
Rumah >Peranti teknologi >AI >Sumber terbuka GitHub 130+Bintang: mengajar anda langkah demi langkah untuk menghasilkan semula algoritma pengesanan sasaran berdasarkan siri PPYOLO
Sumber terbuka GitHub 130+Bintang: mengajar anda langkah demi langkah untuk menghasilkan semula algoritma pengesanan sasaran berdasarkan siri PPYOLO

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-09 18:41:101279semak imbas
Pengesanan objek ialah tugas asas dalam bidang penglihatan komputer Bagaimana kita boleh melakukannya tanpa Zoo Model yang baik?
Hari ini saya akan memberikan anda model algoritma pengesanan sasaran yang ringkas dan mudah digunakan. Ia kini telah memperoleh 130+ bintang di GitHub
Pautan kod: https://github.com/miemie2013/miemiedetection
miemiedetection ialah perpustakaan pengesanan peribadi yang dibangunkan berdasarkan YOLOX Ia juga menyokong PPYOLO, PPYOLOv2, PPYOLOE, FCOS dan algoritma lain.
Terima kasih kepada seni bina YOLOX yang sangat baik, kelajuan latihan algoritma dalam pengesanan miemi adalah sangat pantas, dan pembacaan data bukan lagi kesesakan kelajuan latihan.
Rangka kerja pembelajaran mendalam yang digunakan dalam pembangunan kod ialah pyTorch, yang melaksanakan konvolusi boleh ubah bentuk DCNv2, Matrix NMS dan pengendali sukar lain, dan menyokong kad tunggal mesin tunggal, kad berbilang mesin tunggal dan mod latihan berbilang mesin berbilang kad (sistem Linux disyorkan untuk mod latihan berbilang kad), menyokong sistem Windows dan Linux.
Dan kerana miemiedetection ialah perpustakaan pengesanan yang tidak memerlukan pemasangan, pengguna boleh terus menukar kodnya untuk menukar logik pelaksanaan, jadi ia juga mudah untuk menambah algoritma baharu pada perpustakaan.
Pengarang menyatakan bahawa lebih banyak sokongan algoritma (dan pakaian wanita) akan ditambah pada masa hadapan.

Algoritma dijamin tulen
Model pembiakan, perkara yang paling penting ialah kadar ketepatan pada asasnya haruslah sama seperti yang asal.
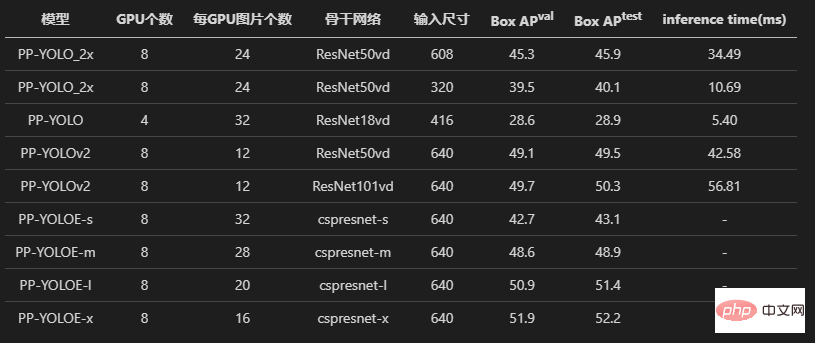
Mula-mula kita lihat tiga model PPYOLO, PPYOLOv2 dan PPYOLOE. Semua pengarang telah menjalani percubaan pada penjajaran kehilangan dan penjajaran kecerunan.
Untuk mengekalkan bukti, anda juga boleh melihat bahagian membaca dan menulis *.npz yang diulas dalam kod sumber, yang tertinggal daripada kod penjajaran.
Dan penulis juga merekodkan proses penjajaran prestasi secara terperinci Bagi orang baru, mengikuti laluan ini juga merupakan proses pembelajaran yang baik!
Semua log latihan juga direkodkan dan disimpan di dalam gudang, yang cukup untuk membuktikan ketepatan penghasilan semula siri algoritma PPYOLO!
Keputusan latihan akhir menunjukkan bahawa algoritma PPYOLO yang dihasilkan semula mempunyai kehilangan yang sama dan kecerunan yang sama seperti gudang asal.
Selain itu, penulis juga cuba menggunakan set data warehouse dan miemiedetection transfer learning voc2012 pembelajaran asal, dan juga memperoleh ketepatan yang sama (menggunakan hyperparameter yang sama).
Sama seperti pelaksanaan asal, menggunakan kadar pembelajaran yang sama, strategi pereputan kadar pembelajaran yang sama warm_piecewisedecay (digunakan oleh PPYOLO dan PPYOLOv2) dan warm_cosinedecay (digunakan oleh PPYOLOE), dan eksponen yang sama EMA purata bergerak , kaedah prapemprosesan data yang sama, parameter yang sama L2 pengecilan berat, kehilangan yang sama, kecerunan yang sama, model pra-latihan yang sama, pembelajaran pemindahan telah memperoleh ketepatan yang sama.
Kami telah melakukan percubaan yang mencukupi dan melakukan banyak ujian untuk memastikan semua orang mempunyai pengalaman yang menarik!
No 998, no 98, cuma klik bintang dan bawa pulang semua algoritma pengesanan sasaran secara percuma!
Muat turun dan penukaran model
Jika anda ingin menjalankan model, parameter adalah sangat penting boleh dimuat turun terus melalui Baidu Netdisk .
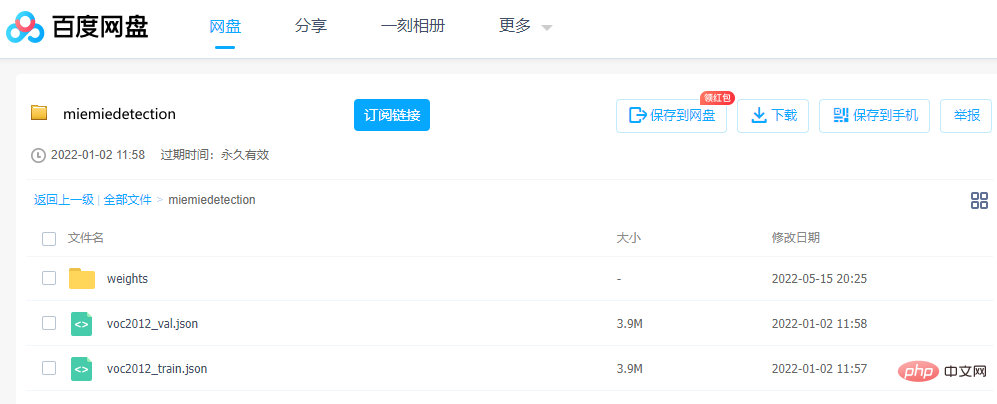
Pautan: https://pan.baidu.com/s/1ehEqnNYKb9Nz0XNeqAcwDw
Kod pengekstrakan: qe3i
Atau ikuti langkah di bawah untuk mendapatkannya:
Langkah pertama ialah memuat turun fail berat dan laksanakannya dalam direktori akar projek (iaitu muat turun fail, pengguna Windows boleh menggunakan Thunder atau pelayar untuk memuat turun wget) Pautan, di sini untuk tujuan pembentangan, hanya ppyoloe_crn_l_300e_coco digunakan sebagai contoh):

Perhatikan bahawa model dengan perkataan pralatihan adalah pra-latihan pada rangkaian ImageNet Backbone, PPYOLO, PPYOLOv2, PPYOLOE memuatkan pemberat ini untuk melatih set data COCO. Selebihnya adalah model terlatih pada COCO.
Langkah kedua ialah menukar pemberat dan melaksanakannya dalam direktori akar projek:

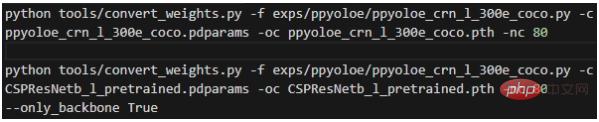
Maksud setiap parameter ialah:
- -f mewakili fail konfigurasi yang digunakan
- -c mewakili fail berat sumber baca; 🎜>- -nc mewakili bilangan kategori dalam set data;
- --only_backbone Apabila Benar, ini bermakna hanya menukar berat rangkaian tulang belakang ;
Selepas pelaksanaan, fail *.pth weight yang ditukar akan diperolehi dalam direktori akar projek.
Tutorial langkah demi langkah
Dalam arahan berikut, kebanyakan mereka akan menggunakan fail konfigurasi model, jadi perlu menjelaskan fail konfigurasi secara terperinci pada permulaannya.
mmdet.exp.base_exp.BaseExp ialah kelas asas fail konfigurasi Ia adalah kelas abstrak yang mengisytiharkan sekumpulan kaedah abstrak, seperti get_model() yang menunjukkan cara mendapatkan model. , dan get_data_loader() menunjukkan cara mendapatkan model Cara mendapatkan pemuat data terlatih, get_optimizer() menunjukkan cara mendapatkan pengoptimum, dsb.
mmdet.exp.datasets.coco_base.COCOBaseExp ialah konfigurasi set data dan mewarisi BaseExp Ia hanya memberikan konfigurasi set data. Gudang ini hanya menyokong latihan set data dalam format anotasi COCO!
Set data dalam format anotasi lain perlu ditukar kepada format anotasi COCO sebelum latihan (jika terlalu banyak format anotasi disokong, beban kerja akan menjadi terlalu besar). Set data tersuai boleh ditukar kepada format label COCO melalui miemieLabels. Semua kelas konfigurasi algoritma pengesanan akan mewarisi COCOBaseExp, yang bermaksud bahawa semua algoritma pengesanan berkongsi konfigurasi set data yang sama.
Item konfigurasi COCOBaseExp ialah:
Antaranya,
 - self.num_classes mewakili bilangan kategori dalam set data;
- self.num_classes mewakili bilangan kategori dalam set data;
- self.cls_names mewakili laluan fail nama kategori bagi set data Ia ialah fail txt, dan satu baris mewakili nama kategori. Jika ia adalah set data tersuai, anda perlu mencipta fail txt baharu dan mengedit nama kategori, dan kemudian mengubah suai self.cls_names untuk menunjuk kepadanya; fail anotasi set data Direktori akar perlu terletak dalam direktori self.data_dir
- self.train_ann mewakili nama fail anotasi set latihan set data; dan perlu ditempatkan dalam direktori self.ann_folder;
- self.val_ann mewakili nama fail anotasi set pengesahan set data, yang perlu ditempatkan dalam diri Direktori .ann_folder;
- diri. train_image_folder mewakili nama folder imej set latihan set data, yang perlu diletakkan dalam direktori self.data_dir; 🎜>- self.val_image_folder mewakili fail imej set pengesahan set data Nama folder perlu diletakkan dalam direktori self.data_dir; Untuk set data VOC 2012, anda perlu mengubah suai konfigurasi set data kepada:
Selain itu, anda juga boleh mengubah suai konfigurasi self.num_classes dan self.data_dir dalam subkelas seperti dalam exps/ppyoloe/ppyoloe_crn_l_voc2012.py, supaya konfigurasi COCOBaseExp akan ditulis ganti (tidak sah).
Selepas memuat turun model yang dinyatakan sebelum ini, buat anotasi folder baharu2 dalam direktori self.data_dir set data VOC2012 dan letakkan voc2012_train.json dan voc2012_val.json ke dalam folder fail ini.
Akhir sekali, lokasi penempatan set data COCO, set data VOC2012, dan projek ini sepatutnya seperti ini:
Direktori akar set data dan induk miemiedetection ialah direktori tahap yang sama. Saya secara peribadi tidak mengesyorkan meletakkan set data dalam miemiedetection-master, jika tidak PyCharm akan menjadi besar apabila dibuka lebih-lebih lagi, apabila beberapa projek (seperti mmdetection, PaddleDetection, AdelaiDet) berkongsi set data, anda boleh menetapkan laluan set data dan projek The; nama tidak penting.
mmdet.exp.ppyolo.ppyolo_method_base.PPYOLO_Method_Exp ialah kelas yang melaksanakan semua kaedah abstrak algoritma tertentu Ia mewarisi COCOBaseExp, yang melaksanakan semua kaedah abstrak. 
exp.ppyolo.ppyolo_r50vd_2x.Exp ialah kelas konfigurasi terakhir model Resnet50Vd bagi algoritma PPYOLO, mewarisi PPYOLO_Method_Exp; fail Ia juga merupakan struktur yang serupa.
Ramalan
Pertama, jika data input ialah gambar, laksanakannya dalam direktori punca projek:

Maksud setiap parameter ialah:
- -f mewakili fail konfigurasi yang digunakan
- -c mewakili berat baca; fail;
- --path mewakili laluan imej; daripada ambang ini akan dilukis;
- --tsize mewakili resolusi mengubah saiz imej kepada --tsize semasa ramalan; ramalan selesai, konsol akan mencetak laluan penjimatan imej hasil, yang boleh dibuka dan dilihat oleh pengguna. Jika anda menggunakan model yang disimpan dalam set data tersuai latihan untuk ramalan, cuma ubah suai -c ke laluan model anda.
Jika ramalan adalah semua gambar dalam folder, laksanakannya dalam direktori akar projek:
Tukar --laluan ke laluan folder imej yang sepadan.
Latih set data COCO2017
Satu arahan memulakan latihan lapan kad mesin tunggal Sudah tentu, premisnya ialah anda benar-benar mempunyai superkomputer lapan kad mesin tunggal.
Maksud setiap parameter ialah: 
-f mewakili fail konfigurasi yang digunakan; >-d mewakili bilangan kad grafik;
-b mewakili saiz kelompok semasa latihan (untuk semua kad); mewakili saiz kelompok semasa penilaian (untuk semua kad); latihan ketepatan;
--num_machines, bilangan mesin, disyorkan untuk berlatih dengan berbilang kad pada satu mesin; - resume menunjukkan sama ada untuk menyambung semula latihan;
Melatih set data tersuai
Adalah disyorkan untuk membaca pemberat pra-latihan COCO untuk latihan, kerana penumpuan adalah pantas.Ambil set data VOC2012 di atas sebagai contoh Untuk model ppyolo_r50vd, jika ia adalah 1 mesin dan 1 kad, masukkan arahan berikut untuk memulakan latihan:
Jika latihan terganggu atas sebab tertentu dan anda ingin membaca model yang disimpan sebelum ini untuk menyambung semula latihan, cuma ubah suai -c ke laluan yang anda ingin baca model , dan tambah parameter --resume Can.
Jika terdapat 2 mesin dan 2 kad, iaitu 1 kad pada setiap mesin, masukkan arahan berikut pada mesin 0:
dan masukkan arahan berikut pada mesin No. 1:
Cuma tukar 192.168.0.107 di atas 2 arahan kepada 0 IP LAN mesin sudah mencukupi.
Jika ia adalah 1 mesin dan 2 kad, masukkan arahan berikut untuk memulakan latihan:

Pindahkan set data pembelajaran VOC2012, AP yang diukur (0.50:0.95) ppyolo_r50vd_2x boleh mencapai 0.59+, AP (0.50) boleh mencapai 0.82+, dan AP (kecil) boleh mencapai 0.18+. Tidak kira sama ada ia satu kad atau berbilang kad, keputusan ini boleh diperolehi.
Semasa pembelajaran pemindahan, ia mencapai ketepatan dan kelajuan penumpuan yang sama seperti PaddleDetection Log latihan kedua-duanya terletak dalam folder train_ppyolo_in_voc2012.

Jika ia adalah model ppyoloe_l, masukkan arahan berikut pada satu mesin untuk memulakan latihan (rangkaian tulang belakang dibekukan)

Pindahkan set data pembelajaran VOC2012, AP yang diukur (0.50:0.95) ppyoloe_l boleh mencapai 0.66+, AP (0.50) boleh mencapai 0.85+, dan AP (kecil) boleh mencapai 0.28+.
Nilai perintahdan parameter khusus seperti berikut.

Hasil berjalan dalam direktori akar projek ialah:
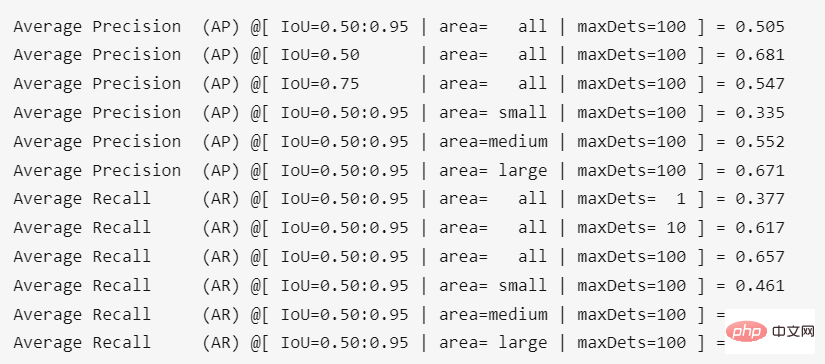
Ketepatan selepas menukar berat adalah Sedikit kerugian, kira-kira 0.4%.
Atas ialah kandungan terperinci Sumber terbuka GitHub 130+Bintang: mengajar anda langkah demi langkah untuk menghasilkan semula algoritma pengesanan sasaran berdasarkan siri PPYOLO. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI