
Rumah >Peranti teknologi >AI >Kajian semula teknologi model NLP pengaturcaraan automatik
Kajian semula teknologi model NLP pengaturcaraan automatik

- PHPzke hadapan
- 2023-04-13 09:52:051748semak imbas
Copilot, Codex dan AlphaCode: Keadaan semasa program komputer yang diprogramkan secara automatik
Dalam beberapa tahun kebelakangan ini, disebabkan peningkatan transformer dalam bidang pemprosesan bahasa semula jadi, kami telah melihat satu siri kedalaman yang mengejutkan penulisan kod Model pembelajaran. Keupayaan untuk menulis program komputer, sering dipanggil masalah sintesis program, telah dikaji sejak sekurang-kurangnya lewat 1960-an dan awal 1970-an.
Pada tahun 2010-an dan 2020-an, kejayaan model berasaskan perhatian dalam bidang lain sekali lagi merangsang penyelidikan mengenai sintesis prosedur, iaitu, pra-latihan pada ratusan gigabait teks dengan berjuta-juta atau Strategi untuk skala besar model saraf berasaskan perhatian (pengubah) dengan berbilion parameter.
Model pra-latihan menunjukkan keupayaan yang mengagumkan dalam meta-pembelajaran, terima kasih kepada mekanisme perhatian mereka, dan nampaknya mempunyai aplikasi praktikal dalam pembangunan tugasan teks - dengan menggunakan gesaan Hanya beberapa contoh (dipanggil "zero-shot atau pembelajaran beberapa pukulan" dalam literatur penyelidikan) disediakan dalam kandungan.
Sintesis program moden berdasarkan model NLP mendalam
Model NLP boleh dilatih lebih lanjut menggunakan set data khusus untuk memperhalusi prestasi untuk tugasan tertentu. Menulis kod ialah kes penggunaan yang sangat menarik untuk aplikasi ini.
Projek Copilot di GitHub, yang dinaikkan pangkat sebagai "Your AI Pair Programmer", menimbulkan kontroversi apabila ia dilancarkan pada 2021. Sebahagian besarnya, ini disebabkan oleh penggunaan semua kod GitHub awam dalam set data latihan. Mengikut arahan, asas kod ini termasuk projek dengan lesen copyleft, yang mungkin tidak membenarkan kod digunakan dalam projek seperti Copilot, melainkan Copilot itu sendiri adalah sumber terbuka.
Copilot ialah produk perhubungan antara organisasi OpenAI dan Microsoft Corporation, dan berdasarkan versi terlatih kod GPT-3. Versi yang ditunjukkan oleh OpenAI dan tersedia melalui APInya dipanggil Codex. Penerangan eksperimen formal menggunakan Copex diperincikan dalam kertas yang diterbitkan oleh Chen et al.
Pada awal tahun 2022, DeepMind tidak boleh ketinggalan dan membangunkan sistem NLP mendalam mereka sendiri yang disintesis mengikut prosedur: AlphaCode.
Pencabar Baharu: AlphaCode
Seperti Codex dan Copilot sebelum ini, AlphaCode ialah model NLP berskala besar yang direka dan dilatih untuk menulis kod. Seperti Copilot, AlphaCode tidak dibangunkan untuk menggunakan AlphaCode sebagai alat produktiviti untuk jurutera perisian, tetapi untuk mencabar prestasi pengaturcaraan peringkat manusia dalam tugas pengaturcaraan yang kompetitif.
Cabaran pengekodan persaingan yang digunakan untuk melatih dan menilai AlphaCode (yang membentuk set data CodeContests baharu) dalam julat kesukaran antara kesukaran set data sebelumnya dan kesukaran kejuruteraan perisian dunia sebenar.
Bagi mereka yang tidak biasa dengan tapak cabaran pengaturcaraan yang kompetitif, tugas ini agak seperti versi ringkas pembangunan dipacu ujian. Memandangkan beberapa huraian tekstual dan beberapa contoh, intipati cabaran ini adalah untuk menulis atur cara yang lulus satu set ujian—kebanyakannya disembunyikan daripada pengaturcara.
Sebaik-baiknya, ujian tersembunyi hendaklah menyeluruh dan lulus semua ujian bermakna masalah yang diberikan telah berjaya diselesaikan. Walau bagaimanapun, meliputi setiap kes tepi dengan ujian unit adalah masalah yang sukar. Sumbangan penting kepada bidang sintesis program sebenarnya ialah set data CodeContests itu sendiri, kerana pasukan DeepMind melakukan usaha yang ketara untuk menjana ujian tambahan melalui proses mutasi, dengan tujuan untuk mengurangkan kadar positif palsu (ujian lulus, tetapi masalahnya telah tidak diselesaikan ) dan kadar positif perlahan (ujian lulus, tetapi penyelesaiannya terlalu perlahan).
Prestasi AlphaCode dinilai berdasarkan kandungan daripada cabaran pengaturcaraan kompetitif di tapak web pertandingan CodeForces. Secara keseluruhannya, purata prestasi AlphaCode dalam kalangan pengaturcara (mungkin manusia) yang bersaing ialah "54.3% teratas".
Sila ambil perhatian bahawa metrik ini mungkin agak mengelirukan kerana ia sebenarnya menyamai prestasi 45.7%. Hebatnya, sistem AlphaCode mampu menulis sebarang algoritma yang melepasi semua ujian tersembunyi. Walau bagaimanapun, amaran: AlphaCode menggunakan strategi yang sangat berbeza daripada yang dilakukan manusia untuk menyelesaikan masalah pengaturcaraan.
Walaupun pesaing manusia mungkin menulis algoritma untuk menyelesaikan kebanyakan rutin - menggabungkan cerapan daripada menjalankan versi penyelesaian yang lebih awal dan terus memperbaikinya sehingga ia melepasi semua ujian, namun, AlphaCode menggunakan kaedah yang lebih luas hasilkan berbilang sampel untuk setiap soalan dan kemudian pilih 10 sampel untuk diserahkan.
Sumbangan besar kepada prestasi AlphaCode pada set data CodeContests ialah hasil penapisan dan pengelompokan pasca generasi: selepas ia menghasilkan kira-kira 1,000,000 penyelesaian calon, ia mula menapis calon untuk mengalih keluar masalah dalam perihalan masalah. Calon yang gagal dalam ujian sampel, dengan itu menghapuskan kira-kira 99% kumpulan calon.
Penulis menyebut bahawa kira-kira 10% daripada masalah tidak mempunyai penyelesaian calon yang melepasi semua ujian contoh pada peringkat ini.
Calon yang tinggal kemudian ditapis melalui pengelompokan kepada 10 atau kurang penyerahan. Ringkasnya, mereka melatih model lain untuk menjana input ujian tambahan berdasarkan penerangan masalah (tetapi ambil perhatian bahawa mereka tidak mempunyai output yang sah untuk ujian ini).
Penyelesaian calon yang tinggal (bilangan selepas penapisan mungkin kurang daripada 1000), dikelompokkan berdasarkan outputnya pada input ujian yang dijana. Seorang calon daripada setiap kluster dipilih untuk penyerahan mengikut tertib daripada terbesar kepada terkecil. Jika terdapat kurang daripada 10 kluster, kluster diambil beberapa kali.
Walaupun langkah penapisan/pengkelompokan adalah unik dan AlphaCode diperhalusi pada set data CodeContests baharu, ia pada mulanya dilatih dengan cara yang sama seperti Codex atau Copilot. AlphaCode pertama kali dilatih pada set data kod yang besar dan tersedia untuk umum daripada GitHub (didapatkan pada 14 Julai 2021). Mereka melatih 5 varian, dan bilangan parameter meningkat daripada 284 juta kepada 41 bilion.
Dalam semangat yang sama seperti siri AlphaGo atau robot AlphaStar yang memainkan permainan StarCraft II, AlphaCode juga merupakan projek penyelidikan yang bertujuan untuk membangunkan sistem yang mendekati keupayaan manusia dalam bidang tugas khusus, dan dibangunkan dalam proses sintesis prosedur Halangan kemasukan untuk program utiliti luar kotak adalah lebih rendah.
Dari perspektif membangunkan alat praktikal untuk menyelesaikan masalah, wakil robot dalam kawasan ini adalah alat Codex dan Copilot berdasarkan GPT-3. Codex ialah varian OpenAI GPT-3, dilatih pada korpus kod yang tersedia untuk umum. Berdasarkan set data HumanEval yang dikeluarkan bersama kertas kerja, OpenAI melaporkan bahawa Codex mampu menyelesaikan lebih daripada 70% masalah dengan menjana 100 sampel dalam tugasan dalam format "docstring to code".
Seterusnya, kami akan meneroka teknik pengaturcaraan segera ini yang menjana kod secara automatik melalui penggunaan Codex. Kami akan menggunakan model yang diberikan di bawah secara serentak untuk membangunkan Permainan Kehidupan John Conway.
GitHub Copilot menggunakan penyiapan kod automatik Borang pembungkusan semasa adalah lanjutan daripada persekitaran pembangunan bersepadu seperti Visual Studio, VSCode, Neovim dan JetBrains. Menurut penerangan pada halaman web Copilot, Copilot telah berjaya menulis semula set fungsi Python yang telah diuji dengan baik mengikut penerangan yang diberikan, 57% daripadanya adalah serupa dengan set data HumanEval.
Kami akan melihat beberapa kes penggunaan dunia sebenar untuk Copilot, seperti menulis ujian secara automatik menggunakan versi beta khusus sambungan Copilot untuk VSCode.
Pengaturcaraan Segera: Menulis "Game of Life" Conway dengan Codex
Dalam bahagian ini, kami akan memperkenalkan penulisan simulator automaton selular berdasarkan tugasan "Game of Life" John Conway. Dengan beberapa pengubahsuaian dan tiada pengekodan keras peraturan, program kami seharusnya dapat mensimulasikan mana-mana set peraturan automaton selular seperti hidup.
Daripada menjana 100 contoh dan memilih yang terbaik (sama ada secara manual atau dengan menjalankan ujian) kami akan mengambil pendekatan interaktif. Apabila Codex memberikan penyelesaian yang lemah, kami membuat pelarasan untuk cuba membimbing jawapan yang lebih baik. Sudah tentu, jika benar-benar perlu, kami boleh terus mengubah suai kod untuk mendapatkan contoh yang berfungsi sekiranya Codex gagal sepenuhnya.
Tulis CA (Cellular Automata) yang realistik Ia adalah model dinamik grid di mana masa, ruang dan keadaan semuanya diskret, dan interaksi spatial dan kausalitas temporal adalah setempat , mempunyai keupayaan untuk mensimulasikan spatiotemporal proses evolusi sistem kompleks) Langkah pertama simulator adalah untuk mencadangkan fungsi untuk mengira jiran. Kami menulis gesaan docstring berikut dan memberikannya kepada code-davinci-001, yang merupakan model Codex terbesar dalam perpustakaan API OpenAI:
# PROMPT<br>import numpy as np<br>def compute_neighborhood(grid: np.array) -> np.array:<br>"""<br>Compute the sum of cell states in the Moore neighborhood<br>for each cell in the input grid.<br>A Moore neighborhood includes 8 cells,<br>diagonally and orthogonally adjacent to, but not including, the center cell.<br>The cells denoted by '1' correspond to the Moore neighborhood for cell a:<br>1 1 1<br>1 a 1<br>1 1 1<br>If cell 'a' is on the edge of the grid,<br>the Moore neighborhood wraps around to the cells on the opposite edge,<br>i.e. grid is on a toroid.<br><br>args:<br>grid, a numpy array with binary values 0 or 1. grid contains the current cell state values<br>Returns:<br><br>neighorhood_grid, a numpy array with integer values from 0 to 8.<br>For each cell (element in grid) in grid, neighborhood_grid should<br>contain the sum of states in that cell's Moore neighborhood<br>"""
Dalam kod di atas, tambahkan baris ulasan "# PROMPT" dan "#GENERATED" untuk menjadikannya lebih jelas di mana gesaan itu berakhir.
Adakah anda telah menganalisis dengan teliti gesaan docstring yang agak komprehensif di atas? Bagaimanakah Codex berfungsi? Sebenarnya, percubaan pertama Codex kelihatan seperti ini:
# GENERATED<br># TODO: implement this function<br>pass
Ini mungkin tidak sesuai untuk percubaan kecil kami. Walaupun selepas menala hiperparameter nilai P untuk mencapai pensampelan kernel yang lebih longgar (dan diharapkan kepelbagaian yang lebih baik), Codex nampaknya masih tidak mempunyai jawapan kepada soalan di atas.
Nasib baik, kami hanya boleh menambah sedikit perkara seperti berikut pada gesaan docstring dan Codex akan menghasilkan output yang lebih menjanjikan.
# PROMPT (appended to previous prompt)<br><br>this function is completed and does not include any TODOs<br>"""<br><br># GENERATED<br><br># get the dimensions of the grid<br>n_rows, n_cols = grid.shape<br><br># initialize the output array<br>neighborhood_grid = np.zeros((n_rows, n_cols), dtype=int)<br><br># loop over the grid<br>for i in range(n_rows):<br>for j in range(n_cols):<br><br># get the current cell value<br>cell_val = grid[i, j]<br><br># get the Moore neighborhood of the current cell<br># using the get_neighborhood function<br>neighborhood = get_neighborhood(grid, i, j)<br><br># sum the cell values in the neighborhood<br>neighborhood_sum = np.sum(neighborhood)<br><br># store the sum in the neighborhood grid<br>neighborhood_grid[i, j] = neighborhood_sum<br><br>return neighborhood_grid
Sudah tentu, ini bukan penyelesaian yang bagus lagi, kerana ia memperkenalkan cell_val pembolehubah yang tidak digunakan dan mewakilkan sebahagian besar kerjanya kepada fungsi lain yang baru ditambah, get_neghborhood. Tetapi secara keseluruhan, ini kelihatan seperti permulaan yang boleh dilaksanakan.
Seterusnya, kami menulis docstring ringkas untuk fungsi get_neighborhood yang dinyatakan di atas:
def get_neighborhood(grid: np.array, i: int, j: int) -> np.array:<br>"""<br>get_neighborhood is used by compute_neighborhood <br>to return the 3x3 Moore neighborhood for the cell <br>located at coordinates i,j If i,j coordinates are <br>on the edge of the grid (i.e. i or j equal 0, or i == <br>grid.shape[0]-1 or j == grid.shape[1]), the Moore<br>Neighborhood should wrap around to include cells on the<br>opposite edge. In other words the grid can be considered to <br>be the surface of a toroid, like 'Pac-Man'<br><br>args:<br>grid, np.array, this is the current state of<br>the cellular automata grid<br>i, int, this coordinate corresponds to the row<br>j, int, coordinate corresponding to column<br><br>returns:<br>moore_neighborhood - np.array, should always have<br>dimensions 3x3 and<br>contain the Moore neighborhood for the cell at i,j <br>in grid.Because the center cell is not part of the<br>neighborhood, moore_neighborhood[1,1] should always <br>be 0<br>"""<br><br># GENERATED<br><br># get the dimensions of the grid<br>n_rows, n_cols = grid.shape<br><br># initialize the output array<br>moore_neighborhood = np.zeros((3, 3), dtype=int)<br><br># get the coordinates of the Moore neighborhood<br># using the get_neighborhood_coordinates function<br>neighborhood_coords = <br>get_neighborhood_coordinates(i, j, n_rows, n_cols)<br><br># loop over the coordinates<br>for coord in neighborhood_coords:<br># get the cell value at the coordinate<br>cell_val = grid[coord[0], coord[1]]<br><br># store the cell value in the output array<br>moore_neighborhood[coord[0], coord[1]] = cell_val<br><br>return moore_neighborhood
Output program di atas juga kelihatan boleh dilaksanakan tetapi selepas diperiksa, ia sebenarnya Mengandungi ralat penting.
Dalam gelung di atas koordinat jiran, ia memberikan nilai kepada kejiranan Moore menggunakan koordinat yang sama yang mengambil nilai daripada grid.
Kami tidak menemui cara yang jelas untuk menggesa Codex untuk mengelakkan ralat oleh itu, kami terpaksa mengubah suai kod secara manual:
# FIXED loop over the coordinates <br>for index, coord in enumerate(neighborhood_coords): <br># get the cell value at the coordinate<br>cell_val = grid[coord[0], coord[1]] <br><br># FIXED store the cell value in the output array<br>moore_neighborhood[index // 3, index % 3] = cell_val<br><br>return moore_neighborhood
Selain itu, satu lagi fungsi get_neighborhood_coordinates telah diperkenalkan dalam sebelumnya. kod untuk mengendalikan perbandingan Bahagian "susah".
Seterusnya, kita perlu menulis gesaan untuk fungsi get_neighborhood_coordinates.
# PROMPT <br>def get_neighborhood_coordinates(<br>i: int, j: int, n_rows: int, n_cols: int) -> list:<br>"""<br>get_neighborhood_coordinates is used by get_neighborhood <br>to return the coordinates of the 3x3 Moore neighborhood for<br>the cell located at coordinates i,j If i,j coordinates are on<br>the edge of the grid (i.e. i or j equal 0, or i ==<br>grid.shape[0]-1 or j == grid.shape[1]), the Moore<br>Neighborhood should wrap around to include cells on the<br>opposite edge. In other words the grid can be considered to <br>be the surface of a toroid, like 'Pac-Man'<br><br>args:<br>i, int, this coordinate corresponds to the row<br>j, int, coordinate corresponding to column<br>n_rows, int, number of rows in the grid<br>n_cols, int, number of columns in the grid<br><br>returns:<br>neighborhood_coords - list of tuples, <br>each tuple contains the coordinates<br>of a cell in the Moore neighborhood<br>"""<br><br># GENERATED<br><br># initialize the output list<br>neighborhood_coords = []<br><br># get the coordinates of the Moore neighborhood<br># using the get_neighborhood_coordinates function<br>for row in range(i-1, i+2):<br>for col in range(j-1, j+2):<br># skip the center cell<br>if row == i and col == j:<br>continue<br><br># check if the cell is on the edge of the grid<br># if so, wrap around to the opposite edge<br>if row row = n_rows - 1<br>elif row == n_rows:<br>row = 0<br><br>if col col = n_cols - 1<br>elif col == n_cols:<br>col = 0<br><br># store the cell coordinates<br>neighborhood_coords.append((row, col))<br><br>return neighborhood_coords
这比我们预期的函数式编程深度要深一点(compute_neighborhood调用get_neighborhood,反过来get_neighborhood又调用get_neighborhood_coordinates),但看起来我们终于有了一组函数,可以返回一个邻居和的网格。
还剩下update函数,它对应的docstring提示如下所示:
# PROMPT<br><br>def update_grid(grid: np.array, rules: list) -> np.array:<br>"""<br>update input arg grid according the the Life-like rules<br>contained in input arg rules. rules is a list of lists, <br>with the first element containing a list of 'birth'<br>conditions (cells go from 0 -> 1) and the second element<br>containing a list of 'survival' conditions (cells are<br>unchanged).<br>Cells which have a neighborhood sum that is not in the<br>'birth' (B) or 'survival' (S) rules go to 0. <br><br>This functions uses function compute_neighborhood to compute <br>the neighborhood value for each cell in grid.<br><br>args:<br>grid, np.array. grid contains the cell values (0 or 1)<br> rules, list of lists. rules contains the B/S rules <br> for Life-like cellular automatafor example, to<br> simulate Conway's Life CA, `rules = [[3], [2,3]]`,<br> i.e. B3/S23 Life Without Death has rules<br> B3/S012345678, so `rules = [[3],<br> [0,1,2,3,4,5,6,7,8]]`<br><br>update_grid should raise an Exception if rules contains <br>values greater than 8 (maximum number of live cells in a<br>Moore neighborhood) or less than 0. <br>"""<br><br># GENERATED<br><br># get the dimensions of the grid<br>n_rows, n_cols = grid.shape<br><br># get the neighborhood grid<br>neighborhood_grid = compute_neighborhood(grid)<br><br># loop over the grid<br>for i in range(n_rows):<br>for j in range(n_cols):<br># get the current cell value<br>cell_val = grid[i, j]<br><br># get the neighborhood value for the current cell<br>neighborhood_val = neighborhood_grid[i, j]<br><br># check if the cell is alive<br>if cell_val == 1:<br># check if the cell should die<br>if neighborhood_val not in rules[1]:<br>grid[i, j] = 0<br>else:<br># check if the cell should be born<br>if neighborhood_val in rules[0]:<br>grid[i, j] = 1<br><br>return grid
这看起来是解决上面问题的一种非常合理的方法;尽管我们确实明确建议,如果邻居网格包含错误的值并且在生成的输出中找不到,就会引发异常。
只需进行一些修复:在函数get_neighborhood中进行手动干预,并且尝试给出一些提示,我们就可以成功地设计出一个完全可行的类似生命的细胞自动机模拟器。
上面的代码不是一个特别快的实现方案,但它的质量与程序员在开始使用一种新语言时可能做出的那种“Hello World”尝试相似。值得注意的是,在训练数据集中包含了许多示例,供研究者参考。
在康威的《生命游戏》中,我们可以想象这段程序在微型滑翔机的发展过程中取得的成功。

虽然我们确实通过一组函数完成了CA模拟器的编写,但这种方法对于日常软件工程来说并不是非常有用或现实的开发方式。但另一方面,这并不能阻止像SourceAI这样的初创公司(本质上是OpenAI Codex API的包装商)将其服务宣传为“给每个人创造有价值的定制软件的机会”。
“我们构建了一个独立的系统,可以开发出世界上最熟练的工程师级别的软件。”不过,与Codex交互的确是学习或实践编程的一种潜在有用的方式,尤其是针对CodeSignal、CodeForces或HackerRank等网站的编程问题方面。
接下来,我们将尝试评估Codex/Copilot,以获得自动编写测试和docstring的更现实的使用情形。
任务2:编写测试
对于本例来说,我们选择使用VSCode开发工具的GitHub Copilot扩展来编写测试。
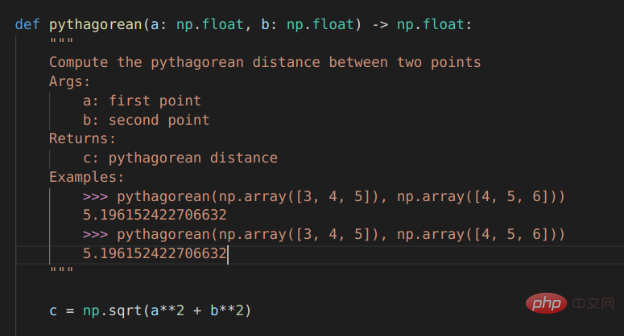
# PROMPT (in VSCode)<br>import numpy as np<br>def pythagorean(a: np.float, b: np.float) -> np.float:<br>"""<br>Use the Pythagorean theorem to comput the hypotenuse for<br>a triangle with side lengths a and b<br><br>args:<br>a, np.float, side of the triangle<br>b, np.float, the other side of the triangle<br><br>returns:<br>c, np.float, the length of the hypotenuse<br>"""<br>c = np.sqrt(a**2 + b**2)<br>return c<br><br>def test_pythagorean():<br><br># GENERATED (Copilot autocomplete)<br>"""<br>Test the pythagorean function<br>"""<br>a = np.array([3, 4, 5])<br>b = np.array([4, 5, 6])<br>c = pythagorean(a, b)<br><br>assert np.allclose(c, np.sqrt(a**2 + b**2))
虽然毕达哥拉斯定理函数可能过于简单,但Copilot建议进行一次合理的测试。如果您运行它,它就会通过。你会注意到,自动完成建议能够正确地获得测试的结构和数字内容。
如果我们想使用自己喜欢的框架以更系统的方式编写测试,该怎么办?不用太担心,因为我们已经使用numpy库和自动微分技术编写了大量的低级学习模型,供给测试者使用。因此,虽然接下来的这个示例不是100%真实地来自真实世界,但效果还是比较贴近真实情况的。
在本例中,我们将使用autograd和numpy以及unittest中的TestCase类设置一个简单的多层感知器前向传递、损失函数和梯度函数进行测试。
#PROMPT<br>import unittest<br>from autograd import numpy as np<br>from autograd import grad<br><br>def forward_mlp(input_x: np.array, <br>weights: list, biases: list) -> np.array:<br>"""<br>compute the forward pass of a multilayer perceptron. <br>The number of layers is equal to the length of the list of<br>weights, which must be the same as the list of biases,<br>biases. <br><br>args:<br>input_x, np.array, input data<br>weights, list of np.arrays, a list of np.array matrices,<br> representing the weights<br>biases: list of np.arrays, a list of biases for each<br> layer<br><br>returns:<br>result, np.array, the output of the network<br>"""<br><br>assert len(weights) == len(biases)<br><br>for layer_index in range(len(weights) - 1):<br>input_x = np.tanh(np.matmul(input_x,<br>weights[layer_index]) + biases[layer_index])<br><br>output = np.matmul(input_x, weights[-1]) + biases[-1]<br>return output<br>def get_loss(input_x: np.array, weights: list, <br>biases: list, target: np.array) -> np.float:<br>"""<br>compute the mean squared error loss for an mlp with weights<br>and biases, with respect to the input data input_x and the<br>target array target.<br><br>args:<br>input_x, np.array, input data<br>weights, list of np.arrays, a list of np.array matrices,<br>representing the weights<br>biases: list of np.arrays, a list of biases for each<br>layer<br>target: np.array, the target values<br><br>returns:<br>loss, np.float, the loss<br>"""<br><br>output = forward_mlp(input_x, weights, biases)<br><br>return np.mean((output - target)**2)<br><br>get_loss_grad = grad(get_loss, argnum=(1,2))<br><br><br>class TestMLP(unittest.TestCase):<br>"""<br>tests for MLP, get_loss, and get_grad_loss<br>"""<br># GENERATED (chosen from Copilot suggestions)<br>def setUp(self):<br>pass<br><br>def test_forward_mlp(self):<br>"""<br>test forward_mlp<br>"""<br><br>input_x = np.array([[1, 2, 3], [4, 5, 6]])<br>weights = [np.array([[1, 2], [3, 4]]), <br>np.array([[5, 6], [7, 8]]), <br>np.array([[9, 10], [11, 12]])]<br>biases = [np.array([[1, 2]]), np.array([[3, 4]]),<br>np.array([[5, 6]])]<br><br>output = forward_mlp(input_x, weights, biases)<br>self.assertTrue(np.allclose(output, <br>np.array([[-0.9, -0.9], [-0.9, -0.9]])))<br><br>def test_get_loss(self):<br>"""<br>test get_loss<br>"""<br>input_x = np.array([[1, 2, 3], [4, 5, 6]])<br>weights = [np.array([[1, 2], [3, 4]]), <br>np.array([[5, 6], [7, 8]]), <br>np.array([[9, 10], [11, 12]])]<br>biases = [np.array([[1, 2]]), np.array([[3, 4]]),<br>np.array([[5, 6]])]<br>target = np.array([[1, 1], [1, 1]])<br><br>loss = get_loss(input_x, weights, biases, target)<br><br>self.assertTrue(np.allclose(loss, 0.5))<br><br>def test_get_loss_grad(self):<br>"""<br>test get_loss_grad<br>"""<br><br>input_x = np.array([[1, 2, 3], [4, 5, 6]])<br>weights = [np.array([[1, 2], [3, 4]]), <br>np.array([[5, 6], [7, 8]]), <br>np.array([[9, 10], [11, 12]])]<br>biases = [np.array([[1, 2]]), np.array([[3, 4]]), <br>np.array([[5, 6]])]<br>target = np.array([[1, 1], [1, 1]])<br><br>loss_grad = get_loss_grad(<br>input_x, weights, biases, target)<br><br>self.assertTrue(<br>np.allclose(loss_grad[0], <br>np.array([[-0.9, -0.9], [-0.9, -0.9]])))<br>self.assertTrue(<br>np.allclose(loss_grad[1], <br>np.array([[-0.9, -0.9], [-0.9, -0.9]])))<br>self.assertTrue(<br>np.allclose(loss_grad[2],<br>np.array([[-0.9, -0.9], [-0.9, -0.9]])))<br><br># END GENERATED (the final two lines are part of the prompt)<br>if __name__ == "__main__":<br>unittest.main(verbosity=1)
Copilot的建议虽然并不完美,但确实为测试类提供了合理的思路。不过,如果您尝试原封不动地运行代码的话,则不会执行任何测试,更不用说通过测试了。
输入数据和第一个权重矩阵之间存在维度不匹配,数据类型也是错误的(所有数组都是整数数据类型),而且无法使用Autograd梯度函数。
当然,上面这些问题并不是很难解决,如果用3x2矩阵替换权重矩阵列表中的第一个条目,那么前向传播应该可以运行。要使得梯度计算测试顺利进行,或者需要在np.array定义的数字上添加小数点,或者显式定义数组数据类型。
有了这些更改后,测试即可成功执行并失败,但预期值在数字表现方面还不正确。
任务3:自动文档字符串
Copilot有很大潜力的一项任务是自动编写文档,特别是为已经编写的函数填写docstring内容。这方面几乎是比较实用了。
对于毕达哥拉斯定理的示例程序,Copilot运行结果已经非常接近,但它将问题描述为查找两点a和b之间的距离,而不是查找边长c到边长a和边长b的距离。不出所料,随同Copilot一同发行的docstring中的示例也与函数的实际内容不匹配:返回的是一个标量,而不是c的值数组。
Copilot对前向MLP函数的docstrings的建议也很接近,但并不完全正确。
Copilot支持的自动Docstring建议
机器能取代我的工作吗?
对于软件工程师来说,程序合成方面的每一项新进展都可能引发一次经济恐慌。
Lagipun, jika program komputer boleh memprogram komputer seperti pengaturcara, bukankah itu bermakna mesin harus "mengambil kerja kita"? Adakah ini akan berlaku dalam masa terdekat?
Pada zahirnya, jawapannya nampaknya "belum lagi"; walau bagaimanapun, itu tidak bermakna sifat kejuruteraan perisian berkemungkinan kekal sama apabila alat ini menjadi lebih matang. Pada masa hadapan, menggunakan alat autolengkap yang canggih untuk penaakulan yang berjaya mungkin sama pentingnya dengan menggunakan alat pemformatan kod.
Copilot kini dalam versi beta dengan bilangan pilihan terhad tentang cara menggunakannya. Begitu juga, Codex juga mempunyai API yang tersedia dalam beta melalui OpenAI. Syarat penggunaan program perintis dan pertimbangan privasi mengehadkan potensi kes penggunaan teknologi tersebut.
Mengikut dasar privasi semasa, sebarang input kod ke dalam sistem ini boleh digunakan untuk memperhalusi model dan boleh disemak oleh kakitangan GitHub/Microsoft atau OpenAI. Ini menolak kemungkinan menggunakan Codex atau Copilot dalam projek sensitif.
Copilot memang menambah banyak utiliti pada model Codex yang berasaskannya. Anda boleh menulis rangka atau garis besar untuk kod yang anda inginkan (seperti menulis contoh untuk ujian rangka kerja unittest) dan gerakkan kursor ke tengah garis besar untuk mendapatkan cadangan autolengkap OK yang wajar.
Pada masa ini Copilot tidak mungkin mencadangkan kod lengkap yang betul untuk sebarang masalah yang lebih kompleks daripada amalan pengekodan mudah, bagaimanapun, ia biasanya boleh membuat garis besar yang munasabah dan menyimpan beberapa penaipan manual.
Perlu diingatkan juga bahawa Copilot berjalan di awan. Ini bermakna ia tidak berfungsi di luar talian dan cadangan autolengkap agak perlahan. Pada ketika ini, anda boleh menyemak cadangan dengan menekan Alt+], tetapi kadangkala terdapat hanya beberapa cadangan untuk dipilih atau malah hanya satu cadangan untuk dipilih.
Apabila Copilot berfungsi dengan baik - ia sebenarnya cukup bagus untuk menjadi sedikit berbahaya. Ujian yang dicadangkan dalam contoh ujian unit dan docstring yang dicadangkan untuk fungsi Pythagoras kelihatan betul pada pandangan pertama dan mungkin akan lulus penelitian jurutera perisian yang letih. Tetapi apabila ia mengandungi kesilapan misteri, ini hanya membawa kepada kesakitan kemudian!
Ringkasnya, walaupun Copilot/Codex lebih seperti mainan atau alat pembelajaran dalam keadaan semasanya, sungguh menakjubkan bahawa ia benar-benar berfungsi. Jika anda bertemu dengan beruang waltzing, saya tidak fikir apa yang akan menarik perhatian anda ialah sejauh mana ia menari. Begitu juga, jika anda menjumpai alat penyiapan kod pintar, perkara yang mengagumkan anda tidak sepatutnya seberapa sempurna kod yang ditulisnya.
Ringkasnya, dengan perkembangan lanjut teknologi model NLP pengaturcaraan automatik, dan sejumlah besar pelarasan yang dibuat oleh pengaturcara manusia untuk menggunakan alat penyiapan automatik NLP, kemungkinan besar akan terdapat aplikasi pembunuh utama program model sintesis dalam masa terdekat.
Pengenalan penterjemah
Zhu Xianzhong, editor komuniti 51CTO, blogger pakar 51CTO, pensyarah, guru komputer di sebuah universiti di Weifang dan seorang veteran dalam industri pengaturcaraan bebas. Pada hari-hari awal, beliau memberi tumpuan kepada pelbagai teknologi Microsoft (menghimpun tiga buku teknikal yang berkaitan dengan ASP.NET AJX dan Cocos 2d-X Dalam sepuluh tahun yang lalu, beliau telah menumpukan dirinya kepada dunia sumber terbuka (biasa dengan popular penuh-). susun teknologi pembangunan web) dan pelajari tentang OneNet/AliOS+Arduino /ESP32/Raspberry Pi dan teknologi pembangunan IoT lain serta Scala+Hadoop+Spark+Flink dan teknologi pembangunan data besar yang lain.
Tajuk asal: Model NLP untuk Menulis Kod: Sintesis Program, Pengarang: Kevin Vu
Atas ialah kandungan terperinci Kajian semula teknologi model NLP pengaturcaraan automatik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI