
Rumah >Peranti teknologi >AI >Stable Diffusion-XL dibuka untuk beta awam, membebaskan anda daripada gesaan yang panjang dan menyusahkan!
Stable Diffusion-XL dibuka untuk beta awam, membebaskan anda daripada gesaan yang panjang dan menyusahkan!

- WBOYke hadapan
- 2023-04-23 10:16:071657semak imbas
Sejak Midjourney mengeluarkan v5, terdapat peningkatan yang ketara dalam realisme aksara dan butiran jari dalam imej yang dijana, dan peningkatan juga telah dibuat dalam ketepatan pemahaman segera, kepelbagaian estetik dan kemajuan bahasa.
Sebaliknya, walaupun Stable Diffusion adalah percuma dan sumber terbuka, anda perlu menulis senarai panjang gesaan setiap kali dan menjana imej berkualiti tinggi bergantung pada kad lukisan beberapa kali.

Baru-baru ini, Stability AI secara rasmi mengumumkan bahawa Stable Diffusion XL yang sedang dibangunkan telah mula diuji untuk orang ramai dan kini tersedia untuk percubaan percuma pada Clipdrop platform.

Pautan percubaan: https://clipdrop.co/stable-diffusion

Gim di rumah minimalis dengan lantai getah, TV di dinding, bangku berat, bola ubat, dumbel, tikar yoga, berteknologi tinggi peralatan, perincian tinggi, tersusun dan cekap.
Gim di rumah ringkas, lantai getah, TV yang dipasang di dinding, bangku berat, bola ubat, dumbel, tikar yoga, Peralatan berteknologi tinggi, perincian tinggi, organisasi dan kecekapan
Berikut adalah beberapa contoh yang dikeluarkan secara rasmi oleh SD-XL Dapat dilihat bahawa kualiti imej sudah sangat mengagumkan .






SD-XL: Versi sumber terbuka Midjourney
Mengenai maklumat khusus model Stable Diffusion XL, pegawai itu melakukannya tidak mendedahkan banyak, Pada masa ini, kita hanya tahu bahawa ia adalah model dengan seni bina yang serupa dengan model v2, tetapi dengan skala dan kiraan parameter yang lebih besar.
SD-v2.1 termasuk 900 juta parameter, SD-XL mempunyai kira-kira 2.3 bilion parameter, dan Emad berkata bahawa versi rasmi mungkin mengeluarkan versi suling tambahan yang lebih kecil.
Peningkatan SD-XL berbanding versi sebelumnya adalah seperti berikut:
- Gunakan gesaan deskriptif yang lebih pendek untuk menjana Imej berkualiti tinggi
- boleh menjana imej yang sesuai dengan segera dengan lebih baik
- Struktur badan manusia dalam imej lebih munasabah
- Berbanding dengan versi v2.1 dan v1.5 (sebahagian kecilnya), gambar yang dihasilkan oleh SD-XL lebih sesuai dengan estetika awam
- Negatif gesaan adalah OK Pilihan
- Potret yang terhasil adalah lebih realistik
- Teks dalam imej lebih jelas
Sila ambil perhatian bahawa SD-XL mungkin tidak serasi dengan versi pemalam sebelumnya.
Teks yang jelas dan boleh dibaca
Dalam siri v1 dan versi v2.1 model Stable Diffusion, ia tidak dijana dalam imej Keupayaan membaca teks.
Walaupun maklumat teks yang dijana oleh SD-XL tidak selalu tepat, ia memberikan peningkatan yang besar.

Foto seorang wanita sedang duduk di restoran memegang menu yang tertera “Menu”
Seorang wanita sedang duduk di sebuah restoran sambil memegang menu dengan tulisan "Menu"

Foto seorang lelaki memegang papan tanda bertulis “Stable Diffusion” Stable Diffusion"
a perempuan muda memegang papan tanda bertulis "Stable Diffusion", menonjolkan rambut, duduk di luar restoran, mata coklat, memakai gaun , lampu sisi
Seorang wanita muda memegang papan tanda bertulis "Stable Diffusion" dengan rambut diserlahkan duduk di luar restoran, mata coklat , memakai skirt, lampu sisi
Struktur manusia yang lebih baik
Stable Diffusion sentiasa mengalami banyak masalah dalam menjana anatomi manusia, mempunyai lebih banyak kaki dan kurang lengan adalah masalah yang sangat biasa Ia biasanya perlu menggunakan fungsi inpaint untuk membetulkan lagi butiran imej atau menggunakan Pose Terbuka ControlNet berfungsi untuk menyalin postur badan manusia daripada imej rujukan.Contohnya, apabila SD-v1.5 menjana imej yoga, badan manusia yang herot sering muncul.
Foto seorang wanita dalam pakaian yoga, pose segi tiga, pantai pada waktu petang, pencahayaan rim

Foto wanita dalam pakaian yoga, pose segi tiga, pantai pada waktu malam, pencahayaan tepi
Walaupun imej yang dihasilkan oleh SD-XL tidak sempurna, mereka telah mencapai kemajuan yang ketara dalam postur manusia.

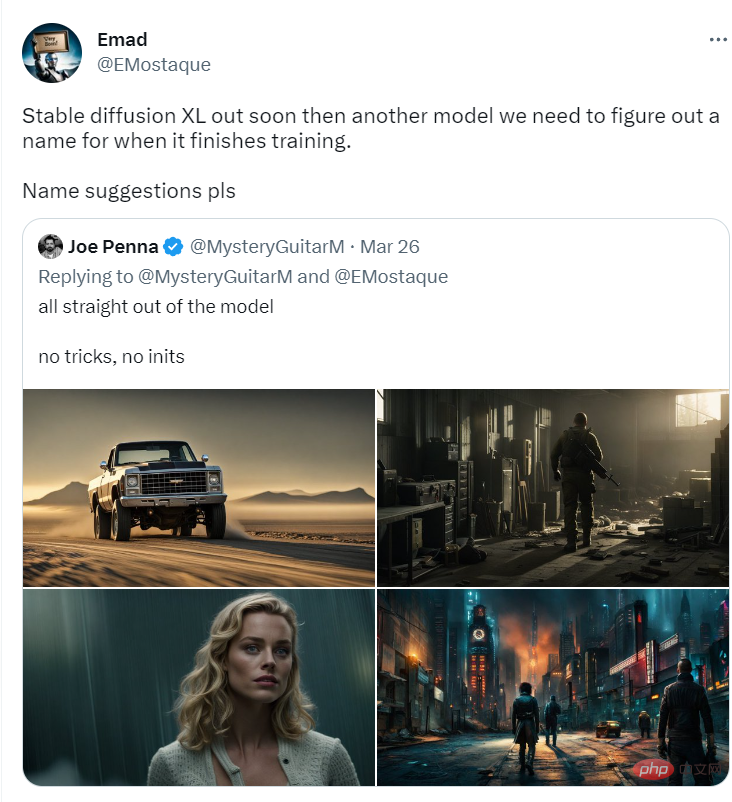
Lebih estetik
Contohnya, dengan tema rumah yang sama, SD-XL Ini menghasilkan foto yang lebih simetri dan mempunyai kesan visual yang lebih baik.

SD-XL juga mempunyai peningkatan ketara dalam foto potret.
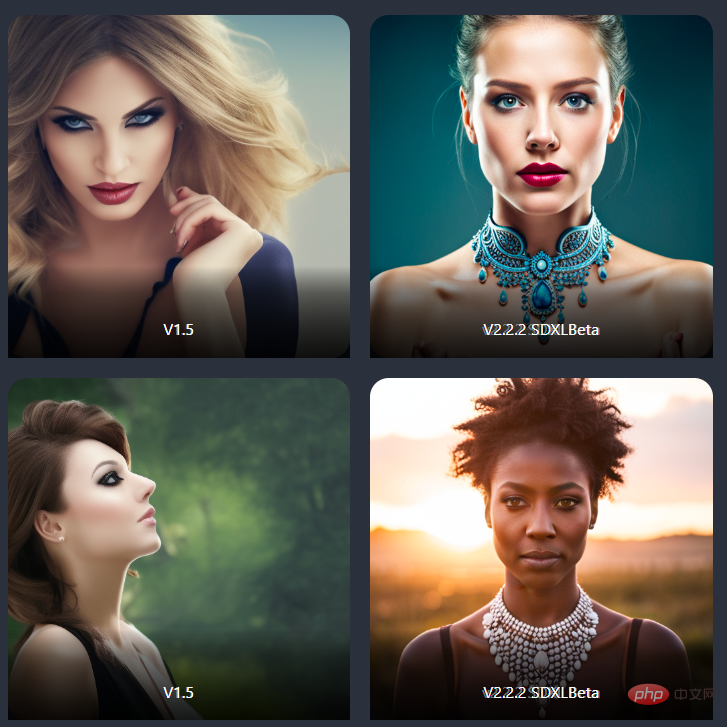
gambar gambar seorang wanita
Foto
Imej yang lebih sesuai dengan gesaan
SD-XL boleh lebih memahami gesaan input dan menjana imej yang lebih tepat.
Sebagai contoh, mengambil duotone (dua warna) sebagai contoh, SD-v1.5 hanya akan menjana imej hitam dan putih, manakala SD-XL boleh menjana imej dwi-nada dengan pelbagai warna.
Keupayaan untuk memahami gesaan telah bertambah baik berbanding model v1.

potret duotone seorang wanita
Dua nada potret
Oleh kerana SD-XL tergolong dalam model siri v2 yang sama, saiz model teks lebih besar dan perkataan gesaan boleh difahami dengan lebih baik daripada model v1.

Sebagai contoh, dalam contoh di bawah, model v1.5 tidak boleh memahami dua subjek (robot dan manusia) dalam imej, tetapi SD-XL Model ini boleh menghasilkan imej biasa (walaupun robot masih tidak cukup besar).
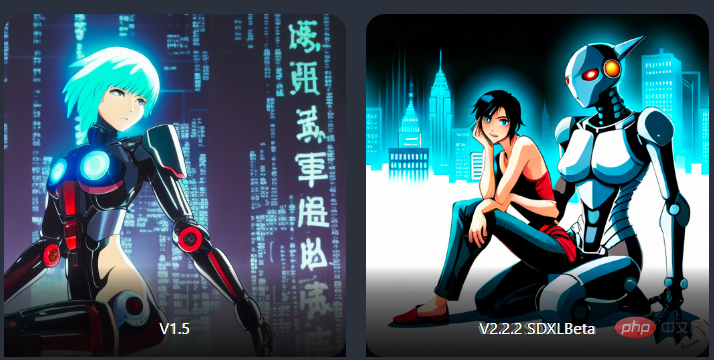
rakan robot besar duduk di sebelah manusia, hantu dalam gaya cangkerang, kertas dinding anime
Rakan robot besar yang duduk di sebelah kertas dinding anime gaya Ghost in the Shell manusia

seorang lelaki muda, sorotan rambut, mata coklat, berbaju putih dan jean biru di pantai dengan latar belakang gunung berapi
Seorang lelaki muda, dengan rambut dicelup Mata coklat yang sangat terang, memakai baju putih dan seluar jeans biru, berdiri di pantai dengan latar belakang gunung berapi
gaya artistik
Dari segi gaya artistik, SD-XL tidak dipertingkatkan dengan ketara, dan ia berbeza daripada versi sebelumnya.
Sebagai contoh, dua model menjana imej gaya Edward Hopper dari sudut yang berbeza.

Bandar New York oleh Edward Hopper
Bandar New York oleh Edward Hopper
Dalam gaya Leonid Afmov, SD-v1.5 lebih tepat, SD-XL tidak mempunyai sapuan berus papan berwarna-warni yang jelas.

Bandar New York oleh Leonid Afremov
Leonid Afemov Drawn New York
Dalam gaya William-Adolphe Bouguereau, kedua-dua V1.5 dan SDXL boleh menjana beberapa kandungan yang serupa, antaranya SD-XL lebih dekat dengan akademik klasik gaya yang dicipta oleh Bouguereau Painting, dan lebih banyak perincian muka.

Potret wanita cantik oleh William-Adolphe Bouguereau
Potret wanita cantik yang dilukis oleh William-Adolphe Bouguereau
Masalah perubahan gaya
Selepas menambah beberapa kata kunci yang tidak berkaitan, model itu Gaya mungkin berubah secara tiba-tiba.
Sebagai contoh, jana imej gaya foto dahulu.

seorang lelaki muda, rambut sorotan, mata coklat, berbaju putih dan jean biru di pantai dengan latar belakang gunung berapi
Seorang lelaki muda dengan rambut dicelup cerah dan mata coklat memakai baju putih dan seluar jeans biru berdiri di pantai dengan gunung berapi di latar belakang
Selepas menambah selendang kuning, gaya imej menjadi gaya kartun.

seorang lelaki muda, serlahan rambut, mata coklat, berpakaian selendang kuning, berbaju putih dan jean biru di pantai dengan latar belakang gunung berapi
Seorang lelaki muda dengan rambut dicelup cerah, mata coklat, memakai selendang kuning, memakai kemeja putih dan seluar jeans biru , berdiri di pantai dengan gunung berapi sebagai latar belakang
Masalahnya mungkin disebabkan isu pratonton saya tidak tahu sama ada isu ini boleh diselesaikan selepas rasmi lepaskan.
Atas ialah kandungan terperinci Stable Diffusion-XL dibuka untuk beta awam, membebaskan anda daripada gesaan yang panjang dan menyusahkan!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI