
Rumah >Peranti teknologi >AI >Daripada ODS kepada ADS, penjelasan terperinci tentang stratifikasi gudang data!
Daripada ODS kepada ADS, penjelasan terperinci tentang stratifikasi gudang data!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-30 20:22:042256semak imbas
1. Mengapakah kita perlu melapiskan gudang data
Hanya apabila model data mengatur dan menyimpan data dengan cara yang teratur boleh data besar mencapai tahap tinggi prestasi, kos rendah, kecekapan tinggi dan penggunaan berkualiti tinggi.
01 Makna hierarki
1) Struktur data yang jelas: Setiap titik data Setiap lapisan mempunyai skopnya, supaya kita boleh mencari dan memahaminya dengan lebih mudah apabila menggunakan jadual.
Hubungan data yang teratur: Terdapat hubungan data yang kompleks antara sistem sumber Contohnya, maklumat pelanggan wujud dalam sistem teras, sistem kredit, sistem pengurusan kewangan dan sistem modal pada masa yang sama Bagaimana kita harus membuat keputusan apabila mengambil nombor? Gudang data akan menjalankan pemodelan bersatu data pada tema yang sama dan menyusun perhubungan data yang kompleks ke dalam model data yang jelas, yang boleh mengelakkan masalah di atas apabila digunakan.
2) Penjejakan keturunan data: Ringkasnya, kita boleh memahaminya dengan cara ini akhirnya memberikan integriti perniagaan adalah Terdapat hanya satu jadual perniagaan yang boleh digunakan secara langsung, tetapi ia datang dari banyak sumber Jika terdapat masalah dengan salah satu jadual sumber, kami berharap dapat mengesan masalah dengan cepat dan tepat dan memahami. skop kemudaratannya.
3) Penggunaan semula data untuk mengurangkan pembangunan berulang: Piawaikan lapisan data dan bangunkan beberapa perantaraan biasa Data lapisan boleh mengurangkan banyak pengiraan berulang. Berdasarkan prinsip pemprosesan lapisan demi lapisan data, lapisan bawah mengandungi semua data yang diperlukan untuk pemprosesan data lapisan atas Kaedah pemprosesan ini mengelakkan setiap pembangun data daripada mengekstrak semula data daripada sistem sumber untuk pemprosesan. Melalui pengenalan lapisan ringkasan, pengiraan berulang bagi logik pengguna hiliran dielakkan, menjimatkan masa dan tenaga pembangunan pengguna, dan juga menjimatkan pengiraan dan penyimpanan. Ia sangat mengurangkan lebihan data yang tidak perlu, membolehkan penggunaan semula hasil pengiraan, dan mengurangkan kos penyimpanan dan pengkomputeran.
4) Permudahkan masalah yang kompleks. Uraikan tugas yang kompleks kepada beberapa langkah untuk diselesaikan Setiap lapisan hanya mengendalikan satu langkah, yang agak mudah dan mudah difahami. Ia juga mudah untuk mengekalkan ketepatan data Apabila terdapat masalah dengan data, anda tidak perlu membaiki semua data Anda hanya perlu mula membaikinya dari langkah yang bermasalah.
5) Lindungi (pengaruh) data asal dan lindungi kesan ke atas perniagaan. Apabila perniagaan atau sistem berubah, tidak perlu menukar perniagaan sekali sebelum mengakses semula data. Meningkatkan kestabilan dan kesinambungan data.
Lindungi kerumitan sistem perniagaan sumber: sistem sumber mungkin sangat kompleks, dan penamaan jadual, penamaan medan, makna medan, dll. mungkin pelbagai dan diseragamkan melalui lapisan DW Dan melindungi semua kerumitan ini untuk memastikan kemudahan dan penyeragaman penggunaan data oleh pengguna data hiliran. Jika perniagaan sistem sumber berubah, perubahan yang berkaitan akan diproses oleh lapisan DW, yang telus kepada pengguna hiliran tanpa mengubah kod dan logik pengguna hiliran.
Kebolehselenggaraan gudang data: Reka bentuk berlapis membenarkan masalah pada lapisan tertentu diselesaikan hanya pada lapisan itu, tanpa mengubah kod dan kod seterusnya lapisan logik.
Sistem data besar memerlukan pendekatan model data untuk membantu mengatur dan menyimpan data dengan lebih baik untuk mencapai keseimbangan terbaik antara prestasi, kos, kecekapan dan kualiti!
02 Empat operasi gudang data (ETL)
ETL (pemuatan transformasi pengekstrakan) bertanggungjawab untuk mengubah sumber data teragih dan heterogen Selepas data diekstrak ke lapisan tengah sementara, ia dibersihkan, diubah, disepadukan, dan akhirnya dimuatkan ke dalam gudang data atau data mart. ETL ialah teras dan jiwa melaksanakan gudang data Reka bentuk dan pelaksanaan peraturan ETL menyumbang kira-kira 60% hingga 80% daripada keseluruhan beban kerja pembinaan gudang data.
1) Pengekstrakan data Termasuk pemuatan data awal dan penyegaran data: pemuatan data awal tertumpu terutamanya pada cara mewujudkan jadual dimensi dan jadual fakta, dan meletakkan data yang sepadan ke dalam jadual data ini memfokuskan pada cara menambahkan dan mengemas kini data yang sepadan dalam gudang data apabila data sumber berubah (contohnya, anda boleh membuat tugas berjadual atau mencetuskan borang untuk muat semula data biasa).
2) Pembersihan data terutamanya bertujuan untuk kekaburan, pertindihan dan ketidaklengkapan yang muncul dalam pangkalan data sumber , data yang melanggar peraturan perniagaan atau logik dan isu lain diproses secara seragam. Iaitu, membersihkan data yang tidak selaras dengan perniagaan atau tidak berguna. Contohnya, anda boleh menulis hive atau MR untuk membersihkan data yang panjangnya tidak memenuhi keperluan.
3) Transformasi data (transformasi) Terutamanya untuk menukar data yang dibersihkan menjadi gudang data Data yang diperlukan: Kamus data atau format data medan data yang sama daripada sistem sumber yang berbeza mungkin berbeza (contohnya, ia dipanggil id dalam jadual A dan id dalam jadual B perlu disediakan untuk mereka dalam gudang data). . dan format, untuk menormalkan kandungan data sebaliknya, kandungan beberapa medan yang diperlukan oleh gudang data mungkin tidak tersedia dalam sistem sumber, tetapi perlu ditentukan berdasarkan kandungan berbilang medan dalam sistem sumber .
4) Pemuatan data adalah untuk mengimport data terakhir yang diproses ke dalam ruang storan yang sepadan (hbase, mysql , dsb.) untuk memudahkan penyediaan data kepada data mart untuk visualisasi.
Secara amnya syarikat besar mempunyai platform data terkapsul dan platform penjadualan tugas mereka sendiri untuk keselamatan data dan kemudahan operasi . Spark cluster, sqoop, hive, zookeeper, hbase, dsb. hanya menyediakan antara muka web dan memberikan kebenaran yang berbeza kepada pekerja yang berbeza, dan kemudian melakukan operasi dan panggilan yang berbeza pada gugusan. Mengambil gudang data sebagai contoh, gudang data dibahagikan kepada beberapa peringkat logik. Dengan cara ini, untuk tahap operasi data yang berbeza, tahap tugasan yang berbeza boleh dibuat dan dilaksanakan dalam tahap aliran tugas yang berbeza (sekelompok dalam syarikat besar biasanya mempunyai beribu-ribu, malah berpuluh-puluh ribu, tugasan berjadual yang menunggu untuk dilaksanakan setiap hari, jadi bahagian adalah berbeza aliran tugas hierarki, tugas pada tahap yang berbeza dilaksanakan dalam aliran tugas yang sepadan, yang akan menjadikan pengurusan dan penyelenggaraan lebih mudah).
03 Salah faham tentang layering
Pembahagian dalaman lapisan data warehouse bukan layering untuk kepentingan layering, layering adalah untuk menyelesaikan ETL tugasan Dan pelbagai isu seperti organisasi aliran kerja, aliran data, kawalan kebenaran membaca dan menulis, dan kepuasan keperluan yang berbeza.
Amalan biasa dalam industri ialah membahagikan keseluruhan lapisan gudang data kepada banyak lapisan seperti DWD, DWT, DWS, DIM, DM, dsb. Walau bagaimanapun, kami tidak pernah dapat memberitahu apa sempadan yang jelas antara lapisan ini, atau kami boleh menerangkan dengan jelas sempadan di antara mereka Namun, senario perniagaan yang kompleks menghalang kami daripada melaksanakannya.
Secara umumnya, tiga lapisan adalah yang paling asas untuk stratifikasi data Bagi cara membahagikan lapisan DW, ia adalah berdasarkan keperluan perniagaan tertentu dan syarikat Tentukan sendiri tempat kejadian.
2. Seni bina teknikal gudang data
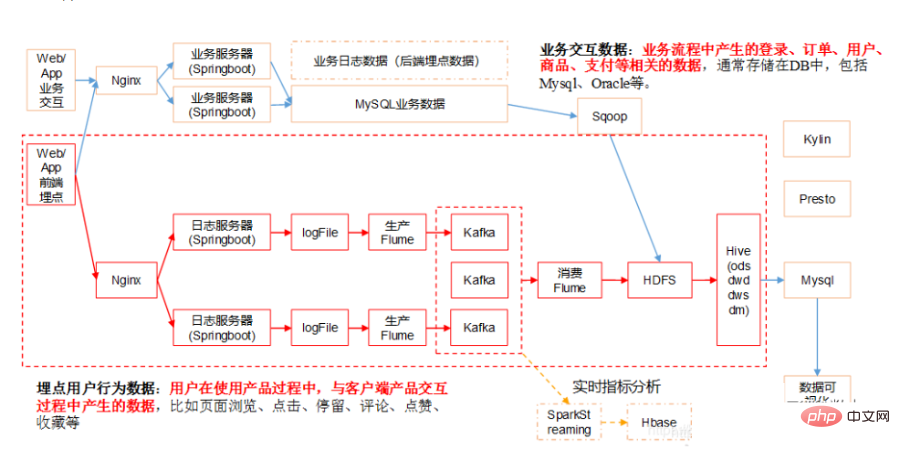
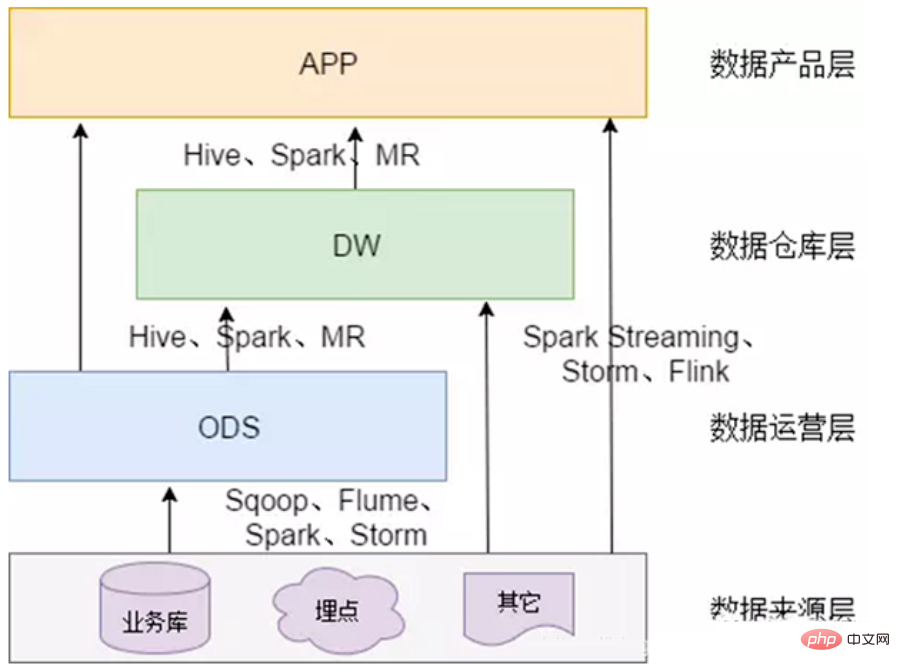
Pusat data mengandungi banyak kandungan jika ia sepadan dengan kerja tertentu, ia boleh termasuk kandungan berikut:
- Seni bina sistem: Sistem seni bina berpusat pada Hadoop, Spark dan komponen lain
- Data seni bina: Reka bentuk peringkat atas, pembahagian kawasan subjek, reka bentuk hierarki, ODS-DW-ADS
- Pemodelan data: Pemodelan dimensi, proses perniagaan - tentukan kebutiran - dimensi - jadual fakta
- Pengurusan data: Pengurusan aset, pengurusan metadata , pengurusan kualiti , pengurusan data induk, piawaian data, pengurusan keselamatan data
- Sistem tambahan: Sistem penjadualan, sistem ETL, sistem pemantauan
- Perkhidmatan data: Portal data, perlombongan data pembelajaran mesin, pertanyaan data, analisis, sistem laporan, sistem visualisasi, muat turun perkongsian pertukaran data
3. Seni bina berlapis gudang data
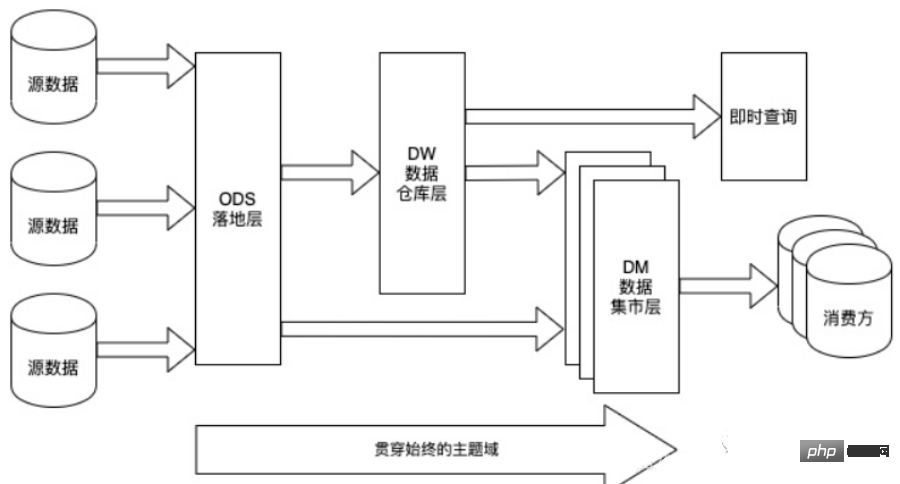
Piawaian gudang data boleh dibahagikan kepada empat lapisan. Walau bagaimanapun, sila ambil perhatian bahawa bahagian dan penamaan ini tidak unik Secara amnya, gudang data mempunyai empat peringkat, tetapi syarikat yang berbeza mungkin mempunyai nama yang berbeza. Tetapi konsep teras semuanya datang daripada model data empat lapisan.


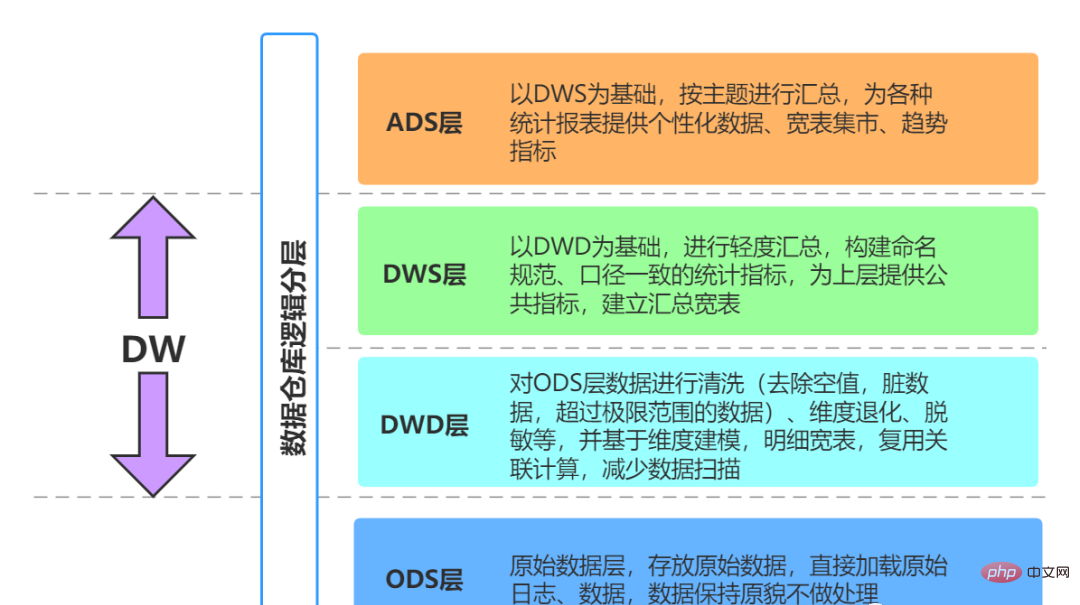
01 Tampal lapisan sumber (ODS, Operasi Stor Data)
Lapisan pengenalan data (ODS, Stor Data Operasi, juga dikenali sebagai lapisan pangkalan data): Data asal diproses dengan hampir tiada pemprosesan Ia disimpan dalam sistem gudang data dan pada asasnya konsisten dalam struktur dengan sistem sumber Ia adalah kawasan penyediaan data gudang data. Tanggungjawab utama lapisan ini adalah untuk menyegerakkan dan menyimpan data asas.
Secara umumnya, data lapisan ODS dan data sistem sumber adalah isomorfik, dan tujuan utamanya adalah untuk memudahkan pemprosesan data seterusnya. Dari segi kebutiran data, kebutiran data lapisan ODS adalah baik. Jadual dalam lapisan ODS biasanya termasuk dua jenis, satu digunakan untuk menyimpan data semasa yang perlu dimuatkan dan satu digunakan untuk menyimpan data sejarah selepas pemprosesan. Data sejarah biasanya disimpan selama 3-6 bulan dan kemudian perlu dikosongkan untuk menjimatkan ruang. Walau bagaimanapun, projek yang berbeza harus dilayan secara berbeza Jika jumlah data dalam sistem sumber tidak besar, ia boleh disimpan untuk jangka masa yang lebih lama atau disimpan sepenuhnya.
Nota: Pada lapisan ini, ia bukan akses data yang mudah, tetapi harus mempertimbangkan pembersihan data tertentu, seperti pemprosesan medan tidak normal dan penyeragaman medan penamaan , penyatuan medan masa, dsb. Secara umumnya ini mudah diabaikan, tetapi ia adalah penting. Ia akan sangat berguna terutamanya apabila kita melakukan penjanaan automatik pelbagai ciri kemudian.
Nota: Lapisan ODS sesetengah syarikat tidak akan melakukan terlalu banyak penapisan data dan akan diletakkan dalam lapisan DWD untuk diproses. Sesetengah syarikat akan melakukan penapisan data yang agak halus pada lapisan ODS dari awal Ini tidak ditakrifkan dengan jelas dan bergantung pada idea dan spesifikasi teknikal setiap syarikat.
Pembangunan perusahaan am akan melakukan beberapa pemprosesan asas apabila data asal disimpan dalam ODS.
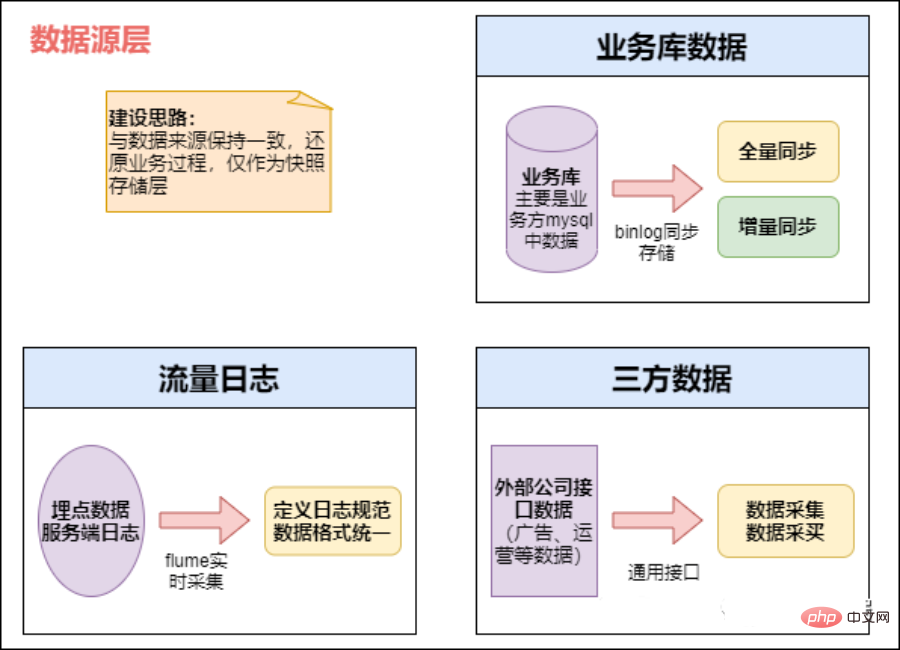
Pembezaan sumber data
Data disimpan dalam partition berdasarkan masa, biasanya mengikut hari. Terdapat juga syarikat yang menggunakan partition tiga peringkat tahun, bulan dan hari untuk penyimpanan.
Lakukan pemprosesan data paling asas, seperti membuang ralat format, menapis maklumat utama yang hilang, dsb.
Data masa nyata di luar talian
- Aspek luar talian: tugas berjadual harian: menjalankan tugas kelompok, perpustakaan perniagaan, seperti tugas pengkomputeran harian biasa kami, di mana Sqoop sering digunakan untuk mengekstrak, contohnya, kami mengekstrak sekali sehari . Kira data hari sebelumnya setiap awal pagi, dan baca laporan pada waktu pagi. Tugasan seperti ini sering dikira menggunakan Hive dan Spark, dan hasil akhir ditulis ke Hive, Hbase, Mysql, Es atau Redis.
- Data masa nyata: data log atau pangkalan data perniagaan Bahagian ini digunakan terutamanya oleh pelbagai sistem masa nyata, seperti pengesyoran masa nyata dan sebenar kami -potret pengguna masa Secara amnya, kami akan menggunakan Spark Streaming dan Flink untuk pengiraan, dan akhirnya jatuh ke dalam Es, Hbase atau Redis. Sumber data ialah pangkalan data perniagaan Anda boleh mempertimbangkan untuk menggunakan Canal untuk memantau Binlog Mysql dan mengaksesnya dalam masa nyata Kemudian ia juga dikumpulkan ke dalam baris gilir mesej, dan akhirnya ditarik ke HDFS oleh Camus.
1) Sumber utama data:
- Data sumber Ia adalah pangkalan data perniagaan Data yang dijana oleh semua sistem syarikat
- dilaporkan dengan menguburkan mata pada klien, mengumpul log tingkah laku pengguna dan beberapa kembali. -log tamat sumber data jenis log. Untuk log tingkah laku terkubur, ia biasanya melalui proses seperti ini Pertama, data dilaporkan kepada Nginx dan kemudian dikumpulkan oleh Flume Kemudian ia disimpan dalam baris gilir mesej seperti Kafka, dan kemudiannya ditarik oleh beberapa masa nyata atau tugas menarik luar talian Dapatkan HDFS gudang data luar talian kami
- data luaran (termasuk data koperasi dan data yang diperolehi oleh perangkak), dan ringkaskan data yang dikumpul bersama
2) Strategi penyimpanan data (bertambah, penuh)
Dalam aplikasi sebenar , anda boleh memilih untuk menggunakan tambahan, storan penuh atau storan zip.
- Storan tambahan
Untuk memenuhi data sejarah analisis Jika perlu, anda boleh menambah dimensi masa sebagai medan partition dalam jadual lapisan ODS. Storan tambahan dalam beberapa hari, dengan tarikh perniagaan sebagai partition, dan setiap partition menyimpan data perniagaan tambahan harian.
Contohnya:
Pada 1 Januari, pengguna A melawat Syarikat A E- kedai perdagangan B dan log e-dagang syarikat A menjana rekod t1 Pada 2 Januari, pengguna A melawat kedai e-dagang C syarikat A sekali lagi, dan log e-dagang syarikat A menjana rekod t2.
Menggunakan kaedah storan tambahan, t1 akan disimpan dalam partition pada 1 Januari dan t2 akan disimpan dalam partition pada 2 Januari.
Pada 1 Januari, pengguna A membeli produk B di tapak web e-dagang syarikat A, dan log transaksi akan menghasilkan rekod t1 pada 2 Januari, pengguna A mengembalikan produk B sekali lagi, dan log transaksi akan mengemas kini rekod t1.
Menggunakan kaedah storan tambahan, rekod t1 awal yang dibeli akan disimpan dalam partition pada 1 Januari, dan t1 yang dikemas kini akan disimpan dalam partition pada 2 Januari dalam partition ini.
Jadual ODS dengan sifat transaksi yang kukuh seperti transaksi dan log sesuai untuk storan tambahan. Jadual jenis ini mempunyai jumlah data yang besar, dan kos penyimpanan menggunakan storan penuh adalah tinggi. Di samping itu, aplikasi hiliran jadual sedemikian mempunyai kurang permintaan untuk akses data sejarah penuh (permintaan sedemikian boleh diperolehi melalui pengagregatan berikutnya oleh gudang data). Sebagai contoh, jadual ODS log tidak mempunyai proses perniagaan kemas kini data, jadi semua partition tambahan UNION bersama-sama untuk membentuk satu set lengkap data.
- Storan penuh
Storan penuh dalam beberapa hari Penggunaan Storan tarikh perniagaan sebagai partition, dan setiap partition menyimpan jumlah penuh data perniagaan sehingga tarikh perniagaan.
Sebagai contoh, pada 1 Januari, penjual A mengeluarkan dua produk, B dan C, di tapak web e-dagang syarikat A hasilkan dua rekod t1, t2 Pada 2 Januari, penjual A mengeluarkan produk B dari rak dan mengeluarkan produk D pada masa yang sama Jadual produk bahagian hadapan akan mengemas kini rekod t3. Menggunakan kaedah storan penuh, dua rekod t1 dan t2 disimpan dalam partition pada 1 Januari, dan rekod t1, t2 dan t3 yang dikemas kini disimpan dalam partition pada 2 Januari.
Untuk menukar data dimensi secara perlahan dengan jumlah data yang kecil, seperti kategori produk, storan penuh boleh digunakan secara langsung.
- Storan Zip
Storan Zip dengan menambah dua A medan cap waktu (start_dt dan end_dt) digunakan untuk merekod semua data perubahan dengan butiran harian Biasanya medan partition juga adalah dua medan cap masa ini.
Skim
Konsep: juga dipanggil lapisan antara muka (peringkat), digunakan untuk Kedai data tambahan harian dan data berubah
Kaedah penjanaan data: terima terus data sumber daripada kafka, yang memerlukan jadual perniagaan untuk menjana kemas kini, memadam dan memasukkan data setiap hari . Hanya jadual perniagaan untuk memasukkan data dijana dan data dimasukkan terus ke dalam lapisan butiran.
Pelan perbincangan: Hanya letakkan log terusan terus ke dalam lapisan penimbal Jika terdapat perniagaan lain dengan data berzip, masukkan juga ke dalam lapisan penimbal.
Kaedah penyimpanan log: menggunakan penampilan impala dan format fail parket untuk memudahkan pembacaan data yang memerlukan pemprosesan MR.
Kaedah pemadaman log: storan jangka panjang, hanya data beberapa hari terakhir boleh disimpan. Pelan perbincangan: penyimpanan jangka panjang langsung.
Skema jadual: Pembahagian biasanya dibuat mengikut hari, dan pembahagian oleh biasanya disimpan mengikut hari.
Perpustakaan dan penamaan jadual. Nama perpustakaan: ods, nama jadual: Format pertimbangan awal ialah nama jadual perniagaan tarikh ods, yang akan ditentukan.
Jadual luar Hive sepadan dengan jadual perniagaan.
jadual luar sarang, fail yang menyimpan data mungkin tidak berada di lokasi lalai hdfs sarang, dan apabila jadual sarang yang sepadan dipadamkan, fail data yang sepadan is not akan dipadamkan dengan cara ini, untuk pembangunan perusahaan, ia boleh menghalang data berharga daripada dipadamkan daripada jadual perniagaan sarang disebabkan oleh operasi pemadaman jadual Sebaliknya, fail data disimpan di lokasi lalai yang sepadan dengan sarang. Apabila jadual dipadamkan, fail yang sepadan juga akan dipadamkan.
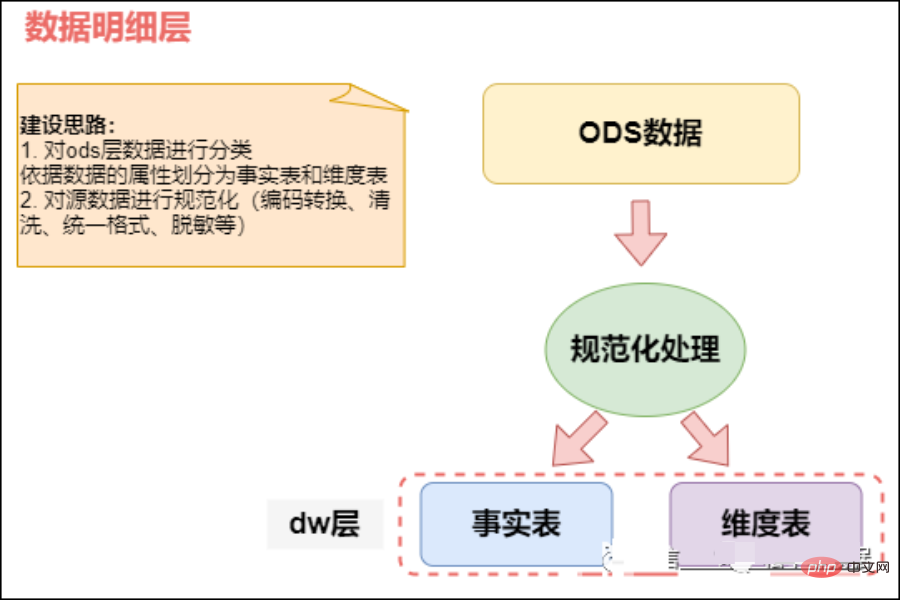
02 Lapisan gudang data (DW, gudang data)
Lapisan gudang data (DW): gudang data Lapisan adalah lapisan reka bentuk teras apabila kita membina gudang data Lapisan ini akan membina pelbagai model data mengikut tema berdasarkan data yang diperoleh daripada lapisan ODS Setiap tema sepadan dengan kawasan analisis makro membuat keputusan data, memberikan pandangan ringkas tentang topik tertentu. Semua data sejarah dalam sistem BI akan disimpan pada lapisan DW, seperti data 10 tahun.
DW menyimpan data fakta terperinci, data jadual dimensi dan data ringkasan penunjuk awam. Antaranya, data fakta terperinci dan data jadual dimensi secara amnya dijana berdasarkan pemprosesan data lapisan ODS. Data ringkasan penunjuk awam biasanya dijana berdasarkan data jadual dimensi dan data fakta terperinci.
Lapisan DW dibahagikan lagi kepada lapisan dimensi (DIM), lapisan data terperinci (DWD) dan lapisan data ringkasan (DWS), menggunakan kaedah model dimensi sebagai teori Pada asasnya, anda boleh menentukan hubungan antara kunci utama model dimensi dan kunci asing dalam model fakta, mengurangkan lebihan data dan meningkatkan kebolehgunaan jadual data terperinci. Dalam lapisan data ringkasan, dimensi dalam butiran statistik yang digunakan semula juga boleh dikaitkan, dan kaedah jadual yang lebih luas boleh digunakan untuk membina lapisan data penunjuk awam untuk meningkatkan kebolehgunaan semula penunjuk awam dan mengurangkan pemprosesan berulang.
Lapisan dimensi (DIM, Dimensi): Menggunakan dimensi sebagai pemacu pemodelan, berdasarkan makna perniagaan setiap dimensi, ia ditakrifkan dengan menambahkan atribut dimensi, dimensi yang berkaitan, dll. Kira logik, lengkapkan proses definisi atribut dan wujudkan jadual dimensi analisis data yang konsisten. Untuk mengelakkan atribut dimensi yang dikaitkan secara berlebihan dalam model dimensi, jadual dimensi dibina berdasarkan model kepingan salji.
Lapisan data terperinci (DWD, Data Warehouse Detail): Mengambil proses perniagaan sebagai pemacu pemodelan, berdasarkan ciri-ciri setiap proses perniagaan tertentu, butiran terbaik dibina jadual fakta terperinci. Beberapa medan atribut penting boleh dibuat berlebihan dengan sewajarnya, iaitu pemprosesan jadual lebar.
Lapisan data ringkasan (DWS, Ringkasan Gudang Data): Menggunakan objek subjek yang dianalisis sebagai pemacu pemodelan, berdasarkan keperluan penunjuk aplikasi dan produk lapisan atas, jadual penunjuk ringkasan berbutir awam dibina. Gunakan kaedah jadual lebar untuk menfizikalkan model, bina penunjuk statistik dengan piawaian penamaan dan kaliber yang konsisten, sediakan penunjuk awam untuk lapisan atas, dan wujudkan jadual lebar ringkasan dan jadual fakta terperinci.
Domain tema: Berorientasikan proses perniagaan, koleksi abstrak acara aktiviti perniagaan, seperti penempatan pesanan, pembayaran dan bayaran balik ialah semua proses perniagaan. Pembahagian tema untuk tahap perincian biasa (DWD).
Domain data: Untuk analisis perniagaan, ia merupakan koleksi abstrak proses atau dimensi perniagaan. Pembahagian domain data untuk lapisan ringkasan biasa (DWS).
Lapisan DWD didorong oleh proses perniagaan.
Lapisan DWS, lapisan DWT dan lapisan ADS adalah didorong oleh permintaan.
DWD: lapisan perincian data butiran gudang data. Terutamanya melakukan beberapa operasi pembersihan dan penyeragaman data pada lapisan data ODS.
Pembersihan data: alih keluar nilai nol, data kotor, penukaran nilai penghitungan dan nilai yang melebihi julat had.
DWB: lapisan pangkalan data pangkalan data gudang, yang menyimpan data objektif Ia biasanya digunakan sebagai lapisan perantaraan dan boleh dianggap sebagai lapisan data untuk a sejumlah besar penunjuk.
DWS: lapisan perkhidmatan data perkhidmatan gudang data, berdasarkan data asas pada DWB, disepadukan dan diringkaskan ke dalam lapisan data perkhidmatan yang menganalisis kawasan subjek tertentu, biasanya permukaan yang luas. Digunakan untuk menyediakan pertanyaan perniagaan seterusnya, analisis OLAP, pengedaran data, dsb.
Tingkah laku pengguna, pengagregatan ringan
Terutama untuk Do beberapa ringkasan ringan data lapisan ODS/DWD.
1) Lapisan dimensi awam (DIM, Dimensi)
DIM: This The lapisan agak mudah Sebagai contoh, anda boleh memahami bahawa maklumat seperti kod negara dan nama negara, lokasi geografi, nama Cina dan gambar bendera disimpan dalam lapisan DIM.
Berdasarkan konsep pemodelan dimensi, wujudkan dimensi yang konsisten merentas keseluruhan perusahaan. Kurangkan risiko kaliber dan algoritma pengiraan data yang tidak konsisten.
Lapisan ringkasan dimensi awam (DIM) terutamanya terdiri daripada jadual dimensi (jadual dimensi). Dimensi ialah konsep logik, satu perspektif untuk mengukur dan memerhati perniagaan. Jadual dimensi ialah jadual yang menfizikalkan jadual yang dibina pada platform data berdasarkan dimensi dan atributnya, dan mengguna pakai prinsip reka bentuk jadual lebar. Oleh itu, membina lapisan ringkasan dimensi biasa (DIM) terlebih dahulu memerlukan penentuan dimensi.
Data dimensi kardinaliti tinggi: secara amnya jadual data serupa dengan jadual data pengguna dan jadual data produk. Jumlah data mungkin berpuluh juta atau ratusan juta.
Data dimensi kardinaliti rendah: biasanya jadual konfigurasi, seperti makna Cina yang sepadan dengan nilai penghitungan atau jadual dimensi tarikh. Jumlah data mungkin satu digit atau puluhan ribu.
Reka bentuk jadual dimensi:
Selepas melengkapkan definisi dimensi, anda boleh Menambahnya dan menjana jadual dimensi. Reka bentuk jadual dimensi memerlukan perhatian:
Adalah disyorkan bahawa maklumat jadual dimensi tidak boleh melebihi 10 juta keping.
Apabila menyertai jadual dimensi dengan jadual lain, anda disyorkan agar menggunakan Map Join
Elakkan mengemas kini data jadual dimensi terlalu kerap. Perlahan menukar dimensi: meja zip
Spesifikasi jadual dimensi Common Dimension Summary Layer (DIM)
Spesifikasi penamaan jadual dimensi Lapisan Ringkasan Dimensi Awam (DIM): dim_{Nama segmen perniagaan/pub}_{Definisi dimensi}[_{Label penamaan tersuai}], pub yang dipanggil berkaitan dengan segmen perniagaan khusus Dimensi yang tidak relevan atau biasa kepada semua sektor perniagaan, seperti dimensi masa.
Contohnya: jadual dimensi kawasan awam dim_pub_area jadual dimensi produk dim_asale_itm
Tahap butiran perniagaan yang dinyatakan oleh rekod dalam jadual fakta dipanggil butiran. Secara umumnya, kebutiran boleh dinyatakan dalam dua cara: satu ialah tahap perincian yang diwakili oleh gabungan atribut dimensi, dan satu lagi ialah makna perniagaan khusus yang diwakili. Telus! Kaedah pemodelan biasa dan contoh praktikal dalam medan gudang data.
Kaedah dan prinsip pemodelan
Perlu membina model dimensi, secara amnya menggunakan Model corak bintang, keadaan yang dibentangkan secara amnya ialah model buruj (terdiri daripada berbilang jadual fakta, jadual dimensi adalah awam dan boleh dikongsi oleh berbilang jadual fakta); 🎜> Untuk menyokong data dijalankan semula, medan tarikh perniagaan data tambahan boleh ditambah, jadual boleh dibahagikan mengikut hari, dan data lapisan ODS tambahan serta jadual berkaitan DWD pada hari sebelumnya boleh digunakan untuk pemprosesan gabungan?
Kebutiran ialah deretan maklumat yang mewakili tingkah laku, seperti membuat pesanan.
Langkah pemodelan dimensi
Pilih proses perniagaan: Dalam sistem perniagaan, pilih Berminat baris perniagaan, seperti perniagaan pesanan, perniagaan pembayaran, perniagaan bayaran balik, perniagaan logistik, satu baris perniagaan sepadan dengan satu jadual fakta. Jika ia adalah syarikat kecil atau sederhana, cuba pilih semua proses perniagaan. Jika DWD adalah sebuah syarikat besar (lebih daripada 1,000 meja), pilih baris perniagaan yang berkaitan dengan keperluan.
Kebutiran pengisytiharan: Kebutiran data merujuk kepada tahap pemurnian atau kekomprehensif data yang disimpan dalam gudang data. Mengisytiharkan kebutiran bermakna dengan tepat mentakrifkan barisan data dalam jadual fakta Anda harus memilih butiran terkecil yang mungkin untuk memenuhi pelbagai keperluan. Pernyataan kebutiran biasa adalah seperti berikut: setiap item dalam susunan dianggap sebagai baris dalam jadual fakta pesanan dan kebutiran adalah setiap kali. Bilangan pesanan setiap minggu diberikan secara berturut-turut, dengan butiran adalah setiap minggu. Bilangan pesanan setiap bulan dibentangkan sebagai satu baris, dengan butiran adalah setiap bulan. Jika butiran pada lapisan DWD adalah mingguan atau bulanan, maka tidak akan ada cara untuk mengira penunjuk terperinci kemudian. Oleh itu, disyorkan untuk menggunakan butiran terkecil.
Tentukan dimensi: Peranan utama dimensi adalah untuk menerangkan fakta perniagaan, terutamanya mewakili maklumat seperti "siapa, di mana, bila". Prinsip untuk menentukan dimensi ialah: sama ada penunjuk dimensi yang berkaitan perlu dianalisis dalam keperluan berikutnya. Contohnya, statistik diperlukan untuk menentukan bila lebih banyak pesanan dibuat, wilayah mana yang membuat lebih banyak pesanan dan pengguna yang membuat lebih banyak pesanan. Dimensi yang perlu ditentukan termasuk: dimensi masa, dimensi wilayah dan dimensi pengguna. Jadual dimensi: Degradasi dimensi perlu dilakukan mengikut prinsip skema bintang dalam pemodelan dimensi.
Tentukan fakta: Perkataan "fakta" di sini merujuk kepada nilai ukuran (bilangan kali, bilangan, bilangan keping, jumlah) dalam perniagaan, yang boleh menjadi Pengumpulan), seperti jumlah pesanan, bilangan pesanan yang dibuat, dsb. Dalam lapisan DWD, proses perniagaan digunakan sebagai pemacu pemodelan, dan jadual fakta lapisan terperinci yang paling terperinci dibina berdasarkan ciri-ciri setiap proses perniagaan tertentu. Jadual fakta boleh diluaskan dengan sewajarnya.
Nota: Lapisan DWD didorong oleh proses perniagaan. Lapisan DWS, lapisan DWT dan lapisan ADS semuanya dipacu permintaan dan tiada kaitan dengan pemodelan dimensi. DWS dan DWT membina jadual lebar dan membina jadual mengikut tema. Tema adalah setara dengan perspektif dari mana masalah itu dilihat. Sesuai dengan jadual dimensi.
Mengenai topik:
Data dalam gudang data disusun mengikut topik . Tema ialah konsep abstrak yang digunakan untuk mensintesis, mengklasifikasikan, menganalisis dan menggunakan data dalam sistem maklumat perusahaan pada tahap tinggi Setiap tema pada asasnya sepadan dengan medan analisis makro. Sebagai contoh, analisis kewangan adalah bidang analisis, maka tema aplikasi gudang data ini ialah "analisis kewangan".
Mengenai domain subjek:
Domain subjek biasanya merupakan pengumpulan topik data yang berkait rapat. Topik data ini boleh dibahagikan kepada bidang subjek yang berbeza berdasarkan kebimbangan perniagaan (iaitu, sempadan topik yang ditentukan selepas menganalisis topik)
Mengenai pembahagian bidang subjek:
Penentuan bidang subjek mesti diselesaikan secara bersama oleh pengguna akhir (perniagaan) dan pereka gudang data Apabila membahagikan kawasan subjek, titik masuk yang berbeza boleh menyebabkan beberapa perdebatan dan pembinaan semula pertimbangkan mungkin beberapa aspek berikut:
- Dibahagikan mengikut perniagaan atau proses perniagaan: Sebagai contoh, syarikat yang bergantung pada penjualan jawatan pengiklanan domain subjek portal mungkin mempunyai domain pengiklanan, domain pelanggan, dsb., dan domain pengiklanan mungkin mempunyai inventori pengiklanan, analisis jualan, analisis penghantaran dalaman dan topik lain
- Dibahagikan mengikut bahagian permintaan: Contohnya, jika bahagian permintaan ialah jabatan kewangan, bidang subjek kewangan yang sepadan boleh ditetapkan, dan bidang subjek kewangan mungkin termasuk topik seperti analisis gaji pekerja, analisis nisbah pulangan pelaburan, dsb. ;
- Dibahagikan mengikut fungsi atau aplikasi: Contohnya, medan data bulatan rakan, medan data sembang kumpulan, dll. dalam WeChat, dan bulatan medan data rakan mungkin mempunyai tema maklumat dinamik pengguna dan tema pengiklanan dll.; dsb. Dalam domain operasi, mungkin ada analisis perbelanjaan gaji, analisis kesan promosi acara, dll. Tema
- Pendek kata, jika permulaan; logik titik adalah berbeza, boleh ada logik bahagian yang berbeza. Pendekatan berulang boleh diguna pakai semasa proses pembinaan Daripada menumpukan pada menyelesaikan abstraksi semua topik sekaligus, anda boleh bermula dengan topik yang ditakrifkan dengan jelas dan kemudian secara beransur-ansur meringkaskannya ke dalam model standard untuk industri anda sendiri.
Topik: pihak, pemasaran, kewangan, perjanjian kontrak, organisasi, alamat, saluran, produk,
Apakah tema perniagaan kewangan: Ia boleh dibahagikan kepada empat tema:
Tema pengguna (umur pengguna, jantina, penghantaran alamat , nombor telefon, wilayah, dsb.)
- Subjek transaksi (data pesanan, data bil, dll.)
- Tema kawalan risiko (tahap kawalan risiko pengguna, data kredit pihak ketiga)
- Tema pemasaran (senarai aktiviti pemasaran, konfigurasi aktiviti maklumat, dsb.)
- 2) DWD (perincian gudang data) lapisan butiran data, lapisan fakta berbutir
DWD ialah lapisan pengasingan antara lapisan perniagaan dan gudang data Lapisan ini menyelesaikan beberapa isu kualiti data dan isu integriti data.
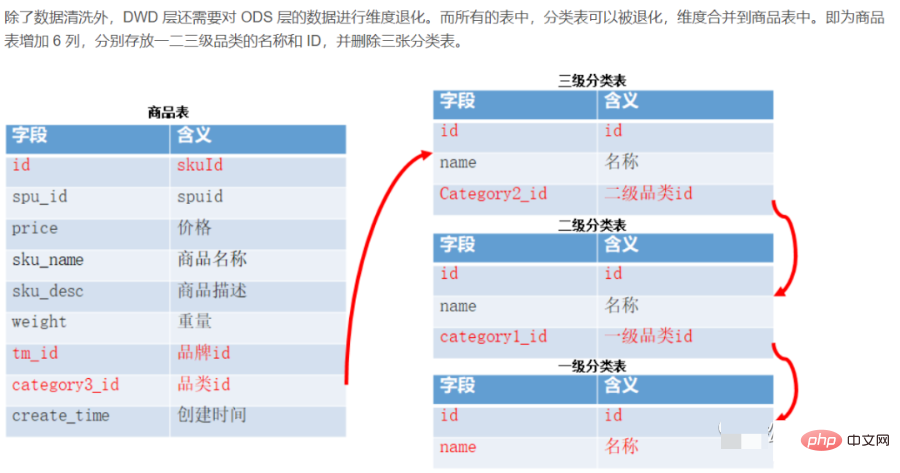
Jadual terperinci digunakan untuk menyimpan data terperinci yang ditukar daripada jadual asal lapisan ODS Data lapisan DWD hendaklah konsisten, tepat dan bersihkan data, iaitu, Bersihkan data sistem sumber data lapisan ODS (buang nilai nol, data kotor, data melebihi julat had, tukar storan baris kepada storan lajur, tukar format mampatan), normalisasi, degradasi dimensi, penyahpekaan dan operasi lain. Sebagai contoh, maklumat data pengguna datang daripada banyak jadual yang berbeza, dan masalah seperti kehilangan data tertangguh sering berlaku Untuk memudahkan setiap pengguna menggunakan data dengan lebih baik, kami boleh mencipta perisai pada lapisan ini. Lapisan ini juga mengandungi data dimensi bersatu.
Lapisan fakta butiran terperinci (DWD): Menggunakan proses perniagaan sebagai pemacu pemodelan, berdasarkan ciri-ciri setiap proses perniagaan tertentu, butiran terbaik lapisan terperinci dibina Jadual fakta. Menggabungkan ciri penggunaan data perusahaan, beberapa medan atribut dimensi penting bagi jadual fakta terperinci boleh dibuat secara berlebihan, iaitu pemprosesan jadual lebar. Jadual pada tahap fakta berbutir halus sering juga dipanggil jadual fakta logik.
Bertanggungjawab untuk data yang paling berbutir, berdasarkan lapisan DWD, diringkaskan secara ringkas, digabungkan dengan dimensi biasa (masa, lokasi, peringkat organisasi, pengguna, komoditi, dsb.)
Lapisan ini secara amnya mengekalkan butiran data yang sama seperti lapisan ODS, dan menyediakan jaminan kualiti data tertentu dan melaksanakan pemprosesan data berdasarkan ODS. Pemprosesan untuk menyediakan data yang lebih bersih. Pada masa yang sama, untuk meningkatkan kebolehgunaan lapisan butiran data, lapisan ini akan menggunakan beberapa teknik degradasi dimensi Apabila sesuatu dimensi tidak mempunyai sebarang data yang diperlukan oleh gudang data, dimensi boleh direndahkan dan dimensi boleh diubah. diturunkan kepada jadual fakta, mengurangkan bilangan jadual fakta dan perkaitan jadual Dimensi.
Contohnya:
Id pesanan, tidak perlu menggunakan jadual dimensi untuk Storan yang begitu besar. dan id pesanan secara amnya sangat penting apabila kami melakukan analisis data, jadi kami melebihkan id pesanan dalam jadual fakta Dimensi ini ialah dimensi merosot.
Data pada tahap ini secara amnya mengikut bentuk normal ketiga atau pemodelan dimensi pangkalan data, dan butiran datanya biasanya sama dengan ODS. Semua data sejarah dalam sistem BI akan disimpan pada lapisan PDW, seperti data 10 tahun.
Kerja berikut perlu dilakukan sebelum data dimuatkan ke dalam lapisan ini: denoising, penyahduplikasi, pengekstrakan, pengekstrakan perniagaan, penyatuan unit, pemotongan medan dan pengenalan perniagaan.
Jenis data yang dibersihkan:
- Data tidak lengkap
- Data buruk
- Data pendua
Tugas pembersihan data adalah untuk menapis data yang tidak memenuhi keperluan dan menyerahkan hasil yang ditapis kepada jabatan perniagaan yang bertanggungjawab untuk mengesahkan sama ada ia ditapis atau diperbetulkan oleh unit perniagaan sebelum pengekstrakan.
Apakah yang dilakukan oleh lapisan DWD?
①Pembersihan dan Penapisan Data
Alih keluar medan terbengkalai dan maklumat yang tidak diformatkan
Alih keluar maklumat yang telah kehilangan medan utama
Tapis data tidak bermakna dalam medan teras , contohnya, id pesanan dalam jadual pesanan adalah batal, dan id pembayaran dalam jadual pembayaran kosong
Nyahpekakan data sensitif seperti nombor telefon mudah alih dan nombor ID
Alih keluar data yang tidak mengandungi maklumat masa (ini bergantung pada perniagaan khusus syarikat, tetapi secara amnya data tersebut akan mempunyai cap masa, yang akan memudahkan pemprosesan maklumat seterusnya dalam dimensi masa) Analisis, pemprosesan dan pengekstrakan)
Sesetengah syarikat juga akan meratakan data pada lapisan ini, tetapi ini bergantung pada keperluan perniagaan kerana kylin sesuai untuk pemprosesan Data yang diratakan tidak sesuai untuk memproses maklumat data jadual bersarang
Sesetengah syarikat juga akan memotong sesi data, yang biasanya log data apl senario perniagaan lain mungkin tidak sesuai Ini kerana apl memasuki mod latar belakang Contohnya, pengguna membuka apl selama 10 minit pada waktu pagi, dan kemudian apl itu pergi ke latar belakang dan dibuka semula pada. malam. Pada masa ini, sesi masih satu, dan ia sebenarnya harus dipotong ( Terdapat juga syarikat yang akan merekodkan rekod aplikasi memasuki latar belakang dan memasuki latar depan semula untuk melakukan pemotongan sesi)
②Pemetaan dan penukaran data
Tukar latitud dan longitud GPS kepada alamat terperinci wilayah dan bandar. Pertanyaan pantas GPS biasa dalam industri biasanya memetakan pangkalan pengetahuan lokasi geografi menggunakan geohash, dan kemudian menukar GPS untuk dibandingkan kepada geohash dan kemudian membandingkan geohash dalam pangkalan pengetahuan untuk mengetahui maklumat lokasi geografi syarikat yang menggunakan api terbuka, seperti Amap , API Peta Baidu memetakan GPS dan maklumat lokasi geografi, tetapi memerlukan wang untuk mencapai bilangan kali tertentu, jadi semua orang tahu bahawa
juga akan menggunakan alamat IP Tukar kepada alamat terperinci wilayah, bandar dan bandar. Terdapat banyak perpustakaan carian pantas, tetapi prinsip asasnya ialah carian binari, kerana alamat IP boleh ditukar menjadi integer panjang Contoh biasa ialah perpustakaan ip2region
<.> yang menukar masa Seragamkan data untuk maklumat dimensi tahun, bulan, hari malah minggu dan suku
, kerana data yang diproses oleh data besar mungkin berasal daripada jabatan yang berbeza bagi syarikat sumber, projek yang berbeza, dan berbeza Di sisi pelanggan, medan data perniagaan yang sama, jenis data, nilai nol, dsb. mungkin berbeza pada masa ini, lapisan DWD perlu diratakan. Jika tidak, ia akan menyebabkan banyak masalah semasa pemprosesan seterusnya
Sebagai contoh, boolean ditandakan dengan 0 1 dan true false digunakan untuk
, seperti nilai nol rentetan, Ada yang menggunakan "", ada yang menggunakan null, hanya gunakan null
Sebagai contoh, format tarikh lebih berbeza dan perlu ditentukan berdasarkan data perniagaan sebenar, tetapi secara amnya diformatkan ke dalam format standard seperti YYYY-MM-dd HH:mm:ss
Degradasi dimensi: Lakukan penurunan dimensi dan pengurangan dimensi pada jadual yang dipindahkan daripada data perniagaan. (Produk tahap satu, tahap dua, tahap tiga, wilayah, bandar, daerah, tahun, bulan, hari) Lebihan ID Pesanan terdapat dalam jadual fakta
Bagaimana banyak data yang munasabah untuk dibersihkan: 1 Bersihkan 1 daripada 10,000 keping data.
Bilangan meja yang munasabah: Sepuluh ribu meja menjadi tiga ribu meja, tiga ribu meja menjadi seribu meja
Prinsip reka bentuk jadual fakta berbutir terperinci:
- Jadual fakta berbutir halus hanya dikaitkan dengan satu dimensi.
- Sertakan seberapa banyak fakta yang mungkin berkaitan dengan proses perniagaan.
- Pilih hanya fakta yang berkaitan dengan proses perniagaan.
- Urai fakta bukan tambahan kepada komponen aditifnya.
- Kebutiran mesti diisytiharkan sebelum memilih dimensi dan fakta.
- Anda tidak boleh mempunyai berbilang fakta butiran berbeza dalam jadual fakta yang sama.
- Unit fakta hendaklah konsisten. Kebutiran
- Kendalikan nilai Null dengan berhati-hati.
- Gunakan dimensi merosot untuk meningkatkan kebolehgunaan jadual fakta.
Rancangan
Pelan perbincangan: Kaedah sintesis data ialah:
Penuh: Setiap hari, data penuh hari sebelumnya dan data baharu semalam pada lapisan butiran digabungkan menjadi jadual data baharu, meliputi jadual lama. Pada masa yang sama, gunakan pencerminan sejarah untuk menyimpan cermin sejarah dalam jadual baharu mengikut minggu/bulan/tahun.
Kaedah penyimpanan log: data langsung menggunakan penampilan impala dan format fail parket. Lapisan berikut adalah semua data yang dijana daripada impala. Adalah disyorkan bahawa semua Gunakan jadual dalaman + pembahagian statik/dinamik.
Skema jadual: Secara umumnya buat partition mengikut hari dan pilih medan partition mengikut perniagaan tertentu jika tiada konsep masa. dibahagikan oleh biasanya disimpan mengikut hari.
Perpustakaan dan penamaan jadual. Nama perpustakaan: dwd, nama jadual: Format pertimbangan awal ialah nama jadual perniagaan tarikh dwd, yang akan ditentukan.
Kaedah kemas kini data lama: timpa langsung
Lapisan fakta berbutir terperinci (DWD ) Spesifikasi
Spesifikasi penamaan ialah: dwd_{bahagian perniagaan/pub}_{singkatan domain data}_{singkatan proses perniagaan}[_{penamaan jadual tersuai label Singkatan}] _{Pengecam penuh penambahan partition tunggal}, pub menunjukkan bahawa data termasuk data daripada berbilang sektor perniagaan. Pengecam jumlah penuh tambahan bagi satu partition biasanya: i bermaksud kenaikan, f bermaksud jumlah penuh.
Contohnya: dwd_asale_trd_ordcrt_trip_di (Jadual fakta pesanan tiket udara syarikat e-dagang, kenaikan segar semula harian) dwd_asale_itm_item_df (Jadual fakta snapshot produk e-dagang Jumlah penuh dimuat semula setiap hari).
Dalam tutorial ini, lapisan DWD terutamanya terdiri daripada tiga jadual:
- Jadual fakta maklumat produk dagangan: dwd_asale_trd_itm_di.
- Jadual fakta maklumat ahli dagangan: ods_asale_trd_mbr_di.
- Jadual fakta maklumat pesanan transaksi: dwd_asale_trd_ord_di.
CREATE TABLE IF NOT EXISTS dwd_asale_trd_itm_di ( item_id BIGINT COMMENT '商品ID', item_title STRING COMMENT '商品名称', item_price DOUBLE COMMENT '商品价格', item_stuff_status BIGINT COMMENT '商品新旧程度_0全新1闲置2二手', item_prov STRING COMMENT '商品省份', item_city STRING COMMENT '商品城市', cate_id BIGINT COMMENT '商品类目ID', cate_name STRING COMMENT '商品类目名称', commodity_id BIGINT COMMENT '品类ID', commodity_name STRING COMMENT '品类名称', buyer_id BIGINT COMMENT '买家ID', ) COMMENT '交易商品信息事实表' PARTITIONED BY (ds STRING COMMENT '日期') LIFECYCLE 400;
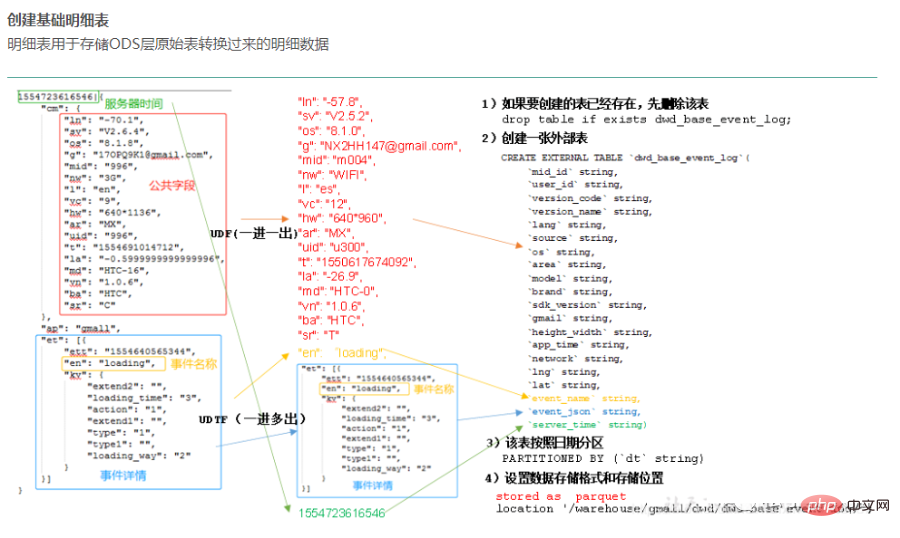
3) Lapisan perkhidmatan data DWS (perkhidmatan gudang data), jadual lebar lapisan ringkasan
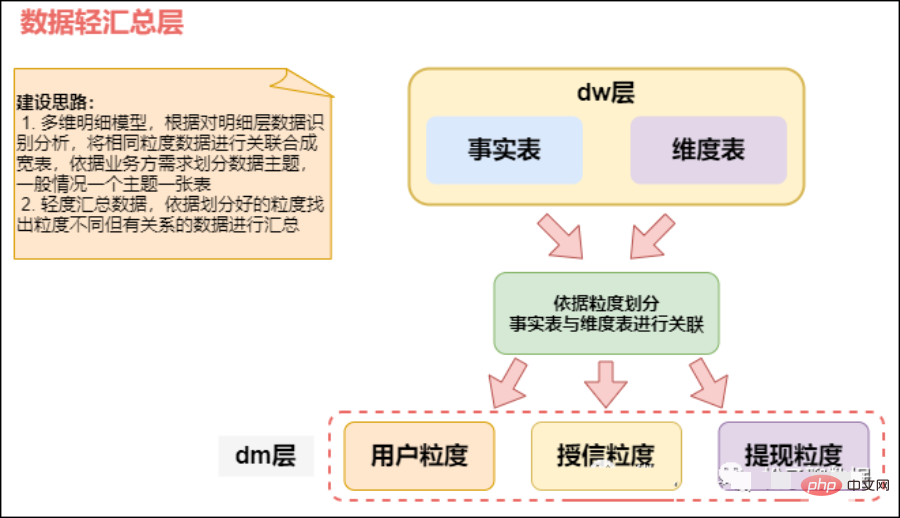
Berdasarkan lapisan data terperinci DWD, kami akan menyusun data kami mengikut beberapa senario analisis, entiti analisis, dll., dan menyusunnya ke dalam beberapa lapisan data ringkasan DWS mengikut tema.
Kebutiran terperinci==> Kebutiran ringkasan
Lapisan DWS (lapisan ringkasan data) Jadual lebar, ringkasan berorientasikan subjek, mempunyai dimensi yang agak sedikit DWS melaksanakan ringkasan berbutir kasar dan pengagregatan mengikut setiap ID dimensi berdasarkan data asas lapisan DWD, seperti pengagregatan mengikut sumber transaksi dan jenis transaksi. Mengintegrasikan dan meringkaskan data perkhidmatan untuk analisis kawasan subjek tertentu, biasanya dalam jadual yang luas.
Ringkasan ringkas mengikut hari berdasarkan DWD. Statistik tingkah laku harian setiap objek subjek (contohnya, tingkah laku pembelian, statistik kadar pembelian semula produk).
Akan terdapat sedikit jadual data dalam lapisan ini, dan kebanyakannya adalah jadual lebar (satu jadual akan merangkumi lebih banyak kandungan perniagaan, dan akan terdapat lebih banyak medan dalam jadual) ). Mengikut topik, seperti pesanan, pengguna, dsb., jadual lebar dengan banyak medan dijana untuk menyediakan pertanyaan perniagaan seterusnya, analisis OLAP, pengedaran data, dsb.
Sepadukan berbilang data lapisan tengah untuk membentuk jadual fakta berdasarkan topik, seperti jadual fakta pengguna, jadual fakta saluran, jadual fakta terminal, jadual fakta aset, dsb. . Jadual fakta biasanya adalah jadual yang luas, mencapai konsistensi data peringkat perusahaan pada lapisan ini.
Mula-mula bahagikan topik perniagaan kepada domain jualan, domain inventori, domain pelanggan, domain pembelian, dll. Langkah kedua ialah menentukan jadual fakta bagi setiap subjek domain dan jadual dimensi. Biasanya berdasarkan keperluan perniagaan, ia dibahagikan kepada trafik, pesanan, pengguna, dsb., dan jadual lebar dengan banyak medan dijana untuk menyediakan pertanyaan perniagaan seterusnya, analisis OLAP, pengedaran data, dsb.
Jumlah jualan kategori tertentu (contohnya: peralatan dapur) di setiap wilayah pada hari terakhir, nama 10 produk jualan teratas dalam kategori , dan pengagihan kuasa beli pengguna di setiap wilayah. Oleh itu, kita boleh meringkaskan data hari terakhir dari perspektif transaksi terakhir yang berjaya bagi barangan, kategori, pembeli, dsb.
Contohnya, bilangan produk yang dibeli oleh pengguna pada IP log masuk yang berbeza dalam setiap tempoh masa, dsb. Ringkasan yang ringan di sini akan menjadikan pengiraan lebih cekap Berdasarkan ini, ia akan menjadi lebih cepat jika tingkah laku hanya 7 hari, 30 hari dan 90 hari dikira. Kami berharap 80% perniagaan boleh dikira melalui lapisan DWS kami dan bukannya ODS.
Apakah yang dilakukan oleh lapisan DWS?
dws meringkaskan data dalam lapisan dwd mengikut tema dan meletakkannya ke dalam jadual mengikut tema,
Sebagai contoh, di bawah tema pengguna, maklumat pendaftaran pengguna, alamat penghantaran pengguna dan data kredit pengguna akan dimasukkan ke dalam jadual yang sama, dan ini sepadan dengan berbilang jadual dalam lapisan dwd, dibahagikan mengikut perniagaan , seperti trafik, pesanan , pengguna, dsb., menjana jadual lebar dengan banyak medan
Pemodelan topik, menjalankan pemodelan data sekitar tema perniagaan tertentu dan ekstrak data yang berkaitan .
Contohnya:
- Atur sesi trafik mengikut hari dan bulan Pengagregatan
- Penggabungan pengguna baharu harian
- Penggabungan pengguna aktif harian Pengagregatan
- Pemodelan dimensi sebenarnya serupa, tetapi berdasarkan keperluan perniagaan, data dimensi yang diperlukan untuk pemprosesan pertanyaan data berikutnya diekstrak dan diproses terlebih dahulu untuk memudahkan tindak- sehingga penggunaan Pertanyaan.
- Sebagai contoh, jika data dimensi operasi diagregatkan
- untuk menambah saluran baharu Pengagregatan data dimensi
①DWS lapisan 1-3 jadual lebar bagi setiap topik (mengendalikan lebih daripada 70% keperluan untuk 100-200 penunjuk)
Nama jadual lebar khusus: jadual lebar tingkah laku pengguna, jadual lebar tingkah laku butiran produk pembelian pengguna, jadual lebar produk, jadual lebar logistik, selepas jualan, dsb.
②Meja lebar yang manakah paling lebar? Kira-kira berapa banyak bidang yang ada?
Yang paling luas ialah jadual lebar tingkah laku pengguna. Terdapat kira-kira 60-200 medan
③Nama medan jadual lebar tingkah laku pengguna khusus
Komen, ganjaran, kumpul, ikuti--produk, ikuti--orang, suka, kongsi, berita harga baik, keluaran artikel, aktif, log masuk, tandatangan semula kad, rumah bertuah, hadiah, syiling emas, klik e-dagang , gmv
④Petunjuk yang dianalisis
Aktiviti harian, aktiviti bulanan, aktiviti mingguan, pengekalan , kadar pengekalan, penambahan baharu (hari, minggu, tahun), kadar penukaran, churn, return, 3 hari berturut-turut log masuk dalam masa tujuh hari (suka, koleksi, ulasan, pembelian, pembelian tambahan, pesanan, aktiviti), 3 minggu berturut-turut ( Bulan) log masuk, GMV (jumlah transaksi, penempatan pesanan), kadar belian semula, kedudukan kadar pembelian semula, suka, ulasan, koleksi, bilangan orang yang menerima diskaun, menggunakan diskaun, senyap, sama ada ia berbaloi untuk dibeli, bilangan bayaran balik, bayaran balik Topn popular item
- Aktif
Aktiviti harian: 1 juta; pengguna aktif bulanan: 2-3 kali ganda pengguna aktif harian, 3 juta
Berapa jumlah pengguna berdaftar yang ada? Antara 10 juta hingga 30 juta
- GMV, produk manakah yang paling laris? Berapa banyak pesanan dibuat setiap hari?
GMV: 100,000 pesanan sehari (50 – 100 yuan) 5 juta-10 juta
Dengan aktiviti harian sebanyak 1 juta, terdapat kira-kira 100,000 pembelian setiap hari, dengan penggunaan purata 100 yuan setiap orang ialah GMV sehari ialah 10 juta
10 %-20% 1 juta-2 juta
- Kadar belian balik
Pembelian semula produk harian tertentu; (kertas tandas, topeng muka, ubat gigi) 10%-20%
Komputer, monitor, jam tangan 1%
- Kadar penukaran
Butiran produk=》 Tambah ke troli=》 Place order=》Bayar
5%-10% 60-70% 90%-95%
- Kadar pengekalan
1/2/3, pengekalan mingguan , pengekalan bulanan
Aktiviti: 10-20%
Rancangan:
Konsep: Juga dikenali sebagai data mart atau wide table. Berdasarkan bahagian perniagaan, seperti trafik, pesanan, pengguna, dsb., jadual lebar dengan banyak medan dijana untuk menyediakan pertanyaan perniagaan seterusnya, analisis OLAP, pengedaran data, dsb.
Kaedah penjanaan data: dijana oleh lapisan ringkasan cahaya dan pengiraan data lapisan terperinci.
Kaedah storan log: menggunakan jadual dalaman impala, format fail parket.
Skema jadual: Secara umumnya buat partition mengikut hari dan pilih medan partition mengikut perniagaan tertentu jika tiada konsep masa.
Penamaan perpustakaan dan jadual. Nama perpustakaan: dws, nama jadual: Format pertimbangan awal ialah: nama jadual perniagaan tarikh dws, yang akan ditentukan.
Kaedah kemas kini data lama: timpa langsung
Spesifikasi jadual fakta ringkasan awam
公共汇总事实表命名规范:dws_{业务板块缩写/pub}_{数据域缩写}_{数据粒度缩写}[_{自定义表命名标签缩写}]_{统计时间周期范围缩写}。关于统计实际周期范围缩写,缺省情况下,离线计算应该包括最近一天(_1d),最近N天(_nd)和历史截至当天(_td)三个表。如果出现_nd的表字段过多需要拆分时,只允许以一个统计周期单元作为原子拆分。即一个统计周期拆分一个表,例如最近7天(_1w)拆分一个表。不允许拆分出来的一个表存储多个统计周期。
对于小时表(无论是天刷新还是小时刷新),都用_hh来表示。对于分钟表(无论是天刷新还是小时刷新),都用_mm来表示。
举例如下:
dws_asale_trd_byr_subpay_1d(买家粒度交易分阶段付款一日汇总事实表)
dws_asale_trd_byr_subpay_td(买家粒度分阶段付款截至当日汇总表)
dws_asale_trd_byr_cod_nd(买家粒度货到付款交易汇总事实表)
dws_asale_itm_slr_td(卖家粒度商品截至当日存量汇总表)
dws_asale_itm_slr_hh(卖家粒度商品小时汇总表)---维度为小时
dws_asale_itm_slr_mm(卖家粒度商品分钟汇总表)---维度为分钟
- 用户维度:用户主题
drop table
if exists dws_sale_detail_daycount;
create external table dws_sale_detail_daycount(
user_id string comment '用户 id',
--用户信息
user_gender string comment '用户性别',
user_age string comment '用户年龄',
user_level string comment '用户等级',
buyer_nick string comment '买家昵称',
mord_prov string comment '地址',
--下单数、 商品数量, 金额汇总
login_count bigint comment '当日登录次数',
cart_count bigint comment '加入购物车次数',
order_count bigint comment '当日下单次数',
order_amount decimal(16,2) comment '当日下单金额',
payment_count bigint comment '当日支付次数',
payment_amount decimal(16,2) comment '当日支付金额',
confirm_paid_amt_sum_1d double comment '最近一天订单已经确认收货的金额总和'
order_detail_stats array<struct<sku_id:string,sku_num:bigint,order_count:bigint,order_amount:decimal(20,2)>> comment '下单明细统计'
) comment '每日购买行为'
partitioned by(`dt`
string)
stored as parquet
location '/warehouse/gmall/dws/dws_sale_detail_daycount/'
tblproperties("parquet.compression" = "lzo");- 商品维度:商品主题
CREATE TABLE IF NOT EXISTS dws_asale_trd_itm_ord_1d ( item_id BIGINT COMMENT '商品ID', --商品信息,产品信息 item_title STRING COMMENT '商品名称', cate_id BIGINT COMMENT '商品类目ID', cate_name STRING COMMENT '商品类目名称', --mord_prov STRING COMMENT '收货人省份', --商品售出金额汇总 confirm_paid_amt_sum_1d DOUBLE COMMENT '最近一天订单已经确认收货的金额总和' ) COMMENT '商品粒度交易最近一天汇总事实表' PARTITIONED BY (ds STRING COMMENT '分区字段YYYYMMDD') LIFECYCLE 36000;
问:数据集市层是不是没地方放了,各个业务的数据集市表是应该在 dws 还是在 app?
答:这个问题不太好回答,我感觉主要就是明确一下数据集市层是干什么的,如果你的数据集市层放的就是一些可以供业务方使用的宽表,放在 app 层就行。如果你说的数据集市层是一个比较泛一点的概念,那么其实 dws、dwd、app 这些合起来都算是数据集市的内容。
03 应用层(ADS)applicationData Service应用数据服务
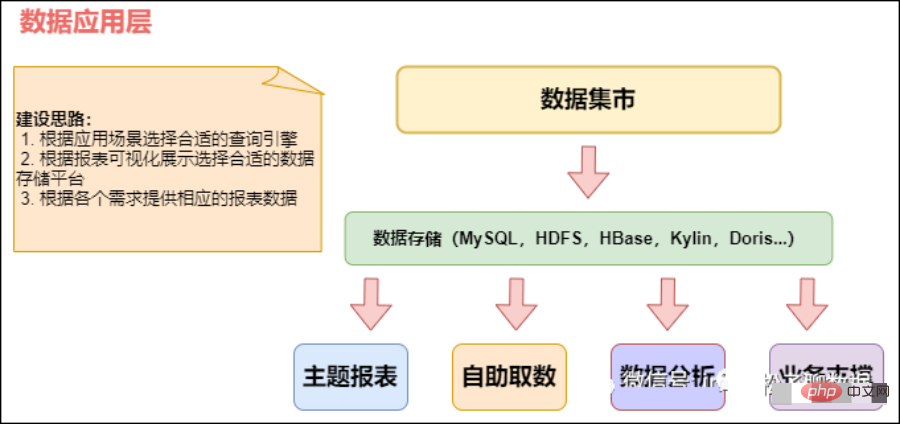
数据应用层(ADS,Application Data Store):存放数据产品个性化的统计指标数据,报表数据。主要是提供给数据产品和数据分析使用的数据,通常根据业务需求,划分成流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。从数据粒度来说,这层的数据是汇总级的数据,也包括部分明细数据。从数据的时间跨度来说,通常是DW层的一部分,主要的目的是为了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年的即可。从数据的广度来说,仍然覆盖了所有业务数据。
在 DWS 之上,我们会面向应用场景去做一些更贴近应用的 APP 应用数据层,这些数据应该是高度汇总的,并且能够直接导入到我们的应用服务去使用。
应用层(ADS):应用层主要是各个业务方或者部门基于DWD和DWS建立的数据集市(Data Market, DM),一般来说应用层的数据来源于DW层,而且相对于DW层,应用层只包含部门或者业务方面自己关心的明细层和汇总层的数据。
该层主要是提供数据产品和数据分析使用的数据。一般就直接对接OLAP分析,或者业务层数据调用接口了
数据应用层APP:面向业务定制的应用数据主要提供给数据铲平和数据分析使用的数据,一般会放在ES,MYSQL,Oracle,Redis等系统供线上系统使用,也可以放在Hive 或者 Druid 中供数据分析和数据挖掘使用。
APP 层:为应用层,这层数据是完全为了满足具体的分析需求而构建的数据,也是星形或雪花结构的数据。如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。包括前端报表、分析图表、KPI、仪表盘、OLAP、专题等分析,面向最终结果用户;
概念:应用层是根据业务需要,由前面三层数据统计而出的结果,可以直接提供查询展现,或导入至Mysql中使用。
数据生成方式:由明细层、轻度汇总层,数据集市层生成,一般要求数据主要来源于集市层。
日志存储方式:使用impala内表,parquet文件格式。
表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
库与表命名。库名:暂定ads,另外根据业务不同,不限定一定要一个库。
旧数据更新方式:直接覆盖。
ADS 层复购率统计
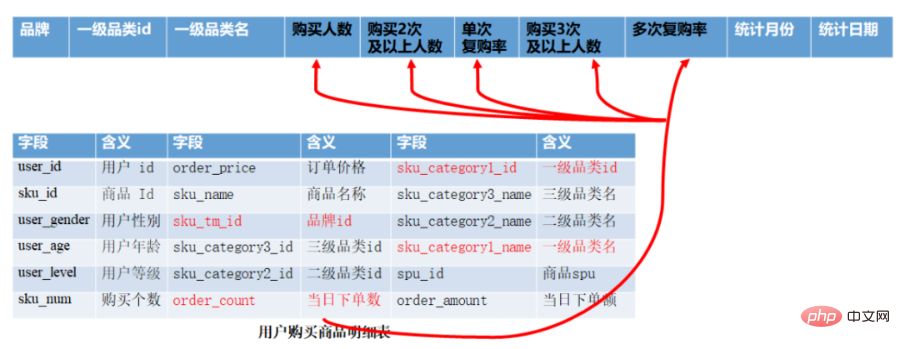



CREATE TABLE app_usr_interact( user_id string COMMENT '用户id', nickname string COMMENT '用户昵称', register_date string COMMENT '注册日期', register_from string COMMENT '注册来源', remark string COMMENT '细分渠道', province string COMMENT '注册省份', pl_cnt bigint COMMENT '评论次数', ds_cnt bigint COMMENT '打赏次数', sc_add bigint COMMENT '添加收藏', sc_cancel bigint COMMENT '取消收藏', gzg_add bigint COMMENT '关注商品', gzg_cancel bigint COMMENT '取消关注商品', gzp_add bigint COMMENT '关注人', gzp_cancel bigint COMMENT '取消关注人', buzhi_cnt bigint COMMENT '点不值次数', zhi_cnt bigint COMMENT '点值次数', zan_cnt bigint COMMENT '点赞次数', share_cnts bigint COMMENT '分享次数', bl_cnt bigint COMMENT '爆料数', fb_cnt bigint COMMENT '好价发布数', online_cnt bigint COMMENT '活跃次数', checkin_cnt bigint COMMENT '签到次数', fix_checkin bigint COMMENT '补签次数', house_point bigint COMMENT '幸运屋金币抽奖次数', house_gold bigint COMMENT '幸运屋积分抽奖次数', pack_cnt bigint COMMENT '礼品兑换次数', gold_add bigint COMMENT '获取金币', gold_cancel bigint COMMENT '支出金币', surplus_gold bigint COMMENT '剩余金币', event bigint COMMENT '电商点击次数', gmv_amount bigint COMMENT 'gmv', gmv_sales bigint COMMENT '订单数' ) PARTITIONED BY( dt string) --stat_dt date COMMENT '互动日期',
①如何分析用户活跃?
在启动日志中统计不同设备 id 出现次数。
②如何分析用户新增?
用活跃用户表 left join 用户新增表,用户新增表中 mid 为空的即为用户新增。
③如何分析用户 1 天留存?
留存用户=前一天新增 join 今天活跃
用户留存率=留存用户/前一天新增
④如何分析沉默用户?
(登录时间为 7 天前,且只出现过一次)
按照设备 id 对日活表分组,登录次数为 1,且是在一周前登录。
⑤如何分析本周回流用户?
本周活跃 left join 本周新增 left join 上周活跃,且本周新增 id 和上周活跃 id 都为 null。
⑥如何分析流失用户?
(登录时间为 7 天前)
按照设备 id 对日活表分组,且七天内没有登录过。
⑦如何分析最近连续 3 周活跃用户数?
按照设备 id 对周活进行分组,统计次数大于 3 次。
⑧Bagaimana untuk menganalisis bilangan pengguna aktif selama tiga hari berturut-turut dalam tujuh hari terakhir?
- Soal pengguna aktif dalam 7 hari lepas dan letakkan tarikh aktif pengguna
- Kira perbezaan antara tarikh aktif pengguna dan kedudukan
- Kumpulkan pengguna yang sama dan perbezaan, dan kira bilangan perbezaan
- Keluarkan data dengan bilangan perbezaan yang sama lebih besar daripada atau sama dengan 3, dan kemudian alih keluar pendua, iaitu pengguna yang telah aktif selama 3 hari berturut-turut atau lebih
7 hari berturut-turut kegemaran, suka, pembelian, pembelian tambahan, pembayaran, menyemak imbas, klik produk, pulangan
1 bulan selama 7 hari berturut-turut
Dua minggu berturut-turut
TMP: Setiap peringkat pengiraan akan mempunyai banyak jadual sementara, dan lapisan DW TMP direka khas untuk menyimpan jadual sementara gudang data kami.
04 Spesifikasi panggilan hierarki
- Panggilan terbalik adalah dilarang
- ODS hanya boleh dipanggil oleh DWD.
- DWD boleh dipanggil oleh DWS dan ADS.
- DWS hanya boleh dipanggil oleh ADS.
- Aplikasi data boleh memanggil DWD, DWS dan ADS, tetapi disyorkan untuk memberi keutamaan kepada data dengan tahap pengagregatan yang tinggi.
- ODS->DWD->DWS>ADS
- ODS->DWD- >IKLAN
Atas ialah kandungan terperinci Daripada ODS kepada ADS, penjelasan terperinci tentang stratifikasi gudang data!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI