
Rumah >Peranti teknologi >AI >Saya mencipta chatbot suara yang dikuasakan oleh API ChatGPT, sila ikut arahan
Saya mencipta chatbot suara yang dikuasakan oleh API ChatGPT, sila ikut arahan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-07 23:01:012536semak imbas
Artikel hari ini memfokuskan pada mencipta aplikasi web Chatbot suara peribadi menggunakan API ChatGPT. Tujuannya adalah untuk meneroka dan menemui lebih banyak kes penggunaan yang berpotensi dan peluang perniagaan untuk kecerdasan buatan. Saya akan membimbing anda langkah demi langkah melalui proses pembangunan untuk memastikan anda memahami dan boleh meniru proses itu untuk anda sendiri.
Mengapa anda memerlukannya
- Bukan semua orang mengalu-alukan perkhidmatan berasaskan menaip, bayangkan kanak-kanak yang masih belajar kemahiran menulis atau warga emas yang tidak dapat melihat perkataan dengan betul pada skrin. AI Chatbot berasaskan suara ialah penyelesaian kepada masalah ini, seperti cara ia membantu anak saya meminta Chatbot suaranya membacakan cerita sebelum tidur kepadanya.
- Memandangkan pilihan pembantu sedia ada yang tersedia, seperti Siri Apple dan Alexa Amazon, menambah interaksi suara pada model GPT boleh membuka lebih banyak kemungkinan. API ChatGPT mempunyai kelebihan keupayaan unggulnya untuk mencipta respons yang koheren dan kontekstual, yang digabungkan dengan idea sambungan rumah pintar berasaskan suara, boleh menawarkan banyak peluang perniagaan. Pembantu suara yang kami buat dalam artikel ini akan berfungsi sebagai titik masuk.
Teori yang cukup, mari kita mulakan.
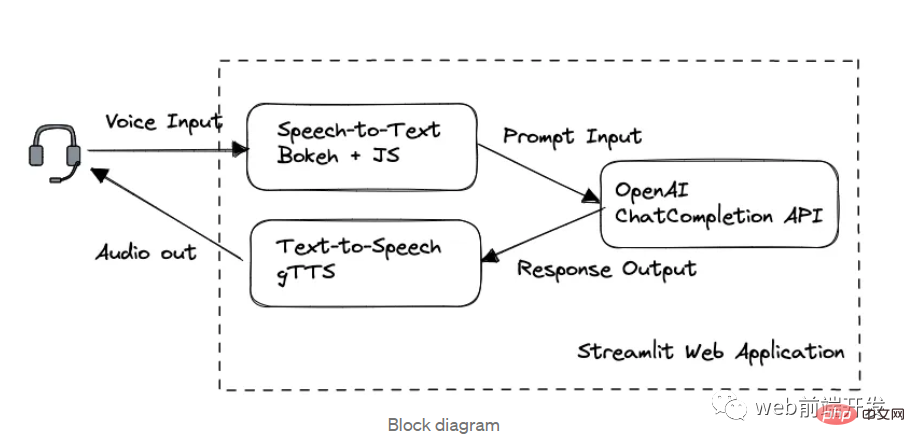
1. Gambar rajah blok
Dalam aplikasi ini, kami dibahagikan kepada tiga modul utama dalam urutan pemprosesan:
- Bokeh dan Ucapan Web to Text with Speech API
- Sembang melalui OpenAI GPT-3.5 API
- gTTS Text to Speech
Rangka kerja web dibina oleh Streamlit.
Jika anda sudah tahu cara menggunakan OpenAI API di bawah model GPT 3.5 dan cara mereka bentuk aplikasi web menggunakan Streamlit, adalah disyorkan agar anda langkau Bahagian 1 dan Bahagian 2 untuk menjimatkan masa membaca.
2. OpenAI GPT API
Dapatkan kunci API anda
Jika anda sudah mempunyai kunci API OpenAI, gunakannya dan bukannya membuat kunci baru. Walau bagaimanapun, jika anda baru menggunakan OpenAI, sila daftar akaun baharu dan cari halaman berikut dalam menu akaun anda:
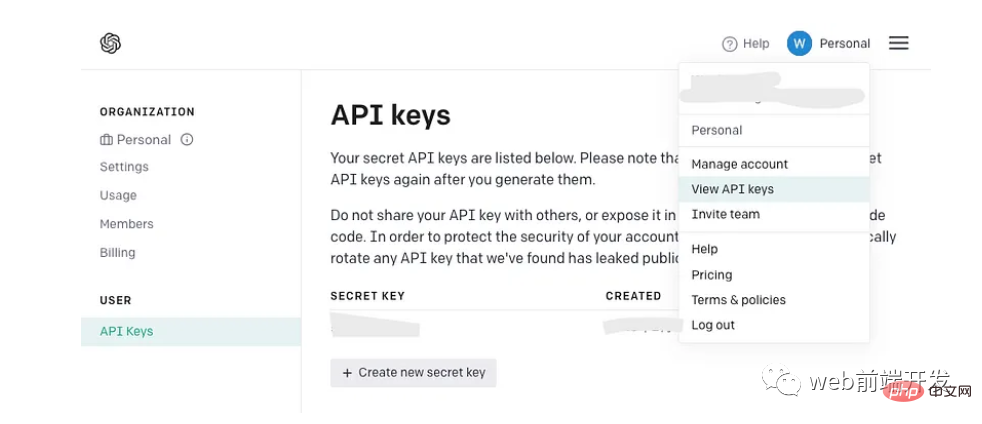
Selepas menjana kunci API , ingat ia hanya akan muncul sekali, jadi pastikan anda menyalinnya ke tempat yang selamat untuk kegunaan masa hadapan.
Penggunaan API ChatCompletion
Pada masa ini GPT-4.0 baru sahaja dikeluarkan, dan API model ini belum dikeluarkan sepenuhnya, jadi saya akan memperkenalkan pembangunan model masih GPT 3.5, yang sudah cukup untuk melengkapkan demo Chatbot suara AI kami.
Sekarang mari kita lihat demo paling ringkas daripada OpenAI untuk memahami definisi asas API ChatCompletion (juga dikenali sebagai API gpt-3.5 atau API ChatGPT):
Pakej pemasangan:
!pip install opena
Jika sebelum ini anda telah membangunkan beberapa model GPT warisan daripada OpenAI, anda mungkin perlu meningkatkan pakej anda melalui pip:
!pip install --upgrade openai
Buat dan hantar petua:
import openai
complete = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)Terima respons teks:
message=complete.choices[0].message.content
Oleh kerana API GPT 3.5 ialah API pelengkapan teks berasaskan sembang, pastikan badan mesej permintaan ChatCompletion mengandungi sejarah perbualan sebagai konteks, anda mahu model tersebut rujukan untuk menjadi Respons yang lebih kontekstual untuk membalas permintaan semasa anda.
Untuk melaksanakan fungsi ini, senarai objek badan mesej hendaklah disusun mengikut susunan berikut:
- Mesej sistem ditakrifkan sebagai tetapan untuk chatbot dengan menambahkan arahan dalam kandungan di bahagian atas senarai mesej Gelagat. Seperti yang dinyatakan dalam pengenalan, ciri ini pada masa ini tidak dikeluarkan sepenuhnya dalam gpt-3.5-turbo-0301.
- Mesej pengguna mewakili input atau pertanyaan pengguna, manakala mesej pembantu merujuk kepada respons yang sepadan daripada API GPT-3.5. Perbualan berpasangan sedemikian menyediakan rujukan untuk model tentang konteks.
- Mesej pengguna terakhir merujuk kepada gesaan yang diminta pada masa semasa.
3. Pembangunan Web
Kami akan terus menggunakan perpustakaan Streamlit yang berkuasa untuk membina aplikasi web.
Streamlit ialah rangka kerja sumber terbuka yang membolehkan saintis data dan pembangun membina dan berkongsi aplikasi web interaktif dengan cepat untuk pembelajaran mesin dan projek sains data. Ia juga menyediakan sekumpulan widget yang boleh dibuat dengan hanya satu baris kod python, seperti st.table(...).
Jika anda tidak begitu mahir dalam pembangunan web dan tidak bersedia untuk membina aplikasi komersial yang besar seperti saya, Streamlit sentiasa menjadi salah satu pilihan terbaik anda kerana ia hampir tidak memerlukan kepakaran dalam HTML.
Mari kita lihat contoh pantas membina aplikasi web Streamlit:
Pasang pakej:
!pip install streamlit
Buat fail Python "demo.py":
import streamlit as st
st.write("""
# My First App
Hello *world!*
""")Jalankan pada mesin tempatan atau pelayan jauh anda:
!python -m streamlit run demo.py
Selepas mencetak output ini, anda boleh mengakses tapak web anda melalui alamat dan port yang disenaraikan:
You can now view your Streamlit app in your browser. Network URL: http://xxx.xxx.xxx.xxx:8501 External URL: http://xxx.xxx.xxx.xxx:8501

Streamlit 提供的所有小部件的用法可以在其文档页面中找到:https://docs.streamlit.io/library/api-reference
4.语音转文字的实现
此 AI 语音聊天机器人的主要功能之一是它能够识别用户语音并生成我们的 ChatCompletion API 可用作输入的适当文本。
OpenAI 的 Whisper API 提供的高质量语音识别是一个很好的选择,但它是有代价的。或者,来自 Javascript 的免费 Web Speech API 提供可靠的多语言支持和令人印象深刻的性能。
虽然开发 Python 项目似乎与定制的 Javascript 不兼容,但不要害怕!在下一部分中,我将介绍一种在 Python 程序中调用 Javascript 代码的简单技术。
不管怎样,让我们看看如何使用 Web Speech API 快速开发语音转文本演示。您可以找到它的文档(地址:https://wicg.github.io/speech-api/)。
语音识别的实现可以很容易地完成,如下所示。
var recognition = new webkitSpeechRecognition(); recognition.continuous = false; recognition.interimResults = true; recognition.lang = 'en'; recognition.start();
通过方法 webkitSpeechRecognition() 初始化识别对象后,需要定义一些有用的属性。continuous 属性表示您是否希望 SpeechRecognition 函数在语音输入的一种模式处理成功完成后继续工作。
我将其设置为 false,因为我希望语音聊天机器人能够以稳定的速度根据用户语音输入生成每个答案。
设置为 true 的 interimResults 属性将在用户语音期间生成一些中间结果,以便用户可以看到从他们的语音输入输出的动态消息。
lang 属性将设置请求识别的语言。请注意,如果它在代码中是未设置,则默认语言将来自 HTML 文档根元素和关联的层次结构,因此在其系统中使用不同语言设置的用户可能会有不同的体验。
识别对象有多个事件,我们使用 .onresult 回调来处理来自中间结果和最终结果的文本生成结果。
recognition.onresult = function (e) {
var value, value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
}5.引入Bokeh库
从用户界面的定义来看,我们想设计一个按钮来启动我们在上一节中已经用 Javascript 实现的语音识别。

Streamlit 库不支持自定义 JS 代码,所以我们引入了 Bokeh。Bokeh 库是另一个强大的 Python 数据可视化工具。可以支持我们的演示的最佳部分之一是嵌入自定义 Javascript 代码,这意味着我们可以在 Bokeh 的按钮小部件下运行我们的语音识别脚本。
为此,我们应该安装 Bokeh 包。为了兼容后面会提到的streamlit-bokeh-events库,Bokeh的版本应该是2.4.2:
!pip install bokeh==2.4.2
导入按钮和 CustomJS:
from bokeh.models.widgets import Button from bokeh.models import CustomJS
创建按钮小部件:
spk_button = Button(label='SPEAK', button_type='success')
定义按钮点击事件:
spk_button.js_on_event("button_click", CustomJS(code="""
...js code...
"""))定义了.js_on_event()方法来注册spk_button的事件。
在这种情况下,我们注册了“button_click”事件,该事件将在用户单击后触发由 CustomJS() 方法嵌入的 JS 代码块…js 代码…的执行。
Streamlit_bokeh_event
speak 按钮及其回调方法实现后,下一步是将 Bokeh 事件输出(识别的文本)连接到其他功能块,以便将提示文本发送到 ChatGPT API。
幸运的是,有一个名为“Streamlit Bokeh Events”的开源项目专为此目的而设计,它提供与 Bokeh 小部件的双向通信。你可以在这里找到它的 GitHub 页面。
这个库的使用非常简单。首先安装包:
!pip install streamlit-bokeh-events
通过 streamlit_bokeh_events 方法创建结果对象。
result = streamlit_bokeh_events( bokeh_plot = spk_button, events="GET_TEXT,GET_ONREC,GET_INTRM", key="listen", refresh_on_update=False, override_height=75, debounce_time=0)
使用 bokeh_plot 属性来注册我们在上一节中创建的 spk_button。使用 events 属性来标记多个自定义的 HTML 文档事件
- GET_TEXT 接收最终识别文本
- GET_INTRM 接收临时识别文本
- GET_ONREC 接收语音处理阶段
我们可以使用 JS 函数 document.dispatchEvent(new CustomEvent(…)) 来生成事件,例如 GET_TEXT 和 GET_INTRM 事件:
spk_button.js_on_event("button_click", CustomJS(code="""
var recognition = new webkitSpeechRecognition();
recognition.continuous = false;
recognition.interimResults = true;
recognition.lang = 'en';
var value, value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
document.dispatchEvent(new CustomEvent("GET_TEXT", {detail: {t:value, s:rand}}));
document.dispatchEvent(new CustomEvent("GET_INTRM", {detail: value2}));
recognition.start();
}
"""))并且,检查事件 GET_INTRM 处理的 result.get() 方法,例如:
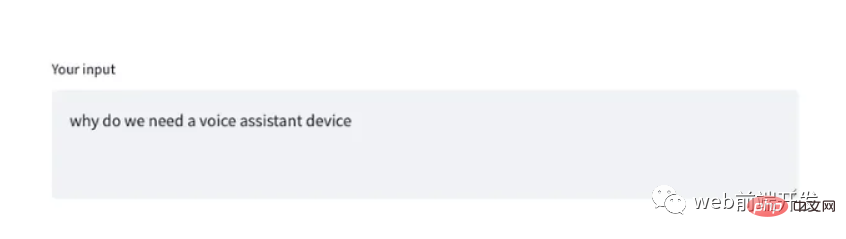
tr = st.empty()
if result:
if "GET_INTRM" in result:
if result.get("GET_INTRM") != '':
tr.text_area("**Your input**", result.get("GET_INTRM"))这两个代码片段表明,当用户正在讲话时,任何临时识别文本都将显示在 Streamlit text_area 小部件上:
6. 文字转语音实现
提示请求完成,GPT-3.5模型通过ChatGPT API生成响应后,我们通过Streamlit st.write()方法将响应文本直接显示在网页上。

但是,我们需要将文本转换为语音,这样我们的 AI 语音 Chatbot 的双向功能才能完全完成。
有一个名为“gTTS”的流行 Python 库能够完美地完成这项工作。在与谷歌翻译的文本转语音 API 接口后,它支持多种格式的语音数据输出,包括 mp3 或 stdout。你可以在这里找到它的 GitHub 页面。
只需几行代码即可完成转换。首先安装包:
!pip install gTTS
在这个演示中,我们不想将语音数据保存到文件中,所以我们可以调用 BytesIO() 来临时存储语音数据:
sound = BytesIO() tts = gTTS(output, lang='en', tld='com') tts.write_to_fp(sound)
输出的是要转换的文本字符串,你可以根据自己的喜好,通过tld从不同的google域中选择不同的语言by lang。例如,您可以设置 tld='co.uk' 以生成英式英语口音。
然后,通过 Streamlit 小部件创建一个像样的音频播放器:
st.audio(sound)
全语音聊天机器人
要整合上述所有模块,我们应该完成完整的功能:
- 已完成与 ChatCompletion API 的交互,并在用户和助手消息块中定义了附加的历史对话。使用 Streamlit 的 st.session_state 来存储运行变量。
- 考虑到 .onspeechstart()、.onsoundend() 和 .onerror() 等多个事件以及识别过程,在 SPEAK 按钮的 CustomJS 中完成了事件生成。
- 完成事件“GET_TEXT、GET_ONREC、GET_INTRM”的事件处理,以在网络界面上显示适当的信息,并管理用户讲话时的文本显示和组装。
- 所有必要的 Streamit 小部件
请找到完整的演示代码供您参考:
import streamlit as st
from bokeh.models.widgets import Button
from bokeh.models import CustomJS
from streamlit_bokeh_events import streamlit_bokeh_events
from gtts import gTTS
from io import BytesIO
import openai
openai.api_key = '{Your API Key}'
if 'prompts' not in st.session_state:
st.session_state['prompts'] = [{"role": "system", "content": "You are a helpful assistant. Answer as concisely as possible with a little humor expression."}]
def generate_response(prompt):
st.session_state['prompts'].append({"role": "user", "content":prompt})
completinotallow=openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages = st.session_state['prompts']
)
message=completion.choices[0].message.content
return message
sound = BytesIO()
placeholder = st.container()
placeholder.title("Yeyu's Voice ChatBot")
stt_button = Button(label='SPEAK', button_type='success', margin = (5, 5, 5, 5), width=200)
stt_button.js_on_event("button_click", CustomJS(code="""
var value = "";
var rand = 0;
var recognition = new webkitSpeechRecognition();
recognition.continuous = false;
recognition.interimResults = true;
recognition.lang = 'en';
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'start'}));
recognition.onspeechstart = function () {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'running'}));
}
recognition.onsoundend = function () {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'stop'}));
}
recognition.onresult = function (e) {
var value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
document.dispatchEvent(new CustomEvent("GET_TEXT", {detail: {t:value, s:rand}}));
document.dispatchEvent(new CustomEvent("GET_INTRM", {detail: value2}));
}
recognition.onerror = function(e) {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'stop'}));
}
recognition.start();
"""))
result = streamlit_bokeh_events(
bokeh_plot = stt_button,
events="GET_TEXT,GET_ONREC,GET_INTRM",
key="listen",
refresh_on_update=False,
override_height=75,
debounce_time=0)
tr = st.empty()
if 'input' not in st.session_state:
st.session_state['input'] = dict(text='', sessinotallow=0)
tr.text_area("**Your input**", value=st.session_state['input']['text'])
if result:
if "GET_TEXT" in result:
if result.get("GET_TEXT")["t"] != '' and result.get("GET_TEXT")["s"] != st.session_state['input']['session'] :
st.session_state['input']['text'] = result.get("GET_TEXT")["t"]
tr.text_area("**Your input**", value=st.session_state['input']['text'])
st.session_state['input']['session'] = result.get("GET_TEXT")["s"]
if "GET_INTRM" in result:
if result.get("GET_INTRM") != '':
tr.text_area("**Your input**", value=st.session_state['input']['text']+' '+result.get("GET_INTRM"))
if "GET_ONREC" in result:
if result.get("GET_ONREC") == 'start':
placeholder.image("recon.gif")
st.session_state['input']['text'] = ''
elif result.get("GET_ONREC") == 'running':
placeholder.image("recon.gif")
elif result.get("GET_ONREC") == 'stop':
placeholder.image("recon.jpg")
if st.session_state['input']['text'] != '':
input = st.session_state['input']['text']
output = generate_response(input)
st.write("**ChatBot:**")
st.write(output)
st.session_state['input']['text'] = ''
tts = gTTS(output, lang='en', tld='com')
tts.write_to_fp(sound)
st.audio(sound)
st.session_state['prompts'].append({"role": "user", "content":input})
st.session_state['prompts'].append({"role": "assistant", "content":output})输入后:
!python -m streamlit run demo_voice.py
您最终会在网络浏览器上看到一个简单但智能的语音聊天机器人。
请注意:不要忘记在弹出请求时允许网页访问您的麦克风和扬声器。
就是这样,一个简单聊天机器人就完成了。
最后,希望您能在本文中找到有用的东西,感谢您的阅读!
Atas ialah kandungan terperinci Saya mencipta chatbot suara yang dikuasakan oleh API ChatGPT, sila ikut arahan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI