


Mentafsir CRISP-ML(Q): Proses Kitaran Hayat Pembelajaran Mesin

Penterjemah |. Bugatti
Penilai |. Sun Shujuan
Pada masa ini, tiada amalan standard untuk membina dan mengurus aplikasi pembelajaran mesin (ML). Projek pembelajaran mesin kurang teratur, kurang kebolehulangan dan cenderung gagal secara langsung dalam jangka masa panjang. Oleh itu, kami memerlukan proses untuk membantu kami mengekalkan kualiti, kemampanan, keteguhan dan pengurusan kos sepanjang kitaran hayat pembelajaran mesin.
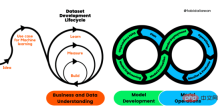
Rajah 1. Proses kitaran hayat pembangunan pembelajaran mesin
Proses standard merentas industri untuk membangunkan aplikasi pembelajaran mesin menggunakan kaedah jaminan kualiti (CRISP-ML(Q )) ialah versi CRISP-DM yang dinaik taraf untuk memastikan kualiti produk pembelajaran mesin.
CRISP-ML (Q) mempunyai enam peringkat berasingan:
1 Pemahaman perniagaan dan data
2 Penyediaan data
3 🎜>
4. Penilaian model 5. Penerapan model 6. Walaupun terdapat susunan dalam rangka kerja, output peringkat kemudian boleh menentukan sama ada kita perlu menyemak semula peringkat sebelumnya.Rajah 2. Jaminan kualiti pada setiap peringkat 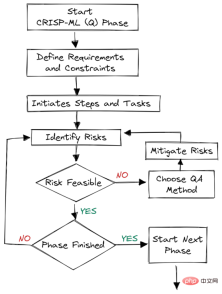
Skop:
Perkara yang kami harap dapat dicapai dengan menggunakan proses pembelajaran mesin. Adakah untuk mengekalkan pelanggan atau mengurangkan kos operasi melalui automasi?Kriteria Kejayaan:
Kita mesti mentakrifkan perniagaan yang jelas dan boleh diukur, pembelajaran mesin (metrik statistik) dan metrik kejayaan ekonomi (KPI).Kebolehlaksanaan:
Kami perlu memastikan ketersediaan data, kesesuaian untuk aplikasi pembelajaran mesin, kekangan undang-undang, keteguhan, kebolehskalaan, kebolehtafsiran dan keperluan sumber.Pengumpulan Data:
Dengan mengumpul data, menjadikannya versi untuk kebolehulangan dan memastikan aliran berterusan data sebenar dan terjana.Pengesahan Kualiti Data:
Pastikan kualiti dengan mengekalkan perihalan, keperluan dan pengesahan data.Untuk memastikan kualiti dan kebolehulangan, kami perlu merekodkan sifat statistik data dan proses penjanaan data.
Penyediaan data Peringkat kedua sangat mudah. Kami akan menyediakan data untuk fasa pemodelan. Ini termasuk pemilihan data, pembersihan data, kejuruteraan ciri, peningkatan data dan normalisasi. 1. Kami bermula dengan pemilihan ciri, pemilihan data dan pengendalian kelas yang tidak seimbang melalui pensampelan berlebihan atau pensampelan terkurang. 2. Kemudian, fokus pada mengurangkan hingar dan mengendalikan nilai yang hilang. Untuk tujuan jaminan kualiti, kami akan menambah ujian unit data untuk mengurangkan nilai yang salah. 3 Bergantung pada model, kami melakukan kejuruteraan ciri dan penambahan data seperti pengekodan dan pengelompokan satu-panas. 4. Ini mengurangkan risiko ciri berat sebelah. Untuk memastikan kebolehulangan, kami mencipta pemodelan data, transformasi dan saluran paip kejuruteraan ciri. Kejuruteraan ModelKekangan dan keperluan fasa pemahaman perniagaan dan data akan menentukan fasa pemodelan. Kita perlu memahami masalah perniagaan dan cara kita akan membangunkan model pembelajaran mesin untuk menyelesaikannya. Kami akan menumpukan pada pemilihan model, pengoptimuman dan latihan, memastikan metrik prestasi model, keteguhan, kebolehskalaan, kebolehtafsiran dan mengoptimumkan sumber storan dan pengkomputeran. 1. Penyelidikan tentang seni bina model dan masalah perniagaan yang serupa. 2. Tentukan penunjuk prestasi model. 3. 4. Fahami pengetahuan domain dengan mengintegrasikan pakar. 5. 6. Pemampatan dan penyepaduan model. Untuk memastikan kualiti dan kebolehulangan, kami akan menyimpan dan metadata model kawalan versi, seperti seni bina model, data latihan dan pengesahan, hiperparameter dan perihalan persekitaran. Akhir sekali, kami akan menjejaki percubaan ML dan membuat saluran paip ML untuk mencipta proses latihan yang boleh berulang. Penilaian ModelIni adalah peringkat di mana kami menguji dan memastikan model sedia untuk digunakan.
- Kami akan menguji prestasi model pada set data ujian.
- Nilai kekukuhan model dengan menyediakan data rawak atau palsu.
- Tingkatkan kebolehtafsiran model untuk memenuhi keperluan kawal selia.
- Bandingkan hasil dengan metrik kejayaan awal secara automatik atau dengan pakar domain.
Setiap langkah fasa penilaian didokumenkan untuk jaminan kualiti.
Pengedaran Model
Penyerahan model ialah peringkat di mana kami menyepadukan model pembelajaran mesin ke dalam sistem sedia ada. Model ini boleh digunakan pada pelayan, penyemak imbas, perisian dan peranti tepi. Ramalan daripada model tersedia dalam papan pemuka BI, API, aplikasi web dan pemalam.
Proses penggunaan model:
- Tentukan inferens perkakasan.
- Penilaian model dalam persekitaran pengeluaran.
- Pastikan penerimaan dan kebolehgunaan pengguna.
- Sediakan pelan sandaran untuk meminimumkan kerugian.
- Strategi penggunaan.
Pemantauan dan Penyelenggaraan
Model dalam persekitaran pengeluaran memerlukan pemantauan dan penyelenggaraan yang berterusan. Kami akan memantau ketepatan masa model, prestasi perkakasan dan prestasi perisian.
Pemantauan berterusan ialah bahagian pertama proses jika prestasi menurun di bawah ambang, keputusan dibuat secara automatik untuk melatih semula model pada data baharu. Tambahan pula, bahagian penyelenggaraan tidak terhad kepada latihan semula model. Ia memerlukan mekanisme membuat keputusan, memperoleh data baharu, mengemas kini perisian dan perkakasan serta menambah baik proses ML berdasarkan kes penggunaan perniagaan.
Ringkasnya, ia adalah penyepaduan berterusan, latihan dan penggunaan model ML.
Kesimpulan
Melatih dan mengesahkan model ialah sebahagian kecil daripada aplikasi ML. Mengubah idea awal menjadi realiti memerlukan beberapa proses. Dalam artikel ini kami memperkenalkan CRISP-ML(Q) dan cara ia memfokuskan pada penilaian risiko dan jaminan kualiti.
Kami mula-mula mentakrifkan matlamat perniagaan, mengumpul dan membersihkan data, membina model, mengesahkan model dengan set data ujian, dan kemudian menggunakannya ke persekitaran pengeluaran.
Satu komponen utama rangka kerja ini ialah pemantauan dan penyelenggaraan yang berterusan. Kami akan memantau data dan metrik perisian dan perkakasan untuk menentukan sama ada untuk melatih semula model atau menaik taraf sistem.
Jika anda baru dalam operasi pembelajaran mesin dan ingin mengetahui lebih lanjut, baca kursus MLOps percuma disemak oleh DataTalks.Club. Anda akan memperoleh pengalaman praktikal dalam kesemua enam fasa, memahami pelaksanaan praktikal CRISP-ML.
Tajuk asal: Memahami CRISP-ML(Q): Proses Kitar Hayat Pembelajaran Mesin, Penulis: Abid Ali Awan
Atas ialah kandungan terperinci Mentafsir CRISP-ML(Q): Proses Kitaran Hayat Pembelajaran Mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Cara Membina Pembantu AI Peribadi Anda Dengan Huggingface SmollmApr 18, 2025 am 11:52 AM
Cara Membina Pembantu AI Peribadi Anda Dengan Huggingface SmollmApr 18, 2025 am 11:52 AMMemanfaatkan kuasa AI di peranti: Membina CLI Chatbot Peribadi Pada masa lalu, konsep pembantu AI peribadi kelihatan seperti fiksyen sains. Bayangkan Alex, seorang peminat teknologi, bermimpi seorang sahabat AI yang pintar, yang tidak bergantung
 AI untuk Kesihatan Mental dianalisis dengan penuh perhatian melalui inisiatif baru yang menarik di Stanford UniversityApr 18, 2025 am 11:49 AM
AI untuk Kesihatan Mental dianalisis dengan penuh perhatian melalui inisiatif baru yang menarik di Stanford UniversityApr 18, 2025 am 11:49 AMPelancaran AI4MH mereka berlaku pada 15 April, 2025, dan Luminary Dr. Tom Insel, M.D., pakar psikiatri yang terkenal dan pakar neurosains, berkhidmat sebagai penceramah kick-off. Dr. Insel terkenal dengan kerja cemerlangnya dalam penyelidikan kesihatan mental dan techno
 Kelas Draf WNBA 2025 memasuki liga yang semakin meningkat dan melawan gangguan dalam talianApr 18, 2025 am 11:44 AM
Kelas Draf WNBA 2025 memasuki liga yang semakin meningkat dan melawan gangguan dalam talianApr 18, 2025 am 11:44 AM"Kami mahu memastikan bahawa WNBA kekal sebagai ruang di mana semua orang, pemain, peminat dan rakan kongsi korporat, berasa selamat, dihargai dan diberi kuasa," kata Engelbert, menangani apa yang telah menjadi salah satu cabaran sukan wanita yang paling merosakkan. Anno
 Panduan Komprehensif untuk Struktur Data Terbina Python - Analytics VidhyaApr 18, 2025 am 11:43 AM
Panduan Komprehensif untuk Struktur Data Terbina Python - Analytics VidhyaApr 18, 2025 am 11:43 AMPengenalan Python cemerlang sebagai bahasa pengaturcaraan, terutamanya dalam sains data dan AI generatif. Manipulasi data yang cekap (penyimpanan, pengurusan, dan akses) adalah penting apabila berurusan dengan dataset yang besar. Kami pernah meliputi nombor dan st
 Tayangan pertama dari model baru Openai berbanding dengan alternatifApr 18, 2025 am 11:41 AM
Tayangan pertama dari model baru Openai berbanding dengan alternatifApr 18, 2025 am 11:41 AMSebelum menyelam, kaveat penting: Prestasi AI adalah spesifik yang tidak ditentukan dan sangat digunakan. Dalam istilah yang lebih mudah, perbatuan anda mungkin berbeza -beza. Jangan ambil artikel ini (atau lain -lain) sebagai perkataan akhir -sebaliknya, uji model ini pada senario anda sendiri
 AI Portfolio | Bagaimana untuk membina portfolio untuk kerjaya AI?Apr 18, 2025 am 11:40 AM
AI Portfolio | Bagaimana untuk membina portfolio untuk kerjaya AI?Apr 18, 2025 am 11:40 AMMembina portfolio AI/ML yang menonjol: Panduan untuk Pemula dan Profesional Mewujudkan portfolio yang menarik adalah penting untuk mendapatkan peranan dalam kecerdasan buatan (AI) dan pembelajaran mesin (ML). Panduan ini memberi nasihat untuk membina portfolio
 AI AI apa yang boleh dimaksudkan untuk operasi keselamatanApr 18, 2025 am 11:36 AM
AI AI apa yang boleh dimaksudkan untuk operasi keselamatanApr 18, 2025 am 11:36 AMHasilnya? Pembakaran, ketidakcekapan, dan jurang yang melebar antara pengesanan dan tindakan. Tak satu pun dari ini harus datang sebagai kejutan kepada sesiapa yang bekerja dalam keselamatan siber. Janji Agentic AI telah muncul sebagai titik perubahan yang berpotensi. Kelas baru ini
 Google Versus Openai: AI berjuang untuk pelajarApr 18, 2025 am 11:31 AM
Google Versus Openai: AI berjuang untuk pelajarApr 18, 2025 am 11:31 AMImpak segera berbanding perkongsian jangka panjang? Dua minggu yang lalu Openai melangkah ke hadapan dengan tawaran jangka pendek yang kuat, memberikan akses kepada pelajar A.S. dan Kanada.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

