
Rumah >Peranti teknologi >AI >Model SOTA yang inovatif Meta boleh menghasilkan video yang menakjubkan berdasarkan satu ayat, mencetuskan kegilaan Internet!
Model SOTA yang inovatif Meta boleh menghasilkan video yang menakjubkan berdasarkan satu ayat, mencetuskan kegilaan Internet!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-23 09:22:071628semak imbas
Saya akan bagi satu perenggan dan minta awak buat video, boleh tak?
Meta berkata, saya boleh melakukannya.
Anda mendengarnya dengan betul: menggunakan AI, anda juga boleh menjadi pembuat filem!
Baru-baru ini, Meta melancarkan model AI baharu dengan nama yang sangat mudah: Make-A-Video.
Berapa kuasa model ini?
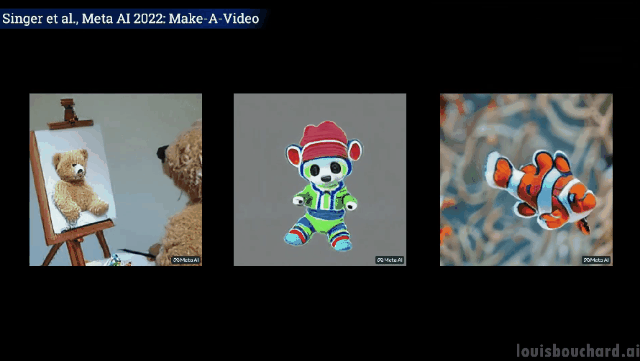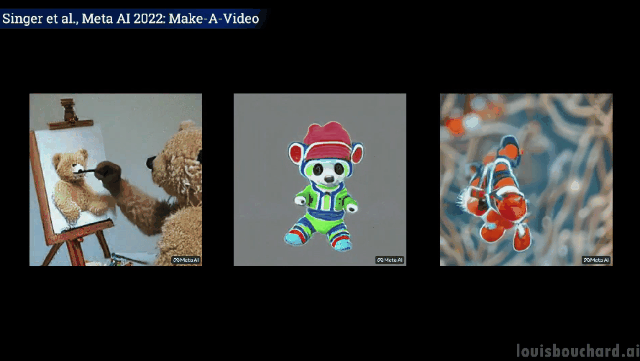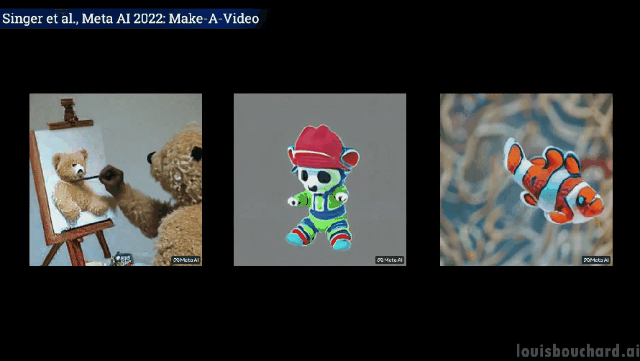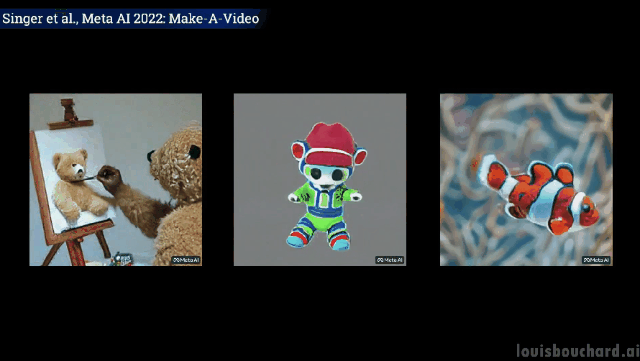
Hanya dengan satu ayat, anda boleh merealisasikan adegan "Tiga Kuda Berlumba-lumba".

LeCun pun cakap, apa yang sepatutnya datang akan sentiasa datang.

Kesan visual yang menakjubkan
Tanpa berlengah lagi, mari kita lihat kesannya.
Dua ekor kanggaru sedang sibuk memasak di dapur (sama ada boleh dimakan itu perkara lain)

Gambar dekat: Pelukis sedang melukis di atas kanvas

Dunia dua orang berjalan dalam hujan lebat (bersama-sama melangkah)

Air minuman kuda

Gadis balet menari di atas pencakar langit

Golden retriever sedang makan ais krim (cakar telah berkembang) di pantai tropika yang indah pada musim panas

Pemilik kucing sedang menonton TV dengan alat kawalan jauh (kaki telah berkembang)

Teddy bear memberikan Lukis potret diri anda sendiri

Tidak dijangka tetapi munasabah, anjing itu mengambil ais krim, kucing mengambil alat kawalan jauh dan teddy bear melukis " "Tangan" memang "berkembang" seperti manusia! (Tactical Backward)
Sudah tentu, selain menukar teks kepada video, Make-A-Video juga boleh menukar imej statik kepada Gif.
Input:

Output:

Input:

Output: (Cahaya kelihatan agak tidak pada tempatnya)

2 imej statik ke GIF, masukkan imej meteorit

Output:

Dan, jadikan video itu sebagai video?
Input:

Output:

Input:

Output:

Prinsip Teknikal
Hari ini, Meta mengeluarkan penyelidikan terbarunya MAKE-A-VIDEO: TEKS-TO-VIDEO GENERATION TANPA TEKS-VIDEO DATA.

Alamat kertas: https://makeavideo.studio/Make-A-Video.pdf
Sebelum model ini muncul, kami sudah mempunyai Stable Diffusion.
Saintis pintar telah meminta AI untuk menghasilkan imej dengan hanya satu ayat Apakah yang akan mereka lakukan seterusnya?
Jelas sekali, ia menjana video.

Anjing superhero memakai jubah merah terbang di langit
Berbanding dengan menjana imej, menjana video adalah lebih sukar. Kita bukan sahaja perlu menjana berbilang bingkai subjek dan pemandangan yang sama, kita juga perlu menjadikannya tepat pada masanya dan koheren.
Ini meningkatkan kerumitan tugas penjanaan imej - kita tidak boleh menggunakan DALLE untuk menjana 60 imej dan kemudian mencantumkannya ke dalam video. Kesannya akan menjadi sangat buruk dan tidak realistik.
Oleh itu, kita memerlukan model yang boleh memahami dunia dengan cara yang lebih berkuasa, dan membolehkannya menjana satu siri imej yang koheren berdasarkan tahap pemahaman ini. Hanya selepas itu imej boleh digabungkan dengan lancar.
Dalam erti kata lain, matlamat kami adalah untuk mensimulasikan dunia dan kemudian mensimulasikan rekodnya. Bagaimana untuk melakukannya?

Menurut idea terdahulu, penyelidik akan menggunakan sebilangan besar pasangan teks-video untuk melatih model, tetapi dalam keadaan semasa, kaedah pemprosesan ini tidak realistik. Kerana data ini sukar diperoleh dan kos latihan sangat mahal.
Oleh itu, para penyelidik membuka minda mereka dan menggunakan pendekatan yang sama sekali baru.
Mereka memilih untuk membangunkan model teks ke imej dan kemudian menggunakannya pada video.
Kebetulan, suatu ketika dahulu, Meta membangunkan Make-A-Scene, model daripada teks ke imej.
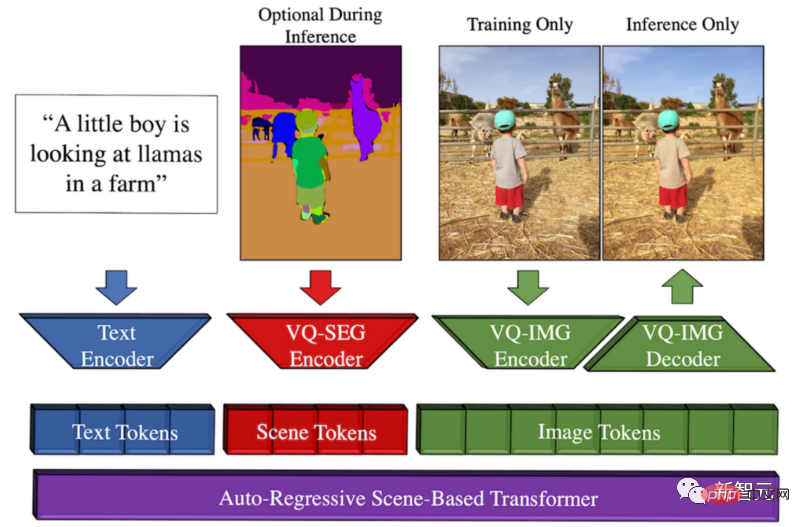
Ikhtisar kaedah Make-A-Scene
Model ini menjana Peluangnya ialah Meta ingin mempromosikan ekspresi kreatif, menggabungkan trend teks-ke-imej ini dengan model lakaran-ke-imej sebelumnya, menghasilkan gabungan yang indah antara teks dan penjanaan imej terkondisi lakaran.
Ini bermakna kita boleh dengan cepat melakar kucing dan menulis jenis imej yang kita mahukan. Mengikuti panduan lakaran dan teks, model ini akan menghasilkan ilustrasi sempurna yang kita inginkan dalam beberapa saat.

Anda boleh menganggap pendekatan AI generatif pelbagai mod ini sebagai model Dall-E dengan lebih kawalan ke atas penjanaan kerana lakaran pantas juga boleh digunakan sebagai input.
Sebab mengapa ia dipanggil berbilang modal adalah kerana ia boleh mengambil berbilang modaliti sebagai input, seperti teks dan imej. Sebaliknya, Dall-E hanya boleh menjana imej daripada teks.
Untuk menghasilkan video, adalah perlu untuk menambah dimensi masa, jadi penyelidik menambah saluran paip spatio-temporal pada model Make-A-Scene.
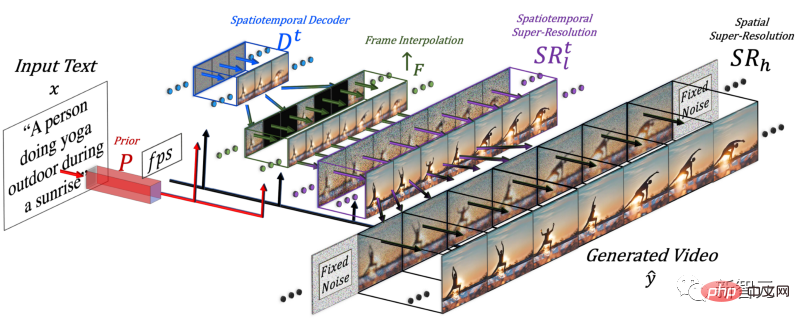
Selepas menambah dimensi masa, model ini tidak menjana hanya satu imej, tetapi menjana 16 imej resolusi rendah untuk mencipta video pendek yang koheren .
Kaedah ini sebenarnya serupa dengan model teks-ke-imej, tetapi perbezaannya ialah ia menambah konvolusi satu dimensi berdasarkan konvolusi dua dimensi konvensional.
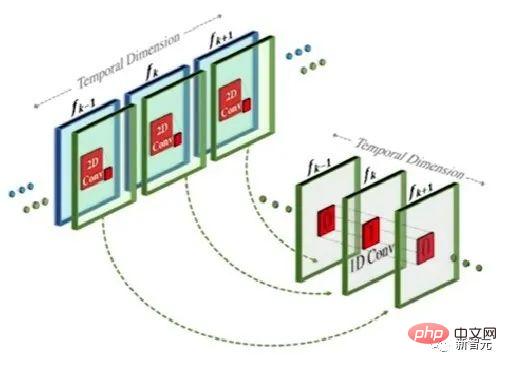
Dengan hanya menambah konvolusi satu dimensi, penyelidik dapat memastikan konvolusi dua dimensi yang telah dilatih tidak berubah sambil menambah dimensi masa . Penyelidik kemudian boleh melatih dari awal, menggunakan semula kebanyakan kod dan parameter model imej Make-A-Scene.
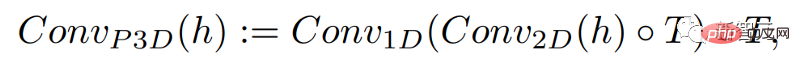
Pada masa yang sama, penyelidik juga ingin menggunakan input teks untuk membimbing model ini, yang akan sangat serupa dengan model imej menggunakan CLIP membenamkan.
Dalam kes ini, penyelidik meningkatkan dimensi spatial apabila mencampurkan ciri teks dengan ciri imej, menggunakan kaedah yang sama seperti di atas: mengekalkan modul perhatian dalam model Make-A-Scene , dan tambah modul perhatian satu dimensi untuk masa - salin-tampal model penjana imej, ulang modul penjanaan untuk satu dimensi lagi untuk mendapatkan 16 bingkai awal.
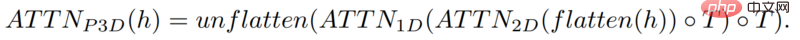
Tetapi hanya bergantung pada 16 bingkai awal ini, video tidak boleh dijana.
Penyelidik perlu menghasilkan video definisi tinggi daripada 16 bingkai utama ini. Pendekatan mereka adalah untuk mengakses bingkai sebelumnya dan akan datang dan menginterpolasinya secara berulang dalam kedua-dua dimensi temporal dan ruang secara serentak.
Dengan cara ini, antara 16 bingkai awal ini, mereka menghasilkan bingkai baharu yang lebih besar berdasarkan bingkai sebelum dan selepas, supaya pergerakan menjadi koheren dan keseluruhan video menjadi Mesti lancar .
Ini dilakukan melalui rangkaian interpolasi bingkai, yang boleh mengambil imej sedia ada untuk mengisi jurang dan menjana maklumat perantaraan. Dalam dimensi spatial, ia melakukan perkara yang sama: membesarkan imej, mengisi ruang dalam piksel dan menjadikan imej lebih definisi tinggi.

Untuk meringkaskan, untuk menjana video, penyelidik memperhalusi model teks-ke-imej. Mereka mengambil model berkuasa yang telah dilatih, diubah suai dan dilatih agar sesuai dengan video.
Oleh kerana penambahan modul spatial dan temporal, anda boleh menyesuaikan model dengan data baharu ini tanpa perlu melatihnya semula, yang menjimatkan banyak kos.
Latihan semula jenis ini menggunakan video tidak berlabel dan hanya perlu mengajar model untuk memahami ketekalan video dan bingkai video, yang menjadikannya lebih mudah untuk membina set data.
Akhir sekali, penyelidik sekali lagi menggunakan model pengoptimuman imej untuk memperbaik resolusi spatial dan menggunakan komponen interpolasi bingkai untuk menambah lebih banyak bingkai untuk menjadikan video lebih lancar.
Sudah tentu, hasil semasa Make-A-Video masih mempunyai kekurangan, sama seperti model teks-ke-imej. Tetapi kita semua tahu betapa pesatnya kemajuan dalam bidang AI.
Kalau nak tahu lebih lanjut, boleh rujuk kertas Meta AI di link. Komuniti juga sedang membangunkan pelaksanaan PyTorch, jadi nantikan jika anda mahu melaksanakannya sendiri.
Pengenalan Pengarang
Sebilangan penyelidik Cina mengambil bahagian dalam kertas kerja ini: Yin Xi, An Jie, Zhang Songyang , Qiyuan Hu .
Yin Xi, saintis penyelidikan FAIR. Sebelum ini bekerja untuk Microsoft sebagai saintis aplikasi kanan untuk Microsoft Cloud dan AI. Beliau menerima PhD dari Jabatan Sains Komputer dan Kejuruteraan di Michigan State University dan ijazah sarjana muda dalam kejuruteraan elektrik dari Universiti Wuhan pada 2013. Bidang penyelidikan utama ialah pemahaman pelbagai modal, pengesanan sasaran berskala besar, penaakulan muka, dsb.
Anjie ialah pelajar kedoktoran di Jabatan Sains Komputer di Universiti Rochester. Kajian di bawah Profesor Roger Bo. Sebelum ini menerima ijazah sarjana muda dan sarjana dari Universiti Peking pada 2016 dan 2019. Minat penyelidikan termasuk penglihatan komputer, model generatif mendalam dan seni AI+. Mengambil bahagian dalam penyelidikan Make-A-Video sebagai pelatih.
Zhang Songyang ialah pelajar kedoktoran di Jabatan Sains Komputer di Universiti Rochester, belajar di bawah Profesor Roger Bo. Beliau menerima ijazah sarjana muda dari Universiti Tenggara dan ijazah sarjana dari Universiti Zhejiang. Minat penyelidikan termasuk penyetempatan detik bahasa semula jadi, induksi tatabahasa tanpa pengawasan, pengecaman tindakan berasaskan rangka, dsb. Mengambil bahagian dalam penyelidikan Make-A-Video sebagai pelatih.
Qiyuan Hu, yang ketika itu merupakan Residen AI di FAIR, terlibat dalam penyelidikan tentang model generatif pelbagai mod yang meningkatkan kreativiti manusia. Beliau menerima PhD dalam fizik perubatan dari University of Chicago dan bekerja pada analisis imej perubatan berbantukan AI. Kini bekerja di Tempus Labs sebagai saintis pembelajaran mesin.
Netizen terkejut
Beberapa ketika dahulu, syarikat besar seperti Google mengeluarkan model teks-ke-imej mereka sendiri, seperti Parti, dsb.
Malah ada yang berpendapat bahawa model generatif teks-ke-video masih lagi agak lama.
Tidak disangka-sangka, Meta membuat kejutan kali ini.
Malah, hari ini, terdapat juga model penjanaan teks-ke-video Phenaki, yang telah diserahkan kepada ICLR 2023. Memandangkan ia masih dalam peringkat semakan buta, institusi penulis masih tidak diketahui.

Netizen berkata daripada DALLE hingga Stable Diffuson hingga Make-A-Video, semuanya berlaku terlalu pantas.

Atas ialah kandungan terperinci Model SOTA yang inovatif Meta boleh menghasilkan video yang menakjubkan berdasarkan satu ayat, mencetuskan kegilaan Internet!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI