
Rumah >Peranti teknologi >AI >Kaedah latihan yang jarang untuk model besar dengan ketepatan yang tinggi dan penggunaan sumber yang rendah telah dijumpai.
Kaedah latihan yang jarang untuk model besar dengan ketepatan yang tinggi dan penggunaan sumber yang rendah telah dijumpai.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-13 19:01:011540semak imbas
Baru-baru ini, kertas kerja Alibaba Cloud Machine Learning PAI "Parameter-Efficient Sparsity for Large Language Models Fine-Tuning" mengenai latihan jarang model besar telah diterima oleh IJCAI 2022, persidangan kecerdasan buatan teratas.
Kertas ini mencadangkan algoritma latihan jarang yang cekap parameter PST Dengan menganalisis indeks kepentingan pemberat, disimpulkan bahawa ia mempunyai dua ciri: peringkat rendah dan struktur. Berdasarkan kesimpulan ini, algoritma PST memperkenalkan dua set matriks kecil untuk mengira kepentingan pemberat Berbanding dengan keperluan asal untuk matriks sebesar berat untuk menyimpan dan mengemas kini indeks kepentingan, jumlah parameter yang perlu. dikemas kini untuk latihan yang jarang dikurangkan. Berbanding dengan algoritma latihan jarang yang biasa digunakan, algoritma PST boleh mencapai ketepatan model jarang yang serupa sambil mengemas kini hanya 1.5% parameter.
Latar Belakang
Dalam beberapa tahun kebelakangan ini, syarikat utama dan institusi penyelidikan telah mencadangkan pelbagai model besar, dengan parameter antara berpuluh bilion hingga puluhan ribu daripada berbilion-bilion hingga ratusan bilion, malah model super besar berpuluh-puluh trilion telah muncul. Model ini memerlukan sejumlah besar sumber perkakasan untuk dilatih dan digunakan, yang menjadikannya sukar untuk dilaksanakan. Oleh itu, bagaimana untuk mengurangkan sumber yang diperlukan untuk latihan dan penggunaan model besar telah menjadi masalah yang mendesak.
Teknologi pemampatan model secara berkesan boleh mengurangkan sumber yang diperlukan untuk penggunaan model Dengan mengalih keluar beberapa pemberat, pengiraan dalam model boleh ditukar daripada pengiraan padat kepada pengiraan jarang, dengan itu mengurangkan penggunaan memori dan mempercepatkan pengiraan. Pada masa yang sama, berbanding dengan kaedah pemampatan model lain (pemangkasan/kuantisasi berstruktur), jarang boleh mencapai kadar mampatan yang lebih tinggi sambil memastikan ketepatan model, dan lebih sesuai untuk model besar dengan sejumlah besar parameter.
Cabaran
Kaedah latihan jarang sedia ada boleh dibahagikan kepada dua kategori, satu ialah algoritma jarang tanpa data berasaskan berat; algoritma jarang. Algoritma jarang berasaskan berat ditunjukkan dalam rajah di bawah, seperti pemangkasan magnitud [1], yang menilai kepentingan berat dengan mengira norma L1 berat, dan menjana hasil jarang sepadan berdasarkan ini. Algoritma jarang berasaskan berat adalah cekap dalam pengiraan dan tidak memerlukan penyertaan data latihan, tetapi indeks kepentingan yang dikira tidak cukup tepat, sekali gus menjejaskan ketepatan model jarang akhir.
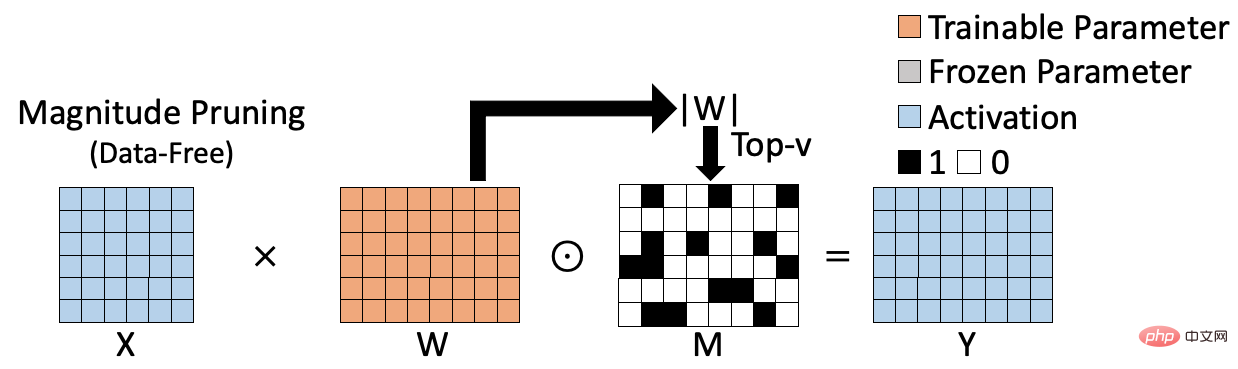
Algoritma jarang berasaskan data ditunjukkan dalam rajah di bawah, seperti pemangkasan pergerakan[2], yang mengukur kepentingan berat dengan mengira hasil darab berat dan penunjuk seksual kecerunan yang sepadan. Kaedah jenis ini mengambil kira peranan pemberat pada set data tertentu dan oleh itu boleh menilai dengan lebih tepat kepentingan pemberat. Walau bagaimanapun, disebabkan keperluan untuk mengira dan menyimpan kepentingan setiap berat, kaedah jenis ini sering memerlukan ruang tambahan untuk menyimpan indeks kepentingan (S dalam rajah). Pada masa yang sama, berbanding dengan kaedah jarang berasaskan berat, proses pengiraan selalunya lebih kompleks. Kelemahan ini menjadi lebih jelas apabila saiz model meningkat.
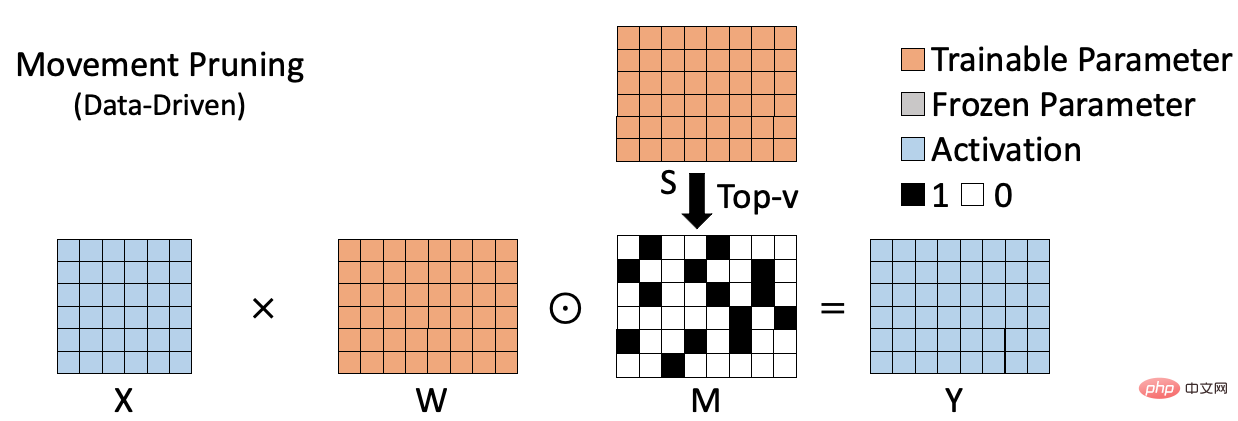
Ringkasnya, algoritma jarang sebelumnya adalah sama ada cekap tetapi tidak cukup tepat (algoritma berasaskan berat), atau tepat tetapi tidak cukup cekap (data -algoritma berasaskan). Oleh itu, kami berharap dapat mencadangkan algoritma jarang yang cekap yang boleh melaksanakan latihan jarang pada model besar dengan tepat dan cekap.
Break
Masalah dengan algoritma jarang berasaskan data ialah mereka biasanya memperkenalkan parameter tambahan yang sama saiz dengan pemberat untuk mengetahui kepentingan pemberat, yang membawa kita kepada Fikirkan tentang cara mengurangkan kepentingan memperkenalkan parameter tambahan untuk mengira berat. Pertama sekali, untuk memaksimumkan penggunaan maklumat sedia ada untuk mengira kepentingan pemberat, kami mereka bentuk indeks kepentingan pemberat sebagai formula berikut:
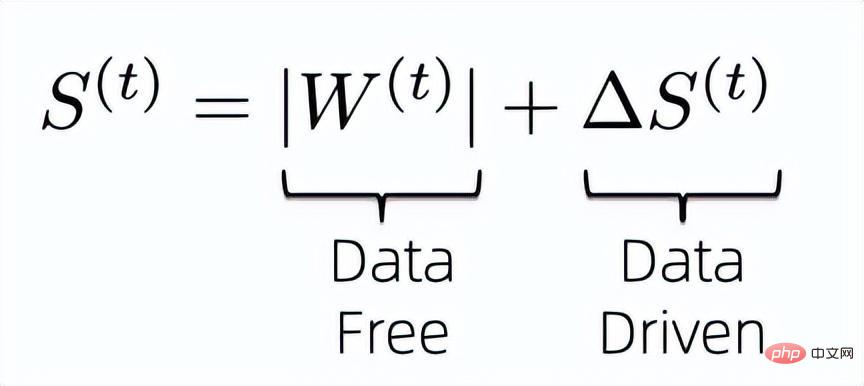
Iaitu, kami menggabungkan penunjuk bebas data dan dipacu data untuk bersama-sama menentukan kepentingan berat model akhir. Adalah diketahui bahawa indeks kepentingan bebas data sebelumnya tidak memerlukan parameter tambahan untuk disimpan dan cekap dalam pengiraan, jadi apa yang perlu kita selesaikan ialah cara memampatkan parameter latihan tambahan yang diperkenalkan oleh indeks kepentingan dipacu data kemudian.
Berdasarkan algoritma jarang sebelumnya, indeks kepentingan terdorong data boleh direka bentuk sebagai

, jadi kami mula menganalisis lebihan penunjuk kepentingan yang dikira oleh formula ini. Pertama sekali, berdasarkan kerja sebelumnya, diketahui bahawa kedua-dua pemberat dan kecerunan yang sepadan mempunyai sifat peringkat rendah yang jelas [3, 4], jadi kita boleh menyimpulkan bahawa indeks kepentingan juga mempunyai sifat peringkat rendah, jadi kita boleh memperkenalkan dua sifat peringkat rendah Matriks kecil untuk mewakili matriks penunjuk kepentingan asal yang sama besar dengan pemberat.
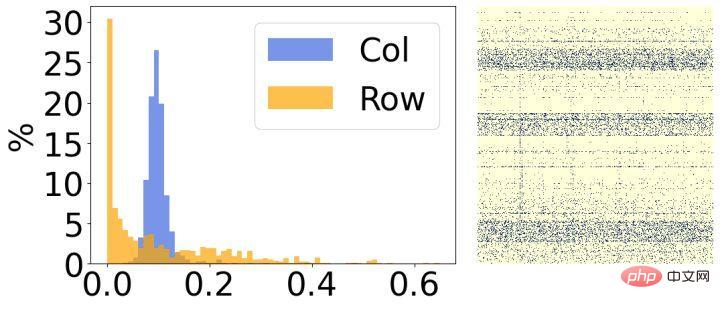
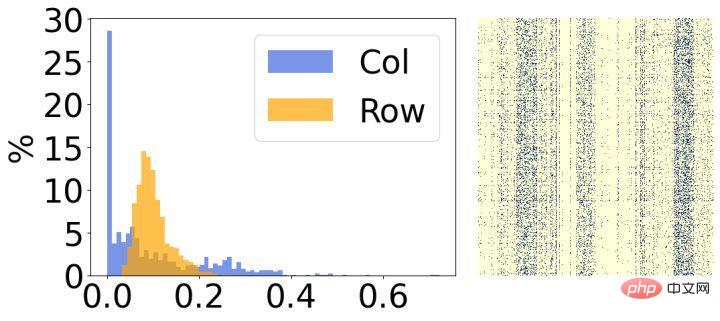
Kedua, kami menganalisis keputusan selepas jarang model dan mendapati ia mempunyai ciri-ciri struktur yang jelas. Seperti yang ditunjukkan dalam rajah di atas, sebelah kanan setiap gambar ialah hasil visualisasi berat jarang akhir, dan sebelah kiri ialah histogram yang mengira kadar sparsity yang sepadan bagi setiap baris/lajur. Dapat dilihat bahawa kebanyakan pemberat dalam 30% baris dalam gambar kiri telah dialih keluar, dan sebaliknya, kebanyakan pemberat dalam 30% lajur dalam gambar kanan telah dialih keluar. Berdasarkan fenomena ini, kami memperkenalkan dua matriks berstruktur kecil untuk menilai kepentingan setiap baris/lajur pemberat.
Berdasarkan analisis di atas, kami mendapati bahawa indeks kepentingan terdorong data mempunyai kedudukan dan struktur yang rendah, jadi kami boleh menukarnya kepada perwakilan berikut:
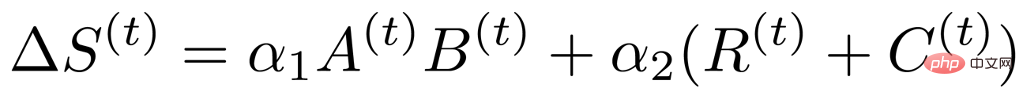
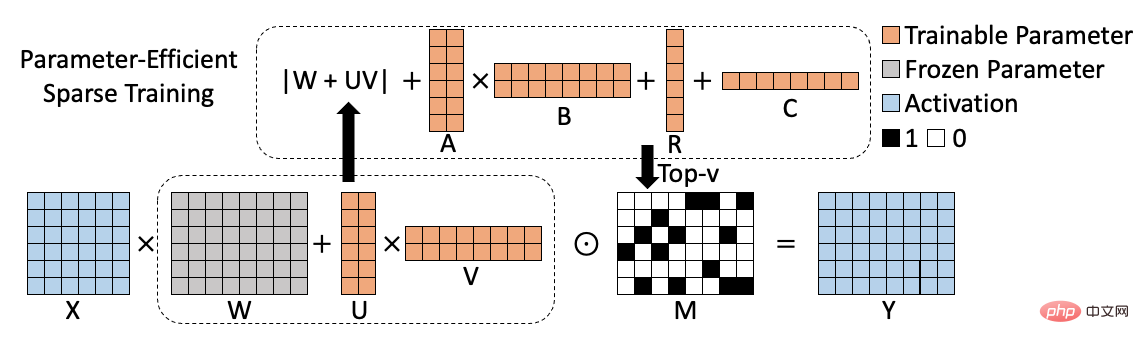
di mana A dan B mewakili kedudukan rendah, dan R dan C mewakili struktur. Melalui analisis sedemikian, matriks indeks kepentingan, yang asalnya sebesar berat, telah diuraikan kepada empat matriks kecil, sekali gus mengurangkan parameter latihan yang terlibat dalam latihan jarang. Pada masa yang sama, untuk mengurangkan lagi parameter latihan, kami menguraikan kemas kini berat kepada dua matriks kecil U dan V berdasarkan kaedah sebelumnya, jadi formula indeks kepentingan akhir menjadi bentuk berikut:
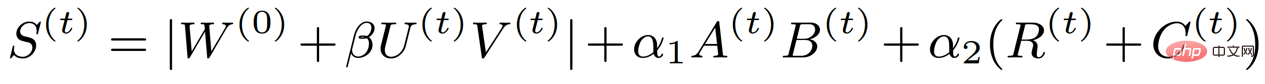
Rajah rangka kerja algoritma yang sepadan adalah seperti berikut:
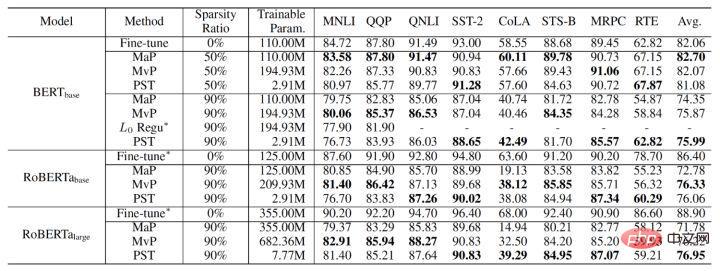
Keputusan percubaan algoritma PST terakhir ialah seperti berikut. Kami Dibandingkan dengan pemangkasan magnitud dan pemangkasan pergerakan pada tugas NLU (BERT, RoBERTa) dan NLG (GPT-2), pada kadar sparsity 90%, PST boleh mencapai ketepatan model yang setanding dengan algoritma sebelumnya pada kebanyakan set data. , tetapi Hanya 1.5% daripada parameter latihan diperlukan.

Teknologi PST telah disepadukan ke dalam perpustakaan mampatan model Alibaba Cloud Machine Learning PAI, serta model besar platform Alicemind Dalam fungsi latihan yang jarang. Ia telah membawa pecutan prestasi kepada penggunaan model besar dalam Kumpulan Alibaba Pada berpuluh bilion PLUG model besar, PST boleh memecut 2.5 kali tanpa mengurangkan ketepatan model dan mengurangkan penggunaan memori sebanyak 10 kali berbanding dengan latihan yang jarang. Pada masa ini, PAI Pembelajaran Mesin Awan Alibaba telah digunakan secara meluas dalam pelbagai industri, menyediakan perkhidmatan pembangunan AI pautan penuh, merealisasikan penyelesaian AI bebas dan boleh dikawal untuk perusahaan, dan meningkatkan kecekapan kejuruteraan pembelajaran mesin secara menyeluruh.
Nama kertas: Parameter-Efficient Sparsity untuk Model Bahasa Besar Penalaan Halus
Penulis kertas: Yuchao Li, Fuli Luo, Chuanqi Tan, Mengdi Wang , Songfang Huang , Shen Li , Junjie Bai
Pautan pdf kertas: https://arxiv.org/pdf/2205.11005.pdf
Atas ialah kandungan terperinci Kaedah latihan yang jarang untuk model besar dengan ketepatan yang tinggi dan penggunaan sumber yang rendah telah dijumpai.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI