
Rumah >masalah biasa >OpenAI dan Microsoft Sentinel Bahagian 3: DaVinci dan Turbo
OpenAI dan Microsoft Sentinel Bahagian 3: DaVinci dan Turbo

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-14 21:28:011706semak imbas
Selamat datang kembali ke siri kami tentang Model Bahasa Besar (LLM) OpenAI dan Microsoft Sentinel. Pada bahagian pertama, kami membina buku permainan asas menggunakan OpenAI dan penyambung Azure Logic Apps terbina dalam Sentinel untuk menerangkan taktik MITRE ATT&CK yang ditemui pada acara tersebut dan membincangkan beberapa parameter berbeza yang boleh menjejaskan model OpenAI, seperti suhu dan kekerapan menghukum. Seterusnya, kami melanjutkan fungsi ini menggunakan API REST Sentinel untuk mencari peraturan analisis berjadual dan mengembalikan ringkasan logik pengesanan peraturan.
Jika anda telah memberi perhatian, anda mungkin perasan bahawa buku permainan pertama kami mencari taktik MITRE ATT&CK daripada acara Sentinel, tetapi tidak memasukkan sebarang teknik acara dalam petua GPT3. kenapa tidak Baik, aktifkan OpenAI API Playground anda dan mari kita pergi ke lubang arnab (dengan memohon maaf kepada Lewis Carroll).
- Mod: Penuh
- Model: text-davinci-003
- Suhu: 1
- Panjang maksimum: 500
- P Maksimum: 1
- Penalti Kekerapan: 0
- Penalti Kehadiran: 0
- Prompt: "Sila terangkan taktik dan teknik MITER ATT&CK berikut: ["DefenseEvasion"], [ " T1564”]”
Berikut ialah keputusan pertama kami:
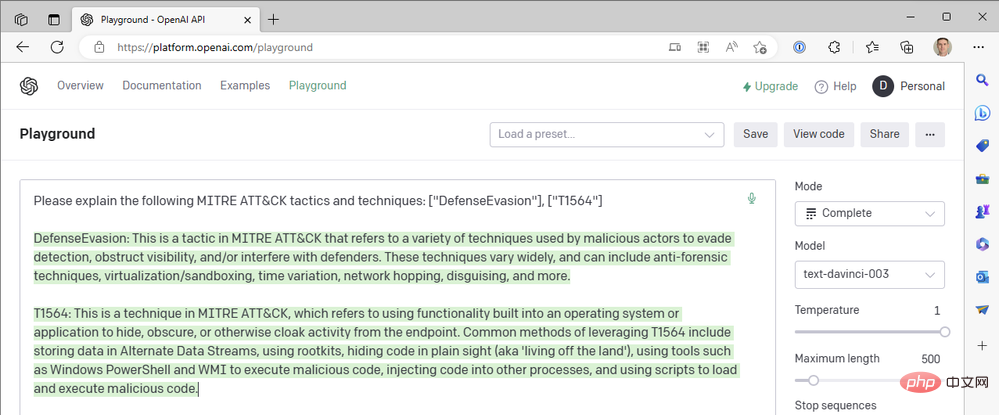
Ini ialah ulasan hebat tentang MITER ATT&CK Tactic TA0005, Defense Evasion Ringkasan yang bagus , tetapi bagaimana pula dengan penerangan teknikal? T1564 ialah Hide Artifacts - Process Injection (T1055) dan Rootkit (T1014) antara teknik lain yang dinamakan. Jom cuba lagi.
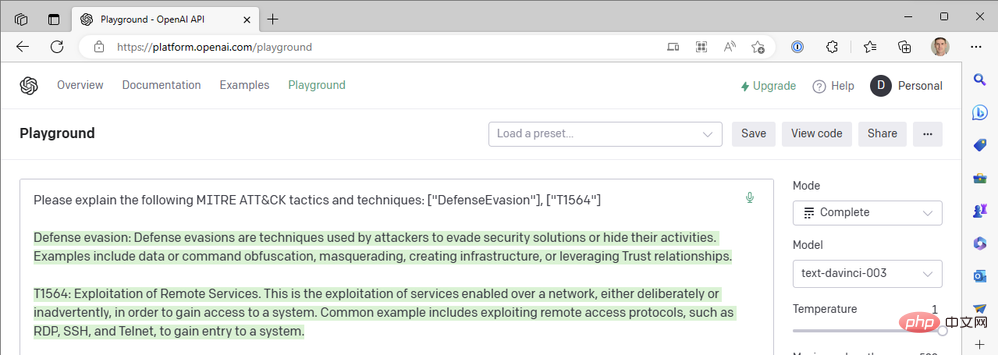
Jauh daripada itu! "Mengeksploitasi perkhidmatan jauh" ialah teknik T1210 dalam strategi pergerakan sisi. Sekali lagi:
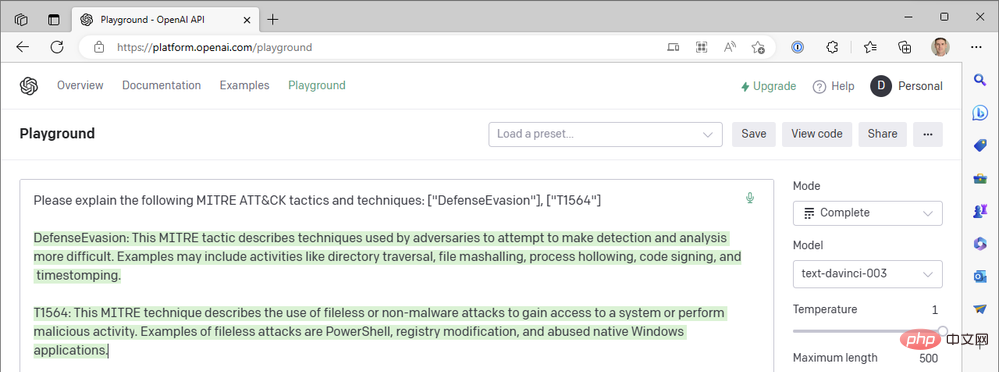
Jadi apa yang berlaku? Bukankah ChatGPT sepatutnya lebih baik daripada ini? !
Nah, ya. ChatGPT benar-benar hebat dalam meringkaskan kod teknikal MITRE ATT&CK, tetapi kami belum bertanya mengenainya lagi. Kami telah menggunakan model Transformer-3.5 (GPT-3.5) "text-davinci-003" terlatih peringkat tertinggi OpenAI dalam mod penyiapan teks. ChatGPT menggunakan model "gpt-3.5-turbo" dalam mod penyelesaian sembang. Perbezaannya sangat besar. Berikut ialah contoh jawapan ChatGPT kepada pertanyaan yang sama di atas:
Tetapi penyambung OpenAI dalam Apl Logik Azure kami tidak memberikan kami tindakan berasaskan sembang, dan kami Tidak mempunyai pilihan untuk model Turbo, jadi bagaimana kami boleh memperkenalkan ChatGPT ke dalam aliran kerja Sentinel kami? Sama seperti kami menutup Penyambung Aplikasi Logik Sentinel dalam Bahagian II untuk memanggil terus operasi HTTP API Sentinel REST, kami boleh melakukan perkara yang sama dengan API OpenAI. Mari kita terokai proses membina aliran kerja Apl Logik yang menggunakan model sembang dan bukannya model pelengkapan teks.
Kami akan merujuk kepada dua dokumen rujukan daripada OpenAI: Rujukan API Penciptaan Sembang dan Panduan Penyiapan Sembang. Untuk memastikan catatan blog ini pada panjang yang munasabah, saya akan meringkaskan beberapa tugas persediaan yang anda perlukan untuk meniru contoh kami dalam persekitaran anda sendiri:
- Kekunci Kebal untuk menyimpan bukti kelayakan API OpenAI anda
- Satu cara untuk membenarkan Apl Logik anda membaca rahsia daripada Key Vault (saya syorkan menggunakan Identiti Terurus Azure RBAC)
- Rangkaian yang membenarkan Apl Logik anda menyambung ke Akses Bilik Kekunci (saya menggunakan alamat IP dan julat CIDR yang ditentukan untuk rantau Azure yang sesuai dalam dokumen penyambung)
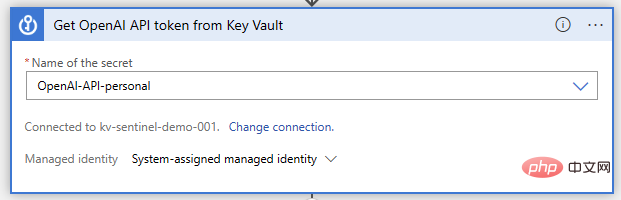
Sekarang, mari buka pereka Aplikasi Logik kami dan mula membina fungsi tersebut. Sama seperti sebelum ini, kami menggunakan pencetus peristiwa Microsoft Sentinel. Kami akan melakukan operasi Bilik Kekunci Kunci "Dapatkan rahsia" selepas ini, di mana kami akan menentukan nama rahsia tempat kunci API disimpan:
Seterusnya, kami perlu menyediakan Permintaan API memulakan dan menetapkan beberapa pembolehubah. Ini tidak semestinya diperlukan; kami hanya boleh menulis permintaan dalam tindakan HTTP kami, tetapi ia akan memudahkan untuk menukar gesaan dan parameter lain kemudian. Dua parameter yang diperlukan dalam panggilan OpenAI Chat API ialah "model" dan "mesej", jadi mari kita mulakan pembolehubah rentetan untuk menyimpan nama model dan pembolehubah tatasusunan untuk mesej.
Parameter "mesej" ialah input utama kepada model sembang. Ia dibina sebagai satu set objek mesej, masing-masing mempunyai peranan, seperti "sistem" atau "pengguna", dan kandungan. Mari lihat contoh dari Taman Permainan:
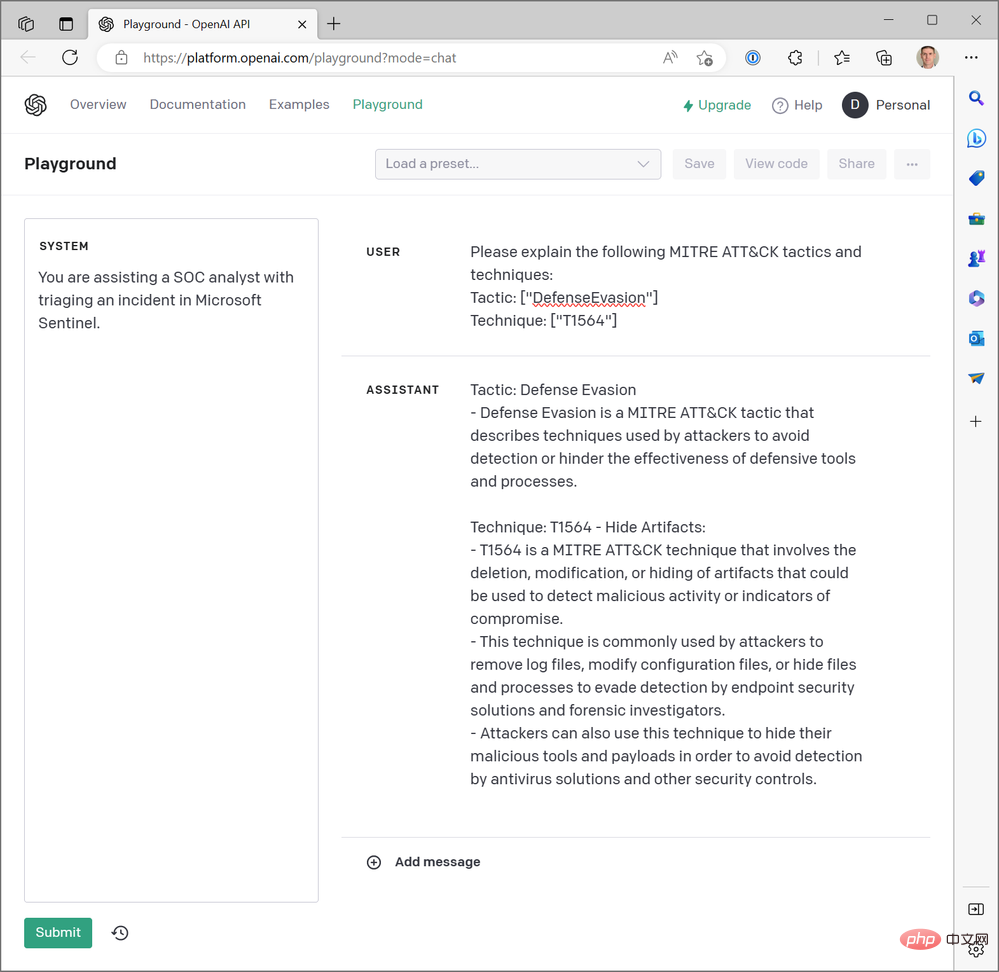
Objek Sistem membolehkan kami menetapkan konteks tingkah laku model AI untuk sesi sembang ini. Objek Pengguna ialah soalan kami dan model akan membalas dengan objek Assistant. Jika perlu, kami boleh memasukkan respons sebelumnya dalam objek Pengguna dan Pembantu untuk menyediakan model AI dengan "sejarah perbualan."
Kembali dalam Pereka Apl Logik kami, saya menggunakan dua tindakan "Tambah pada Pembolehubah Tatasusunan" dan satu tindakan "Memulakan Pembolehubah" untuk membina tatasusunan "Mesej":
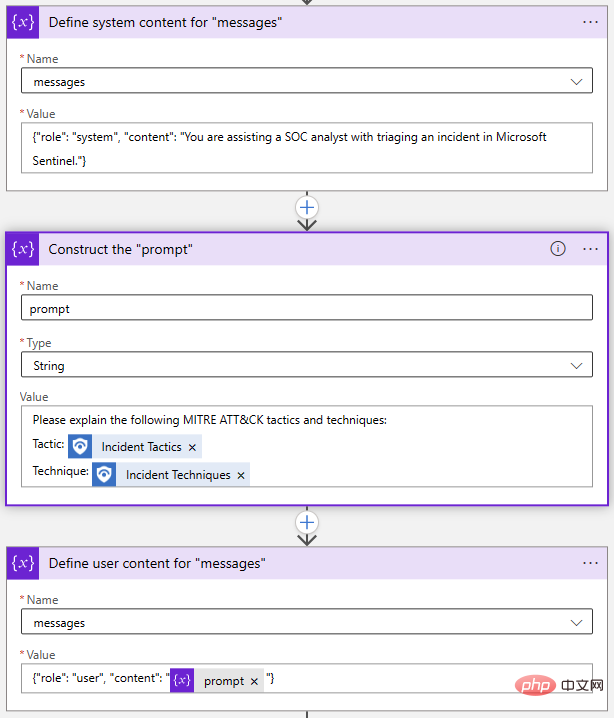
Sekali lagi, ini semua boleh dilakukan dalam satu langkah, tetapi saya memilih untuk meletupkan setiap objek secara berasingan. Jika saya ingin mengubah suai gesaan saya, saya hanya perlu mengemas kini pembolehubah Prompt.
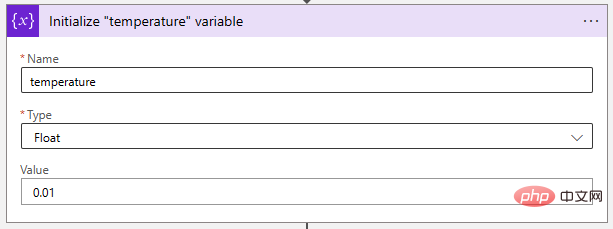
Seterusnya, mari laraskan parameter suhu kepada nilai yang sangat rendah untuk menjadikan model AI lebih deterministik. Pembolehubah "Float" sesuai untuk menyimpan nilai ini.
Akhir sekali, mari kita gabungkan mereka dengan tindakan HTTP seperti ini:
- Kaedah: Mel
- Jenis: https: //api.openai.com/v1/chat/completions
- Badan:
{"model": @{variables('model')},"messages": @{variables('messages')},"temperature": @{variables('temperature')}} - Pengesahan: Mentah
- Nilai:
Bearer @{body('Get_OpenAI_API_token_from_Key_Vault')?['value']}
- Nilai:
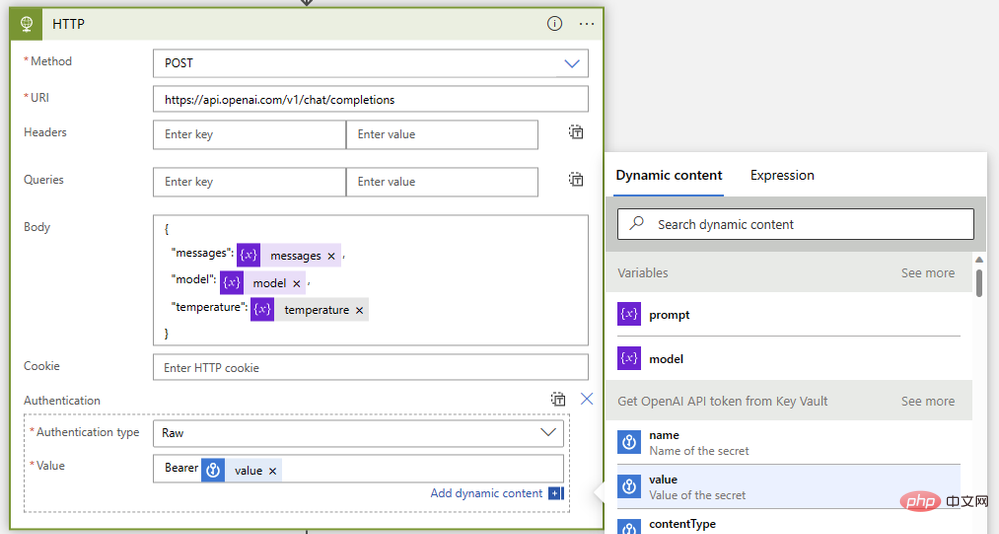
Seperti sebelum ini, mari jalankan buku main ini tanpa sebarang tindakan ulasan untuk memastikan semuanya baik-baik saja sehingga saya menyambung kembali ke tika Sentinel. Jika semuanya berjalan lancar, kami akan mendapat kod status 200 dan ringkasan hebat taktik dan teknik MITER ATT&CK dalam mesej pembantu.
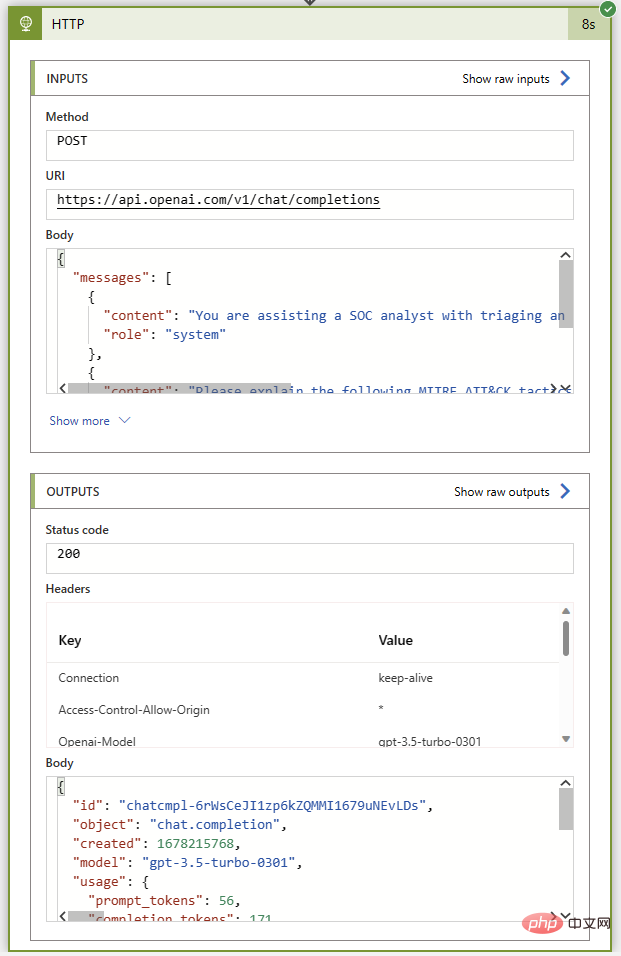
Kini tiba bahagian yang mudah: menambah ulasan acara menggunakan penyambung Sentinel. Kami akan menggunakan operasi Parse JSON untuk menghuraikan badan tindak balas dan kemudian memulakan pembolehubah dengan teks daripada balasan ChatGPT. Memandangkan kami mengetahui format respons, kami tahu bahawa kami boleh mengekstrak balasan daripada item Pilihan pada indeks 0 menggunakan ungkapan berikut:
@{body('Parse_JSON')?['choices']?[0]?['message']?['content']}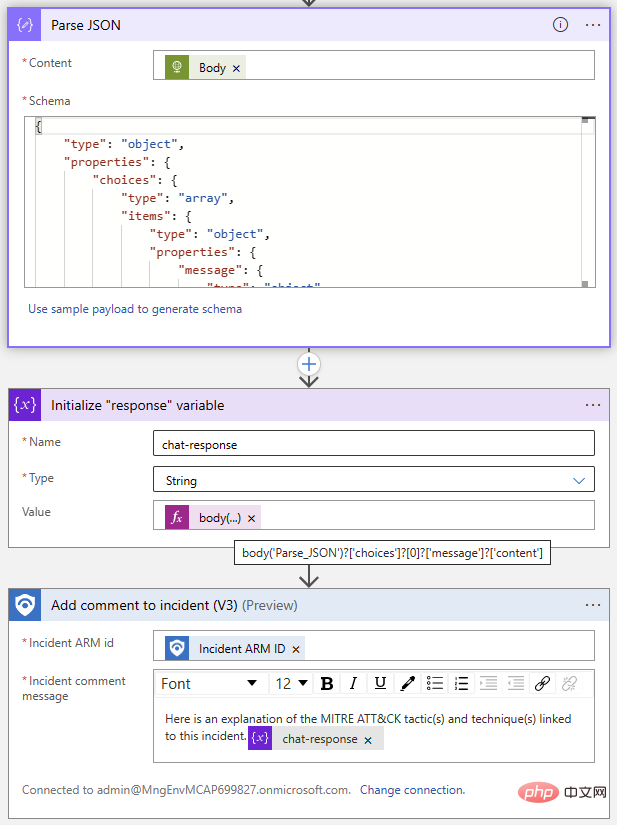
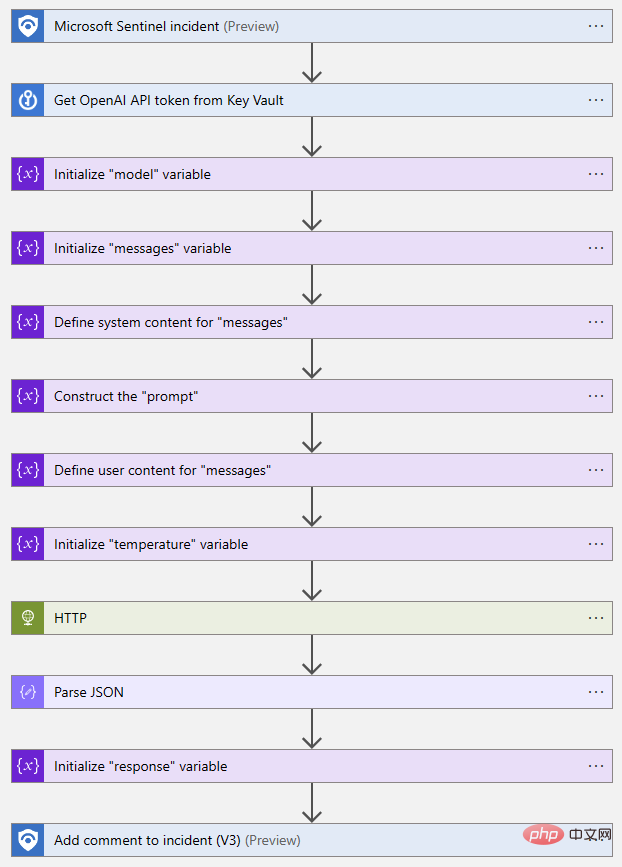
Berikut ialah yang telah dilengkapkan aplikasi logik Pandangan udara proses:
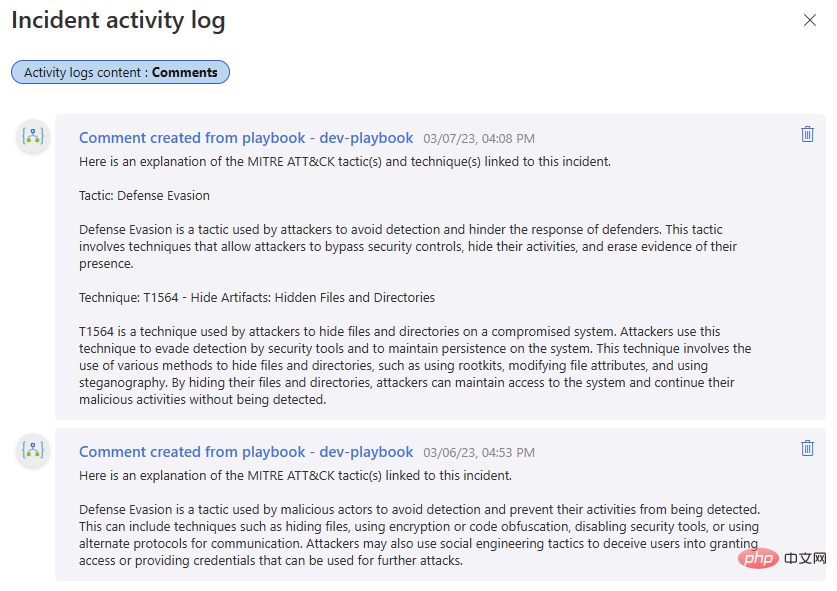
Jom cuba! Saya menyertakan ulasan daripada lelaran sebelumnya bagi buku main ini dalam bahagian pertama siri OpenAI dan Sentinel ini - adalah menarik untuk membandingkan output pelengkapan teks DaVinci dengan interaksi sembang model Turbo.
Atas ialah kandungan terperinci OpenAI dan Microsoft Sentinel Bahagian 3: DaVinci dan Turbo. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!