
Rumah >Peranti teknologi >AI >'Daripada GAN ke ChatGPT: Universiti Lehigh memperincikan pembangunan kandungan yang dijana AI'
'Daripada GAN ke ChatGPT: Universiti Lehigh memperincikan pembangunan kandungan yang dijana AI'

- 王林ke hadapan
- 2023-04-20 17:55:081236semak imbas
ChatGPT dan teknologi AI generatif (GAI) lain termasuk dalam kategori Kandungan Dijana Kecerdasan Buatan (AIGC), yang melibatkan penciptaan kandungan digital seperti imej, muzik dan bahasa semula jadi melalui model AI. Matlamat AIGC adalah untuk menjadikan proses penciptaan kandungan lebih cekap dan boleh diakses, membolehkan penghasilan kandungan berkualiti tinggi pada kadar yang lebih pantas. AIGC dicapai dengan mengekstrak dan memahami maklumat niat daripada arahan yang disediakan oleh manusia, dan menjana kandungan berdasarkan pengetahuan dan maklumat niat mereka.
Dalam beberapa tahun kebelakangan ini, model berskala besar telah menjadi semakin penting dalam AIGC kerana ia menyediakan pengekstrakan niat yang lebih baik, sekali gus meningkatkan hasil penjanaan. Apabila data dan saiz model berkembang, pengedaran yang boleh dipelajari oleh model menjadi lebih komprehensif dan lebih dekat dengan realiti, menghasilkan kandungan yang lebih realistik dan berkualiti tinggi.
Artikel ini menyediakan ulasan menyeluruh tentang sejarah, komponen asas dan kemajuan terkini AIGC, daripada interaksi mod tunggal kepada interaksi berbilang modal. Dari perspektif mod tunggal, tugas penjanaan teks dan imej serta model berkaitan diperkenalkan. Dari perspektif multimodal, aplikasi silang antara modaliti di atas diperkenalkan. Akhir sekali, isu terbuka dan cabaran masa depan AIGC dibincangkan.

Alamat kertas: https://arxiv.org/abs/2303.04226
Pengenalan
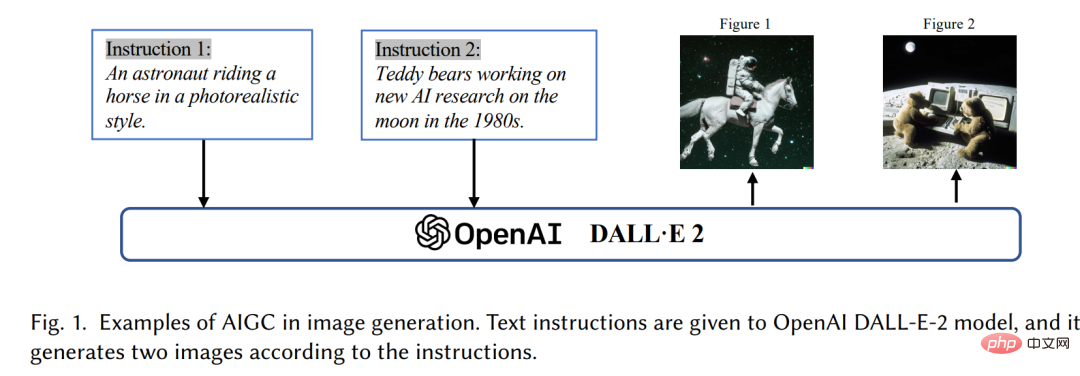
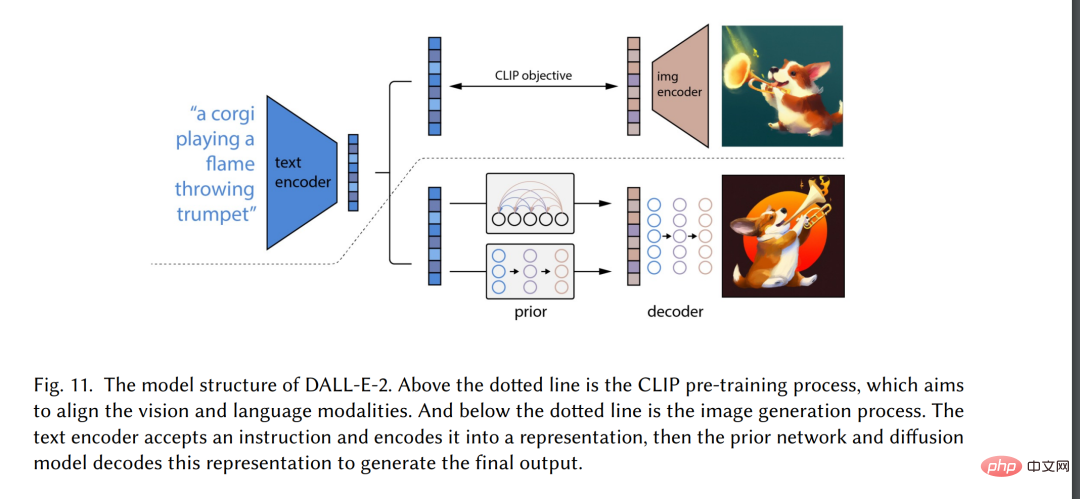
Dalam beberapa tahun kebelakangan ini, Artificial Intelligence Generated Content (AIGC) telah mendapat perhatian meluas di luar komuniti sains komputer, dan seluruh masyarakat telah mula memberi perhatian kepada syarikat teknologi besar [3 ] membina pelbagai produk penjanaan kandungan, seperti ChatGPT[4] dan DALL-E2[5]. AIGC merujuk kepada kandungan yang dijana menggunakan teknologi AI generatif termaju (GAI), bukannya kandungan yang dicipta oleh pengarang manusia secara automatik boleh mencipta sejumlah besar kandungan dalam tempoh yang singkat. Contohnya, ChatGPT ialah model bahasa yang dibangunkan oleh OpenAI untuk membina sistem kecerdasan buatan perbualan yang boleh memahami dan bertindak balas secara berkesan kepada input bahasa manusia dengan cara yang bermakna. Selain itu, DALL-E-2 ialah satu lagi model GAI tercanggih, juga dibangunkan oleh OpenAI, yang mampu mencipta imej unik berkualiti tinggi daripada penerangan teks dalam beberapa minit, seperti yang ditunjukkan dalam Rajah 1 "Seorang angkasawan dengan menunggang kuda dalam gaya realistik". Dengan pencapaian cemerlang AIGC, ramai orang percaya bahawa ini akan menjadi era baharu kecerdasan buatan dan akan memberi impak yang besar kepada seluruh dunia.
Secara teknikal, AIGC merujuk kepada arahan manusia yang diberikan yang boleh membantu mengajar dan membimbing penyiapan model Tugas, gunakan Algoritma GAI untuk menjana kandungan yang memenuhi arahan. Proses penjanaan biasanya merangkumi dua langkah: mengekstrak maklumat niat daripada arahan manusia dan menjana kandungan berdasarkan niat yang diekstrak. Walau bagaimanapun, seperti yang ditunjukkan dalam kajian terdahulu [6,7], paradigma model GAI yang mengandungi dua langkah di atas bukanlah novel sepenuhnya. Berbanding dengan kerja sebelumnya, kemajuan teras AIGC baru-baru ini adalah untuk melatih model generatif yang lebih kompleks pada set data yang lebih besar, menggunakan seni bina model asas yang lebih besar, dan mempunyai akses kepada pelbagai sumber pengkomputeran. Sebagai contoh, rangka kerja utama GPT-3 kekal sama seperti GPT-2, tetapi saiz data pra-latihan meningkat daripada WebText [8] (38GB) kepada CommonCrawl [9] (570GB selepas penapisan), dan saiz model asas meningkat daripada 1.5B kepada 175B. Oleh itu, GPT-3 mempunyai keupayaan generalisasi yang lebih baik daripada GPT-2 pada tugas-tugas seperti pengekstrakan niat manusia.
Selain faedah peningkatan volum data dan kuasa pengkomputeran, penyelidik juga meneroka cara untuk menyepadukan teknologi baharu dengan algoritma GAI. Sebagai contoh, ChatGPT menggunakan pembelajaran pengukuhan daripada maklum balas manusia (RLHF) [10-12] untuk menentukan tindak balas yang paling sesuai kepada arahan yang diberikan, dengan itu meningkatkan kebolehpercayaan dan ketepatan model dari semasa ke semasa. Pendekatan ini membolehkan ChatGPT lebih memahami pilihan manusia dalam perbualan yang panjang. Pada masa yang sama, dalam bidang penglihatan komputer, resapan stabil telah dicadangkan oleh Kestabilan [13]. AI juga telah mencapai kejayaan besar dalam penjanaan imej pada tahun 2022. Tidak seperti kaedah sebelumnya, model resapan generatif boleh membantu menjana imej resolusi tinggi dengan mengawal pertukaran antara penerokaan dan eksploitasi, dengan itu menggabungkan secara harmoni kepelbagaian imej yang dijana dan persamaannya dengan data latihan.
Menggabungkan kemajuan ini, model ini telah mencapai kemajuan yang ketara dalam tugas AIGC dan telah digunakan untuk pelbagai industri, termasuk seni [14], pengiklanan [15], pendidikan [16], dsb. Dalam masa terdekat, AIGC akan terus menjadi bidang penyelidikan penting dalam pembelajaran mesin. Oleh itu, adalah penting untuk menjalankan tinjauan menyeluruh terhadap penyelidikan lepas dan mengenal pasti soalan terbuka di lapangan. Teknologi teras dan aplikasi dalam bidang AIGC dikaji semula.
Ini ialah semakan komprehensif pertama AIGC, meringkaskan GAI dari aspek teknikal dan aplikasi. Penyelidikan terdahulu telah memberi tumpuan kepada GAI dari perspektif yang berbeza, termasuk penjanaan bahasa semula jadi [17], penjanaan imej [18], dan penjanaan dalam pembelajaran mesin pelbagai mod [7, 19]. Walau bagaimanapun, kerja sebelum ini hanya tertumpu pada bahagian tertentu AIGC. Artikel ini mula-mula mengkaji teknik asas yang biasa digunakan dalam AIGC. Ringkasan komprehensif algoritma GAI lanjutan disediakan lagi, termasuk penjanaan puncak tunggal dan penjanaan berbilang puncak, seperti yang ditunjukkan dalam Rajah 2. Selain itu, aplikasi dan potensi cabaran AIGC dibincangkan. Akhir sekali, masalah sedia ada dan hala tuju penyelidikan masa depan dalam bidang ini ditunjukkan. Ringkasnya, sumbangan utama kertas kerja ini adalah seperti berikut:
- Sepanjang pengetahuan kami, kami adalah yang pertama memberikan definisi formal dan Seseorang yang menyelidik secara menyeluruh.
- Menyemak sejarah dan teknologi asas AIGC, dan menjalankan analisis komprehensif tentang kemajuan terkini tugasan dan model GAI dari perspektif penjanaan mod tunggal dan penjanaan pelbagai mod.
- Membincangkan cabaran utama yang dihadapi AIGC dan trend penyelidikan AIGC pada masa hadapan.
Baki tinjauan disusun seperti berikut. Bahagian 2 terutamanya mengkaji sejarah AIGC dari dua aspek: modaliti visual dan modaliti bahasa. Bahagian 3 memperkenalkan komponen asas yang kini digunakan secara meluas dalam latihan model GAI. Bahagian 4 meringkaskan kemajuan terkini dalam model GAI, di mana Bahagian 4.1 menyemak kemajuan daripada perspektif modal tunggal dan Bahagian 4.2 menyemak kemajuan daripada perspektif penjanaan pelbagai mod. Dalam penjanaan multimodal, model bahasa visual, model audio teks, model graf teks dan model kod teks diperkenalkan. Bahagian 5 dan 6 memperkenalkan aplikasi model GAI dalam AIGC dan beberapa penyelidikan penting yang berkaitan dengan bidang ini. Bahagian 7 dan 8 mendedahkan risiko, masalah sedia ada dan hala tuju pembangunan masa depan teknologi AIGC. Akhirnya, kami meringkaskan kajian kami dalam 9.
Sejarah Kepintaran Buatan Generatif
Model generatif mempunyai sejarah yang panjang dalam bidang kecerdasan buatan, sejak tahun 1950-an, dengan Model Markov Tersembunyi (HMM) )[20] dan pembangunan model campuran Gaussian (GMMs)[21]. Model ini menjana data berurutan seperti pertuturan dan siri masa. Walau bagaimanapun, barulah kemunculan pembelajaran mendalam barulah model generatif melihat peningkatan yang ketara dalam prestasi.
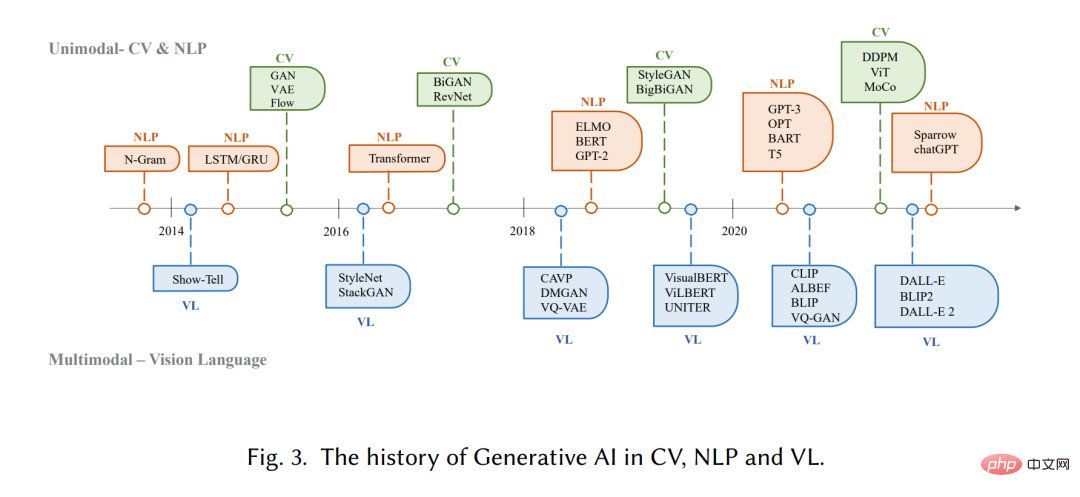
Dalam model generatif dalam awal, domain yang berbeza biasanya tidak banyak bertindih. Dalam pemprosesan bahasa semula jadi (NLP), kaedah tradisional untuk menghasilkan ayat ialah menggunakan pemodelan bahasa N-gram [22] untuk mempelajari pengedaran perkataan dan kemudian mencari urutan yang terbaik. Walau bagaimanapun, kaedah ini tidak dapat menyesuaikan diri dengan ayat yang panjang. Untuk menyelesaikan masalah ini, Rangkaian Neural Berulang (RNN) [23] kemudiannya diperkenalkan kepada tugas pemodelan bahasa, membolehkan kebergantungan yang agak panjang dimodelkan. Selepas itu, pembangunan ingatan jangka pendek panjang (LSTM) [24] dan unit berulang berpagar (GRU) [25], yang menggunakan mekanisme gating untuk mengawal ingatan semasa latihan. Kaedah ini mampu mengendalikan ~200 token dalam sampel [26], yang merupakan peningkatan yang ketara berbanding model bahasa N-gram.
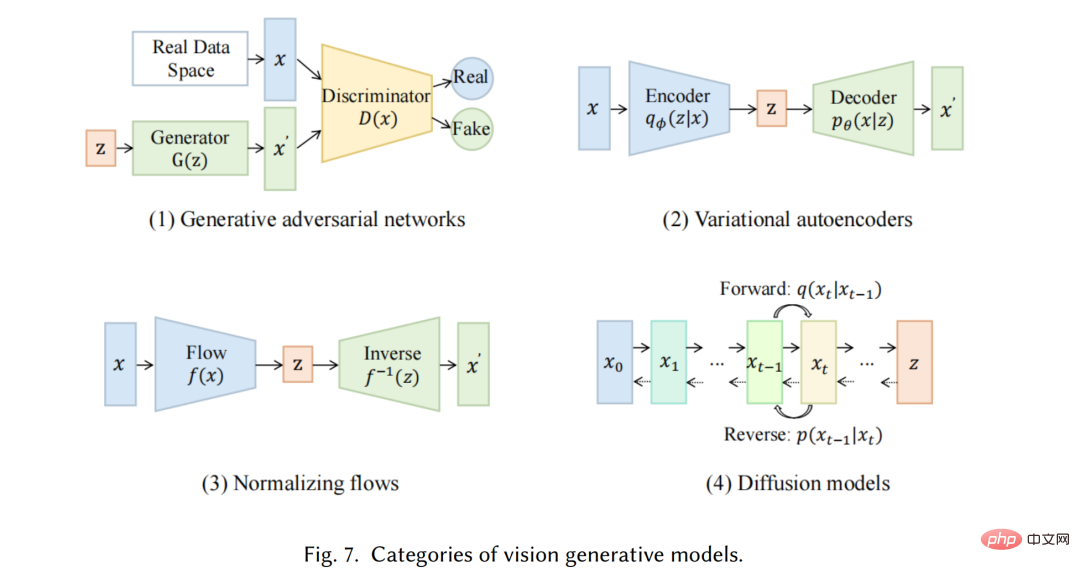
Sementara itu, dalam bidang penglihatan komputer (CV), sebelum kemunculan kaedah berasaskan pembelajaran mendalam, algoritma penjanaan imej tradisional menggunakan teknik seperti sintesis tekstur [27] dan pemetaan tekstur [28] . Algoritma ini berdasarkan ciri rekaan tangan dan mempunyai keupayaan terhad dalam menghasilkan imej yang kompleks dan pelbagai. Pada 2014, Generative Adversarial Networks (GANs) [29] pertama kali dicadangkan dan mencapai hasil yang mengagumkan dalam pelbagai aplikasi, yang merupakan pencapaian penting dalam bidang tersebut. Pengekod auto variasi (VAE) [30] dan kaedah lain, seperti model penjanaan resapan [31], juga telah dibangunkan untuk kawalan halus proses penjanaan imej dan keupayaan untuk menjana imej berkualiti tinggi
Pembangunan model generatif dalam bidang yang berbeza mengikut laluan yang berbeza, tetapi akhirnya masalah keratan rentas timbul: seni bina transformer [32]. Vaswani et al. memperkenalkan tugas NLP pada tahun 2017, dan Transformer kemudiannya digunakan untuk CV, dan kemudian menjadi tulang belakang utama banyak model generatif dalam bidang yang berbeza [9, 33, 34]. Dalam bidang NLP, banyak model bahasa berskala besar yang terkenal, seperti BERT dan GPT, menggunakan seni bina transformer sebagai blok bangunan utama mereka, yang mempunyai kelebihan berbanding blok bangunan sebelumnya seperti LSTM dan GRU. Dalam CV, Vision Transformer (ViT) [35] dan Swin Transformer [36] kemudiannya mengembangkan lagi konsep ini dengan menggabungkan seni bina Transformer dengan komponen penglihatan supaya ia boleh digunakan pada hiliran berasaskan imej. Sebagai tambahan kepada penambahbaikan yang dibawa oleh transformer kepada modaliti individu, crossover ini juga membolehkan model dari domain yang berbeza digabungkan bersama untuk menyelesaikan tugas berbilang modal. Contoh model multimodal ialah CLIP [37]. CLIP ialah model bahasa penglihatan bersama yang menggabungkan seni bina pengubah dengan komponen penglihatan, membolehkannya dilatih mengenai sejumlah besar data teks dan imej. Memandangkan ia menggabungkan pengetahuan visual dan linguistik semasa pra-latihan, ia juga boleh digunakan sebagai pengekod imej dalam penjanaan kiu berbilang modal. Secara keseluruhannya, kemunculan model berasaskan pengubah telah merevolusikan pengeluaran kecerdasan buatan dan membawa kepada kemungkinan latihan berskala besar.
Dalam beberapa tahun kebelakangan ini, penyelidik juga telah mula memperkenalkan teknologi baharu berdasarkan model ini. Sebagai contoh, dalam NLP, orang kadangkala lebih suka petunjuk beberapa tangkapan [38] daripada penalaan halus, yang merujuk kepada memasukkan dalam pembayang beberapa contoh yang dipilih daripada set data untuk membantu model memahami dengan lebih baik keperluan tugasan. Dalam bahasa visual, penyelidik sering menggabungkan model khusus modaliti dengan objektif pembelajaran kontrastif yang diselia sendiri untuk memberikan perwakilan yang lebih mantap. Pada masa hadapan, apabila AIGC menjadi semakin penting, semakin banyak teknologi akan diperkenalkan, menjadikan bidang ini penuh dengan daya hidup.
Kecerdasan Buatan Generatif
Kami akan memperkenalkan mod tunggal tercanggih model generatif. Model ini direka bentuk untuk menerima modaliti data mentah tertentu sebagai input, seperti teks atau imej, dan kemudian menjana ramalan dalam modaliti yang sama seperti input. Kami akan membincangkan beberapa kaedah dan teknik yang paling menjanjikan yang digunakan dalam model ini, termasuk model bahasa generatif seperti GPT3 [9], BART [34], T5 [56] dan model penglihatan generatif seperti GAN [29], VAE [30]. ] dan aliran normal [57].
Model pelbagai mod
Penjanaan pelbagai mod ialah komponen penting AIGC masa kini. Matlamat penjanaan multimodal adalah untuk belajar menjana model modaliti asal dengan mempelajari sambungan multimodal dan interaksi data [7]. Hubungan dan interaksi sedemikian antara modaliti kadangkala sangat kompleks, yang menjadikan ruang perwakilan multimodal sukar dipelajari berbanding dengan ruang perwakilan mod tunggal. Walau bagaimanapun, dengan kemunculan infrastruktur khusus corak yang kuat yang dinyatakan sebelum ini, semakin banyak kaedah dicadangkan untuk menangani cabaran ini. Dalam bahagian ini, kami memperkenalkan model multimodal terkini dalam penjanaan bahasa visual, penjanaan audio teks, penjanaan grafik teks dan penjanaan kod teks. Memandangkan kebanyakan model generatif multimodal sentiasa sangat relevan dengan aplikasi praktikal, bahagian ini terutamanya memperkenalkannya dari perspektif tugas hiliran.
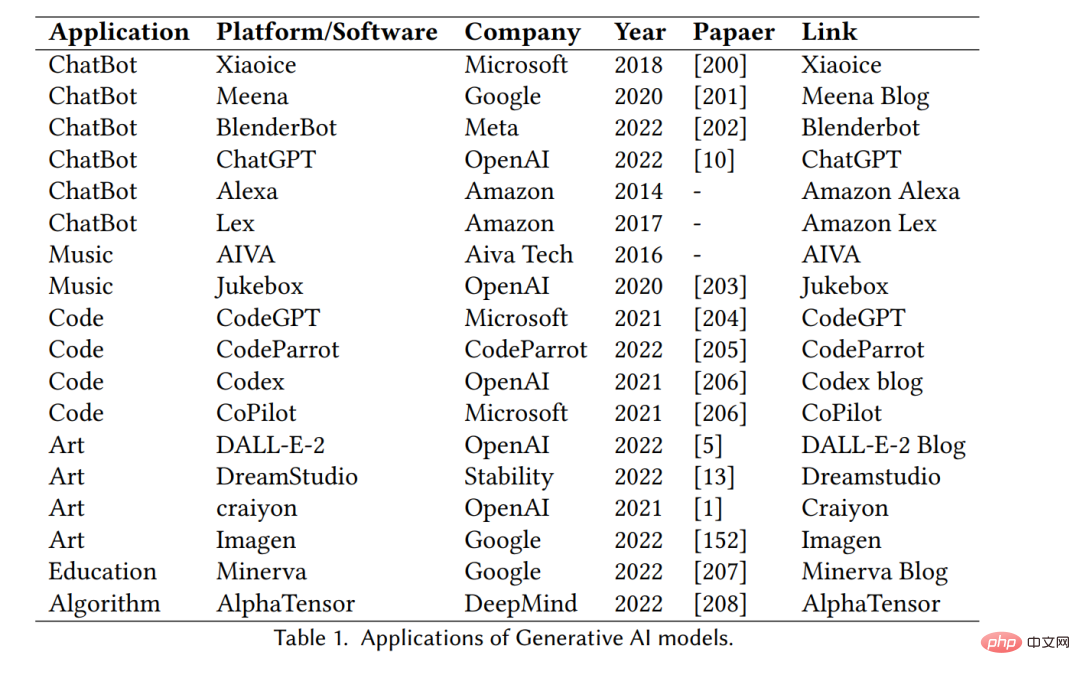
Mohon
Kecekapan
Model kecerdasan buatan generatif mendalam dengan rangkaian saraf telah mendominasi bidang pembelajaran mesin sepanjang dekad yang lalu, dengan peningkatannya disebabkan oleh persaingan ImageNet 2012 [210], yang telah membawa kepada perlumbaan untuk mencipta model yang lebih mendalam dan lebih kompleks. Trend ini juga telah muncul dalam bidang pemahaman bahasa semula jadi, di mana model seperti BERT dan GPT-3 telah membangunkan sejumlah besar parameter. Walau bagaimanapun, jejak model yang semakin meningkat dan kerumitan, serta kos dan sumber yang diperlukan untuk latihan dan penggunaan, menimbulkan cabaran untuk penggunaan praktikal di dunia nyata. Cabaran teras ialah kecekapan, yang boleh dipecahkan seperti berikut:
- Kecekapan inferens : Ini berkaitan dengan pertimbangan praktikal untuk menggunakan model untuk inferens, iaitu mengira output model untuk input yang diberikan. Kecekapan inferens terutamanya berkaitan dengan saiz model, kelajuan dan penggunaan sumber (cth., penggunaan cakera dan RAM) semasa inferens.
- Kecekapan latihan : Ini meliputi faktor yang mempengaruhi kelajuan dan keperluan sumber untuk melatih model, seperti masa latihan, jejak memori dan kebolehskalaan merentas berbilang peranti. Ia juga mungkin termasuk mempertimbangkan jumlah data yang diperlukan untuk mencapai prestasi optimum pada tugasan tertentu.
Atas ialah kandungan terperinci 'Daripada GAN ke ChatGPT: Universiti Lehigh memperincikan pembangunan kandungan yang dijana AI'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI