
Rumah >Peranti teknologi >AI >Model besar boleh 'menulis' kertas dengan sendirinya, dengan formula dan rujukan Versi percubaan kini dalam talian
Model besar boleh 'menulis' kertas dengan sendirinya, dengan formula dan rujukan Versi percubaan kini dalam talian

- 王林ke hadapan
- 2023-04-20 11:10:06917semak imbas
Dalam beberapa tahun kebelakangan ini, dengan kemajuan penyelidikan dalam pelbagai bidang subjek, kesusasteraan saintifik dan data telah meletup, menjadikannya semakin sukar bagi penyelidik akademik untuk menemui cerapan berguna daripada sejumlah besar maklumat. Biasanya, orang menggunakan enjin carian untuk mendapatkan pengetahuan saintifik, tetapi enjin carian tidak dapat mengatur pengetahuan saintifik secara autonomi.
Kini, pasukan penyelidik daripada Meta AI telah mencadangkan Galactica, model bahasa berskala besar baharu yang boleh menyimpan, menggabungkan dan menaakul tentang pengetahuan saintifik.

- Alamat kertas: https://galactica.org/static/paper.pdf
- Alamat percubaan: https://galactica.org/
Seberapa hebatkah model Galactica itu? ia dengan sendirinya Ringkaskan dan rumuskan kertas ulasan:
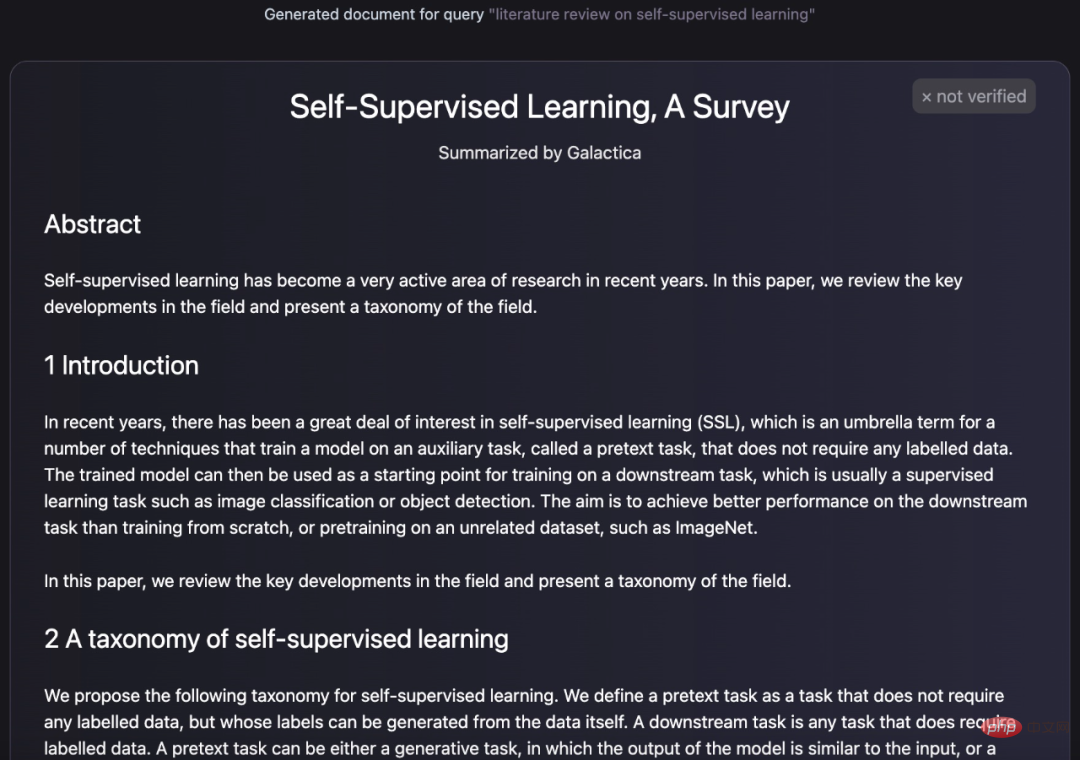
Anda juga boleh menjana pertanyaan ensiklopedia untuk entri:
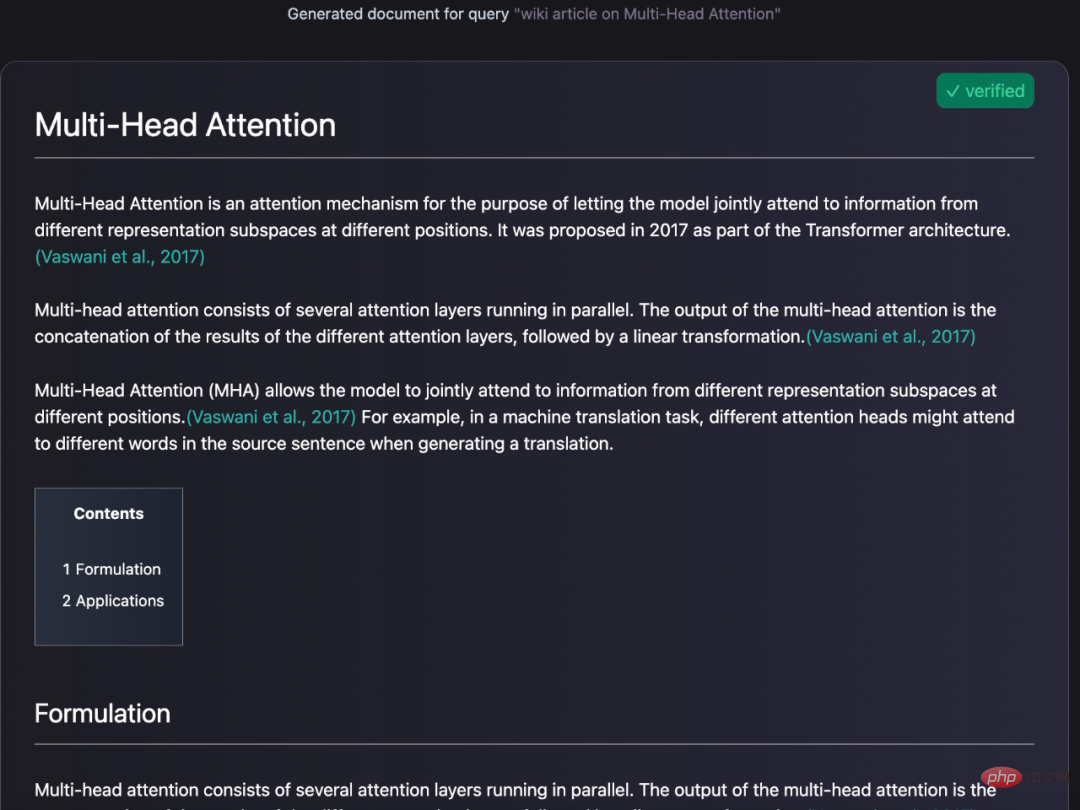
Berikan jawapan yang berpengetahuan kepada soalan yang ditanya:
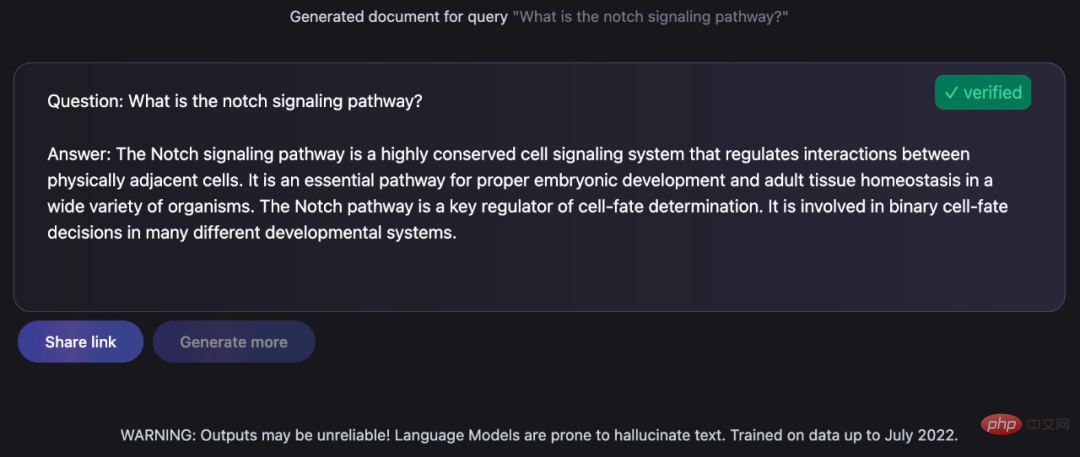
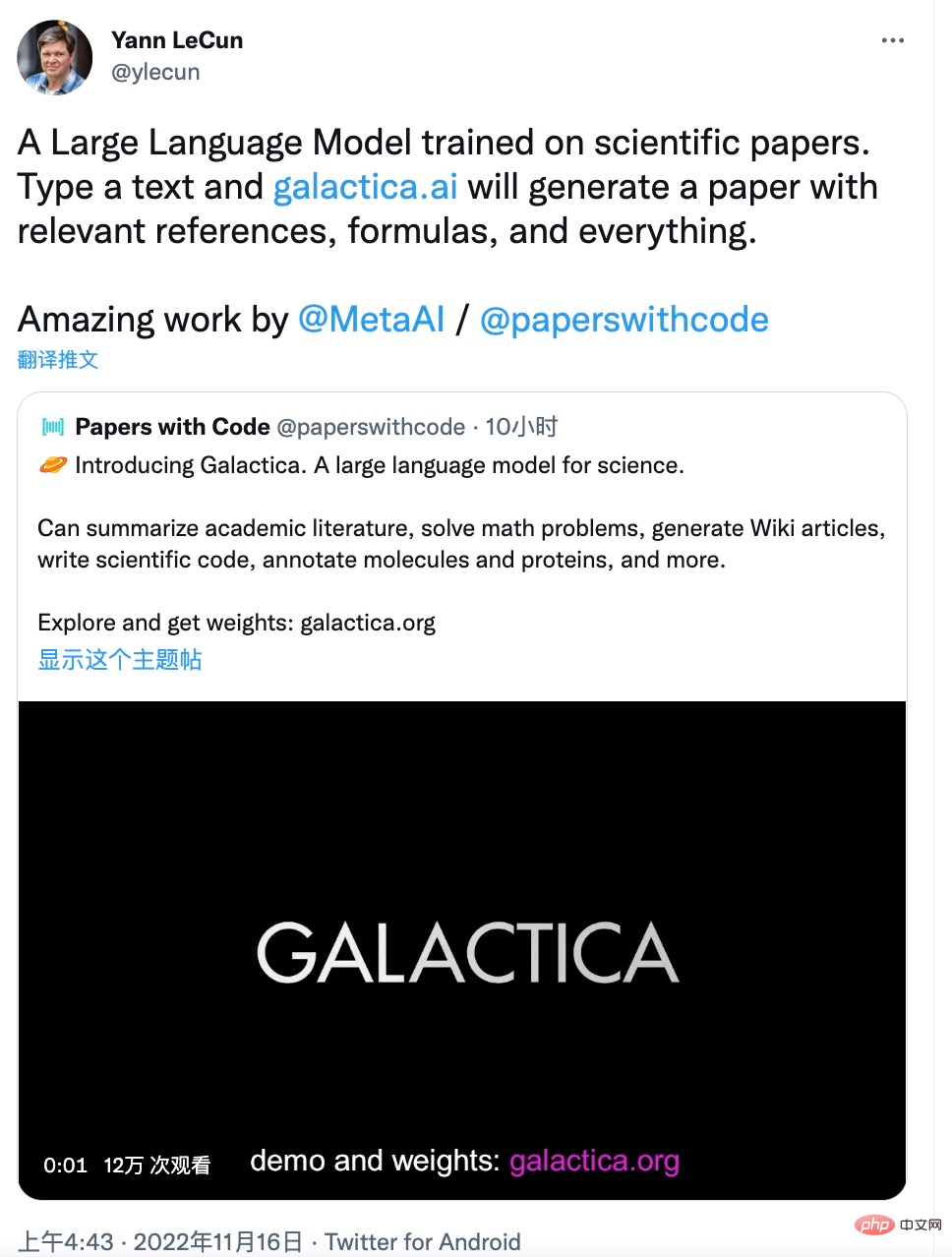
Tugas-tugas ini adalah perkara biasa bagi ahli antropologi A tugas yang mencabar, tetapi satu yang Galactica capai dengan sangat baik. Pemenang Anugerah Turing Yann LeCun turut menulis pujiannya di Twitter:
Mari kita lihat butiran khusus model Galactica.
Gambaran Keseluruhan Model
Model Galactica dilatih pada korpus saintifik besar kertas kerja, bahan rujukan, pangkalan pengetahuan dan banyak sumber lain, termasuk lebih daripada 48 juta artikel Makalah , buku teks dan bahan edaran, pengetahuan tentang jutaan sebatian dan protein, laman web saintifik, ensiklopedia dan banyak lagi. Tidak seperti model bahasa sedia ada yang bergantung pada teks berasaskan perangkak web yang tidak dipilih, korpus yang digunakan untuk latihan Galactica adalah berkualiti tinggi dan dipilih susun tinggi. Kajian ini melatih model untuk berbilang zaman tanpa overfitting, di mana prestasi pada tugasan huluan dan hiliran telah dipertingkatkan dengan menggunakan token berulang.
Galactica mengatasi model sedia ada dalam pelbagai tugas saintifik. Mengenai tugas penerokaan pengetahuan teknikal seperti persamaan LaTeX, prestasi Galactica dan GPT-3 ialah 68.2% VS 49.0%. Galactica juga cemerlang dalam inferens, dengan ketara mengatasi Chinchilla pada penanda aras matematik MMLU.
Galactica juga mengatasi prestasi BLOOM dan OPT-175B di BIG-bench walaupun tidak dilatih dalam korpus biasa. Selain itu, ia mencapai prestasi tertinggi baharu sebanyak 77.6% dan 52.9% pada tugas hiliran seperti pembangunan PubMedQA dan MedMCQA.
Ringkasnya, penyelidikan merangkumi penaakulan langkah demi langkah dalam token khas untuk meniru kerja dalaman. Ini membolehkan penyelidik berinteraksi dengan model menggunakan bahasa semula jadi, seperti yang ditunjukkan di bawah dalam antara muka percubaan Galactica.
Perlu dinyatakan bahawa selain penjanaan teks, Galactica juga boleh melaksanakan tugas berbilang modal yang melibatkan formula kimia dan jujukan protein. Ini akan menyumbang kepada bidang penemuan dadah.
Butiran pelaksanaan
Korpus artikel ini mengandungi 106 bilion token, yang datang daripada kertas kerja, rujukan, ensiklopedia dan bahan saintifik lain. Boleh dikatakan bahawa penyelidikan ini merangkumi kedua-dua sumber bahasa semula jadi (makalah, buku rujukan) dan jujukan dalam alam semula jadi (jujukan protein, bentuk kimia). Butiran korpus ditunjukkan dalam Jadual 1 dan 2 .
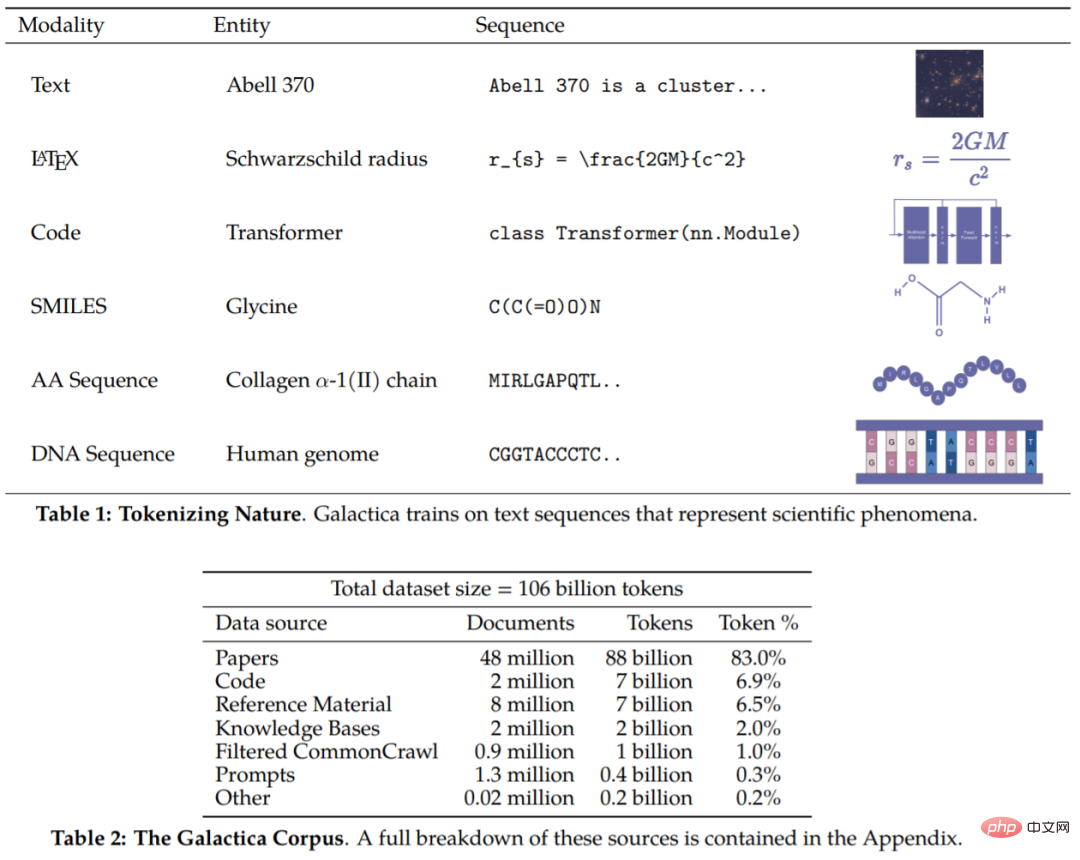
Sekarang korpus tersedia, langkah seterusnya ialah cara mengendalikan data. Secara umumnya, reka bentuk tokenisasi adalah sangat penting. Sebagai contoh, jika jujukan protein ditulis dari segi sisa asid amino, maka tokenisasi berasaskan aksara adalah sesuai. Untuk mencapai tokenisasi, kajian ini melakukan tokenisasi khusus pada modaliti yang berbeza. Contoh khusus termasuk (tetapi tidak terhad kepada):
- Rujukan: gunakan token rujukan khas [START_REF] dan [END_REF] untuk membalut rujukan
- Penaakulan langkah demi langkah: Gunakan token memori berfungsi untuk merangkum penaakulan langkah demi langkah dan mensimulasikan konteks memori kerja dalaman
- Nombor: Bahagikan nombor kepada; token berasingan. Contohnya, 737612.62 → 7,3,7,6,1,2,.,6,2;
- Formula SMILES: balut urutan dengan [START_SMILES] dan [END_SMILES] dan gunakan tokenisasi berasaskan aksara. Begitu juga, kajian ini menggunakan [START_I_SMILES] dan [END_I_SMILES] untuk mewakili SMILES isomer. Contohnya: C(C(=O)O)N→C, (,C,(,=,O,),O,),N;
- Jujukan DNA: Aplikasi 1 Tokenisasi berasaskan aksara yang menganggap setiap bes nukleotida sebagai token, dengan token permulaan ialah [START_DNA] dan [END_DNA]. Contohnya, CGGTACCCTC→C, G, G, T, A, C, C, C, T, C.
Rajah 4 di bawah menunjukkan contoh pemprosesan petikan kertas. Semasa mengendalikan rujukan, gunakan pengecam global dan token khas [START_REF] dan [END_REF] untuk menunjukkan tempat rujukan.

Selepas set data diproses, langkah seterusnya ialah cara melaksanakannya. Galactica telah membuat pengubahsuaian berikut berdasarkan seni bina Transformer:
- Pengaktifan GeLU: Gunakan pengaktifan GeLU untuk model pelbagai saiz; >Tetingkap konteks: Untuk model dengan saiz yang berbeza, gunakan tetingkap konteks dengan panjang 2048;
- Pembenaman lokasi pembelajaran: Pembenaman lokasi pembelajaran untuk model;
- Perbendaharaan kata: Gunakan BPE untuk membina perbendaharaan kata sebanyak 50k token.
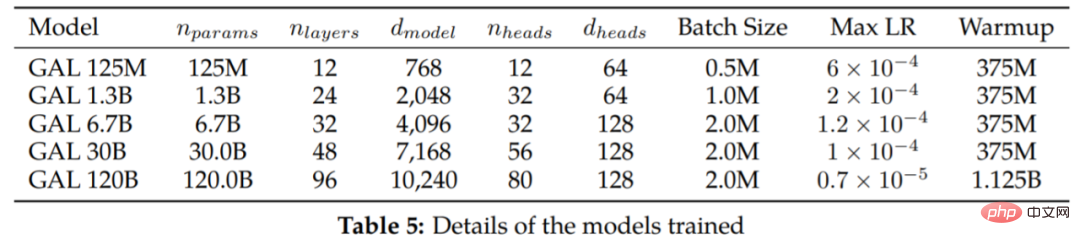
- Jadual 5 menyenaraikan model pelbagai saiz dan hiperparameter latihan.
- Eksperimen
Token pendua dianggap tidak berbahaya
Seperti yang dapat dilihat dari Rajah 6, selepas empat zaman latihan, kehilangan pengesahan terus berkurangan. Model dengan parameter 120B hanya mula terlalu muat pada permulaan zaman kelima. Ini tidak dijangka kerana penyelidikan sedia ada menunjukkan bahawa token pendua boleh membahayakan prestasi. Kajian itu juga mendapati bahawa model 30B dan 120B mempamerkan kesan penurunan dua kali dari segi zaman, di mana kehilangan pengesahan meningkat (atau meningkat), diikuti dengan penurunan. Kesan ini menjadi lebih kuat selepas setiap zaman, terutamanya untuk model 120B pada akhir latihan.
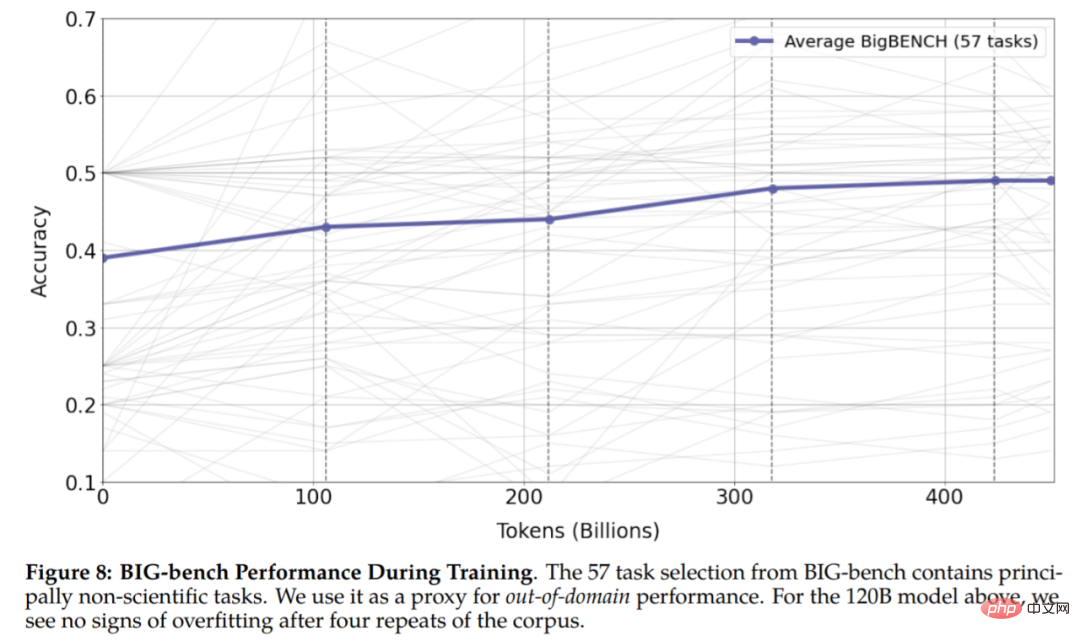
Keputusan Rajah 8 menunjukkan bahawa tiada tanda overfitting dalam eksperimen, yang menunjukkan bahawa token berulang boleh meningkatkan prestasi tugasan hiliran dan huluan.
Hasil lain
 Terlalu lambat untuk menaip formula, sekarang gunakan LaTeX segera boleh dijana:
Terlalu lambat untuk menaip formula, sekarang gunakan LaTeX segera boleh dijana:
Dalam tindak balas kimia, Galactica diperlukan untuk meramalkan hasil tindak balas dalam persamaan kimia LaTeX. Model boleh berdasarkan hanya pada bahan tindak balas Membuat inferens, keputusannya adalah seperti berikut:

Kebolehan penaakulan Galactica. Kajian ini pertama kali dinilai pada penanda aras matematik MMLU dan keputusan penilaian dilaporkan dalam Jadual 8. Galactica berprestasi kukuh berbanding model asas yang lebih besar, dan menggunakan token nampaknya meningkatkan prestasi Chinchilla, walaupun untuk model Galactica 30B yang lebih kecil.
Kajian ini juga menilai dataset MATH untuk meneroka lebih lanjut keupayaan inferens Galactica:
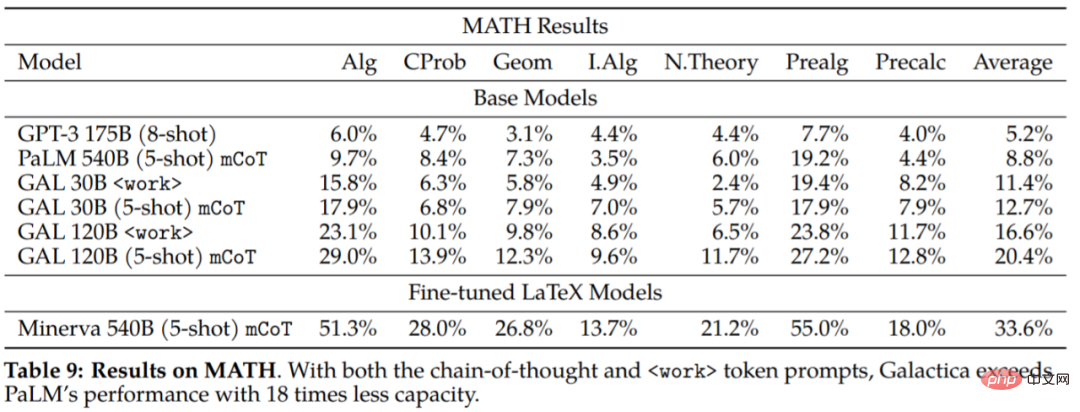
Ia boleh membuat kesimpulan daripada keputusan eksperimen bahawa Galactica jauh lebih baik daripada model PaLM asas dari segi rantaian pemikiran dan gesaan. Ini menunjukkan bahawa Galactica adalah pilihan yang lebih baik untuk mengendalikan tugasan matematik. Keputusan penilaian
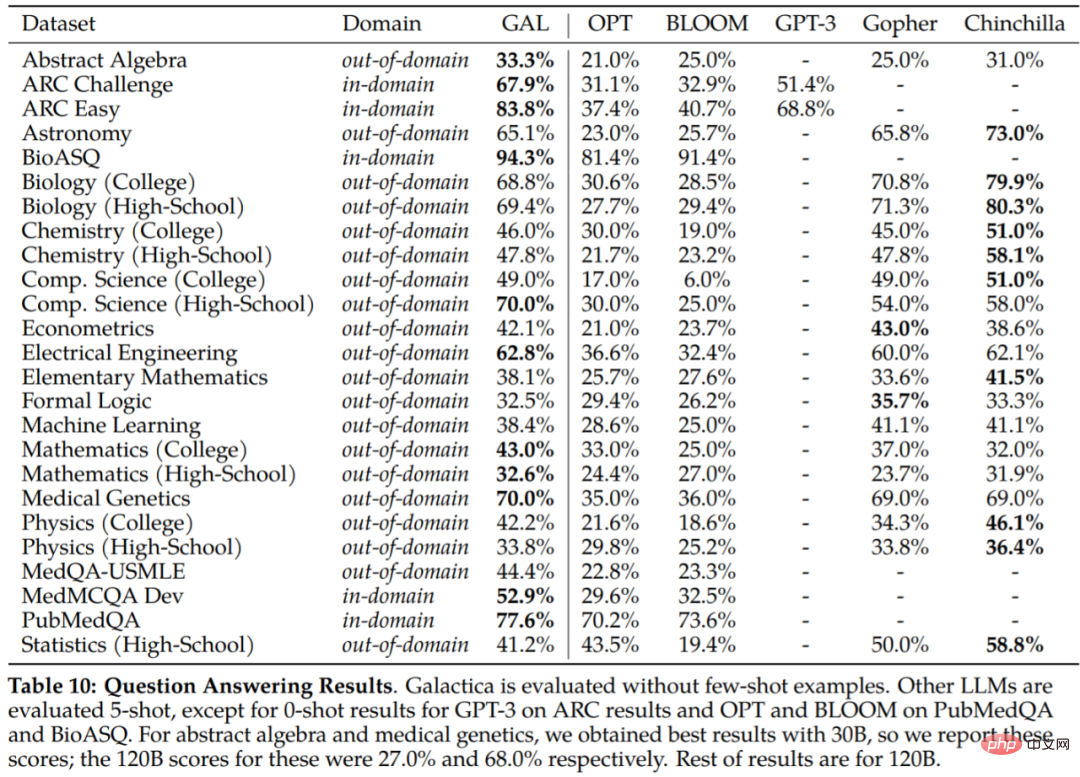
pada tugasan hiliran ditunjukkan dalam Jadual 10. Galactica dengan ketara mengatasi model bahasa lain dan mengatasi model yang lebih besar pada kebanyakan tugas (Gopher 280B). Perbezaan dalam prestasi adalah lebih besar daripada Chinchilla, yang nampaknya lebih kuat pada subset tugasan: terutamanya mata pelajaran sekolah menengah dan tugasan yang kurang matematik, intensif ingatan. Sebaliknya, Galactica cenderung untuk melaksanakan tugasan matematik dan peringkat siswazah dengan lebih baik.
Kajian ini juga menilai keupayaan Chinchilla untuk meramalkan petikan berdasarkan konteks input, penilaian terhadap keupayaan Chinchilla untuk menyusun ujian saintifik. Keputusan adalah seperti berikut:
Untuk lebih banyak kandungan eksperimen, sila rujuk kertas asal.
Atas ialah kandungan terperinci Model besar boleh 'menulis' kertas dengan sendirinya, dengan formula dan rujukan Versi percubaan kini dalam talian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI