
Rumah >Peranti teknologi >AI >Pembelajaran pemeringkatan Pareto: pembelajaran pemeringkatan berdasarkan keadilan sistem pengesyoran
Pembelajaran pemeringkatan Pareto: pembelajaran pemeringkatan berdasarkan keadilan sistem pengesyoran

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-13 13:22:031469semak imbas
Pengarang |. Wang Hao
Penilai |. Syarikat kecerdasan buatan yang terkenal seperti Twitter, Google, IBM dan Baidu semuanya telah menubuhkan pasukan etika kecerdasan buatan atau membangunkan produk etika kecerdasan buatan. Walau bagaimanapun, adalah dikesali bahawa penyelidikan etika kecerdasan buatan bermula lewat di China, dan masih terdapat jurang tertentu berbanding dengan negara luar.
 Pembelajaran pemeringkatan ialah teknologi pembelajaran mesin yang tercetus sekitar tahun 2010 dan telah digunakan secara meluas dalam bidang sistem pengesyoran dan perolehan maklumat. Dalam beberapa tahun kebelakangan ini, pembelajaran kedudukan telah menjadi penanda aras algoritma yang popular untuk penyelidikan etika kecerdasan buatan.
Pembelajaran pemeringkatan ialah teknologi pembelajaran mesin yang tercetus sekitar tahun 2010 dan telah digunakan secara meluas dalam bidang sistem pengesyoran dan perolehan maklumat. Dalam beberapa tahun kebelakangan ini, pembelajaran kedudukan telah menjadi penanda aras algoritma yang popular untuk penyelidikan etika kecerdasan buatan.
Artikel ini akan memperkenalkan makalah Pareto Pairwise Ranking for Fairness Enhancement of Recommender Systems diterbitkan pada 2022 di CISAT 2022 (Persidangan Antarabangsa mengenai Sains Maklumat Komputer dan Teknologi Aplikasi). Artikel ini menerangkan terutamanya cara menggabungkan pengedaran Pareto dan pembelajaran pemeringkatan untuk mencapai algoritma pengesyoran pembelajaran pemeringkatan yang adil.
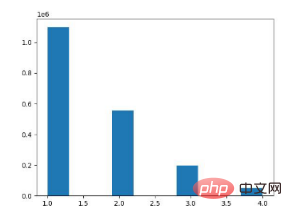
Rajah 1. MovieLens dataset taburan kebarangkalian rating tontonan filem
Kita boleh membuat kesimpulan berikut berdasarkan pemerhatian (Rajah 1) dan teori statistik (anggaran statistik taburan Zipf): Taburan kebarangkalian perbezaan dalam penilaian item yang berbeza oleh pengguna yang sama adalah berkadar dengan perbezaan dalam penilaian. Kami mengubah suai fungsi kehilangan penguraian matriks kebarangkalian dan mendapatkan formula fungsi kehilangan algoritma baharu yang kami cipta, Pareto Pairwise Ranking:
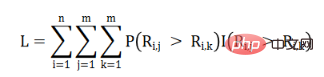
Meletakkan pemerhatian yang baru kami buat ke dalam formula fungsi kehilangan, kami mendapat formula fungsi kehilangan berikut:
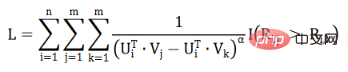
Kita ambil logaritma L dan dapatkan formula berikut:
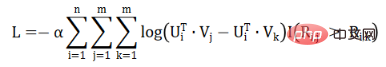
Kami menggunakan formula penurunan kecerunan stokastik untuk menyelesaikan logaritma fungsi kehilangan dan mendapatkan formula berikut:
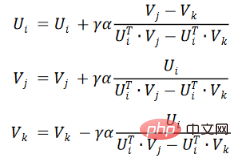
Aliran algoritma pembelajaran ranking Pareto adalah seperti berikut:

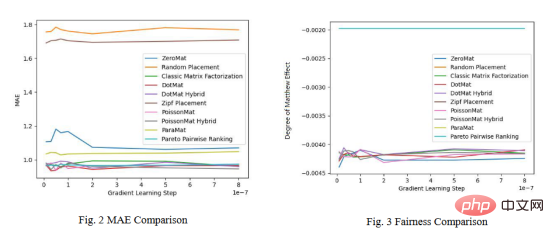
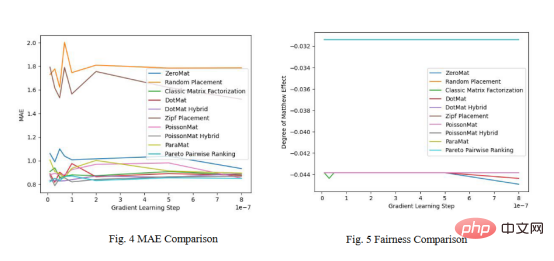
Rajah 4 dan Rajah 5 menunjukkan keputusan ujian pembelajaran pemeringkatan Pareto pada set data LDOS-CoMoDa . Algoritma pembelajaran kedudukan Pareto masih menunjukkan prestasi terbaik pada indeks kesaksamaan.
Algoritma pembelajaran ranking Pareto ialah algoritma sistem pengesyoran pembelajaran berasaskan keadilan yang jarang berlaku di China. Prinsip algoritma adalah mudah, mudah untuk dilaksanakan dan cepat dalam operasi. Penulis mengujinya pada komputer riba Lenovo dengan 16G RAM dan Intel Core i5, dan kelajuan pelaksanaannya sangat pantas. Penyelidikan etika kecerdasan buatan kini menjadi tumpuan penyelidikan di peringkat antarabangsa, dan saya berharap ia akan menarik perhatian yang mencukupi daripada semua orang.
Mengenai pengarang
Wang Hao, bekas ketua Makmal Kepintaran Buatan Funplus, mempunyai lebih daripada 100 pekerja di ThoughtWorks, Douban, Sina, NetEase dan syarikat lain selama 11 tahun pengalaman R&D dan pengurusan. Beliau mempunyai pengalaman teknikal yang kaya dalam bidang sistem pengesyoran, robot sembang, dan kawalan risiko dan anti-penipuan. Menerbitkan 30 kertas kerja dalam persidangan dan jurnal akademik antarabangsa, dan memenangi Anugerah Kertas Terbaik/Anugerah Laporan Kertas Terbaik sebanyak 3 kali. Pingat Emas Pertandingan Serantau ACM 2006. Lulus dari Universiti Utah di Amerika Syarikat dengan ijazah sarjana muda dan ijazah sarjana. Sambilan MBA dari Universiti Perniagaan dan Ekonomi Antarabangsa.
Atas ialah kandungan terperinci Pembelajaran pemeringkatan Pareto: pembelajaran pemeringkatan berdasarkan keadilan sistem pengesyoran. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI