
Rumah >Peranti teknologi >AI >Daripada Model VAE kepada Diffusion: Artikel yang menerangkan paradigma baharu penggunaan teks untuk menjana gambar rajah
Daripada Model VAE kepada Diffusion: Artikel yang menerangkan paradigma baharu penggunaan teks untuk menjana gambar rajah

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-08 20:41:071461semak imbas
1 Kata Pengantar
Lima belas bulan selepas keluaran DALL·E, OpenAI membawakan sekuel DALL·E 2 pada musim bunga ini, yang dengan cepat menduduki pasaran dengan kesan yang lebih menakjubkan dan kebolehmainan yang kaya daripada AI utama masyarakat. Dalam beberapa tahun kebelakangan ini, dengan kemunculan Generative Adversarial Networks (GAN), Variational Autoencoders (VAE), dan model Diffusion, pembelajaran mendalam telah menunjukkan keupayaan penjanaan imejnya yang hebat kepada dunia bersama-sama dengan GPT-3, BERT Menunggu kejayaan Model NLP, manusia secara beransur-ansur memecahkan sempadan maklumat antara teks dan imej.
DALL·E 2, hanya masukkan teks ringkas (prompt), dan ia boleh menjana berbilang imej definisi tinggi 1024*1024. Imej ini juga boleh menyatakan semantik yang tidak konvensional untuk mencipta kesan visual imaginatif dalam bentuk surealistik, seperti "Angkasawan menunggang kuda dalam gaya fotorealistik" dalam Rajah 1.
 Rajah 1. DALL·E 2 generasi contoh
Rajah 1. DALL·E 2 generasi contoh
Artikel ini akan memberikan penjelasan yang mendalam tentang cara paradigma baharu seperti DALL·E boleh mencipta banyak imej yang menakjubkan melalui teks. Artikel tersebut merangkumi banyak pengetahuan latar belakang dan Pengenalan teknologi asas juga sesuai untuk pembaca yang baru dalam bidang penjanaan imej.
2 Penjanaan imej
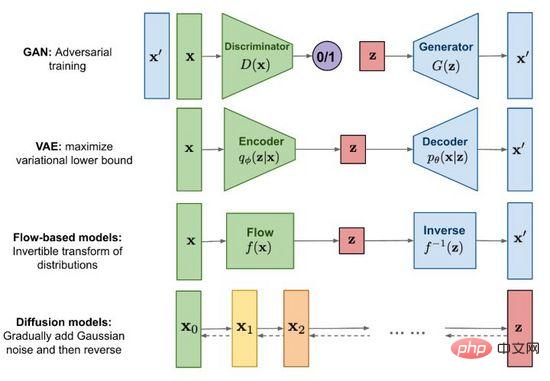
Rajah 2. Kaedah penjanaan imej arus perdana
Sejak kelahiran Generative Adversarial Networks (GAN) pada 2014, imej Penyelidikan generatif telah menjadi topik sempadan yang penting dalam pembelajaran mendalam malah seluruh bidang kecerdasan buatan Pada peringkat ini, pembangunan teknologi telah mencapai tahap di mana palsu boleh dikelirukan dengan yang sebenar. Selain Generative Adversarial Network (GAN) yang terkenal, kaedah arus perdana juga termasuk pengekod auto variasi (VAE) dan model berasaskan aliran (Model berasaskan aliran), serta model resapan (Model resapan) yang telah menarik perhatian ramai baru-baru ini. . Dengan bantuan Rajah 2, kami meneroka ciri dan perbezaan setiap kaedah.
2.1 Generative Adversarial Network (GAN)
Nama penuh GAN ialah G bertenaga A dversarial N etworks, tidak sukar untuk membaca dari nama bahawa "Adversarial" adalah intipati kejayaannya. Idea konfrontasi diilhamkan oleh teori permainan Semasa melatih penjana (Generator), latih seorang diskriminator (Diskriminator) untuk menilai sama ada input adalah imej sebenar atau imej yang dihasilkan permainan minimax dan menjadi lebih kuat, seperti formula (1). Apabila imej yang mencukupi untuk "menipu" dihasilkan daripada hingar rawak, kami percaya bahawa taburan data imej sebenar dipasang dengan baik, dan sejumlah besar imej realistik boleh dijana melalui pensampelan.
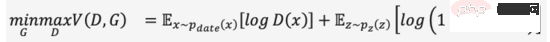
GAN ialah teknologi yang paling banyak digunakan dalam model generatif dan bersinar dalam banyak senario sintesis data seperti imej, video, pertuturan dan NLP. Selain menjana kandungan secara langsung daripada hingar rawak, kami juga boleh menambah syarat (seperti label pengelasan) sebagai input kepada penjana dan diskriminator, supaya hasil yang dijana mematuhi atribut input bersyarat dan kandungan yang dijana boleh dikawal. Walaupun GAN mempunyai kesan yang luar biasa, disebabkan kewujudan mekanisme permainan, kestabilan latihannya adalah lemah dan terdedah kepada keruntuhan mod Bagaimana untuk menjadikan model mencapai titik keseimbangan permainan dengan lancar juga menjadi topik penyelidikan yang hangat di GAN.
2.2 Pengekod Auto Variasi (VAE)
Pengekod Auto Variasi ialah varian pengekod auto Autopengekod tradisional direka bentuk tanpa pengawasan Cara melatih rangkaian saraf adalah dengan memampatkan input asal ke dalam satu. perwakilan perantaraan dan memulihkannya kepada dua proses yang pertama menukar input berdimensi tinggi asal kepada pengekodan lapisan tersembunyi berdimensi rendah melalui pengekod (Pengekod), dan yang terakhir melalui penyahkod (Dekoder ) untuk membina semula data daripada pengekodan. Tidak sukar untuk melihat bahawa matlamat pengekod auto adalah untuk mempelajari fungsi identiti Kita boleh menggunakan entropi silang (Cross-entropy) atau ralat min kuasa dua (Mean Square Error) untuk membina kerugian pembinaan semula untuk mengukur perbezaan antara. input dan output. Seperti yang ditunjukkan dalam Rajah 3, semasa proses di atas kami memperoleh pengekodan lapisan tersembunyi berdimensi rendah, yang menangkap atribut potensi data asal dan boleh digunakan untuk pemampatan data dan perwakilan ciri.
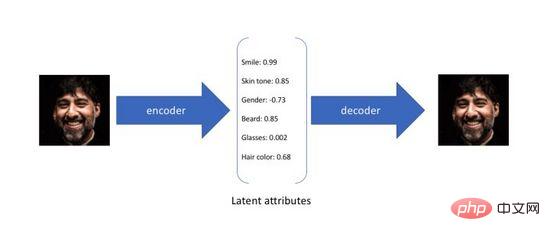
Rajah 3. Pengekodan atribut terpendam bagi pengekod automatik
Oleh kerana pengekod auto hanya menumpukan pada keupayaan pembinaan semula pengekodan lapisan tersembunyi, pengedaran ruang lapisan tersembunyinya selalunya Ia adalah tidak teratur dan tidak sekata. Persampelan rawak atau interpolasi dalam ruang lapisan tersembunyi berterusan untuk mendapatkan set kod biasanya menghasilkan hasil penjanaan yang tidak bermakna dan tidak boleh ditafsirkan. Untuk membina ruang lapisan tersembunyi biasa supaya kami boleh mencuba secara rawak dan menginterpolasi atribut berpotensi berbeza secara rawak, dan akhirnya menghasilkan imej yang bermakna melalui penyahkod, penyelidik mencadangkan pengekod auto variasi pada 2014.
Pengekod auto variasi tidak lagi memetakan input ke dalam pengekodan tetap dalam ruang lapisan tersembunyi, tetapi menukarnya kepada anggaran pengedaran kebarangkalian ruang lapisan tersembunyi Untuk kemudahan ekspresi, kami menganggap bahawa pengedaran terdahulu ialah Gaussian standard pengedaran. Begitu juga, kami melatih model penyahkod kebarangkalian untuk memetakan daripada pengedaran ruang lapisan tersembunyi kepada pengedaran data sebenar. Apabila diberi input, kami menganggarkan parameter taburan (min dan kovarians model Gaussian multivariate) melalui taburan posterior, dan sampel daripada taburan ini Kita boleh menggunakan teknik penyusunan semula untuk menjadikan pensampelan boleh dibezakan (sebagai pembolehubah rawak). , dan akhirnya pengedaran tentang adalah output melalui penyahkod kebarangkalian, seperti yang ditunjukkan dalam Rajah 4. Untuk menjadikan imej yang dijana sebagai realistik yang mungkin, kita perlu menyelesaikan pengedaran posterior, dengan matlamat untuk memaksimumkan kemungkinan log imej sebenar.
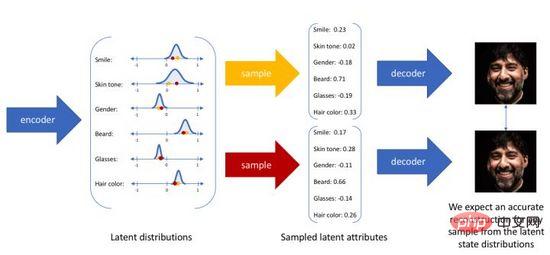
Rajah 4. Proses penjanaan sampel autopengekod variasi
Malangnya, taburan posterior sebenar mengandungi pasangan pasangan mengikut model Bayesian pada ruang selanjar tidak dapat diselesaikan secara langsung. Untuk menyelesaikan masalah di atas, pengekod auto variasi menggunakan kaedah inferens variasi, memperkenalkan pengekod kebarangkalian yang boleh dipelajari untuk menganggarkan taburan posterior sebenar, menggunakan perbezaan KL untuk mengukur perbezaan antara dua taburan, dan menyelesaikan masalah ini daripada Taburan posterior sebenar diterjemahkan kepada cara mengurangkan jarak antara dua taburan.
Kami meninggalkan proses terbitan perantaraan dan mengembangkan persamaan di atas untuk mendapatkan persamaan (2),
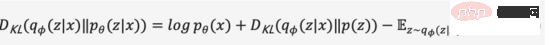
Oleh kerana perbezaan KL adalah bukan negatif, kita boleh tukar maksimum kami Objektif diubah menjadi persamaan (3),
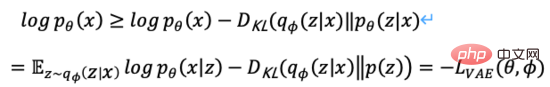
Secara ringkasnya, kami mentakrifkan pengekod kebarangkalian dan penyahkod kebarangkalian sebagai fungsi kehilangan model, dan negatifnya bentuk dipanggil Evidence Lower Bound (Evidence Lower Bound), memaksimumkan bukti lower bound adalah bersamaan dengan memaksimumkan matlamat. Proses variasi di atas adalah idea teras VAE dan pelbagai variasinya Melalui penaakulan variasi, masalah diubah menjadi bukti yang lebih rendah yang memaksimumkan penjanaan data sebenar.
2.3 Model berasaskan aliran
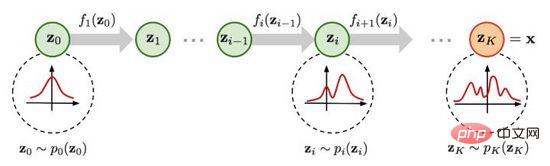
Rajah 5. Proses penjanaan berasaskan aliran
Rajah 5 Seperti yang ditunjukkan, diandaikan bahawa taburan data asal boleh diperolehi daripada taburan yang diketahui melalui satu siri fungsi transformasi boleh balik, iaitu. Melalui penentu matriks Jacob dan peraturan perubahan berubah, kita boleh menganggarkan secara langsung fungsi ketumpatan kebarangkalian data sebenar (formula (4)) dan memaksimumkan kemungkinan log yang boleh dikira.
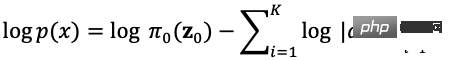
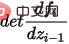 ialah penentu Yakub bagi fungsi transformasi, jadi sebagai tambahan kepada boleh terbalik, ia juga memerlukan penentu Yakubnya boleh dengan mudah dikira. Model penjanaan berasaskan aliran seperti Glow menggunakan lilitan boleh balik 1x1 untuk anggaran ketumpatan yang tepat dan mencapai hasil yang baik dalam penjanaan muka.
ialah penentu Yakub bagi fungsi transformasi, jadi sebagai tambahan kepada boleh terbalik, ia juga memerlukan penentu Yakubnya boleh dengan mudah dikira. Model penjanaan berasaskan aliran seperti Glow menggunakan lilitan boleh balik 1x1 untuk anggaran ketumpatan yang tepat dan mencapai hasil yang baik dalam penjanaan muka.
2.4 Model resapan

Rajah 6. Proses resapan dan songsang model resapan
Model resapan mentakrifkan arah hadapan Terdapat dua proses: proses ke hadapan atau proses resapan, iaitu untuk mengambil sampel daripada pengedaran data sebenar, secara beransur-ansur menambah hingar Gaussian kepada sampel, dan menghasilkan jujukan sampel hingar Proses penambahan hingar boleh dikawal oleh parameter varians masa, ia boleh menjadi lebih kurang setara dengan taburan Gaussian. Proses resapan ialah proses terkawal pratetap, dan proses penambahan hingar boleh dinyatakan sebagai persamaan (5) dengan pengagihan bersyarat,
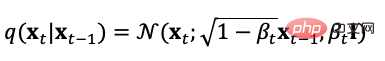
Daripada takrifan proses resapan, kami boleh lihat Gunakan formula di atas untuk pensampelan pada sebarang saiz langkah,
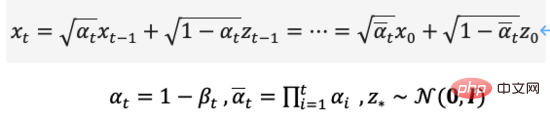
Begitu juga, kita juga boleh membalikkan proses resapan, sampel daripada hingar Gaussian dan mempelajari model untuk menganggarkan taburan kebarangkalian bersyarat benar , jadi proses songsang boleh ditakrifkan sebagai formula (7),
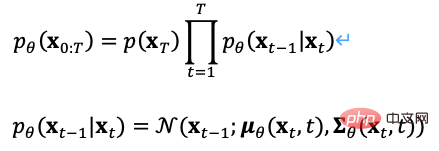
Terdapat banyak pilihan untuk objektif pengoptimuman model resapan Contohnya, semasa proses latihan, memandangkan ia boleh dikira terus daripada proses ke hadapan, kita boleh mengambil sampel daripada yang diramalkan pengedaran, dan proses pensampelan boleh ditambah Klasifikasi imej dan label teks digunakan sebagai input bersyarat, dan kerugian pembinaan semula dioptimumkan dengan ralat min kuasa dua yang minimum.
Dalam model kebarangkalian resapan denoising DDPM, penulis membina versi ringkas kehilangan model ramalan hingar (formula (8)) melalui teknologi penparameteran semula dan masukkan data bising pada saiz langkah 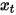 Latih model untuk meramalkan bunyi
Latih model untuk meramalkan bunyi 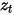 , gunakan
, gunakan
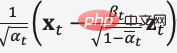
semasa inferens Ramalkan min taburan Gaussian bagi data ternyah 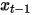 untuk mencapai denoised imej muka.
untuk mencapai denoised imej muka.
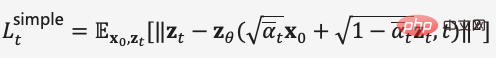
3 Pembelajaran perwakilan pelbagai mod
3.1 NLP pada Transformer
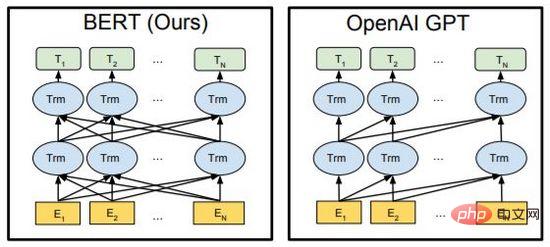
Rajah 7. BERT dan GPT
BERT dan GPT ialah model bahasa pra-latihan yang sangat berkuasa dalam bidang NLP dalam beberapa tahun kebelakangan ini, dan telah membuat penemuan besar dalam tugas hiliran seperti penjanaan artikel, penjanaan kod, terjemahan mesin, Soal Jawab, dsb. . Kedua-duanya menggunakan Transformer sebagai rangka kerja utama algoritma, dan butiran pelaksanaan sedikit berbeza (Rajah 7).
BERT pada asasnya ialah pengekod dua arah Ia menggunakan dua tugas, Model Bahasa Topeng (MLM) dan Prediksi Ayat Seterusnya (NSP), untuk mempelajari perwakilan ciri teks dengan cara yang diselia sendiri dan dipindahkan kepada yang lain dalam tugasan pembelajaran. Intipati GPT ialah penyahkod autoregresif Dengan menggunakan data besar-besaran dan model susun secara berterusan, ia memaksimumkan nilai kemungkinan model bahasa untuk meramalkan teks seterusnya. Yang penting, semasa proses latihan, teks pasca pesanan GPT bertopeng supaya ia tidak kelihatan apabila teks prapesanan dilatih dan diramalkan Dalam BERT, semua teks boleh dilihat antara satu sama lain dan mengambil bahagian dalam perhatian diri pengiraan BERT menggunakan topeng rawak atau input gantian Meningkatkan keteguhan model dan keupayaan ekspresif.
3.2 ViT (Vision Transformer)
Kejayaan besar Transformer dalam bidang NLP telah mencetuskan penyelidik berfikir tentang keupayaannya untuk menyatakan ciri imej. Tidak seperti NLP, maklumat imej adalah besar dan berlebihan Menggunakan pemodelan Transformer secara langsung akan menyebabkan model tidak dapat belajar kerana bilangan Token yang banyak. Sehingga 2020, penyelidik mencadangkan ViT, yang mengurangkan dimensi data imej melalui kaedah tampalan dan unjuran linear, dan menggunakan Pengekod Transformer sebagai pengekod imej kepada hasil ramalan klasifikasi output, mencapai hasil yang besar.
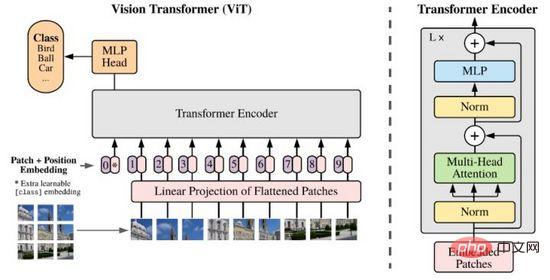
Rajah 8. ViT
Kini Transformer telah menjadi objek kajian baharu dalam bidang pemprosesan imej, sentiasa mencabar status CNN dengan potensinya yang hebat. .
3.3 CLIP
CLIP (Contrastive Language-Image Pretraining) ialah kaedah pembelajaran perbandingan yang dicadangkan oleh OpenAI untuk menghubungkan perwakilan ciri imej dan teks. Seperti yang ditunjukkan dalam Rajah 9, CLIP berjaya mengekod pasangan imej teks untuk menghasilkan pasangan Token melalui pengekodan Transformer, dan menggunakan operasi produk titik untuk mengukur persamaan Daripada ini, untuk setiap teks kami memperoleh kebarangkalian pengelasan satu panas untuk semua imej, dan sebaliknya sebaliknya untuk setiap imej kebarangkalian pengelasan untuk semua teks juga boleh diperolehi. Semasa proses latihan, kami mengoptimumkan kehilangan entropi silang yang dikira untuk setiap baris dan lajur matriks kebarangkalian dalam Rajah 9(1).
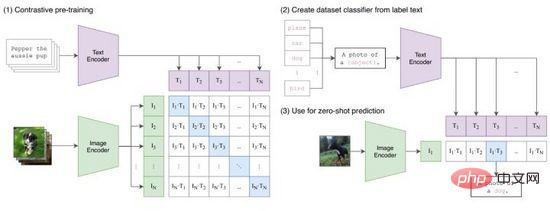
Rajah 9. KLIP
CLIP memetakan perwakilan ciri teks dan imej ke dalam ruang yang sama Walaupun ia tidak merealisasikan pemindahan maklumat merentas mod, ia sangat berkesan sebagai kaedah pemampatan ciri, pengukuran persamaan dan pembelajaran perwakilan silang. Secara intuitif, kami mengeluarkan token imej dengan ciri yang paling serupa antara semua gesaan teks yang dijana dalam julat label, iaitu, klasifikasi imej selesai (Rajah 9 (2)), terutamanya apabila pengedaran data imej dan label belum berada dalam set latihan Muncul sebelum ini, CLIP masih mempunyai keupayaan pembelajaran zero-shot.
4 Penjanaan imej silang mod
Selepas pengenalan dalam dua bab sebelum ini, kami telah menyemak secara sistematik teknologi asas yang berkaitan dengan penjanaan imej dan pembelajaran perwakilan pelbagai mod Bab ini akan memperkenalkan tiga kaedah penjanaan imej Cross-modal terkini, menerangkan cara ia boleh dimodelkan menggunakan teknik asas ini.
4.1 DALL·E
DALL·E telah dicadangkan oleh OpenAI pada awal tahun 2021 dan bertujuan untuk melatih penyahkod autoregresif daripada teks input kepada imej output. Daripada pengalaman CLIP yang berjaya, kami tahu bahawa ciri teks dan ciri imej boleh dikodkan dalam ruang ciri yang sama, jadi kami boleh menggunakan Transformer untuk memodelkan ciri teks dan imej secara autoregresif sebagai satu aliran data ("memodelkan teks dan imej secara autoregresif token sebagai satu aliran data"). aliran data").
Proses latihan DALL·E dibahagikan kepada dua peringkat Satu adalah untuk melatih pengekod auto variasi untuk pengekodan dan penyahkodan imej, dan satu lagi adalah untuk melatih penyahkod autoregresif bagi teks dan imej untuk meramalkan Token bagi. imej yang dihasilkan seperti yang ditunjukkan dalam Rajah 10.
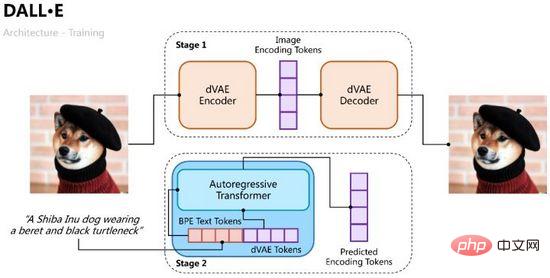
Rajah 10. Proses latihan DALL·E
Proses penaakulan adalah lebih intuitif Gunakan Transformer autoregresif untuk menyahkod token teks ke dalam imej secara beransur-ansur Dalam proses itu, kita boleh mencuba beberapa kumpulan sampel melalui kebarangkalian pengelasan, kemudian memasukkan berbilang kumpulan sampel Token ke dalam pengekodan auto variasi untuk menyahkod berbilang imej yang dijana, dan mengisih serta memilih yang terbaik melalui pengiraan persamaan CLIP, seperti yang ditunjukkan dalam Rajah 11 .
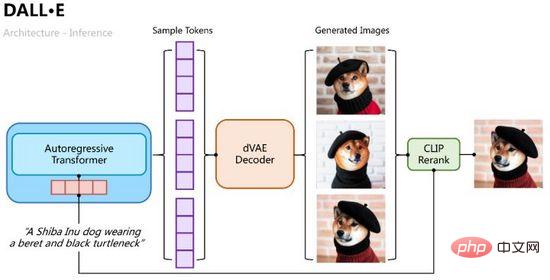
Rajah 11. Proses inferens DALL·E
Seperti VAE, kami menggunakan pengekod kemungkinan dan penyahkod kemungkinan untuk memodelkan ciri lapisan tersembunyi masing-masing taburan kebarangkalian posterior dan taburan kebarangkalian kebarangkalian bagi imej yang dijana dimodelkan menggunakan taburan kebarangkalian bersama teks dan imej yang diramalkan oleh Transformer sebagai priori (dimulakan kepada pengedaran seragam pada peringkat pertama Dengan cara yang sama, bukti sempadan bawah). daripada sasaran pengoptimuman boleh diperolehi ,
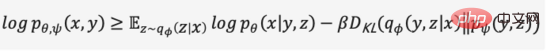
Dalam peringkat pertama latihan, DALL·E menggunakan pengekod auto variasi diskret (Discrete VAE) yang dirujuk sebagai dVAE, iaitu. Vector Quantized VAE (VQ -VAE) versi dinaik taraf. Dalam VAE, kami menggunakan taburan kebarangkalian untuk menerangkan ruang lapisan tersembunyi yang berterusan, dan mendapatkan kod lapisan tersembunyi melalui pensampelan rawak, tetapi kod ini tidak sedeterministik seperti aksara bahasa diskret. Untuk mempelajari "bahasa" ruang lapisan tersembunyi imej, VQ-VAE menggunakan set pengkuantitian vektor yang boleh dipelajari untuk mewakili ruang lapisan tersembunyi terkuantiti ini dipanggil Ruang Embedding atau Buku Kod/Perbendaharaan Kata. Proses latihan dan proses ramalan VQ-VAE bertujuan untuk mencari vektor lapisan tersembunyi yang paling hampir dengan vektor pengekodan imej, dan kemudian menyahkod bahasa vektor yang dipetakan ke dalam imej (Rajah 12 Fungsi kehilangan terdiri daripada tiga bahagian, masing-masing mengoptimumkan kehilangan pembinaan semula , kemas kini Ruang Benam dan kemas kini pengekod, dan kecerunan ditamatkan.
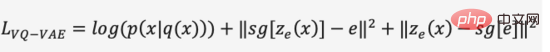
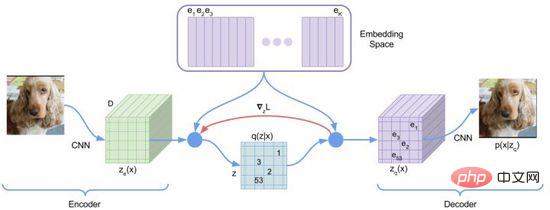
Rajah 12. VQ-VAE
VQ-VAE mempunyai kebarangkalian posterior tertentu disebabkan oleh andaian pemilihan jiran terdekat, iaitu, jarak terdekat Kebarangkalian vektor lapisan tersembunyi ialah 1 dan selebihnya ialah 0, yang bukan rawak proses pemilihan vektor terdekat tidak boleh dibezakan, dan kaedah penganggar lurus digunakan untuk menghantar kecerunan kepada .
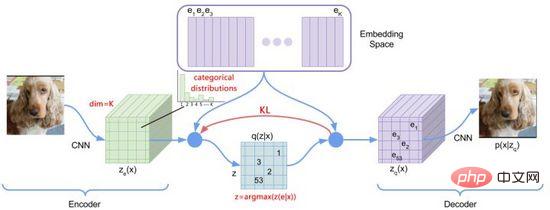
Rajah 13. dVAE
Untuk mengoptimumkan masalah di atas, DALL·E menggunakan Gumbel-Softmax untuk membina dVAE baharu (Rajah 13), penyahkod Keluaran menjadi 32*32 K=8192-kebarangkalian pengelasan dimensi pada Ruang Benam Semasa proses latihan, hingar ditambah pada pengiraan Softmax bagi kebarangkalian pengelasan untuk memperkenalkan rawak, dan suhu menurun secara beransur-ansur digunakan untuk membuat. taburan kebarangkalian anggaran pengekodan satu panas Vektor lapisan dipilih dan diparameterkan semula untuk menjadikannya boleh dibezakan (Persamaan (11)), dan jiran terdekat masih diambil semasa proses inferens.
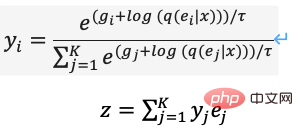
Dalam pelaksanaan PyTorch, hard=True boleh ditetapkan untuk mengeluarkan anggaran pengekodan satu panas, dan pada masa yang sama, melalui y_hard = y_hard - y_soft.detach () + y_soft Pastikan ia boleh dikendalikan.
Apabila peringkat pertama latihan selesai, kami boleh membetulkan dVAE untuk menjana token imej sasaran yang diramalkan untuk setiap pasangan imej teks. Dalam fasa kedua latihan, DALL·E menggunakan kaedah BPE untuk mula-mula mengekod teks ke dalam token teks dengan dimensi yang sama d=3968 sebagai token imej, kemudian menggabungkan token teks dan token imej bersama-sama, menambah pengekodan kedudukan dan pengekodan padding , dan menggunakan Transformer Encoder melakukan ramalan autoregresif, seperti yang ditunjukkan dalam Rajah 14. Untuk meningkatkan kelajuan pengiraan, DALL·E juga menggunakan tiga mekanisme topeng perhatian yang jarang: Baris, Lajur dan Konvolusi.
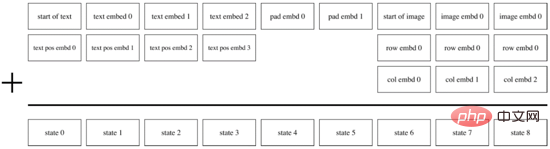
Rajah 14. Penyahkod autoregresif DALL·E
Berdasarkan pelaksanaan di atas, DALL·E bukan sahaja boleh menjana Imej “sebenar” juga boleh disepadukan ke dalam penciptaan, pemahaman pemandangan dan transformasi gaya, seperti yang ditunjukkan dalam Rajah 15. Selain itu, kesan DALL·E mungkin menjadi lebih teruk dalam bidang sampel sifar dan profesional, dan resolusi imej yang dijana (256*256) adalah lebih rendah.

Rajah 15. Pelbagai senario penjanaan DALL·E
4.2 DALL·E 2
Untuk menambah baik lagi penjanaan imej kualiti dan Untuk meneroka kebolehtafsiran ruang ciri imej teks, OpenAI menggabungkan model resapan dan CLIP untuk mencadangkan DALL·E 2 pada April 2022. Ia bukan sahaja meningkatkan saiz penjanaan kepada 1024*1024, tetapi juga menggambarkan teks melalui interpolasi operasi ruang ciri -Proses penghijrahan ruang ciri imej.
Seperti yang ditunjukkan dalam Rajah 16, DALL·E 2 menggunakan pembenaman teks dan pembenaman imej yang diperolehi oleh pembelajaran perbandingan CLIP sebagai input model dan objek ramalan Proses khusus adalah untuk mempelajari Sebelum sebelumnya dan meramalkan pembenaman imej yang sepadan daripada teks. , artikel menggunakan dua kaedah latihan: Transformer autoregresif dan model resapan, yang kedua menunjukkan prestasi yang lebih baik pada setiap set data kemudian mempelajari penyahkod model resapan UnCLIP, yang boleh dianggap sebagai proses terbalik pengekod imej CLIP, dan Ramalan sebelumnya Pembenaman imej yang diperolehi ditambah sebagai syarat untuk mencapai kawalan, dan pembenaman teks dan kandungan teks digunakan sebagai syarat pilihan Untuk menambah baik resolusi, UnCLIP juga menambah dua penyahkod upsampling (rangkaian CNN) untuk menjana terbalik yang lebih besar-. imej bersaiz.
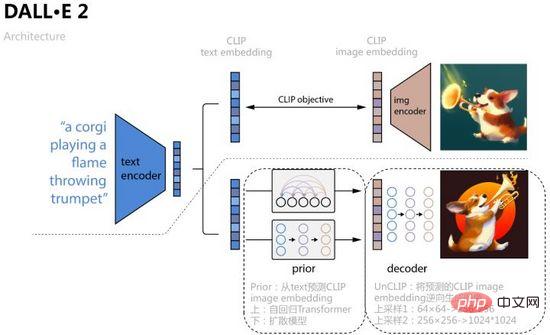
Rajah 16. DALL·E 2
Dalam latihan model resapan Sebelum ini, DALL·E 2 menggunakan Penyahkod Transformer untuk meramalkan proses resapan, masukkan jujukan ialah teks yang dikodkan BPE + pembenaman teks + pembenaman langkah masa+ pembenaman imej bising semasa, ramalkan pembenaman imej yang ditolak, gunakan MSE untuk membina fungsi kehilangan,
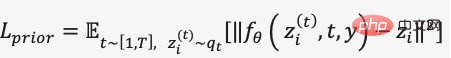
DALL·E 2. Untuk mengelakkan model daripada menghasilkan hasil penjanaan jenis berarah untuk label teks tertentu dan mengurangkan kekayaan ciri, sekatan ditambah pada syarat ramalan model resapan untuk memastikan panduan bebas pengelas. Contohnya, dalam latihan model resapan Prior dan UnCLIP, kebarangkalian jatuh ditetapkan untuk syarat seperti menambah pembenaman teks, supaya proses penjanaan tidak melengkapkan input keadaan bergantung. Oleh itu, dalam proses penjanaan terbalik, kami boleh menjana variasi imej yang sama melalui pensampelan pembenaman imej sambil mengekalkan ciri asas Kami juga boleh menginterpolasi dalam pembenaman imej dan pembenaman teks Mengawal nisbah interpolasi boleh menjana hasil visualisasi penghijrahan yang lancar ditunjukkan dalam rajah 17 yang ditunjukkan.

Rajah 17. Pemeliharaan dan pemindahan ciri imej boleh dicapai oleh DALL·E 2
DALL·E 2 telah melakukan banyak perkara terhadap keberkesanan Prior dan UnCLIP Eksperimen pengesahan, contohnya, melalui tiga kaedah: 1) Hanya masukkan kandungan teks ke dalam model penjanaan UnCLIP 2) Hanya masukkan kandungan teks dan pembenaman teks ke dalam model penjanaan UnCLIP 3) Tambah pembenaman imej yang diramalkan berdasarkan kaedah di atas; tiga kaedah Peningkatan beransur-ansur kesan penjanaan mengesahkan keberkesanan Sebelum. Di samping itu, DALL·E 2 menggunakan PCA untuk mengurangkan dimensi pembenaman ruang lapisan tersembunyi Apabila dimensi dikurangkan, ciri semantik imej yang dijana akan menjadi lemah. Akhir sekali, DALL·E 2 membandingkan kaedah lain pada set data MS-COCO dan mencapai kualiti penjanaan terbaik dengan FID= 10.39 (Rajah 18).
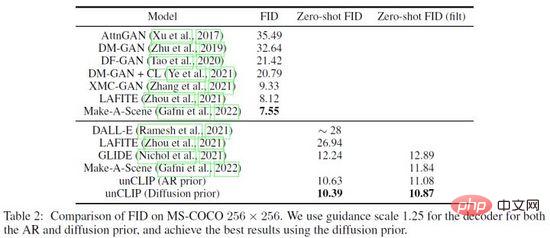
Rajah 18. Hasil perbandingan DALL·E 2 pada dataset MS-COCO
4.3 ERNIE-VILG
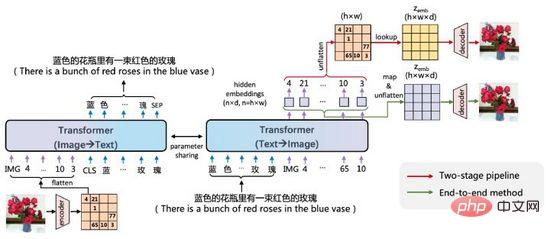
ERNIE-VILG ialah Baidu The model penjanaan dua hala imej teks bagi adegan Cina yang dicadangkan oleh Wen Xin pada awal 2022.
Rajah 19. ERNIE-VILG
Idea ERNIE-VILG adalah serupa dengan DALL·E, yang mengekodkan ciri imej melalui pra- pengekod variasi terlatih , gunakan Transformer untuk meramalkan Token teks dan Token imej secara autoregresif:
- ERNIE-VILG bergantung pada teknologi platform Baidu Wenxin dan boleh mengendalikan adegan Cina >Selain Teks Proses autoregresif -ke-Imej juga memodelkan proses arah Imej-ke-Teks, dan parameter proses dua arah dikongsi
- Semasa proses autoregresif Teks-ke-Imej, tidak ada pemprosesan topeng antara Token Teks ;
- Pengekodan dan penyahkodan imej menggunakan VQ-VAE dan VQ-GAN Proses penyahkodan imej disambungkan dengan proses autoregresif melalui peta&ratakan untuk mencapai latihan hujung ke hujung.
- Satu lagi ciri hebat ERNIE-VILG ialah ia boleh mengendalikan penjanaan berbilang objek dan hubungan kedudukan yang kompleks dalam adegan Cina, seperti yang ditunjukkan dalam Rajah 20.
 Rajah 20. Contoh generasi ERNIE-VILG
Rajah 20. Contoh generasi ERNIE-VILG
4. Ringkasan
Artikel ini mentafsir penjanaan graf berasaskan teks terkini melalui contoh .
Kini, teknologi penjanaan teks ke imej mempunyai ambang yang tinggi, dan kos latihannya jauh lebih tinggi daripada kaedah mod tunggal seperti pengecaman muka, terjemahan mesin dan sintesis pertuturan sebagai contoh, OpenAI mengumpul dan menganotasi 250 juta pasangan sampel telah dikumpulkan, dan 1024 V100 GPU digunakan untuk melatih model dengan 12 bilion parameter. Selain itu, sentiasa ada isu seperti diskriminasi kaum, pornografi ganas dan privasi sensitif dalam bidang penjanaan imej. Bermula pada tahun 2020, semakin banyak pasukan AI telah melabur dalam penyelidikan generasi silang Dalam masa terdekat, kita mungkin tidak dapat dibezakan daripada palsu di dunia nyata dan dunia yang dijana.
Atas ialah kandungan terperinci Daripada Model VAE kepada Diffusion: Artikel yang menerangkan paradigma baharu penggunaan teks untuk menjana gambar rajah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI