
Rumah >Peranti teknologi >AI >Bina model pembelajaran mesin dengan PySpark ML
Bina model pembelajaran mesin dengan PySpark ML

- PHPzke hadapan
- 2023-04-09 13:51:081246semak imbas
Spark ialah rangka kerja sumber terbuka yang direka untuk pertanyaan interaktif, pembelajaran mesin dan beban kerja masa nyata, dan PySpark ialah perpustakaan untuk Python menggunakan Spark.
PySpark ialah bahasa yang sangat baik untuk melaksanakan analisis data penerokaan pada skala, membina saluran pembelajaran mesin dan mencipta ETL untuk platform data. Jika anda sudah biasa dengan perpustakaan seperti Python dan Pandas, PySpark ialah bahasa yang bagus untuk dipelajari dan membuat analisis dan saluran paip yang lebih berskala.
Tujuan artikel ini adalah untuk menunjukkan cara membina model pembelajaran mesin menggunakan PySpark.
Conda mencipta persekitaran maya ular sawa
conda menguruskan hampir semua alatan dan pakej pihak ketiga sebagai pakej, malah ular sawa dan conda sendiri. Anaconda ialah koleksi berpakej, yang diprapasang dengan conda, versi python tertentu, pelbagai pakej, dsb.
1.
Buka baris arahan dan masukkan conda -V untuk menyemak sama ada ia dipasang dan versi conda semasa.
Pasang versi lalai Python melalui Anaconda 3.6 sepadan dengan Anaconda3-5.2, dan 5.3 dan lebih baru ialah python 3.7.
(https://repo.anaconda.com/archive/)
2.Arahan conda yang biasa digunakan
1) Semak pakej yang dipasang
conda list
2) Semak persekitaran maya yang wujud pada masa ini
conda env list <br>conda info -e
3) Semak dan kemas kini konda semasa
conda update conda
3 Python mencipta persekitaran maya
conda create -n your_env_name python=x.xanaconda mencipta persekitaran maya dengan python versi x.x dan namakan nama_env_anda. Fail your_env_name boleh didapati di bawah fail envs dalam direktori pemasangan Anaconda. 4. Aktifkan atau tukar persekitaran maya Buka baris arahan dan masukkan python --version untuk menyemak versi python semasa.
Linux:source activate your_env_nam<br>Windows: activate your_env_name5. Pasang pakej tambahan dalam persekitaran maya
conda install -n your_env_name [package]6. Persekitaran PATH Versi python lalai)
7 Padamkan persekitaran maya
deactivate env_name<br># 或者`activate root`切回root环境<br>Linux下:source deactivate
8 Padamkan pakej tertentu jam persekitaran
conda remove -n your_env_name --all
9. Tetapkan domestik Pelayan cermin
conda remove --name $your_env_name$package_namehttp://Anaconda.org berada di luar negara Apabila memasang berbilang pakej, kelajuan muat turun conda selalunya sangat perlahan. Sumber cermin Tsinghua TUNA mempunyai cermin gudang Anaconda, cuma tambahkannya pada konfigurasi conda:
10 Pulihkan cermin lalai
# 添加Anaconda的TUNA镜像<br>conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/<br><br># 设置搜索时显示通道地址<br>conda config --set show_channel_urls yes
Pasang PySpark
<.> Proses pemasangan PySpark semudah pakej python lain (seperti Pandas, Numpy, scikit-learn).conda config --remove-key channels
Satu perkara penting ialah pastikan java dipasang pada mesin anda terlebih dahulu. Anda kemudiannya boleh menjalankan PySpark pada buku nota jupyter anda.
Meneroka data Kami menggunakan set data diabetes, yang dikaitkan dengan Institut Kebangsaan Diabetes dan Penyakit Pencernaan dan Penyakit Diabetes. Matlamat klasifikasi adalah untuk meramalkan sama ada pesakit menghidap diabetes (ya/tidak).
Kami menggunakan set data diabetes, yang dikaitkan dengan Institut Kebangsaan Diabetes dan Penyakit Pencernaan dan Penyakit Diabetes. Matlamat klasifikasi adalah untuk meramalkan sama ada pesakit menghidap diabetes (ya/tidak).
from pyspark.sql import SparkSession<br>spark = SparkSession.builder.appName('ml-diabetes').getOrCreate()<br>df = spark.read.csv('diabetes.csv', header = True, inferSchema = True)<br>df.printSchema()Kehamilan: Bilangan kehamilanGlukosa: Kepekatan glukosa darah dalam ujian toleransi glukosa oral dalam masa 2 jam- Tekanan Darah: Tekanan darah diastolik (mm Hg)
- Ketebalan Kulit: ketebalan lipatan kulit trisep (mm)
- Insulin: insulin serum 2 jam (mu U/ml)
- BMI: indeks jisim badan (berat dalam kg/(tinggi) dalam m) )²)
- fungsi diabespedigree: fungsi spektrum diabetes
- Umur: umur (tahun)
- Hasil: pembolehubah kelas (0 atau 1)
- Pembolehubah input: Glukosa, tekanan darah, BMI, umur, kehamilan, insulin, ketebalan kulit, fungsi spektrum diabetes.
- Pembolehubah output: hasil.
- Lihat lima pemerhatian pertama. Bingkai data Pandas lebih cantik daripada Spark DataFrame.show().
import pandas as pd<br>pd.DataFrame(df.take(5), <br> columns=df.columns).transpose()
df.toPandas()Semak sama ada kelas itu seimbang sepenuhnya!

df.groupby('Outcome').count().toPandas()Statistik deskriptif
numeric_features = [t[0] for t in df.dtypes if t[1] == 'int']<br>df.select(numeric_features)<br>.describe()<br>.toPandas()<br>.transpose()
from pandas.plotting import scatter_matrix<br>numeric_data = df.select(numeric_features).toPandas()<br><br>axs = scatter_matrix(numeric_data, figsize=(8, 8));<br><br># Rotate axis labels and remove axis ticks<br>n = len(numeric_data.columns)<br>for i in range(n):<br>v = axs[i, 0]<br>v.yaxis.label.set_rotation(0)<br>v.yaxis.label.set_ha('right')<br>v.set_yticks(())<br>h = axs[n-1, i]<br>h.xaxis.label.set_rotation(90)<br>h.set_xticks(())Penyediaan Data dan Kejuruteraan Ciri Dalam bahagian ini, kami akan mengalih keluar lajur yang tidak diperlukan dan mengisi nilai yang tiada. Akhir sekali, ciri dipilih untuk model pembelajaran mesin. Fungsi ini akan dibahagikan kepada dua bahagian: latihan dan ujian.
Dalam bahagian ini, kami akan mengalih keluar lajur yang tidak diperlukan dan mengisi nilai yang tiada. Akhir sekali, ciri dipilih untuk model pembelajaran mesin. Fungsi ini akan dibahagikan kepada dua bahagian: latihan dan ujian.
Pengendalian Data Hilang
Set data ini bagus, tiada nilai yang hilang.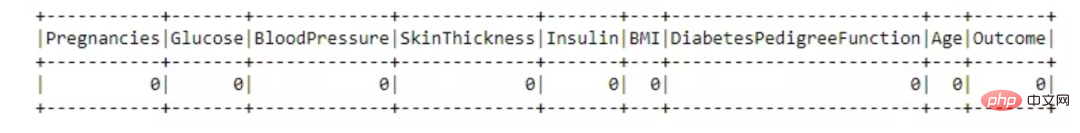
不必要的列丢弃
dataset = dataset.drop('SkinThickness')<br>dataset = dataset.drop('Insulin')<br>dataset = dataset.drop('DiabetesPedigreeFunction')<br>dataset = dataset.drop('Pregnancies')<br><br>dataset.show()

特征转换为向量
VectorAssembler —— 将多列合并为向量列的特征转换器。
# 用VectorAssembler合并所有特性<br>required_features = ['Glucose',<br>'BloodPressure',<br>'BMI',<br>'Age']<br><br>from pyspark.ml.feature import VectorAssembler<br><br>assembler = VectorAssembler(<br>inputCols=required_features, <br>outputCol='features')<br><br>transformed_data = assembler.transform(dataset)<br>transformed_data.show()
现在特征转换为向量已完成。
训练和测试拆分
将数据随机分成训练集和测试集,并设置可重复性的种子。
(training_data, test_data) = transformed_data.randomSplit([0.8,0.2], seed =2020)<br>print("训练数据集总数: " + str(training_data.count()))<br>print("测试数据集总数: " + str(test_data.count()))
训练数据集总数:620<br>测试数据集数量:148
机器学习模型构建
随机森林分类器
随机森林是一种监督学习算法,用于分类和回归。但是,它主要用于分类问题。众所周知,森林是由树木组成的,树木越多,森林越茂盛。类似地,随机森林算法在数据样本上创建决策树,然后从每个样本中获取预测,最后通过投票选择最佳解决方案。这是一种比单个决策树更好的集成方法,因为它通过对结果进行平均来减少过拟合。
from pyspark.ml.classification import RandomForestClassifier<br><br>rf = RandomForestClassifier(labelCol='Outcome', <br>featuresCol='features',<br>maxDepth=5)<br>model = rf.fit(training_data)<br>rf_predictions = model.transform(test_data)
评估随机森林分类器模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', metricName = 'accuracy')<br>print('Random Forest classifier Accuracy:', multi_evaluator.evaluate(rf_predictions))
Random Forest classifier Accuracy:0.79452
决策树分类器
决策树被广泛使用,因为它们易于解释、处理分类特征、扩展到多类分类设置、不需要特征缩放,并且能够捕获非线性和特征交互。
from pyspark.ml.classification import DecisionTreeClassifier<br><br>dt = DecisionTreeClassifier(featuresCol = 'features',<br>labelCol = 'Outcome',<br>maxDepth = 3)<br>dtModel = dt.fit(training_data)<br>dt_predictions = dtModel.transform(test_data)<br>dt_predictions.select('Glucose', 'BloodPressure', <br>'BMI', 'Age', 'Outcome').show(10)
评估决策树模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', <br>metricName = 'accuracy')<br>print('Decision Tree Accuracy:', <br>multi_evaluator.evaluate(dt_predictions))
Decision Tree Accuracy: 0.78767
逻辑回归模型
逻辑回归是在因变量是二分(二元)时进行的适当回归分析。与所有回归分析一样,逻辑回归是一种预测分析。逻辑回归用于描述数据并解释一个因二元变量与一个或多个名义、序数、区间或比率水平自变量之间的关系。当因变量(目标)是分类时,使用逻辑回归。
from pyspark.ml.classification import LogisticRegression<br><br>lr = LogisticRegression(featuresCol = 'features', <br>labelCol = 'Outcome', <br>maxIter=10)<br>lrModel = lr.fit(training_data)<br>lr_predictions = lrModel.transform(test_data)
评估我们的逻辑回归模型。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Logistic Regression Accuracy:', <br>multi_evaluator.evaluate(lr_predictions))
Logistic Regression Accuracy:0.78767
梯度提升树分类器模型
梯度提升是一种用于回归和分类问题的机器学习技术,它以弱预测模型(通常是决策树)的集合形式生成预测模型。
from pyspark.ml.classification import GBTClassifier<br>gb = GBTClassifier(<br>labelCol = 'Outcome', <br>featuresCol = 'features')<br>gbModel = gb.fit(training_data)<br>gb_predictions = gbModel.transform(test_data)
评估我们的梯度提升树分类器。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Gradient-boosted Trees Accuracy:',<br>multi_evaluator.evaluate(gb_predictions))
Gradient-boosted Trees Accuracy:0.80137
结论
PySpark 是一种非常适合数据科学家学习的语言,因为它支持可扩展的分析和 ML 管道。如果您已经熟悉 Python 和 Pandas,那么您的大部分知识都可以应用于 Spark。总而言之,我们已经学习了如何使用 PySpark 构建机器学习应用程序。我们尝试了三种算法,梯度提升在我们的数据集上表现最好。
Atas ialah kandungan terperinci Bina model pembelajaran mesin dengan PySpark ML. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI