
Rumah >Peranti teknologi >AI >Model dialog dwibahasa sumber terbuka semakin popular di GitHub, dengan alasan bahawa AI tidak perlu membetulkan omong kosong
Model dialog dwibahasa sumber terbuka semakin popular di GitHub, dengan alasan bahawa AI tidak perlu membetulkan omong kosong

- 王林ke hadapan
- 2023-04-24 17:49:091006semak imbas
Artikel ini dicetak semula dengan kebenaran AI New Media Qubit (ID akaun awam: QbitAI), sila hubungi sumber untuk mencetak semula
Robot perbualan domestik ChatGLM dilahirkan pada hari yang sama dengan GPT-4.
Dilancarkan bersama oleh Zhipu AI dan Makmal KEG Universiti Tsinghua, versi beta dalaman alfa telah dilancarkan.
Kebetulan ini memberikan Zhang Peng, pengasas dan Ketua Pegawai Eksekutif Zhipu AI, perasaan kompleks yang tidak dapat digambarkan. Tetapi melihat betapa hebatnya teknologi OpenAI telah menjadi, veteran teknikal ini yang kebas dengan perkembangan baharu dalam AI tiba-tiba menjadi teruja semula.
Terutama apabila mengikuti siaran langsung sidang media GPT-4, dia melihat gambar di skrin, tersenyum seketika, melihat bahagian lain, dan tersengih seketika.
Sejak penubuhannya, Zhipu AI yang diketuai oleh Zhang Peng telah menjadi ahli bidang model besar dan telah menetapkan visi "membuat mesin berfikir seperti manusia."
Tetapi jalan bergelombang. Seperti hampir semua syarikat model berskala besar, mereka menghadapi masalah yang sama: kekurangan data, kekurangan mesin dan kekurangan wang. Nasib baik, terdapat beberapa organisasi dan syarikat yang menyediakan sokongan percuma di sepanjang perjalanan.
Pada Ogos tahun lepas, syarikat itu bekerjasama dengan beberapa institut penyelidikan saintifik untuk membangunkan model bahasa besar pra-latihan dwibahasa sumber terbuka GLM-130B, yang boleh hampir atau sama dengan GPT-3 175B (davinci) dari segi ketepatan dan penunjuk hasad , yang kemudiannya menjadi asas ChatGLM. Juga bersumber terbuka pada masa yang sama dengan ChatGLM ialah versi 6.2 bilion parameter ChatGLM-6B, yang boleh dijalankan dengan satu kad untuk 1,000 yuan.
Selain GLM-130B, satu lagi produk terkenal Zhipu ialah kumpulan bakat AI AMiner, yang dimainkan oleh nama-nama besar dalam bidang akademik:
Kali ini dan Pada hari yang sama ketika GPT-4 melanda, kelajuan dan teknologi OpenAI memberi banyak tekanan kepada Zhang Peng dan pasukan Zhipu.
Adakah "karut serius" perlu diperbetulkan?
Selepas ujian dalaman ChatGLM, Qubit mendapat kuota serta-merta dan melancarkan gelombang penilaian manusia.
Jangan bercakap tentang perkara lain Selepas beberapa pusingan ujian, tidak sukar untuk mendapati ChatGLM mempunyai kemahiran yang ChatGPT dan Bing Baharu ada: Omong kosong yang serius, termasuk Tetapi ia adalah. tidak terhad kepada pengiraan -33 anak ayam dalam masalah sangkar ayam dan arnab. Bagi kebanyakan orang yang menganggap AI perbualan sebagai "mainan" atau pembantu pejabat, cara meningkatkan ketepatan adalah perkara yang diberi perhatian dan kepentingan khusus. Dialog AI serius cakap bukan-bukan. Adakah ia benar-benar perlu diperbetulkan?
Sebagai contoh, bersaing dengan OpenAI, walaupun anda hanya cuba untuk mengejar, adalah sebahagian daripada pertandingan.
Pengejaran di sini ialah proses pernyataan, berdasarkan kepercayaan bahawa hala tuju penyelidikan OpenAI adalah satu-satunya cara untuk mencapai matlamat selanjutnya, tetapi mengejar OpenAI bukanlah matlamat utama.
Mengejar bukan bermakna kita boleh berhenti; proses mengejar tidak bermakna kita perlu meniru model Lembah Silikon sebagaimana adanya Reka bentuk tahap untuk menumpukan pada melakukan perkara-perkara besar Hanya selepas itu kita boleh menebus perbezaan kelajuan pembangunan.
Walaupun kami mempunyai pengalaman lebih 4 tahun dari tahun 2019 hingga sekarang, Zhipu tidak berani memberikan sebarang garis panduan mengelak perangkap. Walau bagaimanapun, Zhipu memahami hala tuju umum Ini juga idea biasa yang didedahkan oleh Zhipu yang mereka bincangkan dengan CCF -
Kelahiran teknologi model besar adalah projek sistematik yang sangat komprehensif dan kompleks.
Ini bukan lagi tentang segelintir kepala pintar yang merenung di makmal, menggugurkan beberapa helai rambut, melakukan beberapa eksperimen dan menerbitkan beberapa kertas kerja. Sebagai tambahan kepada inovasi teori asal, ia juga memerlukan pelaksanaan kejuruteraan yang kukuh dan keupayaan sistematisasi, dan juga keupayaan produk yang baik.
Sama seperti ChatGPT, pilih senario yang sesuai, sediakan dan bungkus produk yang boleh digunakan oleh orang seawal 80 dan seawal 8 tahun.
Kuasa pengkomputeran, algoritma dan data semuanya adalah bakat di belakang mereka, terutamanya pengamal kejuruteraan sistem, yang kepentingannya jauh lebih besar daripada masa lalu.
Berdasarkan pemahaman ini, Zhang Peng mendedahkan bahawa menambah sistem pengetahuan (graf pengetahuan) ke medan model besar, membolehkan kedua-duanya berfungsi secara sistematik seperti otak kiri dan kanan, adalah langkah seterusnya graf kebijaksanaan dalam langkah penyelidikan dan eksperimen.
Model perbualan dwibahasa paling popular GitHub
ChatGLM secara keseluruhan merujuk kepada idea reka bentuk ChatGPT.
Iaitu, latihan pra-latihan kod disuntik ke dalam model asas dwibahasa GLM-130B, dan penjajaran niat manusia dicapai melalui penalaan halus yang diselia dan teknologi lain (iaitu, menjadikan jawapan mesin mematuhi nilai manusia dan jangkaan manusia).
GLM-130B dengan 130 bilion parameter di belakangnya dibangunkan bersama oleh Zhipu dan Makmal KEG Universiti Tsinghua. Berbeza daripada seni bina BERT, GPT-3 dan T5, GLM-130B ialah model pra-latihan autoregresif yang mengandungi pelbagai fungsi objektif.
Pada Ogos tahun lepas, GLM-130B telah dikeluarkan kepada umum dan pada masa yang sama sumber terbuka. Dalam laporan Standford, prestasinya luar biasa dalam pelbagai tugas.
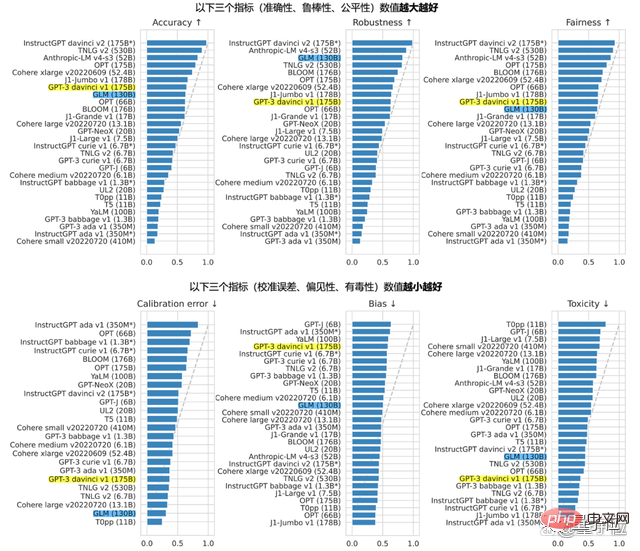
Ketegasan terhadap sumber terbuka datang dari hakikat bahawa Zhipu tidak mahu menjadi perintis kesepian dalam perjalanan ke AGI.
Ini juga sebab mengapa kami akan terus membuka sumber ChatGLM-6B tahun ini selepas membuka GLM-130B.
ChatGLM-6B ialah "versi mengecut" model, dengan saiz parameter 6.2 bilion Asas teknikal adalah sama dengan ChatGLM, dan ia telah mula mempunyai fungsi soal jawab dan dialog bahasa Cina.
Terdapat dua sebab untuk terus membuka sumber.
Salah satunya adalah untuk mengembangkan ekologi model pra-latihan, menarik lebih ramai orang untuk melabur dalam penyelidikan model besar, dan menyelesaikan banyak masalah penyelidikan sedia ada
Yang lain adalah berharap model besar boleh digunakan sebagai prasarana Mendakan untuk membantu menjana nilai seterusnya yang lebih besar.
Menyertai komuniti sumber terbuka sememangnya menarik. Dalam beberapa hari selepas ujian dalaman ChatGLM, ChatGLM-6B mempunyai 8.5k bintang di GitHub, sekali gus melonjak ke tempat pertama dalam senarai sohor kini.
Dari perbualan ini, Qubit juga mendengar suara ini daripada pengamal di hadapan saya:
Pepijat yang sama kerap muncul, tetapi toleransi orang ramai untuk ChatGPT yang dilancarkan oleh OpenAI jelas berbeza daripada robot perbualan Google Bard dan Baidu Wenxinyiyan.
Ini adalah adil dan tidak adil.
Dari sudut pandangan teknikal semata-mata, kriteria penghakiman adalah berbeza, yang tidak adil tetapi syarikat besar seperti Google dan Baidu menduduki lebih banyak sumber, jadi semua orang secara semulajadi merasakan bahawa mereka mempunyai keupayaan teknikal yang lebih kuat dan lebih baik; Kemungkinan untuk menghasilkan sesuatu yang lebih baik adalah lebih tinggi, dan jangkaan lebih tinggi.
"Saya harap semua orang dapat lebih bersabar, sama ada dengan Baidu, kami, atau institusi lain." di atas , Dalam perbualan ini, Qubit juga bercakap dengan Zhang Peng tentang pengalaman ChatGLM secara terperinci.
Transkrip perbualan dilampirkan di bawah. Untuk kemudahan pembacaan, kami telah menyunting dan menyusunnya tanpa mengubah maksud asal.
 Transkrip perbualan
Transkrip perbualan
Qubit: Label yang diberikan kepada versi beta dalaman nampaknya tidak begitu "sejagat". penjagaan perubatan dan kewangan.
Zhang Peng: Ini tiada kaitan dengan data latihan, terutamanya mengambil kira senario aplikasinya.
ChatGLM adalah serupa dengan ChatGPT dan merupakan model perbualan. Kawasan aplikasi manakah yang secara semula jadi lebih dekat dengan senario perbualan? Seperti perkhidmatan pelanggan, seperti perundingan doktor, atau seperti perkhidmatan kewangan dalam talian. Dalam senario ini, teknologi ChatGLM lebih sesuai untuk memainkan peranan.
Qubit: Tetapi dalam bidang perubatan, orang yang ingin berjumpa doktor masih agak berhati-hati tentang AI.
Zhang Peng: Anda pasti tidak boleh menggunakan model besar untuk menyerang! (Ketawa) Jika anda ingin menggantikan manusia sepenuhnya, anda masih perlu berhati-hati.
Pada peringkat ini, ia tidak digunakan untuk menggantikan kerja orang, tetapi lebih kepada peranan sokongan, memberikan cadangan kepada pengamal untuk meningkatkan kecekapan kerja.
Qubit: Kami menghantar pautan kertas GLM-130B ke ChatGLM dan memintanya untuk meringkaskan topik itu secara ringkas untuk masa yang lama, tetapi ternyata ia bukan mengenai artikel ini sama sekali.
Zhang Peng: Tetapan ChatGLM adalah sedemikian rupa sehingga ia tidak boleh mendapatkan pautan. Ia bukan kesukaran teknikal, tetapi masalah sempadan sistem Terutamanya dari perspektif keselamatan, kami tidak mahu ia mengakses pautan luar sewenang-wenangnya.
Anda boleh cuba menyalin teks kertas 130B dan membuangnya ke dalam kotak input Secara amnya, anda tidak akan bercakap kosong.
Qubit: Kami juga membaling seekor ayam dan seekor arnab dalam sangkar yang sama, dan mengira -33 ekor ayam.
Zhang Peng: Dari segi pemprosesan matematik dan penaakulan logik, ia masih mempunyai kelemahan tertentu dan tidak boleh begitu baik. Kami sebenarnya menulis tentang ini dalam arahan beta tertutup.

Qubit: Seseorang di Zhihu membuat penilaian dan keupayaan pengekodan nampaknya sederhana.
Zhang Peng: Bagi keupayaan untuk menulis kod, saya rasa ia agak bagus? Saya tidak tahu apakah kaedah ujian anda. Tetapi ia bergantung kepada siapa yang anda bandingkan dengan ChatGPT, ChatGLM sendiri mungkin tidak melabur sebanyak itu dalam data kod.
Sama seperti perbandingan antara ChatGLM dan ChatGLM-6B, yang terakhir hanya mempunyai 6B (6.2 bilion) parameter Dari segi keupayaan keseluruhan, seperti logik keseluruhan, ilusi semasa menjawab, dan panjang, jurang antara. versi dikurangkan dan versi asal hanya Ia jelas.
Tetapi "versi menyusut" boleh digunakan pada komputer biasa, membawa kebolehgunaan yang lebih tinggi dan ambang yang lebih rendah.
Qubit: Ia mempunyai kelebihan Ia mempunyai pemahaman yang baik tentang maklumat baharu Saya tahu bahawa Ketua Pegawai Eksekutif Twitter semasa ialah Musk, dan saya juga tahu bahawa He Kaiming kembali ke akademi pada 10 Mac - walaupun saya tidak. 'tak tahu tentang GPT- 4 telah dikeluarkan, haha.
Zhang Peng: Kami telah melakukan beberapa pemprosesan teknikal khas.
Qubit: Apa itu?
Zhang Peng: Saya tidak akan membincangkan butiran khusus. Tetapi ada cara untuk menangani maklumat baharu yang agak baru.
Qubit: Bolehkah anda beritahu kami kosnya? Kos latihan GLM-130B masih beberapa juta Berapa rendah kos menjalankan pusingan soal jawab di ChatGLM?
Zhang Peng: Kami secara kasar menguji dan menganggarkan kos, yang serupa dengan kos yang diumumkan oleh OpenAI untuk kali kedua hingga terakhir, dan lebih rendah sedikit daripada kos tersebut.
Tetapi tawaran terkini OpenAI telah dikurangkan kepada 10% daripada harga asal, hanya $0.002/750 perkataan, yang lebih rendah daripada kami. Kos ini sememangnya menakjubkan. Dianggarkan bahawa mereka telah melakukan pemampatan model, pengkuantitian, pengoptimuman, dan lain-lain, jika tidak, ia tidak akan dapat dikurangkan ke tahap yang begitu rendah.
Kami juga melakukan perkara berkaitan dan berharap dapat mengurangkan kos.
Qubits: Lama kelamaan, bolehkah mereka serendah kos carian?
Zhang Peng: Bilakah ia akan jatuh ke tahap yang begitu rendah? saya pun tak tahu. Ia akan mengambil sedikit masa.
Saya telah melihat pengiraan purata kos setiap harga carian sebelum ini, yang sebenarnya berkaitan dengan perniagaan utama. Sebagai contoh, perniagaan utama enjin carian ialah pengiklanan, jadi jumlah hasil pengiklanan harus digunakan sebagai had atas untuk mengira kos. Jika dikira dengan cara ini, apa yang perlu dipertimbangkan bukanlah kos penggunaan, tetapi titik keseimbangan keuntungan dan faedah korporat.
Inferens model memerlukan kuasa pengkomputeran AI, yang pastinya lebih mahal daripada mencari hanya menggunakan kuasa pengkomputeran CPU. Tetapi semua orang bekerja keras, dan ramai orang telah mengemukakan beberapa idea, seperti terus memampatkan dan mengukur model.
Sesetengah orang mahu menukar model dan membiarkannya berjalan pada CPU, kerana CPU lebih murah dan mempunyai volum yang lebih besar, kosnya akan turun dengan ketara.
Qubit: Akhir sekali, saya ingin bercakap tentang beberapa topik tentang bakat Sekarang semua orang berebut untuk mendapatkan bakat untuk model besar Adakah anda takut bahawa Zhipu tidak akan dapat merekrut orang.
Zhang Peng: Kami diinkubasi daripada projek teknologi Tsinghua KEG dan sentiasa mempunyai hubungan baik dengan pelbagai universiti. Lebih-lebih lagi, syarikat mempunyai suasana yang agak terbuka untuk orang muda 75% daripada rakan sekerja saya adalah orang muda. Bakat model besar sememangnya merupakan komoditi yang jarang berlaku sekarang, tetapi kami tidak mempunyai sebarang kebimbangan mengenai pengambilan pekerja.
Sebaliknya, kita sebenarnya lebih bimbang dieksploitasi oleh orang lain.
Atas ialah kandungan terperinci Model dialog dwibahasa sumber terbuka semakin popular di GitHub, dengan alasan bahawa AI tidak perlu membetulkan omong kosong. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI