
Rumah >pembangunan bahagian belakang >Tutorial Python >Saya telah menyusun beberapa ungkapan biasa Python, anda boleh mengambilnya dan menggunakannya!
Saya telah menyusun beberapa ungkapan biasa Python, anda boleh mengambilnya dan menggunakannya!

- PHPzke hadapan
- 2023-04-14 18:07:051702semak imbas

Ekspresi biasa boleh digunakan untuk mencari, mengedit dan memanipulasi teks. Python RegEx digunakan secara meluas oleh hampir semua syarikat dan mempunyai daya tarikan industri yang baik untuk aplikasi mereka, menjadikan ungkapan biasa semakin penting.
Hari ini kita akan belajar ungkapan biasa Python bersama-sama.
Mengapa menggunakan ungkapan biasa.
Untuk menjawab soalan ini, mari kita lihat dahulu pelbagai masalah yang kita hadapi yang boleh diselesaikan dengan menggunakan ungkapan biasa.
Pertimbangkan senario berikut:
Pada penghujung artikel, terdapat fail log yang mengandungi sejumlah besar data Daripada fail log ini, anda hanya ingin mendapatkan tarikh dan masa . Pada pandangan pertama, kebolehbacaan fail log adalah sangat rendah.

Dalam kes ini, ungkapan biasa boleh digunakan untuk mengenal pasti corak dan mengekstrak maklumat yang diperlukan dengan mudah.
Pertimbangkan senario seterusnya: anda seorang jurujual dan mempunyai banyak alamat e-mel, kebanyakannya adalah palsu/tidak sah, lihat imej di bawah:

Apa yang boleh kami lakukan ialah menggunakan ungkapan biasa yang boleh mengesahkan format alamat e-mel dan menapis ID palsu daripada ID sebenar.
Senario seterusnya sangat serupa dengan contoh jurujual, pertimbangkan imej berikut:

Bagaimanakah kita boleh mengesahkan nombor telefon dan kemudian membandingkannya berdasarkan negara asal Kelaskan?
Setiap nombor yang betul akan mempunyai corak tertentu yang boleh dikesan dan dijejaki dengan menggunakan ungkapan biasa.
Seterusnya ialah satu lagi senario mudah:
Kami mempunyai pangkalan data pelajar dengan butiran seperti nama, umur dan alamat. Pertimbangkan situasi di mana kod daerah pada asalnya ialah 59006 tetapi kini telah ditukar kepada 59076, situasi di mana mengemas kini kod ini secara manual untuk setiap pelajar akan memakan masa yang lama dan prosesnya sangat panjang.
Pada asasnya, untuk menyelesaikan masalah ini menggunakan ungkapan biasa, kami mula-mula mencari rentetan tertentu daripada data pelajar yang mengandungi kod pin dan kemudian menggantikan semuanya dengan rentetan baharu.
Apakah itu ungkapan biasa
Ungkapan biasa digunakan untuk mengenal pasti corak carian dalam rentetan teks, ia juga membantu dalam mengetahui ketepatan data dan juga boleh dilakukan menggunakan ungkapan biasa Operasi seperti mencari, menggantikan dan memformat data.
Pertimbangkan contoh berikut:

Daripada semua data untuk rentetan tertentu, dengan mengandaikan kami hanya mahu bandar, ini boleh ditukar dalam format yang cara ke Kamus yang mengandungi hanya nama dan bandar. Persoalannya sekarang, bolehkah kita mengenal pasti corak untuk meneka nama dan bandar? Juga kita boleh mengetahui umur, semakin meningkat usia, mudah, bukan? Ia hanya integer.
Apa yang kita lakukan dengan nama ini? Jika dilihat pada coraknya, semua nama bermula dengan huruf besar. Dengan bantuan ungkapan biasa, kita boleh mengenal pasti nama dan umur menggunakan kaedah ini.
Kita boleh menggunakan kod berikut
import re
Nameage = '''
Janice is 22 and Theon is 33
Gabriel is 44 and Joey is 21
'''
ages = re.findall(r'd{1,3}', Nameage)
names = re.findall(r'[A-Z][a-z]*',Nameage)
ageDict = {}
x = 0
for eachname in names
ageDict[eachname] = ages[x]
x+=1
print(ageDict)Output:
{'Janice': '22', 'Theon': '33', 'Gabriel': '44', 'Joey': '21'}Beberapa contoh ungkapan biasa:
Anda boleh melakukan banyak operasi menggunakan ungkapan biasa. Di sini saya telah menyenaraikan beberapa perkara yang sangat penting untuk membantu lebih memahami penggunaan ungkapan biasa.
Mari kita semak dahulu cara mencari perkataan tertentu dalam rentetan
Cari perkataan dalam rentetan
import re
if re.search("inform","we need to inform him with the latest information"):
print("There is inform")Apa yang kita ada di sini Apa yang dilakukannya ialah mencari perkataan inform untuk hadir dalam rentetan carian kami.
Sudah tentu kami juga boleh mengoptimumkan kod berikut
import re
allinform = re.findall("inform","We need to inform him with the latest information!")
for i in allinform:
print(i)Di sini, dalam kes ini, maklumat akan ditemui dua kali. Satu datang daripada maklumat dan satu lagi datang daripada maklumat.
Seperti yang ditunjukkan di atas, mencari perkataan dalam ungkapan biasa adalah semudah itu.
Seterusnya kita akan belajar cara menjana iterator menggunakan ungkapan biasa.
Menjana lelaran
Menjana lelaran ialah proses mudah mencari dan menyasarkan indeks permulaan dan penamat rentetan. Pertimbangkan contoh berikut:
import re
Str = "we need to inform him with the latest information"
for i in re.finditer("inform.", Str
locTuple = i.span()
print(locTuple)Untuk setiap perlawanan yang ditemui, indeks mula dan tamat dicetak. Apabila kita melaksanakan program di atas, output adalah seperti berikut:
(11, 18) (38, 45)
Seterusnya kita akan menyemak cara memadankan perkataan dengan corak menggunakan ungkapan biasa.
将单词与模式匹配
考虑一个输入字符串,我们必须将某些单词与该字符串匹配。要详细说明,请查看以下示例代码:
import re
Str = "Sat, hat, mat, pat"
allStr = re.findall("[shmp]at", Str)
for i in allStr:
print(i)字符串中有什么共同点?可以看到字母“a”和“t”在所有输入字符串中都很常见。代码中的 [shmp] 表示要查找的单词的首字母,因此,任何以字母 s、h、m 或 p 开头的子字符串都将被视为匹配,其中任何一个,并且最后必须跟在“at”后面。
Output:
hat mat pat
接下来我们将检查如何使用正则表达式一次匹配一系列字符。
匹配一系列字符范围
我们希望输出第一个字母应该在 h 和 m 之间并且必须紧跟 at 的所有单词。看看下面的例子,我们应该得到的输出是 hat 和 mat
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[h-m]at", Str)
for i in someStr:
print(i)Output:
hat mat
现在让我们稍微改变一下上面的程序以获得一个不同的结果
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[^h-m]at", Str)
for i in someStr:
print(i)发现细微差别了吗,我们在正则表达式中添加了插入符号 (^),它的作用否定了它所遵循的任何效果。我们不会给出从 h 到 m 开始的所有内容的输出,而是会向我们展示除此之外的所有内容的输出。
我们可以预期的输出是不以 h 和 m 之间的字母开头但最后仍然紧随其后的单词。Output:
sat pat
替换字符串:
接下来,我们可以使用正则表达式检查另一个操作,其中我们将字符串中的一项替换为其他内容:
import re
Food = "hat rat mat pat"
regex = re.compile("[r]at")
Food = regex.sub("food", Food)
print(Food)在上面的示例中,单词 rat 被替换为单词 food。正则表达式的替代方法就是利用这种情况,它也有各种各样的实际用例。Output:
hat food mat pat
反斜杠问题
import re randstr = "Here is Edureka" print(randstr)
Output:
Here is Edureka
这就是反斜杠问题,其中一个斜线从输出中消失了,这个特殊问题可以使用正则表达式来解决。
import re randstr = "Here is Edureka" print(re.search(r"Edureka", randstr))
Output:
<re.Match object; span=(8, 16), match='Edureka'>
这就是使用正则表达式解决反斜杠问题的简单方法。
匹配单个字符
使用正则表达式可以轻松地单独匹配字符串中的单个字符
import re
randstr = "12345"
print("Matches: ", len(re.findall("d{5}", randstr)))Output:
Matches: 1
删除换行符
我们可以在 Python 中使用正则表达式轻松删除换行符
import re
randstr = '''
You Never
Walk Alone
Liverpool FC
'''
print(randstr)
regex = re.compile("
")
randstr = regex.sub(" ", randstr)
print(randstr)Output:
You Never Walk Alone Liverpool FC You Never Walk Alone Liverpool FC
可以从上面的输出中看到,新行已被空格替换,并且输出打印在一行上。
还可以使用许多其他东西,具体取决于要替换字符串的内容
: Backspace : Formfeed : Carriage Return : Tab : Vertical Tab
可以使用如下代码
import re
randstr = "12345"
print("Matches:", len(re.findall("d", randstr)))Output:
Matches: 5
从上面的输出可以看出,d 匹配字符串中存在的整数。但是,如果我们用 D 替换它,它将匹配除整数之外的所有内容,与 d 完全相反。
接下来我们了解一些在 Python 中使用正则表达式的重要实际例子。
正则表达式的实际例子
我们将检查使用最为广泛的 3 个主要用例
- 电话号码验证
- 电子邮件地址验证
- 网页抓取
电话号码验证
需要在任何相关场景中轻松验证电话号码
考虑以下电话号码:
- 444-122-1234
- 123-122-78999
- 111-123-23
- 67-7890-2019
电话号码的一般格式如下:
- 以 3 位数字和“-”符号开头
- 3 个中间数字和“-”号
- 最后4位数
我们将在下面的示例中使用 w,请注意 w = [a-zA-Z0-9_]
import re
phn = "412-555-1212"
if re.search("w{3}-w{3}-w{4}", phn):
print("Valid phone number")Output:
Valid phone number
电子邮件验证
在任何情况下验证电子邮件地址的有效性。
考虑以下电子邮件地址示例:
- Anirudh@gmail.com
- Anirudh@com
- AC.com
- 123 @.com
我们只需一眼就可以从无效的邮件 ID 中识别出有效的邮件 ID,但是当我们的程序为我们做这件事时,却并没有那么容易,但是使用正则,就非常简单了。
指导思路,所有电子邮件地址应包括:
- 1 到 20 个小写和/或大写字母、数字以及 . _ % +
- 一个@符号
- 2 到 20 个小写和大写字母、数字和加号
- 一个点号
- 2 到 3 个小写和大写字母
import re
email = "ac@aol.com md@.com @seo.com dc@.com"
print("Email Matches: ", len(re.findall("[w._%+-]{1,20}@[w.-]{2,20}.[A-Za-z]{2,3}", email)))Output:
Email Matches: 1
从上面的输出可以看出,我们输入的 4 封电子邮件中有一封有效的邮件。
这基本上证明了使用正则表达式并实际使用它们是多么简单和高效。
网页抓取
从网站上删除所有电话号码以满足需求。
要了解网络抓取,请查看下图:
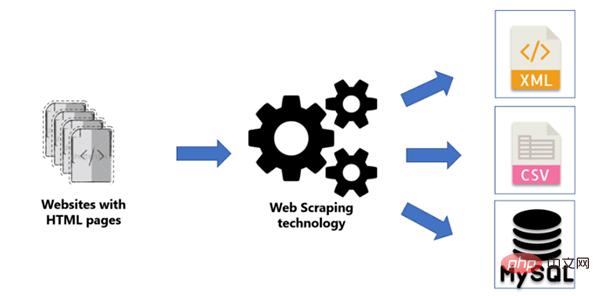
我们已经知道,一个网站将由多个网页组成,我们需要从这些页面中抓取一些信息。
网页抓取主要用于从网站中提取信息,可以将提取的信息以 XML、CSV 甚至 MySQL 数据库的形式保存,这可以通过使用 Python 正则表达式轻松实现。
import urllib.request
from re import findall
url = "http://www.summet.com/dmsi/html/codesamples/addresses.html"
response = urllib.request.urlopen(url)
html = response.read()
htmlStr = html.decode()
pdata = findall("(d{3}) d{3}-d{4}", htmlStr)
for item in pdata:
print(item)Output:
(257) 563-7401 (372) 587-2335 (786) 713-8616 (793) 151-6230 (492) 709-6392 (654) 393-5734 (404) 960-3807 (314) 244-6306 (947) 278-5929 (684) 579-1879 (389) 737-2852 ...
我们首先是通过导入执行网络抓取所需的包,最终结果包括作为使用正则表达式完成网络抓取的结果而提取的电话号码。
Atas ialah kandungan terperinci Saya telah menyusun beberapa ungkapan biasa Python, anda boleh mengambilnya dan menggunakannya!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!