
Rumah >Peranti teknologi >AI >Wang Lin dari Teknologi Taifan: Pangkalan data graf - cara baharu untuk kecerdasan kognitif
Wang Lin dari Teknologi Taifan: Pangkalan data graf - cara baharu untuk kecerdasan kognitif

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-11 14:37:031853semak imbas
Tetamu |
Perancangan | Xu Jiecheng
Kecerdasan buatan mempunyai dua puak yang agak besar: isme rasionaliti dan empirisme. Tetapi dalam produk gred industri sebenar kedua-dua puak ini saling melengkapi. Bagaimana untuk memperkenalkan lebih banyak kawalan dan lebih banyak pengetahuan ke dalam kotak hitam model ini memerlukan aplikasi graf pengetahuan, yang membawa pengetahuan simbolik.Beberapa hari lalu, di Persidangan Inovasi Teknologi Global WOT yang dihoskan oleh 51CTO, CTO Teknologi Taifan Dr. Wang Lin membawa evolusi topik "Pangkalan Data Grafik: Laluan Baharu Kecerdasan Kognitif" kepada para hadirin, memfokuskan pada sejarah dan evolusi model pangkalan data graf cara penting untuk pangkalan data graf untuk mencapai kecerdasan kognitif, Serta reka bentuk pangkalan data graf dan pengalaman praktikal; OpenGauss.
Kandungan ucapan kini disusun seperti berikut, dengan harapan dapat memberi inspirasi kepada anda:
Daripada titik tertentu Dari perspektif dimensi, kecerdasan buatan boleh dibahagikan kepada dua kategori Satu ialah Connectionism, iaitu pembelajaran mendalam yang kita kenali, yang mensimulasikan struktur otak manusia untuk melakukan perkara-perkara seperti itu. sebagai persepsi, pengiktirafan, dan pertimbangan.
Jenis yang lain ialah Simbolisme
, yang biasanya menyerupai minda manusia. Proses kognitif ialah operasi pada perwakilan simbolik. Oleh itu, ia sering digunakan untuk beberapa pemikiran dan penaakulan. Teknologi perwakilan biasa ialah graf pengetahuan.4 cara untuk meningkatkan AI dengan graf
1 🎜> Graf pengetahuan pada asasnya ialah rangkaian semantik berasaskan graf yang mewakili entiti dan hubungan antara entiti. Pada peringkat tinggi, graf pengetahuan juga merupakan koleksi pengetahuan yang saling berkaitan, menerangkan dunia sebenar dan hubungan antara entiti dan benda dalam bentuk yang boleh difahami oleh manusia.
Graf pengetahuan boleh membawa kami lebih banyak pengetahuan domain dan maklumat kontekstual untuk membantu kami membuat keputusan. Dari perspektif aplikasi, graf pengetahuan boleh dibahagikan kepada tiga jenis: 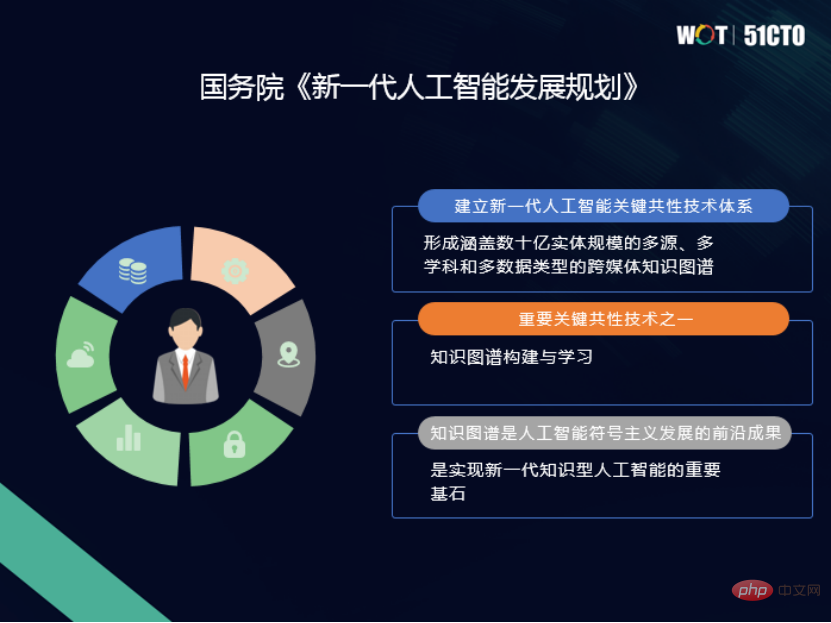
Satu ialahDomain -graf pengetahuan berkaitan. Pengetahuan yang diekstrak daripada data berstruktur dan separa berstruktur membentuk graf pengetahuan, yang relevan dalam bidang Aplikasi yang paling tipikal ialah enjin carian Google.
Yang kedua ialah
graf pengetahuan persepsi luaran. Agregat sumber data luaran dan petakannya kepada entiti dalaman yang diminati. Aplikasi biasa adalah dalam analisis risiko rantaian bekalan, anda boleh melihat maklumat tentang pembekal, huluan dan hilirannya, kilang dan talian bekalan lain, supaya anda boleh menganalisis di mana terdapat masalah dan sama ada terdapat risiko gangguan. 
Yang ketiga ialah
. Pemprosesan bahasa semula jadi termasuk sejumlah besar istilah teknikal dan juga kata kunci dalam bidang, yang boleh membantu kami membuat pertanyaan bahasa semula jadi. 2. Meningkatkan kecekapan operasi
Kaedah pembelajaran mesin sering bergantung pada data yang disimpan dalam jadual, dan kebanyakan data ini sebenarnya adalah operasi intensif sumber menyediakan kandungan yang berkaitan dalam bidang kecekapan tinggi, menyambung data dan mencapai pelbagai darjah pemisahan dalam perhubungan, yang kondusif untuk analisis pantas berskala besar. Daripada perspektif ini, graf itu sendiri mempercepatkan kesan pembelajaran mesin. Selain itu, algoritma pembelajaran mesin selalunya perlu dikira pada semua data. Melalui pertanyaan graf ringkas, anda boleh mengembalikan subgraf data yang diperlukan, dengan itu mempercepatkan kecekapan operasi.
3. Tingkatkan ketepatan ramalan Perhubungan selalunya merupakan peramal tingkah laku yang paling kuat, dan ciri-ciri perhubungan boleh didapati dengan mudah daripada graf.
Dengan mengaitkan data dan rajah perhubungan, ciri-ciri perhubungan boleh diekstrak dengan lebih langsung. Tetapi dalam kaedah pembelajaran mesin tradisional, kadangkala banyak maklumat penting sebenarnya hilang apabila mengabstraksi dan memudahkan data. Oleh itu, sifat hubungan membolehkan kita menganalisis tanpa kehilangan maklumat ini. Selain itu, algoritma graf memudahkan proses menemui anomali seperti komuniti yang ketat. Kami boleh menjaringkan nod dalam komuniti yang ketat dan mengekstrak maklumat tersebut untuk digunakan dalam melatih model pembelajaran mesin. Akhir sekali, pemilihan ciri dilakukan menggunakan algoritma graf untuk mengurangkan bilangan ciri yang digunakan dalam model kepada subset yang paling relevan.
4. Kebolehtafsiran
Dalam beberapa tahun kebelakangan ini, kami sering mendengar tentang "kebolehtafsiran", yang juga merupakan satu cabaran besar dalam penerapan kecerdasan buatan untuk memahami cara kecerdasan buatan mencapai keputusan ini dan keputusan ini, dan terdapat banyak tuntutan untuk kebolehjelasan, terutamanya dalam beberapa bidang aplikasi tertentu, seperti perubatan, kewangan dan keadilan.
Kebolehtafsiran merangkumi tiga aspek:
(1) Data boleh tafsir . Kita perlu tahu mengapa data tersebut dipilih, apakah sumber data tersebut? Data mesti boleh ditafsir.
(2) Ramalan boleh tafsir . Ramalan yang boleh ditafsir bermakna kita perlu mengetahui ciri yang digunakan dan pemberat yang digunakan untuk ramalan tertentu.
(3) Algoritma boleh tafsir . Prospek semasa algoritma yang boleh dijelaskan adalah sangat menarik, tetapi masih jauh lagi rangkaian Tensor sedang dicadangkan dalam bidang penyelidikan, dan kaedah sedemikian boleh digunakan untuk menjadikan algoritma mempunyai kebolehtafsiran tertentu.
Model data graf arus perdana
Memandangkan graf sangat penting untuk aplikasi dan pembangunan kecerdasan buatan, bagaimanakah kita harus melakukannya penggunaannya? Perkara pertama yang perlu anda perhatikan ialah pengurusan storan graf, iaitu model data graf.
Pada masa ini terdapat dua model data graf paling arus perdana: graf RDF dan graf atribut.
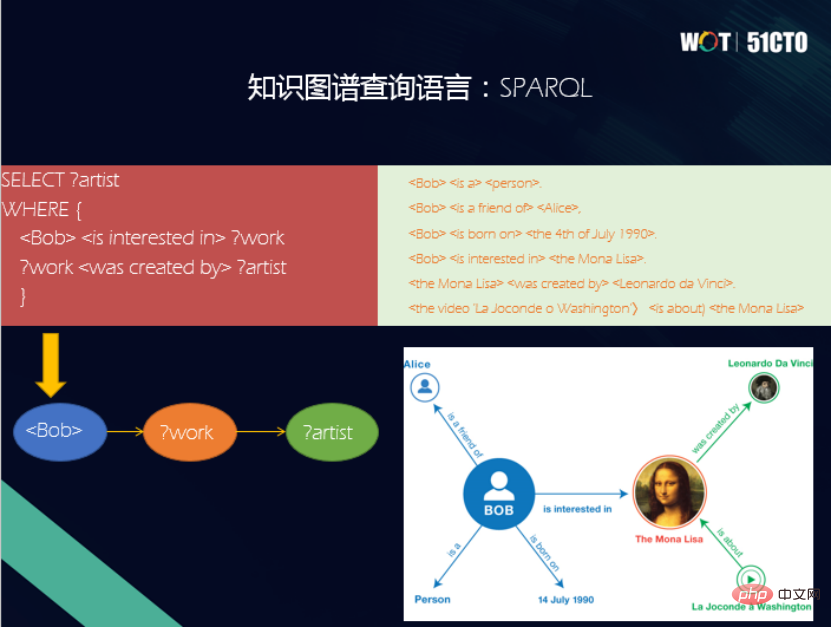
1. Gambar rajah RDF
RDF bermaksud Rangka Kerja Penerangan Sumber Ia adalah data standard yang dirumuskan oleh W3C untuk mewakili pertukaran maklumat yang boleh difahami oleh mesin di Dunia Semantik Model Web. Dalam graf RDF, setiap sumber mempunyai URL HTTP sebagai ID unik. Definisi RDF adalah dalam bentuk triplet, mewakili pernyataan fakta, di mana S mewakili subjek, P ialah predikat, dan O ialah objek. Dalam gambar, Bob berminat dengan The MonoLisa, menyatakan fakta bahawa ini adalah gambar rajah RDF. Model data yang sepadan dengan graf RDF mempunyai bahasa pertanyaannya sendiri - SPARQL. SPARQL ialah bahasa pertanyaan standard untuk graf pengetahuan RDF yang dibangunkan oleh W3C. SPARQL mengambil pengajaran daripada SQL dalam sintaksnya dan merupakan bahasa pertanyaan perisytiharan Unit asas pertanyaan juga merupakan corak triplet.

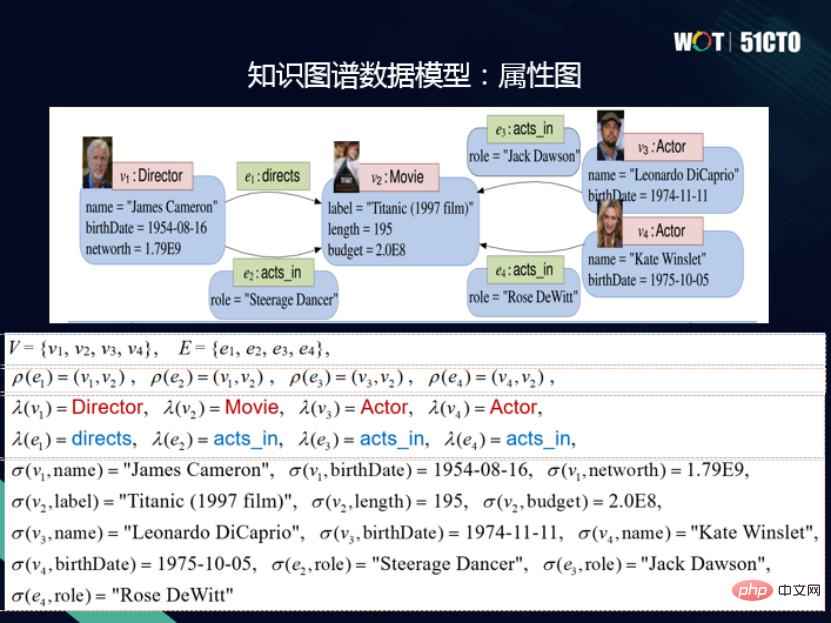
2. Graf atribut
Setiap bucu dan tepi dalam model graf atribut mempunyai ID unik dan bucu serta tepi juga mempunyai ID unik Terdapat label, yang setara dengan jenis sumber dalam graf RDF. Selain itu, bucu dan tepi juga mempunyai satu set atribut, yang terdiri daripada nama atribut dan nilai atribut, sekali gus membentuk model graf atribut.
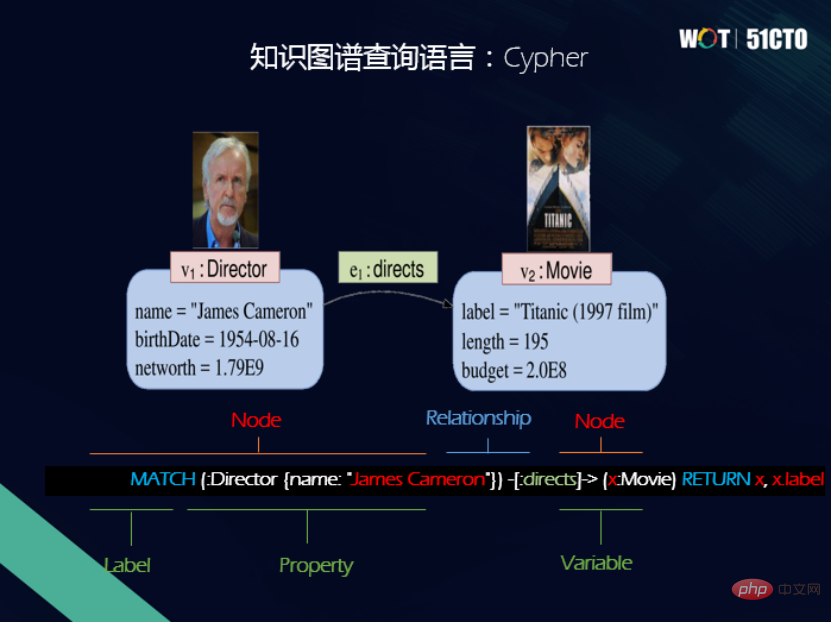
Begitu juga, model graf atribut juga mempunyai bahasa pertanyaan - Cypher. Cypher juga merupakan bahasa pertanyaan perisytiharan Pengguna hanya perlu mengisytiharkan perkara yang mereka mahu cari, dan tidak perlu menunjukkan cara untuk mencari. Salah satu ciri utama Cypher ialah penggunaan sintaks artistik ASCII untuk menyatakan padanan corak graf.
Dengan perkembangan kecerdasan buatan, perkembangan kecerdasan kognitif dan aplikasi graf pengetahuan semakin meningkat . Oleh itu, pangkalan data graf telah mendapat lebih banyak perhatian dalam pasaran sejak beberapa tahun kebelakangan ini, tetapi masalah penting yang dihadapi dalam graf pada masa ini ialah ketidakkonsistenan antara model data dan bahasa pertanyaan, yang merupakan masalah mendesak yang perlu diselesaikan
.
Terdapat dua titik permulaan utama untuk mengkaji pangkalan data graf OpenGauss.
Di satu pihak, saya ingin memanfaatkan ciri-ciri graf pengetahuan itu sendiri. Sebagai contoh, dari segi prestasi tinggi, ketersediaan tinggi, keselamatan tinggi, dan pengendalian dan penyelenggaraan yang mudah, adalah sangat penting bagi pangkalan data untuk dapat menyepadukan ciri-ciri ini ke dalam pangkalan data graf.
Sebaliknya, pertimbangkan model data graf . Pada masa ini terdapat dua model data dan dua bahasa pertanyaan Jika anda menyelaraskan pengendali semantik di belakang dua bahasa pertanyaan yang berbeza ini, seperti unjuran, pemilihan, gabungan, dll. dalam pangkalan data hubungan, jika anda menyelaraskan semantik di belakang bahasa SPARQL dan Cypher, Menyediakan. dua pandangan sintaks yang berbeza, sekali gus mencapai kebolehoperasian semula jadi. Maksudnya, semantik dalaman boleh konsisten, supaya anda boleh menggunakan Cypher untuk menyemak graf RDF, dan anda juga boleh menggunakan SPARQL untuk menyemak graf atribut, yang membentuk ciri yang sangat baik.
OpenGauss—Seni bina Graf
Lapisan bawah menggunakan OpenGauss dan menggunakan model hubungan sebagai graf untuk menyimpan model fizikal. Ideanya adalah untuk menukar graf RDF Jika terdapat apa-apa ketidakselarasan dengan graf atribut, satukan storan fizikal asas dengan mencari pembahagi sepunya yang paling besar.
Berdasarkan idea ini, lapisan bawah seni bina OpenGauss-Graph ialah infrastruktur, diikuti dengan kaedah akses, graf atribut bersatu dan kaedah pemprosesan dan pengurusan graf RDF. Seterusnya ialah enjin pelaksanaan pemprosesan pertanyaan bersatu untuk menyokong pengendali semantik bersatu, termasuk operator pemadanan subgraf, pengendali navigasi laluan, pengendali analisis graf dan pengendali pertanyaan kata kunci. Selanjutnya ialah antara muka API bersatu, yang menyediakan antara muka SPARQL dan antara muka Cypher. Selain itu, terdapat piawaian bahasa untuk bahasa pertanyaan bersatu dan antara muka visual untuk pertanyaan interaktif.
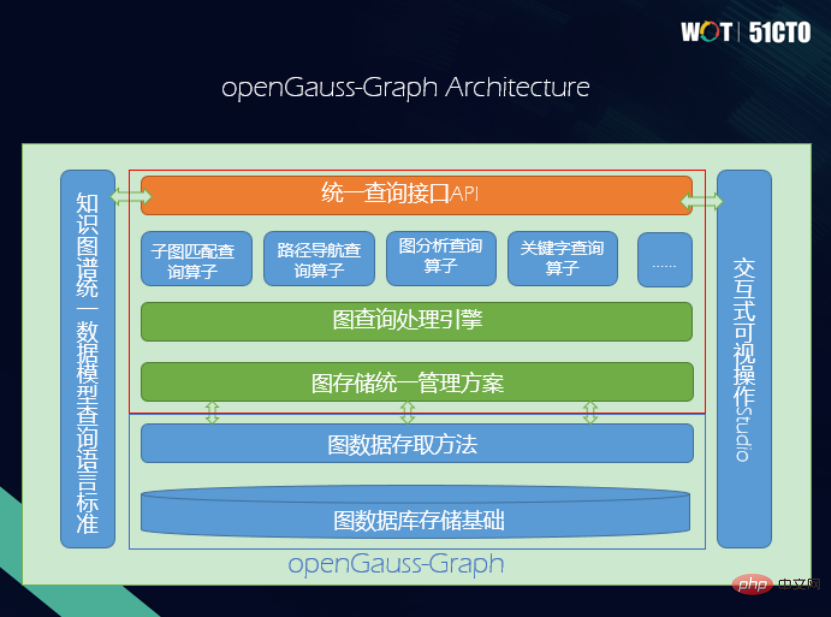
Reka bentuk penyelesaian storan
Dua perkara berikut perlu dipertimbangkan semasa mereka bentuk penyelesaian storan:
(1) Ia tidak boleh terlalu kompleks, kerana kecekapan penyelesaian storan yang terlalu kompleks tidak akan terlalu tinggi.
(2) Ia mesti mampu menampung jenis data dua graf pengetahuan yang berbeza dengan bijak.
Oleh itu, terdapat penyelesaian penyimpanan untuk jadual titik dan jadual tepi. Terdapat jadual titik biasa yang dipanggil sifat Untuk mata yang berbeza, akan ada warisan; Jenis jadual titik dan jadual tepi yang berbeza akan mempunyai salinan, dengan itu mengekalkan penyelesaian penyimpanan untuk koleksi jadual titik dan tepi.
Jika ia adalah graf atribut, titik dengan label yang berbeza akan menemui jadual titik yang berbeza Sebagai contoh, profesor akan mencari jadual titik profesor. Atribut mata dipetakan ke lajur atribut dalam jadual titik, perkara yang sama berlaku untuk jadual tepi, pengarang dipetakan ke jadual tepi pengarang, dan tepi dipetakan ke baris dalam jadual tepi dengan ID bagi nod permulaan dan nod akhir.
Melalui kaedah yang kelihatan mudah tetapi sebenarnya sangat serba boleh, graf RDF dan graf atribut boleh disatukan daripada lapisan fizikal. Tetapi dalam aplikasi sebenar, terdapat sebilangan besar entiti yang tidak ditaip Pada masa ini, kami menggunakan kaedah mengklasifikasikan semantik ke dalam jadual ditaip yang paling hampir.
Amalan pemprosesan pertanyaan
Selain storan, perkara yang paling penting ialah pertanyaan. Pada peringkat semantik, kami telah menjajarkan operasi dan mencapai kesalingoperasian antara dua bahasa pertanyaan, SPARQL dan Cypher.
Dalam kes ini, dua peringkat terlibat: tatabahasa dan leksikon, dan penghuraian mereka tidak boleh menghasilkan percanggahan bersama. Kata kunci dipetik di sini Sebagai contoh, jika anda menyemak SPARQL, anda akan menghidupkan sintaks SPARQL Jika anda menyemak Cypher, anda akan menghidupkan sintaks Cypher untuk mengelakkan konflik.

Kami juga telah melaksanakan banyak pengendali pertanyaan.
(1) Pertanyaan pemadanan subgraf , menanyakan semua komposer, gubahan mereka dan hari lahir komposer ialah masalah pemadanan subgraf biasa. Ia boleh dibahagikan kepada graf atribut dan graf RDF, dan aliran pemprosesan amnya juga sama. Sebagai contoh, titik yang sepadan ditambah pada senarai terpaut bergabung, dan kemudian operasi pemilihan ditambahkan pada lajur sifat, dan kemudian kekangan dikenakan pada sambungan antara jadual titik sepadan dengan corak titik kepala dan ekor. Graf RDF melakukan operasi penting pada titik mula dan akhir jadual tepi Pada akhirnya, kekangan unjuran ditambah kepada pembolehubah dan hasil akhir adalah sama.
Pertanyaan pemadanan subgraf juga menyokong beberapa fungsi terbina dalam, seperti fungsi FILTER, yang mengehadkan bentuk pembolehubah, pengendali logik, pengagregatan dan operator aritmetik Sudah tentu, bahagian ini juga boleh dikembangkan secara berterusan.

(2) Pertanyaan navigasi , yang terdapat dalam pangkalan data hubungan tradisional Di sana tiada perkara seperti itu dalam . Bahagian kiri rajah di bawah ialah graf rangkaian sosial kecil Ini adalah graf terarah Anda boleh melihat bahawa pengetahuan adalah satu hala, tetapi Pat tidak mengenali Tom. Dalam pertanyaan navigasi, jika anda melakukan pertanyaan dua lompatan, lihat siapa yang mengenali Tom. Jika ia adalah 0 lompatan, Tom tahu dirinya. Lompatan pertama ialah Tom mengenali Pat, dan Tom mengenali Summer. Lompatan kedua ialah apabila Tom mengenali Pat, kemudian mengenali Nikki, dan kemudian mengenali Tom semula.
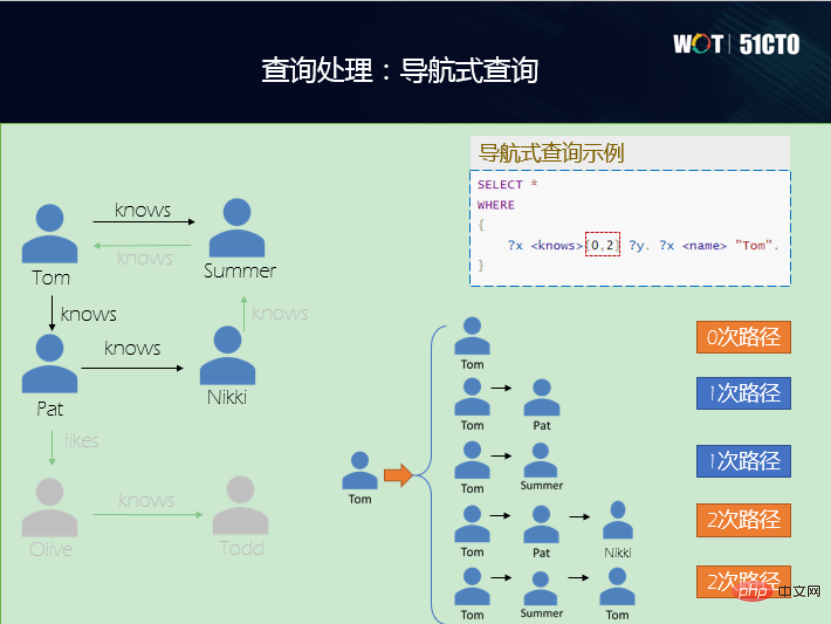
(3) Pertanyaan kata kunci , berikut ialah dua contoh, tsvector dan tsquery . Satu adalah untuk menukar dokumen ke dalam senarai istilah; yang lain adalah untuk bertanya sama ada perkataan atau frasa yang ditentukan wujud dalam vektor. Apabila teks dalam graf pengetahuan agak panjang dan mempunyai atribut yang agak panjang, fungsi ini boleh digunakan untuk menyediakannya dengan fungsi carian kata kunci, yang juga sangat berguna.

(4) Pertanyaan analitik mempunyai ciri uniknya sendiri untuk pangkalan data graf Pertanyaan , seperti laluan terpendek , Pagerank, dsb. adalah semua pengendali pertanyaan berasaskan graf dan boleh dilaksanakan dalam pangkalan data graf. Sebagai contoh, untuk menyemak apakah laluan terpendek dari Tom ke Nikki, pengendali laluan terpendek dilaksanakan melalui Cypher, dan laluan terpendek boleh dikeluarkan dan hasilnya ditemui.
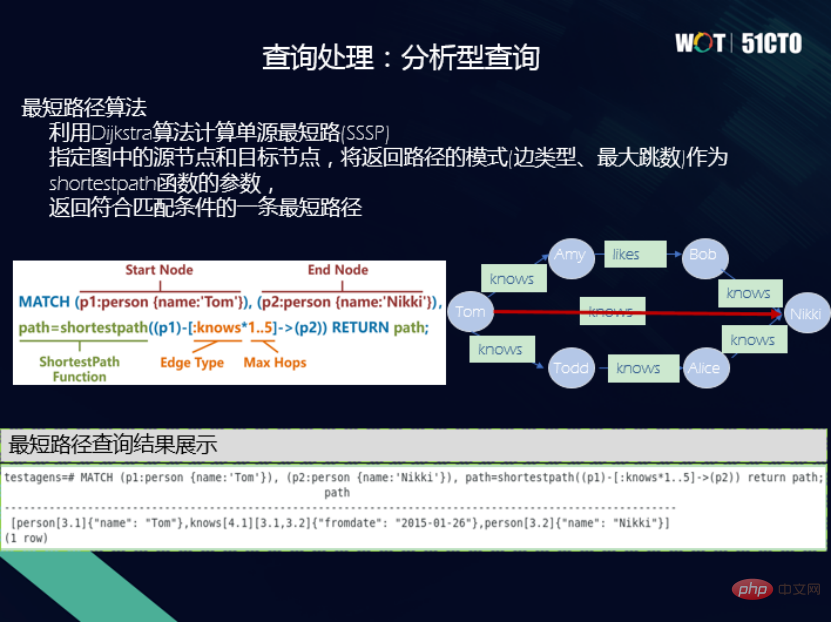
Selain fungsi yang dinyatakan di atas, kami juga melaksanakan studio interaktif visual, dalam Masukkan pertanyaan bahasa Cypher dan SPARQL, dan anda boleh mendapatkan graf intuitif visual, di mana anda boleh mengekalkan, mengurus dan menggunakan graf Anda juga boleh melakukan banyak interaksi pada graf pada masa hadapan, kami akan mempunyai lebih banyak operator dan graf pertanyaan. , carian graf ditambah untuk merealisasikan lebih banyak arahan dan senario aplikasi.
Akhir sekali, semua orang dialu-alukan untuk melawat komuniti OpenGauss Graph Rakan-rakan yang berminat dengan OpenGauss Graph juga dialu-alukan untuk menyertai komuniti, sebagai penyumbang baharu dan membina komuniti OpenGauss Graph bersama-sama. .
Pengenalan Tetamu
Wang Lin, Doktor Kejuruteraan, Penyelenggara Komuniti Pangkalan Data Graf OpenGauss, Teknologi Taifan CTO, jurutera kanan, naib pengerusi Persekutuan Komputer China YOCSEF Tianjin 21-22, ahli eksekutif Jawatankuasa Sistem Maklumat CCF, dipilih ke dalam Projek Bakat Tianjin 131.
Atas ialah kandungan terperinci Wang Lin dari Teknologi Taifan: Pangkalan data graf - cara baharu untuk kecerdasan kognitif. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI