

 Peranti teknologiAIHanya 10% daripada parameter diperlukan untuk mengatasi SOTA! Universiti Zhejiang, Byte dan Cina Hong Kong bersama-sama mencadangkan rangka kerja baharu untuk tugas 'anggaran pose peringkat kategori'
Peranti teknologiAIHanya 10% daripada parameter diperlukan untuk mengatasi SOTA! Universiti Zhejiang, Byte dan Cina Hong Kong bersama-sama mencadangkan rangka kerja baharu untuk tugas 'anggaran pose peringkat kategori'
Memberi robot pemahaman 3D tentang objek harian ialah cabaran utama dalam aplikasi robotik.
Apabila meneroka dalam persekitaran yang tidak diketahui, kaedah anggaran pose objek sedia ada masih tidak memuaskan kerana kepelbagaian bentuk objek.

Baru-baru ini, penyelidik dari Zhejiang University, ByteDance Artificial Intelligence Laboratory dan Chinese University of Hong Kong bersama-sama mencadangkan rangka kerja baharu untuk bentuk objek peringkat Kategori dan membuat anggaran daripada imej RGB-D tunggal.

Alamat kertas: https://arxiv.org/abs/2210.01112
Pautan projek:https://zju3dv.github.io/gCasp
Untuk mengendalikan perubahan bentuk objek dalam kategori , penyelidik Mengguna pakai perwakilan primitif semantik untuk mengekod bentuk yang berbeza ke dalam ruang terpendam bersatu, perwakilan ini adalah kunci untuk mewujudkan surat-menyurat yang boleh dipercayai antara awan titik yang diperhatikan dan bentuk yang dianggarkan.
Kemudian melaluideskriptor bentuk yang direka bentuk iaitu invarian kepada transformasi persamaan badan tegar, anggaran bentuk dan pose objek dipisahkan, sekali gus menyokong sebarang pose yang tersirat pengoptimuman bentuk objek sasaran. Percubaan menunjukkan bahawa kaedah yang dicadangkan mencapai prestasi anggaran pose terkemuka dalam set data awam. Latar Belakang Penyelidikan
Dalam bidang persepsi dan operasi robot, menganggar bentuk dan pose objek harian adalah fungsi asas dan mempunyai pelbagai aplikasi, termasuk 3D pemahaman adegan, operasi robotik dan pergudangan autonomi.Kebanyakan kerja awal pada tugasan ini tertumpu pada anggaran pose peringkat contoh, yang terutamanya mendapatkan pose objek dengan menjajarkan objek yang diperhatikan dengan model CAD yang diberikan.
Walau bagaimanapun, persediaan sedemikian terhad dalam senario dunia sebenar kerana sukar untuk mendapatkan model tepat bagi mana-mana objek tertentu terlebih dahulu.
Untuk menyamaratakan kepada objek yang tidak kelihatan tetapi biasa dari segi semantik, anggaran pose objek peringkat kategori menarik perhatian penyelidikan yang semakin meningkat kerana ia berpotensi mengendalikan Pelbagai kejadian sebenar bagi kategori yang sama dalam tempat kejadian.

Walaupun karya ini telah mencapai kemajuan yang besar, kaedah ramalan satu pukulan ini masih menghadapi kesukaran apabila terdapat perbezaan bentuk yang besar dalam kategori yang sama.
Untuk mengendalikan kepelbagaian objek dalam kategori yang sama, sesetengah karya menggunakan perwakilan tersirat saraf untuk menyesuaikan diri dengan bentuk objek sasaran dengan mengoptimumkan secara berulang pose dan bentuk dalam tersirat ruang, dan Prestasi yang lebih baik diperolehi.
Terdapat dua cabaran utama dalam anggaran pose objek peringkat kategori Satu ialah perbezaan bentuk dalam kelas yang besar, dan satu lagi ialah kaedah sedia ada yang menggabungkan bentuk dan bergambar bersama boleh membawa kepada masalah pengoptimuman yang lebih kompleks.
Dalam kertas ini, penyelidik mengasingkan bentuk dan menganggarkan pose objek dengan mereka bentuk deskriptor bentuk yang tidak berubah kepada transformasi persamaan badan tegar, dengan itu menyokong pose sewenang-wenangnya Pengoptimuman bentuk tersirat objek sasaran. Akhirnya, skala dan pose objek diselesaikan berdasarkan perkaitan semantik antara bentuk anggaran dan pemerhatian.
Pengenalan algoritma
Algoritma terdiri daripada tiga modul,Pengestrakan primitif semantik, Anggaran bentuk generatif dan Anggaran pose objek.
Input algoritma ialah imej RGB-D tunggal Algoritma menggunakan Mask R-CNN yang telah dilatih untuk mendapatkan hasil segmentasi semantik imej RGB, dan kemudian memproyeksikan kembali awan titik bagi. setiap objek berdasarkan parameter intrinsik kamera. Kaedah ini terutamanya memproses awan titik dan akhirnya memperoleh skala dan pose 6DoF setiap objek.
Ekstraksi Primitif Semantik
DualSDF [1] mencadangkan kaedah perwakilan primitif semantik untuk objek yang serupa. Seperti yang ditunjukkan di sebelah kiri rajah di bawah, dalam jenis objek yang sama, setiap contoh dibahagikan kepada bilangan primitif semantik tertentu, dan label setiap primitif sepadan dengan bahagian tertentu bagi jenis objek tertentu.
Untuk mengekstrak primitif semantik objek daripada awan titik cerapan, penulis menggunakan rangkaian pembahagian awan titik untuk membahagikan awan titik cerapan kepada primitif semantik dengan label.

Anggaran bentuk generatif
Model generatif 3D (cth. DeepSDF) kebanyakannya beroperasi dalam sistem koordinat ternormal.
Walau bagaimanapun, akan terdapat transformasi pose yang serupa (putaran, terjemahan dan skala) antara objek dalam pemerhatian dunia sebenar dan sistem koordinat ternormal.
Untuk menyelesaikan bentuk ternormal yang sepadan dengan pemerhatian semasa apabila pose tidak diketahui, penulis mencadangkan deskriptor bentuk yang tidak berubah kepada transformasi serupa berdasarkan perwakilan primitif semantik.
Penerangan ini ditunjukkan dalam rajah di bawah, yang menerangkan sudut antara vektor yang terdiri daripada primitif berbeza:
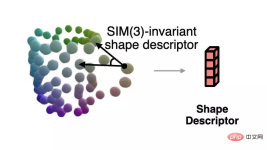
Pengarang menggunakan deskriptor ini untuk mengukur ralat antara cerapan semasa dan bentuk yang dianggarkan, dan menggunakan penurunan kecerunan untuk menjadikan bentuk anggaran lebih konsisten dengan pemerhatian Proses ditunjukkan dalam rajah di bawah.
Pengarang juga menunjukkan lebih banyak contoh pengoptimuman bentuk.

Anggaran pose
Akhir sekali, dengan memerhati awan titik dan menyelesaikan primitif semantik antara bentuk Berdasarkan korespondensi bahasa, penulis menggunakan algoritma Umeyama untuk menyelesaikan pose bentuk yang diperhatikan.

Hasil eksperimen
Pengarang menggunakan set data REAL275 (set data sebenar) dan CAMERA25 (set data sintetik) yang disediakan oleh NOCS Eksperimen perbandingan telah dijalankan untuk membandingkan ketepatan anggaran pose dengan kaedah lain Kaedah yang dicadangkan jauh melebihi kaedah lain dalam pelbagai penunjuk.
Pada masa yang sama, penulis juga membandingkan jumlah parameter yang perlu dilatih pada set latihan yang disediakan oleh NOCS Penulis memerlukan minimum 2.3M parameter untuk mencapai tahap terkini.

Atas ialah kandungan terperinci Hanya 10% daripada parameter diperlukan untuk mengatasi SOTA! Universiti Zhejiang, Byte dan Cina Hong Kong bersama-sama mencadangkan rangka kerja baharu untuk tugas 'anggaran pose peringkat kategori'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Cara Membina Pembantu AI Peribadi Anda Dengan Huggingface SmollmApr 18, 2025 am 11:52 AM
Cara Membina Pembantu AI Peribadi Anda Dengan Huggingface SmollmApr 18, 2025 am 11:52 AMMemanfaatkan kuasa AI di peranti: Membina CLI Chatbot Peribadi Pada masa lalu, konsep pembantu AI peribadi kelihatan seperti fiksyen sains. Bayangkan Alex, seorang peminat teknologi, bermimpi seorang sahabat AI yang pintar, yang tidak bergantung
 AI untuk Kesihatan Mental dianalisis dengan penuh perhatian melalui inisiatif baru yang menarik di Stanford UniversityApr 18, 2025 am 11:49 AM
AI untuk Kesihatan Mental dianalisis dengan penuh perhatian melalui inisiatif baru yang menarik di Stanford UniversityApr 18, 2025 am 11:49 AMPelancaran AI4MH mereka berlaku pada 15 April, 2025, dan Luminary Dr. Tom Insel, M.D., pakar psikiatri yang terkenal dan pakar neurosains, berkhidmat sebagai penceramah kick-off. Dr. Insel terkenal dengan kerja cemerlangnya dalam penyelidikan kesihatan mental dan techno
 Kelas Draf WNBA 2025 memasuki liga yang semakin meningkat dan melawan gangguan dalam talianApr 18, 2025 am 11:44 AM
Kelas Draf WNBA 2025 memasuki liga yang semakin meningkat dan melawan gangguan dalam talianApr 18, 2025 am 11:44 AM"Kami mahu memastikan bahawa WNBA kekal sebagai ruang di mana semua orang, pemain, peminat dan rakan kongsi korporat, berasa selamat, dihargai dan diberi kuasa," kata Engelbert, menangani apa yang telah menjadi salah satu cabaran sukan wanita yang paling merosakkan. Anno
 Panduan Komprehensif untuk Struktur Data Terbina Python - Analytics VidhyaApr 18, 2025 am 11:43 AM
Panduan Komprehensif untuk Struktur Data Terbina Python - Analytics VidhyaApr 18, 2025 am 11:43 AMPengenalan Python cemerlang sebagai bahasa pengaturcaraan, terutamanya dalam sains data dan AI generatif. Manipulasi data yang cekap (penyimpanan, pengurusan, dan akses) adalah penting apabila berurusan dengan dataset yang besar. Kami pernah meliputi nombor dan st
 Tayangan pertama dari model baru Openai berbanding dengan alternatifApr 18, 2025 am 11:41 AM
Tayangan pertama dari model baru Openai berbanding dengan alternatifApr 18, 2025 am 11:41 AMSebelum menyelam, kaveat penting: Prestasi AI adalah spesifik yang tidak ditentukan dan sangat digunakan. Dalam istilah yang lebih mudah, perbatuan anda mungkin berbeza -beza. Jangan ambil artikel ini (atau lain -lain) sebagai perkataan akhir -sebaliknya, uji model ini pada senario anda sendiri
 AI Portfolio | Bagaimana untuk membina portfolio untuk kerjaya AI?Apr 18, 2025 am 11:40 AM
AI Portfolio | Bagaimana untuk membina portfolio untuk kerjaya AI?Apr 18, 2025 am 11:40 AMMembina portfolio AI/ML yang menonjol: Panduan untuk Pemula dan Profesional Mewujudkan portfolio yang menarik adalah penting untuk mendapatkan peranan dalam kecerdasan buatan (AI) dan pembelajaran mesin (ML). Panduan ini memberi nasihat untuk membina portfolio
 AI AI apa yang boleh dimaksudkan untuk operasi keselamatanApr 18, 2025 am 11:36 AM
AI AI apa yang boleh dimaksudkan untuk operasi keselamatanApr 18, 2025 am 11:36 AMHasilnya? Pembakaran, ketidakcekapan, dan jurang yang melebar antara pengesanan dan tindakan. Tak satu pun dari ini harus datang sebagai kejutan kepada sesiapa yang bekerja dalam keselamatan siber. Janji Agentic AI telah muncul sebagai titik perubahan yang berpotensi. Kelas baru ini
 Google Versus Openai: AI berjuang untuk pelajarApr 18, 2025 am 11:31 AM
Google Versus Openai: AI berjuang untuk pelajarApr 18, 2025 am 11:31 AMImpak segera berbanding perkongsian jangka panjang? Dua minggu yang lalu Openai melangkah ke hadapan dengan tawaran jangka pendek yang kuat, memberikan akses kepada pelajar A.S. dan Kanada.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

ZendStudio 13.5.1 Mac
Persekitaran pembangunan bersepadu PHP yang berkuasa

