
Rumah >pembangunan bahagian belakang >Tutorial Python >Sepuluh petua Python merangkumi 90% keperluan analisis data!
Sepuluh petua Python merangkumi 90% keperluan analisis data!

- 王林ke hadapan
- 2023-04-12 08:04:021139semak imbas
Kerja harian penganalisis data melibatkan pelbagai tugas, seperti prapemprosesan data, analisis data, penciptaan model pembelajaran mesin dan penggunaan model.
Dalam artikel ini, saya akan berkongsi 10 operasi Python yang boleh merangkumi 90% masalah analisis data. Dapatkan beberapa suka, kegemaran dan perhatian.
1. Membaca set data
Membaca data ialah bahagian penting dalam analisis data Memahami cara membaca data daripada format fail yang berbeza adalah langkah pertama untuk penganalisis data. Berikut ialah contoh cara menggunakan panda untuk membaca fail csv yang mengandungi data Covid-19.
import pandas as pd
# reading the countries_data file along with the location within read_csv function.
countries_df = pd.read_csv('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_data.csv')
# showing the first 5 rows of the dataframe
countries_df.head()
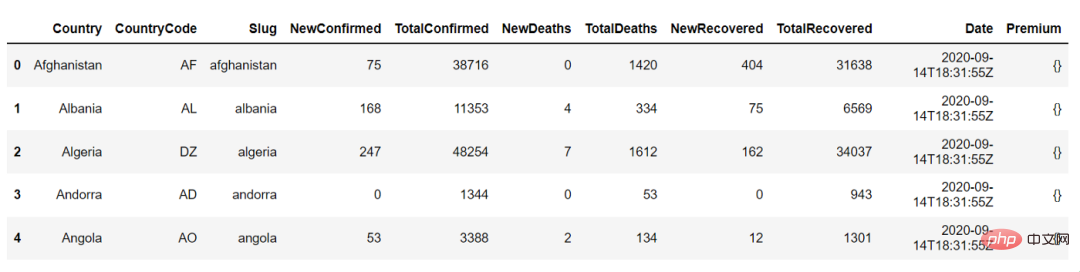
Berikut ialah keluaran country_df.head(), kita boleh menggunakannya untuk melihat 5 baris pertama bingkai data:
2. Statistik ringkasan
Langkah seterusnya ialah memahami data dengan melihat ringkasan data, seperti kiraan lajur angka seperti NewConfirmed dan TotalConfirmed, min, sisihan piawai, kuantiti dan kekerapan dan nilai kejadian tertinggi bagi lajur kategori seperti kod negara
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">countries_df</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">describe</span>()
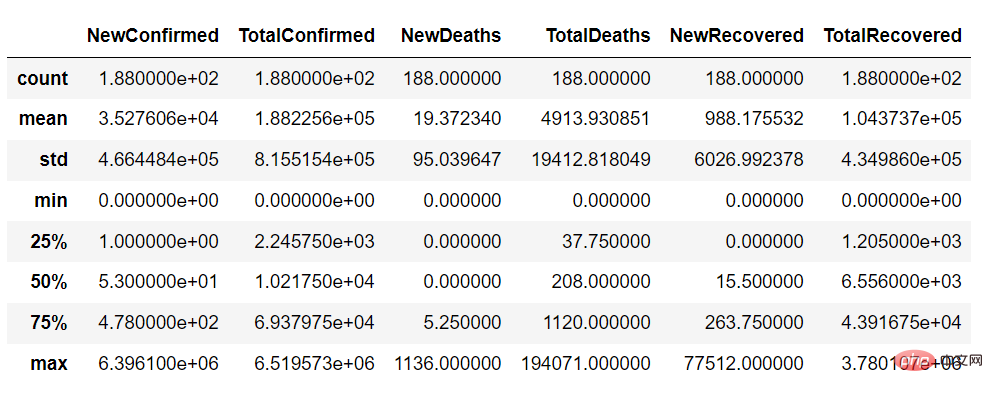
Menggunakan fungsi huraikan, kita boleh mendapatkan ringkasan pembolehubah berterusan set data seperti berikut:
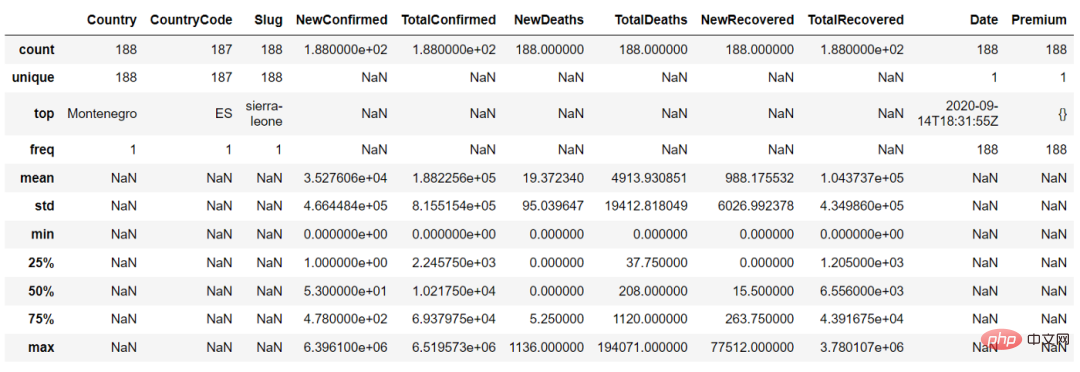
Dalam fungsi describe(), kita boleh menetapkan parameter "include = 'all'" untuk mendapatkan ringkasan pembolehubah berterusan dan pembolehubah kategori
countries_df.describe(include = 'all')
3. Pemilihan dan penapisan data
Analisis sebenarnya tidak diperlukan Semua baris dan lajur set data, cuma pilih lajur yang diminati dan tapis beberapa baris berdasarkan soalan.
Sebagai contoh, kita boleh memilih lajur Negara dan NewConfirmed menggunakan kod berikut:
countries_df[['Country','NewConfirmed']]
Kami juga boleh menapis data pada Negara, menggunakan loc, kami boleh menapis lajur berdasarkan beberapa nilai seperti yang ditunjukkan di bawah :
countries_df.loc[countries_df['Country'] == 'United States of America']

4. Pengagregatan
Penggabungan data seperti kiraan, jumlah, min, dll. adalah salah satu daripada tugas yang paling biasa dilakukan dalam analisis data.
Kami boleh menggunakan pengagregatan untuk mencari jumlah bilangan kes NewConfimed mengikut negara. Gunakan fungsi groupby dan agg untuk melaksanakan pengagregatan.
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})5 Sertai
Gunakan operasi Sertai untuk menggabungkan 2 set data ke dalam satu set data.
Contohnya: Satu set data mungkin mengandungi bilangan kes Covid-19 di negara yang berbeza dan set data lain mungkin mengandungi maklumat latitud dan longitud untuk negara yang berbeza.
Sekarang kita perlu menggabungkan kedua-dua maklumat ini, kemudian kita boleh melakukan operasi sambungan seperti yang ditunjukkan di bawah
countries_lat_lon = pd.read_excel('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_lat_lon.xlsx')
# joining the 2 dataframe : countries_df and countries_lat_lon
# syntax : pd.merge(left_df, right_df, on = 'on_column', how = 'type_of_join')
joined_df = pd.merge(countries_df, countries_lat_lon, on = 'CountryCode', how = 'inner')
joined_df6 Fungsi terbina dalam
Fahami matematik yang dibina -in functions , seperti min(), max(), mean(), sum(), dsb., sangat membantu untuk melaksanakan analisis yang berbeza.
Kita boleh menggunakan fungsi ini secara langsung pada bingkai data dengan memanggilnya, fungsi ini boleh digunakan secara bebas pada lajur atau dalam fungsi agregat seperti berikut:
# finding sum of NewConfirmed cases of all the countries
countries_df['NewConfirmed'].sum()
# Output : 6,631,899
# finding the sum of NewConfirmed cases across different countries
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})
# Output
#NewConfirmed
#Country
#Afghanistan75
#Albania 168
#Algeria 247
#Andorra0
#Angola537 >
Fungsi yang kami tulis sendiri adalah fungsi yang ditentukan pengguna. Kita boleh melaksanakan kod dalam fungsi ini apabila diperlukan dengan memanggil fungsi tersebut. Sebagai contoh, kita boleh mencipta fungsi untuk menambah 2 nombor seperti berikut:# User defined function is created using 'def' keyword, followed by function definition - 'addition()' # and 2 arguments num1 and num2 def addition(num1, num2): return num1+num2 # calling the function using function name and providing the arguments print(addition(1,2)) #output : 38 PivotPivot ialah untuk menukar nilai unik dalam baris lajur kepada berbilang lajur baharu. , Ini adalah teknologi pemprosesan data yang hebat. Menggunakan fungsi pivot_table() pada set data Covid-19, kami boleh menukar nama negara kepada lajur baharu yang berasingan:
# using pivot_table to convert values within the Country column into individual columns and # filling the values corresponding to these columns with numeric variable - NewConfimed pivot_df = pd.pivot_table(countries_df,columns = 'Country', values = 'NewConfirmed') pivot_df9 Lelaran pada bingkai data Banyak kali kita perlu melintasi indeks dan baris bingkai data, kita boleh menggunakan fungsi iterrows untuk melintasi bingkai data:
# iterating over the index and row of a dataframe using iterrows() function
for index, row in countries_df.iterrows():
print('Index is ' + str(index))
print('Country is '+ str(row['Country']))
# Output :
# Index is 0
# Country is Afghanistan
# Index is 1
# Country is Albania
# .......10 Operasi rentetan Berkali-kali kami memproses rentetan dalam lajur set data, dalam hal ini adalah penting untuk memahami beberapa operasi rentetan asas. Contohnya cara menukar rentetan kepada huruf besar, huruf kecil dan cara mencari panjang rentetan. Atas ialah kandungan terperinci Sepuluh petua Python merangkumi 90% keperluan analisis data!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!