
Rumah >Peranti teknologi >AI >Pembelajaran mesin adalah rahmat dari syurga! Saintis data dan master Kaggle mengeluarkan 'Panduan mengelakkan perangkap ML'
Pembelajaran mesin adalah rahmat dari syurga! Saintis data dan master Kaggle mengeluarkan 'Panduan mengelakkan perangkap ML'

- PHPzke hadapan
- 2023-04-12 20:40:011331semak imbas
Sains data dan pembelajaran mesin menjadi semakin popular.
Bilangan orang yang memasuki bidang ini semakin bertambah setiap hari.
Ini bermakna ramai saintis data tidak mempunyai pengalaman yang luas semasa membina model pembelajaran mesin pertama mereka, jadi kesilapan mudah berlaku.
Berikut ialah beberapa kesilapan pemula yang paling biasa dalam penyelesaian pembelajaran mesin.

Tidak menggunakan normalisasi data jika perlu
Betul Untuk pemula, ia mungkin kelihatan seperti tidak perlu berfikir untuk meletakkan ciri ke dalam model dan menunggu ia memberikan ramalan.
Tetapi dalam beberapa kes, hasilnya mungkin mengecewakan kerana anda terlepas langkah yang sangat penting.

Jenis model tertentu memerlukan penormalan data, termasuk regresi linear, rangkaian saraf klasik, dsb. Jenis model ini menggunakan nilai ciri yang didarab dengan pemberat terlatih. Jika ciri tidak dinormalisasi, ia boleh berlaku bahawa julat nilai yang mungkin untuk satu ciri adalah sangat berbeza daripada julat nilai yang mungkin untuk ciri lain.
Anggapkan bahawa nilai satu ciri berada dalam julat [0, 0.001] dan nilai ciri lain berada dalam julat [100000, 200000]. Untuk model di mana dua ciri adalah sama penting, berat ciri pertama akan menjadi 100'000'000 kali berat ciri kedua. Berat yang besar boleh menyebabkan masalah serius untuk model. Sebagai contoh, terdapat beberapa kelebihan.
Tambahan pula, menganggarkan kepentingan pelbagai ciri boleh menjadi sangat sukar, kerana berat yang besar mungkin bermakna ciri itu penting, atau mungkin bermakna ia mempunyai nilai yang kecil.
Dan selepas penormalan, semua ciri berada dalam julat nilai yang sama, biasanya [0, 1] atau [-1, 1]. Dalam kes ini, pemberat akan berada dalam julat yang sama dan akan sepadan dengan kepentingan sebenar setiap ciri.
Secara keseluruhan, menggunakan penormalan data di mana diperlukan akan menghasilkan ramalan yang lebih baik dan tepat.
Fikirkan bahawa lebih banyak ciri, lebih baik
Sesetengah orang mungkin berfikir bahawa lebih banyak ciri, lebih baik, supaya model akan memilih dan menggunakan ciri terbaik secara automatik .
Dalam amalan, ini tidak berlaku. Dalam kebanyakan kes, model dengan ciri yang direka dan dipilih dengan teliti akan mengungguli model yang serupa dengan ciri 10x lebih banyak dengan ketara.
Semakin banyak ciri yang dimiliki oleh model, semakin besar risiko pemasangan berlebihan. Walaupun dalam data rawak sepenuhnya, model ini dapat mencari beberapa isyarat—kadang-kadang lebih lemah, kadang-kadang lebih kuat.

Sudah tentu, tiada isyarat sebenar dalam bunyi rawak. Walau bagaimanapun, jika kami mempunyai lajur hingar yang mencukupi, model mungkin menggunakan sebahagian daripadanya berdasarkan isyarat ralat yang dikesan. Apabila ini berlaku, kualiti ramalan model berkurangan kerana sebahagiannya akan berdasarkan hingar rawak.
Memang terdapat pelbagai teknik untuk pemilihan ciri yang boleh membantu dalam situasi ini. Tetapi artikel ini tidak membincangkannya.
Ingat, yang paling penting - anda seharusnya dapat menerangkan setiap ciri yang anda miliki dan memahami sebab ciri ini akan membantu model anda.
Gunakan model berasaskan pokok apabila ekstrapolasi diperlukan
Sebab utama model pokok popular bukan sahaja kerana kekuatannya, tetapi juga kerana ia digunakan dengan baik .

Namun, ia tidak selalu dicuba dan benar. Dalam sesetengah kes, menggunakan model berasaskan pokok mungkin merupakan satu kesilapan.
Model pokok tidak mempunyai keupayaan inferens. Model ini tidak pernah memberikan nilai ramalan lebih besar daripada nilai maksimum yang dilihat dalam data latihan. Mereka juga tidak pernah mengeluarkan ramalan yang lebih kecil daripada minimum dalam latihan.
Tetapi dalam sesetengah tugasan, keupayaan untuk mengekstrapolasi mungkin memainkan peranan utama. Sebagai contoh, jika model ini digunakan untuk meramalkan harga saham, ada kemungkinan harga saham pada masa hadapan akan lebih tinggi daripada sebelumnya. Jadi dalam kes ini, model berasaskan pokok tidak lagi sesuai kerana ramalan mereka akan dihadkan kepada tahap yang hampir dengan harga tertinggi sepanjang masa.
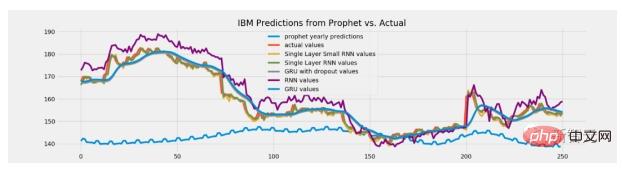

Jadi bagaimana untuk menyelesaikan masalah ini?
Malah, semua jalan menghala ke Rom!
Satu pilihan ialah meramalkan perubahan atau perbezaan dan bukannya meramalkan nilai secara langsung.
Penyelesaian lain ialah menggunakan jenis model yang berbeza untuk tugasan tersebut, seperti regresi linear atau rangkaian saraf yang mampu diekstrapolasi.
Penormalan berlebihan
Semua orang mesti biasa dengan kepentingan penormalan data. Walau bagaimanapun, tugas yang berbeza memerlukan kaedah normalisasi yang berbeza Jika anda menekan jenis yang salah, anda akan kehilangan lebih banyak daripada yang anda perolehi!

Model berasaskan pokok tidak memerlukan penormalan data kerana nilai mentah ciri tidak digunakan sebagai pengganda, dan Outlier juga tidak menjejaskan mereka.
Rangkaian saraf juga mungkin tidak memerlukan penormalan - contohnya, jika rangkaian sudah mengandungi lapisan yang mengendalikan penormalan secara dalaman (seperti BatchNormalization perpustakaan Keras).

Dalam sesetengah kes, regresi linear mungkin tidak memerlukan penormalan data sama ada. Ini bermakna semua ciri berada dalam julat nilai yang sama dan mempunyai makna yang sama. Sebagai contoh, jika model digunakan pada data siri masa dan semua ciri adalah nilai sejarah parameter yang sama.
Dalam praktiknya, penggunaan normalisasi data yang tidak diingini tidak semestinya membahayakan model. Selalunya, keputusan dalam kes ini akan sangat serupa dengan penormalan yang dilangkau. Walau bagaimanapun, melakukan transformasi data tambahan yang tidak perlu merumitkan penyelesaian dan meningkatkan risiko memperkenalkan beberapa ralat.
Jadi, sama ada mahu menggunakannya atau tidak, amalan akan memberitahu anda perkara sebenar!
Pelanggaran Data
Pelanggaran data lebih mudah daripada yang kita fikirkan.
Lihat coretan kod berikut:

Malah, " sum_feature ” dan “diff_feature” adalah kedua-dua ciri yang salah.
Mereka "membocorkan" maklumat kerana selepas berpecah kepada set kereta api/ujian, bahagian dengan data latihan akan mengandungi beberapa maklumat daripada baris ujian. Walaupun ini akan menghasilkan hasil pengesahan yang lebih baik, apabila digunakan pada model data sebenar, prestasi akan merudum.
Pendekatan yang betul ialah melakukan split train/ujian dahulu. Hanya selepas itu fungsi penjanaan ciri digunakan. Secara umumnya, ia adalah corak kejuruteraan ciri yang baik untuk memproses set latihan dan set ujian secara berasingan.
Dalam sesetengah kes, beberapa maklumat mesti dihantar antara keduanya - contohnya, kami mungkin mahu set ujian menggunakan StandardScaler yang sama yang digunakan untuk set latihan dan Latihan itu dijalankan pada. Tetapi ini hanyalah kes individu, jadi kami masih perlu menganalisis isu tertentu secara terperinci!

Adalah bagus untuk belajar daripada kesilapan anda. Tetapi yang terbaik adalah belajar daripada kesilapan orang lain - saya harap contoh kesilapan yang disediakan dalam artikel ini akan membantu anda.
Atas ialah kandungan terperinci Pembelajaran mesin adalah rahmat dari syurga! Saintis data dan master Kaggle mengeluarkan 'Panduan mengelakkan perangkap ML'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI