
Rumah >Peranti teknologi >AI >Menggunakan berbilang API ChatGPT untuk melaksanakan perbualan berbilang pusingan Tsinghua UltraChat
Menggunakan berbilang API ChatGPT untuk melaksanakan perbualan berbilang pusingan Tsinghua UltraChat

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-22 20:37:061106semak imbas
Sejak keluaran ChatGPT, populariti model perbualan hanya meningkat dalam tempoh ini. Walaupun kami mengagumi prestasi menakjubkan model ini, kami juga harus meneka kuasa pengkomputeran yang besar dan sokongan data yang besar di belakangnya.
Mengenai data, data berkualiti tinggi adalah penting, jadi OpenAI telah meletakkan banyak usaha dalam kerja data dan anotasi. Berbilang kajian telah menunjukkan bahawa ChatGPT ialah pencatat data yang lebih dipercayai daripada manusia Jika komuniti sumber terbuka boleh memperoleh sejumlah besar data dialog daripada model bahasa yang berkuasa seperti ChatGPT, ia boleh melatih model dialog dengan prestasi yang lebih baik. Ini dibuktikan oleh keluarga model Alpaca - Alpaca, Vicuna, Koala. Sebagai contoh, Vicuna mereplikasi kejayaan sembilan langkah ChatGPT dengan arahan penalaan halus untuk model LLaMA menggunakan data perkongsian pengguna yang dikumpul daripada ShareGPT. Bukti yang semakin bertambah menunjukkan bahawa data ialah produktiviti utama untuk melatih model bahasa yang berkuasa.
ShareGPT ialah tapak web perkongsian data ChatGPT di mana pengguna memuat naik jawapan ChatGPT yang mereka rasa menarik. Data pada ShareGPT adalah terbuka tetapi remeh dan perlu dikumpul dan disusun oleh penyelidik sendiri. Jika terdapat set data yang berkualiti tinggi dan luas, komuniti sumber terbuka akan mendapat dua kali ganda hasil dengan separuh usaha dalam membangunkan model perbualan.
Berdasarkan perkara ini, projek terbaru yang dipanggil UltraChat secara sistematik membina set data perbualan berkualiti ultra tinggi. Pengarang projek cuba menggunakan dua API Turbo ChatGPT bebas untuk menjalankan perbualan bagi menjana berbilang pusingan data perbualan.
- Alamat projek: https://github.com/thunlp/UltraChat
- Alamat set data: http://39.101.77.220/
- Alamat interaksi set data: https://atlas. ai/map/0ce65783-c3a9-40b5-895d-384933f50081/a7b46301-022f-45d8-bbf4-98107eabdbac

- secara keseluruhannya sumber terbuka, berskala besar, data dialog berbilang pusingan berdasarkan API Turbo untuk memudahkan penyelidik membangunkan model bahasa yang berkuasa dengan keupayaan dialog universal. Di samping itu, dengan mengambil kira perlindungan privasi dan faktor lain, projek itu tidak akan secara langsung menggunakan data di Internet sebagai gesaan. Untuk memastikan kualiti data yang dijana, penyelidik menggunakan dua API Turbo ChatGPT bebas dalam proses penjanaan, di mana satu model memainkan peranan pengguna untuk menjana soalan atau arahan, dan model lain menjana maklum balas.
- Jika anda terus menggunakan ChatGPT untuk menjananya secara bebas berdasarkan beberapa perbualan dan soalan benih, mudah untuk menghadapi masalah seperti topik tunggal dan berulang kandungan, menjadikannya sukar untuk menjamin kepelbagaian itu sendiri. Untuk tujuan ini, UltraChat telah mengklasifikasikan dan mereka bentuk topik dan jenis tugasan yang diliputi oleh data perbualan secara sistematik, dan juga menjalankan kejuruteraan segera terperinci untuk model pengguna dan model balasan Ia mengandungi tiga bahagian:
Soalan tentang Dunia: Bahagian perbualan ini datang daripada pertanyaan luas tentang konsep, entiti dan objek di dunia nyata. Topik meliputi bidang teknologi, seni, kewangan dan lain-lain.
Penulisan dan Penciptaan: Bahagian data perbualan ini memfokuskan pada mengarahkan AI untuk mencipta bahan teks yang lengkap dari awal, dan berdasarkan ini, soalan susulan atau panduan lanjut Untuk meningkatkan penulisan anda, jenis kandungan termasuk artikel, blog, puisi, cerita, drama, e-mel dan banyak lagi. Penulisan semula berbantu (Penulisan dan Penciptaan) data sedia ada: Data dialog dijana berdasarkan data sedia ada termasuk tetapi tidak terhad kepada penulisan semula, kesinambungan, terjemahan, induksi, penaakulan, dan lain-lain, dan topik yang dibincangkan juga sangat pelbagai. Tiga bahagian data ini meliputi kebanyakan keperluan pengguna untuk model AI. Pada masa yang sama, ketiga-tiga jenis data ini juga akan menghadapi cabaran yang berbeza dan memerlukan kaedah pembinaan yang berbeza.Sebagai contoh, cabaran utama bahagian pertama data ialah bagaimana untuk merangkumi pengetahuan umum dalam masyarakat manusia seluas mungkin dalam jumlah ratusan ribu perbualan Untuk tujuan ini, penyelidik bermula dari topik dan sumber yang dijana secara automatik daripada Wikidata Dua aspek entiti ditapis dan dibina.
Cabaran di bahagian kedua dan ketiga terutamanya datang daripada cara mensimulasikan arahan pengguna dan menjadikan penjanaan model pengguna sepelbagai mungkin dalam perbualan seterusnya tanpa menyimpang daripada matlamat utama perbualan ( Hasilkan bahan atau tulis semula bahan seperti yang diperlukan), yang mana penyelidik telah mereka bentuk dan bereksperimen sepenuhnya dengan gesaan input model pengguna. Selepas pembinaan siap, penulis juga melakukan pasca pemprosesan data untuk melemahkan masalah halusinasi.
Pada masa ini, projek itu telah mengeluarkan dua bahagian pertama data, dengan volum data 1.24 juta, yang sepatutnya menjadi set data berkaitan terbesar dalam komuniti sumber terbuka. Kandungan mengandungi perbualan yang kaya dan berwarna-warni di dunia nyata, dan bahagian akhir data akan dikeluarkan pada masa hadapan.
Data isu dunia datang daripada 30 perwakilan dan meta-tema yang pelbagai, seperti ditunjukkan dalam rajah di bawah:

- Berdasarkan meta-topik di atas, projek menghasilkan 1100+ sub-topik untuk pembinaan data; -topik topik, hasilkan sehingga 10 soalan khusus; 🎜 >Untuk setiap soalan, gunakan kedua-dua model secara berulang seperti yang diterangkan di atas untuk menjana 3~7 pusingan dialog.
- Selain itu, projek itu mengumpulkan 10,000 entiti bernama yang paling biasa digunakan daripada Wikidata menggunakan API ChatGPT untuk menjana 5 soalan meta bagi setiap entiti, 10 soalan yang lebih khusus dan 20 soalan yang berkaitan tetapi umum telah dihasilkan; 200,000 soalan khusus, 250,000 soalan umum dan 50,000 soalan meta telah dijadikan sampel, dan 3~7 pusingan dialog telah dihasilkan untuk setiap soalan.
- Seterusnya mari kita lihat contoh khusus:
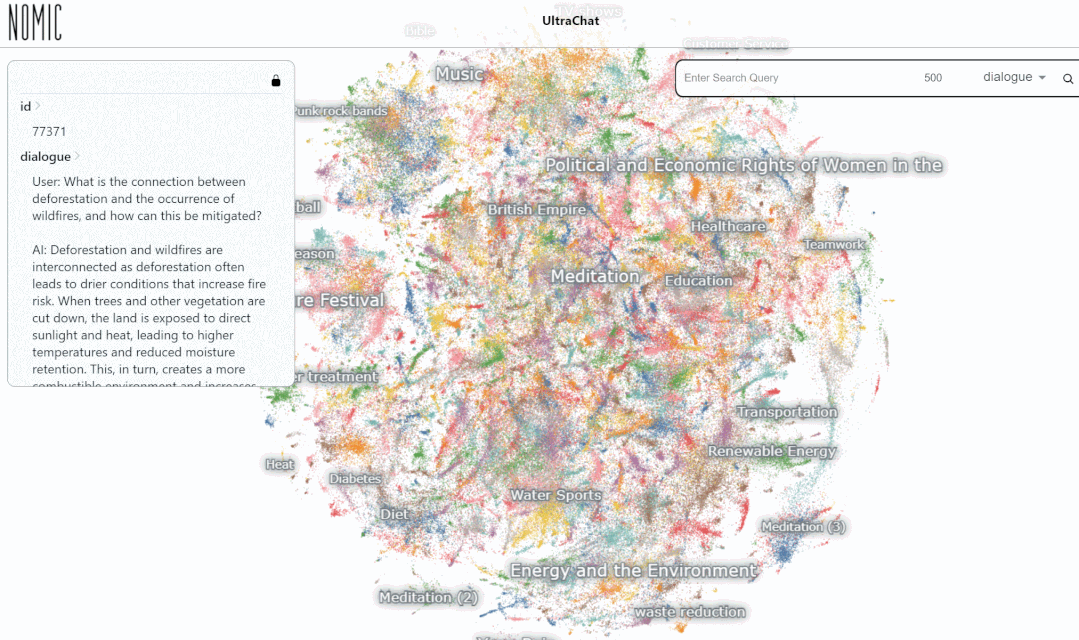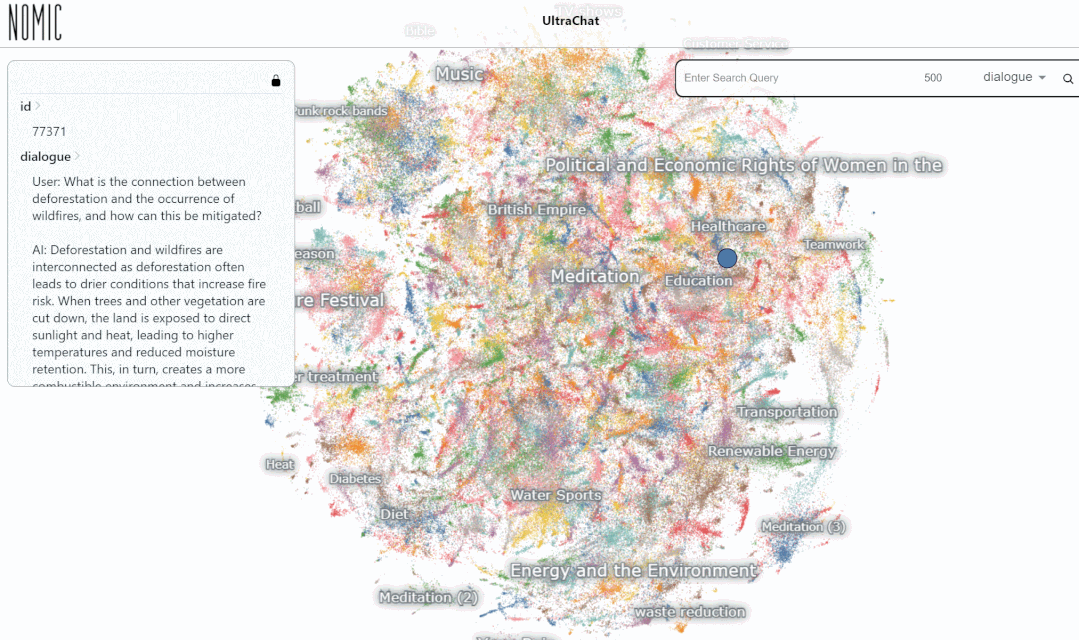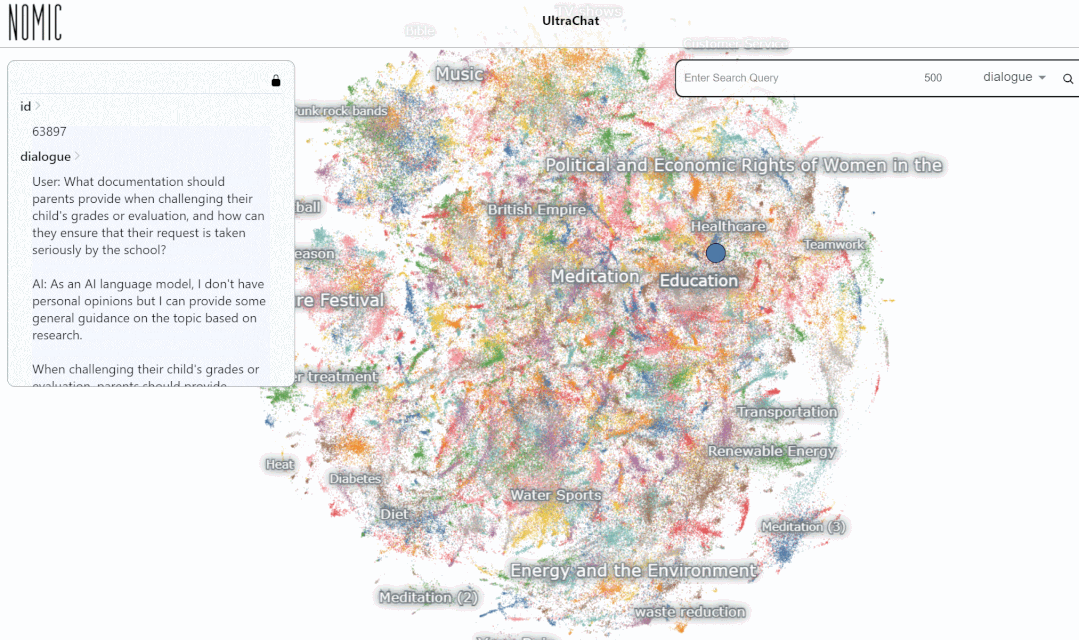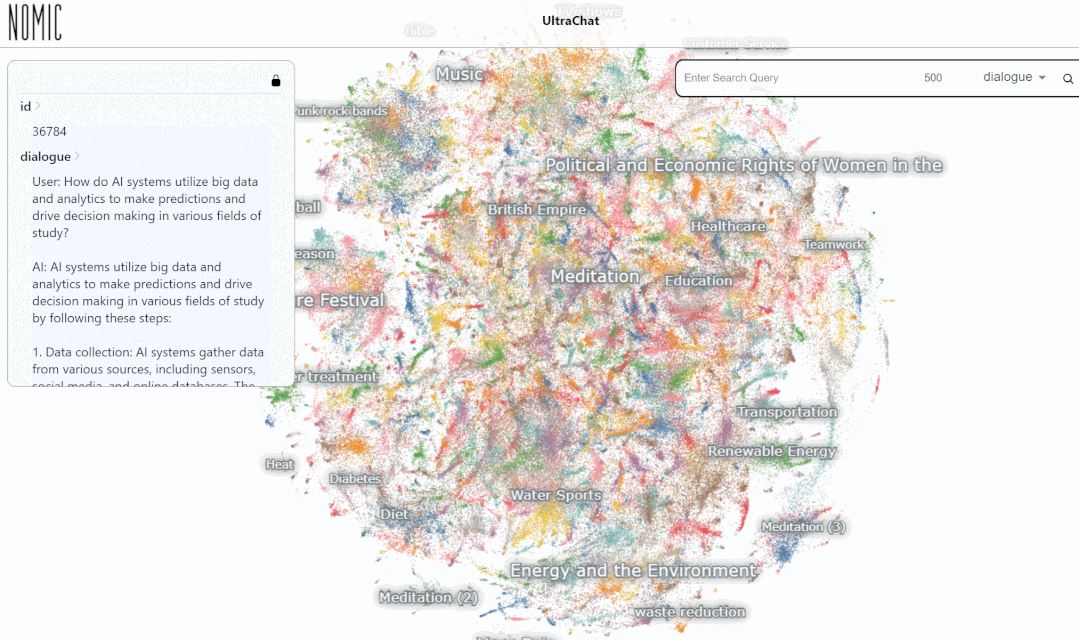
Kami menguji data pada Carian platform UltraChat keputusan. Contohnya, jika anda memasukkan "muzik", sistem akan mencari secara automatik 10,000 set data perbualan ChatGPT berkaitan muzik dan setiap set ialah perbualan berbilang pusingan
Hasil carian untuk memasukkan kata kunci "matematik" menunjukkan 3346 perbualan berbilang pusingan:

Pada masa ini, UltraChat merangkumi Terdapat sudah banyak bidang maklumat, termasuk perubatan, pendidikan, sukan, perlindungan alam sekitar dan topik lain. Pada masa yang sama, penulis cuba menggunakan model LLaMa-7B sumber terbuka untuk melakukan penalaan halus arahan diselia pada UltraChat, dan mendapati bahawa selepas hanya 10,000 langkah latihan, terdapat hasil yang sangat mengagumkan adalah seperti berikut:

Pengetahuan Dunia: Senaraikan 10 universiti China dan Amerika yang baik masing-masing

Soalan imaginasi: Apabila perjalanan angkasa lepas menjadi mungkin, apakah akibat yang mungkin berlaku?
Silogisme: Adakah ikan paus ikan?

Soalan hipotesis: Buktikan bahawa Jackie Chan lebih baik daripada Bruce Lee
Secara umumnya, UltraChat ialah set data perbualan ChatGPT yang berkualiti tinggi dan luas yang boleh digabungkan dengan set data lain untuk meningkatkan kualiti model perbualan sumber terbuka dengan ketara. Pada masa ini, UltraChat hanya mengeluarkan versi bahasa Inggeris, tetapi ia juga akan mengeluarkan versi Cina data pada masa hadapan. Pembaca yang berminat dialu-alukan untuk menerokainya.
Atas ialah kandungan terperinci Menggunakan berbilang API ChatGPT untuk melaksanakan perbualan berbilang pusingan Tsinghua UltraChat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI