
Rumah >Peranti teknologi >AI >Kalahkan OpenAI sekali lagi! Google mengeluarkan 2 bilion parameter model universal untuk mengecam dan menterjemah lebih daripada 100 bahasa secara automatik
Kalahkan OpenAI sekali lagi! Google mengeluarkan 2 bilion parameter model universal untuk mengecam dan menterjemah lebih daripada 100 bahasa secara automatik

- WBOYke hadapan
- 2023-04-25 12:04:061530semak imbas
Minggu lepas, OpenAI mengeluarkan ChatGPT API dan Whisper API, yang baru sahaja mencetuskan karnival di kalangan pembangun.
Pada 6 Mac, Google melancarkan model penanda aras-USM. Ia bukan sahaja boleh menyokong lebih daripada 100 bahasa, malah bilangan parameter juga telah mencapai 2 bilion.
Sudah tentu model itu masih tidak dibuka kepada orang ramai, "Ini sangat Google"!
Ringkasnya, model USM merangkumi 12 juta jam pertuturan dan 28 bilion ayat. Ia dilatih terlebih dahulu pada set data tidak berlabel 300 bahasa berbeza dan diperhalusi pada set latihan berlabel yang lebih kecil.
Penyelidik Google berkata walaupun set latihan anotasi yang digunakan untuk penalaan halus hanya 1/7 daripada Whisper, USM mempunyai prestasi yang setara atau lebih baik, dan juga keupayaan untuk menyesuaikan diri dengan bahasa dan data baharu dengan cekap.

Alamat kertas: https://arxiv.org/abs/2303.01037
Hasilnya menunjukkan bahawa USM bukan sahaja mencapai SOTA dalam pengecaman pertuturan automatik berbilang bahasa dan penilaian tugas terjemahan teks pertuturan, tetapi juga sebenarnya boleh digunakan dalam penjanaan sari kata YouTube.
Pada masa ini, bahasa yang menyokong pengesanan dan terjemahan automatik termasuk bahasa Inggeris, Cina dan bahasa kecil arus perdana seperti Assam.
Paling penting, ia juga boleh digunakan untuk terjemahan masa nyata cermin mata AR masa depan yang ditunjukkan oleh Google pada persidangan IO tahun lepas.

Jeff Dean mengumumkan secara peribadi: Biarkan AI menyokong 1000 bahasa
Sementara Microsoft dan Google berdebat tentang siapa yang mempunyai AI chatbot yang lebih baik, ketahuilah bahawa model bahasa yang besar boleh digunakan untuk lebih daripada itu.
Pada November tahun lalu, Google mula-mula mengumumkan projek baharu untuk "membangunkan model bahasa kecerdasan buatan yang menyokong 1,000 bahasa yang paling biasa digunakan di dunia ."

Pada tahun yang sama, Meta turut mengeluarkan model yang dipanggil "No Language Left Behind" . Ia juga mendakwa bahawa ia boleh menterjemah lebih daripada 200 bahasa dan bertujuan untuk mencipta "penterjemah universal".
Google menerangkan keluaran model terbaharu sebagai "langkah kritikal" ke arah matlamatnya.
Boleh dikatakan ramai hero bersaing dalam membina model bahasa.
Menurut khabar angin, Google merancang untuk mempamerkan lebih daripada 20 produk yang dikuasakan oleh kecerdasan buatan pada persidangan I/O tahunan tahun ini.
Pada masa ini, pengecaman pertuturan automatik menghadapi banyak cabaran:
- Diselia Tradisional kaedah pembelajaran kurang berskala
Dalam kaedah tradisional, data audio memerlukan pelabelan manual yang memakan masa dan mahal, atau diperoleh daripada yang sedia ada dikumpulkan daripada sumber transkripsi, yang mungkin sukar dicari untuk bahasa yang tidak mempunyai perwakilan yang luas.
- Sambil mengembangkan liputan dan kualiti bahasa, model mesti dipertingkatkan dengan cara yang cekap dari segi pengiraan
Ini memerlukan algoritma untuk dapat menggunakan sejumlah besar data daripada sumber yang berbeza, mendayakan kemas kini model tanpa memerlukan latihan semula yang lengkap dan dapat membuat generalisasi kepada bahasa dan penggunaan baharu kes .
Pembelajaran penyeliaan kendiri yang diperhalusi
Menurut kertas kerja, latihan USM menggunakan tiga pangkalan data: set data audio tidak berpasangan, data Teks tidak berpasangan set, korpus ASR berpasangan.
- Set Data Audio Tidak Berpasangan
Termasuk YT-NTL-U (lebih 12 juta jam data audio tak berteg YouTube) dan Pub-U (lebih 429,000 jam kandungan pertuturan dalam 51 bahasa)
- Dataset teks tidak berpasangan
Web- NTL (28 bilion ayat dalam lebih 1140 bahasa berbeza)
- Korpus ASR berpasangan
YT-SUP+ dan Pub-S corpora (lebih 10,000 jam kandungan audio dan teks yang sepadan)

USM menggunakan struktur pengekod-penyahkod standard, di mana penyahkod boleh menjadi CTC, RNN-T atau LAS.
Untuk pengekod, USM menggunakan Conformor, atau Convolution-enhanced Transformer.
Proses latihan dibahagikan kepada tiga peringkat.
Pada peringkat awal, pra-latihan tanpa pengawasan dilakukan menggunakan BEST-RQ (BERT-based Random Projection Quantizer for Speech Pre-training). Matlamatnya adalah untuk mengoptimumkan RQ.
Pada peringkat seterusnya, model pembelajaran perwakilan pertuturan dilatih lagi.
Gunakan PALING (Pralatihan Diselia Berbilang Objek) untuk menyepadukan maklumat daripada data teks lain.
Model memperkenalkan modul pengekod tambahan yang mengambil teks sebagai input dan memperkenalkan lapisan tambahan untuk menggabungkan pengekod pertuturan dan output pengekod teks, dan bersama-sama melatih model pada ucapan tidak berlabel, ucapan berlabel dan data teks.
Langkah terakhir ialah memperhalusi tugas ASR (pengecaman pertuturan automatik) dan AST (terjemahan pertuturan automatik) Model USM yang telah dilatih sahaja sejumlah kecil data Penyeliaan boleh mencapai prestasi yang baik.
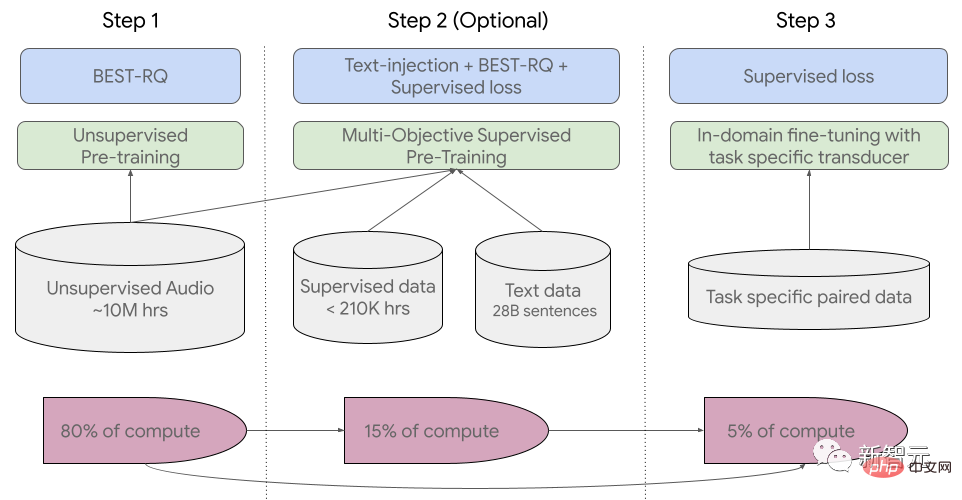
Proses latihan keseluruhan USM
Bagaimanakah prestasi USM yang diuji oleh Google pada sari kata YouTube, promosi tugasan ASR hiliran dan terjemahan pertuturan automatik.
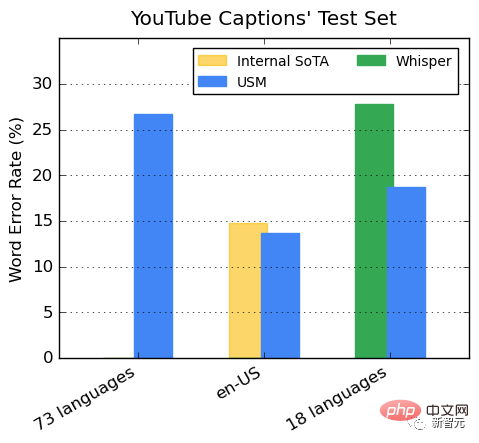
Prestasi pada sari kata berbilang bahasa YouTube
Data YouTube yang diselia termasuk 73 bahasa, dengan purata kurang daripada 3,000 jam data bagi setiap bahasa. Walaupun data penyeliaan terhad, model itu mencapai purata kadar ralat perkataan (WER) kurang daripada 30% merentas 73 bahasa, yang lebih rendah daripada model terkini di Amerika Syarikat.
Selain itu, Google membandingkannya dengan model Whisper (big-v2) yang dilatih dengan lebih 400,000 jam data beranotasi.
Antara 18 bahasa yang Whisper boleh menyahkod, kadar ralat penyahkodannya kurang daripada 40%, manakala purata kadar ralat USM hanya 32.7%.
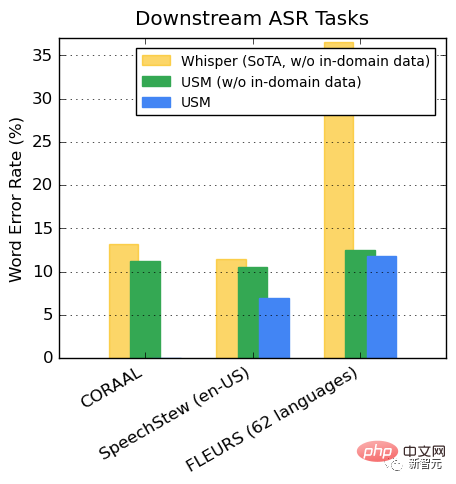
Promosi tugas hiliran ASR
Pada set data yang tersedia secara terbuka, USM menunjukkan prestasi yang lebih rendah pada CORAAL (Bahasa Inggeris Dialek Afrika Amerika), SpeechStew (Bahasa Inggeris-AS) dan FLEURS (102 bahasa) berbanding Whisper WER, tidak kira sama ada terdapat dalam domain data latihan.
Perbezaan FLEURS antara kedua-dua model amat ketara.
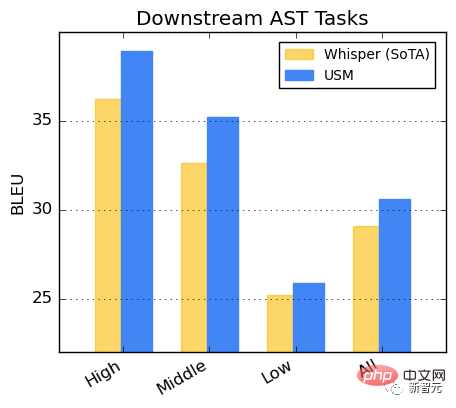
Prestasi pada tugas AST
Memperhalusi USM pada set data CoVoST.
Bahagikan bahasa dalam set data kepada kategori tinggi, sederhana dan rendah mengikut ketersediaan sumber dan hitung skor BLEU pada setiap kategori (lebih tinggi lebih baik), USM menunjukkan prestasi yang lebih baik daripada Whisper dalam setiap kategori.
Penyelidikan mendapati bahawa pra-latihan BEST-RQ ialah kaedah yang berkesan untuk melanjutkan pembelajaran perwakilan pertuturan kepada set data yang besar.
Apabila digabungkan dengan suntikan teks dalam KEBANYAKAN, ia meningkatkan kualiti tugas pertuturan hiliran, mencapai hasil terkini pada FLEURS dan CoVoST 2 prestasi penanda aras.
Dengan melatih modul penyesuai sisa ringan, KEBANYAKAN mewakili keupayaan untuk menyesuaikan diri dengan cepat kepada domain baharu. Modul penyesuai yang tinggal ini hanya meningkatkan parameter sebanyak 2%.
Google berkata pada masa ini, USM menyokong lebih daripada 100 bahasa dan akan berkembang ke lebih daripada 1000 bahasa pada masa hadapan. Dengan teknologi ini, semua orang mungkin selamat untuk mengembara ke seluruh dunia.
Malah, produk cermin mata Google AR terjemahan masa nyata akan datang akan menarik ramai peminat.
Bagaimanapun, aplikasi teknologi ini masih jauh lagi.
Lagipun, dalam ucapannya di Persidangan IO kepada dunia, Google turut menulis teks Arab ke belakang, menarik ramai netizen untuk menonton.
Atas ialah kandungan terperinci Kalahkan OpenAI sekali lagi! Google mengeluarkan 2 bilion parameter model universal untuk mengecam dan menterjemah lebih daripada 100 bahasa secara automatik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI