin dengan imej atau video dan menjana teks sebagai output .
Pengguna boleh memasukkan pertanyaan ke dalam model dan melampirkan foto atau video, dan model akan menjawabnya dengan jawapan teks.

Model Flamingo memanfaatkan dua model pelengkap: model visual yang menganalisis adegan visual dan model bahasa besar yang melaksanakan bentuk asas penaakulan.
VisualGPT
VisualGPT ialah model penerangan imej yang dibangunkan oleh OpenAI yang boleh memanfaatkan pengetahuan dalam model bahasa pra-latihan GPT-2.
Untuk merapatkan jurang semantik antara modaliti yang berbeza, penyelidik mereka bentuk mekanisme perhatian pengekod-penyahkod baharu dengan fungsi pembetulan gating.

Kelebihan terbesar VisualGPT ialah ia tidak memerlukan data sebanyak model imej-ke-teks yang lain Ia boleh meningkatkan kecekapan data model penerangan imej dan boleh digunakan dalam bidang khusus Atau huraikan objek yang jarang ditemui.
Model Teks-ke-Video
Phenaki
Model ini dibangunkan dan dihasilkan oleh Google Research dan boleh, diberikan satu siri gesaan teks, Lakukan sintesis video yang realistik.
Phenaki ialah model pertama yang mampu menjana video daripada isyarat pembolehubah masa domain terbuka.
Untuk menyelesaikan masalah data, penyelidik bersama-sama melatih set data pasangan teks imej yang besar dan bilangan contoh teks video yang lebih kecil, dan akhirnya mencapai keupayaan generalisasi di luar set data video.
Terutamanya set data teks imej cenderung mempunyai berbilion data input, manakala set data teks video jauh lebih kecil dan pengiraan video dengan panjang yang berbeza juga merupakan masalah yang sukar.

Model Phenaki mengandungi tiga bahagian: pengekod C-ViViT, Transformer latihan dan penjana video.
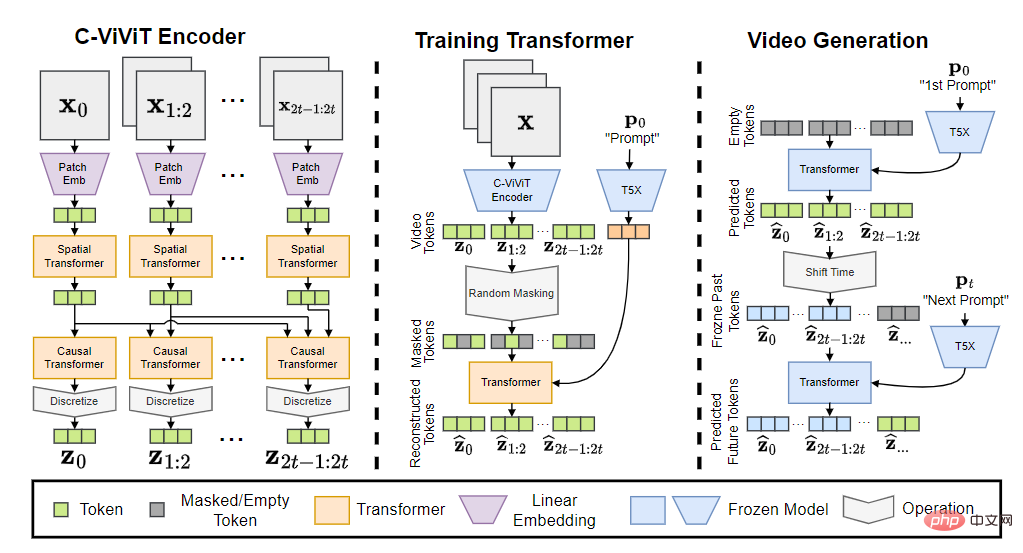
Selepas menukar token input kepada pembenaman, ia kemudiannya melalui Transformer temporal dan Transformer spatial, dan kemudian menggunakan unjuran linear tunggal tanpa pengaktifan untuk memetakan token kembali ke ruang piksel.
Model terakhir boleh menjana video dengan koheren temporal dan kepelbagaian yang dikondisikan pada isyarat domain terbuka, malah mampu mengendalikan beberapa konsep baharu yang tidak wujud dalam set data.
Model berkaitan termasuk Soundify.
Model Teks-ke-Audio
Untuk penjanaan video, bunyi juga merupakan bahagian yang sangat diperlukan.
AudioLM
Model ini dibangunkan oleh Google dan boleh digunakan untuk menjana audio berkualiti tinggi dengan konsistensi jarak jauh.
Apa yang istimewa tentang AudioLM ialah ia memetakan audio input ke dalam jujukan token diskret dan menggunakan penjanaan audio sebagai tugas pemodelan bahasa dalam ruang perwakilan ini.
Dengan melatih korpus besar bentuk gelombang audio mentah, AudioLM berjaya belajar untuk menjana pertuturan berterusan yang semula jadi dan koheren di bawah gesaan ringkas. Kaedah ini malah boleh diperluaskan kepada pertuturan selain daripada suara manusia, seperti muzik piano berterusan, dsb., tanpa menambah perwakilan simbolik semasa latihan.
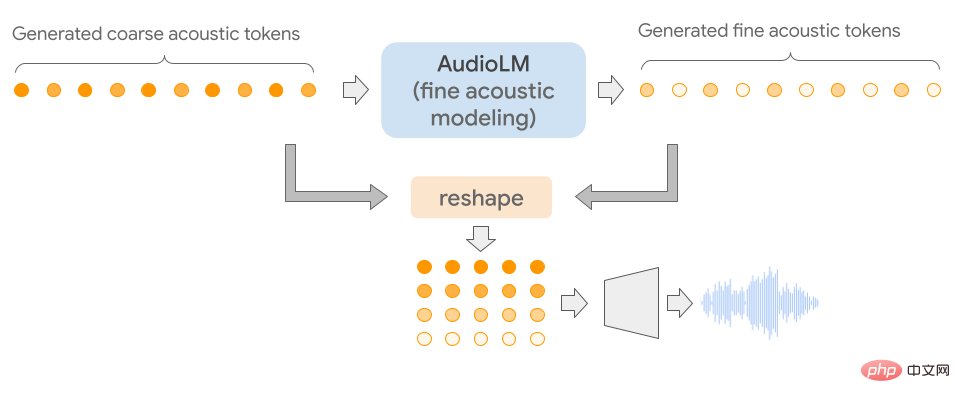
Memandangkan isyarat audio melibatkan abstraksi berbilang skala, adalah sangat mencabar untuk mencapai kualiti audio yang tinggi pada berbilang skala sambil menunjukkan konsistensi semasa sintesis audio. Model AudioLM dilaksanakan dengan menggabungkan kemajuan terkini dalam pemampatan audio saraf, pembelajaran perwakilan diselia sendiri dan pemodelan bahasa.
Untuk penilaian subjektif, penilai diminta untuk mendengar sampel 10 saat dan memutuskan sama ada ia adalah pertuturan manusia atau pertuturan yang disintesis. Berdasarkan 1000 penilaian yang dikumpul, kadarnya ialah 51.2%, yang tidak berbeza secara statistik daripada label yang diberikan secara rawak, iaitu manusia tidak dapat membezakan antara sampel sintetik dan sebenar.
Model lain yang berkaitan termasuk Jukebox dan Whisper
Model Teks-ke-Teks
Biasa digunakan dalam tugasan soal jawab.
ChatGPT
ChatGPT yang popular dibangunkan oleh OpenAI dan berinteraksi dengan pengguna dalam cara perbualan.
Pengguna bertanya soalan atau separuh pertama teks gesaan, dan model akan melengkapkan bahagian seterusnya, dan boleh mengenal pasti prasyarat input yang salah dan menolak permintaan yang tidak sesuai.
Secara khususnya, algoritma di sebalik ChatGPT ialah Transformer, dan proses latihan terutamanya pembelajaran pengukuhan berdasarkan maklum balas manusia.
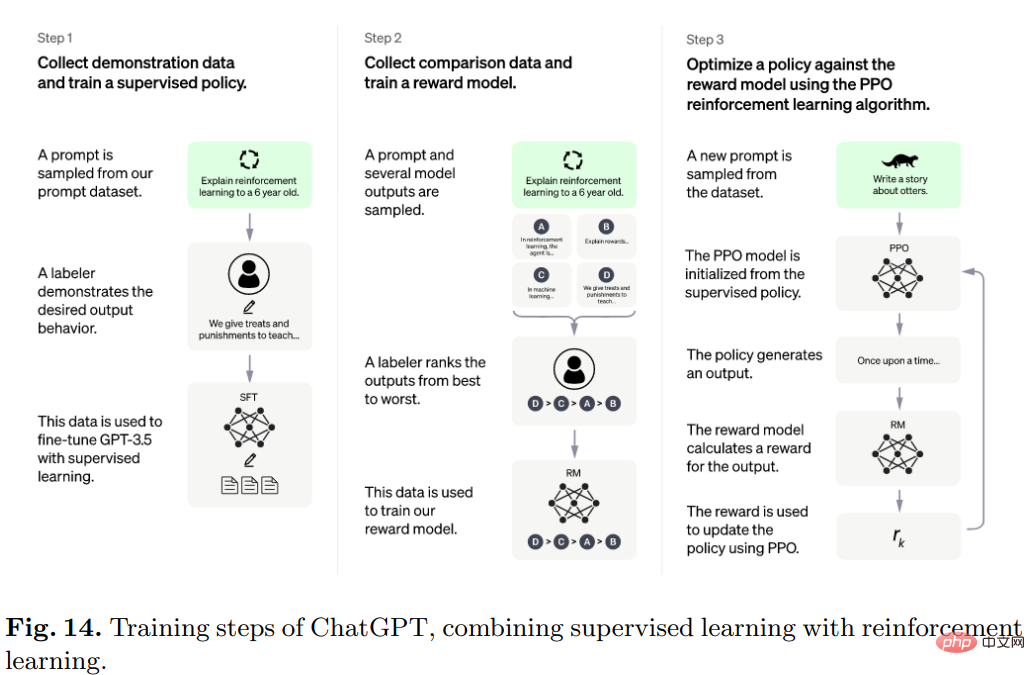
Model awal telah dilatih menggunakan penalaan halus di bawah pembelajaran diselia, dan kemudian manusia menyediakan perbualan di mana mereka bermain antara satu sama lain sebagai pengguna dan pembantu AI, dan kemudian Manusia membetulkan respons yang dikembalikan oleh model dan membantu model bertambah baik dengan jawapan yang betul.
Campurkan set data yang dibuat dengan set data InstructGPT dan tukarkannya kepada format perbualan.
Model lain yang berkaitan termasuk LaMDA dan PEER
Model Teks-ke-Kod
adalah serupa dengan teks-ke-teks, kecuali ia menghasilkan jenis teks khas, iaitu kod.
Codex
Model ini dibangunkan oleh OpenAI dan boleh menterjemah teks kepada kod.
Codex ialah model pengaturcaraan umum yang boleh digunakan pada asasnya sebarang tugas pengaturcaraan.
Aktiviti manusia apabila pengaturcaraan boleh dibahagikan kepada dua bahagian: 1) menguraikan masalah kepada masalah yang lebih mudah;
Bahagian kedua ialah bahagian yang paling banyak membuang masa untuk pengaturcara, dan ia juga merupakan yang terbaik bagi Codex.
Data latihan telah dikumpulkan daripada repositori perisian awam yang dihoskan di GitHub pada Mei 2020, mengandungi 179GB fail Python dan diperhalusi berdasarkan GPT-3 , yang sudah mengandungi perwakilan bahasa semula jadi yang kuat.
Model berkaitan juga termasuk Alphacode
Model Teks-ke-Sains
Teks penyelidikan saintifik juga merupakan salah satu matlamat penjanaan teks AI, tetapi masih jauh lagi. untuk mencapai keputusan.
Galactica
Model ini dibangunkan bersama oleh Meta AI dan Papers with Code dan boleh digunakan untuk menyusun model teks saintifik berskala besar secara automatik.
Kelebihan utama Galactica ialah walaupun selepas latihan untuk berbilang episod, model itu masih tidak akan dipasang terlalu banyak, dan prestasi huluan dan hiliran akan bertambah baik dengan penggunaan berulang token.
Dan reka bentuk set data adalah penting untuk pendekatan ini, kerana semua data diproses dalam format penurunan nilai biasa, membolehkan pencampuran pengetahuan daripada sumber yang berbeza.
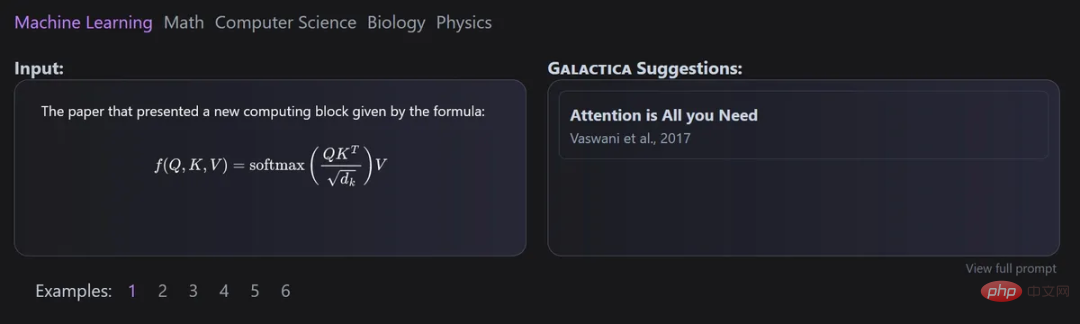
Petikan diproses melalui token tertentu, membolehkan penyelidik meramalkan petikan dalam sebarang konteks input. Keupayaan model Galactica untuk meramalkan petikan meningkat mengikut skala.
Selain itu, model ini menggunakan seni bina Transformer dalam tetapan penyahkod sahaja dengan pengaktifan GeLU untuk semua saiz model, membolehkan untuk melaksanakan tugas berbilang modal yang melibatkan formula kimia SMILES dan jujukan protein,
Minerva
Tujuan utama Minerva adalah untuk menyelesaikan masalah matematik dan saintifik Untuk tujuan ini, ia telah mengumpul sejumlah besar data latihan dan menyelesaikan masalah penaakulan kuantitatif dan berskala besar. model. Untuk membangunkan soalan, teknik penaakulan terkini juga digunakan.
Seni bina model bahasa pensampelan Minerva menyelesaikan masalah input dengan menggunakan penaakulan langkah demi langkah, iaitu input perlu mengandungi pengiraan dan operasi simbolik tanpa memperkenalkan alat luaran.
Model Lain
Terdapat juga beberapa model yang tidak termasuk dalam kategori yang dinyatakan sebelum ini.
AlphaTensor
Dibangunkan oleh Deepmind, ia merupakan model revolusioner sepenuhnya dalam industri kerana keupayaannya untuk menemui algoritma baharu.
Dalam contoh yang diterbitkan, AlphaTensor mencipta algoritma pendaraban matriks yang lebih cekap. Algoritma ini sangat penting sehingga segala-galanya daripada rangkaian saraf kepada program pengkomputeran saintifik boleh mendapat manfaat daripada pengiraan pendaraban yang cekap ini.
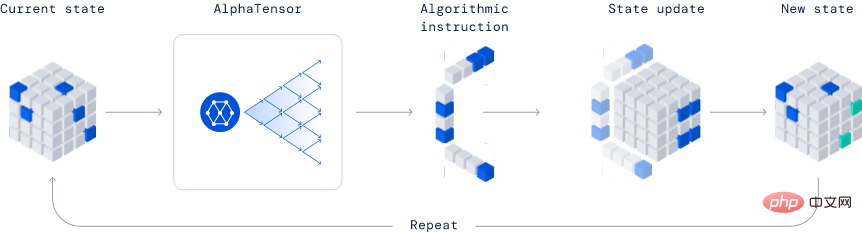
Kaedah ini berdasarkan kaedah pembelajaran pengukuhan mendalam, di mana proses latihan ejen AlphaTensor adalah untuk bermain permainan pemain tunggal, dan matlamatnya adalah untuk mencari penguraian tensor dalam ruang faktor terhad.
Pada setiap langkah TensorGame, pemain perlu memilih cara menggabungkan entri yang berbeza bagi matriks untuk pendaraban, dan memperoleh mata bonus berdasarkan bilangan operasi yang diperlukan untuk mencapai hasil pendaraban yang betul. AlphaTensor menggunakan seni bina rangkaian neural khas untuk mengeksploitasi simetri permainan latihan sintetik.
GATO
Model ini ialah ejen umum yang dibangunkan oleh Deepmind Ia boleh digunakan sebagai strategi generalisasi berbilang modal, berbilang tugas atau berbilang penjelmaan.
Rangkaian yang sama dengan berat yang sama boleh mengehoskan keupayaan yang sangat berbeza, daripada bermain permainan Atari, menerangkan gambar, berbual, menyusun blok dan banyak lagi.
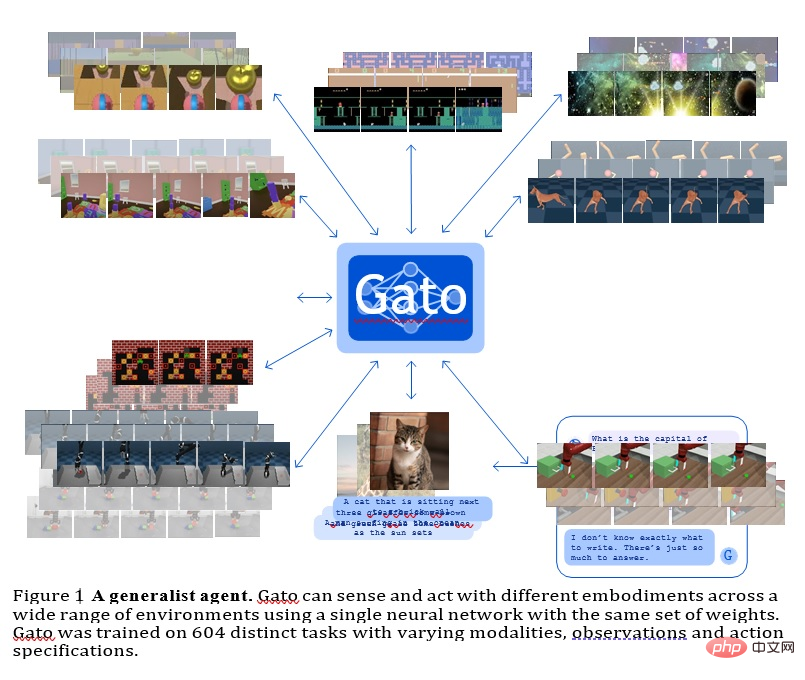
Menggunakan model jujukan saraf tunggal merentas semua tugasan mempunyai banyak faedah, mengurangkan keperluan untuk membuat model dasar dengan berat sebelah induktifnya sendiri dan meningkatkan jumlah data latihan dan Kepelbagaian.
Ejen tujuan am ini berjaya dalam sejumlah besar tugas dan boleh ditala dengan sedikit data tambahan untuk berjaya dalam lebih banyak tugas.
Pada masa ini GATO mempunyai kira-kira 1.2B parameter, yang boleh mengawal skala model robot dunia sebenar dalam masa nyata.
Model kecerdasan buatan generatif lain yang diterbitkan termasuk menjana gerakan manusia, dsb.
Rujukan: https://arxiv.org/abs/2301.04655
Atas ialah kandungan terperinci Baca semua model generatif SOTA dalam satu artikel: ulasan lengkap 21 model dalam sembilan kategori!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI