
Rumah >Peranti teknologi >AI >Meituan menduduki tempat pertama dalam senarai kecil contoh pembelajaran FewCLUE! Pembelajaran Pantas+latihan kendiri
Meituan menduduki tempat pertama dalam senarai kecil contoh pembelajaran FewCLUE! Pembelajaran Pantas+latihan kendiri

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-09 17:41:101362semak imbas
Pengarang: Luo Ying, Xu Jun, Xie Rui, dll.
1 Gambaran Keseluruhan
CLUE(Penilaian Pemahaman Bahasa Cina)[ 1] ialah senarai penilaian berwibawa untuk pemahaman bahasa Cina, yang meliputi banyak analisis semantik dan subtugasan pemahaman semantik seperti klasifikasi teks, hubungan antara ayat dan pemahaman bacaan Ia telah memberi kesan yang besar kepada kedua-dua akademik dan industri.

Rajah 1 Senarai FewCLUE (sehingga 2022-04-18)
FewCLUE [2,3] ialah subsenarai dalam CLUE khusus untuk penilaian pembelajaran sampel kecil bahasa Cina Ia bertujuan untuk menggabungkan keupayaan generalisasi universal dan berkuasa model bahasa pra-latihan untuk meneroka model pembelajaran sampel kecil yang terbaik. dan aplikasinya dalam amalan Cina pada. Beberapa set data FewCLUE hanya mempunyai lebih daripada seratus sampel berlabel, yang boleh mengukur prestasi generalisasi model di bawah sampel berlabel yang sangat sedikit Selepas dikeluarkan, ia menarik perhatian NetEase, WeChat AI, Alibaba, Institut Penyelidikan IDEA dan Penyelidikan Kecerdasan Buatan Inspur Institut dan banyak perusahaan dan institut penyelidikan lain mengambil bahagian. Tidak lama dahulu, model pembelajaran sampel kecil FSL++ Pasukan Pemahaman Semantik Pusat NLP bagi Carian Platform Meituan dan Jabatan NLP memenangi tempat pertama dalam senarai FewCLUE dengan prestasi unggulnya, mencapai tahap SOTA.
2 Pengenalan Kaedah
Walaupun model pra-latihan berskala besar telah mencapai keputusan yang sangat baik dalam pelbagai tugas utama, mereka masih memerlukan banyak data berlabel untuk tugasan tertentu . Pelbagai perniagaan Meituan mempunyai banyak senario NLP, yang selalunya memerlukan kos pelabelan manual yang tinggi. Pada peringkat awal pembangunan perniagaan atau apabila perniagaan baharu perlu dilancarkan dengan cepat, selalunya sampel berlabel tidak mencukupi Menggunakan Pralatihan tradisional (Pra-latihan) + Penalaan Halus (Halus-. penalaan) Kaedah latihan pembelajaran mendalam sering gagal memenuhi keperluan indeks yang ideal, jadi menjadi sangat perlu untuk mengkaji masalah latihan model dalam senario sampel kecil.
Artikel ini mencadangkan satu set model besar + sampel kecil skim latihan bersama FSL++, yang menggabungkan pengoptimuman struktur model, pra-latihan berskala besar, peningkatan sampel, pembelajaran ensemble dan latihan kendiri dan strategi pengoptimuman model lain, dan akhirnya mencapai keputusan cemerlang pada senarai FewCLUE di bawah penanda aras penilaian berwibawa bagi pemahaman bahasa Cina, dan prestasinya melebihi tahap manusia pada beberapa tugas, manakala pada beberapa tugasan (seperti CLUEWSC) masih ada ruang darjah tertentu untuk penambahbaikan.
Selepas keluaran FewCLUE, NetEase Fuxi menggunakan model EET yang dibangunkan sendiri [4], dan meningkatkan pemahaman semantik model melalui latihan menengah, dan kemudian menambah templat. Pembelajaran berbilang tugasan Model Erlangshen Institut Penyelidikan IDEA [5] menggunakan teknologi pra-latihan yang lebih maju untuk melatih model besar berdasarkan model BERT, dan menggunakan Masked dengan strategi Topeng dinamik dalam proses penalaan halus tugas hiliran (MLM) sebagai tugas tambahan. Kaedah ini semuanya menggunakan Pembelajaran Pantas sebagai struktur tugas asas Berbanding dengan model besar yang dibangunkan sendiri ini, kaedah kami terutamanya menambah strategi pengoptimuman model seperti peningkatan sampel, pembelajaran ensemble dan pembelajaran kendiri berdasarkan rangka kerja Pembelajaran Segera, yang sangat bertambah baik. Meningkatkan prestasi tugas dan keteguhan model Pada masa yang sama, kaedah ini boleh digunakan untuk pelbagai model pra-latihan, menjadikannya lebih fleksibel dan mudah.
Struktur model keseluruhan FSL++ ditunjukkan dalam Rajah 2 di bawah. Set data FewCLUE menyediakan 160 data berlabel dan hampir 20,000 data tidak berlabel untuk setiap tugas. Dalam amalan FewCLUE ini, kami mula-mula membina Pembelajaran Segera berbilang templat dalam peringkat Fine-Tune, dan menggunakan strategi peningkatan seperti latihan lawan, pembelajaran kontrastif dan Mixup untuk data berlabel. Memandangkan strategi peningkatan data ini menggunakan prinsip peningkatan yang berbeza, ia boleh dianggap bahawa perbezaan antara model ini agak ketara dan akan mendapat hasil yang lebih baik selepas pembelajaran bersepadu. Oleh itu, selepas menggunakan strategi peningkatan data untuk latihan, kami mempunyai berbilang model yang diselia dengan lemah, dan menggunakan model yang diselia dengan lemah ini untuk meramalkan data tidak berlabel untuk mendapatkan pengedaran pseudo-label data tidak berlabel. Selepas itu, kami menyepadukan berbilang pengedaran pseudo-label bagi data tidak berlabel yang diramalkan oleh model peningkatan data yang berbeza untuk mendapatkan jumlah pengedaran pseudo-label bagi data tidak berlabel, kemudian membina semula Pembelajaran Prompt berbilang templat dan menggunakan data sekali lagi Tingkatkan strategi dan pilih strategi optimum. Pada masa ini, percubaan kami hanya melakukan satu lelaran, dan kami juga boleh mencuba berbilang lelaran Walau bagaimanapun, apabila bilangan lelaran bertambah, peningkatan tidak akan kelihatan lagi.

Rajah 2 Rangka kerja model FSL++
2.1 Pra-latihan yang dipertingkatkan
Model bahasa pra-latihan dilatih pada korpus besar yang tidak berlabel. Contohnya, RoBERTa[6] dilatih mengenai lebih daripada 160GB teks, termasuk ensiklopedia, artikel berita, karya sastera dan kandungan web. Perwakilan yang dipelajari oleh model ini mencapai prestasi cemerlang pada tugas yang melibatkan set data pelbagai saiz daripada pelbagai sumber.
Model FSL++ menggunakan model besar RoBERTa sebagai model asas, dan mengamalkan Pralatihan Penyesuaian Domain (DAPT) yang menggabungkan pengetahuan domain.[ 7]Kaedah pralatihan dan Pralatihan Penyesuaian Tugasan (TAPT)[7] yang menggabungkan pengetahuan tugasan. DAPT menyasarkan untuk menambah sejumlah besar teks tidak berlabel dalam medan untuk meneruskan latihan model bahasa berdasarkan model pra-latihan, dan kemudian memperhalusinya pada set data tugasan yang ditentukan.
Melanjutkan latihan pra pada domain teks sasaran boleh meningkatkan prestasi model bahasa, terutamanya pada tugas hiliran yang berkaitan dengan domain teks sasaran. Lebih-lebih lagi, lebih tinggi korelasi antara teks pra-latihan dan domain tugas, lebih besar peningkatan. Dalam amalan ini, kami akhirnya menggunakan RoBERTa Large, yang telah dilatih terlebih dahulu mengenai 100G CLUE Vocab[8] yang mengandungi korpus dari pelbagai bidang seperti program hiburan, sukan, kesihatan, hal ehwal antarabangsa, filem, selebriti, dll. Model. TAPT merujuk kepada menambah sejumlah kecil korpus tidak berlabel yang berkaitan secara langsung dengan tugas berdasarkan model pra-latihan untuk pra-latihan. Untuk tugas TAPT, data pra-latihan yang kami pilih untuk digunakan ialah data tidak berlabel yang disediakan oleh senarai FewCLUE untuk setiap tugas.
Selain itu, dalam amalan tugas perhubungan antara ayat, seperti tugas inferens bahasa asli Cina OCNLI dan tugas pemadanan teks pendek dialog Cina BUSTM, kami menggunakan antara ayat lain perhubungan Untuk tugasan seperti set data inferens bahasa asli Cina CMNLI dan set data persamaan teks pendek Cina LCQMC, parameter model yang telah dilatih pada set data persamaan teks pendek Cina LCQMC digunakan sebagai parameter awal Berbanding dengan secara langsung menggunakan asal model untuk menyelesaikan tugas, ia juga boleh meningkatkan kesan ke tahap tertentu.
2.2 Struktur Model
FewCLUE mengandungi pelbagai bentuk tugasan dan kami telah memilih struktur model yang sesuai untuk setiap tugasan. Kata kategori tugas pengelasan teks dan kefahaman bacaan mesin (MRC) tugasan itu sendiri membawa maklumat, jadi ia lebih sesuai untuk dimodelkan dalam bentuk Model Bahasa Bertopeng (MLM); dan hubungan antara ayat Tugas menilai perkaitan dua ayat adalah lebih mirip dengan Borang Tugasan Prediksi Ayat Seterusnya(NSP)[9]. Oleh itu, kami memilih model PET[10] untuk tugasan pengelasan dan tugas pemahaman bacaan, dan model EFL[11] untuk tugasan perhubungan antara ayat boleh bina sampel negatif melalui pensampelan global, pelajari pengelas yang lebih mantap.
2.2.1 Pembelajaran Pantas
Matlamat utama Pembelajaran Pantas adalah untuk meminimumkan jurang antara sasaran pra-latihan dan sasaran penalaan halus hiliran. Biasanya tugas pra-latihan sedia ada termasuk fungsi kehilangan MLM, tetapi tugas hiliran tidak menggunakan MLM, tetapi memperkenalkan pengelas baharu, menyebabkan ketidakkonsistenan antara tugas pra-latihan dan tugas hiliran. Pembelajaran Prompt tidak memperkenalkan pengelas tambahan atau parameter lain, tetapi menggunakan templat penyambungan (Templat, yang menggabungkan serpihan bahasa untuk data input, sekali gus mengubah tugasan menjadi bentuk MLM ) dan pemetaan perkataan tag (Verbalizer , iaitu, mencari perkataan yang sepadan dalam perbendaharaan kata untuk setiap label, dengan itu menetapkan sasaran ramalan untuk tugasan MLM ), supaya model itu boleh digunakan dalam tugasan hiliran dengan bilangan sampel yang kecil.
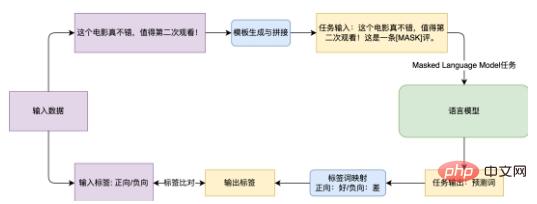
 Rajah 3 Carta Aliran kaedah Pembelajaran Pantas untuk menyelesaikan tugasan analisis sentimen
Rajah 3 Carta Aliran kaedah Pembelajaran Pantas untuk menyelesaikan tugasan analisis sentimen
Ambil tugas analisis sentimen penilaian e-dagang EPRSTMT yang ditunjukkan dalam Rajah 3 sebagai contoh. Memandangkan teks "Filem ini benar-benar bagus dan berbaloi untuk ditonton kali kedua!", klasifikasi teks tradisional adalah untuk menyambungkan pengelas kepada Pembenaman dalam bahagian CLS dan memetakannya kepada klasifikasi 0-1 (0: negatif , 1: Ke hadapan ). Kaedah ini memerlukan latihan pengelas baharu dalam senario sampel kecil, dan sukar untuk mencapai hasil yang baik. Kaedah berdasarkan Pembelajaran Segera adalah untuk mencipta templat "Ini adalah ulasan [MASK] dan kemudian menyambung templat dengan teks asal Semasa latihan, model bahasa meramalkan perkataan pada kedudukan [MASK], dan kemudian memetakan ia kepada kategori yang sepadan (Baik: Positif, Buruk: Negatif).
Menentukan templat berprestasi terbaik dan pemetaan perkataan tag kadangkala sukar kerana kekurangan data yang mencukupi. Oleh itu, reka bentuk pemetaan perkataan berbilang templat dan berbilang label juga boleh diguna pakai. Dengan mereka bentuk berbilang templat, hasil akhir mengguna pakai penyepaduan hasil berbilang templat, atau mereka bentuk pemetaan perkataan satu-ke-banyak supaya satu teg sepadan dengan berbilang perkataan. Sama seperti contoh di atas, gabungan templat berikut boleh direka bentuk ( kiri: berbilang templat untuk ayat yang sama, kanan: pemetaan berbilang label ).

Rajah 4 PET berbilang templat dan pemetaan berbilang label
Sampel tugas

Jadual 1 Pembinaan templat PET dalam dataset FewCLUE
2.2.2 EFL
Model EFL menggabungkan dua ayat bersama-sama, menggunakan Pembenaman pada kedudukan [CLS] lapisan keluaran diikuti dengan pengelas untuk melengkapkan ramalan. Semasa proses latihan EFL, sebagai tambahan kepada sampel dalam set latihan, sampel negatif juga dibina Semasa proses latihan, ayat dalam data lain dipilih secara rawak sebagai sampel negatif dalam setiap kelompok, dan peningkatan data dilakukan dengan membina negatif. sampel. Walaupun model EFL perlu melatih pengelas baharu, pada masa ini terdapat banyak set data implikasi teks awam/antara ayat, seperti CMNLI, LCQMC, dsb., yang boleh dipelajari secara berterusan pada sampel ini (teruskan latihan ), kemudian pindahkan parameter yang dipelajari ke senario sampel kecil dan gunakan set data tugas FewCLUE untuk penalaan lebih lanjut.
Sampel tugas

 Jadual 2 Templat EFL dataset FewCLUE pembinaan
Jadual 2 Templat EFL dataset FewCLUE pembinaan
2.3 Penambahbaikan data
Kaedah peningkatan data terutamanya termasuk peningkatan sampel dan penambahbaikan Benam. Dalam bidang NLP, tujuan peningkatan data adalah untuk mengembangkan data teks tanpa mengubah semantik. Kaedah utama termasuk penggantian teks mudah, menggunakan model bahasa untuk menjana ayat yang serupa, dsb. Kami telah mencuba kaedah seperti EDA untuk mengembangkan data teks, tetapi perubahan dalam perkataan mungkin menyebabkan makna keseluruhan ayat terbalik dan digantikan. teks membawa banyak bunyi Jadi sukar untuk menjana data tambahan yang mencukupi dengan perubahan sampel peraturan mudah. Penambahbaikan benam, bagaimanapun, tidak lagi beroperasi pada input, tetapi beroperasi pada tahap Benam Kekukuhan model boleh dipertingkatkan dengan menambahkan gangguan atau interpolasi pada Benam.
Oleh itu, dalam amalan ini kami terutamanya menjalankan peningkatan Embedding. Strategi peningkatan data yang kami gunakan termasuk Mixup[12], Manifold-Mixup[13] dan latihan lawan (Latihan lawan, AT) [ 14] dan pembelajaran kontrastif R-drop[15].
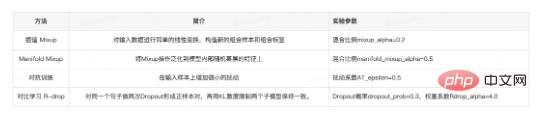
 Jadual 3 Penerangan ringkas tentang strategi peningkatan data
Jadual 3 Penerangan ringkas tentang strategi peningkatan data
Campuran membina sampel gabungan baharu dan label gabungan dengan melakukan transformasi linear ringkas pada data input, yang boleh meningkatkan Keupayaan generalisasi model. Pada pelbagai tugasan diselia atau separa penyeliaan, menggunakan Mixup boleh meningkatkan keupayaan generalisasi model. Kaedah Mixup boleh dianggap sebagai operasi regularisasi, yang memerlukan ciri gabungan yang dijana oleh model pada tahap ciri memenuhi kekangan linear, dan menggunakan kekangan ini untuk mengatur model. Secara intuitif, apabila input model adalah gabungan linear dua input yang lain, outputnya juga merupakan gabungan linear output yang diperolehi selepas kedua-dua data dimasukkan ke dalam model secara berasingan, model itu dikehendaki kira-kira sistem linear.
Campuran Manifold menyamaratakan operasi Campuran di atas kepada ciri. Oleh kerana ciri mempunyai maklumat semantik yang lebih tinggi, interpolasi merentas dimensinya mungkin menghasilkan sampel yang lebih bermakna. Dalam model yang serupa dengan BERT[9] dan RoBERTa[6], bilangan lapisan k dipilih secara rawak dan interpolasi Campuran dilakukan pada perwakilan ciri lapisan ini. Interpolasi Mixup biasa berlaku dalam bahagian Embedding lapisan output, dan Manifold Mixup adalah bersamaan dengan menambah siri operasi interpolasi ini kepada lapisan rawak struktur Transformers dalam model bahasa.
Latihan lawan meningkatkan kehilangan model dengan ketara dengan menambahkan gangguan kecil pada sampel input. Latihan adversarial adalah untuk melatih model yang boleh mengenal pasti sampel asal dan sampel lawan dengan berkesan. Prinsip asas adalah untuk membina beberapa sampel musuh dengan menambah gangguan dan memberikannya kepada model untuk latihan, dengan itu meningkatkan keteguhan model apabila menghadapi sampel musuh, dan pada masa yang sama meningkatkan prestasi dan keupayaan generalisasi model. Contoh lawan perlu mempunyai dua ciri iaitu:
- Berbanding dengan input asal, gangguan tambahan adalah minimum.
- boleh membuat model melakukan kesilapan. Latihan adversarial mempunyai dua fungsi, iaitu meningkatkan keteguhan model terhadap serangan berniat jahat dan meningkatkan keupayaan generalisasi model.
R-Drop melakukan Dropout dua kali untuk ayat yang sama dan memaksa kebarangkalian keluaran submodel berbeza yang dijana oleh Dropout untuk kekal konsisten. Walaupun pengenalan Keciciran berfungsi dengan baik, ia akan membawa kepada masalah ketidakkonsistenan dalam proses latihan dan inferens. Untuk mengurangkan ketidakkonsistenan proses inferens latihan ini, R-Drop menyelaraskan Keciciran, menambah sekatan ke atas pengedaran data output dalam output yang dijana oleh dua sub-model, dan memperkenalkan kehilangan perbezaan KL bagi ukuran pengedaran data, supaya dalam kelompok Dua pengagihan data yang dijana oleh sampel yang sama hendaklah sedekat mungkin dan mempunyai ketekalan pengedaran. Khususnya, untuk setiap sampel latihan, R-Drop meminimumkan perbezaan KL antara kebarangkalian keluaran sub-model yang dijana oleh Keciciran yang berbeza. Sebagai idea latihan, R-Drop boleh digunakan dalam kebanyakan latihan diselia atau separuh diselia dan sangat serba boleh.
Tiga strategi peningkatan data yang kami gunakan, Mixup adalah untuk membuat perubahan linear dalam dua sampel dalam lapisan keluaran Pembenaman model bahasa dan lapisan keluaran lapisan rawak Transformer di dalam model bahasa. , Latihan adversarial adalah untuk menambah gangguan kecil kepada sampel, manakala pembelajaran kontras adalah untuk melakukan Dropout dua kali pada ayat yang sama untuk membentuk pasangan sampel yang positif, dan kemudian menggunakan perbezaan KL untuk mengehadkan kedua-dua sub-model supaya konsisten. Ketiga-tiga strategi meningkatkan generalisasi model dengan melengkapkan beberapa operasi dalam Embedding Model yang diperoleh melalui strategi yang berbeza mempunyai keutamaan yang berbeza, yang menyediakan syarat untuk langkah seterusnya pembelajaran ensemble.
2.4 Pembelajaran Ensembel & Latihan Kendiri
Pembelajaran ensemble boleh menggabungkan berbilang model yang diselia dengan lemah untuk mendapatkan model yang diselia kuat dengan lebih baik dan komprehensif. Idea asas pembelajaran ensemble ialah walaupun pengelas lemah membuat ramalan yang salah, pengelas lemah lain boleh membetulkan ralat. Sekiranya perbezaan antara model yang akan digabungkan adalah ketara, maka pembelajaran ensemble biasanya akan menghasilkan hasil yang lebih baik.
Latihan kendiri menggunakan sejumlah kecil data berlabel dan sejumlah besar data tidak berlabel untuk melatih model secara bersama, mula-mula menggunakan pengelas terlatih untuk meramalkan label semua data tidak berlabel dan kemudian memilih keyakinan Label dengan darjah yang lebih tinggi digunakan sebagai data pseudo-label, dan data berlabel pseudo digabungkan dengan data latihan berlabel secara manual untuk melatih semula pengelas.
Pembelajaran ensemble + latihan kendiri ialah penyelesaian yang boleh menggunakan berbilang model dan data tidak berlabel. Antaranya, langkah-langkah umum pembelajaran ensembel ialah: melatih pelbagai model yang diselia dengan lemah yang berbeza, menggunakan setiap model untuk meramalkan taburan kebarangkalian label bagi data tidak berlabel, mengira jumlah wajaran taburan kebarangkalian label, dan mendapatkan taburan kebarangkalian label pseudo untuk tidak berlabel. data. Latihan kendiri merujuk kepada melatih model untuk menggabungkan model lain Langkah-langkah umum ialah: melatih beberapa model Guru, model Pelajar mempelajari Ramalan Lembut sampel berkeyakinan tinggi dalam taburan kebarangkalian pseudo-label, dan model Pelajar berfungsi sebagai pembelajar kuat akhir.
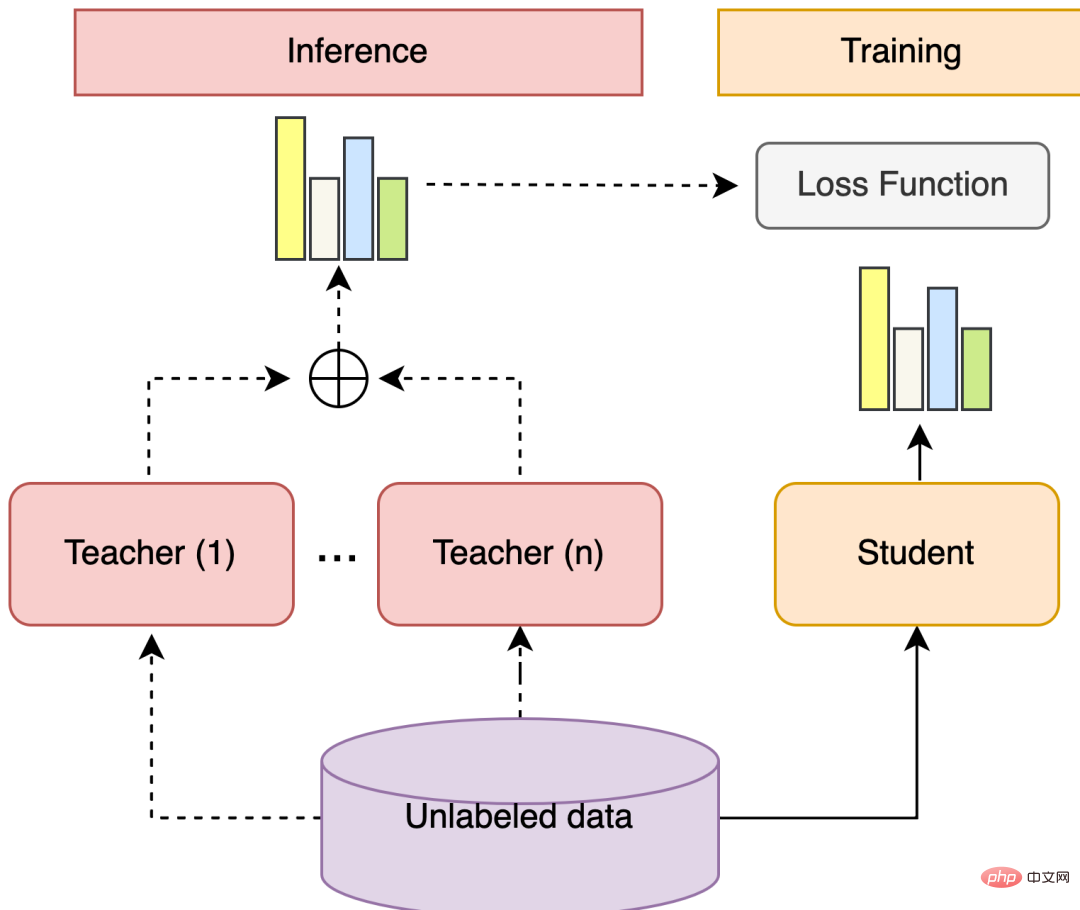
 Rajah 5 Pembelajaran bersepadu + struktur latihan kendiri
Rajah 5 Pembelajaran bersepadu + struktur latihan kendiri
Dalam amalan FewCLUE ini, kami mula-mula membina Pembelajaran Segera berbilang templat dalam peringkat Penalaan Halus, dan menggunakan strategi peningkatan seperti latihan lawan, pembelajaran kontrastif dan Campuran pada data berlabel. Memandangkan strategi peningkatan data ini menggunakan prinsip peningkatan yang berbeza, ia boleh dianggap bahawa perbezaan antara model ini agak ketara dan akan mendapat hasil yang lebih baik selepas pembelajaran bersepadu.
Selepas menggunakan strategi penambahan data untuk latihan, kami mempunyai berbilang model yang diselia dengan lemah dan menggunakan model yang diselia dengan lemah ini untuk meramalkan data tidak berlabel untuk mendapatkan pengedaran Label pseudo-tidak berlabel. Selepas itu, kami menyepadukan berbilang pengedaran pseudo-label data tidak berlabel yang diramalkan oleh model penambahan data yang berbeza untuk mendapatkan jumlah pengedaran pseudo-label data tidak berlabel. Dalam proses saringan data pseudo-label, kita tidak semestinya akan memilih sampel yang mempunyai keyakinan tertinggi, kerana jika keyakinan yang diberikan oleh setiap model penambahan data adalah sangat tinggi, bermakna sampel ini mungkin sampel yang mudah dipelajari. dan mungkin tidak semestinya mempunyai nilai yang besar.
Kami menggabungkan keyakinan yang diberikan oleh berbilang model peningkatan data dan cuba memilih sampel dengan keyakinan yang lebih tinggi tetapi tidak mudah dipelajari (Sebagai contoh, berbilang model tidak meramalkan semua Konsisten). Kemudian Pembelajaran Prompt berbilang templat dibina semula menggunakan set data berlabel dan data berlabel pseudo, strategi penambahan data digunakan semula, dan strategi terbaik dipilih. Pada masa ini, percubaan kami pada masa ini hanya menjalankan satu lelaran, dan kami juga boleh mencuba berbilang lelaran Walau bagaimanapun, apabila bilangan lelaran meningkat, peningkatan akan berkurangan dan tidak lagi ketara.
3 Hasil eksperimen
3.1 Pengenalan set data
Senarai FewCLUE menyediakan 9 tugasan, di mana 4 adalah tugas pengelasan teks, 2 1 antara ayat tugas perhubungan dan 3 tugasan kefahaman bacaan. Tugas klasifikasi teks termasuk analisis sentimen penilaian e-dagang, klasifikasi dokumen saintifik, klasifikasi berita dan tugas klasifikasi topik perihalan aplikasi. Ia terutamanya dikelaskan kepada dua klasifikasi teks pendek, pelbagai klasifikasi teks pendek dan pelbagai klasifikasi teks panjang. Sesetengah tugas mempunyai banyak kategori, lebih daripada 100 kategori, dan terdapat masalah ketidakseimbangan kategori. Tugas perhubungan antara ayat termasuk penaakulan bahasa semula jadi dan tugas pemadanan teks pendek. Tugas pemahaman bacaan termasuk pemahaman bacaan simpulan bahasa, isian kosong terpilih, pertimbangan ringkasan, pengenalpastian kata kunci dan tugas nyahkekaburan kata ganti nama. Setiap tugas menyediakan kira-kira 160 keping data berlabel dan kira-kira 20,000 keping data tidak berlabel. Oleh kerana tugas pengelasan teks panjang mempunyai banyak kategori dan terlalu sukar, ia juga menyediakan lebih banyak data berlabel. Data tugasan terperinci ditunjukkan dalam Jadual 4:

Jadual 4 FewCLUE pengenalan tugas set data
3.2 Perbandingan Eksperimen
Jadual 5 menunjukkan perbandingan keputusan percubaan dengan model dan amaun parameter yang berbeza. Dalam percubaan RoBERTa Base, menggunakan model PET/EFL akan melebihi hasil model Fine-Tune langsung tradisional sebanyak 2-28PP. Berdasarkan model PET/EFL, untuk meneroka kesan model besar dalam senario sampel kecil, kami menjalankan eksperimen pada RoBERTa Large Berbanding dengan RoBERTa Base, model besar boleh meningkatkan model sebanyak 0.5-13PP untuk menggunakan pengetahuan domain dengan lebih baik, kami terus menjalankan eksperimen pada model Petunjuk Besar RoBERTa yang telah dilatih terlebih dahulu pada set data CLUE, dan model besar yang menggabungkan pengetahuan domain meningkatkan lagi keputusan sebanyak 0.1-9pp. Berdasarkan ini, dalam eksperimen seterusnya, kami akan menjalankan eksperimen pada Petunjuk Besar RoBERTa.

Jadual 5 Perbandingan keputusan eksperimen dengan model dan jumlah parameter yang berbeza (fon merah tebal menunjukkan hasil terbaik)
Jadual 6 menunjukkan hasil eksperimen peningkatan data dan pembelajaran bersepadu pada model PET/EFL Ia boleh didapati bahawa walaupun strategi peningkatan data digunakan pada model besar, model itu boleh membawa peningkatan 0.8-9PP, dan pembelajaran bersepadu selanjutnya. & latihan kendiri Pada masa hadapan, prestasi model akan terus meningkat sebanyak 0.4-4PP.

Jadual 6 Model asas + peningkatan data + hasil eksperimen pembelajaran ensembel (fon merah tebal menunjukkan hasil terbaik)
Dalam langkah pembelajaran bersepadu + latihan kendiri, kami mencuba beberapa strategi saringan:
- Pilih sampel dengan keyakinan tertinggi Strategi ini membawa Penambahbaikan adalah dalam 1PP. Kebanyakan sampel pseudo-label dengan keyakinan tertinggi adalah sampel yang mempunyai ramalan yang konsisten daripada pelbagai model dan mempunyai keyakinan yang agak tinggi. Bahagian sampel ini agak mudah dipelajari, dan faedah menyepadukan bahagian sampel ini adalah terhad.
- Pilih sampel dengan keyakinan tinggi dan kontroversi (Terdapat sekurang-kurangnya satu model yang tidak konsisten dengan keputusan ramalan model lain, tetapi keyakinan keseluruhan daripada berbilang model Melebihi ambang 1), strategi ini mengelakkan sampel yang amat mudah dipelajari dan mengelak daripada membawa masuk terlalu banyak data kotor dengan menetapkan ambang, yang boleh membawa peningkatan 0- 3PP;
- Mengintegrasikan dua strategi di atas, jika keputusan ramalan berbilang model adalah konsisten untuk sampel, kami memilih sampel dengan tahap keyakinan kurang daripada ambang 2; sekurang-kurangnya satu model yang tidak konsisten dengan keputusan ramalan model lain, kami memilih sampel dengan keyakinan lebih besar daripada ambang 3. Kaedah ini secara serentak memilih sampel dengan keyakinan yang lebih tinggi untuk memastikan kredibiliti output, dan memilih sampel yang lebih kontroversial untuk memastikan sampel pseudo-label yang dipilih mempunyai kesukaran pembelajaran yang lebih besar, yang boleh membawa peningkatan 0.4-4PP.
4 Aplikasi strategi pembelajaran sampel kecil dalam senario Meituan
Dalam pelbagai perniagaan Meituan, terdapat senario NLP yang kaya, dan beberapa tugas boleh diklasifikasikan. kategori ialah tugas klasifikasi teks dan tugas perhubungan antara ayat Strategi pembelajaran sampel kecil yang dinyatakan di atas telah digunakan untuk pelbagai senario Meituan Dianping. Ia dijangka melatih model yang lebih baik apabila sumber data adalah terhad. Selain itu, strategi pembelajaran sampel kecil telah digunakan secara meluas dalam pelbagai keupayaan algoritma NLP bagi platform pemprosesan bahasa semula jadi dalaman Meituan (NLP) Ia telah dilaksanakan dalam banyak senario perniagaan dan mencapai manfaat yang ketara kepada jurutera dalaman Meituan boleh Gunakan platform ini untuk mengalami keupayaan yang berkaitan dengan pusat NLP.
Tugas pengelasan teks
Klasifikasi tema kecantikan perubatan: pada Meituan dan Dianping Kandungan daripada nota dibahagikan kepada 8 kategori mengikut subjek: memburu rasa ingin tahu, penerokaan kedai, penilaian, kes kehidupan sebenar, proses rawatan, mengelakkan perangkap, perbandingan kesan dan sains popular. Apabila pengguna mengklik pada topik tertentu, kandungan nota yang sepadan dikembalikan, dan perkongsian pengalaman dikongsi pada halaman ensiklopedia dan halaman rancangan saluran kecantikan perubatan Meituan dan Dianping App Ketepatan pembelajaran sampel kecil menggunakan 2,989 data latihan meningkat sebanyak 1.8PP, mencecah 89.24 %.
Pengenalpastian strategi : Strategi perjalanan perlombongan daripada UGC dan nota, menyediakan bekalan kandungan strategi perjalanan, digunakan pada modul strategi di bawah carian tempat yang indah, kandungan ingat semula adalah Untuk nota yang menerangkan strategi perjalanan, pembelajaran sampel kecil menggunakan 384 keping data latihan untuk meningkatkan ketepatan sebanyak 2PP, mencapai 87%.
Klasifikasi teks Xuecheng: Xuecheng (Pangkalan pengetahuan dalaman Meituan) mempunyai sejumlah besar teks pengguna Selepas induksi, teks dibahagikan ke Untuk 17 kategori, model sedia ada telah dilatih pada 700 keping data Melalui pembelajaran sampel kecil, ketepatan model telah dipertingkatkan sebanyak 2.5PP pada model sedia ada, mencapai 84%.
Penapisan projek: Halaman senarai penilaian semasa LE Life Services/Beauty dan perniagaan lain mempunyai susunan penilaian yang bercampur-campur yang menyusahkan pengguna untuk mencari maklumat membuat keputusan dengan cepat, jadi lebih banyak lagi tag klasifikasi berstruktur diperlukan Untuk memenuhi keperluan pengguna, ketepatan pembelajaran sampel kecil menggunakan 300-500 keping data dalam kedua-dua perniagaan ini telah mencapai 95%+ ( Berbilang set data telah meningkat masing-masing sebanyak 1.5-4PP<.>).
Tugas perhubungan antara ayat
Pelabelan keberkesanan kecantikan perubatan: Nota Meituan dan Dianping kandungan dipanggil semula mengikut keberkesanan Jenis-jenis keberkesanan termasuk: penghidratan, pemutihan, pelangsingan muka, penyingkiran kedutan, dan lain-lain. Terdapat 110 jenis keberkesanan yang perlu ditandakan. Hanya 2909 data latihan digunakan untuk pembelajaran sampel kecil. Kadar ketepatan mencapai 91.88% ( meningkat sebanyak 2.8PP).
Penjenamaan kecantikan perubatan: Syarikat huluan jenama mempunyai permintaan untuk promosi jenama dan pemasaran produk mereka, dan pemasaran kandungan ialah kaedah pemasaran arus perdana dan berkesan. Penandaan jenama adalah untuk mengingat semula nota yang memperincikan jenama untuk setiap jenama seperti "Eropah" dan "Shuweike". Terdapat 103 jenama secara keseluruhan, yang telah berada dalam talian di Dewan Jenama Kecantikan Perubatan Hanya 1,676 item latihan diperlukan untuk sampel kecil pembelajaran. Kadar ketepatan data mencapai 88.59% ( meningkat sebanyak 2.9PP).
5 Ringkasan
Dalam penyerahan senarai ini, kami membina model pemahaman semantik berdasarkan RoBERTa dan mempertingkatkan Latihan ramalan, model PET/EFL , penambahan data dan pembelajaran ensembel & latihan kendiri untuk meningkatkan prestasi model. Model ini boleh melengkapkan klasifikasi teks, tugas penaakulan hubungan antara ayat dan beberapa tugasan pemahaman bacaan.
Dengan mengambil bahagian dalam tugas penilaian ini, kami mempunyai pemahaman yang lebih mendalam tentang algoritma dan penyelidikan dalam bidang pemahaman bahasa semula jadi dalam senario sampel kecil, dan juga mempunyai pemahaman yang lebih baik tentang pelaksanaan bahasa Cina keupayaan algoritma canggih Satu ujian menyeluruh telah dijalankan untuk meletakkan asas bagi penyelidikan algoritma dan pelaksanaan algoritma selanjutnya. Selain itu, senario tugasan dalam set data ini sangat serupa dengan senario perniagaan Meituan Search dan Jabatan NLP Banyak strategi model ini juga digunakan secara langsung dalam perniagaan sebenar dan memperkasakan perniagaan secara langsung.
6 Pengarang artikel ini
Luo Ying, Xu Jun, Xie Rui dan Wu Wei semuanya dari Meituan Search dan Jabatan NLP /Pusat NLP.
Atas ialah kandungan terperinci Meituan menduduki tempat pertama dalam senarai kecil contoh pembelajaran FewCLUE! Pembelajaran Pantas+latihan kendiri. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI