
Rumah >Peranti teknologi >AI >Penerokaan awal ke dalam evolusi teknologi pra-latihan bahasa semula jadi
Penerokaan awal ke dalam evolusi teknologi pra-latihan bahasa semula jadi

- 王林ke hadapan
- 2023-04-11 22:04:041260semak imbas
Tiga tahap kecerdasan buatan:
Fungsi pengkomputeran: penyimpanan data dan keupayaan pengiraan, mesin jauh lebih baik daripada manusia.
Fungsi persepsi: penglihatan, pendengaran dan kebolehan lain Mesin sudah setanding dengan manusia dalam bidang pengecaman pertuturan dan pengecaman imej.
Kecerdasan kognitif: Untuk tugasan seperti pemprosesan bahasa semula jadi, pemodelan akal sehat dan penaakulan, mesin masih memerlukan perjalanan yang panjang.
Pemprosesan bahasa semula jadi tergolong dalam kategori kecerdasan kognitif Oleh kerana bahasa semula jadi mempunyai ciri-ciri abstrak, gabungan, kekaburan, pengetahuan dan evolusi, ia membawa cabaran besar kepada pemprosesan mesin bahasa semula jadi. Pemprosesan bahasa dipanggil permata mahkota kecerdasan buatan. Dalam tahun-tahun kebelakangan ini, model bahasa pra-latihan yang diwakili oleh BERT telah muncul, membawa pemprosesan bahasa semula jadi ke era baharu: model bahasa pra-latihan + penalaan halus untuk tugasan tertentu. Artikel ini cuba menyelesaikan evolusi teknologi pra-latihan bahasa semula jadi, dengan tujuan untuk berkomunikasi dan belajar dengan semua orang Kami mengalu-alukan kritikan dan pembetulan kekurangan dan kesilapan.
1. Purba - Perwakilan Perkataan
1.1 Pengekodan Satu-panas
Menggunakan vektor saiz perbendaharaan kata untuk mewakili perkataan, di mana nilai kedudukan perkataan yang sepadan ialah 1, dan kedudukan selebihnya ialah 0. Kelemahan:
- Keseparahan dimensi tinggi
- tidak boleh mewakili persamaan semantik: persamaan vektor Satu-panas bagi dua sinonim ialah 0
1.2 Pengedaran Formula mewakili
hipotesis semantik teragih: perkataan serupa mempunyai konteks yang serupa, dan semantik perkataan boleh diwakili oleh konteks. Berdasarkan idea ini, taburan konteks setiap perkataan boleh digunakan untuk mewakili perkataan.
1.2.1 Perwakilan kekerapan perkataan
Berdasarkan korpus, konteks perkataan digunakan untuk membina jadual kekerapan kejadian bersama Setiap baris jadual perkataan mewakili perwakilan vektor satu perkataan. Maklumat bahasa yang berbeza boleh ditangkap melalui pemilihan konteks yang berbeza Contohnya, jika perkataan dalam tetingkap tetap di sekeliling perkataan dalam ayat digunakan sebagai konteks, lebih banyak maklumat tempatan perkataan itu akan ditangkap: maklumat leksikal dan sintaksis dokumen digunakan sebagai konteks, Tangkap lebih banyak maklumat topik yang diwakili oleh perkataan. Kelemahan:
- Masalah perkataan frekuensi tinggi.
- Tidak boleh menggambarkan perhubungan tertib lebih tinggi: (A, B) (B, C) (C, D) !=> (A, D).
- Masih ada masalah jarang.
1.2.2 Perwakilan TF-IDF
Gantikan nilai dalam perwakilan kekerapan perkataan dengan TF-IDF untuk mengurangkan terutamanya masalah perkataan frekuensi tinggi dalam perwakilan kekerapan perkataan.
1.2.3 Perwakilan maklumat bersama titik
juga mengurangkan masalah perkataan frekuensi tinggi bagi perwakilan kekerapan perkataan Nilai dalam perwakilan kekerapan perkataan digantikan dengan maklumat bersama titik perkataan:

1.2.4 LSA
Dengan melakukan Penguraian Nilai Tunggal (SVD) pada matriks kekerapan perkataan, representasi vektor berdimensi rendah, berterusan dan padat bagi setiap perkataan boleh diperolehi, boleh dianggap mewakili semantik terpendam perkataan, kaedah ini juga dipanggil analisis semantik terpendam (Analisis Semantik Terpendam, LSA).

LSA mengurangkan masalah seperti perkataan frekuensi tinggi, perhubungan tertib tinggi, jarang, dll. Ia mempunyai hasil yang baik dalam algoritma pembelajaran mesin tradisional, tetapi terdapat juga beberapa kelemahan :
- Apabila senarai kosa kata besar, SVD lebih perlahan.
- Tidak dapat mengejar data baharu Apabila korpus berubah atau korpus baharu ditambah, ia perlu dilatih semula.
2. Zaman moden - vektor perkataan statik
Keteraturan teks dan hubungan kejadian bersama antara perkataan memberikan isyarat pembelajaran yang diselia sendiri secara semula jadi untuk pemprosesan bahasa semula jadi , membolehkan sistem untuk mempelajari pengetahuan daripada teks tanpa anotasi manual tambahan.
2.1 Word2Vec
2.1.1 CBOW
CBOW (Continous Bag-of-Words) menggunakan konteks (tetingkap) untuk meramal perkataan sasaran dan menggabungkan perkataan perkataan konteks Vektor adalah purata aritmetik dan kemudian kebarangkalian perkataan sasaran diramalkan.

2.1.2 Langkau-gram
Langkau gram meramalkan konteks demi perkataan.

2.2 GloVe
GloVe (Vektor Global untuk Perwakilan Perkataan) menggunakan vektor perkataan untuk meramalkan matriks kejadian bersama bagi perkataan dan melaksanakan penguraian matriks tersirat . Pertama, matriks kejadian bersama berwajaran jarak X dibina berdasarkan tetingkap konteks perkataan, dan kemudian matriks kejadian bersama X dipasang menggunakan vektor perkataan dan konteks:

Fungsi kerugian ialah:

2.3 Ringkasan
Pembelajaran dan penggunaan vektor perkataan Sebagai tambahan kepada maklumat kejadian bersama antara perkataan dalam korpus, idea asas masih merupakan hipotesis semantik yang diedarkan. Sama ada Word2Vec berdasarkan konteks tempatan atau GloVe berdasarkan maklumat kejadian bersama global yang eksplisit, intipatinya adalah untuk mengagregatkan maklumat konteks kejadian bersama perkataan dalam keseluruhan korpus ke dalam perwakilan vektor perkataan itu dan telah mencapai keputusan yang baik . , kelajuan latihan juga sangat pantas, tetapi vektor kekurangan adalah statik, iaitu, ia tidak mempunyai keupayaan untuk berubah dengan perubahan konteks.
3. Moden - model bahasa pra-latihan
Model bahasa autoregresif: Kira kebarangkalian bersyarat bagi perkataan pada saat semasa berdasarkan sejarah jujukan.

Model bahasa pengekodan automatik: bina semula perkataan bertopeng melalui konteks.

mewakili jujukan bertopeng
3.1 Cornerstone - Transformer

3.1.1 Attention model
Model perhatian boleh difahami sebagai mekanisme untuk menimbang jujukan vektor dan pengiraan berat.

3.1.2 Perhatian Kendiri Pelbagai Kepala
Model perhatian yang digunakan dalam Transformer boleh dinyatakan sebagai:

Apabila Q, K, V datang daripada jujukan vektor yang sama, ia menjadi model perhatian diri.
Perhatian diri berbilang kepala: Sediakan berbilang kumpulan model perhatian kendiri, sambungkan vektor keluarannya dan petakannya kepada dimensi lapisan tersembunyi Transformer melalui pemetaan linear. Model perhatian kendiri berbilang kepala boleh difahami sebagai ensemble pelbagai model perhatian kendiri.


3.1.3 Pengekodan kedudukan
Memandangkan model perhatian kendiri tidak mengambil kira maklumat kedudukan input vektor, tetapi kedudukan Maklumat adalah penting untuk pemodelan jujukan. Maklumat kedudukan boleh diperkenalkan melalui pembenaman kedudukan atau pengekodan kedudukan Transformer menggunakan pengekodan kedudukan.

3.1.4 Lain-lain
Selain itu, sambungan baki, Normalisasi Lapisan dan teknologi lain juga digunakan dalam blok Transformer.
3.1.5 Kelebihan dan Kekurangan
Kelebihan:
- Berbanding dengan RNN, ia boleh memodelkan kebergantungan jarak jauh dan perhatian mekanisma akan Jarak antara perkataan dikurangkan kepada 1, menghasilkan keupayaan yang lebih kukuh untuk memodelkan data jujukan panjang.
- Berbanding dengan RNN, ia boleh menggunakan kuasa pengkomputeran selari GPU dengan lebih baik.
- Keupayaan ekspresi yang kuat.
Kelemahan:
- Berbanding dengan RNN, parameternya lebih besar, yang meningkatkan kesukaran latihan dan memerlukan lebih banyak data latihan.
3.2 Model Bahasa Autoregresif
3.2.1 ELMo
ELMo: Pembenaman daripada Model Bahasa
Lapisan Input
pembenaman perkataan boleh digunakan secara langsung, atau urutan aksara dalam perkataan boleh digunakan melalui CNN atau model lain.

Struktur model

ELMo memodelkan model bahasa ke hadapan dan ke belakang secara bebas melalui LSTM model bahasa:

. Model bahasa belakang:

Matlamat pengoptimuman
Maksimum:

Aplikasi hiliran
Selepas ELMo dilatih, vektor berikut boleh diperolehi untuk digunakan dalam tugas hiliran.

ialah pembenaman perkataan yang diperolehi oleh lapisan input, dan merupakan hasil daripada penyambungan output LSTM ke hadapan dan ke belakang.
Apabila digunakan dalam tugas hiliran, vektor setiap lapisan boleh ditimbang untuk mendapatkan perwakilan vektor ELMo dan pemberat boleh digunakan untuk menskalakan vektor ELMo.

Tahap vektor lapisan tersembunyi yang berbeza mengandungi maklumat teks pada tahap atau butiran yang berbeza:
- Lapisan atas mengekod lebih banyak maklumat semantik
- Lapisan bawah mengekod lebih banyak maklumat leksikal dan sintaksis
Siri 3.2.2 GPT
GPT-1
Struktur model
Dalam GPT-1 (Generative Pra-Training), ia adalah model bahasa sehala yang menggunakan 12 struktur blok transformer sebagai penyahkod Setiap blok transformer ialah mekanisme perhatian kendiri berbilang kepala , dan kemudian dapatkan pengagihan kebarangkalian output melalui sambungan penuh.


- U: vektor satu-panas perkataan
- Kami: matriks vektor perkataan
- Wp: Matriks vektor kedudukan
Objektif pengoptimuman
Maksimum:

Aplikasi hiliran
Dalam tugasan hiliran, untuk set data berlabel, setiap kejadian mempunyai token input:, yang terdiri daripada label. Pertama, token ini dimasukkan ke dalam model pra-latihan terlatih untuk mendapatkan vektor ciri akhir. Kemudian hasil ramalan diperoleh melalui lapisan yang disambungkan sepenuhnya:

Matlamat tugas seliaan hiliran adalah untuk memaksimumkan:

Untuk mengelakkan masalah melupakan bencana, kehilangan pra-latihan dengan berat tertentu boleh ditambah kepada kehilangan penalaan halus, biasanya kerugian pra-latihan.


GPT-2
Idea teras GPT-2 boleh diringkaskan sebagai: mana-mana tugas yang diselia adalah subset model bahasa Apabila kapasiti model sangat besar dan jumlah data cukup kaya, latihan sahaja Pembelajaran model bahasa boleh menyelesaikan tugas pembelajaran lain yang diselia. Oleh itu, GPT-2 tidak melakukan terlalu banyak inovasi struktur dan reka bentuk pada rangkaian GPT-1 Ia hanya menggunakan lebih banyak parameter rangkaian dan set data yang lebih besar Matlamatnya adalah untuk melatih vektor perkataan dengan kebolehan generalisasi yang lebih kuat.
Antara 8 tugas model bahasa, GPT-2 telah mengatasi 7 kaedah terkini pada masa itu melalui pembelajaran sifar pukulan sahaja (sudah tentu, beberapa tugasan masih tidak sebaik model diselia) baik). Sumbangan terbesar GPT-2 adalah untuk mengesahkan bahawa model vektor perkataan yang dilatih dengan data besar-besaran dan sejumlah besar parameter boleh dipindahkan ke kategori tugas lain tanpa latihan tambahan.
Pada masa yang sama, GPT-2 menunjukkan bahawa apabila kapasiti model dan jumlah (kualiti) data latihan meningkat, terdapat ruang untuk perkembangan selanjutnya potensinya Berdasarkan idea ini, GPT-3 adalah dilahirkan.
GPT-3
Struktur model kekal tidak berubah, tetapi kapasiti model, volum data latihan dan kualiti ia dikenali sebagai gergasi, dan kesannya juga sangat baik.
Ringkasan

Dari GPT-1 hingga GPT-3, apabila kapasiti model dan jumlah data latihan meningkat, pengetahuan bahasa yang dipelajari oleh model juga meningkat. Kaya, paradigma pemprosesan bahasa semula jadi telah berubah secara beransur-ansur daripada "model pra-latihan + penalaan halus" kepada "model pra-latihan + pembelajaran sifar / beberapa pukulan". Kelemahan GPT ialah ia menggunakan model bahasa sehala BERT telah membuktikan bahawa model bahasa dua hala dapat meningkatkan kesan model.
3.2.3 XLNet
XLNet memperkenalkan maklumat kontekstual dua hala melalui model bahasa pilihatur (Model Bahasa Permutasi Ia tidak memperkenalkan tag khas dan mengelakkan pengedaran token yang tidak konsisten dalam pra-latihan). dan fasa penalaan halus. Pada masa yang sama, Transformer-XL digunakan sebagai struktur utama model, yang mempunyai kesan yang lebih baik pada teks panjang.
Model bahasa pilihatur
Matlamat model bahasa pilihatur ialah:

ialah set semua pilih atur yang mungkin bagi jujukan teks .
Mekanisme perhatian diri dua aliran
- Tujuan mekanisme perhatian diri dua aliran (Perhatian Kendiri Dua aliran): dengan mengubah Transformer, apabila memasukkan turutan teks biasa , laksanakan model bahasa pilihatur:
- Perwakilan kandungan: mengandungi maklumat
- Perwakilan pertanyaan: hanya mengandungi maklumat


Kaedah ini menggunakan maklumat kedudukan perkataan yang diramalkan.
Aplikasi hiliran
Apabila menggunakan tugas hiliran, tiada perwakilan pertanyaan diperlukan dan topeng tidak diperlukan.
3.3 Autoenkod model bahasa
3.3.1 BERT
Model bahasa topeng
Model bahasa maskd (MLM), rawak Separa menutup perkataan, dan kemudian menggunakan maklumat kontekstual untuk membuat ramalan. Terdapat masalah dengan MLM, terdapat ketidakpadanan antara pra-latihan dan penalaan halus, kerana token [MASK] tidak pernah dilihat semasa penalaan halus. Untuk menyelesaikan masalah ini, BERT tidak selalu menggantikan token perkataan "bertopeng" dengan token [MASK] sebenar. Penjana data latihan secara rawak memilih 15% token dan kemudian:
- 80% kebarangkalian: digantikan dengan token [MASK].
- Kebarangkalian 10%: gantikan dengan token rawak daripada senarai kosa kata.
- 10% kebarangkalian: token kekal tidak berubah.
Token bertopeng dalam BERT asli, dan keseluruhan perkataan atau frasa (N-Gram) boleh bertopeng.
Ramalan ayat seterusnya
Ramalan ayat seterusnya (NSP): Apabila ayat A dan B dipilih sebagai sampel pra-latihan, B mempunyai peluang 50% untuk menjadi ayat A seterusnya, dan peluang 50% mungkin ayat rawak daripada korpus.
Lapisan input

Struktur model

Klasik "model pra-latihan + penalaan halus" Paradigma struktur topik disusun Transformers berbilang lapisan.
3.3.2 RoBERTa
RoBERTa (Pendekatan Pralatihan BERT Dioptimumkan Teguh) tidak meningkatkan BERT secara drastik, tetapi hanya menjalankan eksperimen terperinci pada setiap butiran reka bentuk BERT untuk mencari ruang untuk penambahbaikan BERT.
- Topeng dinamik: Kaedah asal adalah untuk menetapkan topeng dan membetulkannya semasa membina set data Kaedah yang dipertingkatkan adalah untuk menutup data secara rawak apabila memasukkan data ke dalam model dalam setiap pusingan latihan , yang meningkatkan ketepatan data.
- Tinggalkan tugas NSP: Eksperimen telah menunjukkan bahawa tidak menggunakan tugas NSP boleh meningkatkan prestasi untuk kebanyakan tugas.
- Lebih banyak data latihan, kelompok yang lebih besar dan langkah pra-latihan yang lebih panjang.
- Perbendaharaan kata yang besar: Menggunakan perbendaharaan kata BPE peringkat bait bagi SentencePiece dan bukannya perbendaharaan kata BPE peringkat aksara WordPiece, hampir tiada perkataan yang tidak didaftarkan.
3.3.3 ALBERT
BERT mempunyai bilangan parameter yang agak besar Matlamat utama ALBERT (A Lite BERT) adalah untuk mengurangkan parameter:
- <.>Perkataan BERT Dimensi vektor adalah sama dengan dimensi lapisan tersembunyi, dan vektor perkataan tidak bergantung kepada konteks Walau bagaimanapun, lapisan Transformer BERT memerlukan dan boleh mempelajari maklumat kontekstual yang mencukupi, jadi dimensi vektor lapisan tersembunyi harus jauh lebih besar daripada perkataan. dimensi vektor. Apabila meningkatkan untuk meningkatkan prestasi, tidak perlu menambah saiz kerana ruang vektor perkataan mungkin mencukupi untuk jumlah maklumat yang perlu dibenamkan.
- Penyelesaian: Vektor perkataan diubah menjadi dimensi H melalui lapisan bersambung sepenuhnya.
- Parameterisasi pembenaman berfaktor.
- Perkongsian parameter merentas lapisan: Blok pengubah bagi parameter perkongsian lapisan berbeza.
- Ramalan susunan ayat (SOP), mempelajari perbezaan semantik halus dan koheren wacana.




- Penjana dan diskriminator adalah setiap satu BERT, yang menskalakan parameter BERT penjana.
- Penguraian parameter vektor perkataan.
- Perkongsian parameter penjana dan diskriminator: parameter lapisan input dikongsi, termasuk matriks vektor perkataan dan matriks vektor kedudukan.


Satu lagi faedah pengulangan serpihan ialah peningkatan dalam kelajuan penaakulan Berbanding dengan seni bina autoregresif Transformer, yang hanya boleh memajukan satu kepingan masa pada satu masa, proses penaakulan Transformer-XL secara langsung menggunakan semula perwakilan serpihan sebelumnya dan bukannya Kira dari awal. dan menambah baik proses penaakulan kepada penaakulan dalam serpihan.

3.5.2 Pengekodan kedudukan relatif
Dalam Transformer, model perhatian kendiri boleh dinyatakan sebagai:

ialah:


Masalah dengan Transformer ialah tidak kira serpihan mana pun, kedudukan mereka pengekodan adalah sama, iaitu, pengekodan kedudukan Transformer ialah pengekodan kedudukan mutlak relatif kepada serpihan, dan tiada kaitan dengan kedudukan relatif kandungan semasa dalam ayat asal.
Transfomer-XL membuat beberapa perubahan berdasarkan formula di atas dan memperoleh kaedah pengiraan berikut:

- Perubahan 1: Sederhana, Ia terbelah menjadi jumlah sebenar, yang bermaksud bahawa urutan input dan pengekodan kedudukan tidak lagi berkongsi pemberat.
- Perubahan 2: Dalam, pengekodan kedudukan mutlak digantikan dengan pengekodan kedudukan relatif
- Perubahan 3: Dua parameter baharu yang boleh dipelajari diperkenalkan untuk menggantikan vektor pertanyaan dalam Transformer. Menunjukkan bahawa vektor kedudukan pertanyaan yang sepadan adalah sama untuk semua kedudukan pertanyaan. Iaitu, tanpa mengira kedudukan pertanyaan, bias perhatian untuk perkataan yang berbeza kekal konsisten.
- Selepas penambahbaikan, maksud setiap bahagian:
- Kaitan berasaskan kandungan (): Kira maklumat korelasi antara kandungan pertanyaan dan kunci
- Imbang kedudukan berkaitan kandungan (): Kira maklumat perkaitan antara kandungan pertanyaan dan kod kedudukan kunci
- Imbang kandungan global (): Kira perkaitan antara kod kedudukan pertanyaan dan kandungan maklumat utama
- Kedudukan global mengimbangi (): Kira maklumat yang berkaitan antara pertanyaan dan pengekodan kedudukan kunci
3.6 Penyulingan dan pemampatan - DistillBert
Penyulingan pengetahuan teknologi (Knowledge Distillation, KD): Ia biasanya terdiri daripada model guru dan model pelajar Ia memindahkan pengetahuan daripada model guru kepada model pelajar supaya model pelajar sedekat mungkin dengan model guru. model pelajar selalunya dikehendaki lebih kecil dan lebih asas daripada model guru Kekalkan kesan model asal.
Model pelajar DistillBert:
- BERT enam lapisan, sambil mengalih keluar Pembenaman jenis Token (Pembenaman Segmen).
- Mulakan menggunakan enam lapisan pertama model guru.
- Hanya model bahasa bertopeng digunakan untuk latihan, tiada tugas NSP digunakan.
Model guru: BERT-base:
Fungsi kehilangan:
Kehilangan MLM yang diselia: menggunakan topeng Cross -kehilangan entropi yang diperoleh daripada latihan model bahasa kod:
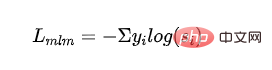
- mewakili label kategori ke dan mewakili kebarangkalian keluaran model pelajar kategori ke.
- Kehilangan MLM suling: Menggunakan kebarangkalian model guru sebagai isyarat panduan, hitung kehilangan entropi silang dengan kebarangkalian model pelajar:
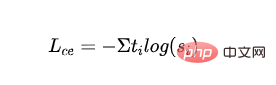
- mewakili label kategori pertama model guru.
- Kehilangan kosinus vektor perkataan: Jajarkan arah vektor lapisan tersembunyi model guru dan model pelajar, dan pendekkan jarak antara model guru dan model pelajar daripada lapisan tersembunyi dimensi:
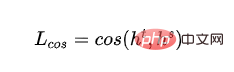
- dan mewakili output lapisan tersembunyi bagi lapisan terakhir model guru dan model pelajar masing-masing.
- Kehilangan akhir:
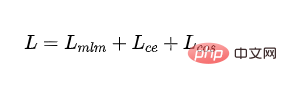
4 Rujukan
https :/. /www.php.cn/link/6e2290dbf1e11f39d246e7ce5ac50a1e
https://www.php.cn/link/664c7298d2b73b13c7298d2b73b
https://www.php.cn/link/67b878df6cd42d142f2924f3ace85c78https://www.php.cn/link/f6a1973fcd084b 🎜>https://www.php.cn/link/82599a4ec94aca066873c99b4c741ed8
https://www .cn/link/2e64da0bae6a7533021c760d4ba5d621
https://www.php.cn/link/56d33021e640f5d64a511
🎜 🎜>Https://www.php.cn/link/4e38d30e656da5ae9d3a425109ce9e04 >
https://www.php.cn/link/a749e38f556d5eb1dc13b9221d1f994fhttps://www.php.cn/link / 8ab9bb97ce35080338be74dc6375e0edhttps://www.php.cn/link/4f0bf7b7b1aca9ad15317a0b4 :// /www.php.cn/link/b81132591828d622fc335860bffec150
https://www.php.cn/link/fca758e52635df5a640df5a640> https://www.php.cn/link/5112277ea658f7138694f079042cc3bb
https://www.php.cn/link/257deb66abf3406d
https://www.php.cn/link/b18e8fb514012229891cf024b6436526https://www.php. cn/link/836a0dcbf5d22652569dc3a708274c16https://www.php.cn/link/a3de03cb426b5e36f23>https://www.php.cn/link/a3de03cb426b5e36f23> https://www.php.cn/link/831b342d8a83408e5960e9b0c5f31f0c
https://www.php.cn/link/6b27e88fdd7249394b48493948b48fdd7269394b 🎜>
https://www.php.cn/link/682e0e796084e163c5ca053dd8573b0c
3https://www.php.cn/link/9739efc
https://www.php.cn/link/b93e78c67fd4ae3ee626d8ec0c412dec
https://www .php.cn/link/c8cc6e90ccbff44c9cee23611711cdc4
Atas ialah kandungan terperinci Penerokaan awal ke dalam evolusi teknologi pra-latihan bahasa semula jadi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI