
Rumah >Peranti teknologi >AI >Menggunakan visualisasi perisian dan pemindahan pembelajaran dalam ramalan kecacatan perisian
Menggunakan visualisasi perisian dan pemindahan pembelajaran dalam ramalan kecacatan perisian

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-13 14:43:031625semak imbas
Motivasi artikel adalah untuk mengelakkan perwakilan perantaraan kod sumber, mewakili kod sumber sebagai imej dan terus mengekstrak maklumat semantik kod untuk meningkatkan prestasi ramalan kecacatan.
Pertama, lihat contoh motivasi seperti yang ditunjukkan di bawah. Walaupun kedua-dua contoh File1.java dan File2.java mengandungi 1 pernyataan if, 2 untuk pernyataan dan 4 panggilan fungsi, ciri semantik dan struktur kod adalah berbeza. Untuk mengesahkan sama ada menukar kod sumber kepada imej boleh membantu membezakan kod yang berbeza, pengarang menjalankan eksperimen: memetakan kod sumber kepada piksel mengikut nombor perpuluhan ASCII aksara, menyusunnya ke dalam matriks piksel dan mendapatkan imej kod sumber. Penulis menunjukkan bahawa terdapat perbezaan antara imej kod sumber yang berbeza.

Gamb. 1 Contoh Motivasi
Sumbangan utama artikel adalah seperti berikut:
Tukar kod kepada imej dan ekstrak maklumat semantik dan struktur daripadanya ;
Cadangkan rangka kerja hujung ke hujung yang menggabungkan mekanisme perhatian kendiri dan pemindahan pembelajaran untuk mencapai ramalan kecacatan.
Rangka kerja model yang dicadangkan dalam artikel ditunjukkan dalam Rajah 2, yang dibahagikan kepada dua peringkat: visualisasi kod sumber dan pemodelan pembelajaran pemindahan mendalam.
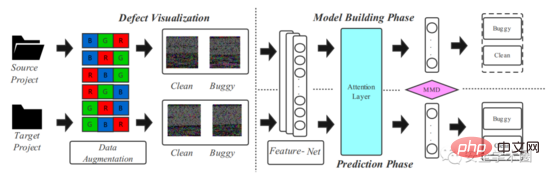
Gamb. 2 Rangka Kerja
1. Visualisasi kod sumber
Artikel menukar kod sumber kepada 6 imej, prosesnya ditunjukkan dalam Rajah 3 ditunjukkan. Tukar kod ASCII perpuluhan bagi aksara kod sumber kepada vektor integer tidak bertanda 8-bit, susun vektor ini mengikut baris dan lajur dan jana matriks imej. Integer 8-bit secara langsung sepadan dengan tahap kelabu. Untuk menyelesaikan masalah set data asal yang kecil, penulis mencadangkan kaedah pengembangan set data berdasarkan peningkatan warna dalam artikel: nilai tiga saluran warna R, G, dan B disusun dan digabungkan untuk menghasilkan 6 imej berwarna. Ia kelihatan agak mengelirukan di sini Selepas menukar nilai saluran, maklumat semantik dan struktur harus berubah, bukan? Tetapi penulis menerangkannya dalam nota kaki, seperti yang ditunjukkan dalam Rajah 4.
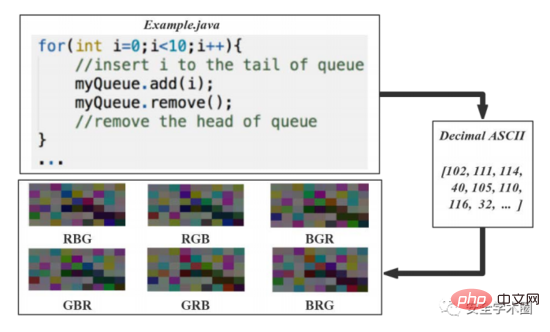
Gamb. 3 Proses visualisasi kod sumber

Gamb. 4 Nota kaki artikel 2
2 .Pemodelan Pembelajaran Pemindahan Dalam
Artikel menggunakan rangkaian DAN untuk menangkap maklumat semantik dan struktur kod sumber. Untuk meningkatkan keupayaan model untuk menyatakan maklumat penting, penulis menambah lapisan Perhatian pada struktur DAN asal. Proses latihan dan ujian ditunjukkan dalam Rajah 5, di mana conv1-conv5 datang daripada AlexNet, dan empat lapisan bersambung sepenuhnya fc6-fc9 digunakan sebagai pengelas. Penulis menyebut bahawa untuk projek baharu, melatih model pembelajaran mendalam memerlukan sejumlah besar data berlabel, yang sukar. Oleh itu, pengarang mula-mula melatih model pra-latihan pada ImageNet 2012, dan menggunakan parameter model pra-latihan sebagai parameter awal untuk memperhalusi semua lapisan konvolusi, dengan itu mengurangkan perbezaan antara imej kod dan imej dalam ImageNet 2012.
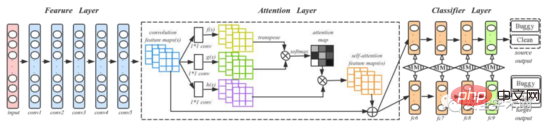
Gamb. 5 Proses latihan dan ujian
3 Latihan dan ramalan model
Kod dan Sasaran yang diberi tag dalam projek Sumber yang tidak berlabel. kod dalam projek menjana imej kod dan memasukkannya ke dalam model pada masa yang sama; kedua-duanya berkongsi lapisan konvolusi dan lapisan Perhatian untuk mengekstrak ciri masing-masing. Kira MK-MDD (Perbezaan Min Maksimum Varian Berbilang Kernel) antara Sumber dan Sasaran dalam lapisan bersambung sepenuhnya. Memandangkan Sasaran tidak mempunyai label, entropi silang hanya dikira untuk Sumber. Model ini dilatih sepanjang fungsi kehilangan menggunakan turunan kecerunan stokastik kumpulan mini. Untuk setiap
Dalam bahagian percubaan, pengarang memilih semua projek Java sumber terbuka dalam gudang data PROMISE dan mengumpul nombor versi, nama kelas dan sama ada terdapat teg pepijat. Muat turun kod sumber daripada github berdasarkan nombor versi dan nama kelas. Akhirnya, data daripada 10 projek Java telah dikumpulkan. Struktur set data ditunjukkan dalam Rajah 6.
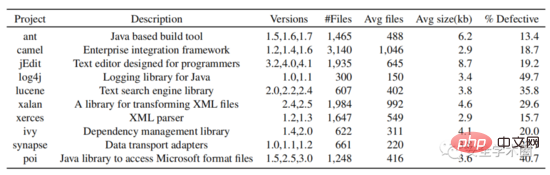
Gamb. 6 Struktur set data
Untuk ramalan kecacatan dalam projek, artikel memilih model garis dasar berikut untuk perbandingan:

Untuk ramalan kecacatan merentas projek, artikel memilih model garis dasar berikut untuk perbandingan:

Untuk meringkaskan, walaupun kertas itu ditulis dua tahun lalu, ideanya ialah masih agak baru , mengelakkan satu siri perwakilan perantaraan kod seperti AST, dan secara langsung menukar kod kepada ciri pengekstrakan imej. Tetapi saya masih keliru Adakah imej yang ditukar daripada kod benar-benar mengandungi maklumat semantik dan struktur kod sumber? Rasanya tak boleh dijelaskan sangat, haha. Kita perlu melakukan beberapa analisis eksperimen kemudian.
Atas ialah kandungan terperinci Menggunakan visualisasi perisian dan pemindahan pembelajaran dalam ramalan kecacatan perisian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI