
Rumah >Peranti teknologi >AI >Terokai teknologi model besar dalam era pasca-GPT 3.0 dan bergerak ke arah merealisasikan masa depan AGI
Terokai teknologi model besar dalam era pasca-GPT 3.0 dan bergerak ke arah merealisasikan masa depan AGI

- PHPzke hadapan
- 2023-04-26 10:58:081745semak imbas
ChatGPT mengejutkan atau menyedarkan ramai orang selepas kemunculannya. Kejutan itu adalah kerana saya tidak menjangkakan bahawa Model Bahasa Besar (LLM) boleh menjadi seberkesan ini; kebangkitan itu adalah kesedaran secara tiba-tiba bahawa pemahaman kita tentang LLM dan falsafah pembangunannya jauh daripada idea yang paling maju di dunia. Saya tergolong dalam kumpulan yang sama-sama terkejut dan tersedar, dan saya juga orang Cina tipikal yang pandai muhasabah diri, maka mereka mula bermuhasabah, dan artikel ini adalah hasil renungan.
Sejujurnya, dari segi teknologi berkaitan model LLM domestik, pada masa ini, jurang antara teknologi paling canggih dan teknologi domestik semakin melebar. Saya berpendapat isu kepimpinan teknologi atau jurang teknologi harus dilihat secara dinamik dari perspektif pembangunan. Dalam tempoh satu hingga dua tahun selepas kemunculan Bert, sebenarnya, teknologi domestik yang mengejar di kawasan ini masih sangat pantas, dan beberapa model penambahbaikan yang baik juga dicadangkan untuk melebarkan jurang harus selepas keluaran GPT 3.0 , iaitu pada tahun 2020 Sekitar pertengahan tahun. Pada masa itu, hanya segelintir orang yang sedar bahawa GPT 3.0 bukan sekadar teknologi khusus, tetapi sebenarnya merangkumi konsep pembangunan ke mana LLM harus pergi. Sejak itu, jurang itu semakin melebar, dan ChatGPT hanyalah akibat semula jadi daripada perbezaan falsafah pembangunan ini. Oleh itu, saya secara peribadi berpendapat, Mengetepikan faktor sama ada anda mempunyai sumber kewangan untuk membina LLM yang sangat besar, dari perspektif teknikal sahaja, jurang terutamanya datang dari pemahaman LLM dan konsep pembangunan ke mana hendak pergi pada masa hadapan.
China semakin ketinggalan dengan teknologi asing Ini adalah fakta, dan mustahil untuk tidak mengakuinya. Sebentar tadi, ramai orang di Internet bimbang bahawa AI domestik kini berada dalam "peringkat kritikal untuk bertahan hidup." Tidakkah anda nampak, adakah OpenAI satu-satunya syarikat di dunia yang mempunyai visi berpandangan ke hadapan? Termasuk Google, sebenarnya, pemahaman mereka tentang konsep pembangunan LLM jelas berada di belakang OpenAI. Realitinya ialah OpenAI telah menunjukkan prestasi yang terlalu baik dan meninggalkan semua orang, bukan hanya di dalam negara.Saya berpendapat OpenAI mendahului Google dan DeepMind di luar negara dari segi konsep dan teknologi berkaitan untuk LLM kira-kira setengah tahun hingga setahun, dan kira-kira dua tahun mendahului China. Mengenai LLM, saya merasakan bahawa pihak Google sepatutnya berada di tempat kedua yang paling mencerminkan visi teknikal Google ialah PaLM dan Pathways telah dilancarkan antara Februari dan April 2022. Dalam tempoh yang sama, OpenAI telah dilancarkan. Ia adalah InstructGPT Dari sini anda boleh melihat jurang antara Google dan OpenAI Mengenai mengapa saya mengatakan ini, anda mungkin boleh memahaminya selepas membaca teks di belakang saya. Fokus DeepMind sebelum ini adalah untuk mengukuhkan pembelajaran untuk menakluki permainan dan AI untuk sains Ia sebenarnya memasuki LLM sangat lambat Ia sepatutnya mula memberi perhatian kepada arah ini dalam tempoh 21 tahun, dan ia sedang mengejar. Apatah lagi Meta, tumpuannya belum tertumpu pada LLM, dan kini terasa seperti cuba mengejar. Ini masih kumpulan institusi yang melakukan yang terbaik pada masa ini Jika ini berlaku, apatah lagi yang domestik? Saya rasa boleh dimaafkan. Bagi falsafah OpenAI mengenai LLM, saya akan bercakap tentang pemahaman saya di bahagian terakhir artikel ini.
Artikel ini meringkaskan teknologi LLM arus perdana sejak kemunculan GPT 3.0 Anda boleh merujuk kepada arus perdana teknologi sebelum ini "PTM menunggang angin dan ombak, tafsiran mendalam tentang kemajuan model pra-latihan."
Saya percaya bahawa selepas membaca kedua-dua artikel ini, anda boleh memahami konteks teknikal bidang LLM, konsep pembangunan berbeza yang telah muncul dalam proses pembangunan teknologi LLM, dan juga kemungkinan trend pembangunan masa depan Mempunyai pemahaman yang lebih jelas. Sudah tentu, kandungan yang disebutkan di banyak tempat adalah pendapat peribadi saya dan sangat subjektif Ralat dan peninggalan tidak dapat dielakkan, jadi sila rujuk dengan berhati-hati.Artikel ini cuba menjawab beberapa soalan berikut:
Adakah ChatGPT telah membawa anjakan paradigma penyelidikan dalam bidang NLP dan juga AI? Jika ya, apakah kesannya? Apakah yang LLM pelajari daripada sejumlah besar data? Bagaimanakah LLM mengakses pengetahuan ini? Apabila skala LLM meningkat secara beransur-ansur, apakah kesannya? Apakah Pembelajaran Dalam Konteks Mengapa ia merupakan teknologi yang misteri? Apakah hubungannya dengan Instruct? Adakah LLM mempunyai keupayaan penaakulan? Bagaimanakah Thought Chain CoT berfungsi? Tunggu, saya percaya anda akan mendapat jawapan kepada soalan-soalan ini selepas membacanya.
Pertama sekali, sebelum bercakap tentang status semasa teknologi LLM, izinkan saya bercakap tentang anjakan paradigma penyelidikan dalam fikiran saya pada peringkat makro. Dengan cara ini, kita boleh "melihat hutan sebelum pokok" dan mempunyai pemahaman yang lebih jelas tentang mengapa teknologi tertentu telah berubah sedemikian rupa.Jika kita memanjangkan garis masa lebih jauh ke hadapan, kembali ke era pembelajaran mendalam dalam bidang NLP, dan amati dalam tetingkap masa yang lebih lama Perubahan teknologi dan kesannya mungkin memudahkan untuk melihat beberapa nod utama. Saya secara peribadi percaya bahawa semasa pembangunan teknologi dalam bidang NLP dalam tempoh 10 tahun yang lalu, mungkin terdapat dua anjakan paradigma penyelidikan yang besar. Paradigm Shift 1.0: Daripada pembelajaran mendalam kepada model pra-latihan dua peringkat Ini Julat masa yang diliputi oleh anjakan paradigma adalah secara kasar daripada pengenalan pembelajaran mendalam kepada bidang NLP (sekitar 2013) hingga sebelum kemunculan GPT 3.0 (sekitar Mei 2020) . Sebelum kemunculan model Bert dan GPT, teknologi popular dalam bidang NLP ialah model pembelajaran mendalam, dan pembelajaran mendalam dalam bidang NLP terutamanya bergantung pada teknologi utama berikut: dengan sejumlah besar penambahbaikan Model LSTM dan sebilangan kecil model CNN yang dipertingkatkan digunakan sebagai pengekstrak ciri biasa untuk Jujukan (atau penyahkod pengekod juga boleh dipanggil) + Perhatian digunakan sebagai rangka kerja teknikal keseluruhan biasa untuk pelbagai tugas khusus; . Dengan sokongan teknologi teras ini, matlamat penyelidikan utama pembelajaran mendalam dalam bidang NLP, jika diringkaskan, ialah cara meningkatkan kedalaman lapisan model atau kapasiti parameter model dengan berkesan. Maksudnya, bagaimana kita boleh terus menambah lapisan LSTM atau CNN yang lebih mendalam pada pengekod dan penyahkod untuk mencapai matlamat meningkatkan kedalaman lapisan dan kapasiti model. Walaupun usaha seperti ini sememangnya telah meningkatkan kedalaman model secara berterusan, secara keseluruhannya ia tidak begitu berjaya dari perspektif kesan menyelesaikan tugasan tertentu Dalam erti kata lain, berbanding dengan kaedah pembelajaran tidak mendalam, kelebihan yang dibawanya tidak hebat. Saya rasa sebab utama pembelajaran mendalam tidak berjaya datang dari dua aspek: dalam satu pihak, jumlah data latihan untuk tugas tertentu adalah terhad. Apabila kapasiti model meningkat, ia perlu disokong oleh jumlah data latihan yang lebih besar. Jika tidak, walaupun anda boleh meningkatkan kedalaman, kesan tugasan tidak akan dicapai. Sebelum kemunculan model pra-latihan, adalah jelas bahawa ini adalah masalah serius dalam bidang penyelidikan NLP aspek lain ialah pengekstrak ciri LSTM/CNN tidak mempunyai keupayaan ekspresif yang kuat. Ini bermakna tidak kira berapa banyak data yang anda berikan, ia tidak berguna kerana anda tidak dapat menyerap pengetahuan yang terkandung dalam data dengan berkesan. Kedua-dua sebab inilah yang menghalang kejayaan kejayaan pembelajaran mendalam dalam bidang NLP. Kemunculan dua model pra-latihan Bert/GPT, kedua-duanya dari perspektif penyelidikan akademik dan aplikasi industri, mewakili lonjakan teknologi dalam bidang NLP dan telah membawanya. anjakan paradigma dalam keseluruhan bidang penyelidikan. Kesan anjakan paradigma ini dicerminkan dalam dua aspek: pertama, kemerosotan dan bahkan kematian beransur-ansur beberapa subbidang penyelidikan NLP kedua, kaedah teknikal dan rangka kerja teknikal bagi subbidang yang berbeza NLP semakin bersatu Setahun selepas kemunculan Bert Pada masa ini, susunan teknologi pada asasnya telah menumpu kepada dua model teknologi. Mari kita bincangkan dua perkara ini secara berasingan. Impak 1: Penghapusan tugas perantaraan NLP ialah istilah umum untuk bidang penyelidikan makro, yang merangkumi pelbagai khusus Jika dianalisis dengan teliti, tugasan ini boleh dibahagikan kepada dua kategori utama dari perspektif sifat tugas: satu jenis boleh dipanggil "tugas perantaraan", dan jenis lain boleh dipanggil "tugas akhir". Tugas perantaraan biasa termasuk: pembahagian perkataan bahasa Cina, penandaan sebahagian daripada pertuturan, NER, analisis sintaksis, resolusi rujukan, penghurai semantik, dsb. Tugasan sedemikian secara amnya tidak menyelesaikan keperluan sebenar Kebanyakan daripada mereka wujud sebagai peringkat perantaraan atau tambahan untuk tugas-tugas yang menyelesaikan keperluan sebenar pengguna tidak perlu melihat NLP ini Pada peringkat pertengahan, keputusan diproses dia hanya mengambil berat tentang sama ada anda telah melakukan tugas tertentu dengan baik. "Tugas akhir" termasuk klasifikasi teks, pengiraan persamaan teks, terjemahan mesin, ringkasan teks, dsb., terdapat banyak. Ciri jenis tugasan ini ialah setiap sub-bidang menyelesaikan keperluan sebenar tertentu, dan hasil tugasan pada asasnya boleh dibentangkan terus kepada pengguna Sebagai contoh, pengguna benar-benar perlu memberi anda ayat dalam bahasa Inggeris dan memberitahunya apa Cina adalah. Secara logiknya, "tugas perantaraan" tidak sepatutnya muncul, dan sebab mengapa ia wujud adalah gambaran tahap pembangunan teknologi NLP yang tidak mencukupi. Pada peringkat awal perkembangan teknologi, kerana teknologi pada masa itu agak mundur, sukar untuk menyelesaikan tugas akhir yang sukar dalam satu langkah. Ambil terjemahan mesin sebagai contoh Pada zaman awal teknologi, sangat sukar untuk melakukan kerja yang baik dalam terjemahan mesin Oleh itu, penyelidik membahagikan dan menakluki masalah yang sukar dan menguraikannya kepada pelbagai peringkat perantaraan seperti pembahagian perkataan, sebahagian daripada. -penandaan pertuturan, dan analisis sintaksis Mereka mula-mula menyelesaikan setiap peringkat perantaraan dengan baik, dan kemudian tiada apa yang boleh kita lakukan untuk bekerjasama untuk menyelesaikan misi terakhir. Tetapi sejak kemunculan Bert/GPT, sebenarnya tidak perlu melakukan tugas-tugas perantaraan ini, kerana melalui pra-latihan dengan jumlah data yang banyak, Bert/GPT telah pun menggunakan tugas perantaraan ini sebagai ciri linguistik , diserap ke dalam parameter Transformer Pada masa ini, kita boleh menyelesaikan tugas akhir secara langsung dari hujung ke hujung tanpa perlu memodelkan proses perantaraan ini secara khusus. Mungkin perkara yang paling kontroversi di sini ialah pembahagian perkataan Cina Sebenarnya, prinsipnya adalah sama untuk menyelesaikan tugasan, ia secara semula jadi akan mempelajarinya Kaedah pembahagian perkataan yang munasabah kajian ini mungkin tidak semestinya sama dengan peraturan pembahagian perkataan yang kita manusia fahami. Berdasarkan pemahaman di atas, sebenarnya, sebaik sahaja Bert/GPT muncul, anda harus membuat kesimpulan bahawa jenis tugas peringkat pertengahan NLP ini akan beransur-ansur menarik diri daripada peringkat sejarah. Impak 2: Penyatuan laluan teknikal dalam arah penyelidikan yang berbeza Sebelum menerangkan kesan khusus, mari kita bincangkannya pertama Cara lain untuk membahagikan tugas NLP, yang berguna untuk memahami kandungan berikut. Jika "tugas akhir" diklasifikasikan lagi, ia boleh dibahagikan secara kasar kepada dua jenis tugasan: tugas pemahaman bahasa semula jadi dan tugas penjanaan bahasa semula jadi. Jika "tugas perantaraan" dikecualikan, tugas pemahaman bahasa semula jadi yang biasa termasuk klasifikasi teks, pertimbangan hubungan ayat, pertimbangan kecenderungan emosi, dsb. Tugasan ini pada asasnya adalah tugas pengelasan, iaitu, memasukkan ayat (artikel), atau dua ayat A, model merujuk kepada semua kandungan input, dan akhirnya memberikan pertimbangan bagi kategori mana ia tergolong. Penjanaan bahasa semula jadi juga termasuk banyak sub-arah penyelidikan NLP, seperti robot sembang, terjemahan mesin, ringkasan teks, sistem soal jawab, dsb. Ciri tugas penjanaan ialah teks input yang diberikan, model mesti menjana rentetan teks output dengan sewajarnya. Perbezaan antara kedua-duanya ditunjukkan terutamanya dalam bentuk input dan output Sejak kelahiran model Bert/GPT, terdapat trend penyatuan teknikal yang jelas. Pertama sekali, pengekstrak ciri subbidang yang berbeza dalam NLP disatukan secara beransur-ansur daripada LSTM/CNN kepada Transformer. Malah, tidak lama selepas Bert didedahkan kepada umum, kita sepatutnya menyedari bahawa ini sudah pasti akan menjadi trend teknologi. Mengenai sebabnya, ia telah dijelaskan dan dianalisis dalam artikel yang saya tulis beberapa tahun lalu, "Zhang Junlin: Lepaskan fantasi, terima sepenuhnya Transformer: Perbandingan tiga pengekstrak ciri utama (CNN/RNN/TF) untuk pemprosesan bahasa semula jadi" . Mereka yang berminat Pelajar boleh merujuknya. Pautan artikel: https://zhuanlan.zhihu.com/p/54743941 Dan, pada masa ini Transformer Ia bukan sahaja menyatukan banyak bidang NLP, tetapi juga sedang dalam proses menggantikan model lain secara beransur-ansur seperti CNN yang digunakan secara meluas dalam pelbagai tugas pemprosesan imej Begitu juga, model multi-modal pada asasnya menggunakan model Transformer. Transformer jenis ini bermula dari NLP dan secara beransur-ansur menyatukan trend semakin banyak bidang AI Ia bermula dengan Vision Transformer (ViT) yang muncul pada penghujung tahun 2020. Ia telah berkembang sejak itu dan telah mencapai kejayaan besar setakat ini. , dan ia terus berkembang ke lebih banyak bidang Momentum pengembangan akan menjadi semakin pesat. Kedua, model penyelidikan dan pembangunan dalam kebanyakan subbidang NLP telah bertukar kepada model dua peringkat: model peringkat pra-latihan + penalaan halus aplikasi (Fine-tuning) atau aplikasi Zero /Beberapa mod Gesaan Tangkapan. Untuk lebih tepat, pelbagai tugasan NLP sebenarnya telah bergabung menjadi dua rangka kerja model pra-latihan yang berbeza: Untuk tugas pemahaman bahasa semula jadi, sistem teknikal telah disatukan ke dalam "model bahasa dua hala pra-latihan + penalaan halus aplikasi" yang diwakili oleh Bert. " mod; untuk tugas penjanaan bahasa semula jadi, sistem teknikal disatukan dengan mod "model bahasa autoregresif (iaitu, model bahasa sehala dari kiri ke kanan) + Sifar /Few Shot Prompt" yang diwakili oleh GPT 2.0. Mengenai mengapa ia dibahagikan kepada dua laluan teknikal, ia tidak dapat dielakkan. Kedua-dua model ini mungkin kelihatan serupa, tetapi ia mengandungi idea pembangunan yang sangat berbeza dan akan membawa kepada arah pembangunan masa hadapan yang berbeza. Malangnya, kebanyakan kita memandang rendah potensi GPT sebagai laluan pembangunan pada masa itu, dan memfokuskan visi kita pada model seperti Bert. Paradigm Shift 2.0: Daripada model pra-latihan kepada Artificial General Intelligence (AGI, Artificial General Intelligence) Julat masa yang diliputi oleh anjakan paradigma ini adalah lebih kurang selepas kemunculan GPT3.0 (sekitar Jun 2020, sehingga kini, kita sepatutnya dalam proses anjakan paradigma ini. ChatGPT ialah nod utama yang mencetuskan anjakan paradigma ini, tetapi sebelum kemunculan InstructGPT, LLM sebenarnya berada dalam tempoh peralihan sebelum anjakan paradigma ini. Tempoh peralihan: Model "model bahasa autoregresif + Prompting" yang diwakili oleh GPT 3.0 mendominasi Seperti yang dinyatakan sebelum ini, dalam Pada zaman awal daripada pembangunan model pra-latihan, rangka kerja teknikal menumpu kepada dua paradigma teknikal yang berbeza, mod Bert dan mod GPT, dan orang ramai lebih optimistik tentang mod Bert. Walau bagaimanapun, apabila teknologi terus berkembang, anda akan mendapati bahawa model LLM terbesar pada masa ini hampir semuanya berdasarkan model "model bahasa autoregresif + Prompting" serupa dengan GPT 3.0, seperti GPT 3, PaLM, GLaM, Gopher, Chinchilla, MT -NLG, LaMDA, dsb., tiada pengecualian. Mengapa ini berlaku? Pasti ada sesuatu yang tidak dapat dielakkan di sebaliknya, dan saya fikir ia mungkin disebabkan oleh dua sebab. Pertama sekali, Model T5 Google secara rasmi menyatukan pemahaman bahasa semula jadi dan manifestasi Luaran semula jadi bagi tugas penjanaan bahasa . Seperti yang ditunjukkan dalam rajah di atas, apa yang ditandakan dengan warna merah ialah masalah klasifikasi teks, dan apa yang ditandakan dengan warna kuning ialah masalah regresi atau klasifikasi yang menentukan persamaan ayat Ini adalah masalah pemahaman bahasa semula jadi yang biasa. Dalam model T5, masalah pemahaman bahasa semula jadi ini adalah konsisten dengan masalah penjanaan dalam bentuk input dan output Dalam erti kata lain, masalah klasifikasi boleh ditukar kepada model LLM untuk menghasilkan rentetan kategori yang sepadan, supaya pemahaman dan. tugas generasi dinyatakan dalam bentuk Perpaduan lengkap tercapai. Ini menunjukkan bahawa tugas penjanaan bahasa semula jadi boleh serasi dengan tugas pemahaman bahasa semula jadi dari segi ekspresi Jika sebaliknya, sukar untuk mencapainya. Kelebihan ini ialah model penjanaan LLM yang sama boleh menyelesaikan hampir semua masalah NLP. Jika mod Bert masih diguna pakai, model LLM ini tidak dapat mengendalikan tugas penjanaan dengan baik. Oleh itu, terdapat satu sebab mengapa kita pastinya cenderung menggunakan model generatif. Sebab kedua, Jika anda mahu melakukannya dengan baik dengan gesaan sifar atau gesaan beberapa tembakan Untuk tugasan, anda mesti menggunakan mod GPT . Terdapat kajian (rujukan: Mengenai Peranan Dwiarah dalam Pra-Latihan Model Bahasa) yang telah membuktikan bahawa jika tugasan hiliran diselesaikan dengan cara penalaan halus, mod Bert adalah lebih baik daripada mod GPT jika gesaan sifar/sedikit pukulan digunakan, ini Jika mod ini menyelesaikan tugasan hiliran, kesan mod GPT adalah lebih baik daripada mod Bert. Ini menunjukkan bahawa model yang dihasilkan adalah lebih mudah untuk melakukan tugasan dalam mod gesaan sifar / beberapa syot, dan mod Bert mempunyai kelemahan semula jadi dalam melakukan tugasan dengan cara ini. Ini adalah sebab kedua. Tetapi inilah persoalannya: Mengapa kita mengejar pukulan sifar/beberapa pukulan menggesa untuk melakukan tugas? Untuk menerangkan masalah ini dengan jelas, pertama sekali kita perlu menjelaskan satu lagi soalan: Apakah jenis model LLM yang paling sesuai untuk kita? Gambar di atas menunjukkan rupa LLM yang ideal sepatutnya. Pertama, LLM harus mempunyai keupayaan pembelajaran bebas yang kukuh. Katakan kita memberi makan kepada semua jenis data seperti teks atau gambar yang terdapat di dunia, ia sepatutnya dapat mempelajari semua mata pengetahuan yang terkandung di dalamnya secara automatik Proses pembelajaran tidak memerlukan campur tangan manusia, dan ia sepatutnya dapat menggunakan pengetahuan yang telah dipelajari secara fleksibel, untuk menyelesaikan masalah praktikal. Kerana data adalah besar, untuk menyerap semua pengetahuan, banyak parameter model diperlukan untuk menyimpan pengetahuan, jadi model ini pasti akan menjadi model gergasi. Kedua, LLM sepatutnya dapat menyelesaikan masalah dalam mana-mana subbidang NLP, bukan hanya menyokong bidang terhad, malah ia sepatutnya dapat bertindak balas kepada masalah dalam bidang lain. bidang selain NLP, Lebih baik jika soalan dalam mana-mana bidang boleh dijawab dengan baik . Tambahan pula, apabila kita menggunakan LLM untuk menyelesaikan masalah dalam bidang tertentu, kita harus menggunakan ungkapan yang kita biasakan sebagai manusia, iaitu, LLM harus memahami perintah manusia. Ini mencerminkan membiarkan LLM menyesuaikan diri dengan orang, bukannya sebaliknya, membenarkan orang menyesuaikan diri dengan model LLM. Contoh biasa orang yang menyesuaikan diri dengan LLM sedang memerah otak mereka untuk mencuba pelbagai gesaan dalam usaha mencari gesaan yang baik yang boleh menyelesaikan masalah yang dihadapi. Mengenai perkara ini, rajah di atas memberikan beberapa contoh pada lapisan antara muka di mana manusia berinteraksi dengan LLM untuk menggambarkan apakah bentuk antara muka yang baik untuk orang ramai menggunakan model LLM. Selepas membaca LLM yang ideal ini, mari kita kembali dan terangkan baki soalan di atas: Mengapakah kita perlu mengejar pukulan sifar/beberapa pukulan yang menggesa untuk menyelesaikan tugasan? Terdapat dua sebab. Pertama, skala model LLM ini mestilah sangat besar, dan mesti terdapat sangat sedikit institusi yang mampu membuat model ini atau menukar parameter model ini . Penuntut tugas ialah beribu-ribu organisasi kecil dan sederhana atau malah individu Walaupun anda membuka sumber model, mereka tidak akan dapat menggunakan model, apatah lagi menggunakan mod Penalaan Halus untuk mengubah suai parameter model. Oleh itu, kita harus meneruskan cara untuk membenarkan penuntut tugas menyelesaikan tugas tanpa mengubahsuai parameter model, iaitu, mod gesaan harus digunakan untuk menyelesaikan tugas dan bukannya mod Penalaan Halus (boleh dilihat daripada ini bahawa arah teknikal gesaan lembut bertentangan dengan aliran pembangunan ini). Pembuat model menukar LLM menjadi perkhidmatan awam dan menjalankannya dalam mod LLM sebagai Perkhidmatan. Sebagai penyokong perkhidmatan, dengan mengambil kira keperluan pengguna yang sentiasa berubah, pengeluar model LLM mesti mengejar matlamat untuk membolehkan LLM menyelesaikan sebanyak mungkin jenis tugasan Ini adalah kesan sampingan, dan ia juga merupakan faktor realistik mengapa super model besar pasti akan mengejar AGI . Kedua, gesaan sifar, gesaan beberapa tembakan, atau gesaan rantaian pemikiran (CoT, Rantaian Pemikiran) yang menggalakkan keupayaan penaakulan LLM teknologi sedia ada dalam lapisan antara muka dalam gambar di atas . Secara khusus, niat asal dorongan sifar sebenarnya adalah antara muka yang ideal antara manusia dan LLM Ia secara langsung menggunakan kaedah ekspresi tugas yang biasa digunakan oleh manusia untuk membiarkan LLM melakukan sesuatu kesannya tidak baik. Selepas penyelidikan berterusan, kami mendapati bahawa untuk tugasan tertentu, jika kami memberikan LLM beberapa contoh dan menggunakan contoh ini untuk mewakili perihalan tugasan, kesannya akan lebih baik daripada gesaan sifar pukulan, jadi semua orang sedang mempelajari teknologi dorongan beberapa pukulan yang lebih baik. Dapat difahami bahawa kami pada asalnya berharap LLM dapat melaksanakan tugas tertentu menggunakan arahan yang biasa digunakan oleh manusia, tetapi teknologi semasa tidak dapat melakukannya, jadi kami memutuskan untuk perkara terbaik seterusnya dan menggunakan teknologi alternatif ini untuk menyatakan tugas manusia. keperluan. Jika anda memahami logik di atas, mudah untuk membuat kesimpulan berikut: few shot prompting (juga dikenali sebagai In Context Learning) hanyalah teknologi peralihan. Jika kita boleh menerangkan tugasan secara lebih semula jadi dan LLM boleh memahaminya, maka kita pasti akan meninggalkan teknologi peralihan ini tanpa teragak-agak Sebabnya jelas bahawa menggunakan kaedah ini untuk menggambarkan keperluan tugasan adalah tidak selaras dengan penggunaan manusia. Inilah sebabnya saya menyenaraikan GPT 3.0+Prompting sebagai teknologi peralihan Kemunculan ChatGPT telah mengubah status quo ini, menggantikan Prompting dengan Instruct, sekali gus membawa anjakan paradigma baharu dalam teknologi. dengan beberapa kesan seterusnya. Impak 1: Antara muka interaktif baharu yang menyesuaikan LLM kepada orang Dalam konteks LLM yang ideal, mari lihat ChatGPT untuk lebih memahami sumbangan teknikalnya. ChatGPT harus menjadi kaedah teknikal yang paling hampir dengan LLM yang ideal antara semua teknologi sedia ada. Jika saya boleh meringkaskan ciri ChatGPT yang paling cemerlang, saya akan menggunakan lapan perkataan berikut: "Berkuasa dan bertimbang rasa". “Berkuasa” Ini, saya percaya, sepatutnya dikaitkan terutamanya dengan LLM GPT3.5, asas yang berasaskan ChatGPT. Kerana walaupun ChatGPT telah menambah data berlabel secara manual, ia hanya dalam puluhan ribu Berbanding dengan ratusan bilion data peringkat token yang digunakan untuk melatih model GPT 3.5, jumlah data ini mengandungi kurang pengetahuan dunia (fakta yang terkandung dalam. data). dan akal sehat) boleh digambarkan sebagai penurunan di lautan, hampir boleh diabaikan, dan pada dasarnya tidak akan memainkan sebarang peranan dalam meningkatkan keupayaan asas GPT 3.5. Oleh itu, fungsi berkuasanya sepatutnya datang daripada GPT 3.5 yang tersembunyi di belakangnya. GPT 3.5 menanda aras model gergasi antara model LLM yang ideal. Jadi, adakah ChatGPT menyuntik pengetahuan baharu ke dalam model GPT 3.5? Ia harus disuntik. Ilmu ini terkandung dalam puluhan ribu data yang dilabel secara manual, tetapi yang disuntik bukanlah pengetahuan dunia, tetapi pengetahuan keutamaan manusia. Apa yang dipanggil "keutamaan manusia" mempunyai beberapa makna: Pertama, ia adalah cara biasa bagi manusia untuk menyatakan tugas. Sebagai contoh, orang biasa berkata: "Terjemahkan ayat berikut daripada bahasa Cina ke bahasa Inggeris" untuk menyatakan keperluan untuk "terjemahan mesin". Namun, LLM bukan manusia, jadi bagaimana ia boleh memahami maksud ayat ini? Anda perlu mencari cara untuk membuat LLM memahami maksud arahan ini dan melaksanakannya dengan betul. Oleh itu, ChatGPT menyuntik pengetahuan jenis ini ke dalam GPT 3.5 melalui anotasi data secara manual, menjadikannya lebih mudah untuk LLM memahami arahan manusia Ini adalah kunci kepada "empati". Kedua, manusia mempunyai piawaian sendiri untuk jawapan yang baik dan jawapan yang tidak baik Contohnya, jawapan yang lebih terperinci adalah baik, jawapan yang mengandungi diskriminasi adalah buruk, dan sebagainya. Ini adalah keutamaan manusia untuk kualiti jawapan. Data yang orang suapan kembali kepada LLM melalui Model Ganjaran mengandungi maklumat jenis ini. Secara keseluruhannya, ChatGPT menyuntik pengetahuan keutamaan manusia ke dalam GPT 3.5 untuk mendapatkan LLM yang memahami pertuturan manusia dan lebih sopan. Dapat dilihat bahawa sumbangan terbesar ChatGPT ialah ia pada dasarnya merealisasikan lapisan antara muka LLM yang ideal, membolehkan LLM menyesuaikan diri dengan ungkapan perintah kebiasaan orang, dan bukannya membenarkan orang ramai. untuk menyesuaikan diri dengannya. Dengan LLM, anda memerah otak anda untuk menghasilkan arahan yang boleh berfungsi (inilah yang dilakukan oleh teknologi segera sebelum teknologi arahan keluar), dan ini meningkatkan kemudahan penggunaan dan pengalaman pengguna LLM. Ia adalah InstructGPT/ChatGPT yang mula-mula menyedari masalah ini dan memberikan penyelesaian yang baik, yang juga merupakan sumbangan teknikal terbesarnya. Berbanding dengan beberapa gesaan tembakan sebelumnya, ia adalah teknologi antara muka manusia-komputer yang lebih sejajar dengan tabiat ekspresi manusia untuk orang ramai berinteraksi dengan LLM. Ini pastinya akan memberi inspirasi kepada model LLM seterusnya dan terus melakukan kerja lanjut pada antara muka mesin manusia yang mudah digunakan untuk menjadikan LLM lebih patuh. Impak 2: Banyak subbidang NLP tidak lagi mempunyai nilai penyelidikan bebas Dalam bidang NLP, anjakan paradigma ini bermakna bahawa banyak bidang penyelidikan NLP yang kini wujud secara bebas akan dimasukkan ke dalam sistem teknologi LLM, dan tidak lagi wujud secara bebas dan beransur-ansur hilang. Selepas anjakan paradigma pertama, walaupun banyak "tugas perantaraan" dalam NLP tidak lagi diperlukan untuk terus wujud sebagai bidang penyelidikan bebas, kebanyakan "tugas akhir" masih wujud sebagai bidang penyelidikan bebas, tetapi ditukar kepada "pra-latihan" . + rangka kerja penalaan halus, dalam menghadapi masalah unik di lapangan, rancangan penambahbaikan baharu telah dicadangkan satu demi satu. Penyelidikan semasa menunjukkan bahawa untuk banyak tugasan NLP, apabila saiz model LLM meningkat, prestasi akan bertambah baik dengan ketara. Berdasarkan ini, saya fikir inferens berikut boleh dibuat: Kebanyakan masalah yang dipanggil "unik" dalam bidang tertentu kemungkinan besar hanya penampilan luaran yang disebabkan oleh kekurangan pengetahuan domain selagi pengetahuan domain mencukupi , masalah yang dipanggil unik untuk bidang ini akan diselesaikan dengan baik. Malah, tidak perlu menumpukan perhatian kepada masalah bidang tertentu dan bekerja keras untuk menghasilkan penyelesaian khusus. Mungkin kebenaran tentang AGI adalah sangat mudah: anda hanya memberikan LLM lebih banyak data dalam medan dan biarkan ia mengetahui lebih lanjut sendiri. Dalam konteks ini, pada masa yang sama, ChatGPT membuktikan bahawa kami kini boleh terus mengejar model LLM yang ideal Kemudian, trend pembangunan teknologi masa depan harus: mengejar model LLM dengan skala yang lebih besar dan lebih besar, dengan meningkatkan The kepelbagaian data pra-latihan meliputi lebih banyak bidang LLM secara bebas mempelajari pengetahuan domain daripada data domain melalui proses pra-latihan Memandangkan skala model terus meningkat, banyak masalah diselesaikan. Tumpuan penyelidikan adalah tentang cara membina model LLM yang ideal ini, dan bukannya menyelesaikan masalah khusus dalam bidang tertentu. Dengan cara ini, semakin banyak subbidang NLP akan dimasukkan ke dalam sistem teknikal LLM dan beransur-ansur hilang. Saya berpendapat bahawa untuk menilai sama ada penyelidikan bebas dalam bidang tertentu perlu dihentikan serta-merta, kriteria penghakiman boleh menjadi salah satu daripada dua kaedah berikut: pertama, menilai tugas tertentu , sama ada kesan penyelidikan LLM melebihi prestasi manusia, tidak ada keperluan untuk penyelidikan bebas dalam bidang penyelidikan di mana kesan LLM melebihi prestasi manusia. Sebagai contoh, untuk banyak tugasan dalam set ujian GLUE dan SuperGLUE, kesan LLM pada masa ini melebihi prestasi manusia Malah, tidak ada keperluan untuk bidang penyelidikan yang berkait rapat dengan set data ini untuk terus wujud secara bebas. Kedua, bandingkan kesan tugasan dua mod Mod pertama adalah penalaan halus dengan data khusus domain yang lebih besar, dan mod kedua ialah kaedah berasaskan arahan atau arahan. Jika kesan kaedah kedua mencecah atau melebihi kaedah pertama, bermakna tidak ada keperluan untuk medan ini terus wujud secara bebas. Jika anda menggunakan standard ini, sebenarnya, dalam banyak bidang penyelidikan, kesan penalaan halus masih dominan (kerana jumlah data latihan yang besar dalam medan mod ini), dan nampaknya ia boleh wujud secara bebas. Walau bagaimanapun, memandangkan untuk banyak tugasan apabila saiz model meningkat, kesan gesaan beberapa tangkapan terus berkembang Dengan kemunculan model yang lebih besar, titik infleksi ini mungkin dapat dicapai dalam jangka pendek. Sekiranya spekulasi di atas adalah benar, ia bermakna fakta kejam berikut: Bagi ramai penyelidik dalam bidang NLP, mereka akan berhadapan dengan pilihan ke mana hendak pergi untuk menyelesaikan masalah yang unik di lapangan? Atau patutkah kita meninggalkan pendekatan yang kelihatan tidak menjanjikan ini dan sebaliknya membina LLM yang lebih baik? Jika kita memilih untuk beralih kepada pembinaan LLM, institusi manakah yang mempunyai keupayaan dan syarat untuk melakukannya? Apakah jawapan anda kepada soalan ini? Impak 3: Lebih banyak bidang penyelidikan selain NLP akan dimasukkan ke dalam sistem teknologi LLM Jika berdiri Dari perspektif AGI, merujuk kepada model LLM ideal yang diterangkan sebelum ini, tugasan yang boleh diselesaikan tidak seharusnya terhad kepada medan NLP, atau satu atau dua bidang subjek LLM yang ideal haruslah model kecerdasan buatan am yang bebas domain kini Pandai dalam satu atau dua bidang tidak bermakna anda hanya boleh melakukan tugasan ini. Kemunculan ChatGPT membuktikan bahawa adalah wajar untuk kita mengejar AGI dalam tempoh ini, dan kini adalah masa untuk mengenepikan belenggu pemikiran "disiplin medan". Selain menunjukkan keupayaan untuk menyelesaikan pelbagai tugasan NLP dalam format perbualan yang lancar, ChatGPT juga mempunyai keupayaan pengekodan yang kukuh. Semestinya semakin banyak bidang penyelidikan lain akan dimasukkan secara beransur-ansur dalam sistem LLM dan menjadi sebahagian daripada kecerdasan buatan am . LLM mengembangkan bidangnya daripada NLP, dan pilihan semula jadi ialah pemprosesan imej dan tugas berkaitan pelbagai mod. Sudah terdapat beberapa usaha untuk menyepadukan multimodaliti dan menjadikan LLM sebagai antara muka manusia-mesin universal yang menyokong input dan output berbilang mod Contoh biasa termasuk DeepMind's Flamingo dan "Model Bahasa ialah Antara Muka Tujuan Umum", seperti yang ditunjukkan di atas pendekatan ditunjukkan. Pertimbangan saya ialah sama ada imej atau pelbagai mod, penyepaduan masa hadapan ke dalam LLM untuk menjadi fungsi berguna mungkin lebih perlahan daripada yang kita fikirkan. Sebab utama ialah walaupun bidang imej telah meniru pendekatan pra-latihan Bert dalam dua tahun yang lalu, ia cuba memperkenalkan pembelajaran penyeliaan kendiri untuk melepaskan keupayaan model untuk mempelajari pengetahuan secara bebas daripada data imej adalah "kontrastif pembelajaran" dan MAE. Ini adalah Dua laluan teknikal yang berbeza. Walau bagaimanapun, berdasarkan keputusan semasa, walaupun kemajuan teknologi yang hebat, nampaknya jalan ini masih belum disiapkan Ini ditunjukkan dalam penerapan model pra-latihan dalam bidang imej kepada tugas hiliran, yang membawa faedah yang jauh lebih sedikit daripada Bert. atau GPT Ia digunakan dengan ketara pada tugasan hiliran NLP. Oleh itu, model prapemprosesan imej masih perlu diterokai secara mendalam untuk membuka kunci potensi data imej, yang akan menangguhkan penyatuan mereka ke dalam model besar LLM. Sudah tentu, jika jalan ini dibuka satu hari nanti, terdapat kebarangkalian tinggi situasi semasa dalam bidang NLP akan berulang, iaitu pelbagai subbidang penyelidikan pemprosesan imej mungkin beransur-ansur hilang dan diintegrasikan ke dalam LLM berskala besar untuk menyelesaikan tugas terminal secara langsung. Selain imej dan pelbagai mod, jelas sekali bahawa bidang lain akan dimasukkan secara beransur-ansur dalam LLM yang ideal . Di atas adalah pemikiran peribadi saya mengenai anjakan paradigma Seterusnya, mari kita menyelesaikan kemajuan teknologi arus perdana model LLM selepas GPT 3.0 . Seperti yang ditunjukkan dalam model LLM yang ideal, teknologi berkaitan sebenarnya boleh dibahagikan kepada dua kategori utama, satu adalah tentang cara model LLM menyerap pengetahuan daripada data, dan juga termasuk kesan pertumbuhan saiz model terhadap keupayaan LLM untuk menyerap; pengetahuan; kategori kedua ialah antara muka Manusia-komputer tentang cara orang menggunakan keupayaan sedia ada LLM untuk menyelesaikan tugasan, termasuk mod Pembelajaran Dalam Konteks dan Arahan. Rangkaian Pemikiran (CoT), teknologi penaakulan LLM, pada asasnya tergolong dalam Pembelajaran Konteks Kerana ia lebih penting, saya akan membincangkannya secara berasingan. Daripada hasil penyelidikan semasa, Transformer ialah pengekstrak ciri yang cukup berkuasa dan tiada peningkatan khas diperlukan. Jadi apa yang Transformer belajar melalui proses pra-latihan? Bagaimanakah pengetahuan diakses? Bagaimana kita membetulkan pengetahuan yang salah? Bahagian ini menerangkan kemajuan penyelidikan dalam bidang ini. Jalan menuju ilmu: Apakah pengetahuan yang telah LLM pelajari LLM telah mempelajari banyak ilmu daripada massive free teks. Jika kita mengklasifikasikan secara kasar pengetahuan ini, ia boleh dibahagikan kepada dua kategori: pengetahuan bahasa dan pengetahuan dunia . Pengetahuan linguistik merujuk kepada leksikal, sebahagian daripada pertuturan, sintaksis, semantik dan pengetahuan lain yang membantu manusia atau mesin memahami bahasa semula jadi . Terdapat sejarah panjang penyelidikan tentang sama ada LLM boleh menangkap pengetahuan linguistik Sejak kemunculan Bert, penyelidikan yang berkaitan telah diteruskan, dan kesimpulan telah dibuat sangat awal sebab ia digunakan Selepas pra-latihan model, salah satu sebab yang paling penting ialah pelbagai tugasan bahasa semula jadi pemahaman bahasa telah mencapai peningkatan prestasi yang ketara. Selain itu, pelbagai kajian juga telah membuktikan bahawa pengetahuan bahasa cetek seperti morfologi, bahagian pertuturan, sintaksis dan pengetahuan lain disimpan dalam struktur peringkat rendah dan pertengahan Transformer, manakala pengetahuan bahasa abstrak seperti pengetahuan semantik tersebar secara meluas. dalam struktur peringkat pertengahan dan peringkat tinggi Transformer. Ilmu dunia merujuk kepada beberapa kejadian sebenar yang berlaku di dunia ini (Factual Knowledge), serta beberapa pengetahuan akal (Common Sense Knowledge ) . Sebagai contoh, "Biden ialah Presiden Amerika Syarikat semasa", "Biden ialah seorang Amerika", "Presiden Ukraine Zelensky bertemu dengan Presiden A.S. Biden", ini adalah pengetahuan fakta yang berkaitan dengan Biden dan "Orang mempunyai Dua mata" dan " Matahari terbit di timur" adalah ilmu akal. Terdapat banyak kajian tentang sama ada model LLM boleh mempelajari pengetahuan dunia, dan kesimpulannya agak konsisten: LLM memang menyerap sejumlah besar pengetahuan dunia daripada data latihan, dan pengetahuan jenis ini diedarkan terutamanya di lapisan tengah dan tinggi Transformer, terutamanya tertumpu di lapisan tengah. Selain itu, apabila kedalaman model Transformer meningkat, jumlah pengetahuan yang boleh dipelajari secara beransur-ansur meningkat secara eksponen (rujuk: BERTnesia: Menyiasat penangkapan dan melupakan pengetahuan dalam BERT). Malah, anda menganggap LLM sebagai graf pengetahuan tersirat yang dicerminkan dalam parameter model Jika anda memahaminya dengan cara ini, saya rasa tiada masalah sama sekali. “Bilakah Anda Memerlukan Berbilion Perkataan Data Pra-latihan?” Artikel ini mengkaji hubungan antara jumlah pengetahuan yang dipelajari oleh model pra-latihan dan amaun data latihan Jenis Bert Untuk model bahasa, anda boleh mempelajari pengetahuan linguistik seperti sintaks dan semantik dengan hanya 10 juta hingga 100 juta perkataan korpus, tetapi untuk mempelajari pengetahuan fakta, anda memerlukan lebih banyak data latihan. Kesimpulan ini sebenarnya dijangkakan, pengetahuan linguistik agak terhad dan statik, manakala pengetahuan fakta adalah besar dan dalam proses perubahan yang berterusan. Penyelidikan semasa telah membuktikan bahawa apabila jumlah data latihan meningkat, model pra-latihan menunjukkan prestasi yang lebih baik dalam pelbagai tugas hiliran, yang menunjukkan bahawa apa yang dipelajari daripada data latihan tambahan adalah terutamanya pengetahuan dunia. Tempat Memori: Bagaimana LLM menyimpan dan mendapatkan semula pengetahuan Seperti yang dapat dilihat dari atas, LLM sememangnya telah banyak belajar daripada data Bahasa dan pengetahuan dunia. Jadi, untuk sesuatu ilmu tertentu, di manakah LLM menyimpannya? Bagaimana ia diekstrak? Ini juga soalan yang menarik. Jelas sekali, pengetahuan mesti disimpan dalam parameter model Transformer. Berdasarkan struktur Transformer, parameter model terdiri daripada dua bahagian: bahagian multi-head attention (MHA) menyumbang kira-kira satu pertiga daripada jumlah parameter, dan dua pertiga daripada parameter tertumpu dalam struktur FFN. MHA digunakan terutamanya untuk mengira kekuatan korelasi antara perkataan atau pengetahuan dan mengintegrasikan maklumat global Ia lebih berkemungkinan untuk mewujudkan hubungan antara pengetahuan Besar kemungkinan mata pengetahuan tertentu tidak akan disimpan, jadi mudah untuk menyimpulkan badan pengetahuan daripada model LLM Ia disimpan dalam struktur FFN Transformer. Walau bagaimanapun, butiran kedudukan ini masih terlalu kasar, dan adalah mustahil untuk menjawab dengan baik bagaimana sesuatu pengetahuan tertentu disimpan dan diambil semula , seperti "China's The capital is Beijing" Pengetahuan ini dinyatakan sebagai triplet sebagai , dengan "is-capital-of" mewakili hubungan antara entiti. Di manakah pengetahuan ini disimpan dalam LLM? "Lapisan Suapan Ke Hadapan Transformer Adalah Kenangan Nilai-Kekunci" memberikan perspektif yang agak baru, yang menganggap FFN Transformer sebagai memori Nilai-Kekunci yang menyimpan sejumlah besar pengetahuan khusus. . Seperti yang ditunjukkan dalam rajah di atas (sebelah kiri rajah adalah rajah kertas asal, yang sebenarnya tidak mudah difahami, anda boleh melihat rajah kanan beranotasi untuk pemahaman yang lebih baik), lapisan pertama FFN adalah lebar MLP lapisan tersembunyi, iaitu lapisan Kekunci Lapisan kedua ialah lapisan tersembunyi sempit MLP dan merupakan lapisan Nilai. Lapisan input FFN sebenarnya ialah Pembenaman keluaran MHA yang sepadan dengan perkataan tertentu, iaitu Pembenaman yang mengintegrasikan konteks input yang berkaitan dengan keseluruhan ayat melalui Perhatian Sendiri, yang mewakili keseluruhan maklumat keseluruhan ayat input. Lapisan utama merekodkan sepasang maklumat . Contohnya, untuk nod Ia mungkin masih kedengaran rumit, jadi mari kita gunakan contoh yang melampau untuk menggambarkan. Kami menganggap bahawa nod Selain itu, artikel ini juga menunjukkan bahawa Transformer peringkat rendah bertindak balas kepada pola permukaan ayat, dan peringkat tinggi bertindak balas kepada pola semantik. FFN peringkat rendah menyimpan pengetahuan permukaan seperti leksikon dan sintaksis, dan lapisan tengah dan Tahap tinggi menyimpan pengetahuan konsep semantik dan fakta, yang konsisten dengan kesimpulan penyelidikan lain. Saya rasa menganggap FFN sebagai memori Nilai-Kunci mungkin bukan jawapan yang betul, tetapi ia mungkin tidak terlalu jauh daripada jawapan yang betul. Cecair Pembetulan Pengetahuan: Bagaimana untuk membetulkan pengetahuan yang disimpan dalam LLM Oleh kerana kita tahu dunia tertentu Pengetahuan adalah disimpan dalam parameter satu atau lebih nod FFN, yang secara semula jadi menimbulkan persoalan lain: Bolehkah kita membetulkan ralat atau pengetahuan lapuk yang disimpan dalam model LLM? Sebagai contoh, mengenai soalan: "Siapakah Perdana Menteri United Kingdom sekarang?" Memandangkan perubahan yang kerap berlaku dalam Perdana Menteri Britain dalam beberapa tahun kebelakangan ini, adakah anda fikir LLM lebih cenderung untuk mengeksport "Boris" atau "Sunak"? Jelas sekali akan terdapat lebih banyak data yang mengandungi "Boris" dalam data latihan Dalam kes ini, kemungkinan besar LLM akan memberikan jawapan yang salah, jadi kami perlu membetulkan pengetahuan lapuk yang disimpan dalam LLM. Jika diringkaskan, pada masa ini terdapat tiga kaedah berbeza untuk mengubah suai pengetahuan yang terkandung dalam LLM: Kategori pertama Kaedah membetulkan pengetahuan daripada sumber data latihan. "Ke Arah Menjejak Pengetahuan Fakta dalam Model Bahasa Kembali ke Data Latihan" Matlamat penyelidikan artikel ini ialah: untuk sesuatu pengetahuan tertentu, bolehkah kita mencari data latihan manakah yang menyebabkan LLM mempelajari ilmu ini? Jawapannya ialah ya, yang bermaksud bahawa kita boleh mengesan sumber data latihan yang sepadan dengan pengetahuan tertentu. Jika kami menggunakan teknologi ini, dengan mengandaikan kami ingin memadamkan sesuatu pengetahuan, kami boleh mencari sumber data yang sepadan dahulu, memadam sumber data, dan kemudian melatih semula keseluruhan model LLM Ini boleh mencapai tujuan memadamkan pengetahuan yang berkaitan dalam LLM. Tetapi ada masalah di sini Jika kita membetulkan sebahagian kecil pengetahuan, kita perlu melatih semula model, yang jelas terlalu mahal. Oleh itu, kaedah ini tidak mempunyai banyak prospek pembangunan. Ia mungkin lebih sesuai untuk pemadaman berskala besar satu kali bagi kategori data tertentu. Ia tidak sesuai untuk senario pembetulan pengetahuan biasa menjadi lebih sesuai untuk menghilangkan berat sebelah Tunggu kandungan toksik dikeluarkan. Kaedah jenis kedua ialah melakukan penalaan halus pada model LLM untuk membetulkan pengetahuan . Kaedah intuitif yang boleh difikirkan ialah: kita boleh membina data latihan berdasarkan pengetahuan baharu yang akan diubah suai, dan kemudian biarkan model LLM melakukan penalaan halus pada data latihan ini, sekali gus membimbing LLM mengingati pengetahuan baharu dan melupakan pengetahuan lama. Kaedah ini mudah dan intuitif, tetapi ia juga mempunyai beberapa masalah pertama sekali, ia akan membawa kepada masalah melupakan bencana, yang bermaksud selain melupakan ilmu yang sepatutnya dilupakan, ia juga melupakan ilmu yang tidak sepatutnya. dilupakan, mengakibatkan penurunan keberkesanan beberapa tugas hiliran selepas berbuat demikian. Di samping itu, kerana model LLM semasa adalah sangat besar, walaupun penalaan halus dilakukan dengan kerap, kos sebenarnya agak tinggi. Mereka yang berminat dengan kaedah ini boleh merujuk kepada "Mengubah Kenangan dalam Model Transformer". Satu lagi jenis kaedah secara langsung mengubah suai parameter model yang sepadan dengan pengetahuan tertentu dalam LLM untuk membetulkan pengetahuan . Katakan kita ingin menyemak semula pengetahuan lama kepada . Mula-mula, kami mencari cara untuk mencari nod FFN yang menyimpan pengetahuan lama dalam parameter model LLM, dan kemudian kami boleh melaraskan dan menukar parameter model yang sepadan secara paksa dalam FFN untuk menggantikan pengetahuan lama dengan pengetahuan baharu. Ia boleh dilihat bahawa kaedah ini melibatkan dua teknologi utama: pertama, bagaimana untuk mencari lokasi penyimpanan khusus sesuatu pengetahuan dalam ruang parameter LLM kedua, bagaimana untuk membetulkan parameter model untuk mencapai pembetulan pengetahuan lama kepada yang baru; pengetahuan. Untuk butiran tentang jenis teknologi ini, lihat "Mencari dan Mengedit Persatuan Fakta dalam GPT" dan "Memori Pengeditan Massa dalam Transformer". Memahami proses penyemakan pengetahuan LLM ini sebenarnya sangat membantu untuk pemahaman yang lebih mendalam tentang mekanisme kerja dalaman LLM. Kami tahu bahawa dalam beberapa tahun kebelakangan ini, skala model LLM telah berkembang pesat Pada masa ini, skala parameter model LLM terbaik kebanyakannya Skala parameter melebihi 100 bilion (100B). Contohnya, saiz GPT 3 OpenAI ialah 175B, saiz LaMDA Google ialah 137B, saiz PaLM ialah 540B, saiz DeepMind's Gogher ialah 280B, dan sebagainya. Terdapat juga model gergasi China di China, seperti Zhiyuan GLM dengan skala 130B, Huawei "Pangu" dengan skala 200B, Baidu "Wenxin" dengan skala 260B, dan Inspur "Yuan 1.0" dengan skala 245B . Jadi, persoalan semula jadi ialah: apakah yang berlaku apabila saiz model LLM terus berkembang? Aplikasi model pra-latihan selalunya dibahagikan kepada dua peringkat: peringkat pra-latihan dan peringkat aplikasi senario khusus. Dalam peringkat pra-latihan, matlamat pengoptimuman adalah entropi silang Untuk model bahasa autoregresif seperti GPT, ia bergantung pada sama ada LLM meramalkan perkataan seterusnya dengan betul manakala dalam peringkat aplikasi senario, ia secara amnya bergantung pada penunjuk penilaian tertentu senario. Intuisi umum kami ialah jika prestasi model LLM dalam fasa pra-latihan adalah lebih baik, keupayaannya untuk menyelesaikan tugas hiliran secara semula jadi akan menjadi lebih kuat. Walau bagaimanapun, ini tidak sepenuhnya benar. Penyelidikan sedia ada telah membuktikan bahawa penunjuk pengoptimuman dalam peringkat pra-latihan memang menunjukkan korelasi positif dengan tugas hiliran, tetapi ia tidak sepenuhnya positif. Dalam erti kata lain, tidak cukup untuk hanya melihat penunjuk di peringkat pra-latihan untuk menilai sama ada model LLM cukup baik. Berdasarkan ini, kita akan melihat secara berasingan pada dua peringkat berbeza ini untuk melihat kesan yang akan berlaku apabila model LLM meningkat. Pertama, mari kita lihat apa yang berlaku apabila saiz model meningkat secara beransur-ansur semasa peringkat pra-latihan. OpenAI secara khusus mengkaji isu ini dalam "Undang-undang Penskalaan untuk Model Bahasa Neural" dan mencadangkan "undang-undang penskalaan" diikuti oleh model LLM. Seperti yang ditunjukkan dalam rajah di atas, kajian ini membuktikan: Apabila kita secara bebas meningkatkan jumlah data latihan, saiz parameter model atau melanjutkan masa latihan model (seperti dari 1 Epoch hingga 2 Epoch), pra -model terlatih menunjukkan prestasi yang lebih baik pada set ujian The Loss akan berkurangan secara monoton, yang bermaksud bahawa kesan model semakin baik dan lebih baik. Memandangkan ketiga-tiga faktor adalah penting, apabila kita benar-benar melakukan pra-latihan, kita mempunyai masalah membuat keputusan tentang cara memperuntukkan kuasa pengkomputeran: Anggapkan jumlah belanjawan kuasa pengkomputeran yang digunakan untuk kereta api LLM (Contohnya, berapa jam GPU atau hari GPU) Memandangkan, patutkah kita meningkatkan jumlah data dan mengurangkan parameter model? Atau adakah jumlah data dan saiz model perlu meningkat pada masa yang sama, mengurangkan bilangan langkah latihan? Apabila skala satu faktor meningkat, skala faktor lain mesti dikurangkan untuk memastikan jumlah kuasa pengkomputeran tidak berubah, jadi terdapat pelbagai kemungkinan pelan peruntukan kuasa pengkomputeran. Akhirnya, OpenAI memilih untuk meningkatkan jumlah data latihan dan parameter model pada masa yang sama, tetapi menggunakan strategi berhenti awal untuk mengurangkan bilangan langkah latihan. Kerana ia membuktikan bahawa: untuk dua elemen kelantangan data latihan dan parameter model, jika anda hanya meningkatkan satu daripadanya secara berasingan, ini bukanlah pilihan terbaik untuk meningkatkan kedua-duanya pada masa yang sama mengikut perkadaran tertentu kesimpulannya adalah untuk memberi keutamaan kepada peningkatan model, dan kemudian jumlah data latihan. Dengan mengandaikan bahawa jumlah belanjawan kuasa pengkomputeran untuk latihan LLM meningkat sebanyak 10 kali, jumlah parameter model harus ditingkatkan sebanyak 5.5 kali dan jumlah data latihan perlu ditingkatkan sebanyak 1.8 kali pada masa ini, kesan model adalah yang terbaik. Kajian oleh DeepMind (Rujukan: Training Compute-Optimal Large Language Models) meneroka isu ini dengan lebih mendalam kesimpulan asasnya adalah serupa dengan OpenAI Sebagai contoh, ia sememangnya perlu untuk meningkatkan Jumlah data latihan dan parameter model akan meningkatkan kesan model. Banyak model besar tidak menganggap perkara ini semasa melakukan pra-latihan Banyak model LLM besar hanya meningkatkan parameter model secara monoton sambil menetapkan jumlah data latihan Pendekatan ini sebenarnya salah dan mengehadkan potensi model LLM. Walau bagaimanapun, ia membetulkan hubungan berkadar antara kedua-duanya dan percaya bahawa jumlah data latihan dan parameter model adalah sama pentingnya, dengan mengandaikan bahawa jumlah belanjawan kuasa pengkomputeran yang digunakan untuk melatih LLM meningkat sebanyak 10 kali, jumlah parameter model. perlu ditingkatkan sebanyak 3.3 kali , 3.3 kali ganda jumlah data latihan, supaya model mempunyai kesan terbaik. Ini bermakna: Meningkatkan jumlah data latihan adalah lebih penting daripada yang kami fikirkan sebelum ini. Berdasarkan pemahaman ini, DeepMind memilih konfigurasi lain dari segi peruntukan kuasa pengkomputeran semasa mereka bentuk model Chinchilla: berbanding dengan model Gopher dengan volum data 300B dan volum parameter model 280B, Chinchilla memilih untuk meningkatkan data latihan sebanyak 4 kali ganda. , tetapi mengurangkan model Parameter dikurangkan kepada satu perempat daripada Gopher, iaitu kira-kira 70B. Walau bagaimanapun, tanpa mengira penunjuk pra-latihan atau banyak penunjuk tugas hiliran, Chinchilla adalah lebih baik daripada Gopher yang lebih besar. Ini membawa kita pencerahan berikut: Kita boleh memilih untuk membesarkan data latihan dan mengurangkan parameter model LLM dalam perkadaran yang sama, untuk mencapai premis tidak mengurangkan kesan model Untuk mengurangkan saiz model. Mengurangkan saiz model mempunyai banyak faedah, seperti kelajuan inferens akan menjadi lebih cepat apabila digunakan Ini sudah pasti laluan pembangunan LLM yang menjanjikan. Di atas ialah kesan skala model dari peringkat pra-latihan Dari perspektif kesan LLM dalam menyelesaikan tugasan hiliran tertentu, apabila skala model meningkat, pelbagai jenis. tugas mempunyai prestasi yang berbeza, khususnya, terdapat tiga jenis situasi berikut. Jenis tugasan pertama dengan sempurna merangkumi undang-undang penskalaan model LLM, yang bermaksud bahawa sebagai skala model secara beransur-ansur meningkat, tugas Prestasi semakin baik dan lebih baik , seperti yang ditunjukkan dalam (a) di atas. Tugasan sedemikian biasanya mempunyai ciri umum berikut: ia selalunya merupakan tugasan yang berintensifkan pengetahuan, yang bermaksud bahawa lebih banyak pengetahuan yang terkandung dalam model LLM, lebih baik prestasi tugasan tersebut. Banyak kajian telah membuktikan bahawa lebih besar model LLM, lebih tinggi kecekapan pembelajaran Maksudnya, untuk jumlah data latihan yang sama, lebih besar model, lebih baik kesan tugasan Ini menunjukkan bahawa walaupun berhadapan dengan yang sama kumpulan data latihan, model LLM yang lebih besar secara relatifnya lebih cekap Model yang lebih kecil dari mana lebih banyak pengetahuan dipelajari. Lebih-lebih lagi, dalam keadaan biasa, apabila meningkatkan parameter model LLM, jumlah data latihan selalunya akan meningkat secara serentak, yang bermaksud model besar boleh mempelajari lebih banyak mata pengetahuan daripada lebih banyak data. Kajian-kajian ini dapat menjelaskan dengan baik angka di atas, mengapa apabila saiz model meningkat, tugas berintensif pengetahuan ini menjadi lebih baik dan lebih baik. Kebanyakan tugas pemahaman bahasa semula jadi tradisional sebenarnya adalah tugasan yang berintensifkan pengetahuan, dan banyak tugas telah mencapai peningkatan yang hebat dalam tempoh dua tahun yang lalu, malah mengatasi prestasi manusia. Jelas sekali, ini berkemungkinan besar disebabkan oleh peningkatan dalam skala model LLM, dan bukannya disebabkan oleh peningkatan teknikal tertentu. Jenis tugasan kedua menunjukkan bahawa LLM mempunyai beberapa "Keupayaan Muncul", seperti yang ditunjukkan dalam (b) di atas. Apa yang dipanggil "keupayaan muncul" bermakna apabila skala parameter model gagal mencapai ambang tertentu, model pada asasnya tidak mempunyai sebarang keupayaan untuk menyelesaikan tugasan tersebut, yang mencerminkan bahawa prestasinya adalah bersamaan dengan memilih jawapan secara rawak skala model menjangkau Sebaik sahaja ambang melebihi, kesan model LLM pada tugasan tersebut akan mengalami peningkatan prestasi secara mendadak. Dalam erti kata lain, saiz model ialah kunci untuk membuka kunci (membuka kunci) keupayaan baharu LLM Apabila saiz model menjadi lebih besar dan lebih besar, semakin banyak keupayaan baharu LLM akan dibuka kuncinya secara beransur-ansur. Ini adalah fenomena yang sangat ajaib, kerana ia bermakna kemungkinan berikut yang membuat orang optimis tentang masa depan: Mungkin banyak tugas tidak dapat diselesaikan dengan baik oleh LLM pada masa ini Walaupun dari perspektif kami pada masa ini, LLM tidak mempunyai penyelesaian sama sekali keupayaan untuk menyelesaikan tugasan sedemikian, tetapi kerana LLM mempunyai "keupayaan muncul", jika kita terus menolak model besar, keupayaan ini mungkin akan dibuka secara tiba-tiba suatu hari nanti. Pertumbuhan model LLM akan membawa kita hadiah yang tidak dijangka dan indah. "Melebihi Permainan Tiruan: Mengukur dan mengekstrapolasi keupayaan model bahasa" Artikel ini menunjukkan bahawa jenis tugasan yang mencerminkan "keupayaan muncul" juga mempunyai beberapa persamaan: tugasan ini adalah umumnya dilakukan oleh Ia terdiri daripada beberapa langkah Untuk menyelesaikan tugasan ini, selalunya perlu untuk menyelesaikan beberapa langkah perantaraan terlebih dahulu, dan keupayaan penaakulan logik memainkan peranan penting dalam penyelesaian akhir tugasan tersebut. Rangkaian Anjuran Pemikiran ialah teknologi tipikal yang mempertingkatkan keupayaan penaakulan LLM dan boleh meningkatkan prestasi tugasan sedemikian dengan ketara Teknologi CoT akan diterangkan dalam bahagian berikut dan tidak akan dibincangkan di sini. Persoalannya, mengapa LLM mempunyai fenomena "kemampuan timbul" ini? Artikel di atas dan "Keupayaan Muncul Model Bahasa Besar" memberikan beberapa penjelasan yang mungkin: Satu penjelasan yang mungkin ialah penunjuk penilaian beberapa tugasan tidak cukup lancar. Sebagai contoh, sesetengah piawaian penghakiman untuk tugas penjanaan memerlukan output rentetan oleh model mesti sepadan sepenuhnya dengan jawapan standard untuk dianggap betul, jika tidak, ia akan mendapat 0 mata. Oleh itu, walaupun model meningkat, kesannya secara beransur-ansur menjadi lebih baik, yang dicerminkan dalam output serpihan aksara yang lebih betul Namun, kerana ia tidak betul sepenuhnya, 0 mata akan diberikan hanya apabila model itu cukup besar, Skor keluaran dijaringkan jika semua segmen adalah betul. Dalam erti kata lain, kerana penunjuk tidak cukup lancar, ia tidak dapat mencerminkan realiti bahawa LLM sebenarnya secara beransur-ansur meningkatkan prestasi tugasan Ia seolah-olah menjadi manifestasi luaran "keupayaan muncul". Penjelasan lain yang mungkin ialah beberapa tugasan terdiri daripada beberapa langkah perantaraan Apabila saiz model bertambah, keupayaan untuk menyelesaikan setiap langkah meningkat secara beransur-ansur, tetapi selagi ada satu Jika langkah perantaraan salah, jawapan akhir akan salah, yang juga akan membawa kepada fenomena "keupayaan muncul" yang cetek ini. Sudah tentu, penjelasan di atas masih menjadi tekaan untuk mengapa LLM mempunyai fenomena ini, kajian yang lebih mendalam dan lebih mendalam diperlukan. Terdapat juga sebilangan kecil tugasan apabila skala model meningkat, kesannya lengkung tugasan akan dipaparkan ciri berbentuk U : Apabila skala model meningkat secara beransur-ansur, kesan tugasan secara beransur-ansur menjadi lebih teruk, tetapi apabila skala model terus meningkat, kesannya mula menjadi lebih baik dan lebih baik, menunjukkan trend pertumbuhan berbentuk U, seperti yang ditunjukkan dalam rajah di atas Trend penunjuk model PaLM merah jambu pada dua tugasan ditunjukkan. Mengapakah tugasan ini kelihatan begitu istimewa? "Penskalaan songsang boleh menjadi berbentuk U" Artikel ini memberikan penjelasan: Tugasan ini sebenarnya mengandungi dua jenis subtugas yang berbeza, satu ialah tugas sebenar dan satu lagi ialah "tugas gangguan (tugas pengalih perhatian)". Apabila saiz model kecil, ia tidak dapat mengenal pasti sebarang sub-tugas, jadi prestasi model adalah serupa dengan memilih jawapan secara rawak Apabila model berkembang kepada saiz sederhana, ia terutamanya melaksanakan tugas gangguan, jadi ia mempunyai kesan negatif prestasi tugas sebenar ini dicerminkan dalam penurunan kesan tugasan sebenar Apabila saiz model ditingkatkan lagi, LLM boleh mengabaikan tugas yang mengganggu dan melaksanakan tugas sebenar, yang dicerminkan dalam kesan yang mula berkembang. Bagi tugasan yang prestasinya merosot apabila saiz model meningkat, jika Rangkaian Pemikiran (CoT) Prompting digunakan, prestasi beberapa tugasan akan ditukar mengikut undang-undang Penskalaan, iaitu saiz model Lebih besar kesannya, lebih baik, manakala tugas lain bertukar kepada lengkung pertumbuhan berbentuk U. Ini sebenarnya menunjukkan bahawa jenis tugasan ini sepatutnya merupakan tugas jenis penaakulan, jadi prestasi tugasan akan berubah secara kualitatif selepas menambah CoT. Secara amnya, teknologi antara muka yang sering kita sebutkan antara orang dan LLM termasuk: gesaan sifar, beberapa pukulan menggesa , Dalam Pembelajaran Konteks, dan Arahan. Ini sebenarnya adalah cara untuk menerangkan tugas tertentu. Tetapi jika anda melihat kesusasteraan, anda akan mendapati bahawa nama-nama itu agak mengelirukan. Antaranya, Instruct ialah kaedah antara muka ChatGPT, yang bermaksud orang memberi penerangan tentang tugasan dalam bahasa semula jadi, seperti "Terjemahkan ayat ini daripada bahasa Cina ke bahasa Inggeris", sesuatu macam ni. Saya faham bahawa gesaan sifar pukulan sebenarnya adalah nama awal Arahan semasa Pada masa lalu, orang biasa memanggilnya pukulan sifar, tetapi kini ramai orang memanggilnya Arahan. Walaupun ia mempunyai konotasi yang sama, terdapat dua kaedah khusus. Pada hari-hari awal, orang melakukan gesaan sifar pada hakikatnya, mereka tidak tahu bagaimana untuk menyatakan tugas, jadi mereka menukar perkataan atau ayat yang berbeza dan berulang kali cuba untuk menyatakan tugasan ini dengan baik data taburan sebenarnya tidak bermakna. Pendekatan semasa Arahan adalah untuk memberikan pernyataan arahan dan cuba membuat LLM memahaminya. Jadi, walaupun semuanya adalah ungkapan tugas di permukaan, ideanya berbeza. Dan Pembelajaran Dalam Konteks mempunyai maksud yang sama dengan beberapa pukulan gesaan, iaitu memberikan LLM beberapa contoh sebagai templat, dan kemudian biarkan LLM menyelesaikan masalah baharu. Saya secara peribadi berpendapat bahawa Pembelajaran Dalam Konteks juga boleh difahami sebagai penerangan tugas tertentu, tetapi Arahan ialah kaedah penerangan abstrak, dan Pembelajaran Dalam Konteks ialah kaedah contoh ilustrasi . Sudah tentu, memandangkan istilah ini digunakan pada masa ini agak mengelirukan, pemahaman di atas hanya mewakili pendapat peribadi saya. Jadi di sini kami hanya memperkenalkan Dalam Pembelajaran dan Arahan Konteks, dan tidak lagi menyebut pukulan sifar dan beberapa pukulan. Misteri Dalam Pembelajaran Konteks Jika anda memikirkannya dengan teliti, anda akan mendapati bahawa Pembelajaran Dalam Konteks ialah teknologi yang sangat ajaib. Apa yang ajaib tentangnya? Keajaibannya ialah apabila anda memberikan LLM beberapa contoh contoh Penalaan Halus dan Pembelajaran Dalam Konteks kedua-duanya nampaknya memberikan beberapa contoh untuk LLM, tetapi terdapat perbezaan kualitatif antara mereka . Perbezaannya (rujuk rajah di atas): Penalaan halus menggunakan contoh ini sebagai data latihan dan menggunakan perambatan belakang untuk mengubah suai parameter model LLM Tindakan mengubahsuai parameter model sememangnya mencerminkan proses pembelajaran LLM daripada contoh ini. Walau bagaimanapun, Dalam Pembelajaran Konteks hanya mengambil contoh untuk LLM lihat, dan tidak menggunakan perambatan belakang untuk mengubah suai parameter model LLM berdasarkan contoh, dan memintanya untuk meramalkan contoh baharu. Memandangkan parameter model tidak diubah suai, ini bermakna nampaknya LLM tidak melalui proses pembelajaran Jika ia tidak melalui proses pembelajaran, maka mengapa ia boleh meramalkan contoh baru hanya dengan melihatnya? Inilah keajaiban Pembelajaran Dalam Konteks. Adakah ini mengingatkan anda tentang lirik: "Hanya kerana saya melihat anda sekali lagi di khalayak ramai, saya tidak dapat melupakan wajah anda lagi Lagu itu dipanggil "Legend". Adakah anda mengatakan ia legenda atau tidak? Nampaknya In Context Learning tidak belajar ilmu daripada contoh Sebenarnya, adakah LLM belajar dengan cara yang pelik? Atau adakah benar ia tidak belajar apa-apa? Jawapan kepada soalan ini masih menjadi misteri yang belum terungkai. Beberapa kajian sedia ada mempunyai pendapat yang berbeza dan sangat pelbagai sehingga sukar untuk menilai mana yang benar. Berikut adalah beberapa pendapat semasa Mengenai siapa yang betul dan siapa yang salah, anda hanya boleh membuat keputusan sendiri. Sudah tentu, saya fikir mengejar kebenaran di sebalik fenomena ajaib ini adalah topik penyelidikan yang baik. Karya yang cuba menunjukkan bahawa Pembelajaran Dalam Konteks tidak belajar daripada contoh ialah “Memikirkan Semula Peranan Demonstrasi: Apa yang Membuatkan Pembelajaran Dalam Konteks Berfungsi?”. Ia mendapati bahawa: dalam contoh contoh Apa yang benar-benar memberi impak yang lebih besar pada Pembelajaran Konteks ialah: pengedaran Ringkasnya, kerja ini membuktikan bahawa In Context Learning tidak mempelajari fungsi pemetaan, tetapi pengagihan input dan output adalah sangat penting, dan kedua-dua ini tidak boleh diubah secara rawak. Sesetengah kerja percaya bahawa LLM masih mempelajari fungsi pemetaan ini Secara keseluruhannya, ini masih misteri yang belum terungkai. Pemahaman Arahan Ajaib Kita boleh menganggap Arahan sebagai pernyataan tugasan yang mudah difahami oleh manusia. Di bawah premis ini, penyelidikan semasa mengenai Arahan boleh dibahagikan kepada dua jenis: Arahan iaitu penyelidikan yang lebih akademik, dan Arahan yang menerangkan keperluan sebenar manusia. Mari kita lihat jenis pertama dahulu: Penyelidikan akademik Arahkan. Tema penyelidikan terasnya ialah keupayaan generalisasi model LLM untuk memahami Arahan dalam senario berbilang tugas . Seperti yang ditunjukkan dalam model FLAN dalam rajah di atas, iaitu, terdapat banyak tugasan NLP Untuk setiap tugasan, penyelidik membina satu atau lebih templat Prompt sebagai Arahan tugas, dan kemudian menggunakan contoh latihan untuk memperhalusi. model LLM supaya LLM boleh mempelajari pelbagai tugasan pada masa yang sama. Selepas melatih model, berikan model LLM Arahan tugas baharu yang tidak pernah dilihatnya sebelum ini, dan kemudian biarkan LLM menyelesaikan tugasan sifar itu sama ada tugas itu diselesaikan dengan cukup baik boleh digunakan untuk menilai sama ada model LLM mempunyai kebolehan generalisasi untuk memahami Arahan. Jika anda meringkaskan kesimpulan penyelidikan semasa (sila rujuk "Scaling Instruction-Fine-tala Models"/"Super-NaturalArahan: Generalisasi melalui Arahan Deklaratif pada 1600+ Tugasan NLP") , Faktor yang berkesan boleh meningkatkan keupayaan generalisasi model LLM Arahan termasuk: meningkatkan bilangan tugasan berbilang tugas, meningkatkan saiz model LLM, menyediakan CoT Prompting dan meningkatkan kepelbagaian tugas. Jika mana-mana langkah ini diambil, pemahaman Arahan model LLM boleh ditingkatkan. Yang kedua ialah Arahan berdasarkan keperluan manusia sebenar Jenis penyelidikan ini diwakili oleh InstructGPT dan ChatGPT . Jenis kerja ini juga berdasarkan pelbagai tugas, tetapi perbezaan terbesar daripada kerja berorientasikan penyelidikan akademik ialah ia berorientasikan kepada keperluan sebenar pengguna manusia. Kenapa awak cakap macam tu? Oleh kerana gesaan perihalan tugasan yang mereka gunakan untuk latihan berbilang tugas LLM diambil contoh daripada permintaan sebenar yang dikemukakan oleh sebilangan besar pengguna, bukannya membetulkan skop tugasan penyelidikan dan kemudian membenarkan penyelidik menulis gesaan perihalan tugasan. Apa yang dipanggil "keperluan sebenar" di sini dicerminkan dalam dua aspek: pertama, kerana ia dipilih secara rawak daripada huraian tugas yang dikemukakan oleh pengguna, jenis tugasan yang diliputi lebih pelbagai dan lebih sesuai dengan keperluan sebenar pengguna; , tertentu Perihalan segera tugasan diserahkan oleh pengguna dan menggambarkan perkara yang akan dikatakan oleh pengguna biasa apabila menyatakan keperluan tugasan, bukan perkara yang anda fikirkan pengguna akan katakan. Jelas sekali, pengalaman pengguna model LLM yang dipertingkatkan oleh kerja seperti ini akan menjadi lebih baik. Dalam kertas InstructGPT, kaedah ini juga dibandingkan dengan kaedah berasaskan Arahan FLAN. Mula-mula, gunakan tugas, data dan templat Prompt yang disebut dalam FLAN untuk memperhalusi GPT3 untuk menghasilkan semula kaedah FLAN pada GPT 3, dan kemudian bandingkan dengan InstructGPT Oleh kerana model asas InstructGPT juga GPT3, hanya terdapat perbezaan data dan kaedah kedua-duanya adalah setanding, dan didapati bahawa kesan kaedah FLAN jauh di belakang InstructGPT. Jadi apa sebab disebaliknya? Selepas menganalisis data, kertas itu percaya bahawa kaedah FLAN melibatkan medan tugas yang agak sedikit dan merupakan subset medan yang terlibat dalam InstructGPT, jadi kesannya tidak baik. Dalam erti kata lain, tugas yang terlibat dalam kertas FLAN adalah tidak konsisten dengan keperluan sebenar pengguna, yang mengakibatkan keputusan yang tidak mencukupi dalam senario sebenar. Maksudnya kepada kami ialah penting untuk mengumpul keperluan sebenar daripada data pengguna. Kaitan antara Pembelajaran Dalam Konteks dan Arahan Jika kita menganggap bahawa Pembelajaran Dalam Konteks adalah konkrit dengan beberapa contoh Untuk menyatakan arahan tugas, Arahan ialah penerangan tugasan abstrak yang lebih sesuai dengan tabiat manusia. Jadi, persoalan semula jadi ialah: adakah terdapat hubungan antara mereka? Sebagai contoh, bolehkah kami memberikan LLM beberapa contoh khusus untuk menyelesaikan tugas tertentu dan biarkan LLM mencari arahan Arahan sepadan yang diterangkan dalam bahasa semula jadi? Pada masa ini terdapat kerja sporadis yang meneroka isu ini, saya rasa hala tuju ini mempunyai nilai penyelidikan yang hebat. Mari kita bercakap tentang jawapannya dahulu. Jawapannya ialah: Ya, LLM Boleh. "Model Bahasa Besar Adalah Jurutera Gesaan Peringkat Manusia" adalah kerja yang sangat menarik ke arah ini Seperti yang ditunjukkan dalam rajah di atas, untuk tugas tertentu, berikan beberapa contoh kepada LLM, biarkan LLM menjana arahan bahasa semula jadi yang boleh menerangkan tugasan itu. dan kemudian Ia kemudian menggunakan perihalan tugas yang dijana oleh LLM untuk menguji kesan tugasan. Model asas yang digunakannya ialah GPT 3 dan InstructGPT Selepas berkat teknologi ini, kesan Instruct yang dijana oleh LLM sangat bertambah baik berbanding GPT 3 dan InstructGPT yang tidak menggunakan teknologi ini, dan dalam beberapa tugas prestasi Superhuman. Ini menunjukkan bahawa terdapat kaitan dalaman yang misteri antara contoh tugasan konkrit dan huraian tugasan bahasa semula jadi. Adapun apa sebenarnya hubungan ini? Kami belum tahu apa-apa tentang perkara ini. Banyak kajian telah membuktikan bahawa LLM mempunyai keupayaan ingatan yang kuat untuk pengetahuan Namun, secara amnya kita tidak akan kerana a Seseorang itu dikatakan sangat pintar jika dia mempunyai daya ingatan yang kuat sama ada dia mempunyai kebolehan penaakulan yang kuat sering menjadi kriteria penting untuk kita menilai sama ada seseorang itu pintar. Begitu juga, jika kesan LLM adalah menakjubkan, keupayaan penaakulan yang kuat adalah perlu. Pada dasarnya, kebolehan menaakul ialah penggunaan menyeluruh dari banyak perkara pengetahuan yang relevan untuk memperoleh pengetahuan baharu atau kesimpulan baharu. Keupayaan penaakulan LLM telah menjadi salah satu bidang penyelidikan yang paling penting dan popular dalam LLM pada tahun lalu. Oleh itu, persoalan yang kami bimbangkan ialah: Adakah LLM mempunyai keupayaan penaakulan? Jika ya, adakah keupayaan penaakulannya cukup kuat ? Jawapan semasa kepada dua soalan ini nampaknya: Apabila skala model cukup besar, LLM sendiri mempunyai keupayaan penaakulan, dan pada masalah penaakulan mudah, LLM telah mencapai keupayaan yang sangat baik, tetapi penyelidikan yang lebih mendalam diperlukan tentang masalah penaakulan yang kompleks. Jika saya menyusun kerja berkaitan penaakulan LLM sedia ada, saya mengklasifikasikannya kepada dua kategori utama, mencerminkan idea teknikal yang berbeza untuk mengetik atau mempromosikan keupayaan penaakulan LLM: terdapat lebih banyak kajian dalam kategori pertama , boleh dirujuk secara kolektif sebagai kaedah berasaskan segera Idea teras adalah untuk merangsang keupayaan penaakulan LLM itu sendiri melalui gesaan yang sesuai atau sampel gesaan Google telah melakukan banyak kerja yang sangat berkesan ke arah ini. Jenis pendekatan kedua ialah memperkenalkan kod program semasa proses pra-latihan dan mengambil bahagian dalam pra-latihan bersama-sama dengan teks untuk meningkatkan lagi keupayaan penaakulan LLM Ini sepatutnya menjadi idea yang dilaksanakan oleh OpenAI. Sebagai contoh, ChatGPT pastinya mempunyai keupayaan penaakulan yang kuat, tetapi ia tidak memerlukan pengguna untuk memberikan beberapa contoh penaakulan Oleh itu, keupayaan penaakulan hebat ChatGPT berkemungkinan besar diperoleh daripada menggunakan kod untuk menyertai pra-latihan GPT 3.5. Arahan umum kedua-dua idea ini sebenarnya sangat berbeza: menggunakan kod untuk meningkatkan keupayaan penaakulan LLM, yang mencerminkan idea secara langsung meningkatkan keupayaan penaakulan LLM dengan meningkatkan kepelbagaian data latihan dan berdasarkan Kaedah Prompt, ia tidak mempromosikan keupayaan penaakulan LLM itu sendiri, tetapi merupakan kaedah teknikal yang membolehkan LLM menunjukkan keupayaan ini dengan lebih baik dalam proses menyelesaikan masalah. Ia boleh dilihat bahawa yang pertama (kaedah kod) merawat punca, manakala yang kedua merawat gejala. Sudah tentu, kedua-duanya sebenarnya saling melengkapi, tetapi dalam jangka panjang, punca utama adalah lebih penting. Kaedah berasaskan segera Terdapat banyak kerja di kawasan ini jika diringkaskan secara kasar dibahagikan kepada tiga laluan Teknikal. Idea pertama adalah untuk terus menambah gesaan penaakulan tambahan kepada masalah. Kaedah ini mudah dan mudah, tetapi berkesan dalam banyak bidang. Pendekatan ini dicadangkan oleh "Model bahasa besar adalah penaakulan sifar pukulan" dan juga dipanggil CoT pukulan sifar. Secara khusus, ia dibahagikan kepada dua peringkat (seperti yang ditunjukkan dalam rajah di atas). , Selepas soalan di peringkat pertama, sambung output proses penaakulan khusus oleh LLM, dan tambah Prompt="Oleh itu, jawapannya (angka Arab) ialah", pada masa itu LLM akan memberikan jawapannya. Operasi mudah sedemikian boleh meningkatkan keberkesanan LLM dalam pelbagai tugas penaakulan Sebagai contoh, pada ujian penaakulan matematik yang ditetapkan GSM8K, selepas menambah gesaan, ketepatan penaakulan meningkat secara langsung daripada 10.4% kepada 40.4%, yang ajaib. Mengapa LLM mempunyai keupayaan untuk menyenaraikan langkah penaakulan terperinci dan mengira jawapan dengan memberikan gesaan "Mari kita fikirkan langkah demi langkah"? Alasannya masih belum muktamad. Tekaan saya adalah: ia mungkin kerana terdapat sejumlah besar data jenis ini dalam data pra-latihan, yang bermula dengan "Mari kita fikirkan langkah demi langkah", diikuti dengan langkah penaakulan terperinci, dan akhirnya memberikan jawapan LLM mengingati corak ini semasa pra-latihan. Apabila kita memasukkan gesaan ini, LLM dirangsang untuk "mengingat" langkah-langkah terbitan contoh tertentu secara samar-samar, supaya kita boleh meniru contoh ini untuk melakukan penaakulan langkah dan memberikan jawapan. Sudah tentu, ini hanyalah kesimpulan saya yang tidak berasas Jika ini benar-benar berlaku, jika anda membaca amalan CoT standard yang diperkenalkan kemudian, anda akan mendapati bahawa Zero-shot CoT mungkin tidak berbeza daripada CoT standard pada dasarnya, kecuali CoT standard ialah. ditulis oleh manusia Contoh langkah, dan Zero-shot CoT berkemungkinan besar mengaktifkan beberapa contoh dalam ingatan yang mengandungi langkah penaakulan melalui gesaan, yang mungkin sangat berbeza. Adalah difahami sepenuhnya bahawa kesan CoT standard adalah lebih baik daripada kesan CoT Zero-Shot, kerana selepas semua, bergantung pada LLM untuk mengingati contoh, ketepatan tidak dianggarkan terlalu tinggi, dan ketepatan contoh yang diberikan secara buatan dijamin, jadi kesan CoT standard semula jadi akan menjadi lebih baik. Ini menggambarkan kebenaran, iaitu, LLM sendiri mempunyai kebolehan untuk menaakul, tetapi kami tidak mempunyai cara untuk merangsang keupayaannya Melalui gesaan yang sesuai, kedua-dua gesaan Langkah boleh melepaskan potensinya pada tahap tertentu. Di samping itu, bagi bahasa Cina, mungkin terdapat satu lagi peringatan emas, seperti "Idea penyelesaian masalah terperinci adalah seperti berikut", serupa dengan ini, kerana apabila korpus Cina menerangkan langkah-langkah penaakulan, ayat pengenalan dan "Mari kita berfikir langkah mengikut langkah" sering digunakan "Ia sepatutnya berbeza. Ini adalah kenyataan Barat yang jelas, dan ia sebenarnya perlu untuk meneroka peringatan emas ini dalam bahasa Cina. Idea kedua biasanya dipanggil rantaian pemikiran berasaskan contoh (CoT beberapa pukulan, Rantaian Pemikiran) Mendorong. Arah ini pada masa ini merupakan hala tuju utama penyelidikan inferens LLM, dan banyak kerja dilakukan untuk idea ini Kami secara ringkas memperkenalkan beberapa karya perwakilan dengan hasil yang ketara, yang pada asasnya boleh mewakili hala tuju pembangunan teknikal CoT. Idea utama CoT sebenarnya sangat mudah; untuk mengajar model LLM untuk belajar menaakul, beberapa contoh penaakulan yang ditulis secara manual diberikan -perincian langkah sebelum mendapat jawapan muktamad Langkah-langkah penaakulan dijelaskan dengan jelas, dan proses penaakulan terperinci yang ditulis secara manual ini ialah Prompting rantaian pemikiran Untuk contoh khusus, sila rujuk biru teks dalam gambar di atas. CoT bermaksud membiarkan model LLM memahami satu kebenaran; iaitu, dalam proses penaakulan, jangan mengambil langkah yang terlalu besar, jika tidak, mudah untuk membuat kesilapan, mengubah masalah besar kepada masalah kecil, langkah demi langkah , kumpulkan kemenangan kecil menjadi kemenangan besar. Artikel terawal yang dengan jelas mencadangkan konsep CoT ialah "Rantai pemikiran mendorong penaakulan dalam model bahasa besar". selepas menggunakan CoT GSM8K Ketepatan set ujian penaakulan matematik telah meningkat kepada kira-kira 60.1%. Sudah tentu, idea untuk memberikan langkah-langkah penaakulan terperinci dan proses perantaraan ini tidak pertama kali dicadangkan oleh CoT Teknologi "pad calar" yang terdahulu (lihat: Tunjukkan Kerja Anda: Pad Conteng untuk Pengiraan Pertengahan dengan Model Bahasa) mula-mula menggunakan idea yang serupa. Tidak lama selepas CoT dicadangkan, pada 22 Mac, satu projek yang dipanggil "Self-Consistency" teknologi penambahbaikan telah meningkatkan ketepatan set ujian GSM8K kepada 74.4%. Idea "Konsistensi Diri" juga sangat intuitif (rujuk gambar di atas): pertama, anda boleh menggunakan CoT untuk memberikan beberapa contoh proses penaakulan bertulis, dan kemudian meminta LLM untuk membuat alasan tentang masalah yang diberikan ialah CoT, secara langsung mengeluarkan Proses inferens dan menjawab, keseluruhan proses telah berakhir. "Ketekalan Diri" tidak begitu. Ia memerlukan LLM untuk mengeluarkan pelbagai proses penaakulan dan jawapan, dan kemudian menggunakan undian untuk memilih jawapan yang terbaik. Idea ini sangat mudah dan langsung, tetapi kesannya sangat bagus. "Ketekalan Diri" sebenarnya mengajar LLM untuk mempelajari kebenaran ini: Kong Yiji pernah berkata bahawa terdapat empat cara untuk menulis perkataan "adas" untuk kacang adas Begitu juga, terdapat banyak penyelesaian yang betul untuk masalah matematik, setiap satu dengan yang berbeza derivasi. Proses semuanya membawa kepada jawapan akhir. Semua jalan menuju ke Rom Walaupun terdapat beberapa orang yang tersesat dan sampai ke Beijing, mereka yang tersesat hanyalah segelintir orang yang pergi, dan di situlah jawapan yang betul. Kaedah mudah selalunya mengandungi makna falsafah yang mendalam, bukankah itu benar? Selain itu, karya "On Advance of Making of Language Models Better Reasoners" menyepadukan lagi "berkembang daripada satu soalan Prompt kepada berbilang soalan Prompt, menyemak ketepatan langkah-langkah penaakulan pertengahan, dan undian berwajaran pada jawapan kepada berbilang output." Tiga penambahbaikan ini telah meningkatkan ketepatan ujian GSM8K yang ditetapkan kepada kira-kira 83%. Idea ketiga merangkumi idea algoritma divide-and-conquer . Sudah tentu, apa yang dipanggil "divide and conquer" ini adalah generalisasi saya, yang lain tidak berkata demikian. Idea teras idea ini ialah: untuk masalah penaakulan yang kompleks, kita menguraikannya kepada beberapa sub-masalah yang mudah diselesaikan Setelah menyelesaikan sub-masalah satu persatu, kita kemudian menyimpulkan jawapan kepada kompleks tersebut masalah daripada jawapan kepada sub-masalah. Anda lihat, ini sememangnya serupa dengan idea algoritma bahagi-dan-takluk. Saya secara peribadi merasakan bahawa pemikiran seperti ini mungkin cara yang sahih untuk mendedahkan intipati masalah dan akhirnya menyelesaikan masalah penaakulan kompleks LLM. Kami mengambil teknologi "Least-to-most prompting" sebagai contoh untuk menggambarkan pelaksanaan khusus idea ini, seperti yang ditunjukkan dalam rajah di atas: ia dibahagikan kepada dua peringkat Pada peringkat pertama, dari masalah asal kita boleh tahu akhir Apakah soalan yang perlu ditanya? Mari kita anggap bahawa masalah akhir ialah Q Akhir, dan kemudian isi templat Prompt dari masalah asal: "Jika saya ingin menyelesaikan masalah Q Akhir, maka saya perlu menyelesaikannya pertama", dan kemudian serahkan masalah asal dan Prompt ini kepada LLM, biarkan Model LLM memberikan jawapan, yang bersamaan dengan membiarkan LLM memberikan sub-soalan awalan Sub Q bagi soalan akhir; kemudian kita memasuki peringkat kedua, membiarkan LLM menjawab sub-soalan Sub Q yang baru diperoleh dan mendapatkan jawapan yang sepadan Kemudian soalan asal disambungkan ke dalam sub-soalan Sub Q dan jawapan yang sepadan, dan kemudian LLM ditanya soalan akhir Q. Pada masa ini, LLM akan memberikan jawapan muktamad. Dengan cara ini, ia merangkumi idea untuk membongkar sub-soalan dan secara beransur-ansur mencari jawapan akhir daripada jawapan kepada sub-soalan. Pralatihan kod meningkatkan keupayaan penaakulan LLM Di atas ialah tiga kaedah arus perdana menggunakan gesaan untuk merangsang keupayaan penaakulan model LLM , dan tentang LLM Fenomena menarik dan membingungkan telah diperhatikan setakat ini: Selain teks, jika kod program boleh ditambah untuk menyertai pra-latihan model, keupayaan penaakulan model LLM boleh menjadi sangat tinggi. dipertingkatkan. Kesimpulan ini boleh dibuat daripada bahagian eksperimen banyak kertas kerja (sila rujuk: RANTAI PEMIKIRAN AUTOMATIK DALAM MODEL BAHASA BESAR/Mencabar tugas BIG-Bench dan sama ada rantaian pemikiran boleh menyelesaikannya dan bahagian kertas eksperimen lain ). Rajah di atas menunjukkan data eksperimen daripada kertas kerja "On the Advance of Making Language Models Better Reasoners" ”, antaranya GPT3 davinci ialah model GPT 3 standard, berdasarkan latihan teks biasa kod-davinci-002 (dirujuk sebagai Codex secara dalaman oleh OpenAI) ialah model yang dilatih pada kedua-dua data Kod dan NLP. Jika anda membandingkan kesan kedua-duanya, dapat dilihat bahawa tidak kira kaedah inferens mana yang digunakan, hanya bertukar daripada model pra-latihan teks tulen kepada model pra-latihan campuran teks dan Kod, keupayaan inferens model telah dipertingkatkan. pada hampir semua set data ujian. Sebagai contoh, kami mengambil kaedah "Konsistensi Diri" sebagai contoh , pada tahap model inferens khusus, kami tidak melakukan apa-apa selain menambah kod program tambahan sebagai tambahan kepada teks semasa pra-latihan. Selain fenomena ini, daripada data di atas, kita juga boleh membuat beberapa kesimpulan lain, seperti GPT 3, model pra-latihan teks tulen, yang sebenarnya mempunyai tahap yang agak besar. daripada keupayaan penaakulan , kecuali prestasi yang agak lemah dalam penaakulan matematik seperti GSM8K, prestasi set data penaakulan lain juga baik, dengan syarat anda perlu menggunakan kaedah yang sesuai untuk merangsang keupayaan yang dimilikinya untuk contoh lain, teks-; davinci-002, yang merupakan model yang menambah penalaan halus arahan berdasarkan kod-davinci-002 (langkah pertama dalam menambah model InstructGPT atau ChatGPT), mempunyai keupayaan penaakulan yang lebih lemah daripada Codex, tetapi kajian lain telah menunjukkan bahawa ia mempunyai Tugas pemprosesan bahasa semula jadi lebih kuat daripada Codex. Ini seolah-olah menunjukkan bahawa penambahan arahan penalaan halus akan merosakkan keupayaan penaakulan model LLM, tetapi ia akan meningkatkan keupayaan pemahaman bahasa semula jadi pada tahap tertentu. Kesimpulan ini sebenarnya sangat menarik dan boleh memberi inspirasi kepada pemikiran dan penerokaan selanjutnya. Jadi, persoalan biasa ialah: Mengapa model pra-latihan boleh memperoleh keupayaan penaakulan tambahan daripada pra-latihan kod? Punca sebenar pada masa ini tidak diketahui dan patut diterokai lebih lanjut. Saya rasa ini mungkin kerana latihan kod versi asal Codex (yang hanya menggunakan latihan kod, sila rujuk: Menilai Model Bahasa Besar yang Dilatih pada Kod) menjana kod daripada teks, dan kod itu sering mengandungi banyak komen teks, yang pada asasnya serupa dengan Model pra-latihan melakukan penjajaran pelbagai mod bagi dua jenis data. Data mesti mengandungi sebahagian besar kod, huraian dan anotasi masalah matematik atau logik Adalah jelas bahawa data penaakulan matematik atau logik ini membantu dalam menyelesaikan masalah penaakulan matematik hiliran. Pemikiran tentang keupayaan penaakulan LLM Di atas memperkenalkan idea teknikal arus perdana penaakulan LLM dan beberapa yang sedia ada Dalam kesimpulan, izinkan saya bercakap tentang pemikiran saya tentang teknologi penaakulan model LLM Kandungan berikut adalah kesimpulan peribadi semata-mata tanpa banyak bukti, jadi sila rujuk dengan berhati-hati. Pertimbangan saya ialah: Walaupun pada tahun lalu, teknologi telah mencapai kemajuan pesat dalam merangsang keupayaan penaakulan LLM, dan kemajuan teknikal yang hebat telah dicapai, perasaan keseluruhannya ialah kita mungkin berada di landasan yang betul. ke arah tuju, tetapi masih jauh lagi perjalanan sebelum mencapai sifat sebenar masalah, yang memerlukan pemikiran dan penerokaan yang lebih mendalam. Pertama sekali, saya bersetuju dengan idea utama algoritma bahagi dan takluk yang disebutkan di atas Untuk masalah penaakulan yang kompleks, kita harus memecahkannya kepada beberapa sub-masalah mudah, kerana untuk LLM , kebarangkalian untuk menjawab sub-masalah dengan betul adalah Jauh lebih besar, biarkan LLM menjawab sub-soalan satu demi satu, dan kemudian secara beransur-ansur memperoleh jawapan akhir. Diilhamkan oleh teknologi "Paling tidak menggesa", jika saya berfikir lebih jauh, saya fikir penaakulan LLM berkemungkinan menjadi salah satu daripada dua kemungkinan berikut: masalah penaakulan graf yang berinteraksi secara berterusan dengan LLM, atau masalah penaakulan graf yang berterusan berinteraksi dengan isu pelaksanaan carta alir Program LLM untuk berinteraksi dengan LLM. Mari kita bincangkan masalah penaakulan graf dahulu, seperti yang ditunjukkan dalam gambar di atas, dengan mengandaikan kita mempunyai cara untuk memecahkan masalah kompleks kepada sub -masalah atau sub-langkah Struktur graf struktur gelung adalah untuk mengulangi sub-langkah tertentu. Dengan mengandaikan bahawa kita boleh mendapatkan gambarajah pembongkaran sub-masalah yang disebutkan di atas, kita boleh membimbing LLM langkah demi langkah mengikut struktur graf mengikut hubungan kebergantungan, dan menjawab soalan kecil yang mesti dijawab terlebih dahulu sehingga jawapan akhir diperolehi . Mari kita bercakap tentang masalah carta alir program Merujuk kepada gambar di atas, andaikan kita mempunyai cara untuk memecahkan masalah kompleks kepada sub-. masalah atau sub-langkah dan menjana sub- Struktur yang terdiri daripada langkah-langkah yang serupa dengan carta alir program Dalam struktur ini, beberapa langkah akan dilaksanakan berulang kali beberapa kali (struktur gelung), dan pelaksanaan beberapa langkah memerlukan pertimbangan bersyarat (bersyarat. cawangan). Ringkasnya, berinteraksi dengan LLM apabila melaksanakan setiap sub-langkah, dapatkan jawapan kepada sub-langkah, dan kemudian teruskan melaksanakan mengikut proses sehingga jawapan akhir adalah output. Serupa dengan model ini. Dengan mengandaikan bahawa idea ini kira-kira betul, adalah mungkin untuk menjelaskan dari perspektif ini mengapa penambahan kod akan meningkatkan keupayaan penaakulan model pra-latihan: Kemungkinan besar model pra-latihan berbilang mod menggunakan kaedah tersirat seperti ini di dalam model Carta aliran program berfungsi sebagai jambatan antara dua modaliti, menghubungkan keduanya, iaitu, daripada penerangan teks kepada carta alir tersirat, dan kemudian pemetaan kepada kod khusus yang dihasilkan oleh carta alir. . Dalam erti kata lain, pra-latihan pelbagai mod seperti ini boleh meningkatkan keupayaan model LLM untuk membina carta alir tersirat daripada teks dan melaksanakannya mengikut carta alir, iaitu, ia mengukuhkan keupayaan penaakulannya. Sudah tentu, masalah terbesar dengan idea di atas ialah bagaimana kita boleh bergantung pada model LLM atau model lain untuk mendapatkan struktur graf atau struktur carta alir berdasarkan masalah yang diterangkan dalam teks? Ini mungkin kesukarannya. Satu idea yang mungkin adalah untuk terus mempertingkatkan teks dan kod berkualiti tinggi pra-latihan, dan mengguna pakai kaedah mempelajari secara tersirat struktur tersirat dalaman. Jika anda berfikir tentang teknologi CoT semasa berdasarkan idea di atas, anda boleh memahaminya dengan cara ini: CoT standard sebenarnya bergantung pada teks bahasa semula jadi untuk menerangkan struktur graf atau carta aliran program manakala teknologi "Paling tidak menggesa". Ia cuba menyimpulkan struktur graf berdasarkan nod graf terakhir dan bergantung pada inferens ke belakang Walau bagaimanapun, adalah jelas bahawa kaedah semasa mengehadkan kedalaman inferens ke belakangnya, yang bermaksud bahawa ia hanya boleh menyimpulkan struktur graf yang sangat mudah. Ini Itulah yang mengehadkan keupayaannya. Berikut ialah beberapa bidang penyelidikan LLM yang saya fikir secara peribadi adalah penting atau yang layak penerokaan mendalam Hala tuju penyelidikan. Meneroka siling skala model LLM Walaupun kami terus menolak skala model LLM, ini nampaknya mustahil Kandungan teknikal, tetapi sebenarnya perkara ini amat penting. Pada pertimbangan peribadi saya, sejak kemunculan Bert, kepada GPT 3, dan kemudian kepada ChatGPT, terdapat kebarangkalian yang tinggi bahawa sumbangan teras kejayaan teknologi utama yang mengagumkan ini datang daripada pertumbuhan saiz model LLM, dan bukannya teknologi tertentu. . Mungkin, kunci sebenar untuk membuka kunci AGI ialah: data berskala sangat besar dan cukup pelbagai, model berskala sangat besar dan proses latihan yang mencukupi . Tambahan pula, membuat model LLM berskala sangat besar memerlukan keupayaan pelaksanaan kejuruteraan yang sangat tinggi dari pasukan teknikal, dan tidak boleh dianggap bahawa perkara ini tidak mempunyai kandungan teknikal. Jadi apakah kepentingan penyelidikan untuk terus meningkatkan skala model LLM? Saya fikir terdapat dua aspek nilai. Pertama sekali, seperti yang dinyatakan di atas, kita tahu bahawa untuk tugas berintensif pengetahuan, apabila saiz model menjadi lebih besar, prestasi pelbagai tugas akan menjadi lebih baik dan lebih baik dan untuk pelbagai jenis penaakulan dan tugas yang sukar, dengan penambahan CoT Prompting Akhir sekali, kesannya juga menunjukkan kecenderungan untuk mengikut undang-undang Penskalaan. Jadi, persoalan biasa ialah: Untuk tugasan ini, sejauh manakah kesan skala LLM dapat menyelesaikan tugasan ini? Ini adalah soalan yang membimbangkan ramai orang, termasuk saya. Kedua, memandangkan "keupayaan muncul" ajaib LLM, jika kami terus meningkatkan saiz model, apakah keupayaan baharu yang akan dibuka yang tidak kami jangkakan? Ini juga soalan yang sangat menarik. Memandangkan dua perkara di atas, kita masih perlu terus meningkatkan saiz model untuk melihat di mana siling saiz model untuk menyelesaikan pelbagai tugas. Sudah tentu, perkara sebegini hanya boleh diperkatakan untuk 99.99% pengamal, tiada peluang atau keupayaan untuk melakukan ini. Untuk melakukan ini, terdapat keperluan yang sangat tinggi terhadap sumber kewangan dan kesanggupan pelaburan, keupayaan kejuruteraan, dan semangat teknikal institusi penyelidikan, dan semuanya amat diperlukan. Anggaran kasar bilangan institusi yang boleh melakukan ini adalah tidak lebih daripada 5 di luar negara dan tidak lebih daripada 3 di dalam negara. Sudah tentu, memandangkan isu kos, mungkin terdapat "model besar saham bersama" pada masa hadapan, yang merupakan fenomena di mana beberapa institusi berkebolehan bekerjasama dan bekerjasama untuk membina model super besar. Tingkatkan keupayaan penaakulan kompleks LLM Seperti yang diterangkan sebelum ini tentang keupayaan penaakulan LLM, walaupun LLM mempunyai sejak kebelakangan ini Keupayaan penaakulan telah bertambah baik sejak beberapa tahun kebelakangan ini, tetapi banyak kajian (rujukan: Batasan Model Bahasa dalam Aritmetik dan Induksi Simbolik/Model Bahasa Besar Masih Tidak Dapat Merancang) menunjukkan bahawa pada masa ini LLM boleh menyelesaikan masalah penaakulan dengan lebih baik. , selalunya Relatif mudah, keupayaan penaakulan kompleks LLM masih lemah Contohnya, walaupun untuk operasi penaakulan atau penambahan, penolakan, darab dan bahagi yang mudah, apabila rentetan atau nombor sangat panjang, keupayaan penaakulan LLM akan menurun dengan cepat , penaakulan yang kompleks seperti keupayaan merancang tingkah laku Keupayaan adalah sangat lemah. Secara keseluruhannya, mengukuhkan keupayaan penaakulan kompleks LLM harus menjadi salah satu aspek terpenting dalam penyelidikan masa depan tentang LLM. Seperti yang dinyatakan di atas, menambah kod dan pra-latihan ialah arah yang secara langsung meningkatkan keupayaan inferens LLM. Pada masa ini tidak mencukupi penyelidikan ke arah ini Ia lebih seperti ringkasan pengalaman praktikal, meneroka prinsip di belakangnya, dan kemudian memperkenalkan lebih banyak jenis data baharu selain kod untuk meningkatkan keupayaan penaakulan LLM lebih asas meningkatkan keupayaan penaakulan. LLM menggabungkan lebih banyak bidang penyelidikan lain selain NLP ChatGPT semasa bagus dalam tugas NLP dan Kod, kerana Pemain benih penting yang membawa kepada AGI adalah untuk menyepadukan imej, video, audio dan imej lain serta pelbagai mod ke dalam LLM, malah AI untuk Sains, kawalan robot dan bidang lain dengan perbezaan yang lebih jelas dimasukkan secara beransur-ansur dalam LLM, yang merupakan pintu masuk kepada LLM Satu-satunya cara untuk pergi dengan AGI. Hala tuju ini baru sahaja bermula, jadi ia mempunyai nilai penyelidikan yang tinggi. Antara muka interaktif yang lebih mudah digunakan untuk orang ramai dan LLM Seperti yang dinyatakan sebelum ini, sumbangan teknikal terbesar ChatGPT ada di sini. Tetapi adalah jelas bahawa teknologi semasa tidak sempurna, dan mesti terdapat banyak arahan yang tidak dapat difahami oleh LLM. Oleh itu, sepanjang arah ini, kami sedang mencari teknologi yang lebih baik untuk membolehkan manusia menggunakan ungkapan arahan terbiasa mereka sendiri, dan LLM boleh memahaminya. Ini adalah arah teknikal yang baharu dan sangat menjanjikan. Membina set data penilaian tugas komprehensif yang sukar Set data penilaian yang baik adalah untuk membimbing kemajuan berterusan bagi asas teknologi. Apabila model LLM meningkat secara beransur-ansur, prestasi tugas bertambah baik dengan cepat, menyebabkan banyak set ujian standard menjadi lapuk dengan cepat. Dalam erti kata lain, set data ini terlalu mudah berbanding dengan teknologi sedia ada Di bawah set ujian tanpa kesukaran, kita tidak tahu di mana kelemahan dan titik buta teknologi semasa. Oleh itu, membina set ujian yang sukar adalah kunci untuk mempromosikan kemajuan teknologi LLM. Pada masa ini, beberapa set ujian baharu akan muncul dalam industri, yang mewakili termasuk BIGBench, OPT-IML, dsb. Set ujian ini mencerminkan beberapa ciri, seperti menjadi lebih sukar daripada teknologi LLM sedia ada dan menyepadukan pelbagai jenis tugas. Diinspirasikan oleh ChatGPT, saya rasa pertimbangan lain harus disertakan: mencerminkan keperluan pengguna sebenar. Maksudnya, ekspresi tugasan ini benar-benar dimulakan oleh pengguna Hanya model LLM yang dibina dengan cara ini boleh menyelesaikan keperluan sebenar pengguna. Selain itu, saya percaya bahawa LLM akan cepat melimpahkan keupayaannya ke dalam bidang selain NLP, dan cara untuk memasukkan lebih banyak data penilaian daripada medan lain juga perlu dipertimbangkan terlebih dahulu. Kejuruteraan data berkualiti tinggi Untuk model pra-latihan, data adalah asasnya, dan pra- proses latihan boleh Memahami ialah proses mendapatkan pengetahuan daripada data. Oleh itu, kita perlu mengukuhkan lagi perlombongan, pengumpulan dan pembersihan data berkualiti tinggi. Mengenai data, terdapat dua aspek yang perlu dipertimbangkan: kualiti dan kuantiti data . Berdasarkan eksperimen perbandingan T5, kita boleh membuat kesimpulan bahawa antara dua faktor kuantiti dan kualiti, kualiti diutamakan, dan laluan yang betul adalah untuk meningkatkan saiz data sambil memastikan kualiti data. Kualiti data merangkumi pelbagai ukuran seperti kandungan maklumat data dan kepelbagaian data Contohnya, Wiki jelas sekali adalah data berkualiti tinggi dengan kepadatan pengetahuan yang sangat tinggi di dunia . Ini berdasarkan maklumat Dari segi kandungan, peningkatan kepelbagaian jenis data sudah pasti asas untuk merangsang pelbagai keupayaan baharu LLM Contohnya, menambah data daripada tapak web Soal Jawab akan membantu meningkatkan keupayaan QA LLM. Data yang pelbagai memberikan LLM keupayaan untuk menyelesaikan lebih banyak jenis tugasan yang berbeza dengan lebih baik, jadi ini mungkin kriteria paling kritikal dalam kualiti data. Mengenai jumlah data, pada dasarnya, semua data yang dikeluarkan secara terbuka di Internet boleh dimasukkan dalam proses pra-latihan model LLM. Jadi, di manakah hadnya? "Adakah kita akan kehabisan data? Analisis had penskalaan set data dalam Pembelajaran Mesin" menganggarkan ini dan membuat kesimpulan bahawa menjelang 2026, data NLP berkualiti tinggi akan digunakan dan data NLP berkualiti rendah akan habis menjelang 2030 . Dan ini bermakna: Sama ada kami mempunyai jenis sumber data baharu pada masa itu, atau kami perlu meningkatkan kecekapan model LLM dalam menggunakan data. Jika tidak, pendekatan terdorong data semasa untuk pengoptimuman model akan berhenti membuat kemajuan, atau faedah akan berkurangan. Sparsifikasi model LLM Transformer yang sangat besar Sebahagian besar model LLM terbesar yang diguna pakai Dengan jarang struktur, seperti GPT 3, PaLM, GLaM, dsb., GPT 4 kemungkinan besar akan mengikuti laluan model yang jarang. Faedah utama menggunakan model berasaskan Sparse ialah ia boleh mengurangkan masa latihan dan masa inferens dalam talian LLM dengan banyak. Kertas Transformer Suis menunjukkan bahawa di bawah premis bajet kuasa pengkomputeran yang sama, menggunakan Transformer jarang, kelajuan latihan model LLM boleh ditingkatkan sebanyak 4 hingga 7 kali ganda berbanding dengan Transformer Padat. Mengapakah model Jarang mempercepatkan masa latihan dan inferens? Ini kerana walaupun parameter model adalah besar, untuk contoh latihan tertentu, model Sparse hanya menggunakan sebahagian kecil daripada keseluruhan parameter melalui mekanisme penghalaan Bilangan parameter aktif yang terlibat dalam latihan dan inferens adalah agak kecil, begitu juga cepat. Saya berpendapat bahawa model LLM yang sangat besar pada masa hadapan berkemungkinan besar akan menumpu kepada model yang jarang. Terdapat dua sebab utama: Di satu pihak, penyelidikan sedia ada menunjukkan (Rujukan: Model Besar adalah Pelajar Parsimonious: Sparsity Pengaktifan dalam Transformer Terlatih) bahawa Transformer Padat standard itu sendiri juga jarang diaktifkan semasa latihan dan inferens, iaitu, hanya sebahagian daripada Parameter akan diaktifkan, dan kebanyakan parameter tidak mengambil bahagian dalam proses latihan dan inferens. Dalam kes ini, kita juga mungkin berhijrah terus ke model jarang di samping itu, tidak syak lagi bahawa skala model LLM akan terus meningkat, dan kos latihan yang tinggi merupakan halangan penting untuk mengembangkan lagi model model jarang boleh mengurangkan kos model yang sangat besar, jadi apabila saiz model menjadi lebih besar, faedah yang dibawa oleh model jarang menjadi lebih jelas. Memandangkan kedua-dua aspek ini, terdapat kebarangkalian yang tinggi bahawa model LLM yang lebih besar pada masa hadapan akan menggunakan penyelesaian model yang jarang. Jadi mengapa model berskala besar lain tidak mengikuti laluan model yang jarang pada masa ini? Oleh kerana model Sparse mempunyai masalah seperti latihan yang tidak stabil dan pemasangan yang mudah, ia tidak mudah untuk dilatih dengan baik. Oleh itu, cara membetulkan masalah yang dihadapi oleh model jarang dan mereka bentuk model jarang yang lebih mudah untuk dilatih adalah hala tuju penyelidikan masa depan yang penting. Jika anda ingin meniru model LLM dengan kesan yang menakjubkan seperti ChatGPT, berdasarkan pelbagai kesimpulan penyelidikan semasa, Apabila membuat pemilihan teknologi, anda perlu menumpukan perhatian untuk menimbang isu berikut: Pertama sekali, Dalam mod pra-latihan, kami mempunyai tiga pilihan: model bahasa autoregresif seperti GPT, model bahasa dwiarah Bert dan model hibrid T5 (seni bina Pengekod-Penyahkod, Pengekod menggunakan model bahasa dwiarah dan Penyahkod menggunakan model bahasa autoregresif, jadi ia adalah struktur hibrid, tetapi ia intipati masih Kepunyaan mod Bert). Kita harus memilih model bahasa autoregresif seperti GPT Sebabnya dianalisis dalam bahagian anjakan paradigma artikel ini. Pada masa ini, apabila LLM domestik membuat pemilihan teknologi di kawasan ini, nampaknya ramai daripada mereka mengambil laluan teknikal model bahasa dua arah Bert atau model bahasa hibrid T5 Berkemungkinan besar arahnya telah tersasar. Kedua, Keupayaan penaakulan yang kuat ialah asas psikologi yang penting untuk pengguna mengenali LLM , dan jika anda mahu LLM mempunyai keupayaan penaakulan yang kukuh, mengikut pengalaman semasa, sebaiknya perkenalkan sejumlah besar kod dan teks untuk melatih LLM bersama-sama semasa pra-latihan . Bagi rasionalnya, terdapat analisis yang sepadan dalam bahagian yang berkaitan dalam artikel ini. Ketiga, Jika anda mahu skala parameter model tidak begitu besar, tetapi masih mahu kesannya cukup baik, terdapat dua pilihan teknikal untuk dikonfigurasikan : atau Tingkatkan pengumpulan data berkualiti tinggi, perlombongan, pembersihan, dsb. , yang bermaksud bahawa parameter model saya boleh menjadi separuh daripada ChatGPT/GPT 4, tetapi untuk mencapai kesan yang sama, jumlah latihan berkualiti tinggi data adalah Ia perlu dua kali ganda saiz model ChatGPT/GPT 4 (pendekatan Chinchilla Laluan lain yang boleh mengurangkan saiz model dengan berkesan adalah dengan mengambil model perolehan teks (Retrieval based) + Laluan LLM , ini juga boleh mengurangkan skala parameter model LLM dengan ketara sambil mengekalkan kesan yang sama. Kedua-dua pilihan teknologi ini tidak saling eksklusif, tetapi saling melengkapi Dalam erti kata lain, kedua-dua teknologi ini boleh digunakan pada masa yang sama untuk mencapai kesan yang serupa dengan model super besar pada premis bahawa saiz model agak kecil. Keempat, disebabkan oleh skala model yang besar, kos latihan model super besar adalah terlalu tinggi, menyebabkan beberapa institusi mempunyai keupayaan untuk melakukan ini. Dan daripada analisis di atas, dapat dilihat bahawa terus mengembangkan skala model LLM adalah sesuatu yang pasti akan berlaku dan harus dilakukan. Oleh itu, cara mengurangkan kos latihan LLM melalui cara teknikal adalah sangat penting. Jarang pengekstrak ciri LLM ialah pilihan teknikal yang boleh mengurangkan kos latihan dan inferens model dengan berkesan. Ini berikutan bahawa apabila model semakin besar, model LLM yang jarang digunakan adalah pilihan yang harus dipertimbangkan. Kelima, ChatGPT pada masa ini ialah penyelesaian teknikal yang paling hampir dengan LLM yang ideal, dan LLM yang ideal harus berdasarkan model besar universal asas yang hampir mahakuasa untuk menyokong pelbagai Pelbagai jenis tugas peringkat atas . Pada masa ini, menyokong lebih banyak jenis tugasan dicapai terutamanya dengan meningkatkan kepelbagaian data pra-latihan LLM Lebih baik kepelbagaian data, lebih kaya jenis tugas yang boleh disokong oleh LLM. Oleh itu, harus memberi perhatian kepada idea menambah keupayaan baharu LLM dengan meningkatkan kepelbagaian data . Keenam, antara muka operasi mesin manusia yang mudah digunakan. Manusia menggunakan ungkapan adat mereka sendiri untuk menerangkan tugas, dan LLM perlu dapat memahami maksud sebenar Arahan ini. Di samping itu, perlu diingatkan juga bahawa Arahan ini adalah selaras dengan keperluan manusia sebenar, iaitu penerangan tugas mesti dikumpulkan daripada pengguna akhir, dan bukannya bergantung kepada imaginasi atau tekaan pembangun itu sendiri. Inspirasi terbesar bagi saya daripada ChatGPT sebenarnya adalah sama ada untuk menggunakan pembelajaran pengukuhan, saya rasa ia tidak penting untuk melakukan perkara yang serupa . Mengapa OpenAI membuat ChatGPT dan bukan organisasi lain? Kita boleh buat analisis mudah di sini. Pada permulaan artikel ini, kami menyebut falsafah OpenAI tentang LLM. Apakah pendapat OpenAI tentang LLM? Mengimbas kembali teknologi yang telah diperkenalkan secara berterusan, dapat dilihat bahawa sebenarnya bermula dari GPT 1.0, ia pada dasarnya menganggap LLM sebagai satu-satunya cara untuk AGI . Secara khusus, di mata OpenAI, AGI masa depan sepatutnya kelihatan seperti ini: terdapat LLM super-besar bebas tugas yang digunakan untuk mempelajari pelbagai pengetahuan daripada data besar-besaran ini menjana segala-galanya untuk menyelesaikan pelbagai masalah praktikal dapat memahami perintah manusia supaya dapat digunakan oleh manusia. Sebenarnya, pemahaman konsep pembangunan LLM pada separuh pertama adalah untuk "membina LLM yang bebas tugas, sangat besar dan membiarkannya mempelajari pelbagai pengetahuan daripada data besar-besaran Ini adalah persetujuan hampir semua orang dan boleh mencerminkan visi sebenar OpenAI Ini separuh masa kedua. Konsep OpenAI agak maju, kedudukan kendirinya telah ditetapkan agak tinggi dari awal, dan ia sentiasa meneroka sama ada kaedah di atas boleh mencapai AGI. Sebab OpenAI boleh membuat ChatGPT adalah kerana ia mempunyai kedudukan yang agak tinggi dan bebas daripada gangguan luar serta mempunyai sikap yang tidak berbelah bahagi. Kita boleh menyemak beberapa langkah utama yang telah diambil: GPT 1.0 mengikuti laluan model bahasa autoregresif untuk menjana corak, yang dikeluarkan lebih awal daripada Bert. Bert membuktikan bahawa model bahasa dua hala berprestasi lebih baik daripada model bahasa sehala autoregresif untuk banyak tugas pemahaman NLP. Walaupun begitu, GPT 2.0 tidak beralih ke laluan model bahasa dua hala Ia masih mengikut laluan penjanaan teks, dan mula mencuba gesaan sifar tangkapan dan gesaan beberapa tangkapan. Malah, pada masa ini, AGI dalam fikiran OpenAI telah mula muncul dan secara beransur-ansur menunjukkan garis besarnya. Hanya kerana kesan sifar pukulan/beberapa pukulan adalah jauh lebih teruk daripada Bert+penalaan halus, semua orang tidak mengambilnya terlalu serius, malah mereka tidak faham mengapa ia sentiasa mendesak laluan model bahasa sehala. Pada masa ini, saya menganggarkan bahawa OpenAI sendiri mungkin tidak dapat memastikan bahawa jalan ini pasti akan berfungsi. Namun, ini tidak menghalangnya daripada terus berjalan semula di jalan ini. GPT 3.0 telah menunjukkan keupayaan sifar pukulan/beberapa pukulan segera pada masa ini, AGI dalam fikiran OpenAI telah bocor sepenuhnya daripada air, dengan garis besar yang jelas, dan kesannya juga membuktikan bahawa laluan ini lebih cenderung untuk diikuti. . GPT 3.0 ialah persimpangan dan kawasan tadahan yang menentukan arah pembangunan LLM. Laluan lain yang sepadan dengannya ialah model "Bert+fine-tuning". Di persimpangan jalan ini, pengamal yang berbeza memilih untuk mengambil jalan yang berbeza, dan jurang teknikal mula melebar dari sini. Malangnya, ramai pengamal domestik memilih untuk terus mengundur ke arah "Bert+fine-tuning", yang juga merupakan titik masa penting yang menyebabkan keadaan mundur hari ini. Melangkah ke hadapan, terdapat InstructGPT dan ChatGPT OpenAI membuktikan sesuatu melalui ChatGPT walaupun kita mungkin masih jauh untuk pergi dari AGI sebenar, jalan ke AGI melalui LLM yang sangat besar, Nampaknya boleh dilaksanakan di sekejap. Arah aliran teratas: transformasi paradigma penyelidikan NLP
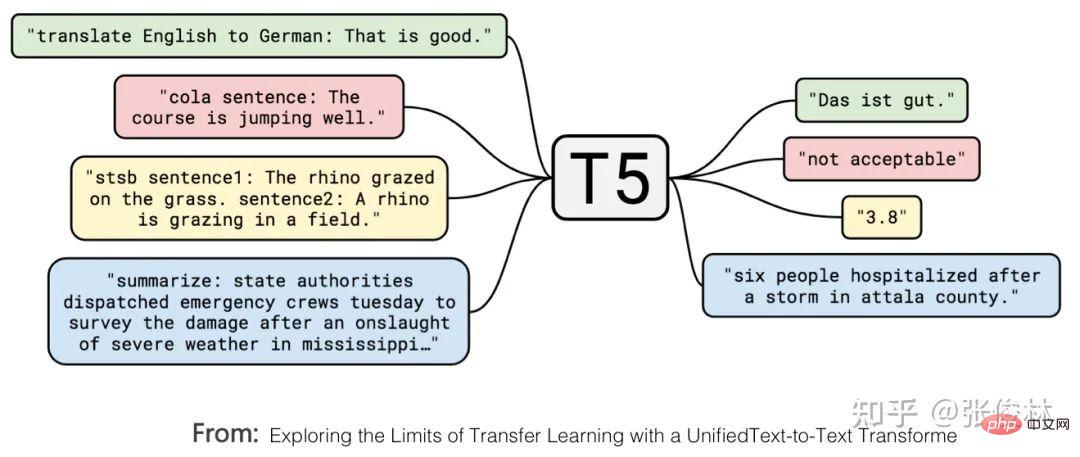
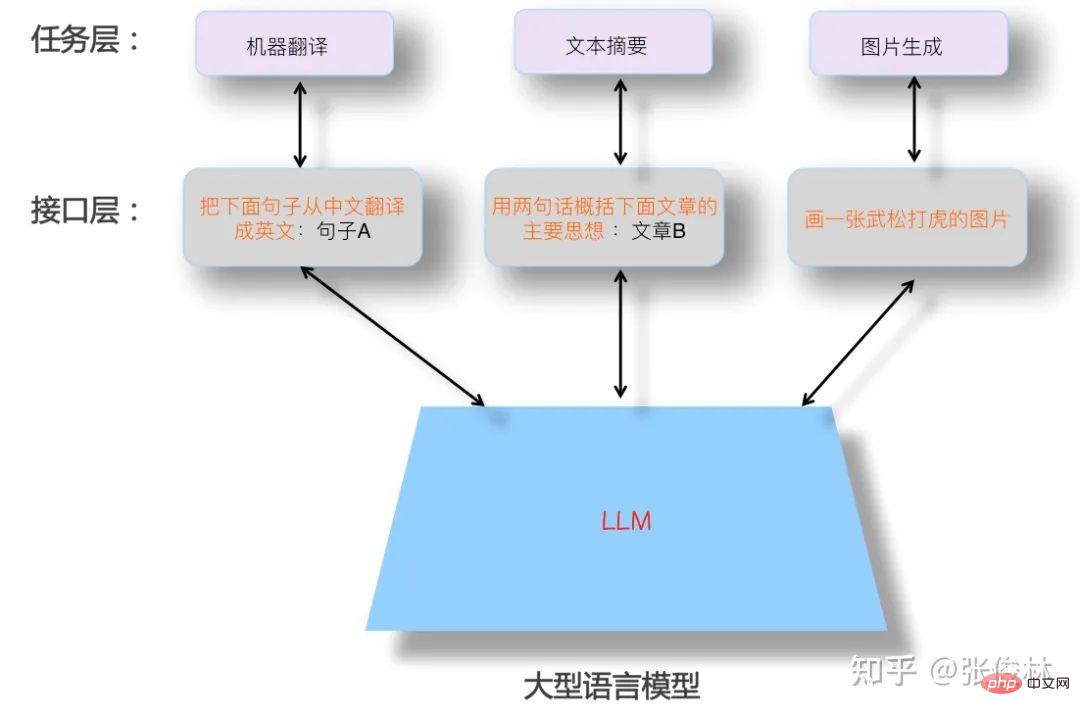
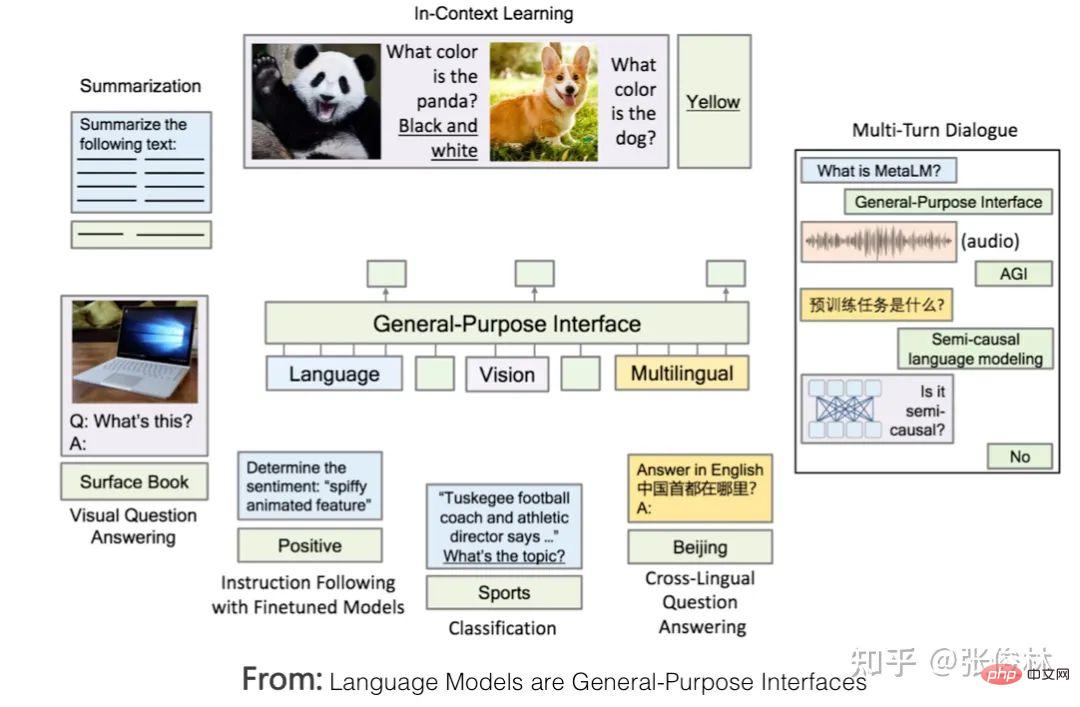
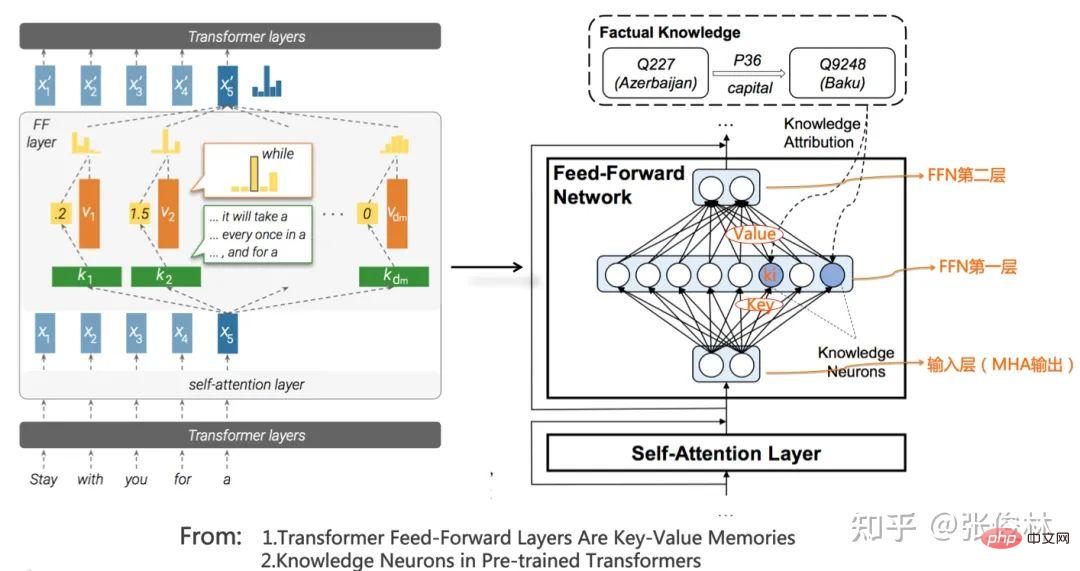

 dalam lapisan tersembunyi pertama FFN dalam rajah di atas, mungkin ia merekodkan pengetahuan. Vektor kunci yang sepadan dengan nod
dalam lapisan tersembunyi pertama FFN dalam rajah di atas, mungkin ia merekodkan pengetahuan. Vektor kunci yang sepadan dengan nod  sebenarnya merujuk kepada nod
sebenarnya merujuk kepada nod  dan vektor berat setiap nod lapisan input dan vektor Nilai yang sepadan merujuk kepada nod
dan vektor berat setiap nod lapisan input dan vektor Nilai yang sepadan merujuk kepada nod  dan Nilai kedua FFN lapisan Setiap nod dalam lapisan membentuk vektor berat sambungan. Vektor kunci setiap neuron digunakan untuk mengenal pasti bahasa atau corak pengetahuan tertentu dalam input. Ia adalah pengesan corak. Jika input mengandungi corak tertentu yang ingin dikesan, maka vektor input dan berat utama nod
dan Nilai kedua FFN lapisan Setiap nod dalam lapisan membentuk vektor berat sambungan. Vektor kunci setiap neuron digunakan untuk mengenal pasti bahasa atau corak pengetahuan tertentu dalam input. Ia adalah pengesan corak. Jika input mengandungi corak tertentu yang ingin dikesan, maka vektor input dan berat utama nod  melakukan pengiraan produk dalam vektor, ditambah dengan Relu, untuk membentuk tindak balas berangka besar
melakukan pengiraan produk dalam vektor, ditambah dengan Relu, untuk membentuk tindak balas berangka besar  , yang bermaksud bahawa
, yang bermaksud bahawa  telah mengesan mod ini, kemudian menyebarkan nilai tindak balas ini ke lapisan kedua FFN melalui vektor berat Nilai nod
telah mengesan mod ini, kemudian menyebarkan nilai tindak balas ini ke lapisan kedua FFN melalui vektor berat Nilai nod  . Ini bersamaan dengan menimbang nilai vektor Nilai dengan nilai tindak balas, dan kemudian menghantar dan mencerminkannya kepada output setiap nod lapisan Nilai kedua. Dengan cara ini, proses pengiraan perambatan hadapan FFN kelihatan seperti mengesan corak pengetahuan tertentu melalui Kunci, kemudian mengeluarkan Nilai yang sepadan dan mencerminkan Nilai pada output lapisan kedua FFN. Sudah tentu, setiap nod dalam lapisan kedua FFN akan mengumpul semua maklumat nod dalam lapisan Utama FFN, jadi ia adalah tindak balas bercampur, dan tindak balas bercampur semua nod dalam lapisan Nilai boleh ditafsirkan sebagai maklumat taburan kebarangkalian yang mewakili perkataan keluaran.
. Ini bersamaan dengan menimbang nilai vektor Nilai dengan nilai tindak balas, dan kemudian menghantar dan mencerminkannya kepada output setiap nod lapisan Nilai kedua. Dengan cara ini, proses pengiraan perambatan hadapan FFN kelihatan seperti mengesan corak pengetahuan tertentu melalui Kunci, kemudian mengeluarkan Nilai yang sepadan dan mencerminkan Nilai pada output lapisan kedua FFN. Sudah tentu, setiap nod dalam lapisan kedua FFN akan mengumpul semua maklumat nod dalam lapisan Utama FFN, jadi ia adalah tindak balas bercampur, dan tindak balas bercampur semua nod dalam lapisan Nilai boleh ditafsirkan sebagai maklumat taburan kebarangkalian yang mewakili perkataan keluaran.  dalam rajah di atas ialah memori Nilai-Kekunci yang merekodkan pengetahuan Vektor Kuncinya digunakan untuk mengesan corak pengetahuan "Ibu negara China ialah..." dan vektor Nilainya pada dasarnya disimpan. Vektor yang hampir dengan Pembenaman perkataan "Beijing". Apabila input Transformer ialah "Ibu kota China ialah [Mask]", nod
dalam rajah di atas ialah memori Nilai-Kekunci yang merekodkan pengetahuan Vektor Kuncinya digunakan untuk mengesan corak pengetahuan "Ibu negara China ialah..." dan vektor Nilainya pada dasarnya disimpan. Vektor yang hampir dengan Pembenaman perkataan "Beijing". Apabila input Transformer ialah "Ibu kota China ialah [Mask]", nod  mengesan corak pengetahuan ini daripada lapisan input, jadi ia menghasilkan output tindak balas yang lebih besar. Kami mengandaikan bahawa neuron lain dalam lapisan Kunci tidak mempunyai tindak balas kepada input ini, maka nod yang sepadan dalam lapisan Nilai sebenarnya hanya akan menerima perkataan pembenaman sepadan dengan Nilai "Beijing", dan melakukan pemprosesan melalui nilai tindak balas besar
mengesan corak pengetahuan ini daripada lapisan input, jadi ia menghasilkan output tindak balas yang lebih besar. Kami mengandaikan bahawa neuron lain dalam lapisan Kunci tidak mempunyai tindak balas kepada input ini, maka nod yang sepadan dalam lapisan Nilai sebenarnya hanya akan menerima perkataan pembenaman sepadan dengan Nilai "Beijing", dan melakukan pemprosesan melalui nilai tindak balas besar  Penguatan berangka selanjutnya. Oleh itu, output yang sepadan dengan kedudukan Mask secara semula jadi akan mengeluarkan perkataan "Beijing". Ia pada asasnya proses ini Ia kelihatan rumit, tetapi ia sebenarnya sangat mudah.
Penguatan berangka selanjutnya. Oleh itu, output yang sepadan dengan kedudukan Mask secara semula jadi akan mengeluarkan perkataan "Beijing". Ia pada asasnya proses ini Ia kelihatan rumit, tetapi ia sebenarnya sangat mudah. Kesan skala: Apa yang berlaku apabila LLM menjadi lebih besar dan lebih besar
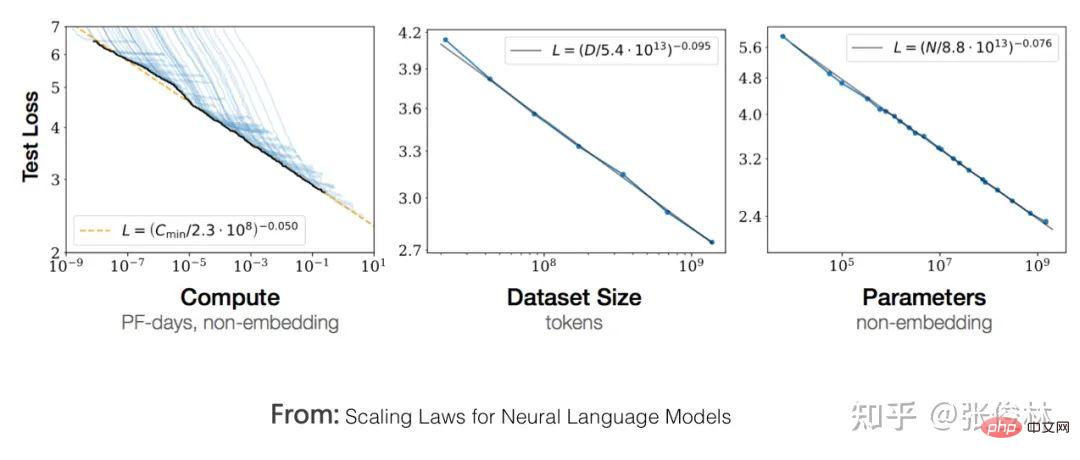
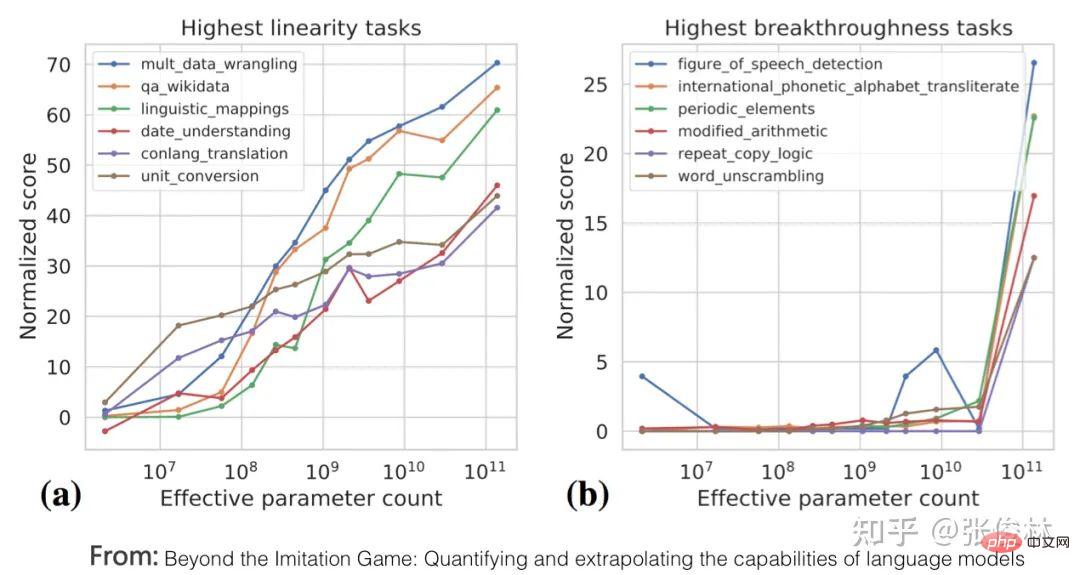
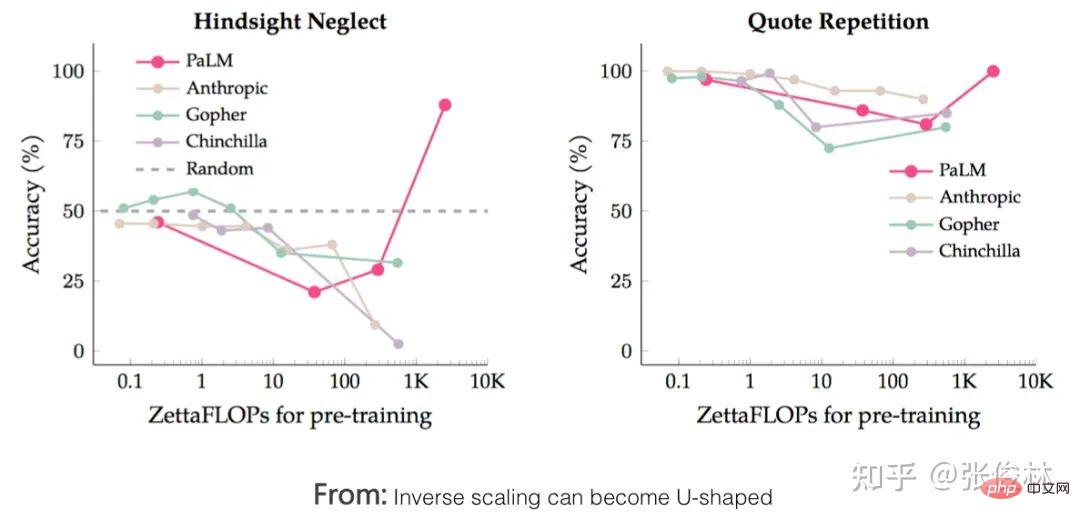
Antara Muka Manusia-Komputer: Dari Pembelajaran Dalam Konteks untuk Mengarahkan Pemahaman
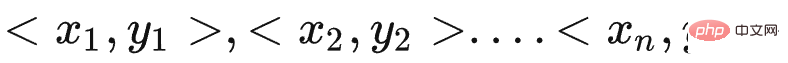 , dan kemudian memberikannya
, dan kemudian memberikannya  , LLM boleh berjaya meramalkan
, LLM boleh berjaya meramalkan  yang sepadan . Apabila anda mendengar ini, anda mungkin bertanya: Apa yang ajaib tentang ini? Bukankah itu cara penalaan halus berfungsi? Jika anda bertanya perkara ini, ini bermakna anda masih belum berfikir secara mendalam tentang isu ini.
yang sepadan . Apabila anda mendengar ini, anda mungkin bertanya: Apa yang ajaib tentang ini? Bukankah itu cara penalaan halus berfungsi? Jika anda bertanya perkara ini, ini bermakna anda masih belum berfikir secara mendalam tentang isu ini. 
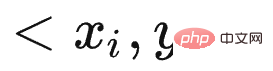 yang diberikan kepada LLM, sebenarnya tidak kira sama ada
yang diberikan kepada LLM, sebenarnya tidak kira sama ada  ialah jawapan yang betul untuk
ialah jawapan yang betul untuk  , jika kita menggantikan jawapan yang betul
, jika kita menggantikan jawapan yang betul  dengan jawapan rawak yang lain
dengan jawapan rawak yang lain  , ini tidak menjejaskan kesan Pembelajaran Dalam Konteks. Ini sekurang-kurangnya menggambarkan satu perkara: Dalam Pembelajaran Konteks tidak menyediakan LLM dengan maklumat fungsi pemetaan daripada
, ini tidak menjejaskan kesan Pembelajaran Dalam Konteks. Ini sekurang-kurangnya menggambarkan satu perkara: Dalam Pembelajaran Konteks tidak menyediakan LLM dengan maklumat fungsi pemetaan daripada  hingga
hingga  :
: 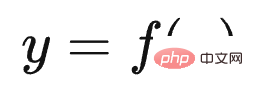 , sebaliknya, jika anda menukar label yang betul secara rawak, ia pasti akan mengganggu fungsi pemetaan
, sebaliknya, jika anda menukar label yang betul secara rawak, ia pasti akan mengganggu fungsi pemetaan 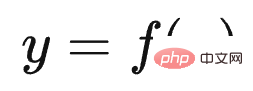 . Dengan kata lain, In Context Learning tidak mempelajari proses pemetaan dari ruang input ke ruang output.
. Dengan kata lain, In Context Learning tidak mempelajari proses pemetaan dari ruang input ke ruang output.  dan
dan  , iaitu pengedaran teks input
, iaitu pengedaran teks input  dan apa yang jawapan calon
dan apa yang jawapan calon  ialah , jika anda menukar kedua-dua pengedaran ini, seperti menggantikan
ialah , jika anda menukar kedua-dua pengedaran ini, seperti menggantikan  dengan kandungan selain daripada jawapan calon, kesan Pembelajaran Dalam Konteks akan menurun secara mendadak.
dengan kandungan selain daripada jawapan calon, kesan Pembelajaran Dalam Konteks akan menurun secara mendadak. 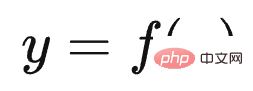 daripada contoh yang diberikan, tetapi ia dipelajari secara tersirat. Sebagai contoh, "Algoritma pembelajaran apakah pembelajaran dalam konteks? Penyiasatan dengan model linear" percaya bahawa Transformer boleh secara tersirat mempelajari proses pemetaan daripada
daripada contoh yang diberikan, tetapi ia dipelajari secara tersirat. Sebagai contoh, "Algoritma pembelajaran apakah pembelajaran dalam konteks? Penyiasatan dengan model linear" percaya bahawa Transformer boleh secara tersirat mempelajari proses pemetaan daripada  hingga
hingga  daripada contoh dan fungsi pengaktifannya mengandungi beberapa fungsi pemetaan mudah dan LLM. boleh memberi inspirasi kepada yang sepadan dengan contoh. Artikel "Mengapa GPT Boleh Belajar Dalam Konteks? Model Bahasa Secara Rahsia Melakukan Penurunan Kecerunan sebagai Pengoptimum Meta" menganggap ICL sebagai Penalaan Halus tersirat.
daripada contoh dan fungsi pengaktifannya mengandungi beberapa fungsi pemetaan mudah dan LLM. boleh memberi inspirasi kepada yang sepadan dengan contoh. Artikel "Mengapa GPT Boleh Belajar Dalam Konteks? Model Bahasa Secara Rahsia Melakukan Penurunan Kecerunan sebagai Pengoptimum Meta" menganggap ICL sebagai Penalaan Halus tersirat. Cahaya Kebijaksanaan: Bagaimana Meningkatkan Keupayaan Penaakulan LLM
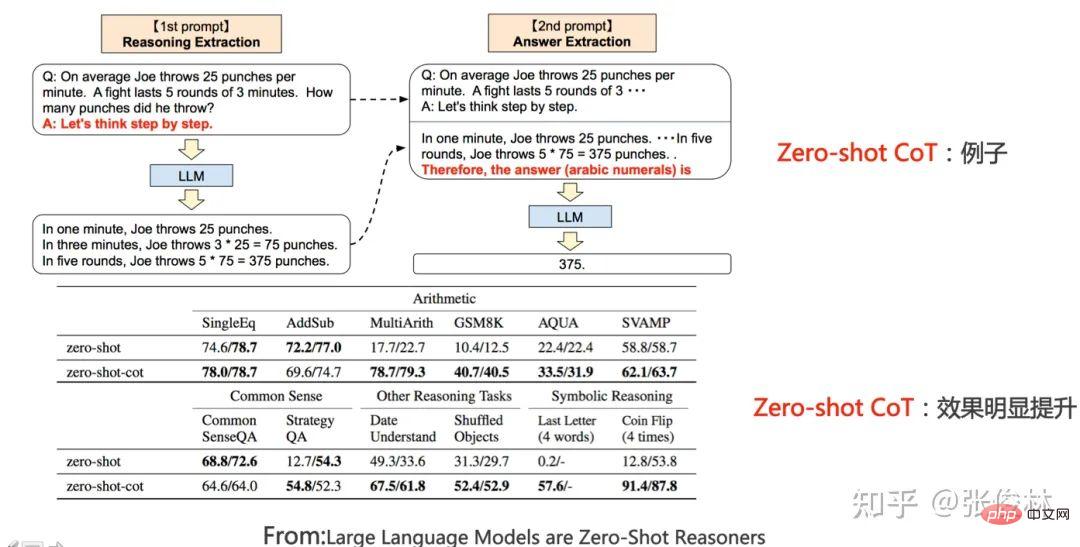
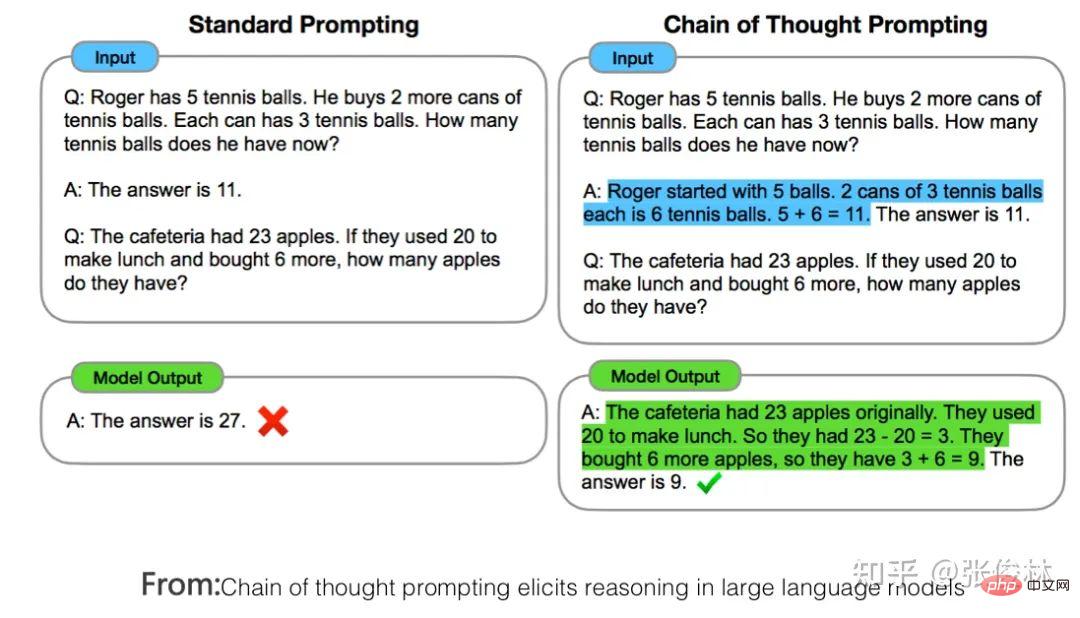
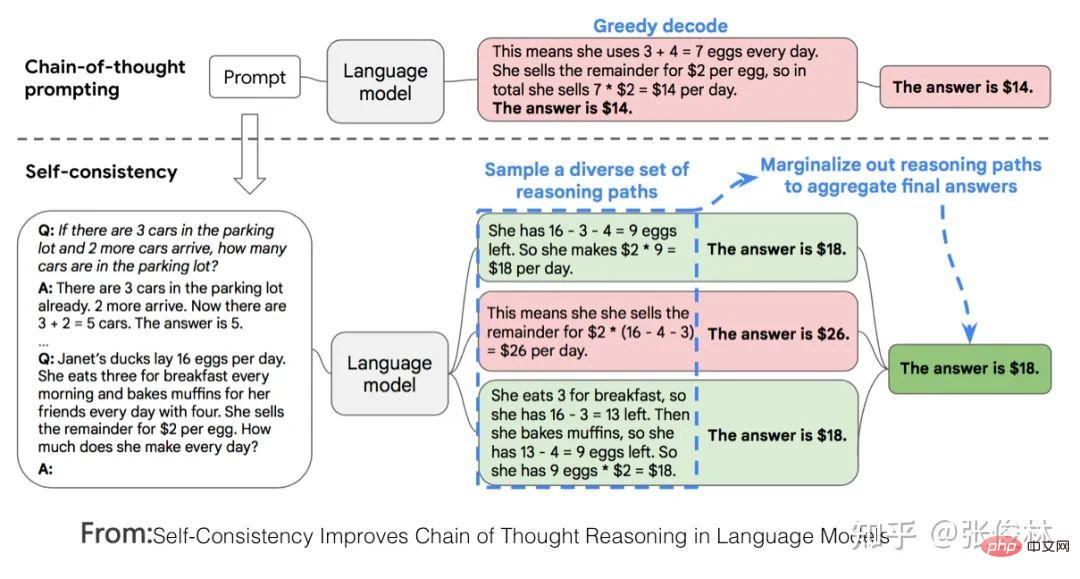
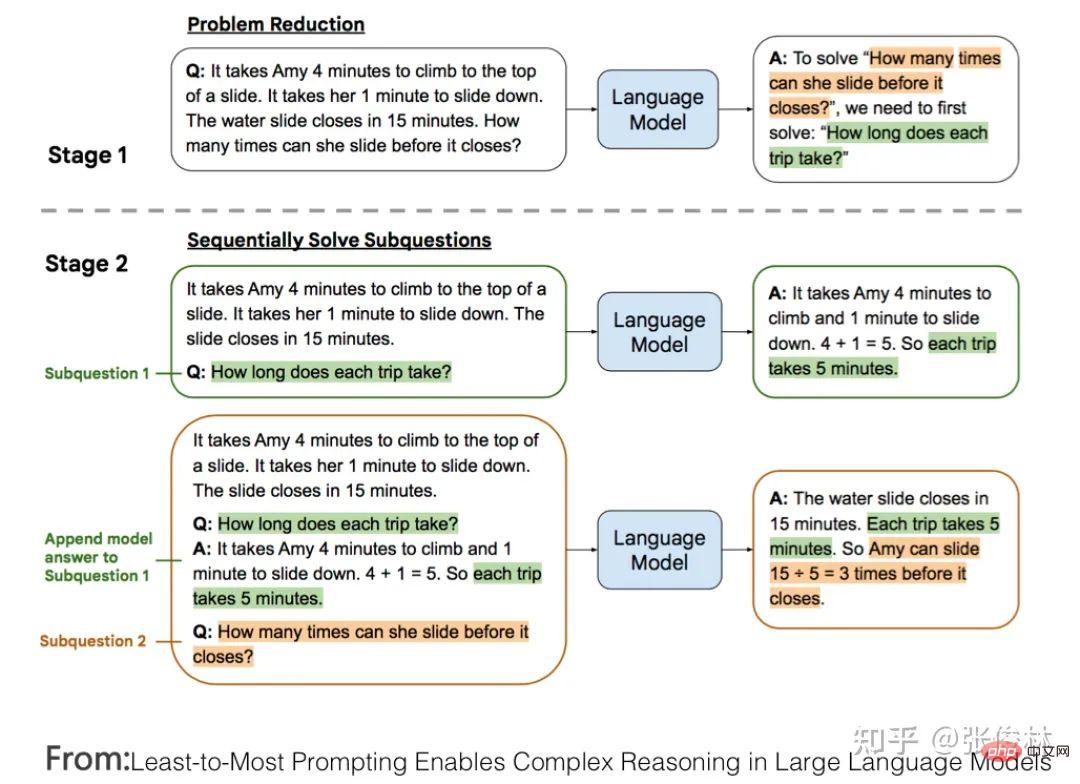
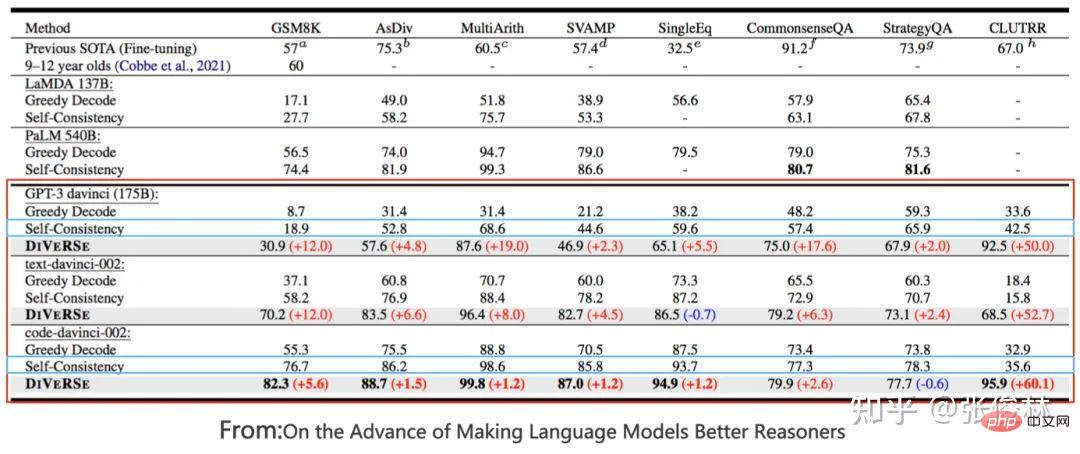
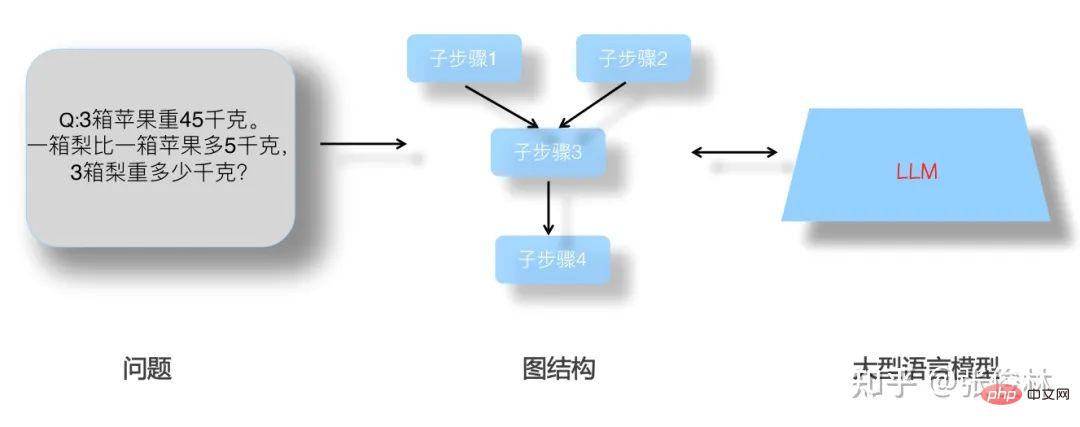
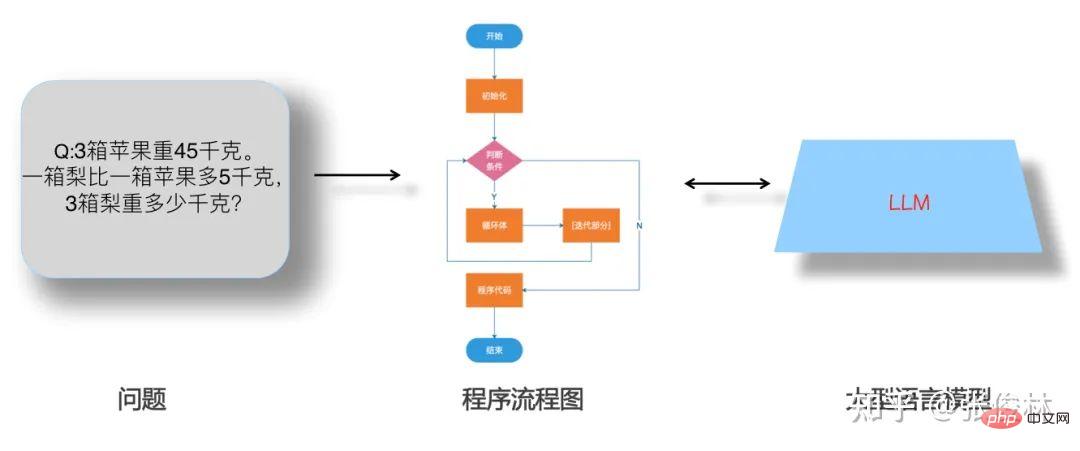
Jalan ke masa hadapan: Aliran penyelidikan LLM dan hala tuju utama yang patut dikaji
Jalan ke arah pembelajaran: Apakah yang perlu anda perhatikan semasa mereplikasi ChatGPT?
ChatGPT: Mengapa OpenAI
Atas ialah kandungan terperinci Terokai teknologi model besar dalam era pasca-GPT 3.0 dan bergerak ke arah merealisasikan masa depan AGI. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI