

 Peranti teknologiAIPenyelidikan DeepMind baharu: pengubah boleh memperbaiki dirinya sendiri tanpa campur tangan manusia
Peranti teknologiAIPenyelidikan DeepMind baharu: pengubah boleh memperbaiki dirinya sendiri tanpa campur tangan manusiaPenyelidikan DeepMind baharu: pengubah boleh memperbaiki dirinya sendiri tanpa campur tangan manusia

Pada masa ini, Transformers telah menjadi seni bina rangkaian saraf yang berkuasa untuk pemodelan jujukan. Sifat ketara transformer terlatih ialah keupayaan mereka untuk menyesuaikan diri dengan tugas hiliran melalui pelaziman isyarat atau pembelajaran kontekstual. Selepas pra-latihan pada set data luar talian yang besar, transformer berskala besar telah ditunjukkan dengan cekap menyamaratakan tugasan hiliran dalam pelengkapan teks, pemahaman bahasa dan penjanaan imej.
Kerja terkini telah menunjukkan bahawa transformer juga boleh mempelajari dasar daripada data luar talian dengan menganggap pembelajaran tetulang luar talian (RL) sebagai masalah ramalan berjujukan. Kerja oleh Chen et al. (2021) menunjukkan bahawa transformer boleh mempelajari dasar tugas tunggal daripada data RL luar talian melalui pembelajaran tiruan, dan kerja seterusnya menunjukkan bahawa transformer boleh mengekstrak dasar berbilang tugas dalam tetapan domain yang sama dan merentas domain. Kerja-kerja ini semuanya menunjukkan paradigma untuk mengekstrak dasar berbilang tugas umum, iaitu pertama mengumpul set data interaksi persekitaran berskala besar dan pelbagai, dan kemudian mengekstrak dasar daripada data melalui pemodelan berjujukan. Kaedah pembelajaran dasar daripada data RL luar talian melalui pembelajaran tiruan ini dipanggil penyulingan dasar luar talian (Offline Policy Distillation) atau penyulingan dasar (Policy Distillation, PD).
PD menawarkan kesederhanaan dan kebolehskalaan, tetapi salah satu kelemahan utamanya ialah dasar yang dijana tidak bertambah baik secara progresif dengan interaksi tambahan dengan alam sekitar. Contohnya, ejen generalis Google Multi-Game Decision Transformers mempelajari dasar bersyarat pulangan yang boleh memainkan banyak permainan Atari, manakala ejen generalis DeepMind, Gato mempelajari penyelesaian kepada pelbagai masalah melalui strategi penaakulan tugasan kontekstual. Malangnya, kedua-dua ejen tidak boleh menambah baik dasar dalam konteks melalui percubaan dan kesilapan. Oleh itu, kaedah PD mempelajari dasar dan bukannya algoritma pembelajaran pengukuhan.
Dalam kertas DeepMind baru-baru ini, penyelidik membuat hipotesis bahawa sebab PD gagal bertambah baik melalui percubaan dan kesilapan ialah data yang digunakan untuk latihan tidak dapat menunjukkan kemajuan pembelajaran. Kaedah semasa sama ada mempelajari dasar daripada data yang tidak mengandungi pembelajaran (cth. dasar pakar tetap melalui penyulingan) atau mempelajari dasar daripada data yang mengandungi pembelajaran (cth. penimbal ulang tayang ejen RL), tetapi saiz konteks yang terakhir ( terlalu Kecil) Kegagalan untuk menangkap penambahbaikan dasar.

Alamat kertas: https://arxiv.org/pdf/2210.14215.pdf
Pemerhatian utama penyelidik ialah sifat pembelajaran berurutan dalam latihan algoritma RL membolehkan, pada dasarnya, memodelkan pembelajaran pengukuhan itu sendiri sebagai masalah ramalan jujukan sebab. Khususnya, jika konteks pengubah cukup panjang untuk memasukkan penambahbaikan dasar yang dibawa oleh kemas kini pembelajaran, maka ia bukan sahaja boleh mewakili dasar tetap, tetapi juga boleh mewakili algoritma penambahbaikan dasar dengan memfokuskan pada keadaan. , tindakan dan ganjaran episod sebelumnya. Ini membuka kemungkinan bahawa mana-mana algoritma RL boleh disuling menjadi model jujukan yang cukup berkuasa seperti transformer melalui pembelajaran tiruan, dan model ini boleh ditukar kepada algoritma RL kontekstual.
Penyelidik mencadangkan Penyulingan Algoritma (AD), yang merupakan pengendali yang dipertingkatkan untuk mempelajari strategi kontekstual dengan mengoptimumkan kehilangan ramalan jujukan sebab dalam sejarah kaedah pembelajaran algoritma RL. Seperti yang ditunjukkan dalam Rajah 1 di bawah, AD terdiri daripada dua bahagian. Set data berbilang tugas yang besar mula-mula dijana dengan menyimpan sejarah latihan algoritma RL pada sejumlah besar tugas individu, dan kemudian model pengubah memodelkan tindakan dengan menggunakan sejarah pembelajaran sebelumnya sebagai konteksnya. Oleh kerana dasar itu terus bertambah baik semasa latihan algoritma RL sumber, AD perlu mempelajari operator yang dipertingkatkan untuk memodelkan tindakan dengan tepat pada mana-mana titik tertentu dalam sejarah latihan. Yang penting, konteks pengubah mestilah cukup besar (iaitu, merentas episod) untuk menangkap peningkatan dalam data latihan.
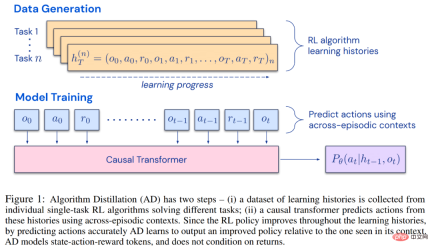
Para penyelidik menyatakan bahawa dengan menggunakan pengubah penyebab dengan konteks yang cukup besar untuk meniru algoritma RL berasaskan kecerunan, AD boleh mengukuhkan sepenuhnya tugas baharu dalam konteks kajian. Kami menilai AD dalam beberapa persekitaran yang boleh diperhatikan separa yang memerlukan penerokaan, termasuk Watermaze berasaskan piksel daripada DMLab, dan menunjukkan bahawa AD mampu penerokaan konteks, penetapan keyakinan temporal dan generalisasi. Selain itu, algoritma yang dipelajari oleh AD adalah lebih cekap daripada algoritma yang menjana data sumber latihan pengubah.
Akhir sekali, perlu diingat bahawa AD ialah kaedah pertama untuk menunjukkan pembelajaran peneguhan kontekstual dengan memodelkan data luar talian secara berurutan dengan kehilangan tiruan.

Kaedah
Semasa kitaran hayatnya, agen pembelajaran pengukuhan perlu menunjukkan prestasi yang baik dalam melakukan tindakan yang kompleks. Bagi ejen pintar, tanpa mengira persekitaran, struktur dalaman dan pelaksanaannya, ia boleh dianggap sebagai selesai berdasarkan pengalaman lalu. Ia boleh dinyatakan dalam bentuk berikut:
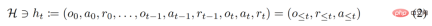
Penyelidik juga menganggap strategi "long history-conditioned" sebagai algoritma dan membuat kesimpulan:

di mana Δ(A) mewakili ruang pengagihan kebarangkalian pada ruang tindakan A. Persamaan (3) menunjukkan bahawa algoritma boleh dibentangkan dalam persekitaran untuk menjana urutan pemerhatian, ganjaran dan tindakan. Demi kesederhanaan, kajian ini mewakili algoritma sebagai P dan persekitaran (iaitu tugas) sebagai  Sejarah pembelajaran
Sejarah pembelajaran  diwakili oleh algoritma , supaya untuk sebarang tugasan yang diberikan
diwakili oleh algoritma , supaya untuk sebarang tugasan yang diberikan  Dihasilkan. Anda boleh mendapatkan
Dihasilkan. Anda boleh mendapatkan

Penyelidik menggunakan huruf Latin besar untuk mewakili pembolehubah rawak, seperti O, A, R dan bentuk huruf kecil yang sepadan o, α, r . Dengan melihat algoritma sebagai dasar bersyarat sejarah jangka panjang, mereka membuat hipotesis bahawa mana-mana algoritma yang menjana sejarah pembelajaran boleh ditukar kepada rangkaian saraf dengan melakukan pengklonan tingkah laku tindakan. Seterusnya, kajian mencadangkan pendekatan yang menyediakan ejen pembelajaran sepanjang hayat model jujukan dengan klon tingkah laku untuk memetakan sejarah jangka panjang kepada pengagihan tindakan.
Pelaksanaan praktikalSecara praktikal, penyelidikan ini melaksanakan penyulingan algoritma (AD) sebagai proses dua langkah. Pertama, set data sejarah pembelajaran dikumpul dengan menjalankan algoritma RL berasaskan kecerunan individu pada banyak tugas yang berbeza. Seterusnya, model jujukan dengan konteks berbilang episod dilatih untuk meramalkan tindakan dalam sejarah. Algoritma khusus adalah seperti berikut:

Eksperimen memerlukan persekitaran yang digunakan menyokong banyak tugas yang tidak boleh diperolehi daripada Inferens mudah dibuat daripada pemerhatian, dan episod cukup pendek untuk melatih transformer sebab-sebab episod silang dengan cekap. Matlamat utama kerja ini adalah untuk menyiasat sejauh mana peneguhan AD dipelajari dalam konteks berbanding dengan kerja sebelumnya. Percubaan membandingkan AD, ED (Penyulingan Pakar), RL^2, dsb.
Hasil penilaian AD, ED, RL^2 ditunjukkan dalam Rajah 3. Kajian mendapati bahawa kedua-dua AD dan RL^2 boleh belajar secara kontekstual mengenai tugas yang disampel daripada pengedaran latihan, manakala ED tidak boleh, walaupun ED melakukan lebih baik daripada meneka rawak apabila dinilai dalam pengedaran.

Mengenai Rajah 4 di bawah, pengkaji telah menjawab beberapa siri soalan. Adakah AD mempamerkan pembelajaran peneguhan kontekstual? Keputusan menunjukkan bahawa pembelajaran peneguhan kontekstual AD boleh belajar dalam semua persekitaran, sebaliknya, ED tidak boleh meneroka dan belajar dalam konteks dalam kebanyakan situasi.
Bolehkah AD belajar daripada pemerhatian berasaskan piksel? Keputusan menunjukkan bahawa AD memaksimumkan regresi episod melalui RL kontekstual, manakala ED gagal untuk belajar.
AD Adakah mungkin untuk mempelajari algoritma RL yang lebih cekap daripada algoritma yang menjana data sumber? Keputusan menunjukkan bahawa kecekapan data AD adalah jauh lebih tinggi daripada algoritma sumber (A3C dan DQN).

Adakah mungkin untuk mempercepatkan AD melalui tunjuk cara? Untuk menjawab soalan ini, kajian ini mengekalkan strategi pensampelan pada titik yang berbeza sepanjang sejarah algoritma sumber dalam data set ujian, kemudian, menggunakan data strategi ini untuk pra-populasi konteks AD dan ED, dan menjalankan kedua-dua kaedah dalam konteks Bilik Gelap, Hasilnya diplot dalam Rajah 5. Walaupun ED mengekalkan prestasi dasar input, AD menambah baik setiap dasar dalam konteks sehingga ia hampir optimum. Yang penting, lebih dioptimumkan strategi input, lebih cepat AD memperbaikinya sehingga mencapai optimum.

Untuk butiran lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Penyelidikan DeepMind baharu: pengubah boleh memperbaiki dirinya sendiri tanpa campur tangan manusia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AM
Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AMMeneroka kerja -kerja dalam model bahasa dengan skop Gemma Memahami kerumitan model bahasa AI adalah satu cabaran penting. Pelepasan Google Gemma Skop, Toolkit Komprehensif, menawarkan penyelidik cara yang kuat untuk menyelidiki
 Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AM
Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AMMembuka Kejayaan Perniagaan: Panduan untuk Menjadi Penganalisis Perisikan Perniagaan Bayangkan mengubah data mentah ke dalam pandangan yang boleh dilakukan yang mendorong pertumbuhan organisasi. Ini adalah kuasa penganalisis Perniagaan Perniagaan (BI) - peranan penting dalam GU
 Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMPernyataan Jadual Alter SQL: Menambah lajur secara dinamik ke pangkalan data anda Dalam pengurusan data, kebolehsuaian SQL adalah penting. Perlu menyesuaikan struktur pangkalan data anda dengan cepat? Pernyataan Jadual ALTER adalah penyelesaian anda. Butiran panduan ini menambah colu
 Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AM
Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AMPengenalan Bayangkan pejabat yang sibuk di mana dua profesional bekerjasama dalam projek kritikal. Penganalisis perniagaan memberi tumpuan kepada objektif syarikat, mengenal pasti bidang penambahbaikan, dan memastikan penjajaran strategik dengan trend pasaran. Simu
 Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMPengiraan dan Analisis Data Excel: Penjelasan terperinci mengenai fungsi Count dan Counta Pengiraan dan analisis data yang tepat adalah kritikal dalam Excel, terutamanya apabila bekerja dengan set data yang besar. Excel menyediakan pelbagai fungsi untuk mencapai matlamat ini, dengan fungsi Count dan CountA menjadi alat utama untuk mengira bilangan sel di bawah keadaan yang berbeza. Walaupun kedua -dua fungsi digunakan untuk mengira sel, sasaran reka bentuk mereka disasarkan pada jenis data yang berbeza. Mari menggali butiran khusus fungsi Count dan Counta, menyerlahkan ciri dan perbezaan unik mereka, dan belajar cara menerapkannya dalam analisis data. Gambaran keseluruhan perkara utama Memahami kiraan dan cou
 Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AM
Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AMRevolusi AI Google Chrome: Pengalaman melayari yang diperibadikan dan cekap Kecerdasan Buatan (AI) dengan cepat mengubah kehidupan seharian kita, dan Google Chrome mengetuai pertuduhan di arena pelayaran web. Artikel ini meneroka exciti
 Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AM
Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AMImpak Reimagining: garis bawah empat kali ganda Selama terlalu lama, perbualan telah dikuasai oleh pandangan sempit kesan AI, terutama memberi tumpuan kepada keuntungan bawah. Walau bagaimanapun, pendekatan yang lebih holistik mengiktiraf kesalinghubungan BU
 5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AM
5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AMPerkara bergerak terus ke arah itu. Pelaburan yang dicurahkan ke dalam penyedia perkhidmatan kuantum dan permulaan menunjukkan bahawa industri memahami kepentingannya. Dan semakin banyak kes penggunaan dunia nyata muncul untuk menunjukkan nilainya


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

